基于网络短文本主题挖掘技术研究∗
2021-06-02冯鑫汤鲲
冯 鑫 汤 鲲
(1.武汉邮电科学研究院 武汉 430074)(2.南京烽火天地通信科技有限公司 南京 210019)(3.南京烽火星空通信发展有限公司 南京 210000)
1 引言
短文本在网络上是普遍存在的,无论是在传统的网站上,如网页标题、文本广告和图片说明,还是在新兴的社交媒体上,如微博评论、知识问答、网购后的评价等都是短文本,它们不像传统的普通文本,这些短文本字数不多,很简练。随着大规模短文本数据集的出现,从它们中推断潜在的主题对于内容分析非常重要,也有巨大的商业价值。短文本内容的稀疏性给主题建模带来了新的挑战,在建模过程中几乎所有的模型都将每个主题看作是单词的分布,每个主题下的单词通常根据相关的概率进行排序,排序在前面的单词可以用来表示主题,然而,很多时候很难将文本主题的内容提取准确,如“薪资”、“工作”这两个词对之间具有相关性,可以通过语义联系将它们归为同一个话题“求职”,而不是单独地分开归为独立的主题,这种考虑词对之间的相关性有效降低了矩阵的维度,使主题提取的效果更好,因此,本文结合CRP[1~2]考虑到了词对之间的相关性,提出基于BTM[3]的Dirichlet过程[4]的GB⁃DP模型来解决稀疏性问题,该模型引入了词间的相似性,也考虑到词对之间的相似性,对短文本中的所有词对进行相似性矩阵的计算,这样不仅仅解决了短文本数据稀疏的问题,也将词汇之间和词对之间的相关性考虑进来,增强了捕捉主题的准确性,更加深入挖掘了文本语义。
2 相关工作
传统的主题模型,缓解稀疏性问题的一个简单解决方案是,在采用主题模型之前,将短文本聚合为长伪文档,例如,翁等[7]在训练LDA之前将单个用户发布的tweets聚合到一个文档中,然而,这种方法的有效性严重依赖于数据,例如,用户信息可能在某些数据集中不可用,另一种处理这个问题的方法是通过在短文本上添加强假设来简化主题模型,虽然这些假设可以通过简化模型来帮助解决数据稀疏性问题,但是它们牺牲了在文档中捕获多个主题的灵活性。此外,它们往往会导致文档中主题的后端达到峰值,这使得模型很容易过度拟合。如PLSA[8]和LDA[9~10],假定文档是主题的混合,其中一个主题被认为是通过一组相关的单词来传递一些语义,通常代表词汇表上的单词分布,然后使用统计技术来学习主题词的分布和主题比例,还有贝叶斯非参数模型(如HDP[11],dHDP[12]),这些都很难将这些短文本与额外的信息结合起来,或者在训练前做出更强的假设。因此,直接将这些模型应用于短文本将会遇到严重的数据稀疏问题,一方面,单个短文本中单词的出现频率比长文本的作用要小,这使得很难推断每个文档中哪些单词的相关性更强,另一方面,由于语境的限制,在短文本中识别歧义词的意义变得更加困难。与之前模式不同的是,BTM[13]通过提取词的共现模式对整个语料库进行建模。它增强了捕捉主题的准确性,但是BTM有其局限性,特别是当主题数量是动态的且数据集很大时,确定主题的数量的效果不好。为了获取适当数量的主题,研究人员提出了许多非参数模型,在这些模型中,HDP发挥了突出的作用,它是对狄利克雷过程的层次概括。Dirichlet过程[14]非常适合于混合模型中词对的先验分布问题。同时,它还提供了一种方法来说明词对效果的分布模型[5]。与HDP不同的是,本文在语料库级应用Dirichlet过程,并将整个语料库看作一个biterm集,考虑到词对之间的相关性,结合CRP提出了基于BTM的Dirichlet过程的GBDP模型来解决稀疏性问题,该模型引入了词间的相似性,也考虑到词对之间也有相似性,对短文本中的所有词对进行相似性矩阵的计算,这样不仅仅解决了短文本数据稀疏的问题,也将词汇之间和词对之间的相关性充分考虑,增强了捕捉主题的准确性,更加深入挖掘了文本语义。
3 基于GBDP模型主题空间分析
3.1 词对相似性与CRP的结合
CRP是Dirichlet过程的一种表示方法,它是模拟顾客到中国餐厅就坐问题的一个随机过程。由于biterm表示短文本中同时出现的无序字对,当bi⁃term分配给一个主题时,其中的单词更可能属于同一个主题,而不是单个单词。具体描述如下:有一家中国餐厅,假设桌子数量和每张桌子的人数不限,每个客户都可以随意选择一张桌子。这种客户就餐是一种Dirichlet的过程,客户就餐选择餐桌过程如下公式所示:i个顾客到j号餐桌就餐,m号客户选择餐桌Zm=j的概率与j号餐桌上的客户的分布有一定关系:

其中r为Dirichlet先验参数,c是第j个顾客选择的餐桌上已有的客户数量。很明显CRP过程是有缺陷的,顾客选择餐桌就餐时只看到了餐桌上面客户的数量而没有考虑到客户与客户之间的联系,只是单纯认为餐桌人数越多对客户的吸引力就越大,但这样是不合实际的,顾客之间也会影响其他顾客的选择,比如有的餐桌上人数不多,但餐桌上面有自己的好朋友,他就可能会选择那一桌。显然CRP没有考虑到顾客与顾客之间的相关性,本文提出的GBDP模型不仅考虑到词间之间的相关性而且考虑到了词对之间的相关性,即充分考虑到客户与客户之间的联系,这种联系是客户自身的,而不仅仅是参桌对客户的吸引力,这种考虑词对之间的相关性有效降低了矩阵的维度,使主题提取的效果更好。对于GBDP模型来说,餐桌就是主题,客户就是词对。
3.2 GBDP模型的Gibbs采样
在本文中采用Gibbs sampling进行近似推理。吉布斯采样是一种简单、应用广泛的马尔可夫链蒙特卡罗算法,与其他潜在变量模型的推理方法如变分推理和最大后验估计相比,吉布斯抽样有两个优点。首先,它在原则上更精确,因为它渐进地接近正确的分配。其次,它的内存效率更高。吉布斯抽样法的基本思想是,用一个变量的值代替另一个变量的值来估计参数,该变量的值由该变量的分布与其余变量的值组成。将链式法则应用于全数据的联合概率,可以方便得到条件概率:
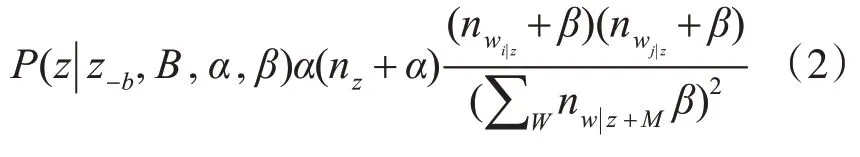
其中nz是biterm b的次数分配给这个话题z,nw|z是这个词的次数w后分配到z的主题。一旦将bit⁃erm b分配给主题z,其中的两个单词wi和wj将同时分配给主题,然后可以估计topic-word分布Φ和文档主题分布θ。Gibbs采样的过程如图1所示。
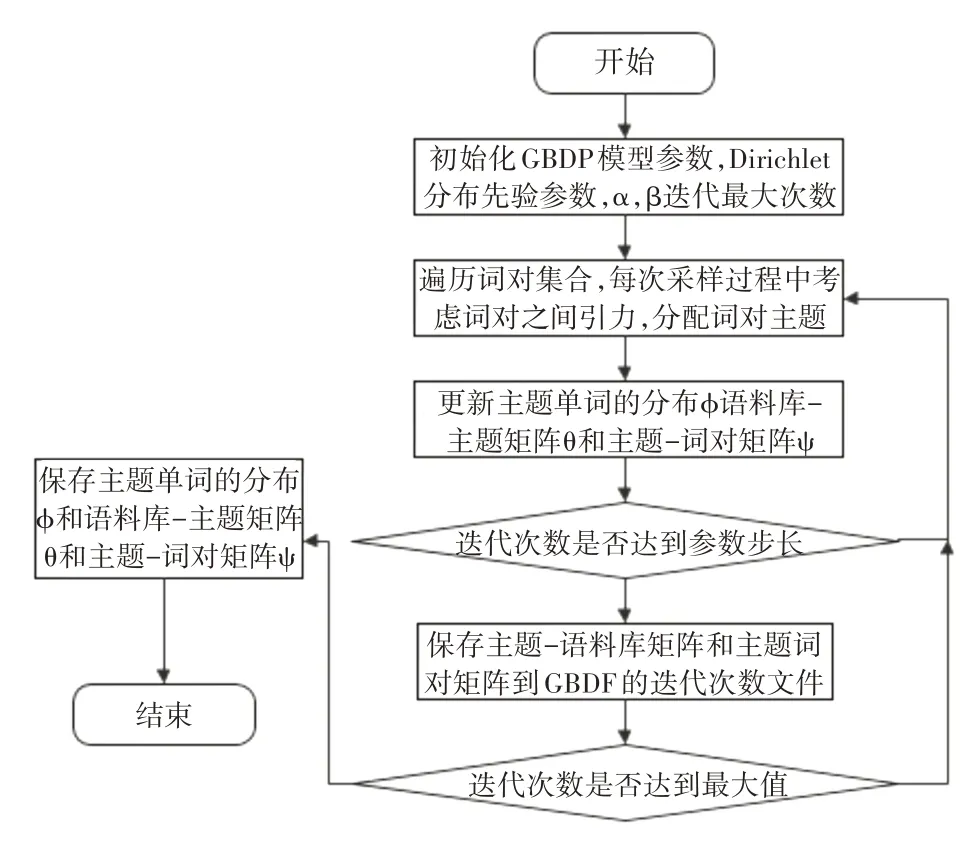
图1 GBDP模型的Gibbs取样
3.3 GBDP语义文本主题表示
在GBDP模型中,更加关注的依然是参数依然是文档-主题矩阵θ和主题-词矩阵Φ,和BTM模型类似,但是在Gibbs采样过程中的方法不同,GBDP模型中增加了主题-词对矩阵ψ。θ是各个主题的概率分布,是D×K维的矩阵,D是文档的数量,K是初始设定的主题数量;Φ是各个词汇在主题下的概率分布,是K×N维矩阵,K是初始设定的主题数量,N是文档集合的所有词汇;ψ矩阵是各个主题下词对的概率分布,是K×M维矩阵,K是主题个数,M是词对个数,在GBDP模型中,词对a+b和b+a视为一样,故,因此该模型时间复杂度为O(N2)主题的表示需要通过Φ矩阵来进行描述,在每个主题下选取概率值前十的词汇来描述改主题,这是因为概率值的大小说明该词汇在该主题下的重程度。
首先,我们需要从所有的文档中提取两个不同的单词来组成训练数据,然后直接基于对单词的共现模式进行建模。在GBDP中,这个观察值xi=(wr,ws)以如下方式出现:

G~DP(a0,G0),G0~Dirichlet(η)。其中wr和wr是在主题zi的多项式分布中得到的。a0是集中参数。通过Gibbs抽样,可以得到除主题文档分布外的全局主题分布θ和主题词分布Φ。但是,正如[16]假设的那样,我们可以计算主题文档分布如下:
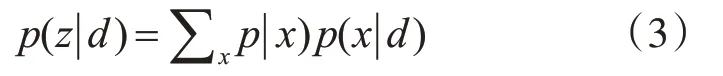
其中p(z|x)可以根据贝叶斯公式计算出来,p(x|d)几乎是均匀分布在文件中的所有词对上。它们的表达式是:
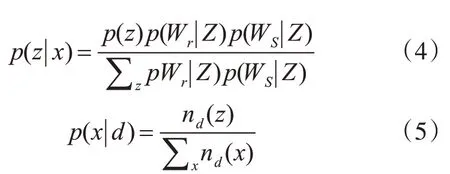
其中,在式(4)、(5)中,x=(wr,ws),p(z)=θz,p(wi|z)=ΦWi|z,nd(x)为文档d中biterm x的频率。
3.4 GBDP模型参数计算
本文采用了一个Gibbs抽样方案,用于给定观测值x={x1,x2,…,x|B|}的后验推理,|B|是一个词对集合,Z={z1,z2,…,zk}K是指主题的数量,x-i是除了xi的所有观测值。首先,我们应该定义给定主题zk中除xi外的所有词对的条件概率xi。根据式(1),我们有
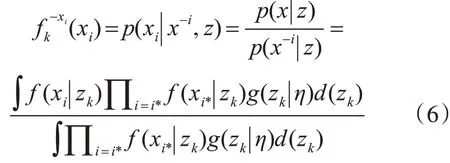
其中f(xi|zk)=f(wr|zk)f(ws|zk),f(·)是Mult(z)的密度,g(·)是Dirichlet(η)的密度。利用共轭先验,式(6)可简化为
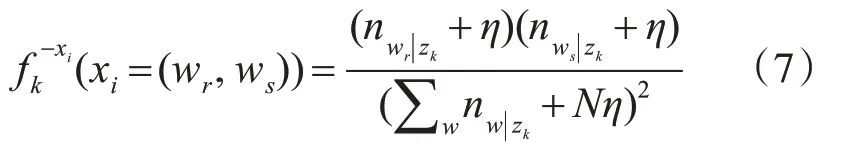
其中nw|zk是给定主题zk的单词w的个数,和N是词表中单词的数量。
1)ki的生成:考虑到词汇的互换性,我们将ki作为最后一个被采样的变量。ki是题目zk的索引,主题的观测值xi被赋给这个索引ki。结合产生xi的可能性,ki的条件后验概率是
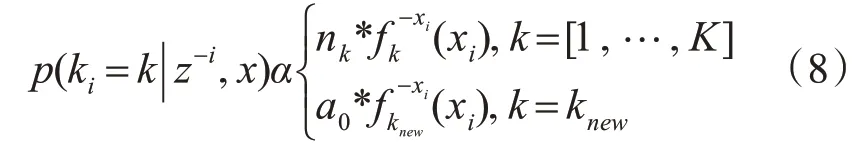
其中nk是除xi之外分配给主题zk的词对数
2)更新Φ,θ和ψ:以z和x为条件,zk的后验分布仅依赖于数据项
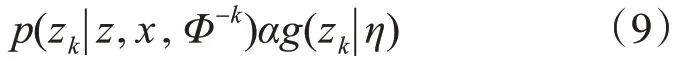
通过对biterm的主题分配和单词的出现,我们可以计算出主题单词的分布Φ和全局主题分布θ和主题词对矩阵ψ,简化公式如下:

3.5 评价指标
1)主题质量
本文使用度量主题一致性更客观地评估主题质量,高分意味着更好的表现,为了评价一个主题集的整体质量,我们计算了每种方法的平均连贯性得分,具体计算公式如下:

2)困惑度
困惑度是评价语言模型的一个重要指标,其思想是给测试集的句子赋予较高概率值的语言模型更好,即当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就在测试集上的概率越大越好,具体的计算公式如下:
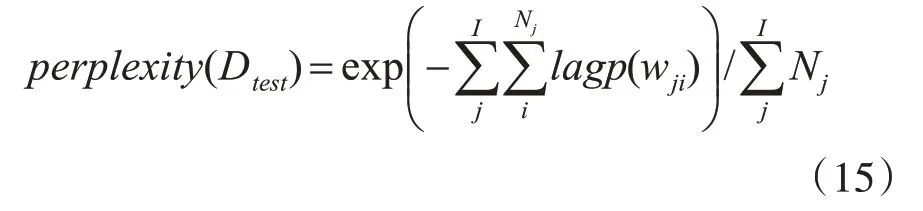
由以上公式可知,perplexity越小,困惑度越低,泛化性能越好,模型性能越好。
4 实验设计
4.1 数据集
为了验证GBDP在短文本上的有效性,本文在一个标准的短文本集合上进行了实验,即采用来自于搜狗实验室的专区数据作为数据集,内容是关于新闻方面的,选取十个类别且每个类别分别选取10篇,类别分别为汽车、财经、健康、体育、旅游、教育、招聘、游戏、文化、科技。为了证明方法的有效性,将三个主题模型作为对比标准:LDA、HDP和BTM。本文评估了两个典型指标的性能:主题的质量和困惑度。
4.2 实验结果分析
1)主题质量连贯性分析
本文抽取所有测试方法的两个共享主题作为样本,收集每个主题的前10个单词(如表1所示),然后使用度量主题一致性更客观地评估主题质量,高分意味着更好的表现。为了评价一个主题集的整体质量,表1中,模型发现主题具有良好的可理解性。我们计算了每种方法的平均连贯性得分(如表2所示),可以看到,GBDP模型在平均一致性评分方面优于其他方法,如图2。
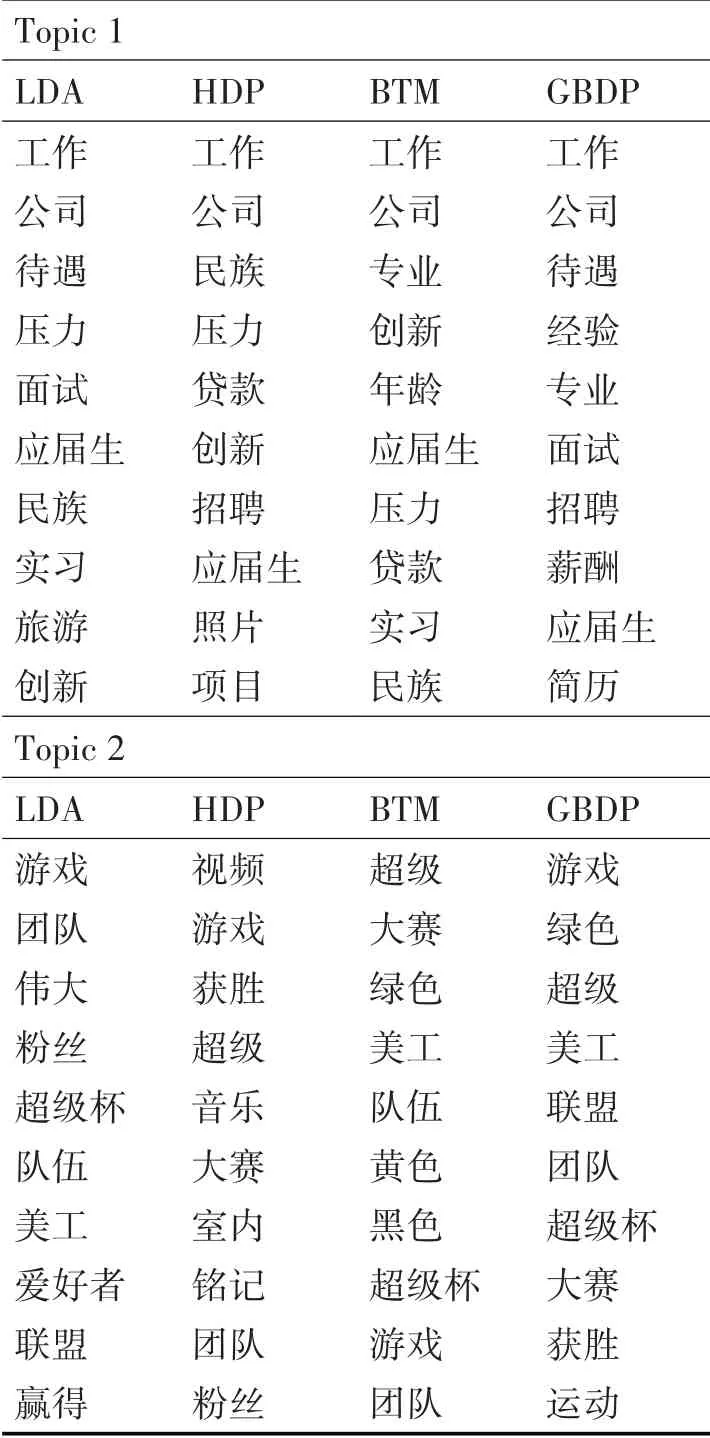
表1 用10个单词选出所选的主题

表2 主题一致性内容平均成绩
2)困惑度分析
结果表明,GBDP具有较低的困惑度,但与HDP一样陷入局部最优。尽管GBDP不是最好的,但它提供了稳定的性能,并且在迭代的开始这方面工作得很好。此外,结果表明GBDP能够找到比任何其他模型更多样化的主题,如图3。

图2 主题连贯性得分
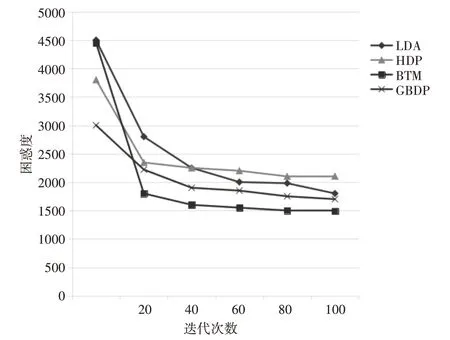
图3 迭代次数对困惑度的影响
5 结语
本文提出了结合CRP的一种基于BTM的Dirichlet过程的主题模型GBDP,该模型能够很好地捕捉短文本中的主题。它考虑的是整个语料库中的单词出现模式,而不是每个文档中的单个单词。通过对实际数据的实验,验证了模型的有效性。即使测试数据很稀疏,它也能很好地工作。此外,它的建模过程更加灵活,不需要确定主题的数量。然而仍然有很多问题要处理,例如,在大规模数据方面,采样算法比较麻烦,需要更多的内存空间。改进取样过程对我们今后的工作具有重要意义。
