利用转录组数据挖掘东紫苏单萜生物合成相关基因
2021-06-11耿秀文张爱丽唐仁华普春霞
耿秀文,张爱丽,唐仁华,普春霞
云南中医药大学 中药材优良种苗繁育工程中心,云南 昆明 650500
东紫苏Elsholtzia bodinieriVaniot 为唇形科荆芥亚科(Nepetoideae)香薷族(Elsholtzieae)香薷属ElsholtziaL.的植物,又名凤尾茶、牙刷草、小山茶、野山茶等,主产于云南滇中、滇南地区,生于海拔1200~3000 m 的山坡草地、稀疏松林中或石山上。东紫苏全草入药,气清香,味辛、微苦,用于感冒、咽喉痛、头痛、扁桃腺炎、小儿口腔炎、牙痛、眼结膜炎、肝炎、消化不良[1-3]。东紫苏含有挥发油、黄酮类、三萜类、酚类等成分[4]。现代药理研究表明,东紫苏具有抑菌[5-6]、抗病毒[6-7]、抗氧化[8-9]、调血脂[10]的作用。
香薷属植物的挥发油被认为具有抗菌、抗氧化等作用[11]。前期课题组对东紫苏15 个居群叶的挥发油进行GC-MS 分析[12],初步确定1,8-桉叶油醇(1, 8-cineole)、α-乙酸松油酯(α-terpinyl acetate)、β-蒎烯(β-pinene)、α-蒎烯(α-pinene)等为东紫苏叶挥发油的主成分,其中单萜为 72.469%~91.855%,倍半萜为3.727%~13.121%。付立卓等[13]、程伟贤等[14]的研究结果在主成分上与本课题组的研究结果基本一致[15]。根据文献报道,1, 8-桉叶油醇有抗炎和镇痛作用[16],对气道炎症具有抑制作用[17],能够减少鼻窦炎的恶化,预防慢性阻塞性肺病加重和改善哮喘[18-20],并且还有解痉和抗菌活性[21],以及一定的止泻作用[22]。
单萜化合物是由2 个异戊二烯结构单元(C10)组成的链状或环状化合物,是一类结构多样的天然化合物,广泛存在于植物挥发油和树脂中[23]。植物单萜(monoterpenoid)由质体内的4-磷酸-2-甲基赤藓糖(2-C-methyl-D-erythritol 4-phosphate,MEP)途径合成,香叶基二磷酸(geranyl diphosphate,GPP)是所有单萜共同的前体物质,GPP 在单萜合酶(monoterpene synthases,mono-TPS)的催化作用下生成单萜,单萜合酶是单萜生物合成的关键酶[24]。东紫苏叶挥发油的主成分1,8-桉叶油醇应是由GPP在桉叶油醇合酶(cineole synthase)的作用下形成[25]。
转录组测序数据是挖掘基因以及参与各种代谢途径的酶的有效方法[26],现已广泛应用于药用植物和芳香植物中次生代谢产物生物合成的关键基因的研究和鉴定[27]。本研究通过对东紫苏进行转录组测序,对测序数据进行组装、拼接及注释,并初步挖掘了东紫苏单萜类化合物代谢途径的相关基因,为东紫苏挥发油单萜合酶基因的克隆、次生代谢生物合成途径解析以及功能验证的研究提供了基因资源和理论基础。
1 材料
样本于2015年11月3日采自云南省昆明市呈贡区松茂水库(经度102°55′18″,纬度24°53′25″,海拔2114 m),编号SM;于2015年11月7日采自云南省昆明市嵩明县阿子营村(经度102°47′43″,纬度25°21′25″,海拔2086 m),编号AZY;原植物由云南中医药大学普春霞副教授鉴定为东紫苏E.bodinieriVaniot。样本材料采集后,移栽至云南中医药大学呈贡校区,于2017年11月22日采样后送转录组测序。
2 方法
2.1 东紫苏挥发油的提取及GC-MS 分析
采用水蒸气蒸馏法提取SM 和AZY 2 个产地东紫苏叶片中的挥发油,利用GC-MS 法分析检测其主要成分及含量。
2.1.1 气相条件 色谱柱:Agilent 19091J-115,HP-5(5% Phenyl Methyl Siloxan,50 m×0.32 mm×0.52 μm);进样口温度250 ℃,检测器(氢火焰离子检测器,FID)温度250 ℃;柱箱升温程序:50 ℃升到250 ℃,每分钟升10 ℃;进样量1 μL;分流比20∶1;进样口压力102.28 kPa;体积流量2.1 mL/min;载气为高纯氦气。
2.1.2 质谱条件 电离方式:EI,电子轰击能量:70 eV,扫描范围m/z50~550;离子源温度230 ℃;四极杆温度150 ℃;定量方法:相对峰面积归一化法;谱库:NIST14。
2.2 转录组测序
采集东紫苏2 个产地叶的样品材料,委托北京诺禾致源科技股份有限公司利用Illumina Hiseq 2000 进行高通量转录组测序。
2.3 转录组数据组装
得到原始测序数据后,为保证信息分析质量,去除带接头的、N(N 表示无法确定碱基信息)的比例大于10%的以及低质量reads,对raw reads 过滤,得到clean reads,然后采用Trinity 对clean reads进行拼接组装,最后得到unigenes。
2.4 转录组功能注释
将组装得到的unigenes 序列比对到NCBI 官方的蛋白序列数据库(RefSeq non-redundant proteins,NR)、NCBI 官方的核酸序列数据库(nucleotide sequence database,NT)、京都基因与基因组百科全书(Kyoto encyclopedia of genes and genomes,KEGG)、Swiss-Prot 蛋白质数据库(A manually annotated and reviewed protein sequence database,Swiss-prot)、蛋白质家族数据库(Protein family,PFAM)、基因本体论数据库(gene ontology,GO)、真核生物蛋白质同源簇数据库(clusters of orthologous groups for eukaryotic complete genomes,KOG)这7 个数据库进行基因功能注释。
2.5 东紫苏挥发油单萜合成相关候选基因筛选及克隆
从转录组数据中筛选出东紫苏挥发油单萜合成相关候选基因,获得基因序列和开放阅读框(ORF),筛选ORF 长度大于700 bp 的基因,分别设计ORF 扩增引物。全部引物由生工生物工程(上海)股份有限公司合成(表1)。
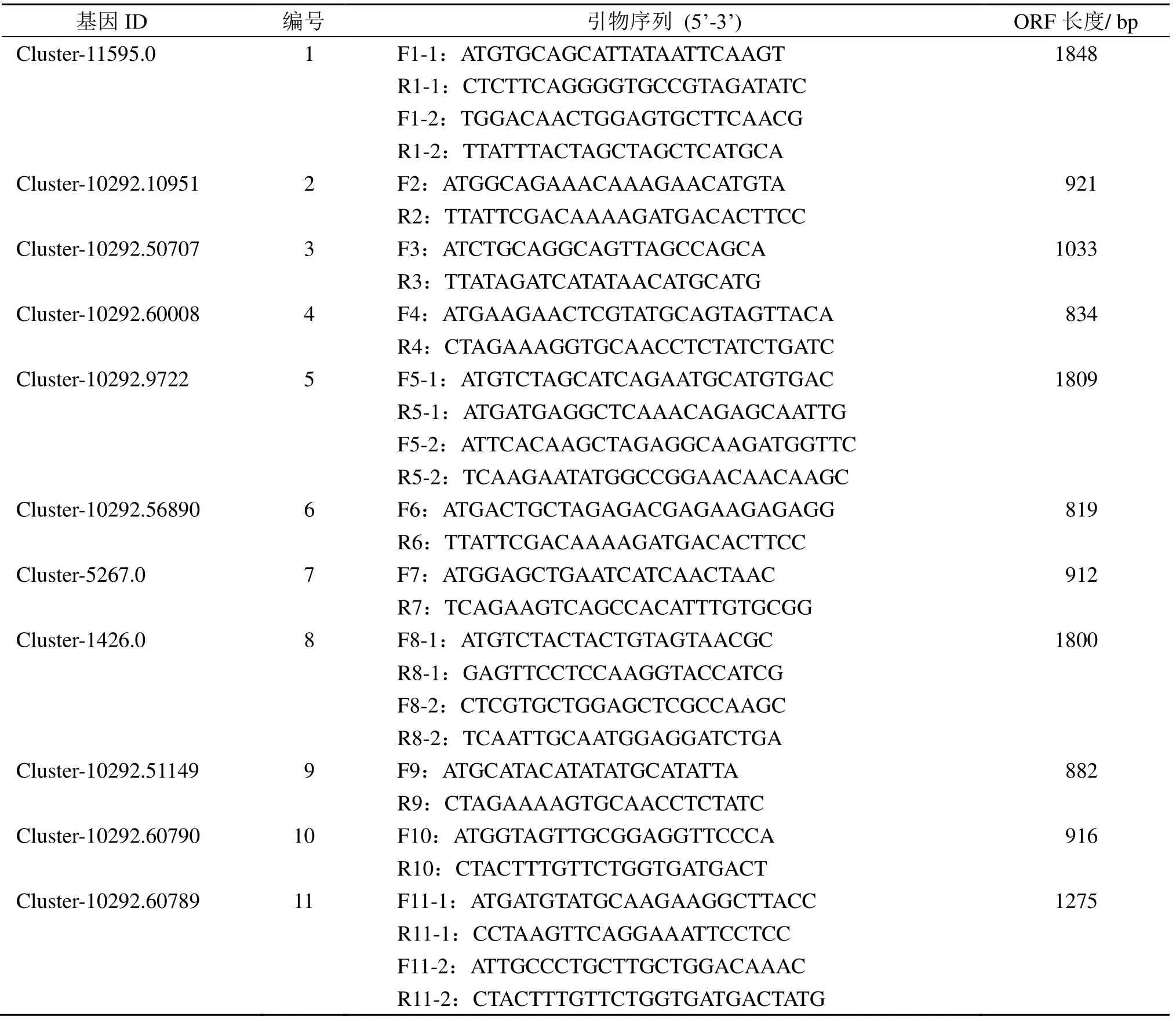
表1 基因与引物序列Table 1 Gene and primer sequences
2.6 东紫苏单萜合成相关候选基因RT-PCR 验证
取东紫苏叶片总RNA 4 μL,按照TaKaRa 公司的PrimeScriptTMII 1st Strand cDNA Synthesis Kit 试剂盒说明书进行反转录反应,合成cDNA。以cDNA为模板,反应体系(50 μL):模板2 μL,正反向引物各1 μL,TaKaRa Taq DNA 聚合酶25 μL,灭菌双蒸水21 μL。PCR 反应程序为98 ℃、30 s;98 ℃、 10 s,58 ℃、20 s,72 ℃、2 min,30 个循环;72 ℃、8 min,12 ℃保温。PCR 产物经电泳分析后,送生工生物工程(上海)股份有限公司测序。
3 结果与分析
3.1 东紫苏挥发油GC-MS 成分测定
按设定的GC-MS 条件分析东紫苏挥发油的化学成分,经NIST14 谱库检索、质谱分析等确定挥发油的化学成分,并用面积归一化法计算各组分的相对含量,其中1,8-桉叶油醇和α-乙酸松油酯均为含量较高的成分。从图1 可以看出,产自松茂的东紫苏叶挥发油含量最高的成分为α-乙酸松油酯,其次是β-蒎烯;而产自阿子营的东紫苏叶挥发油含量最高的成分为1,8-桉叶油醇,其次是β-蒎烯。
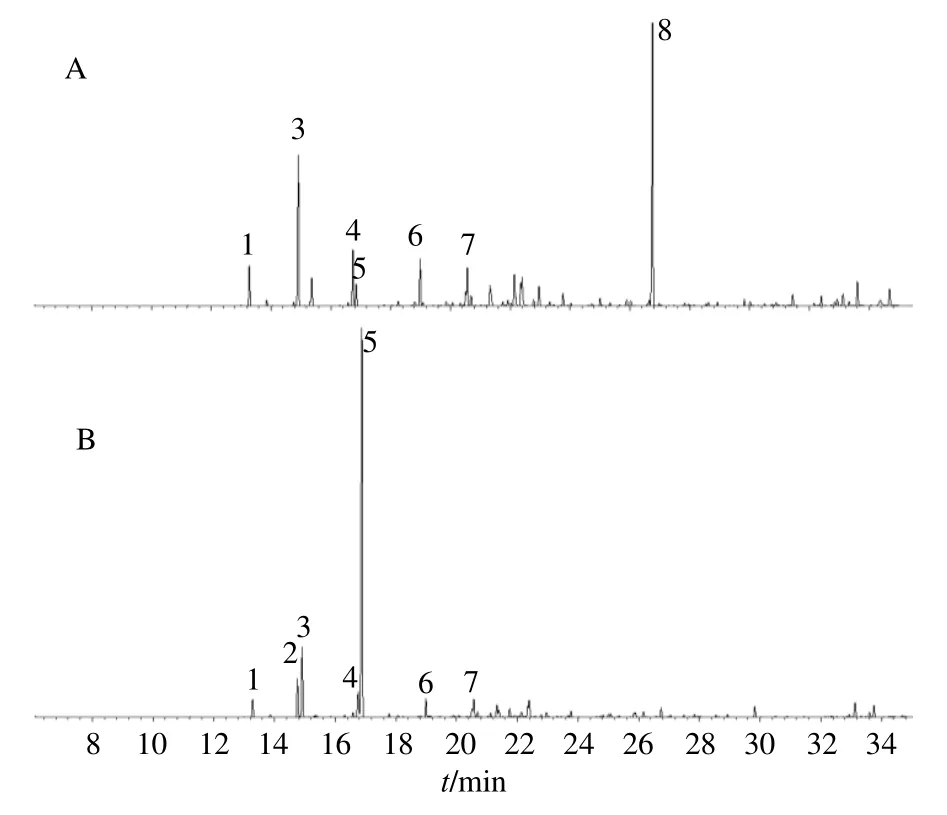
图1 SM (A) 和AZY (B) 产东紫苏挥发油GC-MSFig.1 GC-MS charts of essential oil from E.bodinieri from SM (A) and AZY (B)
3.2 东紫苏转录组数据组装与质量分析
东紫苏转录组测序总计得到93 531 502 条raw reads,过滤产生了91 169 356 条高质量clean reads,共计13.67 Gb 的有效数据,Q20(Phred 数值大于20的碱基占总体碱基的百分比)SM 为94.67%,AZY为94.62%;Q30(Phred 数值大于30 的碱基占总体碱基的百分比)SM 为86.81%,AZY 为86.76%;GC 含量(clean reads 中G 与C 占4 种碱基的百分比)SM 为47.99%,AZY 为47.17%。测序后得到的东紫苏转录组数据产出质量见表2。运用Trinity 软件将质控后得到的高质量序列进行组装,得到153 657 个transcripts,获得93 327 个unigenes,其中unigenes 的总长度为163 878 269 bp,平均长度为1756 bp,N50为2333 bp。unigenes 长度分布图(图2)显示,63 142条unigenes 长度超过1000 bp,31 407 条unigenes 长度超过2000 bp。以上结果表明本研究转录组测序及组装完整性较高,能够进行后续的注释分析。转录组数据已上传至 NCBI 公共数据库,登录号为SRR14567298、SRR14567299。
3.3 东紫苏转录组unigenes 的功能注释
使用BLAST 将拼装所得的unigenes 分别与NR、NT、KEGG、Swiss-prot、PFAM、GO、KOG这7 个数据库进行比对分析,对各数据库注释的unigenes 数目进行统计,进而获得东紫苏转录组unigenes 的功能注释信息,比对结果见表3。结果表明,80 420 条unigenes(86.17%)在NR 数据库比对成功得到注释,在KEGG、Swiss-port、GO、KOG 等数据库获得注释的unigenes 数目依次为34 354 条(36.81%)、64 873 条(69.51%)、61 194条(65.56%)、25 391 条(27.2%)。15 115 条unigenes同时在所有数据库中注释,至少在1 个数据库注释成功的unigenes 有83 704 条(89.68%)。

表2 东紫苏转录组数据产出质量Table 2 Quality of output of E.bodinieri transcriptome data

图2 东紫苏转录组unigenes 长度分布图Fig.2 Length distribution of unigenes in transcriptome of E.bodinieri

表3 东紫苏转录组unigenes 在各数据库注释情况Table 3 E.bodinieri transcriptome unigenes annotated in each database
通过与NR 数据库进行比对注释,可以获取本物种基因序列与近缘物种基因序列的相似性,以及 本物种基因的功能信息。从图3 物种分布图可以看出与其他物种序列的相似性,在比对到NR 数据库中的unigenes 中,有65.2%和芝麻Sesamum indicumL.相匹配,其次是黄色猴面花Erythranthe guttata(DC.) G.L.Nesom.,匹配度为13.5%,丹参Salvia miltiorrhizaBunge、中粒咖啡Coffea canephoraPierre ex Froehn.、葡萄Vitis viniferaL.的匹配度分别为1.6%、1.3%、1.2%,其他物种为17.3%。

图3 东紫苏转录组unigenes 的物种分布图Fig.3 Species classification of unigenes in transcriptome of E.bodinieri
对基因进行GO 注释之后,共有61 194 条(65.56%)unigenes 注释到GO 数据库,并根据GO 功能分别将它们注释到生物过程(biological process)、细胞组分(cellular component)和分子功能(molecular function)3 大类中,共分为56个小组,注释结果见图4。其中生物过程主要聚集在细胞过程(cellular process)、代谢过程(metabolic process),涉及的基因分别有36 783、34 872 条;其次是单组织过程(single-organism process)和生物调节(biological regulation),基因数量分别为27 213、12 627 条。细胞组分中细胞(cell)和细胞部分(cell part)相关基因数量较多,有19 561 和19 559 条,其次是细胞器(organelle),有13 142 条。分子功能中具有结合功能(binding)和催化活性(catalytic activity)的基因数量较多,分别为37 797 和30 440 条,其他类别的基因数目普遍较少。
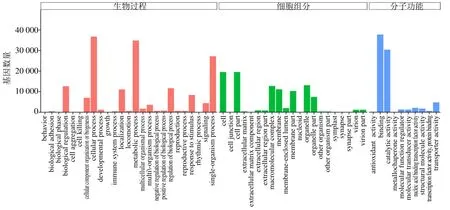
图4 东紫苏转录组unigenes 的GO 功能分类注释Fig.4 GO functional classification annotation of unigenes of E.bodinieri transcriptome
为了进一步分析东紫苏unigenes 的功能,进行了KOG 功能分类,共有25 391 条(27.2%)unigenes注释到KOG 数据库,得到25 个不同的KOG 功能类群(图5)。其中翻译后修饰、蛋白反转和伴侣( posttranslational modification, protein turnover, chaperones)的数量最多,有3509 条;其次是一般功能预测(general function prediction only)的基因,数量为3458 条;而数量最少的为细胞运动性(cell motility),仅有23 条。 将东紫苏unigenes 与KEGG 数据库比对,有34 354条(36.81%)unigenes 注释到该数据库中,分布于129 条代谢通路中。KEGG 代谢通路(图6)分为5大分支:细胞过程(cellular processes,A)1545 条、环境信息处理( environmental information processing,B)1299 条、遗传信息处理(genetic information processing , C ) 7448 条、 代 谢(metabolism,D)13 643 条和有机系统E(organismal systems)1322 条。其中注释数量最多的是碳水化合物代谢(carbohydrate metabolism),为2983 条,其次是折叠、分类和降解(folding,sorting and degardation)为2687 条,数量最少的是膜运输(membrane transport),为135 条。

图5 东紫苏转录组unigenes 的KOG 功能分类注释Fig.5 KOG functional classification annotation of unigenes of E.bodinieri transcriptome
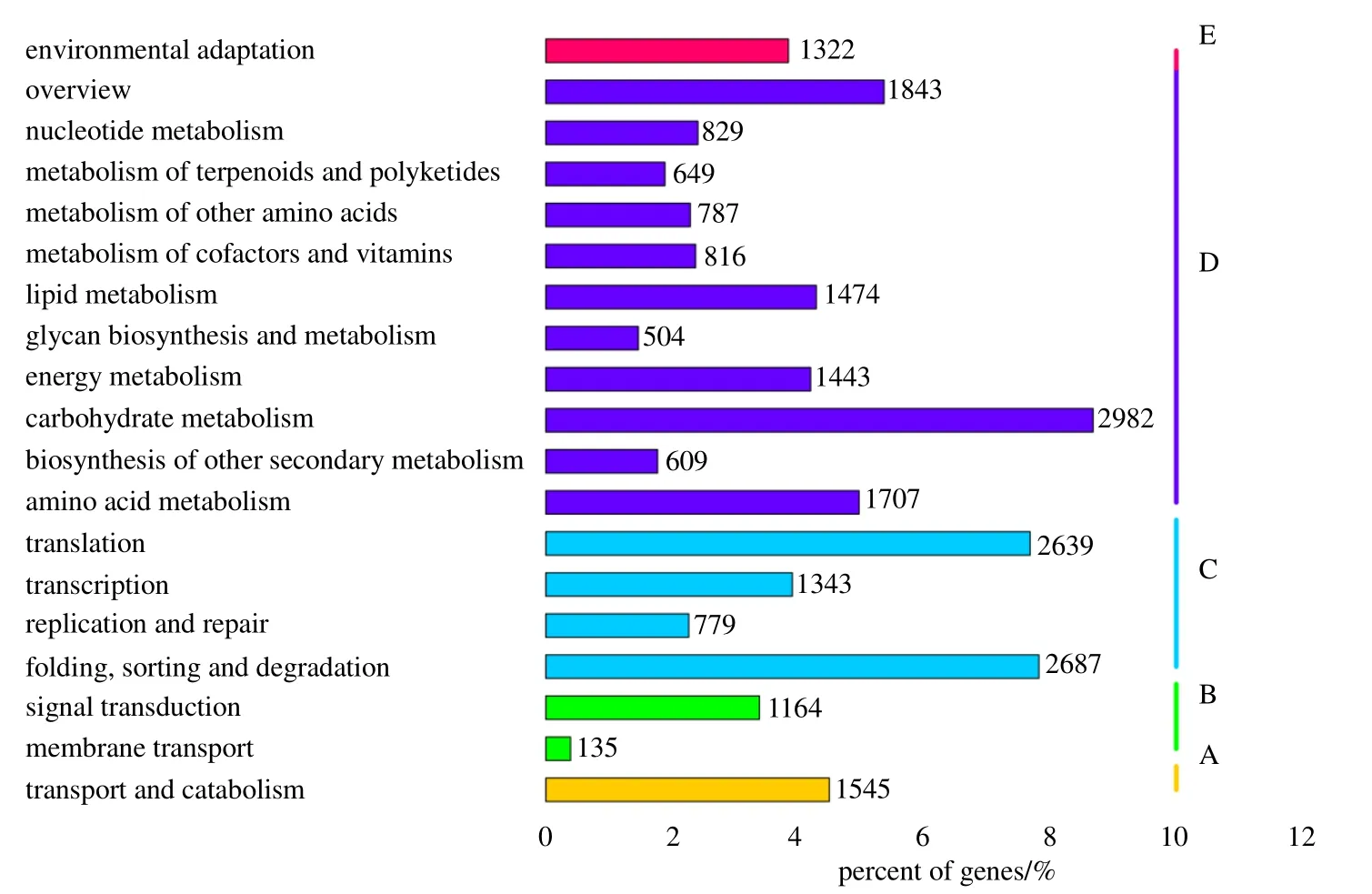
图6 东紫苏转录组unigenes 的KEGG 分类注释Fig.6 KEGG classification annotation of unigenes of E.bodinieri transcriptome
3.4 东紫苏单萜代谢途径与相关基因
通过KEGG 代谢通路分析,发现与东紫苏挥发油萜类生物合成相关的代谢通路有4 条,分别是:萜类骨架生物合成,编号为ko00900,相关基因有218 条;单萜类生物合成,编号为ko00902,相关基因有30 条;柠檬烯和蒎烯降解,编号为ko00903,相关基因有38 条;倍半萜和三萜生物合成,编号为ko00909,相关基因有95 条。其中与东紫苏单萜合成相关的代谢通路是萜类骨架生物合成和单萜类生物合成。
与东紫苏单萜合成相关的酶分别有香叶基二磷酸合酶(geranyl diphosphate synthase,GPS),相关 unigenes 有11条;新薄荷醇脱氢酶[(+)-neomenthol dehydrogenase,NDS],相关unigenes 数量最多,有 22 条;α-松油醇合酶[(-)-alpha-terpineol synthase,ATS],芳樟醇合酶[(3S)-linalool synthase,LIS],月桂烯/罗勒烯合酶(myrcene/ocimene synthase,MS/OS),这3 个酶相关unigenes 数量较少,共有8 条,具体见表4。另外,通过比较这些unigenes 的FPKM 值可以看出,NDS 基因平均表达量是最高的,其中SM 为8.97,AZY 为17.06;其次是ATS 基因,平均表达量SM为7.16,AZY 为3.92;GPS 基因平均表达量SM 为2.29,AZY 为1.64;LIS 基因和MS/OS 基因平均表达量均偏低。
筛选得到的东紫苏11 个单萜合成相关候选基因在SM 和AZY 2 个产地的FPKM 值(图7)。从图7中可以看到,基因2(Cluster-10292.10951)注释为NDS,在2 个产地中的表达量均为最高,其中SM 为25.66,AZY 为29.56;而基因1(Cluster-11595.0)注释为ATS,在2 个产地中的表达量均较低,其中SM为0.18,AZY 则为0;基因9(Cluster-10292.51149)注释为NDS,基因10(Cluster-10292.60790)和基因11(Cluster-10292.60789)均注释为GPS,这3个基因在2 个产地中的表达量基本持平。
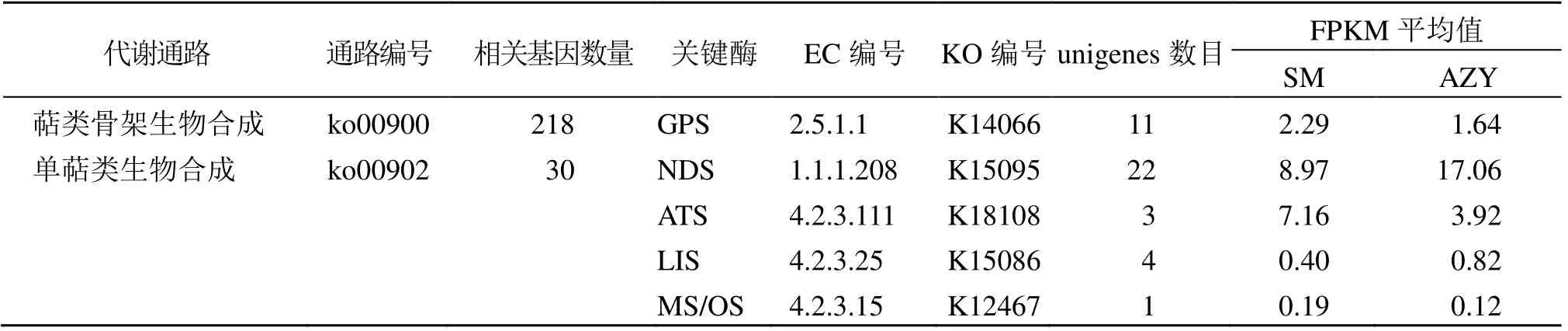
表4 东紫苏挥发油单萜代谢途径的酶与相关基因Table 4 Enzymes and related genes of monoterpene metabolic pathway of essential oil from E.bodinieri

图7 东紫苏单萜合成相关候选基因的表达量Fig.7 Expression of candidate genes related to monoterpene synthesis of E.bodinieri
3.5 东紫苏挥发油单萜合成相关候选基因全长unigenes 的RT-PCR 验证
利用表1 中的ORF 扩增引物进行PCR 扩增,并进一步对PCR 产物进行测序分析,得到以下结果:基因 2(Cluster-10292.10951)、基因 4( Cluster-10292.60008 )、 基因 6 ( Cluster- 10292.56890)、基因7(Cluster-5267.0)、基因10( Cluster-10292.60790 )、 基因11 ( Cluster- 10292.60789)这6 个基因扩增后,经电泳分析,均产生明亮的目标条带(图8),经测序分析后表明这6 个基因与原unigenes ORF 一致,这些候选unigenes为全长基因;另外基因1(Cluster-11595.0)目前扩增出后半段,基因 5(Cluster-10292.9722)、8(Cluster-1426.0)这2 个基因扩增出中间部分,下 一步将继续尝试全长扩增;基因 3(Cluster- 10292.50707)、基因9(Cluster-10292.51149)这2个基因扩增失败。
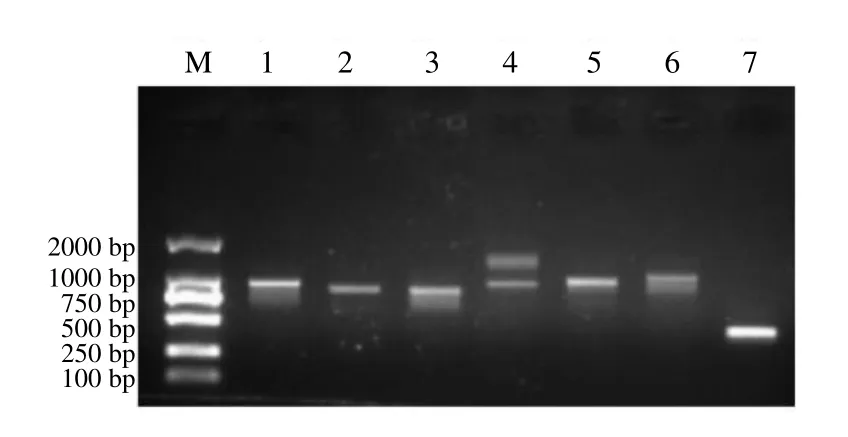
图8 东紫苏挥发油6 个单萜合成相关候选基因RT-PCR 凝胶电泳图Fig.8 RT-PCR gel electrophoresis of six candidate genes related to monoterpene synthesis in essential oil from E.bodinieri
4 讨论
东紫苏作为云南特产物种,在云南主要用作民间药物及保健饮品[28],其作为药用植物的基因资源部分一直是空白。本研究采用Illumina Hiseq 2000高通量测序平台,首次对东紫苏进行转录组测序分 析,填补了东紫苏转录组数据信息的空白。通过测序共获得13.67 Gb 数据,91 169 356 条高质量序列(clean reads),Trinity 组装获得93 327 条unigenes,平均长度为1756 bp。
结合生物信息学分析方法对东紫苏转录组数据进行序列相似性、基因注释和功能分类,将所有unigenes 分别与NR、NT、KEGG、Swiss-prot、PFAM,GO、KOG 等数据库进行比对,经过BLAST 比对分析后发现,有80 420 条unigenes 与其他近缘物种的已知基因具有相似性,与芝麻相似度最高,为65.2%。在KEGG 数据库比对中,有34 354 条(36.81%)unigenes 注释到该数据库中,分布于129条代谢通路中,并发现4 条萜类化合物代谢相关的途径。
RNA-Seq 技术的发展为转录组研究提供了机会,已成为发现与药用植物各种次生代谢途径生物合成相关基因的有力工具,即使是在没有参考基因组的物种中也是如此[29-30]。本研究是通过已注释基因的挖掘,在无参转录组中筛选目的基因,因与芝麻同源性匹配度最高,因此以芝麻作为参照来寻找目的基因。
前期课题组对东紫苏15 个居群叶的挥发油进行GC-MS 分析[12],并根据主成分的差异,将其划分为不同的化学型,其中SM 属于T 型(1,8-桉叶油醇<5%,5%<α-乙酸松油酯<20%),阿子营(AZY)属于C 型(1,8-桉叶油醇>50%,α-乙酸松油酯<5%),与之呼应的是2 个个体在单萜合成相关候选基因表达量上的明显差异。已有研究表明与植物挥发油中高含量成分对应的单萜合酶基因其克隆成功率更高,主要原因可能在于基因表达量与其产物的积累量是一致的[31-34],由于2 个产地的东紫苏叶挥发油主成分差异明显,具有代表性,因此分析这2 个产地的东紫苏叶在转录组数据中相关基因的表达量,有可能提高单萜合酶基因克隆的成功率。基于此,本研究在明确东紫苏挥发油主要成分的基础上,筛选出与单萜合成相关的代谢途径2 条,单萜合成相关候选基因41 个,通过RT-PCR 验证其中的6 个unigenes为全长基因,这为下一步研究东紫苏单萜生物合成及基因功能验证提供数据支持。
本研究筛选出的单萜合酶基因克隆成功率低,并且转录组注释的功能信息与东紫苏挥发油GC-MS 数据分析结果不吻合,即注释的功能与挥发油的成分并不匹配,推测是受测序技术所限,以及数据库可供比对的基因资源有限,增加了功能注释的难度,致使一些东紫苏挥发油单萜合成相关的关键酶基因未能得到精准拼接、组装和注释。此外,由于相同物种来源的单萜合酶的相似性高于不同物种来源而具有相同功能的单萜合酶,序列相关性并不直接转化为产物相关性[23,33,35-38],因此基于序列相似性仅可以判断其是否为单萜合酶,却不能预测其产物,所以已经克隆成功的6 个单萜合成相关候选基因需要进行功能验证,确认其在东紫苏挥发油单萜生物合成过程中的催化功能,才能确定该酶属于哪一种单萜合酶,以便最终得到东紫苏1,8-桉叶油醇合酶基因。
本研究首次采用高通量测序技术建立了东紫苏转录组数据库,获得了大量的转录本信息,并挖掘出单萜生物合成途径的关键酶基因,填补了东紫苏挥发油单萜合成途径分子研究的空白,为东紫苏挥发油单萜合酶基因的克隆、功能验证以及品种选育提供了基因资源及理论指导基础。
利益冲突所有作者均声明不存在利益冲突
