基于机器学习的肺癌生存预测模型研究
2021-05-25王婧
王 婧
(淮北师范大学 计算机与技术科学学院,安徽 淮北 235000)
全球范围内,肺癌是所有癌症中发病率和死亡率最高的癌症。近年来,我国肺癌的发病率和死亡率呈明显上升趋势[1]。为了尽可能掌握疾病的原理,预测并提升病人的生存能力,研究员们通过胸部X光、计算机断层扫描、病历等材料出发进行研究。
生存预测作为热门研究方向,一直有不同领域的学者对其进行研究,最初常利用Cox模型发现规律[2-3],也有部分是基于优化方法进行研究,文献[4]使用微分表达式来选择数据的特征,在训练初期使用排序算法选择筛选对预测结果有效的特征,该筛选在提高预测准确性的同时,也减少了后续模型的计算时间。但是计算复杂度非常高,里面有大量涉及精确优化步骤,只适合少量样本的学习。近年来机器学习方法以较高的预测精确度、较快的运算速度等优势逐渐成为主流方法之一。Jose F. Velez-Serrano等人[5]关注胰腺切除术后生存情况,通过医学知识来提取人口学特征、医院容量、诊断相关死亡编码和切除手术类型等参数建立boost模型,达到了91.6%的预测精度。
采用机器学习方法进行生存预测研究的主要难点有两个,第一是经典机器学习方法无法察觉不均衡数据中少量样本的特征,比如文献[6]通过利用聚类法来发觉较少的类别并对其进行欠采样处理。但是算法发挥不稳定,随机性太高;第二是特征对最终的结果影响重大,因此很多研究都集中在特征选取工程上。文献[7-9]旨在从影像中提取癌症图像特征,采用批量选取最优特征的方法,仿真表现该方法平均能提高5个百分点的精确度。文献[10]提出了一种具有Levenberg-Marquardt模型的高阶递归神经网络系统来管理多模态疾病信息,但是该算法的计算复杂度过高,在超过100个样本时,能计算的特征值数量非常小。Azar等人[11]挑战小样本高维度数据,通过训练出大量的二元分类器来实现集成多样性;然后,由Cascade Forest选出重要的特征。极大提高了不均衡数据集中的准确率。文献[12]在原始输入矩阵的基础上生成大量的随机派生特征,然后对中间值以及派生特征值做线性逻辑回归;但是在百万以及以上数量级的数据集上表现不好,在千级以上的数据集中,机器学习的预测精准度比较低,发挥不稳定。
1 模型与方法
临床对于肺癌病人的生存预测大多是基于检查影响或者手术发现来决定的。但是实际情况下,检查图像不能清晰地呈现出肿瘤边界,对肿瘤大小地判断还依赖机器型号和医生经验,并且肿瘤有可能已经在肺部以外形成,相关数据不能体现实际情况。因此本研究综合考虑患者的其他信息,获取SEER数据库中的全部涉及到肺癌患者的数据。
另外,在众多分类器中,随机森林方法具有较好的灵活性,能够捕捉到更多类型的数据,是准确度相对较高、结构简单、解释性强的一个方法。本文基于随机森林(Random Forest, RF)设计批量选择特征的方法。之后将之应用于XGBoost、CATBoost、神经网络等常见模型,仿真验证基于随机森林的混合模型具有更高的精确度。
图1为研究总体框架图。首先是获取数据的阶段。本研究从SEER官方网站中获取全部肺癌病人的数据,选区第七版本的分级数据库。随后观察缺失数据情况,可以发现部分数据的癌症TMN分级的重要临床数据。由于TMN分级是医生决定治疗手段的重要一环,对空白数据做删除处理,得到129683条干净数据。随后对数据进行选取,选取条件为确诊年龄限定在20岁到80岁之间、起始观测年份在2011到2013年,且已经观测到死亡状态的样本。最终得到2011年间观测到的6547个样本、2012年间观测到的6358个样本、2013年间观测到的6252个样本、以及2014年间观测到的6113个样本等四个样本集,然后通过随机森林方法反向筛掉在随机森林中出现次数比较少的样本特征,最后留下来的特征为诊断时期的年龄、性别、人种、所属区域、TMN分级、手术类型、存活时间、观测节时患者的存活状态特征。样本的简要描述在本文第三个部分有详细描述。之后利用其他常用的机器学习方法构建预测模型,得到生存预测结果。
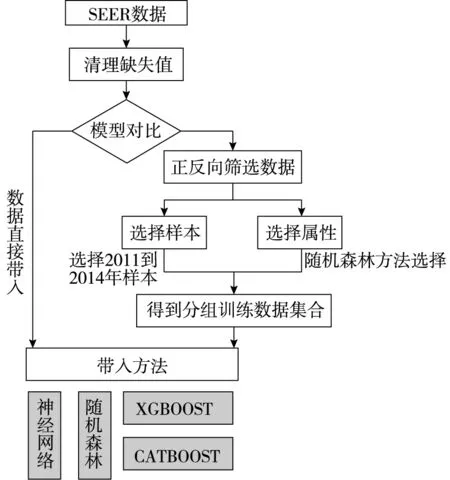
图1 工作流程图
1.1 基于随机森林的特征选取
随机森林算法是一种训练速度快,抗拟合能力比较强的方法,被广泛地应用在数据预处理,分类预测等领域。在构建RF的过程中,单个决策树里的某一节点特征与其他特征相比,能够实现Gini增益的最大化,因此树上的节点特征可以体现其重要性。另外,RF为了增加单颗决策树的差异化,采用双随机的策略,即在采样过程中随机选取样本的范围,并在建立决策树的过程中随机选择特征值集合,这样能够有效地避免对训练集的过拟合。
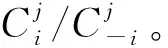
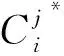
(1)
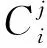
(2)
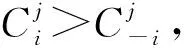
⟹number(Ti)*Cj*≥number(T-i)*Cj
(3)
(4)
(5)
(1)基于OOB方法生成包含N颗决策树的随机森林,其中每颗决策树记为Ti,i≤N。使用投票法获得集成预测结果;
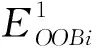
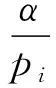
(4)对于特征j的重要性jimp计算为:
(6)
对于上述公式进行分析,当特征j被随机加入与事实有所出入的扰动之后,如果OOB样本的准确率大幅度降低,则说明加入的随机扰动破坏了模型已经习得的规律。如果特征j的jimp值相对其他特征的jimp值更大,即特征j的对模型结论影响更大,此时可以认为jimp能够表达当特征j在当前模型当中的重要程度。实际上,如果特征j对于模型是有利的,那么将第j维特征置换成随机值,将会降低模型的性能,OOB样本误差会变大。本文利用其随机森林模型的特点作为量化每个特征重要性的依据进行特征选择。
1.2 基于XGBoost分类器做生存预测
肿瘤是一个多因素参与、多阶段发展的病症。已经成型的癌细胞的发生异常增殖后侵袭迁移并循环扩散,通过血管完成远端的再生。医学检查无法判断是否完整观测到癌症细胞的发展情况,因此肿瘤数量与大小的计量误差影响因素众多,且呈现非线性相关性。传统的线性模型无法习得非线性的知识。神经网络具有以任意精度逼近非线性函数的优越性能,但是肺癌病人的特征量非常小,样本量比较大,样本内部存在因观测不全导致的相似样本而标签不同的冲突情况。因此神经网络仍然不适合作为本问题的解决方案。
本文选用基于提升树的机器学习系统集成学习算法XGBoost建立预测模型,该模型以良好的过拟合控制机制而著称,具有实现非线性切分能力。设有训练集为{xs,s=1,2,…,S},每条样本包含除标签外的M个特征,标签为ys。XGBoost利用多颗集成决策树的输出,作为最后的预测函数的输入。当对训练集样本xs进行学习时,XGBoost模型可以被表示为:
(7)
其中fn(xs)是第n个树对样本xs预测值,记为wq(x),q:R→T。为了学习模型中使用的函数集合fn(xs),本研究使用如下的最小化正则化目标:
(8)
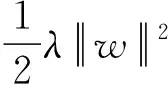
(9)
式中γ和λ是调整参数,控制函数的学习效率,带入到目标函数中并进行二阶泰勒展开,可以推导该公式为:
(10)
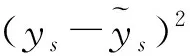
使用贪心的思想,每一次都选取损失函数最小的参数进行构建,则每一次的增益可以计算为:
(11)
(12)
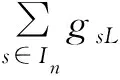
2 数据集样本
首先从国家癌症研究所监测、流行病学和最终结果项目中选取合适肺癌患者样本。缺失情况如图2所示。图中按照数据呈现样式给出缺失值的情况,其中黑色部分代表无缺失数据,白色出现的位置和缺失数据位置一一对应。

图2 样本缺失值分布情况
缺失值过多会直接影响算法的精确度。对于缺失值的处理有两种方法,第一种是删除全部的缺失值,第二种是为缺失值进行赋值。为了做出正确的选择,本文观察缺失数据值之间的关系,发现TMN分期数据是成对缺失的,即缺失完整的分期结论。TMN分期结论是临床检查给出的病程判断,有极大的参考价值,因此对于这部分缺失的数据只能尽数删除。另外值缺失严重的特征regional_node_examined反映了区域节点检查发现的肿瘤状况。由于该特征直接反映样本患者的身体情况,因此对该缺失值做同样的处理。筛选得到38329条干净样本数据集。
随后对干净数据进行正向筛选。首先,为了获得已经观测到正确生存期的患者,筛选已死亡样本;其次,为了避免特殊年龄带来的体制偏差,将确诊年龄限定在在20岁到80岁之间;最后,由于最新版本的数据集对TMN数据的最晚观测时间为2018年,因此在2013年以前确诊的样本观测到的正确存活时间往往小于5年。这样会带来模型方面的数据冲突。比如,下面两个向量分别是2010年和2015年确诊的两个病人的数值化后的样本特征:
[14,71,1,2010,0,0,2,0,341,7,0,4,2,3,8,0,1,0,1,98,0,0,86,0]
[14,71,1,2015,0,0,2,0,341,7,0,8,3,3,8,0,1,0,1,98,0,0,1,1]
上述样本特征加粗了两样本特征值数值不同的元素。最后一个加粗的位置是存活月份。虽然两个诊断年份的样本特征基本相同,但是存活时间差距非常大,这体现了单个样本的数据冲突。另外,总体观察各个年份的存活情况,得到存活数据分布如图3所示。
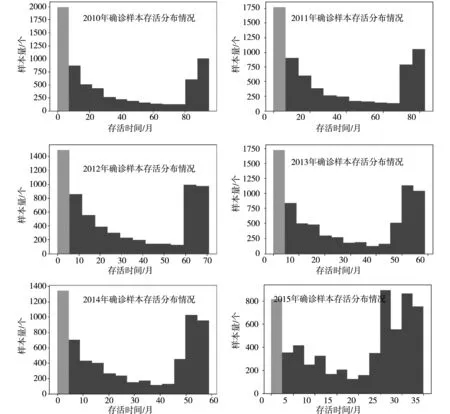
图3 样本分布情况
这种差距是由于2018年未能观测到存活时间超过5年的样本。因此,对该类型的数据进行研究,必须对人为收集数据产生的客观因素误差摒弃掉。因此本研究选取2011至2014年的四年样本进行研究。
正向筛选后共得到25525个样本,样本特征的简要描述如表1所示。
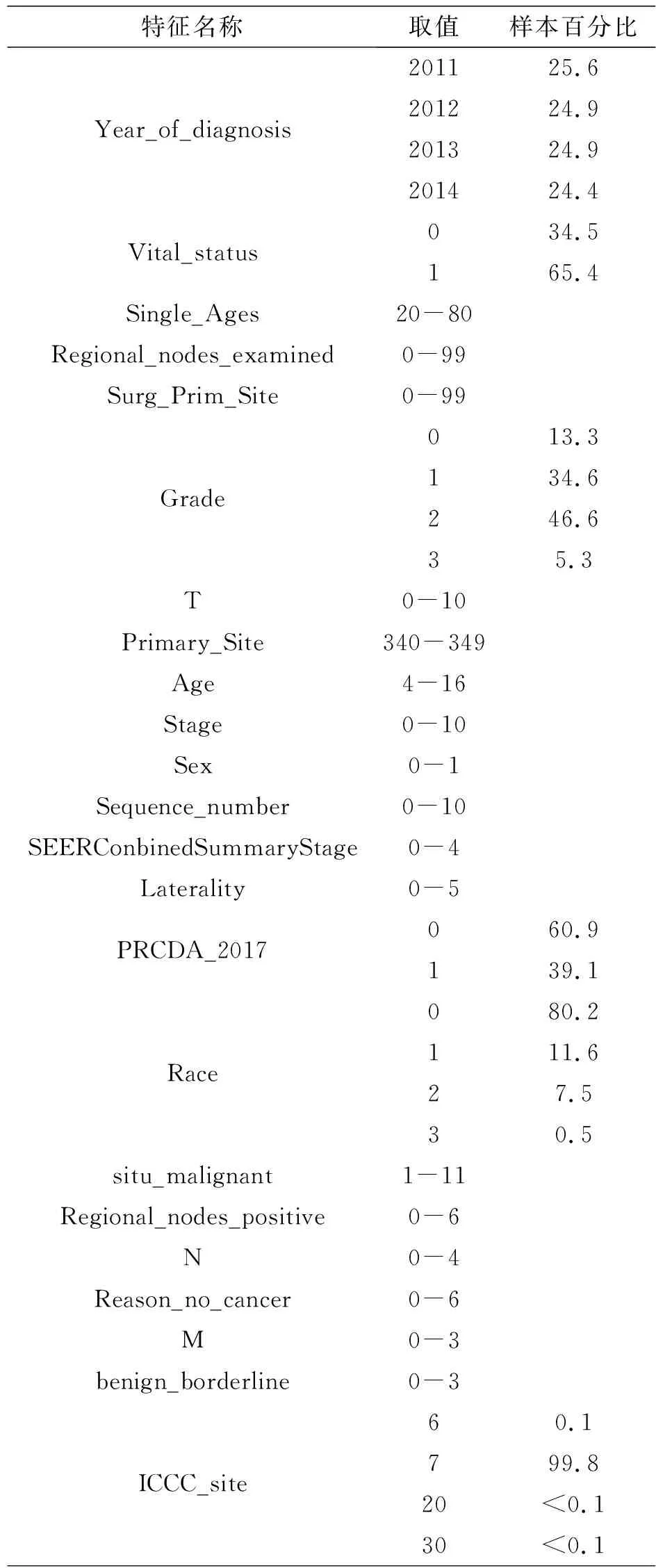
表1 数据集样本特征
表1给出所有样本取值和样本百分比,其中样本取值是分类数字化后的数值。该数据集是一个多因素不均衡数据集。之后利用随机森林预测模型分析所选到的所有特征对于结果的影响力,反向筛选掉影响力为最小的属性,挑选出用于预测存活时间的特征,然后构建XGBoost预测模型以预测患者生存时间。
3 仿真结果
本研究运用Python3.7进行数据处理和分析。从本地SEER库中导入所有和肺癌相关的样本特征,删除掉缺失值后,一共获得了448866个样本,26个样本特征。经过正向选择年份、反向筛选样本特征值后得到38329条数据。针对这些数据根据诊断年份进行分组,在后面仿真过程中将每个样本集按照3:7的比例随机分成测试样本集和训练样本集。
3.1 随机森林选择特征
首先对所有的特征做重要性排序。经过本文提出的策略,最终得到的特征重要性降序排序如表2所示。

表2 特征重要性
根据随机森林方法准则(Akaike Information Criterion,AIC)指标筛选掉最后一个重要性低的编码特征ICCC_site。另外,还可以观察到Jimpor值高的几个特征为生存状态、年龄、观测到的局部肿瘤数量,治疗手段、病理分型结论等。在后续的计算中,可以证明了排名靠前的特征对分类精确度起到了提升作用。
3.2 生存预测分析
首先对2011年、2012年、2013年、2014年四个样本集数据进行直接预测。本文选择了LGBM、MN(神经网络)、NN和RF两者结合(记为NN+NF)等三种算法进行预测。得到如图4所示。
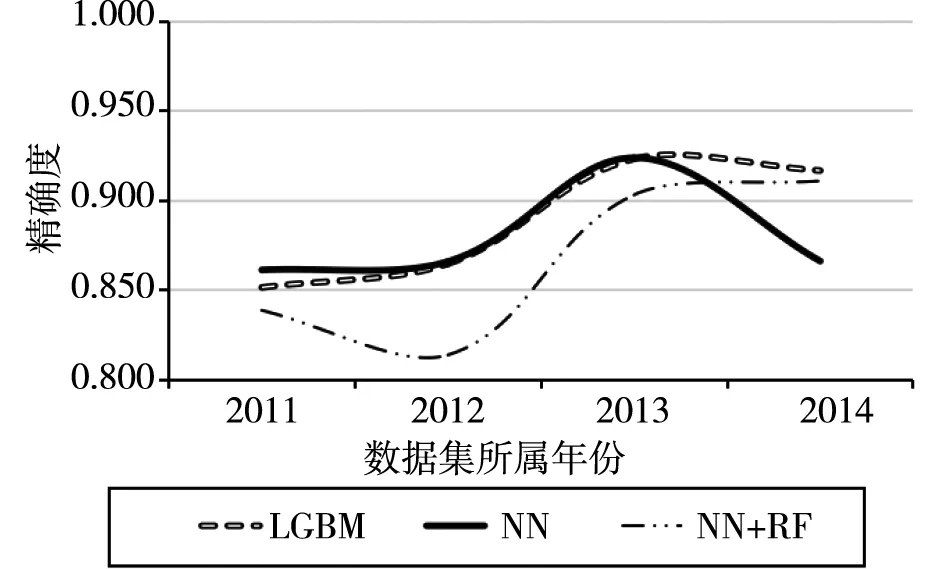
图4 各个经典算法的精确度
本研究采用预测精确度作为最终的评判指标。由上图可以观察到,整体来说RF的预测精度在四个样本集中表现均良好,神经网络算法在2014年数据集上精度较低,NN+RF的融合算法整体精确度偏低。
随后根据表2对数据进行分组。由于重要性较高的几个样本的特征值取值范围较大,不适宜用来分组,在此处选取取值范围在0~3的Grade特征进行分组。分组后的精确度显示如图5所示。
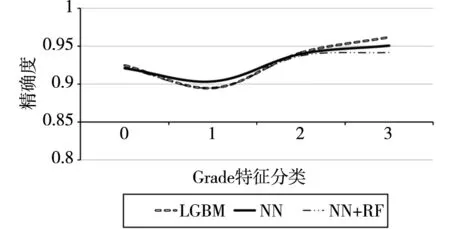
图5 基于Grade特征分类的各算法精确度
由图可观察到,各个算法的精确度都有明显提升,且算法之间的差距缩小。这说明该分组是合理的。在分组的同时,实际上是降低了数据集的规模。为了说明ACI指标的可靠性,本研究选取排名靠后的特征Reason_no_Cancer。该特征取值范围为0~6,对特征值分组后计算其精确度如图6所示。
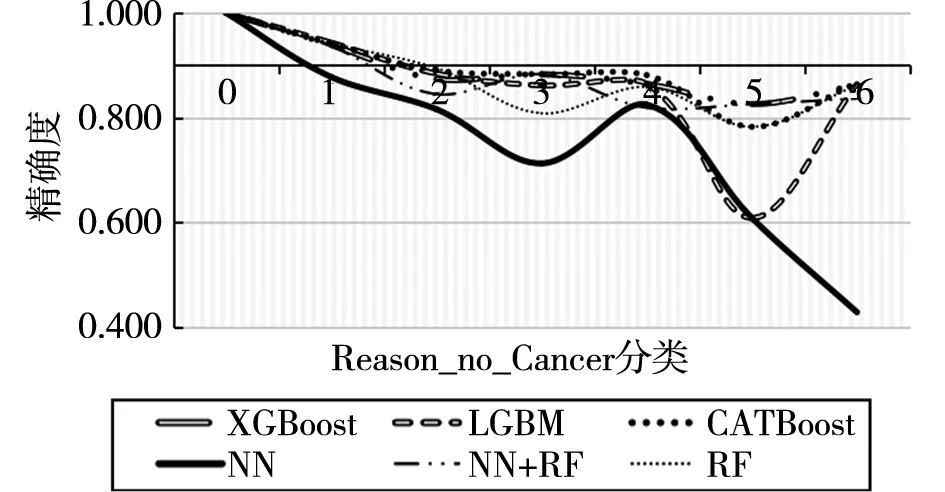
图6 基于Reason_no_Cancer的各算法精确度
为方便对比,图6同样在精确度为90%处画出横坐标,并使用同样的样本量和更多算法(添加了XGboost、CATBoost、RF等四个算法)进行计算。可观察到整体精确度低于基于Grade进行特征分类的算法精度。虽然其中不乏存在样本分布的区别,但是两张图中所有使用的数据量是一致的。图6出现在第一个数据集上所有算法预测精度为1,这是因为第一类的样本集中只有61条数据。另外RF+NN的组合方式对这类数据的分类效果最佳。综合所有算法所用集合和精确度,根据ACI准则对样本进行处理可以极大地提高算法的稳定性和精确度。
结语
在临床经验中,要做好肺癌的生存预测,需要准确地找出影响因素。患者目前的健康状况,身体素质,家庭情况、是否缴纳保险等众多特征值都是医生在信息收集过程中的重点关注对象。从中挑选初有利用价值的数据对于传统临床诊断有很大的指导意义,相似的临床数据可以为患者提供有力的数据经验支持。
