基于融合LDA和Doc2vec算法的文本表示模型的研究
2021-06-03莫秀良王春东佟寅铖
宁 宁,莫秀良,王春东,佟寅铖
(天津理工大学 计算机科学与工程学院 天津市智能计算及软件新技术重点实验室,天津 300384)
随着信息技术的不断发展,人们已经从信息缺乏的时代过渡到信息极为丰富的数字化时代,网络上的信息量正在飞速增长当中,为了能够在海量的文本中及时准确地获得有效的信息,文本分类技术已经成为近年来文本挖掘领域的热门话题[1].文本分类技术是指基于固定规则对指定文本进行监督学习的过程,它通常包括以下操作部分:预处理,文本表示,文本特征提取,分类算法,测试和评估[2],其中文本表示及特征提取十分影响分类器分类的效果.
文本表示分为离散表示和分布式表示.离散表示的代表就是词袋模型[3],它把文档集中的文档拆成一个个的词,去重后得到词典,进行文本表示.这种模型的特点是词典中的词没有特定的顺序,句子的总体结构也被改变了.因此,文本的离散表示存在着数据稀疏、向量维度过高、字词之间的关系无法度量的问题.
另一种是分布式表示也叫做词嵌入,它将单词分布在一个与实际语义高度相关的低维向量中.Word2vec是Google的Mikolov等人提出来的一种文本分布式表示的方法[4].这种方法弥补了词袋模型的缺点.利用将单词嵌入到另一个实数向量空间从而完成降维,并且单词的向量表示具备具体意义,向量之间的距离通常也能刻画在语料中两个单词之间的差异性.在此基础上他们还提出了Doc2vec,通过嵌入词向量的线性组合来训练文档向量[5].这种模型不仅能训练得到词向量,还能得到段落向量.更重要的是它也考虑了单词的顺序进而继承了单词的语义.
LDA是一种基于概率模型的主题模型算法,它可以用来识别大规模文档集或语料库中的潜在主题信息[6].因此,许多研究者将LDA模型用于文本主题分类的任务.Hsu CI提出的LDA-GA方法主要使用遗传算法(GA)来找到主题集的最优权重,即使用GA来改变LDA的θ矩阵[7].Zhao D等人通过向LDA添加主题类别分布参数来提出一种名为gLDA的主题文本分类算法,这种方法限制了主题与类别分布参数的生成范围[8].为了提高文本分类的准确性,Moody提出了LDA2vec[9].他在生成单词向量的步骤中添加文档向量来获得上下文向量,通过上下文信息来学习更多可解释的主题.Wang Z提出了一种基于Word2vec和LDA的新混合方法[10],使用的主题向量和文档向量都是通过Word2vec训练出来的词向量组合而成的.紧接着Sun F又提出了一种考虑语法类别—组合权重和主题高频词因素的LDA主题模型[11].运用LDA和Word2vec对语法类别——组合权重的概念进行向量化以获得组合向量.
在以上研究分析的基础上,本文提出了一种综合表示文档的方法.将LDA与Doc2vec相结合,运用LDA模型挖掘出主题与文档之间的关系,利用Doc2vec将其向量化.再用余弦相似度来度量空间中文档和主题之间的相似性.本文选择了20Newsgroups数据集来进行性能评估,使用SVM算法进行分类.与LDA+SVM、Doc2vec+SVM、LDA+Word2vec+SVM等方法相比较,结果表明文新方法的分类性能更好.
1 相关模型的描述
1.1 Latent Dirichlet Allocation模型
LDA是一种主题空间模型,它可以将文档集中每一篇文档的主题以概率分布的形式表示出来.如图1所示.
在LDA模型中,对于给定的文档集D,包含M篇文档,K个主题,每篇文档i中又包含Ni个词语.
LDA定义生成任意一篇文档需要进行如下过程:

图1 LDA模型Fig.1 Latent dirichlet allocation model
1)从α中取样生成文档i的主题分布θi,其中α是每篇文档的主题分布的先验分布(Dirichlet分布)的超参数.
2)从主题的多项式分布θi中取样生成文档i中第j个词的主题zi,j.
3)从β中取样生成主题zi,j对应的词语分布φz,其中β是每个主题的单词分布的先验分布(Dirichlet分布)的超参数.
4)从词语的多项式分布φz中取样最终生成文档i中第j个词语wi,j.
以上总结成公式(1)与(2),不断重复以上步骤,最终生成一篇文档.其中通过Gibbs抽样得到的θ和φ可以发现文档中的潜在主题,并预测具有主题比例分布的任何新文档.

1.2 从Word2vec模型到Doc2vec模型
Doc2vec模型是在Word2vec模型的基础上所产生的.其中Word2vec中包含两种词向量模型:Continuous Bag of Words(CBOW)和Skip-Gram[12],如图2所示.这两个模型各自训练一个网络来预测相邻的单词.首先随机初始化单词向量,在CBOW的模型中,通过输入目标词的上下文单词向量来预测目标词汇.相反,在Skip-Gram的模型中,则通过输入目标词向量来预测上下文单词.预测任务可分解为以下公式.Word2vec模型的目标是最大化平均对数概率来预测目标词汇,如公式(3):

图2 CBOW模型和Skip-Gram模型Fig.2 Continuousbag of wordsand Skip-Gram

通过利用softmax函数很预测单词wm,如公式(4):

对于每一个输出的单词wi,每一项ywi都是其非标准化对数概率.计算表达式如公式(5):

其中a、b为softmax参数,f由从词汇表矩阵W中提取的词汇向量的串联或平均构成.在Word2vec模型中,用初始化的词向量去预测句子中下一个词的过程中,通过不断的调整参数来最小化真实值和预测值的差值,最终可以间接的得到这些词的向量表示.
在此基础上加入段落这个属性的考量,紧接着又提出Doc2vec模型来预测段落向量.其中Doc2vec模型也分为两种预测形式PV-DM和PV-DBOW,如图3所示.PV-DM和CBOM相似,不同的是PV-DM模型还需要随机初始化一个段落向量,将段落向量和词向量通过取平均值或者相连接来对目标单词进行预测.在公式(5)中函数f通过段落矩阵V和单词矩阵W共同构造.PV-DBOW则是通过输入的段落向量来预测上下文单词.

图3 PV-DM模型和PV-CBOM模型Fig.3 PV-DM and PV-CBOW
通过举例来描述Doc2vec模型和Word2vec模型在预测效果上的区别.例如,已知两个段落其中段落1中描述的主题是“我出门郊游野餐”,段落2描述的主题是“我在家吃午饭”,给出上下文“我坐在__”让模型预测空缺的单词.对于Word2Vec来说,不会考量段落1或是段落2的语境和主题,该模型也许会认为“椅子上”在训练集中出现的次数最多,所以预测出坐在“椅子上”最有可能.但对于Doc2Vec来说,同时跟随上下文输入的还有一个代表了本段落的向量.当一起输入的是代表着段落1的向量时,最有可能预测的是“草坪上”或“地上”这类单词,较小概率预测到“椅子上”;当一起输入的是段落2的向量时,更有可能预测的是“椅子上”,而“草坪上”或是“地上”就显得不太合理,所以被预测到的概率降低.正如上述例子所描述的,Doc2vec考虑段落语境对词语的预测更加准确、更加灵活.
2 新模型的介绍
正如前几节所介绍的,LDA模型可以从全局中挖掘文档中的潜在主题,但是却忽略了单词之间的顺序丢失了局部语义信息.而Doc2vec模型弥补了这样的缺点,训练出来的词向量运用了整个语料库的信息,而得到的段落向量含有局部语义信息.将两种方法相融合来训练向量,最终把词向量、主题向量、段落向量都投射到同一语义空间中去.该模型不仅能挖掘出更细粒度的特征词,还对后续的分类任务提高了辨识能力.
图4展示了新模型,该模型将单词、文档和主题投射到同一语义空间中.Doc2Vec模型可以直接将段落或句子转换成具有固定维度向量的分布式文档表示.所以说文档向量是由段落向量构成的,而其中每个文档又都有自己的长度,因此它的向量要除以文档中的段落总数,这样才能保证测量的尺度相同.主题向量则由词向量构成,通过选取每个主题中前a个最高概率的词来表示主题,然后重新计算这些词的权重.最后通过计算主题向量和文档向量的余弦相似度,找到相似的文档.
给定文档集D={d1,d2,…,dn},在Doc2vec的模型下训练D可以得到单词向量{v(w1),…,v(wN)}与段落向量{v(p1,1),…,v(p1,r1);v(p2,1),…,v(p2,r2);…;v(pn,1),…,v(pn,rn)},其中{w1,…,wN}代表词汇表中的单词,{p1,1…p1,r1,…,pn,1,…,pn,rn}代表文档段落.接下来,通过公式(6)计算文档向量v(di),其中S是文档中的段落数.

与此同时通过LDA模型训练D挖掘潜在主题{t1,…,tm},其中在主题ti下任意一个单词wi,j的概率分布为θi,j.选出每个主题下概率最高的前a个单词,根据公式(7)重新计算单词的概率分布λi,j.在此基础上,通过公式(8)可以得到主题向量{v(t1),…,

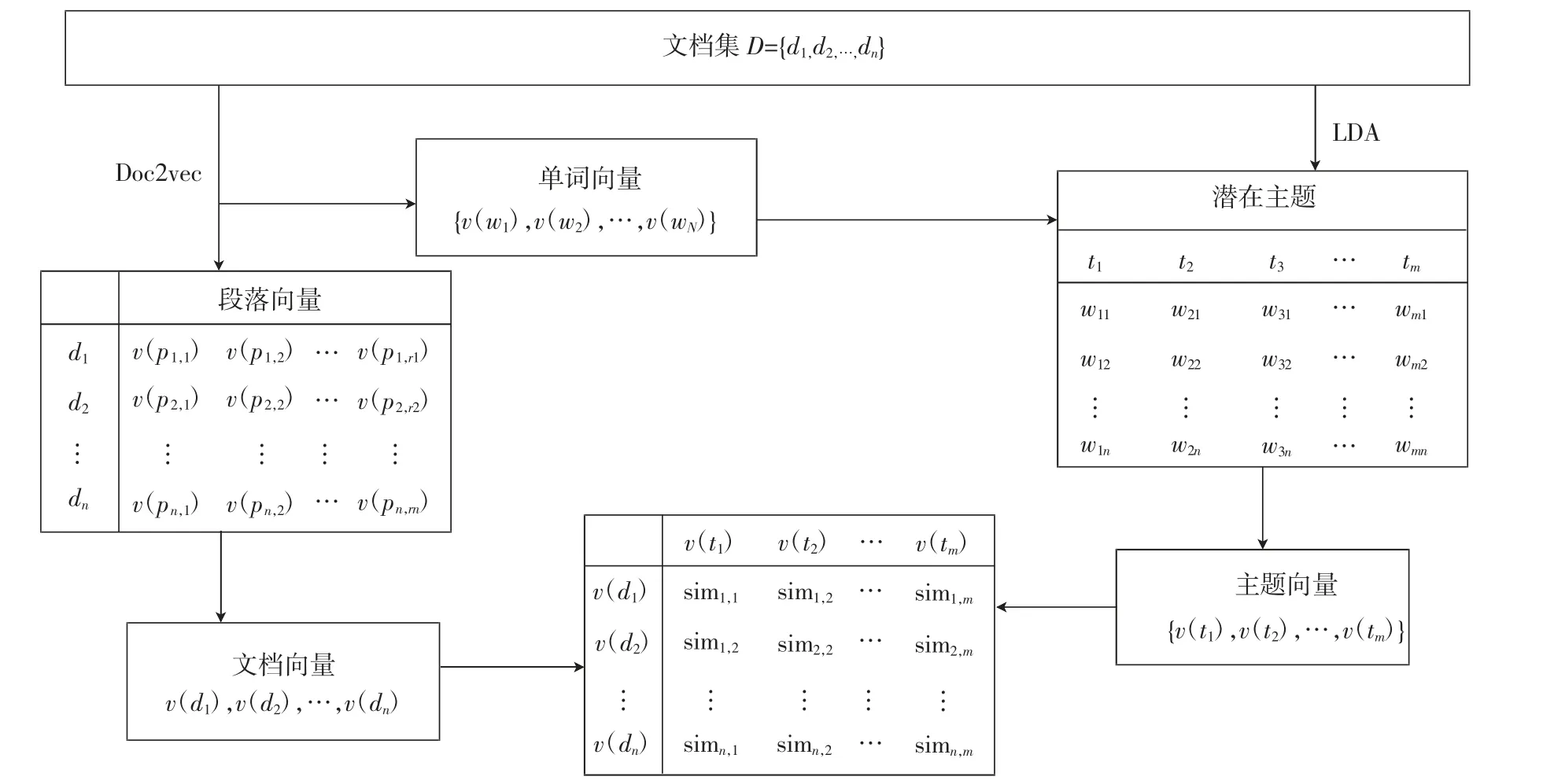
图4 新模型Fig.4 New model
新模型得到主题特征,不仅降低了数据的维度也改善了数据的稀疏性,更重要的是考略了单词的语义和顺序.这使挖据出来的潜在主题信息更丰富并且更接近于特定的文本内容.该模型通过度量新定义的主题向量和文档向量之间的相似距离来将主体信息融入到文本表示之中,可以很容易找到对应文档的主题.
3 实验结果及评价
3.1 数据处理
为了测试新模型的文本分类效果,利用国际标准数据集20Newsgroups进行试验检测,数据集包含18 846篇新闻报道,这些新闻报道又被分到20组不同类别的文档集中.本实验首先对数据集进行文本预处理.将文本拆分为句子,将句子拆分为单词,把所有单词变换为小写单词并删除标点符号.再删除所有的停用词,删除在语料库中出现少于3个字符的单词.最后将过去时态和未来时态的动词都改为现在时态,词语也被简化为词根的形式.
3.2 实验结果与分析
使用数据集中的所有文档去训练LDA和Doc2vec来提取主题向量、单词向量、段落向量.LDA和Doc2vec都是使用Gensim包来实现.在LDA中,超参数a设置为0.1,pass设置为20,以保证收敛.Doc2vec使用的PV-DM模型在Gensim中具有默认设置.最后使用scikit-learn包对gamma=0.001的分类执行SVM[13],分类指标采用Micro F1.第一部分实验选取了一篇关于曲棍球比赛的新闻报道来验证新模型的有效性,相关实验数据如表1所示.
在表1的左栏中,语料经过LDA模型学习后得到该文档中60个主题的概率分布,实验中选取了前5个与文章最相关的主题,其中包含主题8、13、26、32和54,其他未列出的主题概率为0.表格的右栏代表由新模型得到的距离分布,括号中的两个值分别代表主题索引和标准化距离,其中标准化距离越小,主题信息与文本内容越接近.通过计算得到右栏中的平均余弦距离为1.876,此外在右栏也找到了与左栏中相应的主题并加粗来表示,可以发现这些主题的距离小于之前计算的平均值,证明这些主题可以代表该文档.右栏中的的主题26和主题58分别是距离最短与距离最长的主题,通过分析主题26与主题58所包含的主题词来解释其中的意义.主题26中包含“胜利”、“第一次”、“比分”、“卫冕”等与示例文曲棍球运动相关的词.而主题58包含“仓库”、“种族”、“竖直”、“自动”等诸多与文档内容无意义的词汇.这就说明这些距离具有可解释性.另一方面,例如像主题19,它的余弦距离小于主题8、13、32、54,并且主题19包含“半场”、“得分”、“曲棍球”等词,这说明本文提出的模型可以挖出更多与文档内容相关的主题信息.

表1 样本的主题分布与距离分布Tab.1 Topic distribution and distance distribution of samples
为了证明该模型的优点,在第二部分实验中对相同数据集下的LDA+SVM、Doc2vec+SVM、LDA+Word2vec+SVM的实验结果进行了分析.首先得到不同向量维度下的Doc2vec+SVM的分类结果,如表2所示.
根据上图所示,发现当向量维度设置为220时,Micro F1的结果最好.
接下来将LDA+Doc2vec与LDA+SVM、LDA+Word2vec+SVM进行分类对比,通过上述实验找到新模型中向量的最优维度vector_doc=220,通过改变对比模型中的主题数继续进行分类比较.如图5所示.

图5 Micro F1值的对比图Fig.5 Micro F1 valuescomparion chart
从图5中可以看出,LDA模型的分类效果最差,得到的Micro F1值也最低.从整体上看LDA+Word2Vec模型与LDA+Doc2vec模型的分类效果明显优于LDA模型.随着主题数量的增加LDA+Doc2vec模型和LDA+Word2Vec模型的Micro F1值在降低,这有可能是因为设置的主题数量的不合理,影响了文本分类的准确性.尽管如此,LDA+Doc2vec模型的整体效果也是优于LDA+Word2Vec模型,即使在较少的主题下,该方法的Micro F1值也是较高的.在新模型中由于Doc2vec在训练时加入了对于段落的考量,这样不仅考虑了词语的语序,还考虑到不同语境下词语向量所表示的含义,从而得到的段落向量则越来越接近于段落的主旨.再根据表3所示.

表2 不同向量维度下的Doc2vec+SVM的分类结果Tab.2 Classification results of Doc2vec+SVM in different vector dimensions

表3 四组实验的结果Tab.3 The resultsof four experiment
综合以上实验结果,LDA+Doc2vec模型的分类效果比传统的LDA模型高出20%,与其他方法相比新模型的Micro F1值能达到0.851,分类效果最好.
4 结论
文本分类问题的研究具有重要的现实意义和应用要求.本文通过结合LDA模型与Doc2vec提出新的文本表示方法,该方法结合了描述文章主题的主题向量,考虑了描述文章上下文的段落向量,比传统的文本表示方法更加全面.通过与上述三种方法的分类效果进行比较,该方法不仅挖掘出更多可能的潜在主题,还包含更多的语义信息,达到的分类效果也是最好的.本文的研究重点是提高文本分类的效果.在实验过程中,发现LDA初始主题的设置对于生成的文档表示非常重要.因此,在后续工作中计划先进行文本聚类找到最优话题数,之后再进行算法的混合.另一方面,通过计算算法效率发现了该模型存在建模速度缓慢的问题.所以,在未来的研究工作中,将考虑如何提高建模的速度,以适应海量文本数据的应用.最后,在文本分类问题上,本文只是研究了特征工程这一部分,在选取分类器上还可以进一步进行研究.
