基于MIPS32架构三角函数指令集扩展的设计与实现
2021-06-01李正平
李正平,高 杨
(安徽大学 电子信息工程学院,安徽 合肥 230601)
0 引 言
电子通信技术的迅速发展使得人们对数字系统实时性和准确性提出了更高的要求,人们需要精度更高,频率更快的系统来处理数字信号。然而,基于软件处理数字信号会消耗大量的时钟周期,无法满足实时性要求;使用硬件加速器虽然能够减少时钟周期,但是加速器缺乏灵活性且硬件资源消耗得比较多,在通用的处理器上针对特定的应用领域扩展指令集已经成为了两者折中的方式[1-2]。本文提出了基于MIPS商用处理器架构,CORDIC算法指令集扩展的设计与实现。
1 CORDIC算法及其特点
CORDIC算法的主要思想是在坐标系中不断旋转特定的角度,使得旋转角度的累加值不断逼近待计算的角度[3]。该算法的最大优势在于可以通过简单移位运算替代复杂的数学运算,便于硬件实现[4]。文献[5]对CORDIC算法进行统一的整理,给出求解初等函数的统一公式,即
xi=K{xi-1cos(αm1/2)+yi-1m1/2sin(αm1/2)},
yi=K{yi-1cos(αm1/2)-xi-1m-1/2sin(αm1/2)},
zi=zi-1+α
(1)
αi=tan-1(2-i)
(2)
(3)
其中:α为每次逼近时需要旋转的角度;i≥0为迭代的次数;K为初值常数,和迭代的次数相关;x0、y0为旋转起始点的坐标;z0为旋转起始点与x轴的夹角;zn为迭代n次角度的累加值。
2 cordic指令集扩展
2.1 MIPS32商用处理器流水线结构
处理器的内部结构如图1所示,和经典的五级流水[6]不同的是,该处理器采用了四级流水,将五级流水的译码和执行2个步骤合并成一步完成,可以同时处理4条指令的4个不同阶段。处理器内部含有多个功能部件,比如乘法部件、除法部件以及本文新增加的三角运算部件。三角运算部件能够支持六种函数运算。
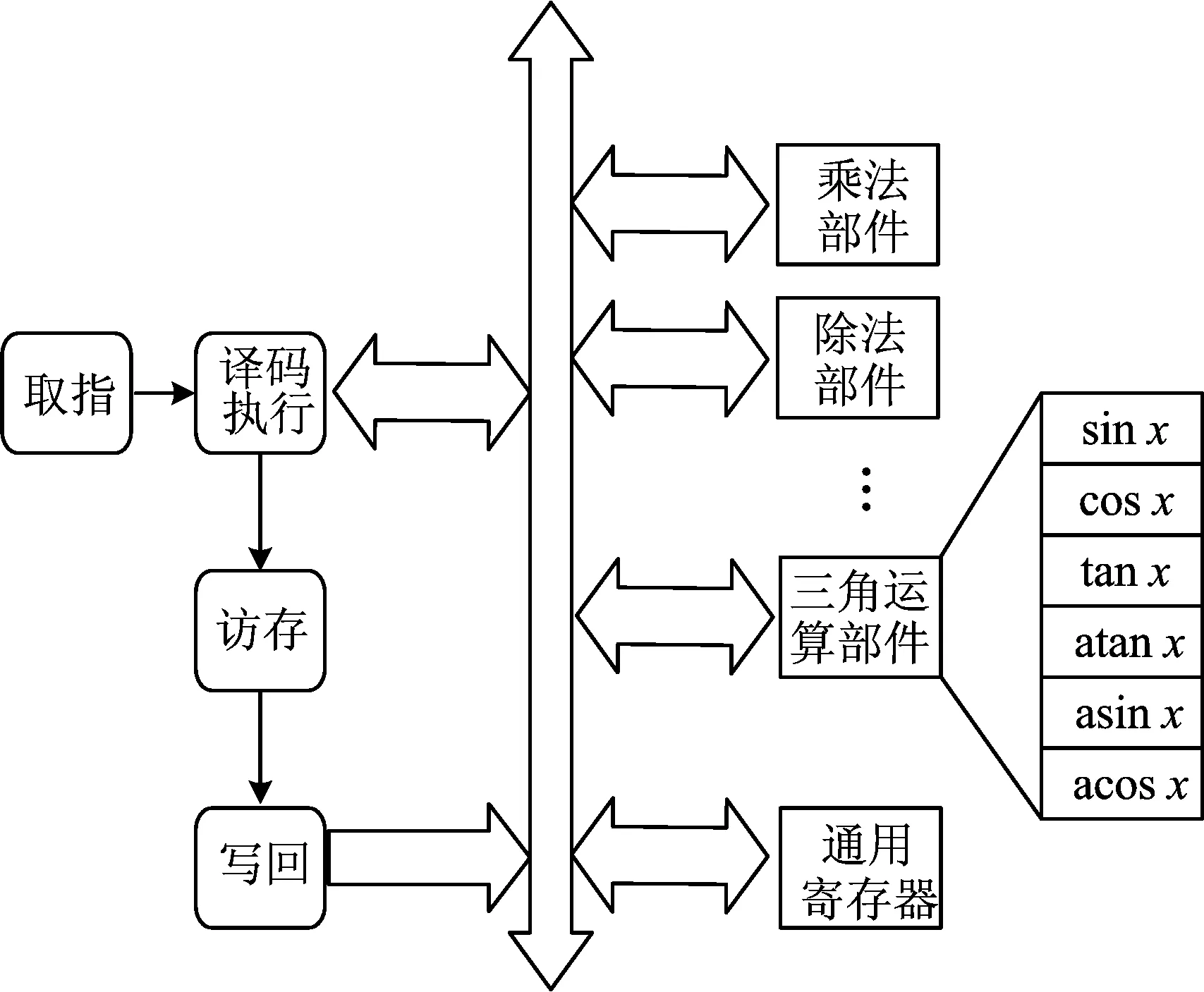
图1 处理器内部结构
2.2 指令集的定义
工程中的处理器采用32位的指令系统,为了使扩展指令能够很好地融入到处理器中,将扩展的指令定义成32位。每部分的具体功能见表1所列。

表1 指令定义格式
31~26 bit用于指示三角函数运算类型,25~21 bit指定源操作数的起始地址,20~16 bit指示本次需要计算操作数的个数,15~11 bit指定运算结果的起始地址,10~0 bit表示功能码。指令中指定源操作数的个数可以有效地降低处理器的取指译码环节的工作量,可以有效地提高处理器的工作效率。
扩展指令的名称、功能以及对应的操作码见表2所列。

表2 指令功能描述
当MIPS32处理器译码得到的指令在表2中,就会启动功能部件计算三角函数值,若干拍之后,功能部件将运算的结果写入到目的寄存器并且通知处理器。功能部件在运算期间,处理器可以处理其他的任务。
当MIPS32处理器译码得到的是其他指令,则功能部件不进行运算,功能部件中的所有寄存器将维持之前的值。
扩展指令不能直接对外部存储器进行访问,仅支持寄存器寻址方式。待计算的角度值存储在外部存储器中,首先通过MIPS32处理器现有的访存指令将待计算的值存在内部通用寄存器中,然后使用扩展指令,功能部件运算的结果存储在目的寄存器中。
2.3 数据运算部件
数据运算部件读取源寄存器中待测的角度值,并根据处理器传输过来的控制信号进行运算,计算完成后,将数据写到目的寄存器中,供处理器读取。
具体运算过程如图2所示。
图2中,输入缓存单元用来存储待计算的角度值,为数据运算部件提供数据输入。因为CORDIC算法对待测的角度有范围限制,只能计算第一象限和第四象限的值,所以需要对待计算的角度值进行预处理,如果待计算的角度不在第一象限或者第四象限,通过三角函数诱导公式,将该角度映射到第一象限进行计算,角度映射单元完成的是映射功能。配置寄存器的数据主要是用来控制迭代计算的次数,由用户输入,用户可以根据不同的需求设置不同的数据,达到电路可定制化的需求。

图2 功能部件运算流程
输出缓存单元,用来将计算的结果暂存。计算结果暂存之前,需要根据诱导公式进行换算。具体操作如下:
则
(4)
z=z0-π,
则
(5)
数据运算部件最核心的地方在于迭代计算单元,迭代计算主要根据(1)式进行运算。具体的电路实现如图3所示。
由(1)式可知,一次迭代需要计算3次加法。为了提升速度,图3中硬件电路使用3个加法器同时工作,cmp单元是比较器,用以判断当前迭代的次数是否达到配置寄存器中的值。电路中还包含3个寄存器、2个移位寄存器以及1个只读存储器(ROM)。使用寄存器存储每次迭代的结果,移位寄存器根据(1)式从寄存器中选择特定的位数据,将数据传入到加法器中进行下一次的迭代计算。只读存储器ROM预先存储每次迭代的角度值。

图3 迭代运算单元的电路实现图
运算部件工作的具体步骤如下:
(1) 处理器从存储器中取出指令,译码得到扩展指令,从寄存器中取源操作数并传输给输入缓存单元。同时,处理器发出控制信号,启动运算部件。
(2) 源操作数进入Z寄存器,同时X寄存器和y寄存器赋值初始值。
(3) 迭代运算,X寄存器和Y寄存器的特定位进行加法运算,Y寄存器和X寄存器的特定位进行加法运算,Z寄存器与只读存储器ROM中的第1个数据进行加法运算。
(4) 将3个加法器运算的结果送回到对应的寄存器。
(5) 当迭代次数不足时,转步骤(3),否则,将运算结果写入目的寄存器。
(6) 功能部件发出信号,通知处理器取数据。
3 仿真验证
3.1 精度分析
为了验证功能部件计算结果的准确性,以正弦函数为例,在区间[0,2π]之间以0.000 3 rad为步长,取20 930个测试点,利用VCS2016工具进行仿真,将仿真的结果导出与Matlab软件运算得到的标准值进行比较,统计的相对误差如图4所示。
从图4可以看出,使用专用指令计算三角函数得到的结果,误差的最大值不超过10-7,并且大部分数据的误差维持在10-8以下。为了更直观地说明本文设计结构的优越性,本文将三角函数的运算结果与文献[7]进行对比,可以看出本文设计计算的结果更加准确,见表3所列。

图4 正弦函数值相对误差统计值

表3 本文结果与文献[7]结果对比
3.2 性能评估
运算单元的物理性能评估结果见表4所列。

表4 性能评估结果对比
从表4可以看出,文献[8]中的设计最大工作频率仅只有282 MHz,本文的系统频率可达1 GHz约是文献[8]的4倍,三角函数运算部件可以匹配频率更高的处理器。本文设计需要462个寄存器,文献[8]则需要1 993个寄存器,相比之下,寄存器个数节省了将近76%。本文设计的电路在不使用M9K的前提下消耗的查找表是文献[8]使用1个M9K消耗查找表的2.5倍,总体而言,本文设计在资源节约方面具有很大的优势。
4 结 论
本文基于40 nm工艺MIPS32商用处理器架构,设计了三角函数功能部件,通过指令扩展的形式,使得处理器和功能部件很好地结合起来。功能部件的时钟频率高达1 GHz,能够适配高频率处理器。为了验证部件运算结果的准确性,将本文结果与Matlab软件运算的结果进行对比,发现计算结果的精度不低于10-7。和已有的电路结构进行比较,本文的设计具有频率高、结果准确、寄存器资源消耗少等优势。在数字信号的处理中,会涉及到大量的数学运算,进一步丰富本系统的指令集来满足更多的数学运算将是以后的研究方向。
