基于多模态特征融合的自主驾驶车辆低辨识目标检测方法
2021-05-19殷国栋刘昊吉耿可可黄文涵薛宏伟
邹 伟 殷国栋 刘昊吉 耿可可 黄文涵 吴 愿 薛宏伟
东南大学机械工程学院,南京,211189
0 引言
实时有效的环境感知是自主驾驶车辆安全行驶的前提和基础。目前,国内外研究者应用深度学习技术在车道、车辆、 行人、标识感知识别方面做了大量工作,识别率和实时性也获得了极大的提高,尤其很多针对理想环境下的行人和车辆的目标检测算法[1-6]受到广泛关注。但大量的研究工作以理想环境为背景,缺乏针对复杂环境下特征不明显的低辨识目标检测算法研究。自主驾驶车辆在真实场景下行驶的过程中不可避免地会遇到各种复杂环境,尤其是雨雪天、夜间等环境下目标特征不明显,各种传感器会受到很大的影响,此时由具有特定特征的图像训练得到的模型将不能很好地识别出低辨识目标。
近年来,计算机视觉领域的学者也初步开展了复杂环境下目标智能识别方法的研究,尤其在多模态图像的融合和辨识方面提出了很多富有创新性的想法。SIMON等[7]使用卷积神经网络( convolutional neural network, CNN)融合彩色图像、深度图、红外图像实现对人脸的检测,实验结果表明,相比单模态检测方法,多模态的融合方法极大地提高了识别的准确率。ZHOU等[8]提出了一种新颖的夜间视觉增强算法,通过导引滤波器来实现红外图像和彩色图像的融合。另外,许多研究人员试图解决在不利照明条件下行人和车辆检测的问题。GONZALEZ等[9]比较了由彩色图像、红外图像、彩色图像和红外图像组合训练的深度神经网络的性能,结果表明,两种模态的图像结合的方式可以提高行人检测的识别率,尤其是在夜晚的环境条件下,这种提高特别明显,即红外图像可以提高夜间行人的辨识。CAI等[10]提出了一种基于视觉显著性的夜间行人检测算法,该算法使用远红外图像,首先使用基于融合显著性的方法检测包含可疑行人的区域;然后使用支持向量机分类器对行人进行最终分类,与某些现有的行人检测算法相比,该算法在真实的远红外图像数据集上具有更好的检测率和处理速度性能。KONIG等[11]提出了一种基于预先训练的非常深的卷积网络VGG-16的新型多光谱区域建议网络,进一步使用增强决策树分类器来减少该网络的潜在假阳性检测,在KAIST多光谱行人检测基准测试的测试集上,对数平均漏检率为29.83%。XU 等[12]使用一种新颖的交叉模式学习框架来检测不利照明条件下的行人,首先采用深度卷积网络来学习非线性映射,从而对RGB与红外数据之间的关系进行建模,然后将学习得到的特征表示转移到第二深度网络,该第二深度网络接收RGB图像作为输入并输出检测结果,该方法在KAIST多光谱行人数据集和Caltech数据集上表现出色。SAVASTURK等[13]用红外图像中的单眼视觉分析了立体视觉在可见域中的优势,提出了可见光图像和红外图像的组合算法并用于车辆检测,结果表明,在红外图像中对车辆进行额外的检测可以显著提高车辆的检测率。
目前,针对多模态输入的目标检测任务,研究者设计的网络大部分针对不同的模态数据(如RGB-D数据)分别建立了独立的网络来提取不同模态数据的特征[14-15],然后以一定的方式将两个网络得到的结果融合得到最终的输出。上述方法思路很直接,既然有多个模态的数据,则为每个模态的数据构建一个网络,这些网络往往也是利用预训练网络做微调,但是这种方法也面临一些现实的难题,目前很多的多模态数据集(如RGBN-D,RGB-thermal)规模都比较小,而且缺乏大量的人工标注,若要获得与Imagenet一样规模的数据集,则需要耗费大量的时间和人力。
本文构建了用于深度卷积神经训练和测试的多模态数据集MMPVD(multi-modal pedestrain and vehicle dataset),该数据集包含三个模态(彩色、红外、经过偏振片滤镜的彩色)图像对,目标包括行人、轿车、越野车、运输车辆。建立的多模态数据集在模态数量、规模、数据质量(图像配准精度、图像清晰度)、目标类型及环境复杂度上均超过当前公开的双模态数据集KAIST[16]。基于Faster R-CNN算法[17]设计了双模态及三模态目标检测融合算法,融合CNN网络提取彩色图像、偏振图像、红外图像特征,搭建多模态传感器视觉感知平台,实现对复杂环境下特征不明显的低辨识目标的实时且有效的检测,提高多模态目标检测算法在自主驾驶车辆行驶过程中面临不同环境时的鲁棒性和泛化性能。
1 算法介绍
事实证明,相对于传统的检测算法,基于深度CNN网络的目标检测方法无论在检测精度还是在泛化性能等方面都具有无可比拟的优势并且取得了巨大的成功。目前基于CNN网络的目标检测算法主要分为两阶段的目标检测(two-stage detection)和单阶段的目标检测(one-stage detection)。两阶段的目标检测算法以R-CNN系列为代表,发展出Fast R-CNN[18]、Faster R-CNN等性能优越的算法。经典的单阶段的目标检测算法有YOLO[19]系列、SSD[20]、FPN[21]等。单阶段的目标检测算法的优势在于运算速度快,满足实时性要求,但存在正负样本比例失衡问题,检测精度上稍逊于两阶段网络。两阶段网络存在候选框提取操作,检测精度较高,但相对于单阶段网络,两阶段网络检测的速度较慢。本文选取VGG-16深度卷积神经网络作为骨干网络(backbone),对不同模态图像的特性进行提取,将得到的特征图进行卷积融合,基于两阶段的Faster R-CNN算法设计多模态目标检测算法。
1.1 卷积神经网络特征提取
深度学习采用的典型网络结构是卷积神经网络CNN。CNN 在图像目标检测中具有位移不变性、 缩放不变性及其他形式的扭曲不变性[22]。由CNN 的卷积核通过训练数据进行学习,所以在使用 CNN时,避免了人工的特征设计和抽取,隐式地从训练数据中进行特征学习。
图1为CNN的一般架构图,CNN采用卷积层与池化层交替设置,卷积层用于学习输入数据中的特征,池化层用于降低卷积层所学到的特征的维度,用以提高网络的鲁棒性,这样卷积层提取出图像特征,再进行组合形成对图片对象描述的更抽象特征,最后将所有参数归一化到一维数组中形成全连接层,进行目标特征训练或检测。相对于全连接网络,CNN网络最大的特点在于局部连接性和权值共享性。局部连接的方式有效地减少了权值参数的个数;权值共享是指同一个卷积核所连接的权值相同,大大减少了连接权值的个数。卷积层的计算公式为
C=σ(M⊗W+b)
(1)
式中,C为卷积后的矩阵;σ为激活函数;M为图像对应的矩阵;W为卷积核权重;b为偏置项。
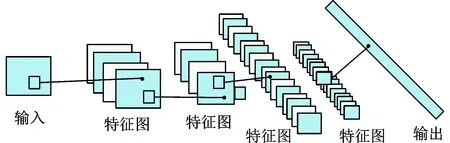
图1 CNN网络结构Fig.1 Network of CNN
1.2 VGG-16特征提取网络
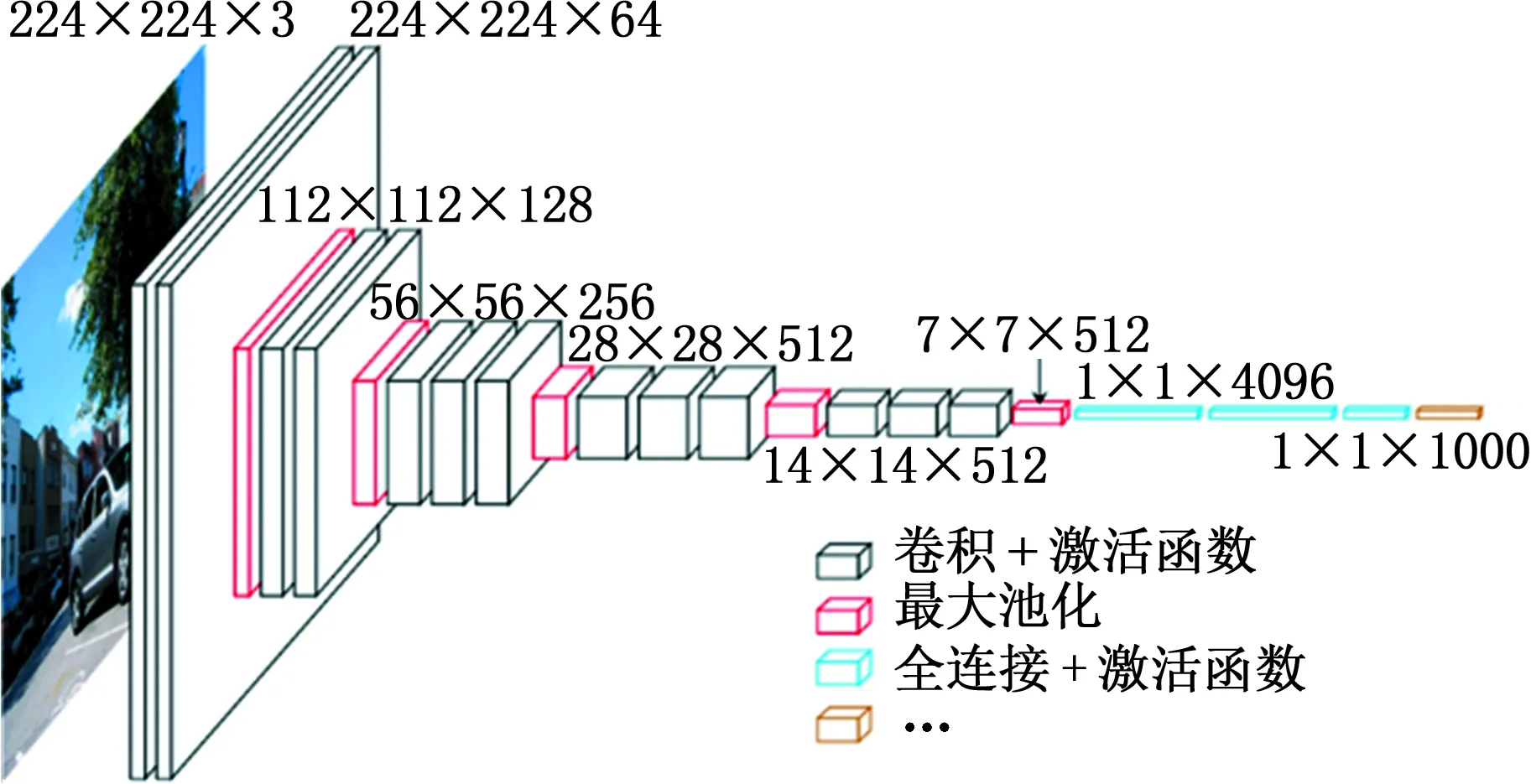
VGG-16的网络结构[23]如图2a所示,进行特征提取时,其输入是一个224×224×3的三维矩阵(表示一个大小为224×224的三通道RGB图像),对输入图像的预处理是从每个像素中减去在训练集上的RGB均值,输出是图像分类的结果(1000种)。VGG-16共有5个卷积块,每个卷积块都包含数次卷积操作,卷积核的大小均为3×3,在卷积之前都进行了填充处理,使得卷积操作不会改变输入输出矩阵大小;而在每个卷积块的最后添加最大池化层,在2×2的像素窗口上进行最大池化,步长为2,每次池化输出特征的长和宽变为输入的1/2。在一维卷积池化操作后是3个全连接层,前2层都是4096维,第3层为1000维的ILSVRC分类,包含1000个输出,每个输出对应一个类别,最后一层为soft-max分类层。
在Faster R-CNN目标检测算法中,使用VGG-16卷积网络的中间层输出,去掉了最后一个池化层,选取第5个卷积块的第3个卷积网络(Conv5/Conv5_3)的输出作为最后得到的特征图。具体的网络结构参数见表1。
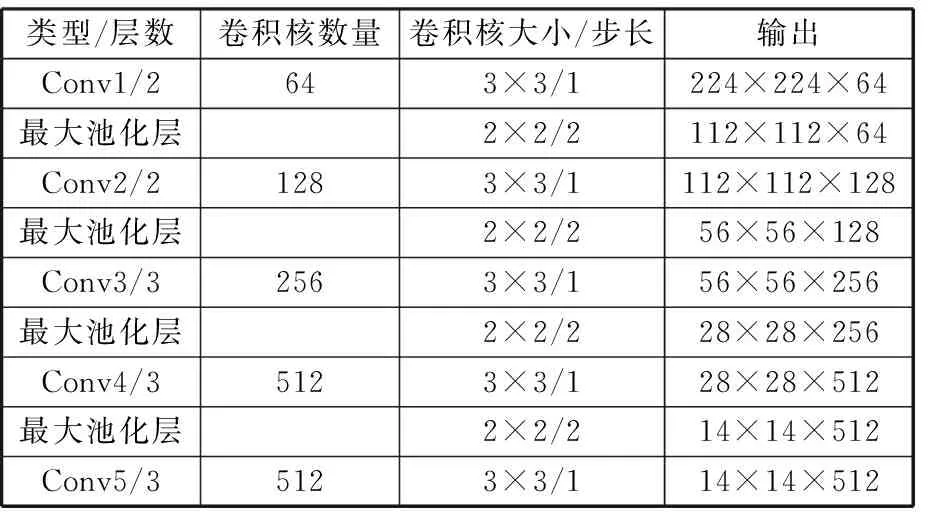
表1 VGG-16网络结构参数
1.3 Faster R-CNN目标检测算法
1.3.1网络结构
Faster R-CNN包括CNN特征提取层、区域建议网络(region proposal network, RPN)、感兴趣区池化层(region of interest pooling, ROI pooling)、决策层(fast R-CNN)四个部分。CNN特征提取层对输入的图像数据经过多次卷积和池化操作进行特征的提取和降维,得到特征图。RPN层提取候选框并对候选框进行初步的回归,将候选框映射到特征图上,由于候选框的尺度不同,对应的候选框的特征的尺度不同,故通过ROI pooling层将每个候选框的特征归化到同样的尺度,方便输送到后面的全连接层,对目标进行分类和边界框的回归。Faster R-CNN网络结构如图2b所示。RPN网络在最后一层卷积特征图上进行候选框的提取,具体方法如图3所示。
(a)VGG-16网络结构[23]
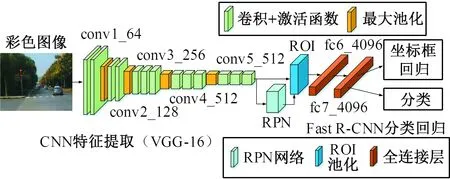
(b)Faster R-CNN网络结构图2 模型网络结构Fig.2 Network structure of models
RPN的核心在于采用锚(anchor)机制,可以理解为将卷积特征图上的每一个点(或对应原图上的某些点)作为锚点,以这些锚点为中心,在每一个锚点上选取m种纵横比、n种尺度、共k个初始的anchor作为候选框,文中m=3,n=3,k=9。对所有的候选框做二分类,判断其为前景或背景的概率,并对这些候选框做简单的边界框初次回归。如此多的候选框中,根据二分类的结果从中选取部分较好的候选框,用以进行后续的运算。

图3 RPN提取候选框示意图Fig.3 RPN making proposal boxes
1.3.2损失函数
Faster R-CNN 包括两部分损失:RPN网络的损失和 Fast R-CNN 网络的损失,其中每个损失又包括分类损失和回归损失[17]。分类损失使用的是交叉熵函数,回归损失使用的是smooth L1 函数。训练RPN网络,给每个anchor分配一个二进制的标签(是否包含前景),正标签的anchor是与任意真实包围盒(ground truth,GT)的交并比(intersection over union, IoU)大于0.7的anchor,负标签的 anchor 是与所有GT的IoU均小于0.3的anchor,剩下的anchor(即与GT的IoU介于0.3~0.7的anchor)不参与RPN网络的训练。本文采用 Fast R-CNN 中的多任务损失最小化目标函数。损失函数定义如下:
(2)
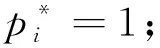
(3)
回归损失计算公式为
(4)
其中,R是Faster R-CNN中定义的鲁棒损失函数,其计算公式为
(5)
本文沿用Faster R-CNN中上述损失函数。
1.4 多模态特征融合算法
1.4.1双模态目标检测算法
基于Faster R-CNN目标检测算法框架,设计了双通道的深度卷积特征提取网络分别提取红外图像和彩色图像特征,选取VGG-16作为骨干(backbone)特征提取网络,双模态目标检测网络结构[24]如图4a所示,网络的输入分别为彩色图像和红外图像,图中虚线框为两个模态的 VGG-16 特征提取网络,分别提取彩色图像特征和红外图像特征。实验证明,相对于传统的单模态目标检测算法,基于双模态特征融合的深度卷积神经网络对复杂环境下的低辨识目标具有更好的检测和识别性能,且在VGG-16的中间阶段将红外图像特征和彩色图像特征融合为最优的方式。
1.4.2多模态目标检测算法
本文基于Faster R-CNN目标检测算法,设计3个通道的深度卷积特征提取网络来融合红外图像、偏振图像和彩色图像特征,选取VGG-16作为骨干(backbone)特征提取网络,三模态目标检测网络结构如图4b所示。
网络的输入分别为彩色图像、偏振图像和红外图像,图4b中虚线框为3个通道的VGG-16特征提取网络,分别提取彩色图像特征、偏振图像和红外图像特征。数据集中存在很多远距离拍摄分辨率较低的目标,像素信息较少,为了提高此类目标的检测性能,去除了VGG-16的最后一个池化层,提高高层特征的分辨率,保留更多图片的细节,防止下采样过度造成小目标丢失。对于多模态目标检测任务,需要解决的最基本问题是如何将多个模态的信息加以融合,以便更好地完成目标检测任务。在深度学习目标检测中,该问题意味着选择合适的层来将多个模态的信息(特征)加以融合。LIU等[15]设计了4种卷积网络融合架构,这些架构在不同的深度神经网络阶段将两分支卷积网络融合在一起,他们在KAIST数据集行人基准测试中的实验结果表明,基于中段卷积特征的中间融合(halfway fusion)模型具有最佳性能,因此,本文采取中间融合方式。
左右模块分别是在VGG-16的第4和第5个卷积块之后将来自不同模态的特征图进行融合的网络示意图见图5。绿色块、浅绿色和橘色块分别表示不同模态的卷积层,得到不同模态图像的卷积特征,黄色表示融合后的网络层,红色虚线框表示融合层。
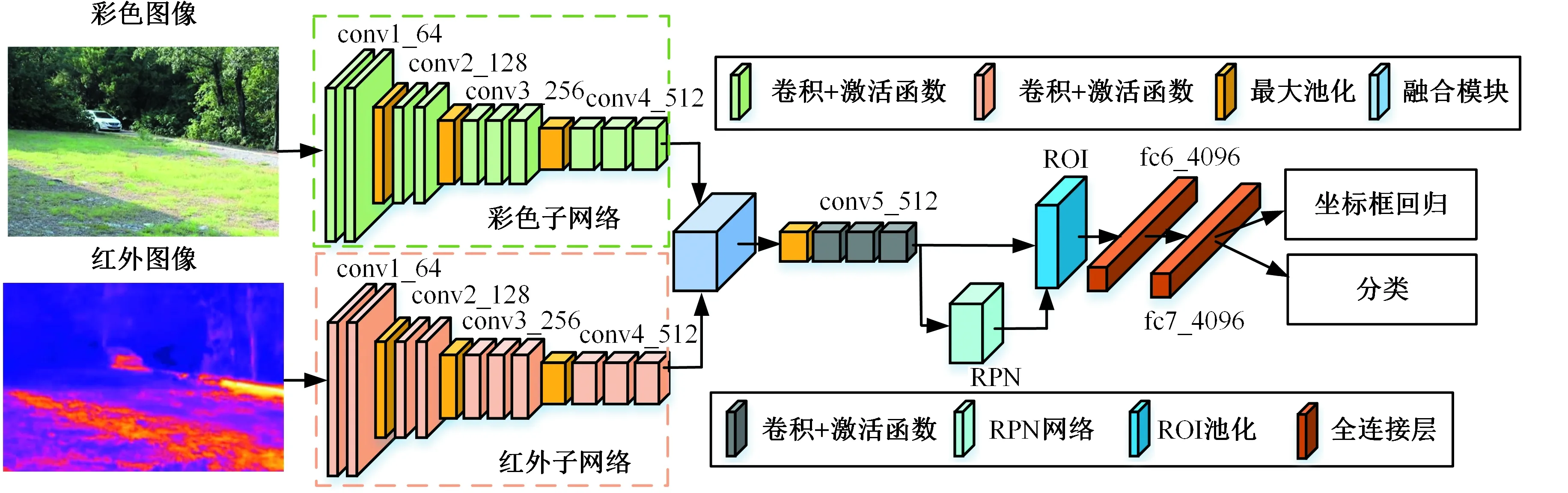
(a)双模态目标检测网络结构[24]
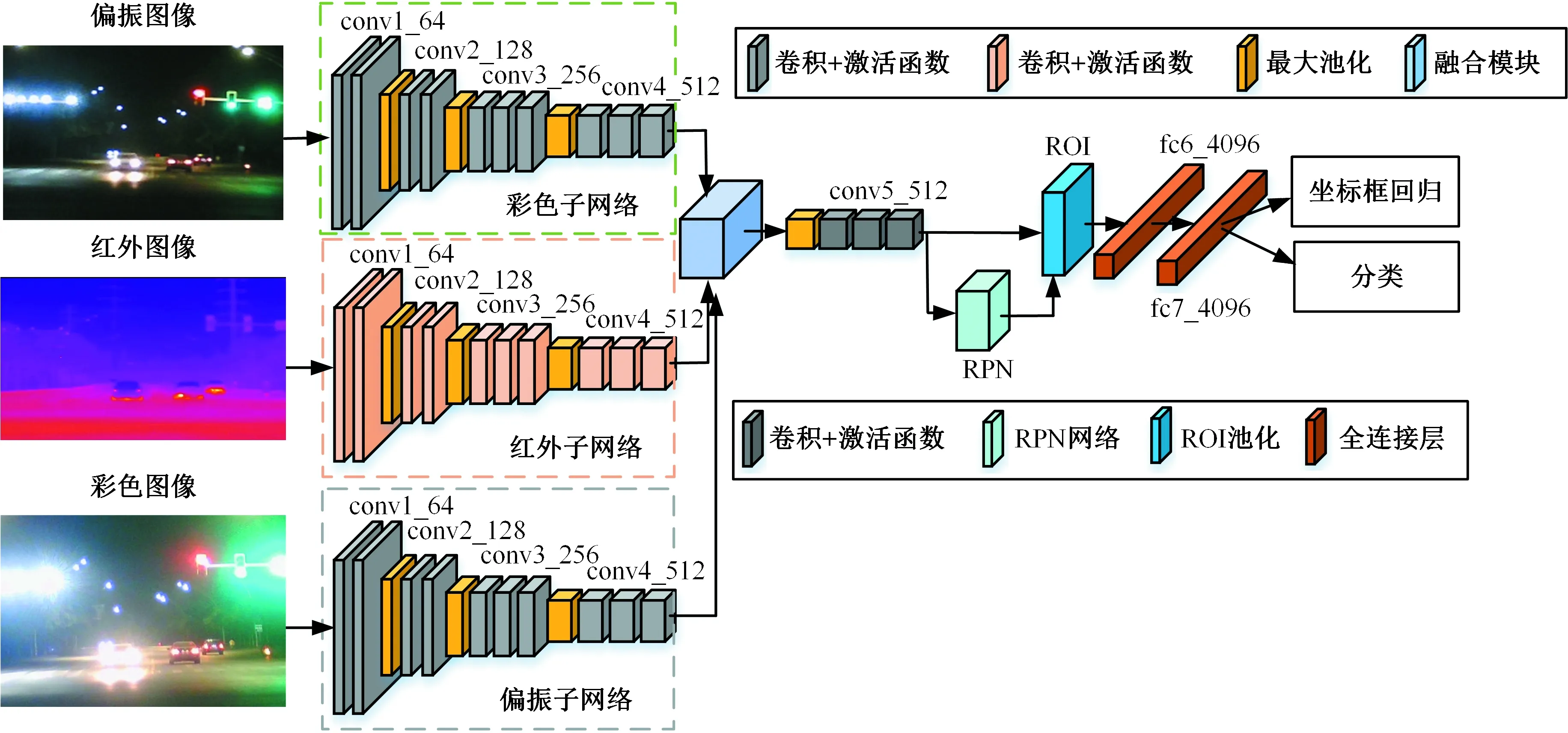
(b)三模态目标检测网络结构图4 多模态目标检测网络结构Fig.4 Structure of multi-modal object detection network
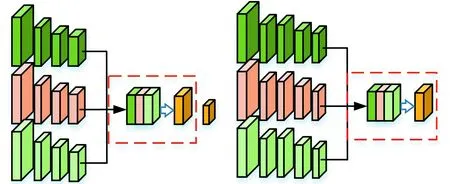
图5 两种融合方式Fig.5 Two fusion methods
融合层的详细结构如图6所示。将来自3个模态的特征图在最后一个维度(通道)进行串接,则原来均为512层的彩色图像特征图、偏振图像特征图和红外图像特征图变为1536层(通道数变为3倍)的堆叠特征图,再通过1×1的卷积核将特征图进行融合并将1536维度降低到原来的512,最后得到512维的融合特征图。本文沿用Faster R-CNN中各部分损失函数,融合层的1×1的卷积核的参数参与模型的训练,融合后的特征图将继续经过后面的RPN层以及ROI池化层,最终到达全连接层,将3个模态的信息逐层传递进行最后的分类和边界框回归。网络训练同样采用反向传播算法,整个网络可以看作由节点构成的计算图,从后向前逐层更新参数。
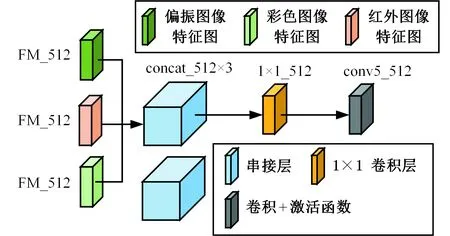
图6 融合层网络结构Fig.6 Structure fusion layer network
多模态目标检测网络配置文件的超参数设置如下:网络训练的学习率为0.001,并在第50 000步迭代之后学习率设置为0.0001;RPN网络部分的锚点横纵比为[1,2,0.5],尺度为[8,16,32];模型训练需要对输入的图像进行标准化,求得RGB图像的像素均值为[85.38,107.37,103.21],红外图像的像素均值为[99.82,53.63,164.85],偏振图像的像素均值为[79.68,88.75,94.55];模型训练采用的优化器为Momentum优化器,动量超参数设置为0.9;模型训练迭代105步。
2 多模态图像数据集的建立
本文构建了彩色图像、偏振图像和红外图像三模态数据集MMPVD(multi-modal pedestrain and vehicle dataset)。多模态图像数据集的图像分辨率为640 pixel×480 pixel,场景包含城市道路、乡村道路和校园场景,目标包括行人、轿车、越野车、运输车辆,环境覆盖晴天、黄昏、夜间、雨天、雾天等不同能见度和照度的天气。
低辨识目标包含被遮挡超过50%以上的目标或在非良好行驶环境条件下的目标。良好行驶环境条件是指良好的照度(大于500lx)和良好的能见度(大于2000 m)。低辨识度数据子集是指在非良好行驶环境条件(如夜间、雨天等)下拍摄的图像数据集。在测试数据集中,目标遮挡率主要为50%~60%,而没有遮挡的遮挡率则为0~10%。
目前已经完成各种环境条件下大约6万对多模态图像的采集,使用公开的标注工具LabelImg完成了其中46 065对热成像-可见光-偏振光图像对的人工标注,共计产生大约134 000个标注结果(图像中可能包含多个行人和不同车辆种类目标)。其中,70%的数据作为训练集,30%的数据作为测试集。图像数据分布统计见表2。MMPVD的几种典型低辨识目标数据集示例见图7。

表2 图像数据统计

图7 MMPVD典型低辨识目标图像数据Fig.7 Typical low observable target image dataof MMPVD
2.1 硬件采集系统

图8 多模态传感器视觉感知平台及图像采集系统Fig.8 Multi-modal sensor visual perception platformand image acquisition system
为了获得成对的彩色图像、红外图像、偏振图像数据,搭建多模态传感器视觉感知平台,如图8所示。RGB彩色相机选用CGimagetech单目摄像头,搭配4~12 mm工业镜头,分辨率为640 pixel×480 pixel,帧率为30帧/秒,USB串口传输;红外相机选用大力DM66红外热成像仪,分辨率为640 pixel×480 pixel,帧率为50帧/秒,视场角为15°×11°,网络传输;偏振相机选用CGimagetech单目摄像头,搭配4~12 mm工业镜头,加装工业镜头偏振镜,偏振镜由两片偏振片组成。试验系统使用自制的铝合金架搭载RGB相机、红外相机和偏振相机,以3台设备的拍摄轴线定位,保证其拍摄轴线在同一垂直平面内。针对可见光相机和红外相机的传感器曝光方式、触发机制和帧率均不相同的问题,使用ROS(robot operating system)系统中的时间同步器(time synchronizer)模块接收来自3个相机的图像消息实现多模态相机的同步采集。同时,对彩色图像、红外图像和偏振图像进行同步后的配准操作,使得多模态图像采集系统可以实时获取同一时间具有相同视角和重叠区域的目标图像对。多模态图像数据采集计算平台使用Nvidia Xavier处理器。
2.2 多模态图像的配准算法
因两个可见光相机和红外相机不在同一空间位置且视野范围也有较大差别,故需要对获取的原始三模态图像进行配准处理。对图像对进行配准,需要提取与匹配图像对当中的对应特征点,通过特征点求取图像之间的变换矩阵。
单应性(homography)定义了两幅图像之间的变换关系,一张图像上的点在另一个图像上有且只有一个对应点,它在计算机视觉领域是一个非常重要的概念,在图像校正、图像拼接、相机位姿估计、视觉SLAM等领域有非常重要的作用[25]。单应性矩阵就是描述从一张图像到另一张图像的映射关系的3×3变换矩阵:
(6)
单应性变换矩阵为
(7)
其中,(x1,y1)与(x2,y2)为图像对上对应的一组特征点坐标。为了求得两幅图像之间的单应性矩阵,至少需要一组图形对上的4组对应特征点[25]。以红外相机为基准,分别求取RGB相机、偏振相机相对红外相机的单应性矩阵H1、H2,实现3个模态图像的像素级配准。对于红外相机的成像方式,通过特征点自动提取算法在红外图上提取准确度不高,导致多个模态图像匹配点求取有误,进而影响后续图像对校准的效果,因此采用手动选取图像对上对应的特征点来求取两个图像对之间的单应性矩阵,可实现多模态图像对的配准。通过稳定平台固定3个相机的相对位置,并保持各自的镜头焦距不变,因此只需要求取一次单应性矩阵。具体的多模态图像的配准算法步骤如下:
(1)固定RGB相机、红外相机以及有偏振相机镜头焦距,加热自制铁标定板,移动标定板,拍摄20对三模态图像。
(2)取20组RGB相机和红外相机图片对,每组先在RGB图像上选取4个特征点,再在红外图像上选择相同位置的特征点,得到4对特征点,计算RGB相机平面到红外相机的矩阵H,对得到的20组H矩阵取均值,并保存为H1。
(3)取20组有偏振相机和红外相机拍摄的图片对,每组先在有偏振图像上选取4个特征点,再在红外图像上选择相同位置的特征点,计算偏振相机平面到红外相机的矩阵H,对得到的20组H矩阵取均值,并保存为H2。
图9所示为配准前的三模态图像对示例,可以看到RGB相机及偏振相机的视野范围更大,需要进行单应性变换,对图像进行配准。变换位置,拍摄这样的图像对20组,求得标定结果如下:
(8)
(9)

图9 未配准前的多模态图像对Fig.9 Multi-modal image pairs before registration
得到H1、H2矩阵后,即可将RGB相机、偏振相机平面映射到红外相机平面,对变换后的图像对进行剪裁操作,保留3个模态图像最大相同区域,得到以红外图像为基准的配准后的多模态图像对。配准结果如图10所示。通过求得的单应性矩阵H1、H2对多模态传感器视觉感知平台得到的图像对进行实时同步和配准,得到配准过后的三模态图像对对齐结果,如图11所示,彩色图像、偏振图像均与红外图像对齐。

图10 配准结果Fig.10 Registration results

(a)RGB图像和红外图像(b)偏振图像和红外图像图11 配准后的多模态图像对齐Fig.11 Multi-modal image alignment after registration
3 试验验证
3.1 试验平台
深度学习模型的权重训练在实验室的高性能图像处理工作站上完成,工作站配置见表3,主要包括Intel i9-7980XE(CPU),32GB内存,双GTX 1080Ti GPU,22GB显存,1TB 固态硬盘+12TB混合硬盘(RAID 1冗余备份阵列)。

表3 工作站配置
3.2 模型训练
针对多模态目标检测网络的训练,本文沿用前文的Faster R-CNN各部分损失函数。由于所设计的多通道的目标识别网络采用3个VGG-16网络作为骨干特征提取网络,网络层数较深,结构复杂,参数较多,因此,为了防止模型在自建的MMPVD数据集上出现过拟合的现象以及缩短模型收敛的时间,需要选择合适的初始值初始化网络模型中3个不同模态的VGG-16。红外热像仪和可见光相机的成像原理不同导致红外图像和可见光图像差异较大,所以在MMPVD训练集上分别训练单模态的红外图像目标检测网络和单模态的可见光图像目标检测网络,分别得到适合红外图像和可见光图像(包括彩色图像、偏振图像)的特征提取网络VGG-16,以此作为三模态目标检测网络中不同模态VGG-16的初始化,模型初始化示意图见图12。
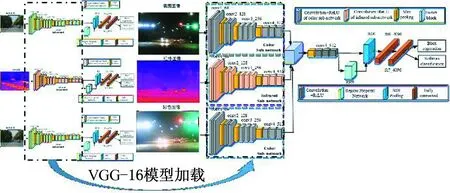
图12 VGG-16模型初始化Fig.12 Initialization of VGG-16
在该配置环境下,多模态深度学习网络在整个MMPVD训练集上完成105次迭代需要约15 h,网络模型训练的损失(loss)函数变化过程如图13所示。其中,绿色和红色虚线分别代表训练单模态的红外图像目标检测网络损失和单模态的可见光图像目标检测网络损失,蓝色实线为多模态目标检测网络损失。由图13可知,在经过105次迭代后,模型均达到很好的收敛效果。还可从图13的局部放大图中看到,相对于单模态网络的训练,多模态目标识别网络训练的损失变化得更加平稳,模型收敛得更快。
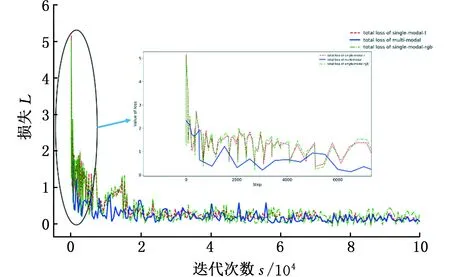
图13 损失曲线Fig.13 Loss curve
3.3 试验结果对比与分析
平均精度(average precision, AP)是查准率(precision)和查全率(recall)综合计算的结果,是机器学习中检测算法性能的重要评价方法之一。以查准率为纵轴、查全率为横轴作图,就得到查准率-查全率曲线,简称“P-R曲线”。平均精度为P-R曲线在横坐标[0,1]区间上的定积分,反映了模型的性能,面积越大,平均精度越大,性能越好。“平衡点”(break-even point,BEP)是查准率等于查全率的取值。BEP越大,性能越好[26]。mAP是子类中平均精度的平均值。测试集为MMPVD测试集中低辨识目标测试子集,用于验证多模态目标检测算法在复杂环境下对低辨识目标的检测性能。
在VGG-16的第4和第5个卷积块之后,不同融合方式在MMPVD测试集上的测试结果性能对比如图14所示,其中Conv4和Conv5分别表示在VGG-16的第4和第5个卷积块后进行多模态特征的融合,以单模态的Faster R-CNN作为算法性能对比基准。测试集为MMPVD三模态数据集中的全部测试子集,涵盖全部采集场景和环境条件,包括良好驾驶环境条件和非良好驾驶环境下的目标。
图14a、图14b分别为本算法在测试集上人员、车辆目标的P-R曲线与平衡点,图14c为所有识别目标的AP值统计直方图。由图14可以发现:基于多模态特征融合的深度卷积神经网络能够获得更高的AP值,P-R曲线完全覆盖单模态目标检测网络,平衡点处的取值也大于单模态目标检测网络。因此,相对于传统的单模态目标检测算法,多模态目标检测算法对复杂环境下的低辨识目标具有更好的检测和识别性能。而且实验发现,在VGG-16的第5个卷积块后将来自不同模态的特征进行融合的效果稍优于在第4个卷积块后融合的效果。
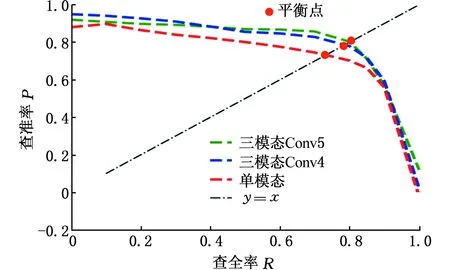
(a)人员P-R曲线与平衡点
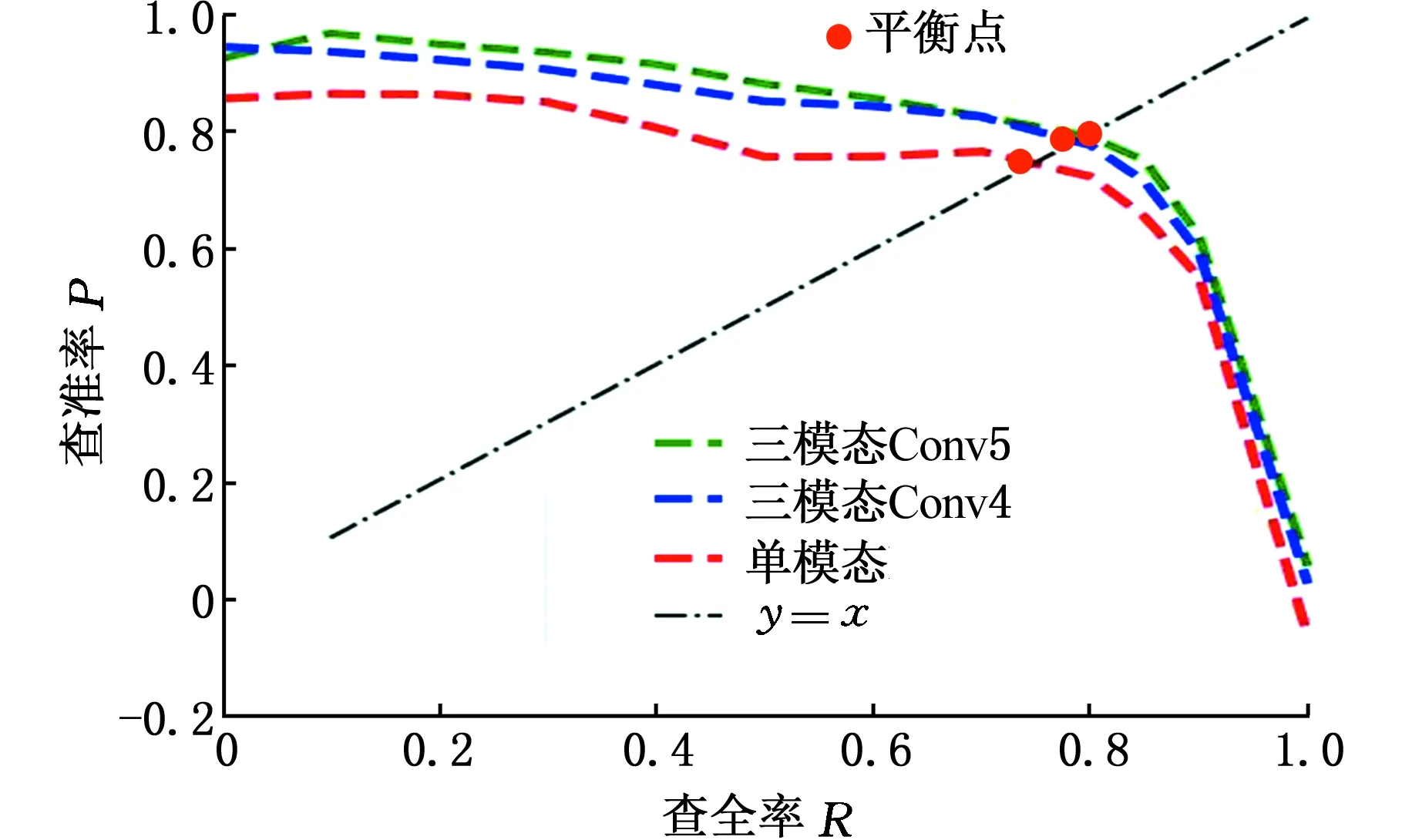
(b)车辆P-R曲线与平衡点
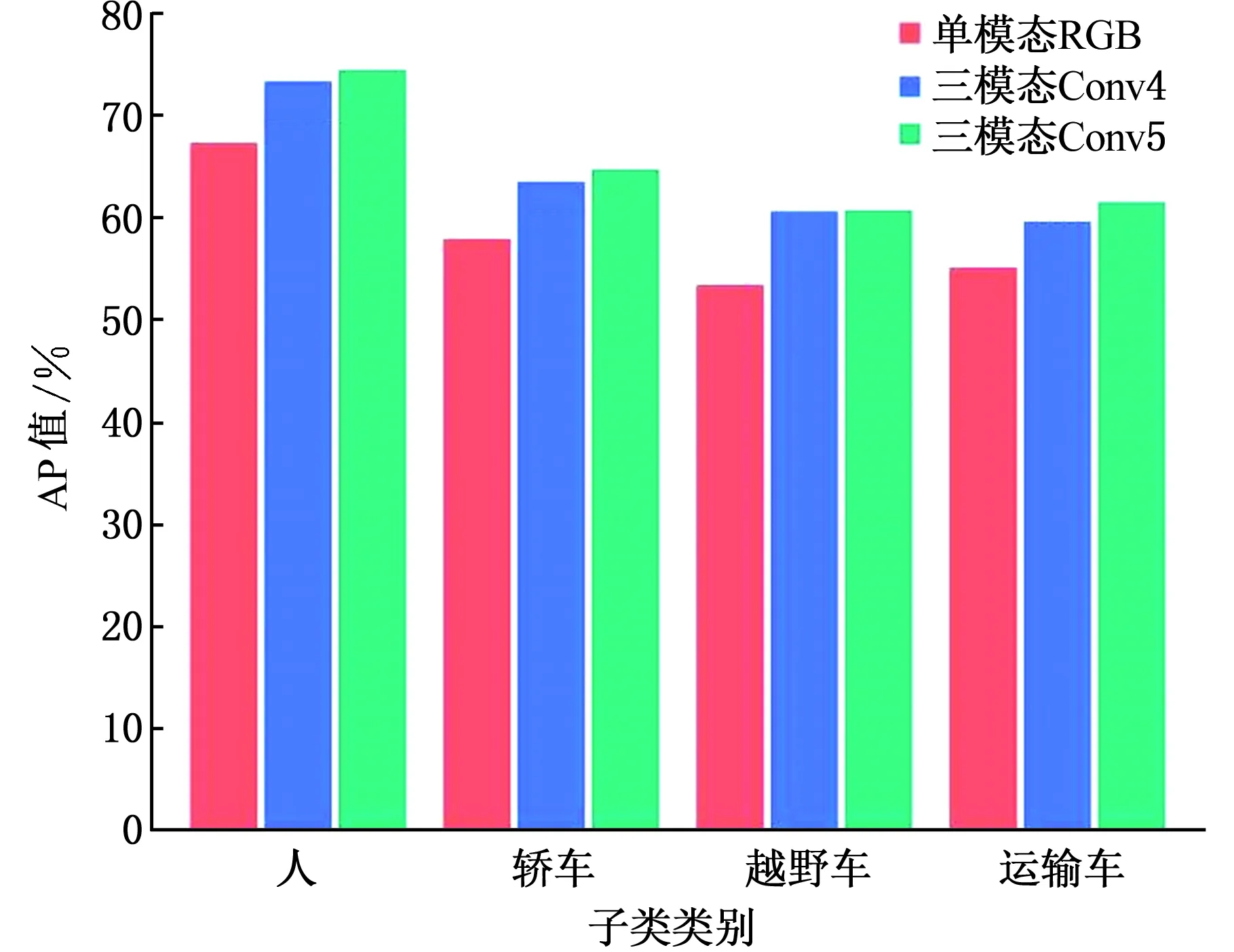
(c)AP值直方图图14 不同融合方式对比结果Fig.14 Comparison results of different fusion methods
纵向对比单模态、双模态和三模态目标识别算法性能,同时以MMPVD三模态数据集中的低辨识目标为测试数据子集(涵盖了不同驾驶场景中低照度、低能见度下的低辨识目标,且多包含RGB图像受到光斑、耀斑严重影响的多模态图像对),验证多模态目标检测算法在自动驾驶真实驾驶复杂环境下针对低辨识目标的检测性能,以单模态的Faster R-CNN作为算法性能对比基准,测试结果如图15所示。由图15可以发现:在MMPVD低辨识目标测试数据集上,相对于单模态目标检测算法,基于双模态及三模态特征融合的深度卷积神经网络目标检测算法取得了更好的AP值,其P-R曲线完全覆盖单模态目标检测网络Faster R-CNN的P-R曲线,平衡点处的取值也大于单模态目标检测网络的取值,而且融合了偏振图像特征的多模态目标检测算法的检测性能优于双模态目标检测算法的性能。
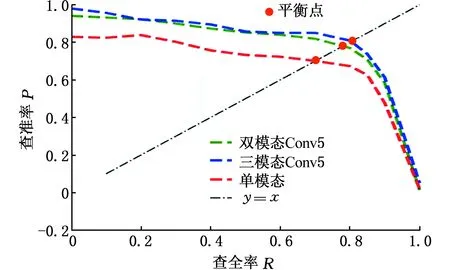
(a)人员P-R曲线与平衡点

(b)车辆P-R曲线与平衡点

(c)AP值直方图图15 不同模态对比结果Fig.15 Comparison results of different modalities
针对低能见度、低照度环境条件下受到严重的光斑、耀斑影响的低辨识目标,融合红外图像特征、RGB图像特征及偏振图像特征的多模态目标检测算法的检测性能优势更加明显,当RGB图像上的目标特征不明显时,单模态目标检测算法检测性能急剧下降,而红外图像特征由于成像方式的特殊性可以很好地进行特征信息补充,且偏振图像能够有效滤除偏振光在影像上所形成的亮斑、耀斑,改善图像清晰度的光学特性的同时也从另一个方面补充了特征信息,从而提高了自动驾驶在真实驾驶环境下的视觉感知能力。
相对于传统的单模态目标检测算法,双模态和三模态目标检测算法对复杂环境下的低辨识目标均具有更好的检测和识别性能,而且三模态目标检测算法检测性能在某些特殊场景下优于双模态的目标检测算法,尤其是针对低能见度、低照度环境条件下受到严重的光斑、耀斑影响的低辨识目标具有更明显的优势。
3.4 基于机器人操作系统的多模态目标实时检测系统
考虑到自主驾驶车辆对环境感知实时性的要求,对比分析多模态目标检测算法在图像处理工作站上的处理速度,算法帧率实验对比结果如下:单模态、双模态、三模态的帧率分别为23帧/秒、18帧/秒、14帧/秒。相对于单模态的目标检测算法,多模态目标检测算法的卷积层的参数数量更大,网络结构更加复杂,所以帧率有所下降。三模态目标检测算法前向处理一帧图像对约需要0.07 s,双模态目标识别网络需要0.05 s,满足实时检测的要求。
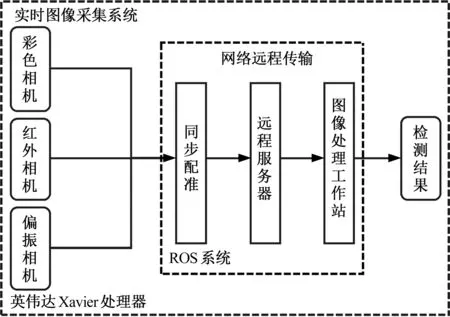
图16 实时检测系统框架图Fig.16 Framework of real-time detection system
设计基于ROS系统的多模态目标实时检测系统,系统框架如图16所示。在自主驾驶车辆上搭载Nvidia Xavier嵌入式处理器,实现多模态图像数据的实时采集,然后基于ROS系统实现多模态图像的同步和配准,获取配准过后的多模态图像对,将得到的多模态图像对通过基于TCP协议的网络传输算法传输到远程的阿里云服务器,本地的图像处理工作站作为客户端实时获取远程服务器上的多模态图像对视频流,将得到的视频流输入多模态目标检测算法实现对自主驾驶车辆周围环境的实时感知。多模态目标检测系统检测结果可视化如图17所示。
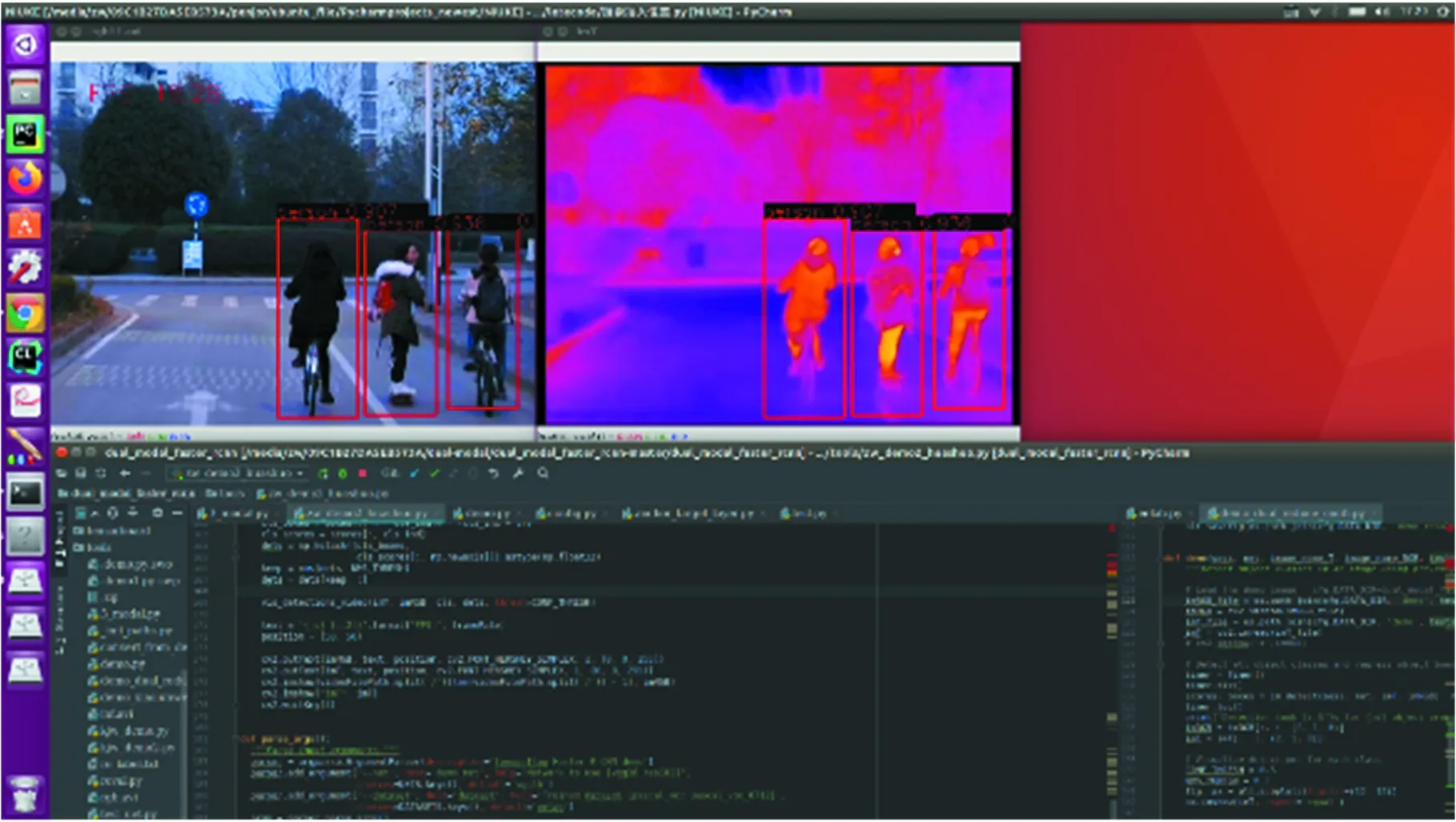
图17 多模态实时目标检测系统可视化Fig.17 Visualization of multi-modal and real-timeobject detection system
图18、图19分别为多模态目标检测算法和单模态目标检测算法在MMPVD测试集上的部分检测结果。可以看到,针对复杂环境下的低辨识目标,本文所设计的多模态目标检测算法具有更高的分类置信度(confidence)和较好的检测结果,而单模态目标检测算法存在严重的漏检现象。

(a)双模态1 (b)单模态1

(c)双模态2 (d)单模态2

(e)双模态3 (f)单模态3

(g)双模态4 (h)单模态4图18 MMPVD双模态测试结果对比Fig.18 Comparison testing results of dual-modal MMPVD

(a)三模态(RGB+红外+偏振,置信度:0.918)

(b)双模态(RGB+红外,置信度:0.768)(c)单模态(RGB,置信度:0)

(d)三模态(RGB+红外+偏振,置信度:0.753,0.961)

(e)双模态(RGB+红外,置信度:0.603,0.682)(f)单模态(RGB,置信度:0,0.560)

(g)三模态(RGB+红外+偏振,置信度:0.933)

(h)双模态(RGB+红外,置信度:0.833)(i)单模态(RGB,置信度:0.719)

(j)三模态(RGB+红外+偏振,置信度:0.760)

(k)双模态(RGB+红外,置信度:0.639)(l)单模态(RGB,置信度:0)图19 MMPVD三模态测试结果对比Fig.19 Comparison testing results of 3-modal MMPVD
4 结论
(1)本文针对自主驾驶车辆复杂环境下的低辨识目标识别问题,设计基于多模态特征融合的目标检测算法。融合彩色图像、偏振图像、红外图像特征,实现对低辨识目标的有效检测。实验结果表明,在MMPVD多模态低辨识目标测试集上,相对于传统的单模态目标检测算法,基于多模态特征融合的深度卷积神经网络对复杂环境下的低辨识目标具有更好的检测和识别性能,而且三模态目标检测算法检测性能在某些特殊场景下优于双模态的目标检测算法,尤其是针对低能见度、低照度环境条件下受到严重的光斑、耀斑影响的低辨识目标,融合了偏振图像特征的多模态目标检测算法的检测性能具有更明显的优势。
(2)构建了彩色图像、偏振图像和红外图像三模态数据集MMPVD,该数据集在模态数量、规模、数据质量(图像配准精度、图像清晰度)、目标类型及环境复杂度上均超过当前公开的双模态数据集KAIST。
(3)针对自主驾驶车辆对环境感知实时性要求,搭建多模态传感器视觉感知平台,基于ROS系统构建多模态目标实时检测系统,探索多模态图像特征融合在自动驾驶视觉感知系统中的应用。实验结果表明,本算法满足目标检测实时性要求。
下一步研究可以考虑通过优化多模态目标检测网络结构、扩充低辨识度目标数据集及模型压缩,从而提高自主驾驶车辆视觉感知的准确性和实时性。
