基于大数据处理的模式匹配算法效率分析
2021-05-15汪滢,熊璐,刘晓
汪 滢,熊 璐,刘 晓
(南昌师范学院,江西 南昌330032)
0 引 言
目前大数据和网络技术已经相对成熟,每天产生的数据信息呈指数级增长,网络数据流的高效快速处理是当前信息安全研究的重要方向[1]。海量数据有四个特点:数量大、种类多、速度快、价值高,因此常规数据处理方法难以适用。检索大量数据并进行快速匹配是许多系统应用所要解决的问题。模式匹配算法是防火墙数据过滤、入侵检测、天气数据分析和预测等应用中不可缺少的一部分[2]。
数据检索和快速匹配技术的核心是模式匹配算法,该算法主要有单模式匹配和多模式匹配两种,单一模式匹配算法只能匹配文本串中的一个模式字符串,而多模式匹配算法则是一组模式,即在文本字符串中快速匹配多个模式字符串。单一模式匹配算法的研究是多模式匹配算法的基础,但是在实际应用中,多模式匹配算法得到了越来越广泛的应用。
分析模式匹配算法效率对于提高匹配算法的适用性有重要意义。文献[3]提出了一种基于Snort系统的模式匹配算法效率分析方法,设计了马尔可夫链状态转换图,然而这种转换图虽然具有直观的意义,但是由于不能将匹配次数和文本串联系到一起,所以得到的结论与实际结果严重不符。文献[4]提出了基于一次判断双字符比较的模式匹配算法,通过穷举法计算算法效率,该算法准确率高,然而计算过程复杂。
综上所述,本文基于大数据处理研究了一种模式匹配算法效率分析方法,建立算法分析模型,并通过穷举法对算法的效果进行分析,最后通过实验验证了方法的有效性。
1 模式匹配算法效率分析模型
由于基于大数据处理的模式匹配算法效率分析方法有单模式匹配算法和多模式匹配算法,因此本文建立的模式匹配算法分析模型也包括两种,分别是单模式匹配算法分析模型和多模式匹配算法分析模型[5⁃6]。
1.1 单模式匹配算法效率分析模型
设定单模式匹配算法文本串为T,计算表达式为:

根据式(1)可知,文本串的长度为n。
设定单模式匹配算法的模式串为P,表达式为:
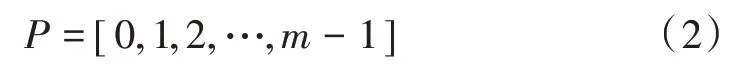
根据式(2)可知,模式串的长度为m。
在对单模式匹配算法进行分析时,需要判断在文本串中是否出现过模式串,如果判断结果为出现,则证明匹配结果是成功的;如果判断结果为没有出现,则证明匹配结果是失败的[7⁃9]。具体单模式匹配算法的匹配过程如图1所示。

图1 单模式匹配算法数据匹配过程
单模式匹配算法的效率平均值计算需要进行字符串和模式串匹配,匹配方向为从右向左,如果第一组数据匹配成功,则继而进行第二组数据匹配,依次进行,如果所有的数据都能够顺利匹配,则证明匹配成功;反之,则证明匹配失败[10⁃11]。
1.2 多模式匹配算法分析模型
设定多模式匹配算法文本串为T′,计算表达式为:
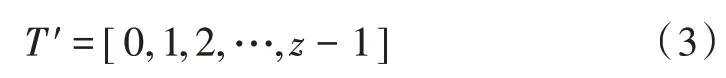
根据式(3)可知,文本串的长度为z。
设定多模式匹配算法的模式串为P′,表达式为:
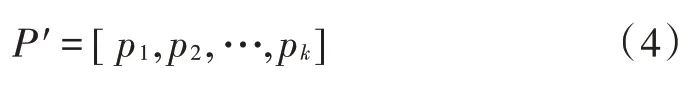
根据式(4)可知,模式串的长度为k。
多模式匹配算法的分析方法与单模式匹配算法分析方法相同,需要判断在文本串中是否出现过模式串,如果结果为出现,则匹配成功;否则为失败[12]。多模式匹配算法数据匹配过程如图2所示。

图2 多模式匹配算法数据匹配过程
单模式匹配算法的效率平均值计算需要进行字符串和模式串匹配,匹配方向为从右向左,如果第一组数据匹配成功,则继而进行第二组数据匹配,依次进行,如果所有的数据都能够顺利匹配,则证明匹配成功;反之,则证明匹配失败[13]。
2 基于大数据处理的模式匹配算法效率分析
在构建模式匹配算法效率分析模型后,应用大数据处理技术分析模式匹配算法效率[9]。扫描被匹配的文本串中的字符,根据扫描结果判断运行状态,分析过程中引入Goto表、Fail表、Output表。
匹配过程如图3所示。
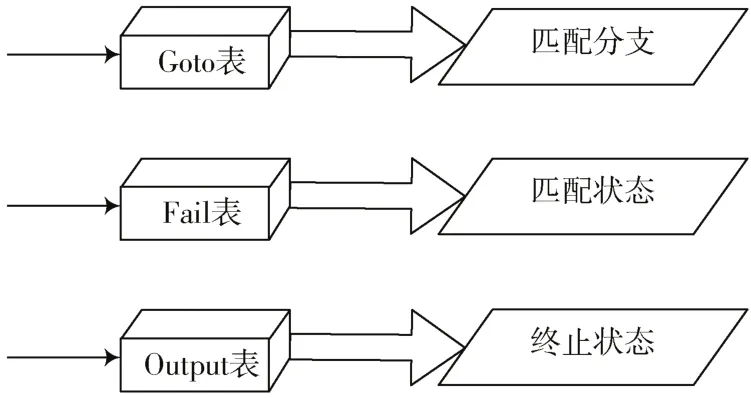
图3 不同表格匹配过程
不同表格负责不同的工作,分析过程如下:
1)Goto表负责记录模式串中的内容,将匹配的字符以模式串的形式转给不同的分支,将得到的分支转到模式树结构中,挑选出模式树中重复的部分,并重新创建,将最后的字符进行标记,得到终止状态。
2)Fail表记录不同自动机的状态,将其输入到不同模式中,记录文本串中的各个字符,通过转换状态,判断字符是否失败,Fail表记录的是跳转过程中深度最大的状态。
3)Output表负责记录终止状态,当记录的状态为终止状态时,将所有的模式串集合到一起,如果前面两个表的状态发生改变,则需要再次记录终止状态,直到所有的终止状态都写入到Output表为止。具体的分析流程如图4所示。
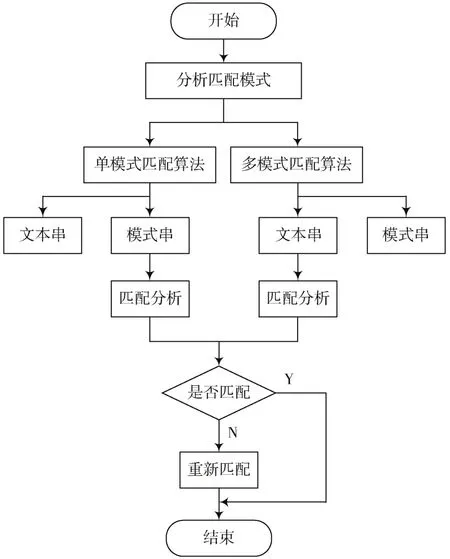
图4 匹配算法分析流程
记录不同算法的匹配差,设定算法在进行移动的过程中,文本串和模式串的字符个数共有μ个,其中,属于模式串的字符个数为α,不属于模式串的字符个数为β,利用大数据算法对文本匹配结果进行计算,结果如式(5)所示:
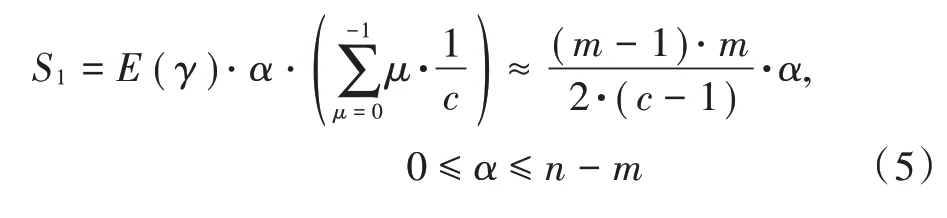
式中S1代表匹配后的结果。由于匹配的所有文本字符都是随机字符,彼此互相独立,分布特征与二项式分布特征相同[14],对分布概率进行计算,得到的概率计算公式为:
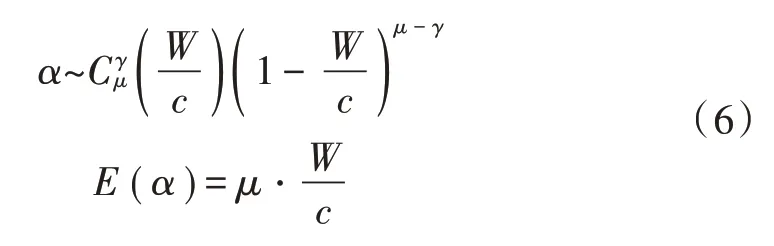
根据式(6)可知,如果文本中的字符与模式串的字符不符合,则证明匹配结果不成立。根据上述过程实现匹配算法效率分析。
3 实验与研究
经过对上述模式匹配算法的效率分析研究,为验证本文分析方法的性能,将本文方法的研究结果与传统方法的研究结果进行实验比较,并构建对比实验。
本文实验在单机的环境下执行任务操作指令。硬件系统规格为内置CPU,内存2 GB,操作主系统选用Fedoral13。将基于Snort系统的模式匹配算法效率分析(见文献[3])、规则软件系统模式匹配算法效率分析(见文献[4])与本文基于一次判断双字符比较的模式匹配算法效率分析在上述实验环境中进行对比。实验过程中的操作数据来自于互联网中的流数据,模式集数据由频繁出现于网络中的系统数据组成,流数据结构图如图5所示。
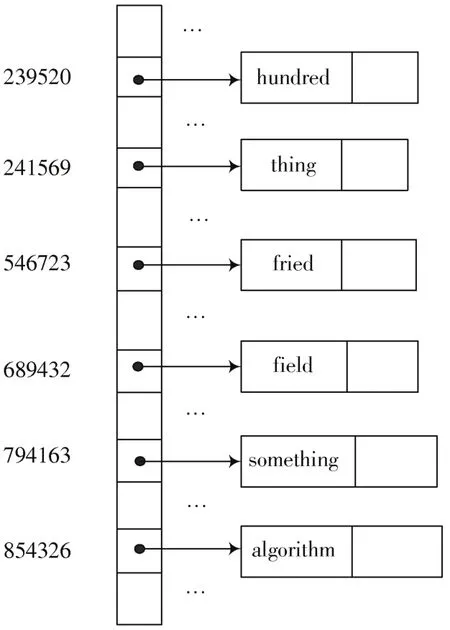
图5 流数据结构图
将以上数据与实验数据集合相组合,并匹配相应的系统操作手段,调整此时的实验环境操作状态,按照实验内部监管原则对操作的数据进行监管,保证算法运行的安全可靠性。将模式集数据划分为规模结构不同的5组数据,实验操作文本数据均来自于内部网络空间,由此确保操作的有效性。将需进行实验操作的算法分别录入模式集数据中,并进行实验操作匹配。构建的数据及参数如表1所示。
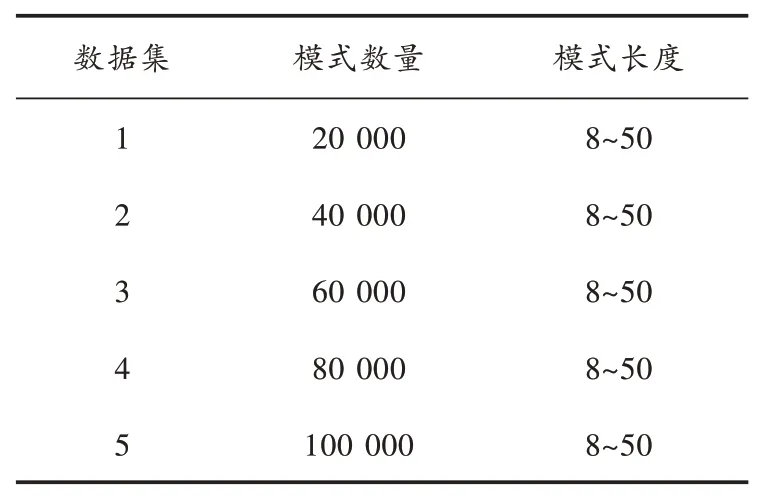
表1 数据集参数表
本文利用上述数据集管理不同的模式匹配算法效率状况,并对实验得出的不同算法匹配次数进行比较,检验其与标准次数间的差异,设置标准次数为32次,所获取的实验结果与标准次数的差异越小,则表示该方法的效率分析效果越好。构建实验对比结果如图6所示。
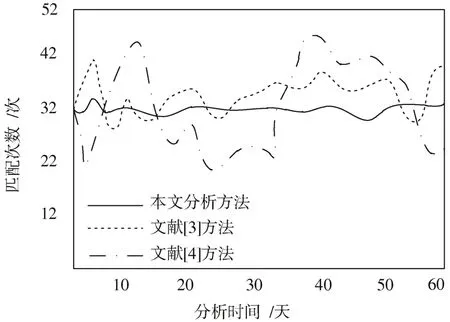
图6 匹配次数差异对比图
根据图6可以分析出,本文基于大数据处理的模式匹配算法效率分析的匹配次数相较于其他两种分析方法更加接近标准次数,算法效率分析效果较好。文献[3]方法的匹配次数与标准次数的差异较小,文献[4]方法的匹配次数与标准次数的差异较大。
由于本文分析方法在实验研究的过程中不断录入相应的数据信息保护规则,将数据控制在系统可控的范围内。同时,及时保存消耗的数据信息,时刻记录已完成实验操作的数据,并专门设置数据存储中心存储已接受检验的匹配算法数据,减少了不必要的操作麻烦,缩减操作步骤,节约算法信息匹配时间,缩减匹配次数差异率。文献[3]方法利用Snort系统快速检测操作引擎及原理,调整操作状态,弥补算法匹配过程中的不足。加强对数据集移动距离的计算力度,获取较为精准的算法信息数据,提升其算法运算效率,降低匹配次数差异率。而文献[4]方法虽完善了内部效率管理空间性能,但对于匹配操作的了解程度较低,未达到效率分析的标准,匹配次数差异较高。
在实现以上实验操作后,进一步验证本文分析方法的效率分析性能,对其分析过程中产生的内存占用率进行比较。将属于相同系统操作的内部存储空间进行清理,确保实验研究的精准性,避免无关数据的干扰,并转化数据链状态,调控内存信息,构建数据链转化图如图7所示。
调配存储性装置,将匹配算法空间内部的无关内存清空,保留原始匹配数据,在进行实验的同时注重对匹配原则的管理,防止匹配原则的外泄。时刻追踪匹配内存占用信息,掌控内部数据流通状况,检验不同匹配算法产生的内存占用量。根据获取的数据进行实验对比,构建实验对比图如图8所示。
由图8可得,文献[3]方法的分析内存占用率较大,文献[4]方法的分析内存占用率较小,本文基于大数据处理的模式匹配算法效率分析的分析内存占用率均低于其他两种传统分析方法。
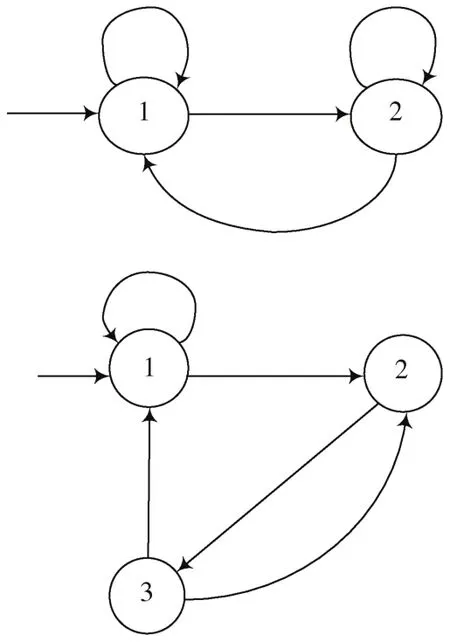
图7 数据链转化图
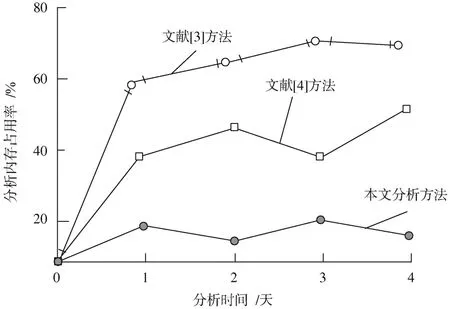
图8 分析内存占用率对比图
造成此种差异的原因在于:本文分析方法不断匹配相应的内部计算程序,精准掌握匹配算法的运算流程,及时清除干扰度较高的数据因素,控制匹配算法在分析过程中的完整性匹配,集中优化模式匹配算法的操作流程,追踪内部算法操作信息,并时刻管理不同的效率分析结构,在分析的同时获取高质量的数据流信息,减少分析内存的占用数量,分析内存占用率较低。
文献[4]方法利用规则软件系统规范算法数据的流通状况,减少不必要的数据内存占用数量,并在数据管理的过程中匹配相关的信息操控装置,监管分析空间内部的内存信息,在产生异常占用时,立刻清除内存数据,降低分析内存占用率。文献[3]方法虽缓解了分析过程中的数据压力,但未对分析空间进行系统分析,空间内部结构较为混乱,对于内存占用的了解程度较低,导致其分析过程中产生了大量的无关数据,分析内存占用率较高。
4 结 语
综上可知,本文基于大数据处理的模式匹配算法的效率分析效果良好,能够减少效率分析过程中的数据冲突,合理管理匹配算法的匹配程序,能够为后续研究操作提供较为精准的数据基础。
