基于不同算法对桂枝茯苓胶囊内容物吸湿性预测建模研究
2021-06-11徐芳芳王振中
陈 琪,徐芳芳 ,张 欣 ,徐 冰,吴 云 ,王振中 ,肖 伟,
1.南京中医药大学,江苏 南京 210023
2.江苏康缘药业股份有限公司,江苏 连云港 222001
3.中药制药过程新技术国家重点实验室,江苏 连云港 222001
4.北京中医药大学,北京 100029
桂枝茯苓胶囊(Guizhi Fuling Capsules,GFC)是由桂枝、茯苓、牡丹皮、桃仁和白芍5 味药材组成,具有活血、化瘀、消癥等功效,用于治疗痛经、子宫肌瘤等疾病。GFC 内容物属于中药半浸膏粉,具有吸湿性强、易结块等特点[1-2],会影响胶囊的装量差异和稳定性等关键质量属性。王晴等[1]采用偏最小二乘算法(partial least squares,PLS)建立GFC内容物吸湿性预测模型,该建模方法在生产应用中需手动筛选关键变量,数据预处理工作量大,所建模型的交叉验证决定系数(determination coefficient of cross-validation ,Q2)、校正集决定系数(determination coefficient of calibration,R2c)和预测集决定系数(determination coefficient of prediction,R2p)较高且需进一步提升。本实验尝试从算法角度提高模型性能,研究不同算法对模型性能的影响。
决策树算法(classification and regression tree,CART)、多元自适应回归样条算法(multivariate adaptive regression splines,MARS)都可自动筛选变量,处理速度快,能够提升建模效率和模型性能,还可利用预测建模技术自动化、智能化对缺失值进行处理。吴晓倩等[3]引入决策树算法,利用与成绩相关的数据实现对学生未来成绩的预测,预测准确率达到94%。仉文岗等[4]基于大量可靠的岩土监测数据,运用MARS 算法对输入、输出参数进行相关性拟合,得到各输入参数的相对重要性。2 个评估实例中测试集的R2c分别为0.921、0.986。上述研究表明CART 算法和MARS 算法可以弥补PLS 算法的缺陷和不足。广义路径追踪算法(generalized pathseeker,GPS)算法的应用未见报道,但它也具备自动筛选变量的优点,模型性能情况有待进一步研究。上述3 种可自动筛选变量的算法都属于目前机器学习算法,在胶囊内容物吸湿性方面的应用未见报道,本实验基于现有数据运用不同算法建模,优选出最佳算法后嵌入在线控制系统中进行后续生产验证,以此来提升GFC 生产过程中质量控制智能化水平。
1 仪器与数据来源
BT-1001 智能粉体特性测试仪,丹东百特仪器有限公司;Bettersize 2600 激光粒度分布仪,丹东百特仪器有限公司;LHS-250HC-II 恒温恒湿箱,上海一恒科学仪器有限公司。
本研究所使用的数据来自于前期研究获得的80 批GFC 生产过程中的5 种中间体(原料细粉、湿颗粒、干燥颗粒、整粒颗粒、总混颗粒)和GFC成品的物性参数,收集的样品为2018年6月份至2018年11月份生产的中间体样品,样品的批次为180610~181121 共480 个样品,均由江苏康缘药业股份有限公司提供[1]。
2 方法
2.1 样本集的划分
本研究按照实际生产时间顺序将样本以3∶1比例划分校正集和验证集,前60 批次为校正集,后20 批次为验证集,校正集的范围覆盖了预测集的 整个范围,且校正集分布较广,适宜建立定量校正模型。
2.2 物性表征方法
2.2.1 粒径 使用激光粒度分布仪测定颗粒粒度分布,计算D10(累计粒度分布数达到10%时所对应的粒径)、中值粒径(D50,累计粒度分布数达到50%时所对应的粒径)和D90(累计粒度分布数达到90%时所对应的粒径),以及粒径分布宽度(span)。

2.2.2 粒径<50 μm 百分比(%Pf)和相对均齐度指数(Iθ) 以空气为分散媒介,使用激光粒度分布仪测定颗粒粒度分布,计算每个粒径范围内颗粒所占的比例,平行3 次试验。所选取的粒径分别为355、212、100、50 μm。

Fm为颗粒粒径在多数范围(100~212 μm)的质量百分比,Fm-1为多数粒径范围下一层筛子(50~100 μm)截留颗粒的质量百分比,Fm+1为多数粒径范围上一层筛子(212~355 μm)截留颗粒的质量百分比,dm为多数粒径范围的颗粒平均粒径,dm-1为多数粒径范围下一层筛子截留颗粒平均粒径,dm+1为多数粒径范围上一层筛子截留颗粒平均粒径,n为所确定的粒径范围个数
2.2.3 休止角(α) 采用固定底面积法,使用粉末流动性测定仪对样品进行测试,底面圆盘直径100 mm,喷嘴直径为10 mm。取待测中间体颗粒约50.0 g,将仪器校零后,从特殊喷嘴漏斗的上方缓慢加入,使其逐渐堆积在圆盘上,形成锥体,测定锥体高(h)和底面圆盘半径(d),平行3 次试验。

2.2.4 松装密度(Da) 将约50.0 g(质量记为m)待测颗粒缓慢地加入到100 mL 量筒中,轻轻抹平表面,读取待测颗粒的体积(Va),平行3 次试验。

2.2.5 振实密度(Dc) 将上述盛有待测颗粒的量筒固定在振实密度仪上,设定频率70 Hz,振动1250次后读取待测颗粒的体积(Vc),平行3 次试验。

2.2.6 豪斯纳比(Hausner ratio,HR) 由松装密度和振实密度计算而得。

2.2.7 卡尔指数(Carr index,CI) 由松装密度和振实密度计算而得。

2.2.8 颗粒间孔隙率(Ie) 由松装密度和振实密度计算而得。
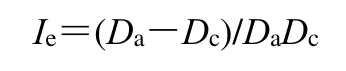
2.2.9 吸湿性(H) 取干燥的具塞称量瓶置于恒温恒湿箱(设置温度为25 ℃,相对湿度为75%)中,12 h 后精密称定质量(m1)。取待测颗粒适量,置上述称量瓶中并平铺于称量瓶内,厚度约为1 mm,精密称定质量(m2)。将称量瓶敞口,并与瓶盖同置于上述恒温恒湿条件下。24 h 后盖好称量瓶盖,精密称定质量(m3),平行3 次试验。

本实验建模所用的输入参数X为软材细粉(RC)、干颗粒(GZ)、整粒颗粒(ZL)、总混颗粒(ZH)的D10、D50、D90、Da、Dc、span、%Pf、Iθ、HR、α、Ie、CI 以及湿颗粒(SKL)的Da、Dc、HR、α、Ie、CI 共54 个参数,输出参数Y为胶囊内容物H值。
2.3 数据分析软件
采用SIMCA-P 软件(version 12.0,瑞典MKS Umetrics 公司)建立PLS 模型,采用SPASS25.0 进行自变量共线性评价,采用SPM8.3 软件(美国Salford Systems 公司)中不同机器学习算法建立吸湿性预测模型。
2.4 建模原理与方法
2.4.1 PLS 算法 PLS 是经多次迭代映射分解,组合成1 个Y与X的线性回归(Y=bX+f),将每次迭代过程中的映射变换参数进行线性运算可以得到最终模型的参数b和f。PLS 采用成分分解的思路来进行特征降维;PLS 关注各个变量对目标变量的解释,会保留共线性的变量;PLS 先拟合大致轮廓,再逐步拟合细节,考虑当前的最优拟合决策进行局部最优化。
2.4.2 CART CART 具有高速、精确和容易使用 的特点,并自动对数据提供深入的探索研究,产生高度可理解的预测模型;仅使用排序信息因而不需要进行变量变形,不会受到孤立点的影响,同时使用替代分裂变量智能的处理缺失值。CART 是非参数的,没有预设的函数形式,它通过局域性的总结来逼近数据模式,动态地决定使用哪个变量,动态地决定关注哪个区域,所有的一切都由数据自动决定[5-10]。
2.4.3 MARS MARS 是一种非线性和多维关系建模的算法,可以高度自动化的回归分析,可以看成是逐步线性回归的推广,也可以看成是为了提高CART 在回归中的效果而进行的改进。
MARS 算法分为前向选择、后向剪枝、模型选择3 个步骤,通过自适应的选取节点对数据进行分割,每选取1 个节点就生成2 个新的基函数,前向过程结束后生成1 个过拟合的模型,后向剪枝过程是删除导致模型过度拟合的基函数,便于选择最佳模型,这一过程遵循广义交叉验证(generalized cross-validation,GCV)原则,GCV 值最小的模型为最终的MARS 模型[11-13]。GCV 是根据误差模型和正则化解构造1 个广义交叉G 函数,GCV 的计算方法如下式所示。

N为样本数据总数,H为基函数的个数,d为惩罚系数
MARS 的主要优点是可以进行变量选择,将相关变量与不相关的预测变量分开;能够估计基函数的贡献,允许预测变量的加性和交互影响来确定相应变量;使用新的嵌套变量技术处理缺失值;进行广泛的自我测试,以防止过度拟合[14-17]。
2.4.4 GPS GPS 提供了完整的正则化策略,利用更为广谱的弹性系数建立更多候选模型,开始时模型里没有任何预测变量,在每一步中添加1 个新的变量或者更新现有变量的1 个系数,通过建立若干步数不同的路径模型,并自动选择出其中最优的线性模型。GPS 从速度和覆盖率2 个方面对正则化回归进行了显著提升。模型效果会比传统回归更好、更稳定,同时提供了强大的变量筛选能力,更好应对大数据高纬度降维的挑战。
以上机器学习算法都可以对变量重要性列表进行建模精炼,筛选重要变量。
2.5 模型性能评价
2.5.1 PLS 模型评价 使用R2c、R2p、Q2评价拟合效果,这些指标越接近1,表示PLS 模型拟合数据效果越好,校正或预测能力越好;用决定系数(R2)、交叉验证均方根误差(root mean square errors of cross validation,RMSECV)、预测均方根误差(root mean square errors of prediction,RMSEP)评价模型的性能,R2越大,RMSECV 和RMSEP 越小,模型的性能越好。
2.5.2 机器学习算法模型评价 以R2、均方根误差(root mean square error,RMSE)、平均绝对百分比误差(mean absolute percent arror,MAPE)等指标来评价模型的性能,R2越接近1,MAPE 越接近0,表明模型的性能越好;RMSE 越接近0,表明模型的预测性能越强[18-19]。n为校正集或验证集的样本数,t∈[1,n],y为参考值,yi为预测值,y为所有样品参考值的平均值
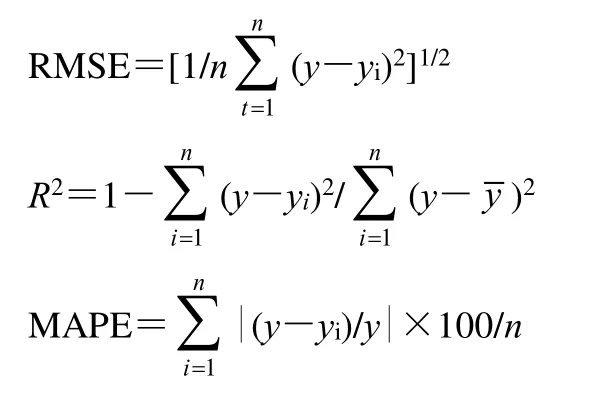
2.5.3 模型精度评价 PLS 和机器学习算法都是根据验证集中的相对预测误差来评价模型预测精度的影响。
3 结果与分析
3.1 多算法模型的建立
3.1.1 PLS 建模结果 以胶囊内容物吸湿性(Y)为因变量,54 个物性参数为自变量(X),建立的PLS 预测模型的Q2为0.399,R2c和R2p分别为0.216、0.656。变量个数为8 时,Q2达到最大值0.549,R2X和R2Y为0.616、0.602。筛选出的物性参数包括RC-D10、RC-D50、RC-span、RC-α、RC-%Pf、ZH-Dc、SKL-Da、SKL-Dc。绘制的变量投影重要性(variable importance in the projection,VIP)图如图1 所示,自变量回归系数如图2 所示。使用方差膨胀因子(variance inflation factor,VIF)评价以上8 个物性参数的共线性程度,RC-%Pf、RC-α、RC-D10、RC-D50、RC-span、ZH-Dc、SKL-Da、SKL-Dc物性参数共线性检验结果的VIF 值分别为25.839、1.303、7.181、21.223、2.461、1.259、7.054、7.109。由图1、2 和VIF 值考察结果可知,VIP>1、回归系数>0.2、VIF<10 的变量有RC-α、RC-D10、Rc-span、SKL-Dc、ZH-Dc,可作为潜在关键物料属性。以5 个变量建立的模型性能指标Q2为0.531,R2c和R2p分别为0.616、0.615。

图1 模型的VIP 分布Fig.1 VIP indexes for independent variables of PLS model

图2 模型自变量回归系数Fig.2 Regression coefficients of PLS model
用20 批样品测试所建模型的稳健性,验证集真实值与预测值相关性如图3 所示,校正集R2c为0.602 5,交叉验证均方根误差RMSECV 为0.630 9,预测集R2p为0.348 7,预测均方根误差RMSEP 为0.408,验证集的相对预测误差为3.69%。

图3 PLS 模型拟合效果Fig.3 Comparison between target and predicted hygroscopicity
3.1.2 CART 算法建模结果 节点和树的深度对算法的影响较大,开始建模前通过AUTOMATE 自动建模选项筛选最优max nodes 参数为8,树的深度为30 时,性能最佳。根据变量重要性表来逐步筛选关键变量并结合验证集预测误差来确定最优模型。由54 个物性参数建模,随机选择20%的样本作为验证集,所得变量重要性如图4 所示,不同变量个数建立的CART 模型性能和预测性能比较如表2 所示,用20 批样品对模型进行外部验证的结果如表1所示。由表1 可知当变量数为14 时,CART 模型的 性能不是最好但预测效果较好,变量数目减少,预测相对误差增大,可能损失了一些重要的信息。

图4 变量重要性Fig.4 Importance of input variables

表1 不同变量个数建立的CART 模型的性能和预测性能比较Table 1 Comparison of CART model performance and prediction performance established with different numbers of variables
3.1.3 MARS 算法建模结果 基函数的个数影响着预测模型的选择,可由GCV 性能曲线得到最优基函数,因此得到最佳模型尺寸[20-21]。由图5可知GCV值随基函数的变化规律,GCV 值最小时对应的基函数个数为7,由表2 可知基函数个数对GCV 函数值和校正集验证集决定系数R2和均方误差(mean square errors,MSE)的影响,拟合效果不随基函数增长而优化,应不断调试预设基函数的数目,以此选择最优基函数,建立最佳模型[11]。

图5 不同GCV 值对应基函数个数Table 5 Different GCV values correspond to number of basis functions
MARS 算法中随机选择20%的样本做为验证集,由54 个物性参数建立的MARS 模型得到8 个重要变量:SKL-Dc、ZH-Da、RC-α、GZ-Da、GZ-D90、SKL-Da、GZ-D10、GZ-α,校正集的R2c为0.843,RMSE 为0.391,MAPE 为0.025,预测集的R2p为0.808,RMSE 为0.031,MAPE 为0.031。
另取20 批样品对MARS 模型进行外部验证,参考值与预测值如表3 所示,吸湿性平均相对预测误差为2.69%,预测结果相对准确。
3.1.4 GPS 算法建模结果 MSE 表示测试集模型的性能,由来自于复杂的内部搜索结果的弹性系数决定。图6 显示了最佳模型是一种最小化测试样品的MSE 的模型,蓝色线是校正集,红色线是验证集,对应的模型系数为26。不同变量个数建立的GPS 模型性能和预测性能比较如表4 所示,用20批样品对模型进行外部验证的结果如表4 所示。
由表4可知用54个物性参数建立的模型过拟合程度较大,当逐步剔除变量重要性小的变量重新建模时,所选变量数为3 时,模型的稳定性和预测精度最好,这3 个变量为SKL-Dc、RC-α、ZH-Dc。

表2 GCV 函数值和评价指标随基函数数目变化情况Table 2 GCV function value and variations of measuring indexes with basis function number

表3 外部验证样本参考值和预测值结果Table 3 Experimental values and predicted values for external validation samples

图6 MSE 随弹性系数变化规律Table 6 MSE changes with elasticity coefficient
3.2 不同算法模型性能和预测精度比较结果
综合对比分析以上不同算法建立的最优模型结果如表5 所示,可以发现MARS 算法建立的预测模型在校正集和验证集上获得了较大的决定系数和较小的各项误差,模型的稳定性和预测精度更好。校正集和预测集的决定系数分别为0.843、0.808,RMSE 分别为0.391、0.472,MAPE 分别为0.025、0.031,验证样本的平均预测误差为2.69%。

表4 不同变量个数建立的GPS 模型性能和预测性能比较Table 4 Comparison of GPS model performance and prediction performance established with different numbers of variables

表5 不同算法模型性能和预测精度比较Table 5 Comparison of performance and prediction accuracy of different algorithm models
4 讨论
本研究运用不同算法对GFC 内容物吸湿性进行建模,结果表明MARS 算法建立的模型最好,模型平均相对预测误差为2.69%。综合分析可知,MARS算法优化了PLS算法需手动筛选关键变量的缺点,提高了模型运用的效率;标识了PLS 算法和CART 算法未显示的变量累加贡献值或变量之间的相互作用结果[14,22-23];弥补了GPS 算法不可处理非线性问题的缺陷。
本研究选用的4 种算法都以特殊的方式来计算变量重要性,PLS 算法根据残差平方和的最小化选择变量[24],CART 算法根据信息增益选择特征变量,GPS 算法利用正则化策略和弹性系数来选择变量,MARS 算法利用广义交叉原则和基函数来筛选变量。4 种算法筛选出的相同变量有SKL-Dc、RC-α,表明GFC 内容物吸湿性与软材细粉的休止角和湿颗粒的振实密度有关,与前期研究结果相同。休止角的大小是粉体粒子大小和粒径分布、粉体表面性质以及粒子间相互作用力的综合体现,休止角越大,吸湿性越强[1]。软材细粉的休止角与制软材时浸膏的干燥粉碎方式、干燥工艺参数和浸膏的混合比例等有关,需收集更多的样本来进行实验研究确定影响吸湿性的显著因素。湿颗粒振实密度与颗粒的粒径分布、骨架密度和孔隙结构有关,因而影响颗粒吸湿性。前期研究结果显示湿法制粒过程中物料与黏合剂作用导致粉体表面黏性变化,湿颗粒振实密度与黏合剂加入量和浓度有关,提示生产过程中需及时调整黏合剂用量和浓度来保证颗粒的吸湿性处于一定的均匀范围内。湿颗粒振实密度还有可能与制粒过程中所加辅料的性质有关,尚需通过实验进一步验证[25-27]。
本研究所选数据量远少于生产过程产生的大批量数据,在后续研究中还需要继续收集更多的数据来进一步验证、更新、维护和优化模型,提高模型预测精确度,以此提升GFC 生产过程质量控制智能化水平。
利益冲突所有作者均声明不存在利益冲突
