基于CEEMDAN-SVM的高铁轴承故障诊断研究
2021-06-10郝如江
杨 帅, 郝如江
(石家庄铁道大学 机械工程学院,河北 石家庄 050043)
0 引言
高铁轴承是高铁的重要部件之一,对于高铁安全稳定运行起着决定性作用[1]。由于轴承运行状态的很多相关信息都可以在轴承振动信号中得以体现,因此在轴承故障诊断方法中,振动信号分析法是最常用也是最有效的方法。CEEMDAN算法[2]是一种信号的自适应分解算法,能够有效改善其他分解算法中存在的模态混叠现象[3-4],并且重构误差较小,完备性较好。在信号处理和分析方面,特征提取是一种常用的技术手段,近些年来,排列熵、样本熵、奇异值等无量纲参数被引入机械设备振动信号的特征提取之中,给机械故障诊断提供了更多的方法和思路。刘珍珍等[5]利用多尺度排列熵算法,成功地对轴承故障样本进行了特征分类;别峰峰等[6]利用奇异值作为特征提取方式,对往复泵的振动信号样本进行了特征提取;张宁等[7]则利用样本熵作为特征提取手段,进行了行星齿轮箱故障诊断研究。支持向量机[8]是一种分类算法,可以用于不同类型信号的分类和识别,且其对小样本数据的支持性较好,运行效率也比较高。狼群优化算法是一种新型的启发式参数寻优算法,因为能够进行全局寻优,且收敛速度快、寻优精度高而被广泛应用于各种领域,周同乐等[9]利用狼群算法来辅助生成无人机攻防策略数学模型,成功提高攻防策略的作战效能并降低了行动代价;蒋一锄[10]则利用狼群算法来优化图书馆借阅数据聚类模型的初始参数值,并成功提高了聚类精度。本次实验以高铁轴承不同故障状态下的振动信号作为实验对象,并将振动信号分解后提取出的各阶分量的样本熵特征值作为样本和测试数据,利用SVM进行高铁轴承故障的诊断。结果表明,此方法能有效进行高铁轴承的故障分类,准确率也较高。
1 相关原理
1.1 CEEMDAN原理
CEEMDAN算法是对EMD算法的一种改进,通过添加自适应噪声来辅助分解,使得分解结果能够在一定程度上改善模态混叠现象,并且信号重构的完备性较好,误差也比较小[11],下面简述CEEMDAN分解算法的原理。

(1)
S1(t)=S(t)-IMF1(t)
(2)
(2)定义一种新的计算方式Ek(·),其含义为任意信号经过EMD分解后得到的第k个分量。在剩余信号S1(t)中加入噪声再次构造新的信号S1(t)=S1(t)+a1E1[ni(t)],再对其进行一阶段的EMD分解,将获得的多个第一阶段的本征模态分量再次集合平均,得到最终的第二阶本征模态分量IMF2(t),计算方法如式(3)所示,得到剩余信号S2(t),计算方法如式(4)所示。
(3)
S2(t)=S1(t)-IMF2(t)
(4)
(3)按照上文中的规则可以一直计算下去,直到最后的剩余信号不满足再次分解所需要的条件,分解结束,信号经过分解后得到多个本征模态分量和剩余信号,其结果的表达形式为
(5)
1.2 样本熵原理
样本熵[12]是评价信号混乱程度的一种方式,计算简单,不依赖于数据长度,且对于噪声等干扰条件的抵抗能力较强,能有效表征不同信号在时间序列上的复杂性。下面简述其计算方式。
(1)首先,对于任意一个时间序列x={x1,x2,x3,…,xn},构造一个形式如式(6)的新的M维的X(i),其中i的取值范围是{1,2,n-M+1},n是原始信号的数据长度,M是预先设定的模式维数,新数据的含义是原始信号从第i个点开始截取的M个连续的信号数值。
XM(i)={x(i),x(i+1),…,x(i+M-1)}
(6)
(2)定义向量XM(i)和XM(j)之间的距离为D,其计算方式为2个不同向量之间相对应的元素差值的绝对值的最大者,即D{XM(i),XM(j)}=Max{∣x(i+q)-x(j+q)∣},其中,q的取值范围为{1,2,…,M-1}。
(3)根据事先确定的阈值R,统计距离D小于R的个体数目,记为Bi,其中,1≤i≤N-M,计算出其在总个数N-M中所占的比值,记为Bi(R)=Bi/(N-M-1),对于所有的Bi(R)按照式(7)取其算术平均值,记为B(R)。
(7)
(4)将模式维数设定为M+1维,再次重复以上步骤,可以计算出M+1维度下新的B(R)值,将其记为A(R),那么对于含有有限个点的数据x而言,其样本熵便定义为SampEn(x)=-ln[A(R)/B(R)]。样本熵的计算需要设定模式维度M和阈值R2个参数,一般情况下,M的取值为1或者2,而阈值的取值可以落在0.1~0.2倍原始信号标准差这个区间范围内,在这样的前提下,计算结果比较准确合理。
1.3 狼群优化算法
灰狼优化算法是模拟自然界中狼群狩猎捕食行为的一种启发式优化算法,它按照自然界中狼群等级将种群分为α、β、δ、ω4种等级,其中α狼的等级最高,又被称为头狼,它负责统领并协调其他狼,为种群的领导者,其他3种狼受头狼的指挥,整个寻优计算过程就是狼群之间相互配合不断接近直到最终捕捉猎物的自然行为。它的主要过程如下:
(1)包围。这一步代表的是狼群搜索猎物并接近猎物的行为,数据的更新规则如式(8)所示,其中的t表示当前的迭代次数,A和C是协同系数向量,Xp代表猎物位置,X(t)表示灰狼位置,2个r是[0,1]之间的随机向量。
(8)
(2)狩猎。这一步模型假定α、β、δ3匹狼识别潜在猎物的能力较强,因此可以保留最优的3匹狼的位置信息来更新其他搜索代理的位置,更新规则如式(9)所示,其中Xα、Xβ、Xδ表示当前3匹狼的位置信息,X表示灰狼的位置信息,D表示当前候选灰狼和最优3匹狼之间的距离。
(9)
(3)攻击。这一步便是狼群捕食的最后一步,也就是算法得到最优解的过程,其中α头狼所代表的数据结果便是寻找的最优解结果。
2 实验方案设计
本次实验采用东方所振动信号采集仪(INV3018A)以及DASP软件来采集铁路轴承综合性能实验台的数据,其中采样频率设定为51 200 Hz,驱动电机转速为1 200 r/min,不添加外部荷载。实验所用的轴承为实验室的高铁轮对轴承,其外径长度为240 mm,内径长度为130 mm,节径长度为185 mm,采用人为加工缺陷来模拟不同部位的轴承故障,故障尺寸长宽深分别为5、1、0.7 mm。分别采集正常轴承、内圈故障轴承和外圈故障轴承3种状态下的高铁轴承振动信号,传感器为振动加速度传感器,型号为PCB35A26。本次实验一共采用了360组数据,其中的150组用作训练数据,其余210组用作测试数据。具体的实验方案及流程设计如下:
(1)采集不同类型的振动信号,并将每一个信号样本作为原始数据输入CEEMDAN分解算法进行自适应分解,分解过程中辅助白噪声的幅值设定为原始信号标准差的0.2倍,保存分解结果。
(2)计算每一组分解后获得的本征模态分量的样本熵特征值,其中模式维度设定为2,并将结果作为SVM模型的训练样本数据和测试样本数据。
(3)将训练数据和测试数据进行预处理,例如归一化操作等,利用训练数据创建SVM的模型,其中的参数惩罚因子C和核函数参数G采用狼群算法进行优化,创建完模型后利用测试数据来测试模型,利用训练数据和测试数据进行SVM模型的故障诊断实验,记录分类效果,统计分类的正确率,评价故障诊断模型的效果。模型的创建、训练和识别的流程如图1所示。

图1 故障诊断实验流程图
3 高铁轴承故障诊断实验
(1)启动铁路轴承测试实验台的设备和DASP采集系统,从实验台中分别采集正常轴承、内圈故障轴承、外圈故障轴承3种不同状态下的轴承振动信号,典型的3种不同状态的振动信号如图2所示。从3种信号的时域波形图中无法有效分辨3种信号的差异,需要提取更加深层次的信息。

图2 轴承振动信号时域波形图
(2)将不同状态的振动信号进行CEEMDAN自适应分解,从中挑选任意3种不同信号分解后获得的分量的时域波形图进行展示,限于篇幅,只展示了其前5阶段的本征模态分量,其分解结果如图3~图5所示,观察信号模态分量的时域图仍然难以明确分辨3种信号分量之间的具体差异。

图3 正常轴承信号CEEMDAN分解图

图4 内圈故障信号CEEMDAN分解图
图5 外圈故障信号CEEMDAN分解图
(3)分别计算任意3组数据的样本熵特征参数值,其结果如图6所示。从图6中不难发现,在图中黑色竖线标记的左侧,三者的特征值的数值都在0.5以上,并且三者有着较为明显的差距,而在竖线右侧,特征值小于0.5,且三者的特征值差别不大,无法有效代表不同类型信号之间的差异,因此,为使样本的特征值数据有最好的识别和区分度,本次实验选择3种信号分解后提取出的前5阶样本熵特征参数值数据作为SVM模型的训练和识别数据。

图6 样本熵特征参数值对比图
(4)对所有采集到的不同故障状态下的轴承振动信号分别进行以上的CEEMDAN分解和计算特征值的操作,其部分特征值如表1的内容所示。将得到的150组训练样本和210组测试样本先后输入支持向量机SVM中,训练模型时,正常信号的标签被设定为1,内圈故障轴承信号的标签设定为2,外圈故障轴承信号的标签设定为3。训练所采用的参数C和G利用灰狼优化算法来确定,在灰狼算法的计算下,可以得到优化后的参数值。在实验中,狼群的种群规模设定为20,最大的进化迭代次数设定为25,优化参数数量设定为2个,取值范围限定于[0.01,100]区间范围内,经过计算,优化后的惩罚因子C的值为70.93,核函数参量G的值为9.91。将以上训练数据和优化结果录入SVM进行模型的创建,在创建完模型后,采用相同的标签设定规则对测试数据进行标签设定,而后再将其输入SVM进行分类,SVM的识别结果如图7所示。采用相同的实验数据,利用未优化参数的SVM模型进行了对比实验,标签设定与SVM模型设定方式相同,其中2个参数仍在[0,100]范围内取值。本次实验进行了2次人为取值,取值分别为[80,60]和[90,80],采用与上文相同的实验方法进行故障识别,其识别结果如图8所示。
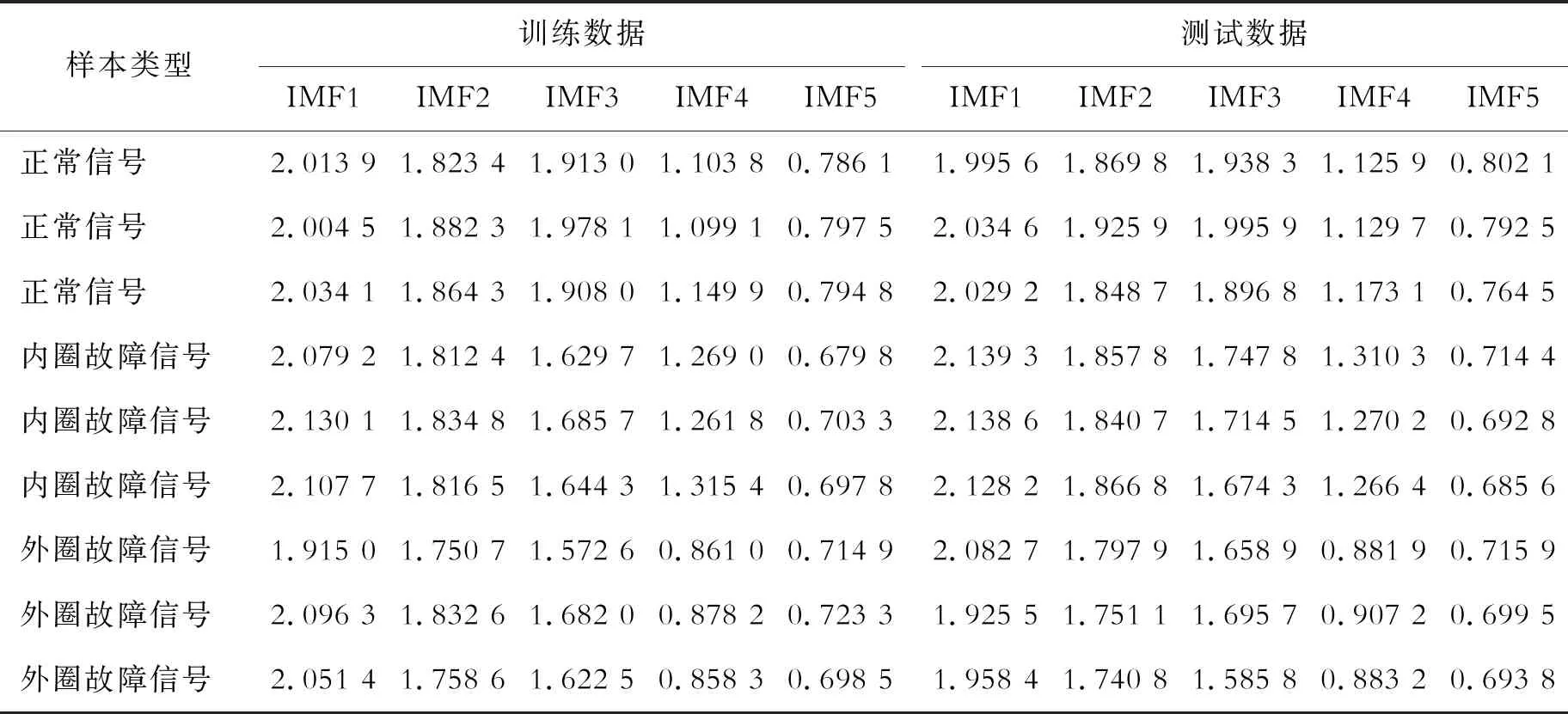
表1 部分实验数据表
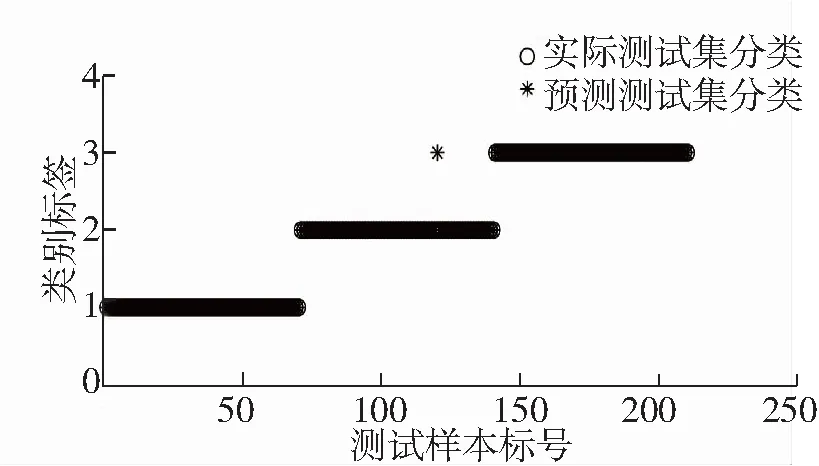
图7 优化后的GWOSVM计算结果图

图8 未优化的SVM计算结果图
(5)具体的计算结果数据汇总于表格2中。由表2中数据可以看出,在GWO优化的SVM模型下,其中正常信号和外圈故障信号全部识别正确,内圈故障信号只有一个样本被错误识别成了外圈故障样本,总体的正确率可以到达比较高的99.52%。在第一次未优化参数的实验中,正常信号数据中有3个被误判为外圈故障信号数据,内圈故障信号数据中有5个被误判为外圈故障信号数据,整体的正确率为96.19%;在第二次未优化参数的实验中,正常信号数据中有7个被误判为外圈故障信号数据,内圈故障信号数据中有7个被误判为外圈故障信号数据,整体的正确率为93.33%,2次模型分类的准确率均比参数优化后的模型分类的准确率要低。由以上数据可以得出,GWO优化后的SVM取得了较高的识别正确率,并且由于GWO算法可以根据实际的数据来自动确定参数,无需人工设定,让实验流程更加科学合理;未优化参数的SVM模型的识别正确率较低,说明人为选定参数可能会对识别结果产生影响,也增大了故障诊断过程中潜在的人为经验误差。

表2 分类识别结果
4 结论
总结出一种基于CEEMDAN和SampEn特征参数和GWOSVM的高铁轴承故障诊断方法,并利用实际采集的高铁轴承振动信号进行了模型可行性测试实验。实验结果表明,对于高铁轴承不同故障类型振动信号的识别和分类,此模型是有效的,且能取得较好的分类结果,GWO算法的加入让参数的设定更加科学,避免了人为操作带来的误差影响,是一种科学合理的高铁轴承故障诊断方案。
