基于深度卷积神经网络的极相似动物纤维自动识别技术
2021-05-25钟跃崎郭腾伟柴新玉
钟跃崎,郭腾伟,路 凯,柴新玉
(1.东华大学 纺织学院, 上海 201620; 2.东华大学 纺织面料技术教育部重点实验室, 上海 201620;3.苏州科达科技股份有限公司, 江苏 苏州 200030; 4.许昌学院 信息工程学院, 河南 许昌 461000;5.文思海辉技术有限公司, 北京 100192)
1 山羊绒和绵羊毛纤维识别研究现状
山羊绒和绵羊毛纤维均属于动物纤维,其外观视觉形态、物理化学性质以及结构组成成分等方面都有很多相似之处,寻找一种能够快速准确地自动鉴别山羊绒、绵羊毛纤维的方法,一直都是纤维鉴别中的挑战。 从原理上而言,目前较为实用的解决方法大致分为3 种。 第1 种是从形态学的角度,第2种是从DNA 的角度,第3 种是从蛋白质组学(proteomics)的角度。
从形态学的角度进行动物纤维的鉴别,主要是通过光学显微镜[1]或者电子显微镜[2]进行纤维外观形态的观察,通过人工识别的方式,从山羊绒和绵羊毛纤维鳞片形状、面积、密度,以及纤维的直径、条干光泽度等方面根据主观经验做出判断。 目前,光学显微镜下的人工鉴别是应用最为广泛的鉴别方法之一[3]。 扫描电子显微镜图像由于放大倍数高,相对光学显微镜图像更为清晰,容易分辨,故识别精度更高,但检测周期长,对设备和制样有特殊的要求。
随着聚合链式反应(Polymerase Chain Reaction,PCR)技术的发展,自2005 年起PCR 体外扩增技术被用于山羊绒和绵羊毛检测,Subramanian 等[4]利用PCR-RFLP(Polymerase Chain Reaction Restriction Fragment Length Polymorphism)扩增技术对提取的羊毛、羊绒线粒体DNA 进行扩增,提出了单核苷酸多态性法(Single Nucleotide Polymorphism, SNP法)。 2014 年,Tang 等[5]使用荧光PCR 法(TaqMan PCR)对绵羊毛和山羊绒混合物DNA 定量分析,证实了根据线粒体DNA 鉴别羊绒羊毛的可靠性。GB/T 36433—2018《纺织品 山羊绒和绵羊毛的混合物DNA 定量分析 荧光PCR 法》于2019 年1 月1 日起开始实施。
但是,纤维条干中几乎不含核DNA,只含有很少量的线粒体DNA,并且纤维存放时间较长,易于使DNA 发生降解,提取DNA 困难,给鉴别造成很大困难[6]。 而羊绒、羊毛纤维中的蛋白质含量很高,便于提取[7],因此可以从蛋白质组学的角度解决山羊绒、绵羊毛的鉴别问题。 如采用质谱谱图特征(谱峰的强度, 质/荷比和出峰的时间)、肽的特征(来源相同肽离子的质量同位素峰)、或肽(相同肽不同电荷状态的多个肽特征)来表示[8]。 特别是近年来广泛用于蛋白质、多肽、核酸和多糖等大分子研究领域[9]的基质辅助激光解吸电离飞行时间质谱技术,吸引了越来越多的关注[10-12]。
然而,上述技术在实现无人工干预的全自动实时检测方面均难以胜任。 事实上,形态学检测所提供的信息,利用机器学习的手段,是最有可能实现实时检测的。 Wu 等[13]收集了5 种不同产地的山羊绒,使用近红外光谱分析技术获得相应的光谱数据以及主成分分析(PCA)降维,再通过支持向量机对产地进行分类。 季益萍等[14]通过3 种不同的决策树模型,对纤维细度、鳞片高度等特征进行数据的分类预测。 沈巍等[15]利用了支持向量机法进行山羊绒、绵羊毛混纺比研究。 Zhong 等[16]提出了一种将山羊绒、绵羊毛纤维显微镜图像转换为投影曲线,然后提取投影曲线特征间接识别山羊绒、绵羊毛的算法。 路凯等[17-18]也提供了基于词典模型和空间金字塔匹配对山羊绒、绵羊毛光学显微镜图像进行识别的算法。
上述方法有2 个共同点,一是纤维的形态学特征往往来自于人为设定(Hand Crafted Features),二是所用样本空间的容量有限,模型的泛化能力不强。事实上,随着深度学习技术的进步,已经可以通过深度神经网络,在更大的样本容量上,实现泛化性能更好的多品种极相似动物纤维的全自动识别。
2 试样准备与图像采集
本文使用了蒙古青羊绒、蒙古紫羊绒、国产青羊绒、国产白羊绒、普通羊毛(美利奴)和土种羊毛共计6 种纤维进行测试。 按照GB/T 16988—2013《特种动物纤维与绵羊毛混合物含量的测定》,使用哈氏切片器从纤维样本中部切取长度为0.4 ~0.6 mm的纤维片段进行制样。 将制作好的切片放置在光学显微镜载物台上,物镜放大40 倍,目镜放大10 倍,图片保存格式为TIFF 格式,图片大小为640×480 像素。 在整个过程中只对单根纤维的图像拍摄保存,因为多根纤维同时出现在视野中会交叉造成多焦面现象(1 根纤维清晰,另外其他纤维模糊)无法进行判断。 分别采集了国产青羊绒10 181 张,土种羊毛9 929 张, 普 通 毛 条10 007 张, 蒙 古 青 羊 绒10 093 张,国 产 白 羊 绒10 017 张, 蒙 古 紫 羊 绒10 836 张,合计61 063 张纤维图片,6 种纤维光学显微镜图像示例如图1 所示。

图1 6 种纤维光学显微镜图像示例
由于深度神经网络需要在大样本数据集上进行训练,才能获得比较好的泛化性能,因此在图像数据量不足的情况下, 可使用数据增广( Data Augmentation),一方面能够扩充样本的数据量,增加训练集中样本的多样性,另一方面在一定程度上缓解过拟合现象带来模型泛化性能的恶化。
常用的数据增广技术有随机翻转、随机旋转、随机裁剪,改变图像对比度和亮度等。 鉴于本文实验所用的60 000 余张样本图像,在实践中使用随机水平翻转、随机垂直翻转和图像对比度改变这3 种策略。 需要注意的是,不推荐采用随机裁剪的方式,因为这种方法处理后的图片有可能均为背景,不存在纤维样本,不利于神经网络训练。
实验所用计算机硬件配置如下:CPU 为Intel i7-3 770 K@3.50 GHz×8,内存大小为8 GB,显卡为NVIDIA GeForce GTX1070。 操作系统为Ubuntu 16.04TLS,本文相关代码使用PyTorch 深度学习框架编写。 在训练时,共训练24 个轮次(epoch),并采用分段函数式的学习率衰减模式,即在训练过程每训练7 个轮次(epoch),学习率降为原来的1/10。在网络参数的优化方面,选取Adam 和Momentum这2 种优化方式。
3 神经网络的筛选与验证
仔细观察图1 不难发现,相对于常规图像分类任务所面对的风景、车辆或行人等彩色图像,纤维的光学显微镜图像内容较为简单,因此不宜采用参数数量太多且过于复杂的深度神经网络。 另外,在训练神经网络之前,需要对参数的初始化方式进行设置,通常有下述3 个方案可供选择。
方案1:从零开始,在前述纤维显微图像数据集上进行深度神经网络模型的训练。 鉴于神经网络参数矩阵初始值的设定能够影响训练过程收敛与否,以及最终是否能够训练出理想的实验结果。 故此在实验过程中,对网络中的全连接层采用Xavier 初始化[19]。 令nin和nout分别为某层神经网络输入和输出的神经元个数,Xavier 初始化旨在维持输入和输出数据分布在方差层面的一致性,
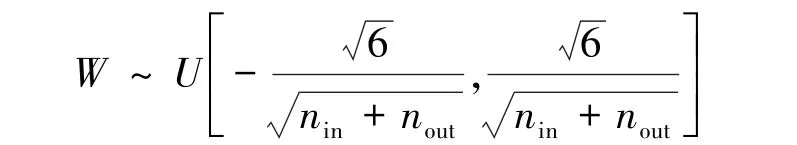

方案2:将所选择的神经网络先在一个更大规模的数据集上完成预训练,然后通过迁移学习的方法,在本文的数据集上完成权重矩阵的微调,达到更好的识别精度。 这是因为人类面对新的任务时,往往也是优先使用过往经验和知识,然后再针对新任务进行改良优化,并非总是从零开始重新学习。
本文采用在ImageNet 上训练过的不同卷积神经网络模型的参数作为神经网络参数矩阵的初始值。 这是因为ImageNet 中拥有1 000 个类别、上百万张图像,在规模上和复杂度上相对于本文的数据集更有优势。 基于ImageNet 训练的模型往往具有非常强的广义图像视觉特征表达能力,从而在某种程度上能够加快纤维识别模型的收敛速度,增强模型的泛化能力。
鉴于ImageNet 有1 000 个类别,而本文所用数据集只有6 个类别,故全连接层采用Xavier 初始化。完成了初始化之后,网络中所有参数在整个训练过程中都会随着训练过程中的梯度下降而得到更新。
方案3: 将所有卷积层均初始化为经过ImageNet 上预训练的参数矩阵并固定不变,在训练过程中仅更新全连接层中的权重参数。
以ResNet18 为例,在山羊绒、绵羊毛分类任务中测试了3 种方案的表现,结果如图2 所示。 很显然,方案2 的表现最好,而方案3 只有不到70%的准确率,这说明基于ImageNet 预训练的图像特征不能表达山羊绒、绵羊毛纤维图像特征,必须通过ResNet18 网络卷积层训练更新优化后才能产生具有自动提取山羊绒、绵羊毛图像特征的能力,并通过全连接层进行分类识别。 同时,在测试集上,方案2的准确率超过方案1 的15%以上,说明该方法比从零开始的训练更适合纤维图像的识别任务。
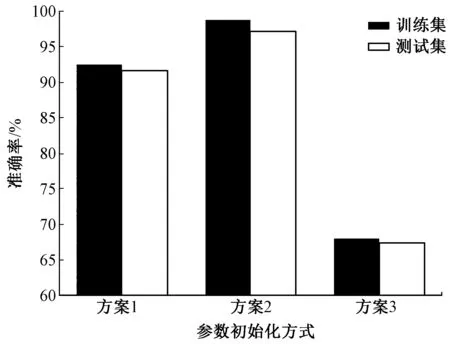
图2 3 种不同初始化方案训练集和测试集准确率
有鉴于此,在后续的实验中,本文使用了VGG11、VGG13、VGG16、InceptionV3、InceptionV4、ResNet18、ResNet34 和ResNet50 共8 种网络模型进行对比,采用方案2 进行参数初始化。 多种模型准确率结果如图3、4 所示。
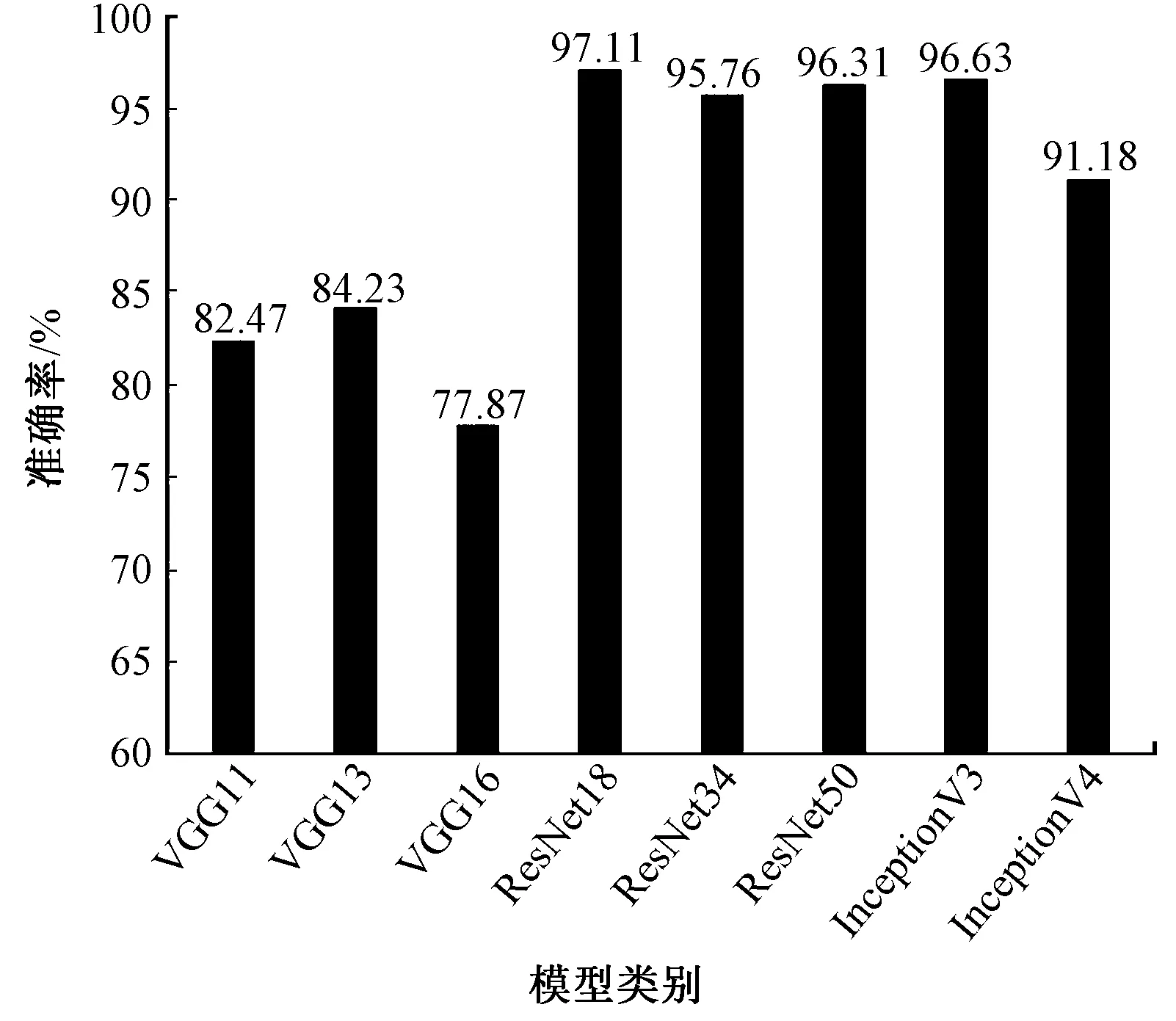
图3 8 种模型使用Adam 优化器测试集下的准确率

图4 8 种模型使用Momentum 优化器测试集下的准确率
由实验结果可以发现,ResNet18 在Adam 优化器下测试集准确率达到了最高,原因有二:①相对其他非残差类型神经网络,ResNet 引入了残差跳跃结构,使梯度的流动更为健康,即不会出现梯度消失和爆炸的问题,从而使得优化效果良好,准确率得到了较 大 提 升。 ② 对 比 ResNet34, ResNet50,InceptionV3,InceptionV4,在山羊绒、绵羊毛识别问题中,由于样本类别只有2 种,且图像本身较为简单。 若将深度神经网络看作一个非线性拟合函数,其所需的参数无需非常庞大,故ResNet18 恰好满足了够用的基本要求。 而其他网络模型与之相比,参数更多,容易因参数冗余而造成过拟合现象,故而在测试集上的表现不及ResNet18。
此外,即使在准确率接近的场合中,也会优先选择ResNet18。 因为其无论在训练时还是在测试时速度更快,用时更少,更加高效,便于实用阶段的部署。 另外从图3 中可知,VGG 网络在使用Adam 优化器时效果较差,故此不建议使用Adam 算法对其进行优化。
为进一步了解各种网络的性能,对训练和测试过程中的总耗时进行了测算,如表1、2 所示。
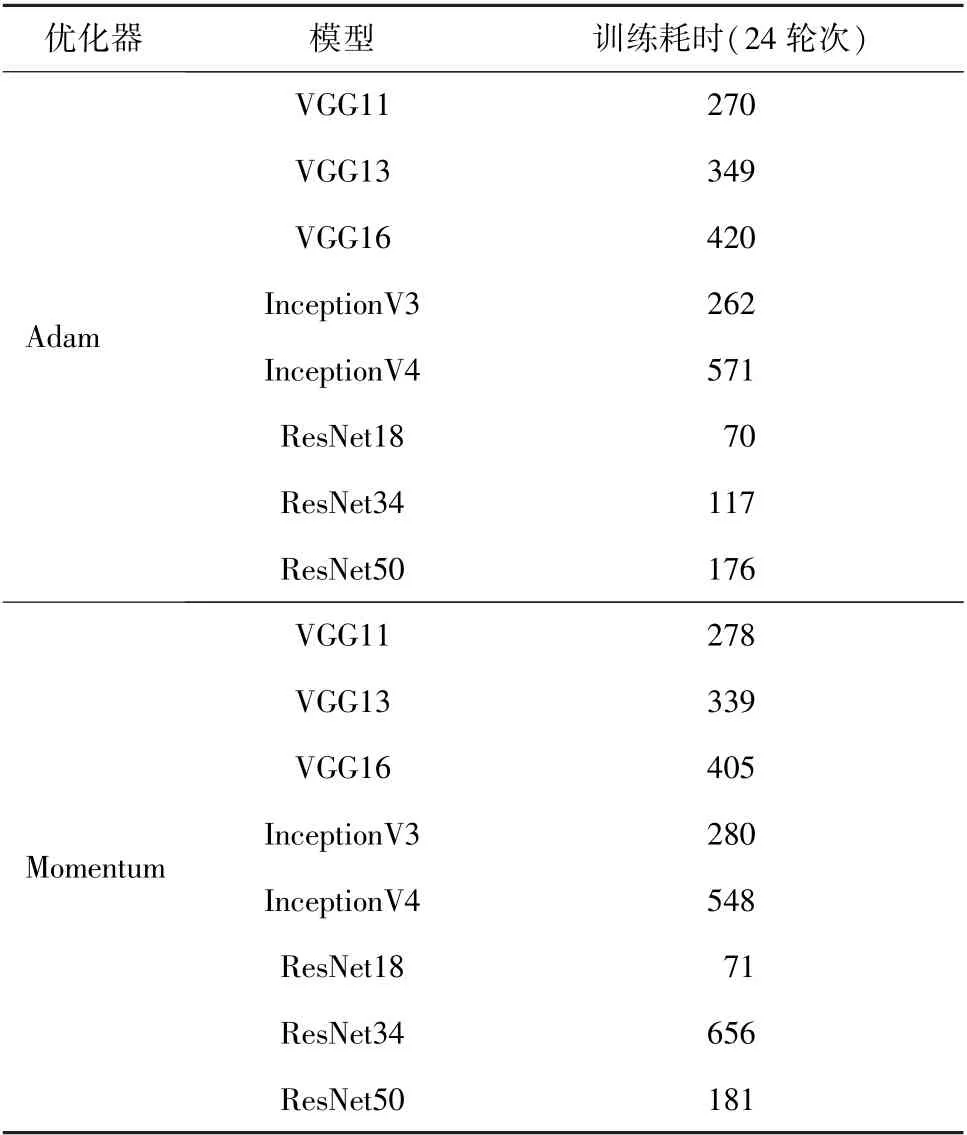
表1 8 种模型不同优化器训练过程总耗时 min
可以看到,ResNet18 网络模型在训练过程中耗时最少,相比InceptionV4 少了420 min 左右,效率大幅提升。 在实际测试时,对6 000 张测试集上的图片进行自动鉴别,耗时均不到1 min,等于每秒钟可以检测至少100 张图片,足以将基于深度神经网络的山羊绒、绵羊毛图像识别流程用于实时检测。

表2 8 种模型不同优化器在6 000 张测试集图片上总耗时s
为进一步验证ResNet18 模型的性能,给出了6 种动物纤维在测试集上识别准确率的混淆矩阵分析,如图5 所示。 混淆矩阵又称为误差矩阵,是一种较为高效评估有监督学习目标分类准确率的工具。通过混淆矩阵可以将数据的真实值与通过模型预测的结果进行对比。 由于这里的分类数目为6,故混淆矩阵大小为6×6。 其中每行代表实际纤维归属类别,每行的总数之和表示测试集中每类纤维的总根数;每列代表通过ResNet18 得出的预测值,每列的总数之和表示预测为该类别纤维的总根数;混淆矩阵对角线上的数字表示正确判断为各个纤维类别的数量根数。
本文使用召回率表示每种纤维是否容易被神经网络区分。 召回率是指每种纤维类别预测正确数量根数占该类实际总根数的百分比值。 召回率越大代表该类别纤维越容易被区分,反之,越难被识别出来也就是越容易被错识别为其他纤维类别。 从混淆矩阵图中可以看出普通毛条和蒙古紫绒非常容易被ResNet18 识别,其召回率高达99.8%和98.5%,其次是土种羊毛,为97.7%。 而国产白羊绒、国产青羊绒和蒙古青羊绒最难被识别,召回率分别是95.2%、95.5%和96.0%。 换言之,对ResNet18 而言,羊毛“冒充”羊绒是比较容易被识别出来的,而蒙古紫羊绒容易被识别是因为其纤维呈现深色,具有比较明显的区分度。 从图5 中还可以发现蒙古青羊绒和国产青羊绒互相被错分较多,这与实际情况相吻合,根据颜色类别条件划分,他们都是属于青羊绒,在物种属性上也更为相近,因此互相区分度更小,被识别错误较多。

图5 6 种动物纤维测试集混淆矩阵分析图
在ResNet18 网络中,最后一个卷积层输出的特征图(feature map)大小为512×7×7,意味着512 个7×7 的特征图。 根据ResNet 的工作原理,在进入Softmax 层进行分类之前,需要先对7×7 的特征图进行全局平均池化,输出1×1 的特征图。 因为最终分类结果实质上是经过池化后的512 个值与相应的权重的乘积,所以实际上也是7×7 的特征图与权重的乘积。 这里的权重代表了每个7×7 特征图对最终分类结果的贡献程度。 根据这一原理,可利用这512 个特征图乘以对应权重进行求和得到一个新的7×7 的权重特征图,这个权重特征图上每个像素值对应了其对分类结果的影响程度,结果越大代表影响程度越大,最后将该权重特征图映射到大小为224×224 的原图中,就可以直观地看出哪个区域对分类效果影响更大。
图6 所示热力图中,红色代表该处的特征对最终识别的贡献较大,蓝色代表贡献较小。 通过图6(e)(f),可见大部分红色区域都在纤维条干上拍摄较为清晰的部分,说明ResNet18 网络的识别过程较好的模拟了人类识别,自动“注意”到了整幅图像中特征明显的区域,并以此作为判断的依据。 这也是深度学习拥有人工智能特色的原因所在。

图6 国产白羊绒和国产青羊绒及其热力图
4 结束语
本文对不同卷积神经网络模型在自建的6 类别山羊绒/绵羊毛图像数据集上进行了训练和测试,发现ResNet18 通过加载在ImageNet 上预训练的网络参数进行迁移学习时效果最佳。 通过混淆矩阵,说明了本文所提出的方法在6 种极相似动物纤维的鉴别中,鉴别准确率均在95%以上,且泛化性能良好,可用于实时自动检测。
由于在使用光学显微镜的真实检测环境中,载玻片上通常是多根纤维混搭,此时除了分类任务之外,还需给出具体聚焦清晰的纤维所在位置以判断根数, 因此整个任务变为了目标检测(object detection),未来可在训练集完备的情况下,采用相关目标检测网络(如YOLO V4[21])开发更贴近实用的自动检测系统。
此外,由于深度神经网络的训练离不开标注良好的图像数据,而目前的数据标注均需人工参与。因此,该类方法在极相似纤维鉴别领域,不会超越人类的表现。 这也是为什么用该类方法,很难识别且肉眼也难以直接识别的黑色牦牛绒冒充黑色羊绒(细度、长度、色泽均相同的前提下),或者回用羊绒冒充纯新羊绒的情况。
