基于需求侧管理的电力用户能耗预测分析∗
2021-06-02樊立攀李劲松霍伟强田晓霞
樊立攀 李劲松 霍伟强 田晓霞 傅 晨
(国网湖北省电力有限公司 武汉 430000)
1 引言
在供电需求侧管理中,根据用电情况、天气预报和建筑物内供热、供冷系统的特点进行用电需求分析和预测,有助于电力部门掌握居民用电的动态行为,为电力需求侧管理提供决策依据,对优化供电侧调度管理和提高低压供电质量都具有参考意义[1~3]。建筑能耗预测方法主要是利用线性回归算法[4]、决策树算法[5]、神经网络算法[6]和支持向量机[7]来概括输入特征与输出预测之间的映射关系。目前大多数关于住宅建筑的研究都立足于对建筑能耗的短期能耗预测(每小时)或长期预测(每年),以削减一天内高峰时段用电量或确定电网规划和投资的要求,但是面向区域需求侧管理的大量住宅建筑的月用电量预测研究相对较少[8~9]。为此,本文提出一种能够准确预测住宅用电量的模型。试验表明,该模型能够通过精确的分类结果较准确地预测该地区未来一个月的电力需求侧状况和分布,为供电的调度和控制提供可靠的数据支撑。
2 预测方法
2.1 方法概述
本文所提出的针对住宅建筑能耗预测问题的解决方案如图1所示。首先,对从数据库中获取的数据进行预处理,包括住宅建筑的特征、天气信息和能源消耗,以去除数据中的噪声、异常值和缺失值。在预处理之后,对数据集进行特征提取。提取方法是首先进行数据特征描述和数据归一化处理,随后通过特征工程从数据中提取有效信息,最后进行特征维数约简。在预测住宅用户用电量前,首先利用PSO-K-means算法对每个季度的用电量数据进行聚类分析,然后根据聚类中心点将每个季度的用电量值划分为相应的水平。经过数据采样后,采用SVM模型对输入的是住宅建筑的特征、天气信息和历史能耗数据(即上月的天然气和电力消耗)进行计算,输出为下个月的住宅用户用电量水平。下面对四个关键算法进行阐述。
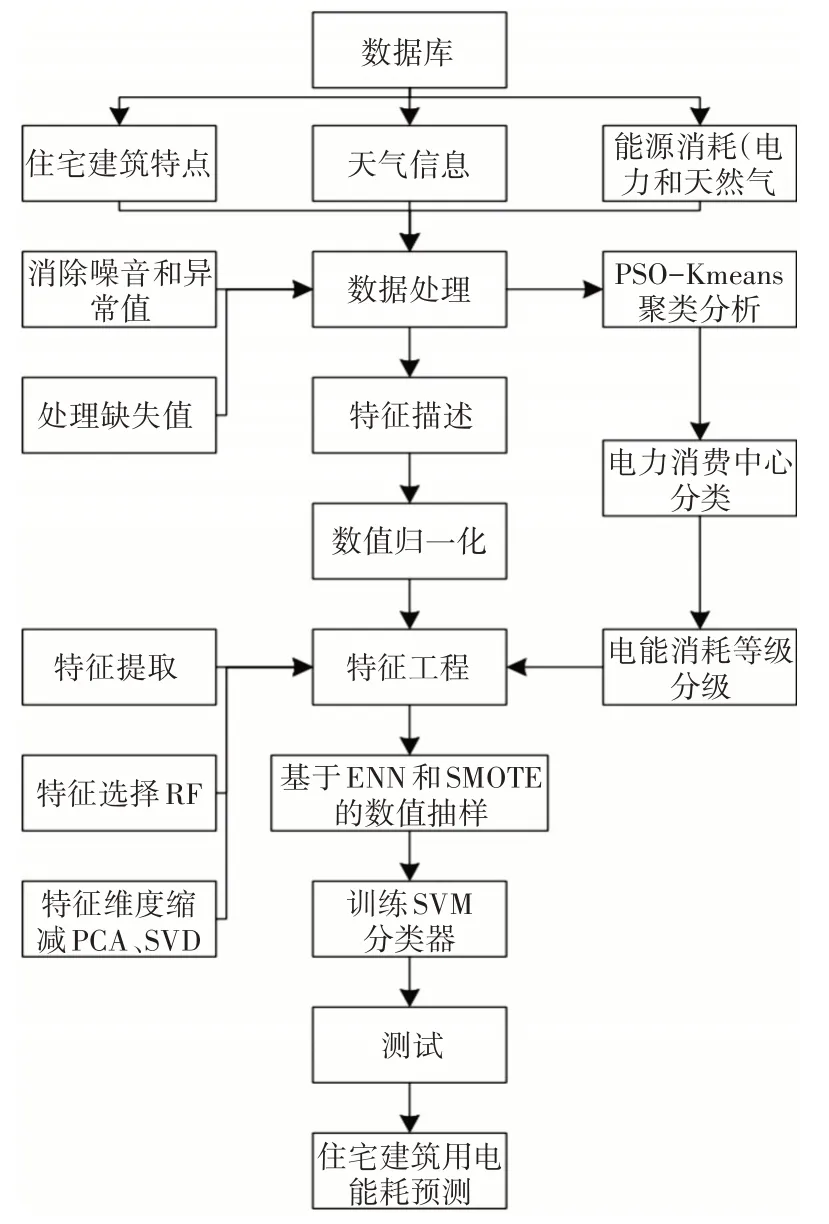
图1 住宅建筑用电能耗预测
2.2 PSO-K-Means聚类分析
在预测住宅建筑的电能消耗等级之前,利用K-means聚类算法分析了数据的分布规律。本研究将电能消耗数据分为四个季度,然后提取每个季度三个月的值作为特征向量。例如,第一季度的特征向量为1月份的电能消耗,2月份的电能消耗,3月份的电能消耗。
K-means聚类算法具有收敛速度快、稳定性好等特点。然而,聚类过程无法确定聚类中心的数量。本文引入适应度sdbw值作为聚类结果的评价指标。sdbw不仅考虑了聚类内的紧凑性,还考虑了两个聚类之间的密度问题。适应度值越小,聚类效果越好,说明聚类内连接越紧密,聚类间分离越大。
设D={Vi|i=1,2…,c}将数据集S划分为c个凸聚类,其中vi为每个聚类的中心。从中心到聚类Stdev点的平均距离计算公式如下[13]:
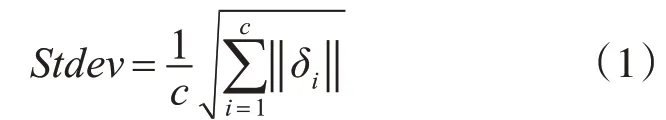
有效性指数sdbw定义为
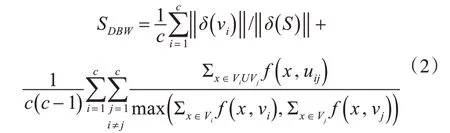
式(1)和式(2)中δ(vi)是聚类vi的方差,δ(S)是数据集的方差,vi和vj分别是聚类vi和vj的中心,uij是由vi和vj的中心定义的线段中点。如果中心u与点x之间的距离d(x,u)大于聚类Stdev的平均标准差,则f(x,u)=0;否则,f(x,u)=1。
聚类效果取决于初始聚类中心的选择。为了解决这一问题,本文采用改进的粒子群优化算法(PSO)作为K-means聚类算法的前一步。
假设n维空间中有m个粒子运动。在这一点上,在所有粒子中都找到了每个粒子各自的最佳位置pbestk和全局最佳粒子位置gbest。对于任意粒子k,位置xk和飞行速度vk根据以下计算公式进行调整:

采用线性调整策略动态调整公式中的权重:

上式中w(t)是惯性权重函数,c1是认知权重因子,c2是社会权重因子,r1和r2是在[0,1]范围内均匀分布的两个随机数,wmax和wmin分别是初始和最终惯性权重因子,tmax是最大迭代数,t是当前迭代数。
在迭代的后期,优化算法的搜索速度趋于缓慢,适应值趋于稳定。因此,本研究引入适应度方差的阈值以完成迭代,其计算公式如下[14]:
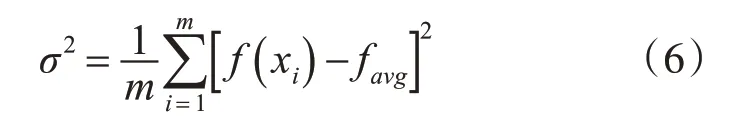
式(6)中m为群中粒子数,f(xi)为单个粒子的适应度值,favg为粒子群的平均适应度。
PSO-K-means算法的实现如算法1所示。
算法1 PSO-K-means算法
输入:聚类数据集(居民用电量)S={x1,x2,…,xw},聚类中心数c,粒子群大小m,最大迭代数t max
输出:聚类分类D={V1,V2,…,Vc}
1)迭代s次,找到每个维度的最大值和最小值作为位置范围[xmin,xmax],其中速度范围为[-xmax,xmax];
从S中随机选择c个初始化中心,然后重复并生成m粒子群;
使用式(2)计算每个粒子的适应度值sdbw;
初始化pbestk和gbest;
2)for(迭代次数<tmax)do
for(k=0,1,…,m)do
根据式(3)和(4)更新粒子的速度和位置,并确保速度和位置在控制范围内;
根据式(5)动态调整权重;
end for
for(数据点=1,2,……,w)do
使用欧几里得距离将每个数据点划分进最近的簇;
使用式(2)计算适应度值sdbw;
if sdbw<个体极值,则更新pbestk和gbest;
end for
使用式(6)计算粒子群的适应度方差;如果适应度方差>阈值,转至步骤3);
end for
3)获取最佳数量的群集中心C和gbest;
执行k-means算法;
4)从粒子群优化算法的结果中选择最小sdbw的PC粒子作为初始聚类中心;
5)for(数据点=1,2,……,w)do
使用欧几里得距离将每个数据点划分进最近的聚类;
end for
for(聚类数量=1,2,……,c)do
更新每个聚类的平均值并标记中心点;
end for
如果聚类中心点没有更改,则返回聚类分类D={V1,V2,…,Vc}。
2.3 抽样算法
为了解决数据分类不平衡的问题,本研究采用最近邻(ENN)算法[15]和合成少数技术(SMOTE)算法[16]分别对大多数类别数据和少数类别数据进行抽样,以实现对数据集的平衡,为下一步的数据分类处理提供方便。
算法2 ENN算法
输入:原始数据集T,相邻样本个数K
输出:过采样后的数据集TENN
1)i=0,TENN=T;
2)while(i<抽样个数)do
比较数据集T中xi周围的K个相邻样本的类别和xi的类别,如果不同,则删除xi;
end while
SMOTE通过在少数类数据点之间随机插入新的样本来平衡样本。该方法在一定程度上避免了分类器的过度拟合,提高了分类能力和预测精度。
在本研究中,抽样算法集成了ENN与SMOTE以平衡数据集,将数据集分为不同的电能消耗等级。大多数类别中的数据被抽样采集(删除了一些数据点),少数类别中的数据被对偶取样(添加了新的数据点),以改进后续SVM分类器的预测结果。SMOTE算法如算法3所示。
算法3 SMOTE算法
输入:数据集TENN,相邻样本数k,过采样率n
输出:数据集TSMOTE
1)i=0;
2)while(i<抽样个数)do
在xi附近找到K个相邻的样本,选择n个样本xij
for j=1,2,…,n
根据以下计算公式对新的少数类别样本yj进行拟合:yj=xi+(xi-xij)rand(0,1);
end while
3)将yj加入数据集TSMOTE
2.4 SVM方法
SVM是一种被广泛使用的机器学习分类算法[17]。由于SVM方法具有训练过程简单,输入量少的优势,本研究使用该分类对用电量数据进行分类处理。
当数据线性可分时,SVM解决分类问题的方法为
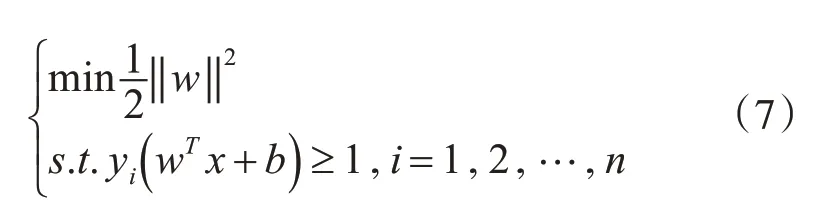
在SVM理论中,通常将拉格朗日乘子引入目标函数,使得目标函数呈现对偶形式易于求解。拉格朗日函数的形式如下:
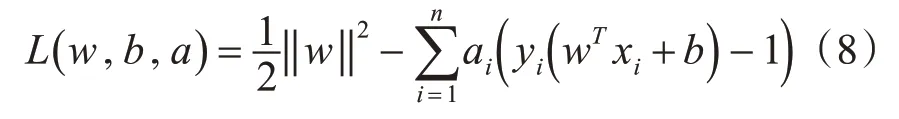
其中w和b是通过计算a得到的,w是欧几里得范数,ai(i=1,2,…,n)是拉格朗日乘数。对偶问题定义如下:
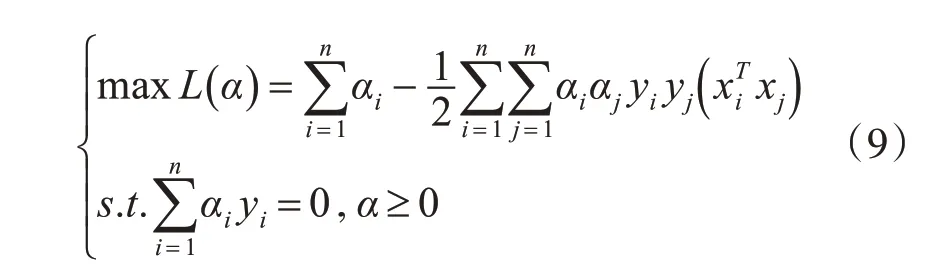
随后将对偶问题转化为目标函数的极值问题:
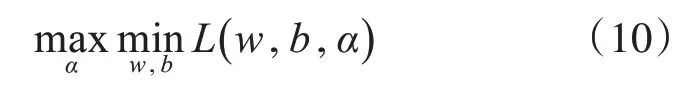
分类超平面的计算方法为
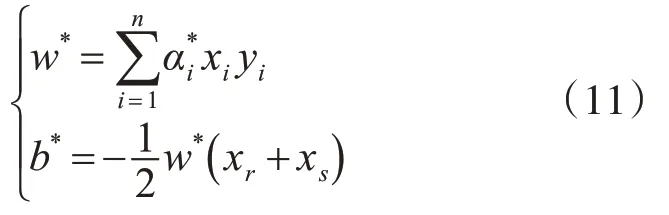
其中,是最佳拉格朗日乘数,xr和xs是两类支持向量中的任意一对。
本研究的用电量水平的预测是一个多分类问题,因此需要将其分为多个二分类问题。划分策略采用OvR(一对剩余)的形式。可以使用OvR为每个类训练一个分类器,其中特定的类被认为是正类,所有其他的样本被认为是负类。在实验中将使用n个分类器将具有最高置信度的类标签分配给特定的样本。
3 实验
3.1 实验设置和评价指标
本文利用湖北省武汉市电力公司和武燃集团提供的2018年度公共能源消耗数据,对上述能耗预测方法进行了测试。所使用的公共能源消耗数据包括住宅建筑的特点和每月的电力和天然气能耗。测试算法采用python实现。试验平台为一个Windows10操作系统,该操作系统采用Intel酷睿i7 2.7GHz处理器和16GB RAM,软件平台为pycharm和anaconda。采用三个常用的评价指标:准确度、精密度和召回率对预测性能进行量化衡量。
3.2 住宅建筑的用电量分类
实验得出的每个季度不同深度颜色的聚类结果如图2所示。根据最优适应度值计算聚类中心,如表1所示,划分各住宅建筑月用电量类别。例如,第一季度单位面积用电量低于0.287 kWh/m2的住宅建筑划分为1级。
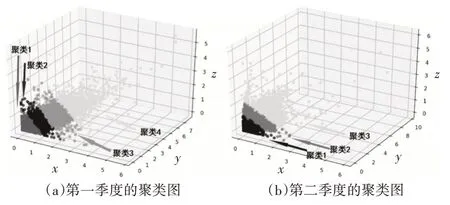
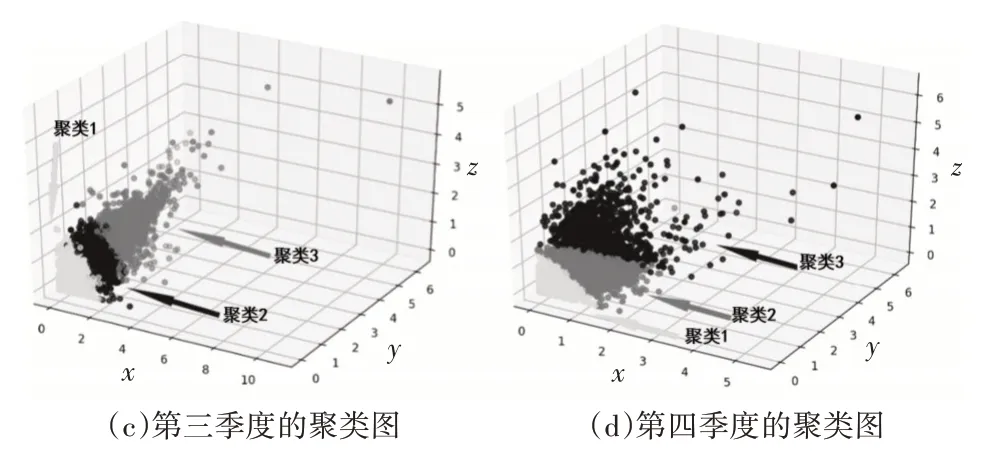
图2 每个季度的聚类结果(x、y、z坐标表示每个季度三个月单位面积的电能消耗(kWh/m2))
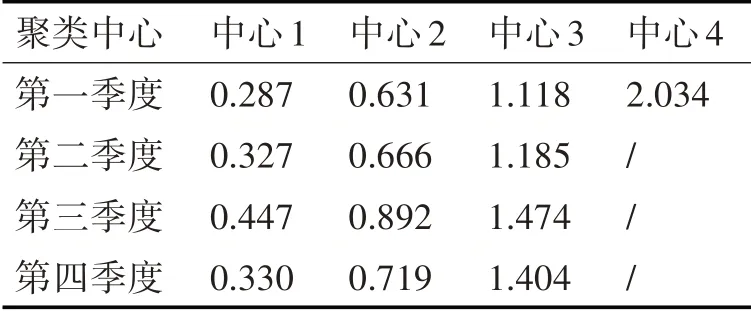
表1 各季度单位面积耗电聚类中心
然后统计每个季度不同等级的住宅建筑数量,如表2所示。第一季度的用电量从高到低可以分为五类,而其他三个季度可以分为四类。

表2 每个季度的聚类统计数
3.3 数据抽样和过度采样
利用聚类算法解决了住宅建筑电能消耗的分类问题,但根据上述内容,出现了一类不平衡问题。本文采用数据抽样和过度采样相结合的方法来解决电力能耗数据的不平衡问题,并采用SMOE-ENN算法对不平衡数据集进行处理。图3显示了原始的一个季度与四个季度中的一个季度之间的比较图。抽样处理后的数据包含14个结构变量,14日天气变量和两种历史能源消耗变量(前一个月的天然气用量和用电量),为了方便对比显示原始数据和,通过PCA算法将抽样处理后的数据维度减少到三个维度(坐标轴没有物理意义)。
3.4 试验结果
试验数据来自于武汉市电力公司和武燃集团公开的2018年度公共能源消耗数据。其中第二、三、四季度用于电力预测的住宅共16560栋,但一季度用于试验的住宅11003栋的能耗数值缺失。为了预测每月的电能消耗等级,80%的处理数据集用于训练,20%用于测试。对GBDT、BP和SVM每种模型重复实验20次。表3中的实验结果说明了本文所述的模型在预测住宅建筑用电上的具有最优的性能指标。
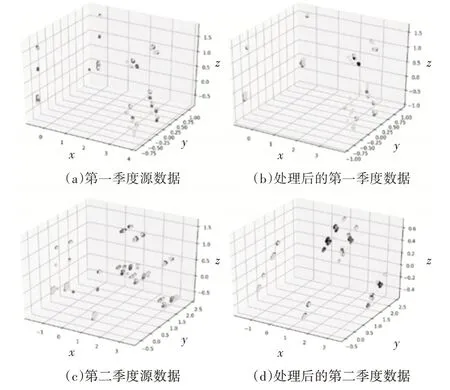
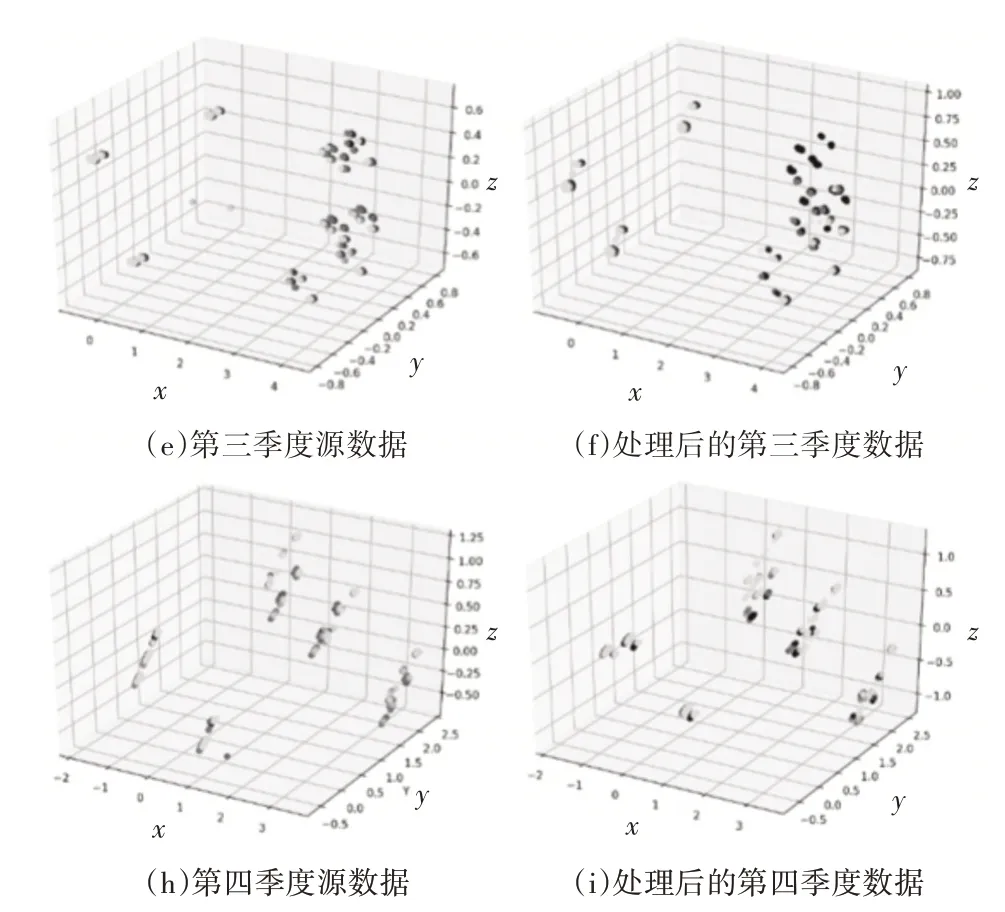
图3 经过抽样算法的数据比较图
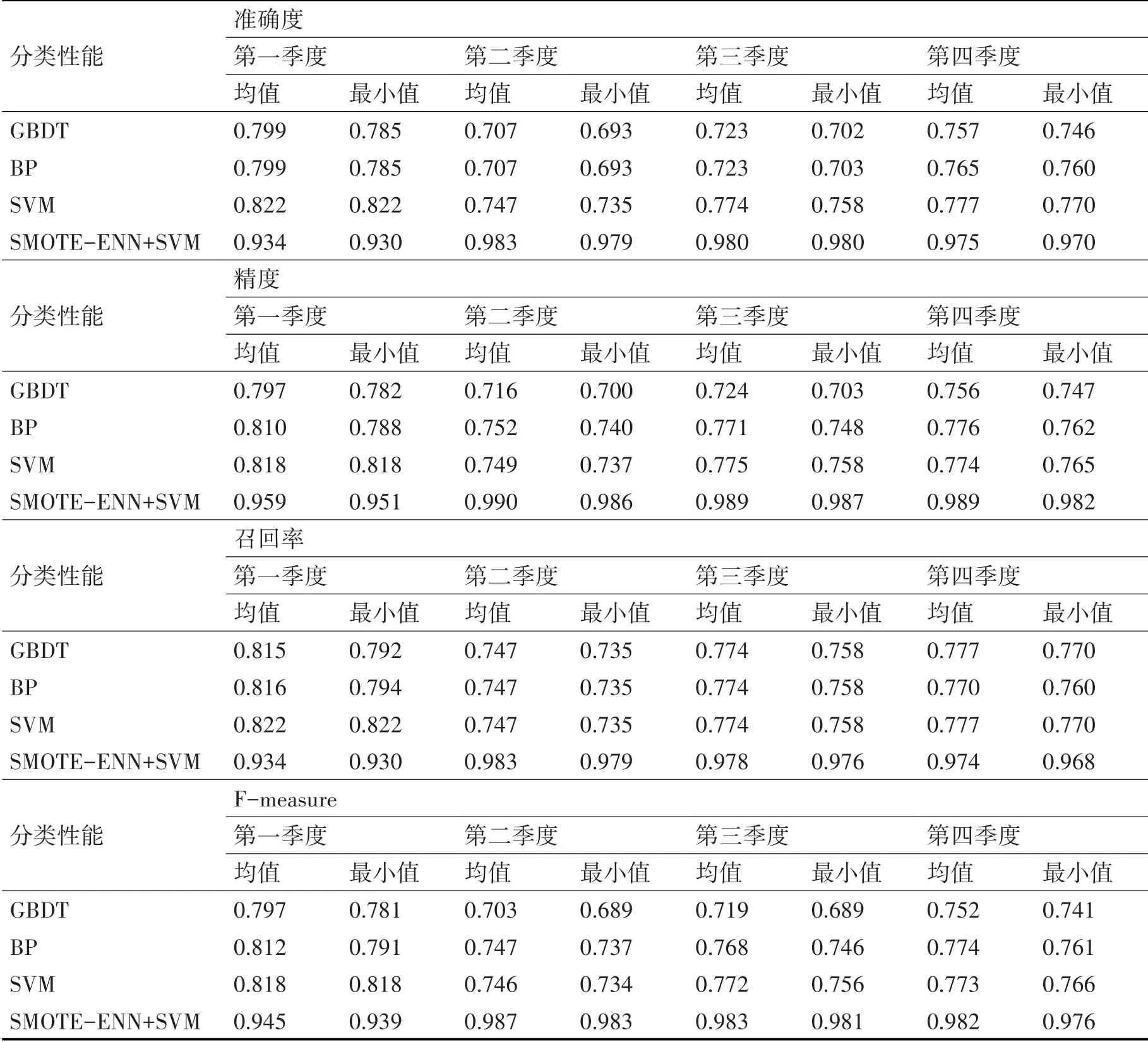
表3 GBDT、BP、SVM和SMOE-ENNCSVM模型的分类性能比较
4 结语
本文提供了一个优化的SVM模型,通过使用SMOE-ENN抽样算法来解决不平衡分类问题,提高了模型的分类精度,从而更好地预测住宅建筑的季度电能消耗。该模型首先针对高维数据稀疏的特点,采用组合式RF-PCA-SVD特征工程算法;其次利用改进的PSO-K均值聚类算法对电能消耗数据进行了季度分析;最后通过采用支持向量机,并将其分类性能与传统的GBDT、BP分类方法进行比较,证明了SVM与抽样算法在住宅建筑用电量月度预测中的优越性。这些研究结果为每月在宏观层面上合理配置整个区域的电力供应提供了参考意见。此外,该模型还有助于改善电网质量,在夏季和冬季的高峰电力季节确保为舒适生活提供稳定的电力供应,可为电力需求侧的管理提供可靠的决策依据。
