基于有序Logistic回归的驾驶人危险辨识影响因素分析
2021-05-14王辛岩李天娇
王辛岩, 李天娇
(西藏大学工学院, 拉萨 850000)
危险辨识(hazard perception, HP)是驾驶人对客观交通环境中危险信息识别、预测与评估能力的体现,又称为危险感知、风险感知、危险知觉、危险认知、危险感受等。由驾驶人相关因素导致交通事故的占比很显著,驾驶人危险辨识是其中一项重要因素。中国台湾地区和国外较多国家均将危险辨识作为学员获取机动车驾驶证的重要考核内容。结合危险辨识的研究现状,就危险辨识的影响因素、动静态测试与能力提升三方面进行分析。
驾驶人危险辨识的影响因素是多方面的。吴初娜等[1]在对驾驶人危险辨识过程进行梳理的基础上,分析了驾驶人危险搜寻能力、危险决策能力和危险处置能力的影响因素,认为危险搜寻能力主要受视觉搜索策略和危险特征的影响,危险决策能力和危险处置能力主要受驾驶经验、年龄、性格、性别等的影响。基于英国驾驶人危险辨识能力测评软件(hazard perception test,HPT),余泰初等[2]分析了性别、年龄、驾龄以及场景特征对危险感知得分的影响,发现驾龄对得分的影响较年龄更显著,男性危险感知能力较女性更好,行人相关场景的得分最低。杨京帅等[3-5]针对驾驶人危险感知开展了较多研究,包括驾驶人危险感知模型的构建、基于交通场景的危险识别与反应测试,以及道路交通碰撞事故的致因分析,认为交通场景危险程度对驾驶人危险感知的总反应时间和识别时间有影响,驾驶经验对驾驶人危险识别时间没有显著影响,对反应时间有影响,且熟练驾驶人的危险感知水平较非熟练驾驶人更好,体现在更好的判断力和更高的自信程度。
同时,针对驾驶人危险辨识能力动静态测试场景的选择,吴初娜等[6]认为危险情境主观风险度与客观风险度之间的一致性会影响测评结果的可靠性,动态情境和静态情境在测试中各有利弊。静态场景有助于规避评估结果的模糊性,改善驾驶人测试过程中的心理感受,而动态场景则贴近实际驾驶活动中的危险辨识机制。Scialfa等[7-9]结合驾驶行为自我报告数据和危险辨识表现探讨了采用动态情境和静态情境进行驾驶人危险感知测试的效果,认为两种方式均能得到可信结果。
在提升驾驶人危险辨识能力的研究中,Castro等[10]分析了危险辨识培训视频对驾驶人危险辨识的改善效果,结果显示培训能够改善驾驶人发现突发危险(abrupt hazards)的能力,且对驾驶人发现渐进性危险(gradual hazards)的培训效果更好。华珺等[11]探讨了不同训练频次及不同丰富度的培训方式对提升新手危险辨识能力的影响,发现反复的训练能够提高驾驶人危险辨识能力并维持在一定水平,尤其是有针对性的教育指导。
以往驾驶人危险辨识影响因素研究中,较多采用单因素分析方法,且鲜有研究讨论驾驶人的交通经历对其危险感知能力的影响。然而,影响因素之间存在相互作用,驾驶人的交通经历对其危险辨识也可能存在一定影响。对此,进一步考虑驾驶人的交通经历及其中秩序情况,采用有序Logistic回归模型探讨驾驶人危险辨识的影响因素及其显著性。本文的创新点有:理论方面,在考虑多个人口社会学因素的基础上,基于多因素Logistic回归模型研究了其他交通工具的驾驶经历、以往驾驶经历中交通秩序情况以及交通情境特征对驾驶人危险辨识时间的影响,进一步丰富了驾驶人危险辨识的影响因素。应用方面,研究结果显示以往驾驶经历和交通情境特征对驾驶人危险辨识的影响是显著的,而驾龄和驾驶里程对危险辨识的影响并不显著。基于此,可在驾驶人管理中关注驾驶人危险辨识的真实水平,有针对性地进行相应的能力评估与安全教育。
1 试验与数据准备
1.1 试验设计
1.1.1 危险辨识平台的设计
为了开展试验,结合以往研究[5,9,12]设计了危险辨识数据采集平台。该平台不仅能够以图片形式展示交通情境,还能够记录被试的危险辨识数据。当被试认为某情境中存在对行车安全构成威胁的危险源时,可用鼠标单击危险源,该平台实时记录被试识别出危险源所需的时间,即作为“危险辨识时间”。该时间段为某情境出现至被试点击危险源。交通情境未被点击时,将相应的危险辨识时间标注为0,便于后期的数据处理。开发的危险辨识平台在笔记本电脑上运行,电脑为Win10系统,i5处理器,8 G内存,显示器大小为15.6 in(1 in=25.4 mm)。
原始情境通过车载录像采集,内容涉及行人过马路、前车切入、路口驶出车辆等。试验过程中,首先挑选两个交通情境供工作人员指导被试开展试验,进而挑选36个交通情境开展正式的试验。
1.1.2 被试自我报告数据
试验过程中,共有偿邀请了40名驾驶人作为被试参加危险辨识试验,并统计了被试的基本信息,如表1所示。被试的年龄在21~30岁,视力(含矫正视力)良好,均持有合法机动车驾驶证,拥有一定的驾驶经验。
同时,邀请被试开展评估工作。评估任务包括:①对危险辨识试验过程中所涉及交通情境的危险程度和混乱程度分别进行评估[9,12],用整数1~5来量化,数值越大代表相应的危险程度或混乱越高;②对其他交通工具的驾驶经历进行评估,涉及电动车/摩托车和自行车两方面,用整数1~3来量化,所赋数值越大代表相应的驾驶经历越丰富;③对个人以往驾驶经历中交通秩序进行评估,同样用整数1~3来量化,所赋数值越大代表相应的交通
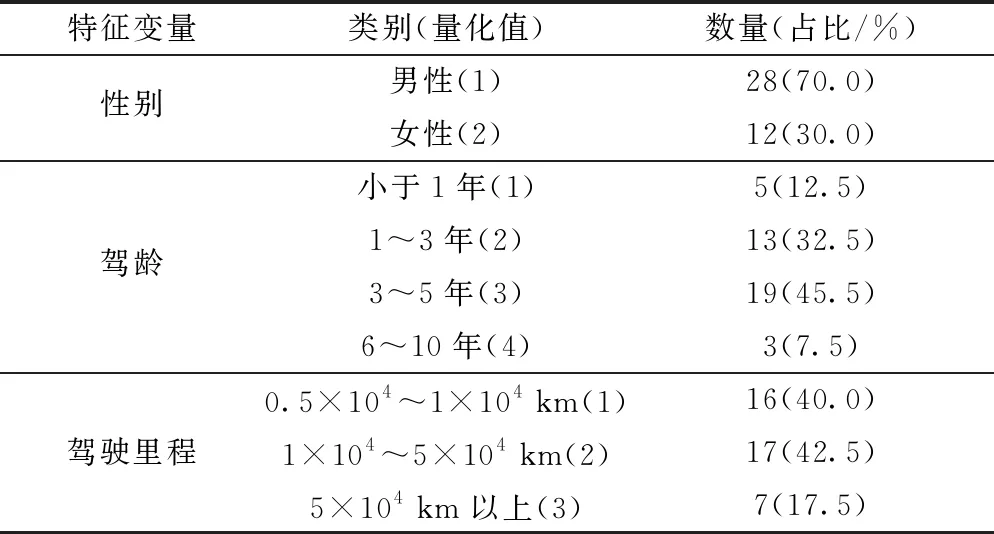
表1 被试基本信息
秩序越不理想。
1.1.3 试验过程
试验过程中,首先由工作人员介绍试验任务,并开展预试验。当确认被试了解试验内容后,开展正式的试验。试验过程可分为3项任务:①交通情境的危险辨识;②交通情境的危险程度和混乱程度评估;③被试个人信息、其他交通工具驾驶经历和交通秩序的自我报告。其中,规定任务②只能在任务①完成后开展,对任务③的顺序不作要求。
1.2 试验数据
1.2.1 数据预处理
数据预处理中发现,交通情境危险辨识数据中包含较多的“未点击”数据(143项),即某些情境被部分被试认为不存在危险源,即“未识别”。对此,为开展下一步分析,参考文献[9]中方法对其进行筛选。针对未识别次数较多的交通情境数据进行删除,且剩余交通情境中未识别数据也不纳入模型的估计。图1显示未识别次数较多地集中在4次及以下,占比为66.667%,其他未识别次数的占比明显偏小。基于此,剔除未识别次数大于4次的危险辨识时间数据,即删除了12组试验数据,包含97项未识别数据。
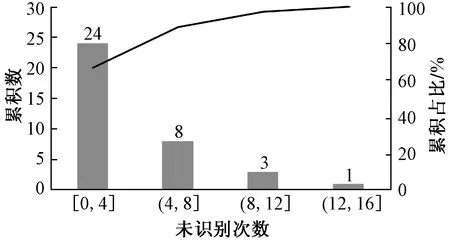
图1 交通情境未识别数量分布
被试的自我报告数据方面,对交通情境危险程度和混乱程度评估数据求取均值,得到每个交通情境在危险程度和混乱程度两方面的特征。对于被试其他3项的自我报告数据仅予以量化,不进行其他处理。
1.2.2 危险辨识数据类别划分
在实际中,无法对驾驶人的危险辨识能力进行精确评估,仅能了解大致水平。基于此,对被试危险辨识时间数据进行类别划分,进而纳入因素分析模型。k-means是一种应用范围广泛的聚类分析方法。借助该算法对被试危险辨识时间数据进行分类。危险辨识时间数据被组织为长度为914(40×24-143+97)的一维向量。k-means聚类分析算法需要将数据对象组织为类别集合C={ci,i=1,2,…,k},每个类别代表一类数据(簇),每个类别都有一个类别中心ci。由于k-means聚类算法需要先确定类别数量k,取k=3,即将危险辨识时间划分为3类,包括辨识时间短、辨识时间一般和辨识时间长。k-means聚类分析的具体步骤为[13]如下。
步骤1随机选择向量中3个数据对象作为初始聚类中心。
步骤2计算空间中数据对象到不同聚类中心的欧式距离d(x,ci),如式(1)所示,进而将数据分配到与其距离最近的聚类中心所在的簇。
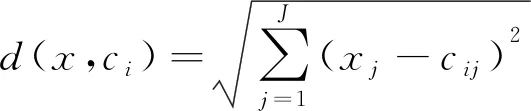
(1)
式(1)中:x为数据对象;ci为第i个聚类中心;J为数据维度;xj、cij分别表示x和ci的第j个属性值。
步骤3计算每个簇中数据均值,将其作为新的聚类中心。进一步计算所有簇的误差平方和(sum of squared error,SSE)为
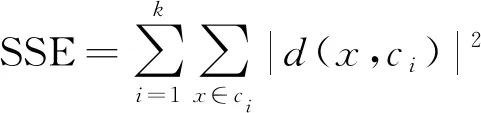
(2)
步骤4返回步骤2,直到SSE不发生变化,即各类总的距离平方和达到最小。
研究中基于MATLAB软件开展k-means聚类分析,得到属于辨识时间短、辨识时间一般和辨识时间长3类数据的数量分别为702、192和20,对应的聚类中心分别为2.094、4.688和11.752 s。
2 模型准备
在将危险辨识时间类别数据作为有序多分类的因变量时,需要通过拟合因变量数量(3个)减1个logit回归模型开展影响因素分析。考虑到不同影响因素对因变量影响的不同且类别变量较多,采用有序多分类Logistic回归模型进行分析。以具有3水平的因变量为例,定义等级概率p1、p2和p3,效应参数β,常数项α,则对于由n个自变量拟合的2个模型如式(3)和式(4)所示,相应参数可由SPSS软件直接估计[14]。
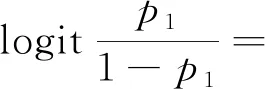
(3)
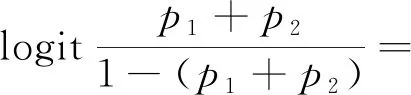
β1x1+…+βnxn
(4)
根据式(3)和式(4)可得到p1、p2和p3,即
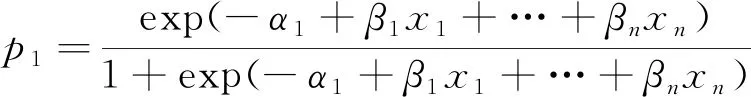
(5)
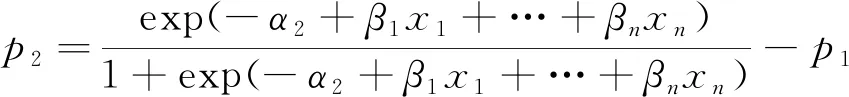
(6)
p3=1-p1-p2
(7)
相比等级概率p与常数项α,更关心效应参数β,用以分析不同因素对被试危险辨识时间的影响。
3 影响因素分析
3.1 模型估计结果
在模型的建立过程中,根据显著性大小对模型中纳入的自变量进行了调整。最初的参数估计结果如表2所示。涉及的自变量有交通情境的混乱程度v1、交通情境的危险程度v2,被试的性别v3、驾龄v4、驾驶里程v5、摩托/电动车驾驶经历v6、自行车驾驶经历v7、以往交通秩序混乱程度v8。同时,软件输出的模型拟合优度Pearson统计量和Deviance统计量均接近1,伪R2系数Cox and Snell、Nagelkerke和McFadden分别为0.075、0.106、0.063,说明该模型拟合程度较好[14]。
表2结果包含较多不显著的自变量。对此,将这些不显著的变量予以剔除并进一步估计,最终的参数估计结果如表3所示。
此时,涉及的自变量均处于较高的显著性水平(P<0.05),包含交通情境的混乱程度v1、交通情境的危险程度v2、性别v3、摩托/电动车驾驶经历v6和以往交通秩序混乱程度v8。同时,模型的拟合优度Pearson统计量和Deviance统计量分别为0.494和0.999,伪R2系数Cox and Snell、Nagelkerke和

表2 最初参数估计
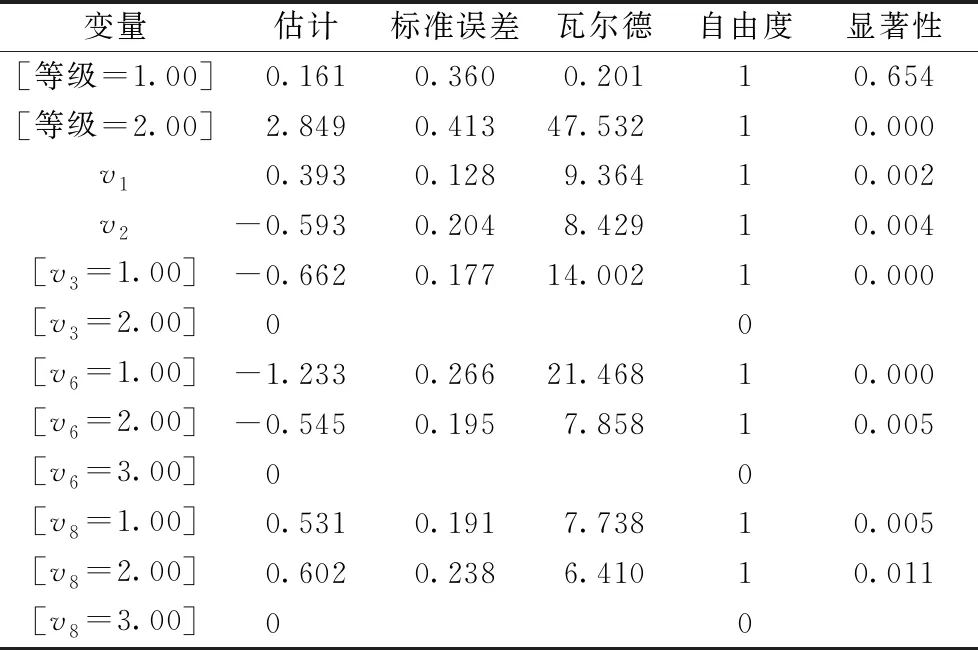
表3 最终参数估计
McFadden分别为0.062、0.088、0.052,说明模型的拟合程度理想。
由表3可得以下回归模型:

0.393v1-0.593v2-0.662v3-1.233v6-0.545v6+0.531v8+0.602v8
(8)

2.849+0.393v1-0.593v2-0.662v3-1.233v6-0.545v6+0.531v8+0.602v8
(9)
根据表3或式(8)和式(9)可知,在交通情境的特征方面,交通情境越混乱,辨识危险所需的时间越长;交通情境越危险,危险辨识时间相对越短。在被试特征方面,相比女性被试,男性被试危险辨识时间相对较短;摩托、电动车驾驶经历对危险辨识时间有影响,表现为经历越丰富,危险辨识时间相对越短;以往交通秩序混乱程度对危险辨识时间有影响,表现为以往所经历交通秩序越混乱,危险辨识时间相对越长。同时,驾龄、驾驶里程、自行车驾驶经历对其危险辨识时间并无显著的影响。
3.2 模型结果分析
(1)交通情境越混乱,辨识危险所需的时间越长。这是符合常理的,在混乱的信息中寻找危险信息相对简单背景下的危险信息搜寻更为困难。交通秩序越差的环境中,驾驶人工作负荷越大,反应能力越差,越容易诱发交通事故[15]。
(2)交通情境越危险,危险辨识时间相对越短。之所以出现该现象可能是由于危险程度越高,信息越突出,越容易被识别与判断。同时,采用图像展示交通情境,所包含的动态信息相对较少,危险源的位置更容易被确定。
(3)男性被试的危险辨识时间较女性更短。以往研究显示,性别对驾驶人的情境意识有影响,且女性驾驶人的辨识能力相对较差[2,16-17],本文结果与之类似。这可能与女性被试在危险判断过程中表现更为谨慎有关。
(4)摩托、电动车驾驶经历越丰富,危险辨识时间相对越短,但自行车驾驶经历对危险辨识时间并无显著影响。摩托、电动车的驾驶经历有助于驾驶人提高危险辨识能力,这可能是由于这些驾驶经历中存在较多与机动车驾驶经历类似的情境,而自行车的驾驶模式与摩托、电动车的驾驶模式存在着速度、动力、行驶条件等多方面的差异。
(5)以往交通秩序越混乱,危险辨识时间相对越长。以往驾驶经历中交通秩序越混乱意味着被试经历的危险交通情境越多,之所以导致被试危险辨识时间的增大,很可能是由于以往类似经历使其更加重视来自交通秩序的影响,进而在危险辨识中更为谨慎。
(6)驾龄、驾驶里程对危险辨识时间并无显著影响。以往研究显示,驾驶经验对驾驶人危险识别时间没有显著影响[3],本文结果与之类似。这可能是由于本文中被试者均为有合法机动车驾驶证的年轻驾驶人,即均具备一定的驾驶经验。同时,所建立模型还考虑了交通经历、情境特征等其他因素,这些因素的纳入使得驾龄与驾驶里程对危险辨识时间未能产生实质影响。针对危险辨识的培训能够提升并保持驾驶人的危险辨识能力[10-11],也从侧面支持了这一设想。
4 结论
驾驶人对危险的辨识关乎道路交通安全,分析驾驶人危险辨识时间影响因素有助于交通环境和驾驶人管理工作的开展。
道路交通环境和人口社会学因素对驾驶人危险辨识的影响的多方面的。交通情境的危险程度和混乱程度对的驾驶人危险辨识的影响是显著的。驾驶人性别及其以往驾驶经历对其危险辨识有影响。营造良好的交通氛围有助于降低驾驶人的工作负荷,有利于驾驶人的危险辨识与驾驶安全。
限于样本量和所考虑的指标数量,很多其他因素并未考虑。下一步的研究将尝试分析驾驶人及交通情境的其他指标,以及它们之间的交互作用对驾驶人危险辨识时间及危险辨识能力的影响。
