基于BERT模型的文本评论情感分析
2021-06-03杨文军
杨 杰,杨文军
(天津理工大学 计算机科学与工程学院,天津 300384)
自然语言处理中的情感分析任务,是采用计算机辅助手段,基于文本,分析人们对于产品、服务、组织、个人、事件、主题及其属性等实体对象所持的意见、情感、评价、看法和态度主观的感受[1].
文本情感分析(Sentiment Analysis)是指利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程.文本分类在情感分析中应用,从而引申出了文本分类技术.文本分类利用自然语言处理、数据挖掘和机器学习等技术,可以有效地对不同类型的文本进行分析[2].随着深度学习概念的大火,研究者逐渐尝试使用深度学习模型处理文本分类任务.其中模型大致可以分为两类,卷积神经网络(CNN)[3]和循环神经网络(RNN).
本文中的情感分析的研究是通过对文本评论进行情感分类,即对文本内容进行特征提取后再进行文本分类任务[4].
1 相关概念
1.1 Word2Vector
Word2Vector是Google在2013年开源的一款用于词向量计算的工具.在原文中,作者提出了两个新颖的模型架构用来计算大规模数据集中的连续词向量,分别是CBOW(Continuous Bag-of-Word Model)模型架构与Skip-gram模型架构.其中CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量,Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量.Word2Vector是从大量文本语料中以有监督的方式学习语义知识的一种模型.其原理是通过学习文本,用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近.
1.2 BERT模型
BERT模型是谷歌公司AI团队在2018年发布的模型.该模型基于Transformers的双向编码器表示,与最新的语言表示模型不同,BERT被设计为通过在所有层的左和右上下文上共同进行条件预处理来从未标记的文本中预训练深层双向表示[5].BERT在一些自然语言处理任务上获得了很好的结果[6].
BERT模型的架构是一个多层双向的Transformer解码器.模型的主要创新点是在预训练方法的改进,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别representation.其模型通过双向训练语句,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示.BERT模型主要的任务是进行词向量的获取,通过对海量文本的学习,分析不同单位token之间的关系,将关系反映到词向量中.最早开始在NLP领域中是通过词典的方式将文本分词后进行编码,之后放入计算机进行不同的下游任务处理,由于词典编码的方式具有明显的缺点:浪费存储空间和不能体现词语之间的相关关系,Word2Vector出现了[7].Word2Vec的含义是将每个token通过训练得到词向量,但是由于输入的文本以句子为单位,同一个token在不同的句子中表达的含义不一定相同,简单说可能存在一词多义的情况.BERT模型采用两阶段的模型训练.一阶段使用双向语言模型预训练,第二阶段采用具体任务fine-tuning或者做特征集成;同时第二阶段的特征提取采用了transformer结构作为特征提取器而没有采用传统的RNN或CNN框架.所以BERT训练后的词向量效果更好,普适性强.
1.3 注意力机制
BERT模型是基于transformer,transformer模型的核心是注意力机制[8].最早将注意力模型引入自然语言处理领域的是Bahdanau等[9].
注意力机制[10]的核心目标是从众多信息中选择出对当前任务目标更关键的信息[11].为简单理解,可以将其看作对特征权重做动态调优.之前传统的做法是将词向量训练的过程中,对每一个token并没有特殊处理,注意力机制就是在这一过程中为每一个token分配特殊的权重,之后应用到相应的下游任务.注意力机制通常应用于Encoder-Decoder模型之中.其数学原理如图1所示,假设当前输出结果为Yt,已知Decoder的上一时刻的隐藏层输入为St-1,将当前的全部token输入Encoder中,获得相应的词向量,通过F函数,在经过softmax函数获得相应的权重,使得解码过程中对不同的词向量对lable产生不同的影响权重.

图1 注意力机制的数学原理图Fig.1 Mathematical schematic diagram of attention mechanism
1.4 LSTM
长短时记忆网络(Long Short TermMemory Network,LSTM),是一种改进之后的循环神经网络.由于独特的设计结构,LSTM适合于处理和预测时间序列中间隔延迟非常长的重要事件,并且它可以解决RNN无法处理的长距离依赖这一问题[12].LSTM[13]模型中有三种门,输入门,输出门,遗忘门.它的核心在于通过各种门来实现信息的添加与删除.
2 模型介绍
2.1 模型框架介绍
模型框架分为上游任务和下游任务两个部分.上游任务将原始语句经过预训练生产词向量,下游任务将预训练结果通过神经网络生成分类结果.
2.2 模型设计理念
情感分析任务是文本分类中的一种,其本质任务还是分类任务.模型的设计将任务分为上游和下游两个部分,其中上游任务主要的目的是在保留文本句意的情况下,将文本以向量的形式进行表达,用以处理下游任务.下游任务的目的是实现分类判别,将向量放入神经网络进行分类任务,据对比LSTM模型和GRU模型,最后决定采用LSTM模型,因为GRU模型最后输出的值有一大部分的都在0.5左右之间,这就说明,模型分类的“信息”不是很足,同时,虽然GRU模型的运行速度比LSTM模型快了一些,但是准确率仍然没有LSTM模型高.目前主流的预训练任务模型为Word2Vector模型和BERT模型.
3 实验过程
3.1 数据集和实验介绍
实验的数据集使用的谭松波老师的酒店评论预料.数据集总共包含了2 000条正向样本,2 000条负面样本一共4 000条样本.

图2 实验模型架构图Fig.2 Experimental model architecture
实验过程分为2个部分.一个是基准实验,词向量过程使用的是chinese-word-vectors模型,下游情感分类任务使用的是自己搭建的LSTM神经网络模型;第二个是改进实验,词向量过程使用的是调优后的BERT模型,下游情感分类任务使用的是自己搭建的LSTM神经网络模型.
实验任务,通过训练集训练模型,完成情感分析任务,得到一个准确率较高的文本情感分类器,并将文本情感分类器用于测试真实现实语句,期望在较高准确率的情况下获得相应的结果.
3.2 基于Word2Vector和LSTM模型的情感分析
实验搭建神经网络的结构如表1所示.

表1 基于Word2Vector和LSTM模型的神经网络Tab.1 Neural network based on Word2Vector and LSTM
经过多组实验,实验采用Adam作为优化器,学习率参数设置为e-3,损失函数loss设为binary_crossentropy,metrics参数为accuracy,训练集和验证集划分为9∶1,训练过程中epochs值设为20,batch_size值设为128,callbacks=callbacks.训练过程定义early stoping如果3个epoch内validation loss没有改善则暂停训练.同时调用ReduceLROnPlateau函数降低学习率,其中的参数设置factor=0.1,min_lr=1e-8,patience=0,verbose=1.
3.3基于BERT和LSTM模型的情感分析
实验搭建神经网络的结构如表2所示.

表2 基于BERT和LSTM模型的神经网络Tab.2 Neural network based on Bert and LSTM model
实验采用Adam作为优化器,学习率参数设置为e-5,损失函数loss设为binary_crossentropy,metrics参数为accuracy,训练集和验证集划分为9∶1,训练过程中epochs值设为20,batch_size值设为128,callbacks=callbacks.
3.4 实验流程
本词实验采用监督学习的方法,将文本预料设置为输入参数X,将情感结果设置为输出结果Y,设定正向情感标签为1,负面情感标签为0.如图3所示,下面是基于Word2Vector和LSTM模型的情感分析的流程图.
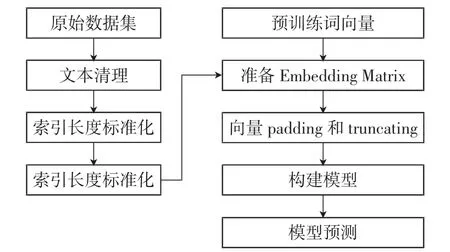
图3 基于Word2Vector和LSTM模型的情感分析的流程图Fig.3 Flow chart of emotion analysis based on Word2Vector and LSTM
3.5 实验结果和分析
本次实验的环境:CPU为inter i7-7700HQ 8核CPU,内存大小为16 G.实验过程中并没有使用GPU加速训练.其中Word2Vector+LSTM,平均训练的时间约为45 min左右,BERT+LSTM模型的运行时间约为2 h左右.经过对比,BERT+LSTM的模型运行时间更长.
训练过程中的每一个epoch的训练集和测试集的准确度如图4和图5所示.
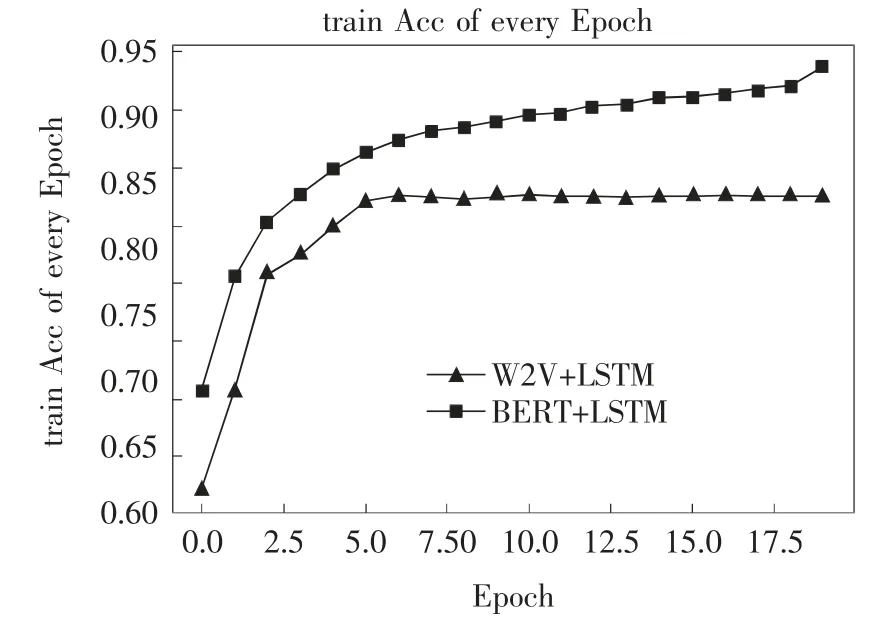
图4 训练过程训练集准确率对比图Fig.4 Training process training set accuracy comparison chart
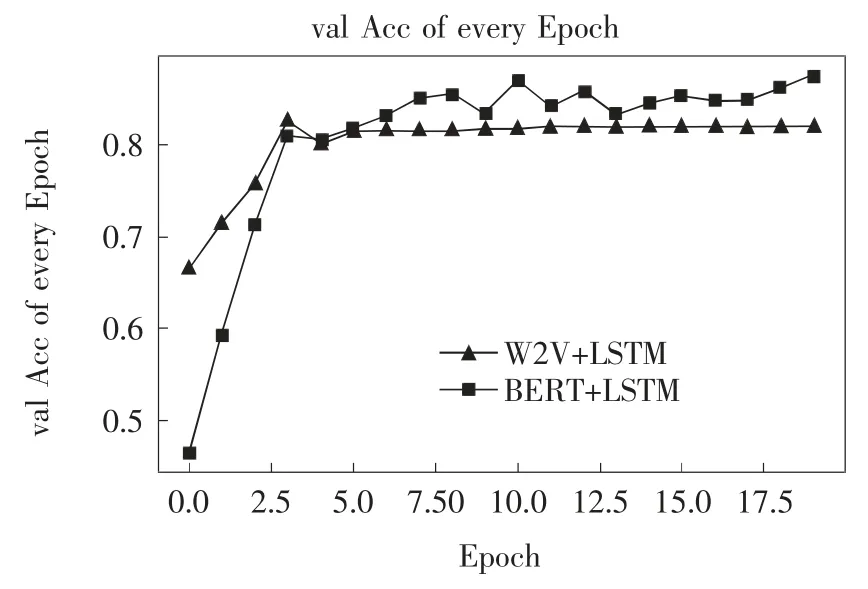
图5 训练过程验证集准确率对比图Fig.5 Training processvalidation set accuracy comparison chart
从图4和图5可以清晰的看出对比效果,在训练过程中,BERT+LSTM模型完全优胜于Word2Vector+LSTM模型.在验证过程中,BERT+LSTM模型基本优于Word2Vector+LSTM模型.从图中还可以看出,Word2Vector+LSTM模型收敛速度快,基本在5个epoch后就完全收敛.而BERT+LSTM模型在验证过程中存在一定的波动,说明收敛过程中出现了局部最优的情况,但总体的准确率是在不断增长的,说明模型并没有困于局部最优.同时也显示了BERT+LSTM模型的收敛速度慢.两种实验结果最终结果如表3所示.

表3 实验对比分析表Tab.3 Experimental comparison and analysistablel
通过对比可得,BERT+LSTM模型分析的结果明显优于Word2Vector+LSTM模型框架分析的结果.使得训练集和验证集的准确率和损失率都有明显的提高.同时通过参数对比可以清楚的看到,在Word2Vector+LSTM型中,参数总共为15 196 177个,但是Non-trainable params却高达15 000 000,而在BERT+LSTM模型总参数为918 785个,但是其中的Non-trainableparams却为0个.说明BERT_LSTM模型充分利用了参数,避免了不必要训练过程.
3.6 真实情景的预测
最后,作者找到了一些真实的评论预料进行预测.由于篇幅关系,这里仅展示一小部分测试结果,训练文本如表4所示.

表4 测试文本Tab.4 Test text
测试结果如表5所示.

表5 测试文本结果Tab.5 Test text results
通过主观测试,任务中只有3,5属于正面评价,其他属于负面评价.经过统计,Word2Vector+LSTM模型经过测试,有1条错误,BERT+LSTM模型经过测试具有0条错误.
4 结论
经过分析对比实验结果和用真实的语料文本进行测试.BERT+LSTM模型除了在训练时间方面比Word2Vector+LSTM模型需要花费更久的时间,但在其他方面BERT+LSTM模型几乎都完全优于Word2Vector+LSTM模型.
通过查询相关文献,得知因为有些语句的情感含义不是特别的容易区分,即使是成年人类也有一定的误判率,通常来说,实际情况中准确率能够达到85的准确率已经算是比较不错的结果,本次实验中BERT+LSTM模型最终验证准确率为87.5,算是得到了比较好的结果.
但是本次实验中仍有一些不足,通过实验结果可以很明显的看到,训练过程的准确率都是强于验证集的.说明存在了过拟合现象.尤其是BERT+LSTM模型中,训练集和验证集的准确率相差了大约6%.这在后期仍然可以优化.本文为读者提供了一个较好的情感分析解决方案.
