基于行为轮廓的模块化流程模型修复方法
2021-05-19盛梦君方贤文邵叱风
盛梦君,方贤文,邵叱风
(安徽理工大学数学与大数据学院,安徽 淮南 232001)
模型修复是一种新的过程挖掘技术,它将事件日志和流程模型作为输入,通过对日志进行分析来发现流程模型中的偏差,进而对模型进行修复。目前,可以通过事件日志来研究系统的真实情况,运用过程挖掘技术得到流程模型。但是,由于挖掘出能够确切描述现实生活的系统模型是困难的,且流程往往会在系统的生命周期中发生变化。因此,对于模型修复问题的研究具有重要意义。
关于模型修复国内外学者已经做了很多工作。过程挖掘技术一共有三类应用:模型发现、一致性检测和过程增强,模型修复属于过程增强。评价过程模型的质量有四个标准:拟合度、精确度、泛化度和简化度。工作流网中适应性感知控制流修复的方法通过事件日志将不符合要求和符合要求的迹分开,将不合格的迹分解为不合格的子日志,每个子日志都能在相应的子流程工作流网中被发现,然后以这种方式将这些子流程添加到初始模型中,使得修复后的模型能够成功重放给定的事件日志。这种方法还允许删除不常使用的模型片段,令修复后的模型更简单,但这种删除方式略显暴力,并不是简化模型的最佳方法。基于此,通过一种简化模型结构的方法,使得模型仍然可以重放日志中描述的大多数行为。现有的模型修复方法大多侧重于通过一致性检验找到事件日志与模型之间的偏差,但未侧重修复偏差问题。基于对齐的概念,建议改变运营分配成本,通过调查所有可能的修复空间,提出并评估了一组最优修复算法,将Petri网的修复问题简化为了优化问题。通过考虑过程挖掘中应用分而治之原则的问题,提出一个过程发现的模式,该修复方法也是利用分而治之的思想进行模块化修复。通过分析事件日志来研究系统的真实情况,发现真实系统模型,工程师可以使用一致性检验技术来诊断观察事件日志和流程模型之间的差异。但一味地提高修复后模型的适应度或简化度会让修复成本大大提高,并且修复过程中事件日志遍历的次数过大,与其修复模型不如重新通过事件日志挖掘新模型。因此,进一步降低修复成本,减少以往修复算法的迭代次数和遍历事件日志的次数以及修复算法的时间复杂度是本文针对的问题。
针对上述问题,本文提出了基于行为轮廓的流程模型修复方法,运用模型分解及线性过滤的方法对模型进行修复,尽可能地保持初始模型结构不改变、原模型可读以及结构良好的性能来进一步降低修复成本,降低修复算法的时间复杂度。此外,还给出了过滤模块以及选择模块中相应的算法,从而较好地提升了模型修复的有效性。
1 基础知识
定义1(流程模型Petri网)满足以下条件的四元组N
=(P
,T
,F
,C
)称作一个流程模型Petri网:(1)P
是有限非空库所集,T
是有限非空变迁集;(2)P
∪T
≠φ
且P
∩T
=φ
;(3)F
⊆(P
×T
)∪(T
×P
)是N
中的流关系,(P
∪T
,F
)是强连通图;(4)dom
(F
)∪cod
(F
)=P
∪T
,其中dom
(F
)={x
∈P
∪T
|∃y
∈P
∪T
∶(x
,y
∈F
)}cod
(F
)={x
∈P
∪T
|∃y
∈P
∪T
∶(y
,x
∈F
)};(5)C
={and,xor,or}是流程网的结构类型。定义2(行为轮廓)设P
=(A
,I
,C
,F
,T
)是一个流程模型(x
,y
)∈((N
∪F
)×(N
∪F
))是满足下列关系中的一个:(1)严格序关系→,如果x
≻y
且y
≻x
;(2)排他关系+,如果x
≻y
且y
≻x
;(3)交叉序关系‖,如果x
≻y
且y
≻x
。以上三种关系的集合是P
=(A
,I
,C
,F
,T
)的行为轮廓。定义3(流程模型)将流程模型设定为一个元组M
=(P
,T
,F
,J
,ε
,σ
,M
,M
),P
是库所集∀p
∈P
;T
是变迁集∀t
∈T
;F
是连接所有直接跟随库所与变迁之间的流关系,F
⊆(P
×T
)(T
×P
);J
是排序的有限集合;ε
是满射函数,将每个变迁关联到一个排序,T
→J
;σ
是指定函数,将所有变迁映射到活动集或静默变迁中,T
→A
∪{τ
},σ
(t
)=∂(e
)=a
,∀a
∈A
,τ
∈T
,σ
(τ
)∉A
;M
是初始标识;M
是终止标识。
图1 流程模型工作流网示例

表1 图1 示例中字母代表的活动事件
定义4(事件日志,迹)事件日志是一个数学模型,用于捕获有关动态系统执行的历史信息。从形式上讲,定义Σ
是一组动作集,迹l
∈Σ
是一个动作序列,L
∈ΙΒΣ
)是一个事件日志即一组迹的多元集。其中每组迹都是将系统(即流程实例)的执行描述为一系列观察到的事件。因为可以存在多个具有相同迹的情况,如果迹的频率不相关,将记录日志称为一组迹L
={l
,…,l
}。定义5(工作流网的有效分解)设N
∈U
是一个带标签函数l
的工作流网。D
={N
,N
,…,N
}⊆U
是一个有效的分解,当且仅当:—任意1≤i
≤n
,N
=(P
,T
,F
,l
)是一个Petri网,—任意1≤i
≤n
,l
=lΓ
,—任意1≤i
<j
≤n
,则P
∩P
=0,
N
=∪1≤≤N
D
(N
)对任意网N
是一个有效分解集。2 本文方案
(1) 模块化修复框架
本文考虑的修复问题:给定工作流网N和事件日志L,事件日志L不完全符合N,提出了一种基于模型分解及线性过滤的模块化修复方法,构造模型Nr(修复后模型),让Nr能够重放L。主要思想是基于分而治之的原则筛选出需要修复的片段,修复方法由构建的块组成,每个块执行其中一个步骤,模块化模型修复方法如图2所示,构建的块分别为:①分解;②过滤;③选择;④修复;⑤组合;⑥案例分析。弧表示块之间的数据传输。

图2 模块化修复框架
本文基于模块化模型修复的一般方法如下:该方法的输入是一组(L
,N
),其中L
是一组事件日志,N
是一个不完全符合事件日志的初始模型。在分解块中,使用极大分解算法将模型N分解成几个片段,分解结果是唯一的。在过滤块中,本文给出了一个包含在过滤块中线性过滤算法,算法将这些模型片段即子模型的直链结构进行过滤筛除,直链结构不执行下一步选择过程,从而直接保留直链的原始模型片段,最后与修复后的模型片段组合。在选择块中,选择算法将分解后的子模型的执行序列与新增的两条事件日志的迹运用行为轮廓相关知识进行比对,符合事件日志的迹即为优子模型,反之为劣子模型。在修复块中,将剩下的劣子模型与事件日志对比分析运用感应挖掘算法进行修复。在组合块中,将过滤掉的直链结构、优子模型和修复后的子模型进行组合,得到能够重放事件日志修复后的模型。(2)使用极大分解方法进行模块化修复
本文提出的模块化修复方法在每个构建的块中使用特定算法。其中分解块中使用的极大分解方法是一个有效分解,极大分解是基于边缘的划分,其定义如下:每个变迁严格地位于单个片段中,具有唯一标签的变迁被放置在片段的边界上,在片段之间需要有因果关系的支持。因此,对于每个变迁,一个在初始网中具有唯一标签的变迁将存在于两个或者多个片段中,最后,拆分保存了网络的初始标识。如果库所在初始网中被标记了,那么它在片段中也是被标记的。在给定的系统网中,有且仅有一个极大分解,且分解结果是唯一的。极大分解网能够很容易地通过融合有相同标签的变迁组合回完整的网。

图3 图1中模型的极大分解
将文献中提出的极大分解算法应用到分解块中,并在此基础上开发了过滤块和选择块的算法,其工作原理如下:如果网片段发现可见的变迁,可依据decompose、handlePlace、handlePlace recursively三个函数的工作原理调用以后对其进行分解。即decompose函数从初始网中任意库所开始,当有库所需要遍历时调用handlePlace函数,调用handlePlace函数后,调用handlePlace recursively函数来遍历此流程中库所的前置节点和后继节点。以初始网图1中库所p为例,调用后三个函数后它的前置节点为变迁A和变迁G,后继节点为变迁B,因此分解后片段为图3中SN2片段。
初始网图1中完整流程模型分解后得到的全部子模型如图3所示;过滤块中运用线性过滤算法再将其进行过滤,若子模型中的库所前、后集个数分别为1或0,则可直接过滤此直链结构,直链结构不执行下一步选择过程,过滤后的模型片段如图4所示;过滤后选择劣子模型进行修复,选择块中的选择算法将过滤后模型片段的执行序列与增加的事件日志运用Petri网中行为轮廓定义进行比对,符合的为优子模型,反之为劣子模型。过滤算法及选择算法如下:
输入:ModelSetε
输出:ModelSetφ
ModelSetε
;ModelSetφ
=Null;1)for each part model A in ModelSetε
;2)pre set of place=prsp;
3)post set of place=posp;
4)if |prsp|=|posp|=1 || (|prsp |=1 and |posp|=0)|| (|posp |=1 and |prsp|=0)
5)part model A is null;
6)break;
7)else
8)Return (prsp X posp) of A
9)end if
10)φ
.add(part model);11)end for each
12)for each (x
,y
) in (prsp X posp)13)for each Trace in New Log
14)ifx
in Trace and y not in pre ofx
;15)return (x
,y
) , part Model of (x
,y
)16)end for each
17)end all

图4 图3过滤后模型片段
文献[13]已有许多流程发现的算法,本文使用感应挖掘保证模型发现的适应性(零噪音阈值的不频繁感应挖掘)。它使用顺序和回归的感应推理来构建一个可以转化为工作流网结构的过程树。
假设图3中的模型中变迁C和E与其行为顺序不完全一致,如果二者同时出现,则在事件日志的迹中E总是在C之前出现,根据行为轮廓,即E和C是严格序关系,记作E→C,也就是说事件日志包含迹

图5 通过感应挖掘发现此模型片段
在发现正确的模型片段并组合所有片段之后,得到了如图6所示的网。这个模型与事件日志的迹

图6 变迁组合后的Petri网
3 案例分析
本节以上述退换货系统为例计算修复前后模型的适合度来评估所提方法的可行性,并与Fahland修复方法进行对比实验。
在给定事件日志L和模型M上进行实验评估。如表2所示,事件日志L一共包含事件总数为:|N
|=12 781,其运行次数依次为{58,87,230,270,198,205,109,26,100,12,49,210,180,33,101}。事件日志中总共有15条完整有效的执行序列,大小分别为{6,7,10,11,12,15,16,14,13,15,14,13,10,8,7},预定义模型上的所有发生序列大小依次为{7,7,10,10,12,15,16,14,12,15,15,12,10,7,7}。将日志与模型进行最优校准,得到15组最优校准。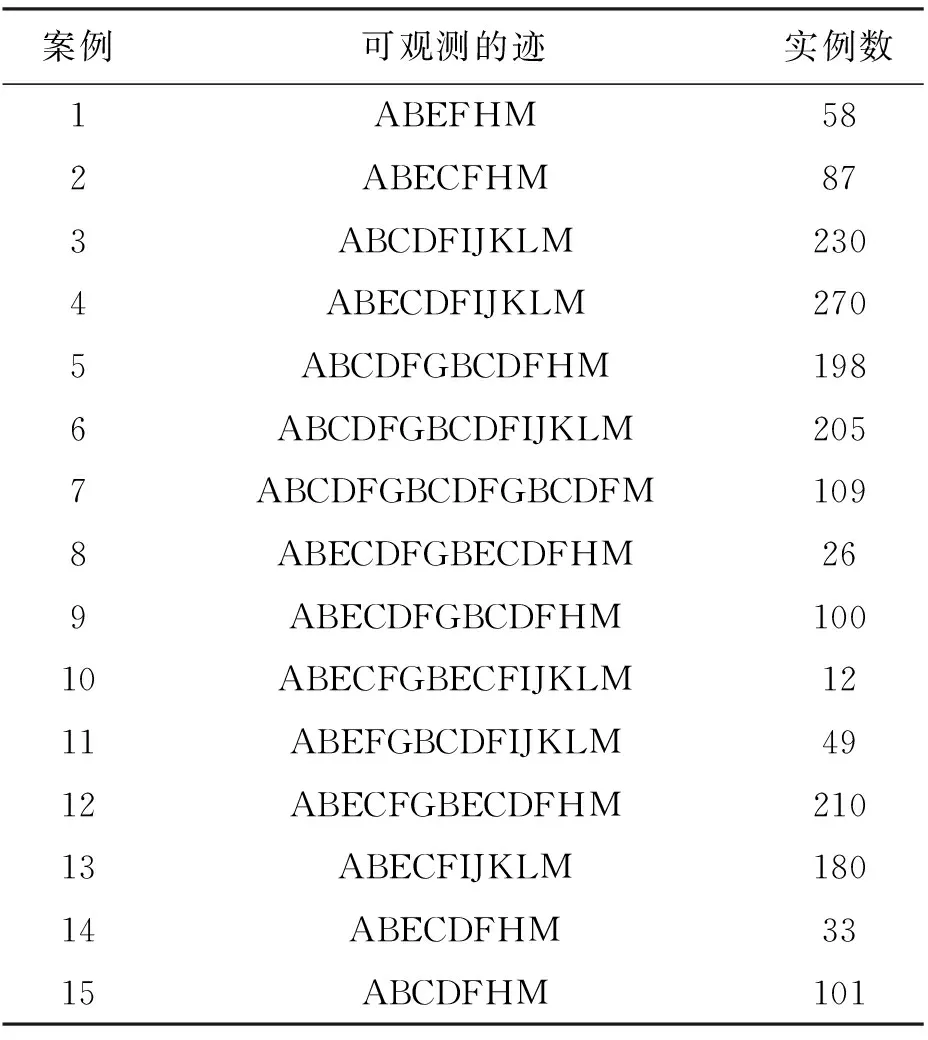
表2 网购退换货系统的事件日志
分析得到的15组最优校准,这些校准中的不一致由偏差引起,偏差分为日志插入偏差和网N
跳过偏差,如案例1即n
=1中是日志插入偏差,n
=2中是网N
跳过偏差。因此,日志与初始模型之间的拟合度为

(1)
式中:L
表示每组发生序列的发生次数即实例数,n
表示校准的组数(本文有15组),C
表示每组校准的偏差成本,这里将所有偏差成本设为1,M
表示日志发生序列,M
表示模型中的发生序列,ε
表示日志发生序列的元素个数,δ
表示模型发生序列的元素个数,而日志与修复后模型之间的适合度为1,因此本文的修复方法具有可行性。根据本文所提算法的第12~17两层嵌套循环可以看出,其算法的时间复杂度为O
(MN
)。运用Fahland方法对案例模型修复结果如图7所示,与本文所提方法的对比实验结果如表3所示。
图7 运用Fahland方法修复后模型

表3 修复结果对比数据
4 结论
本文在已有研究的基础上提出了一种基于模型分解和线性过滤的模块化流程模型修复方法,通过线性过滤算法进一步有效降低了修复的成本和修复算法的时间复杂度,并且尽可能保持了初始模型结构。首先将初始模型运用极大分解算法分解,其次使用过滤算法进行线性过滤,再使用选择算法选择劣子模型然后通过感应挖掘重新发现模型片段,最后对模型片段进行组合得到修复后模型。
本文的方法可能略微降低了模型的精度,对于此问题,计划提出更细微的分解技术以避免片段边界节点的相关问题。基于分解的模型修复也会考虑到拟合度,精确度,泛化度和简化度的组合度量,此外修复是基于模型,对模型分解的相关问题可能非常有帮助,这也是未来可以研究的方向之一。
