基于IFC标准的BIM自适应分词方法
2021-05-13周小平
张 鑫,周小平,2,王 佳,2
基于IFC标准的BIM自适应分词方法
张 鑫1,周小平1,2,王 佳1,2
(1. 北京建筑大学电气与信息工程学院,北京 100044; 2. 建筑大数据智能处理方法研究北京市重点实验室,北京 102616)
建筑信息模型(BIM)已经成为建筑行业信息技术应用的有效方案。随着BIM数据不断增长,为了高效使用BIM数据,很多研究将自然语言处理(NLP)引入BIM应用中。在中文环境中,由于缺乏建筑行业的术语特征,导致基础环节的中文分词在建筑领域BIM应用中的适应性较差。通过分析当前流行的BIM数据格式工业基础类(industry foundation class, IFC)文件,从中提取BIM模型特征,配合建筑领域术语特征加入分词模型中,以提高中文分词在建筑领域的性能。实验结果表明,与原始条件随机场(CRF)分词模型相比,在建筑领域测试集上,分词模型的F-measure提高了1.26%,其中,在仅加入BIM模型特征时,F-measure提升了0.10%,说明在分词模型中加入BIM模型特征对于提高中文分词在建筑领域的性能是有效的。同时,在BIM模型测试集上,相较于仅加入建筑领域术语特征,在加入BIM模型特征后,准确率从46.97%提升至87.74%,召回率从67.60%提升至94.77%,F-measure从55.43%提升至91.12%,提升了35.69%,有效提高了中文分词在建筑领域的BIM模型自适应性。
建筑信息模型;工业基础类;中文分词;模型自适应;建筑信息提取
建筑信息模型(building information model,BIM)是记录建筑设施物理特性与功能特性的数字信息模型[1]。BIM包含了建筑全生命周期中各阶段的详细信息,实现了其数据的互操作性,促进了建筑工程项目各参与方的有效协同[2]。目前,BIM已成为建筑工程行业(architecture,engineering and construction,AEC)工程信息化的有效解决方案和重要趋势[3],并在AEC内得到了广泛地研究和应用[4]。
随着项目的不断推进,作为记录建筑全部信息的知识库,BIM的数据量也在不断增大[5]。随之,信息超载的问题日益凸显,用户在BIM应用中获取所需要的信息时更加困难[6]。随着搜索引擎和新型信息系统的不断发展,用户习惯于利用自然语言来进行检索数据等操作。
在建筑领域中,为了提高BIM数据的使用效率,一些研究探索了自然语言处理(natural language processing,NLP)在各种BIM系统中的应用。WU等[7]提出了一种基于自然语言的BIM目标数据库和Revit建模智能搜索引擎,通过构建领域本体,从用户的自然语句中提取目标关键字并限制序列,结合关键字和约束序列的概念形成最终的查询,且通过本体中的语义关系对查询概念进行扩展,最终在BIM数据库中进行检索。实验结果表明,该方法的性能优于传统的基于关键字的方法。LIU等[8]提出了一种用于建筑业产品模型检索的显示语义分析方法,即利用扩展算法来解决术语不足问题,其次,提出了一种新的重定位方法解决概念粒度问题。实验结果表明,该方法显著提高了产品模型检索的性能。XIE等[9]结合BIM和NLP提出了将真实世界的设备同BIM项目中的构件相匹配的方法,并利用实际工程验证了该方法的有效性。然而,以上应用和方法在中文信息处理场景中的应用前提假设是可以正确的分词,但这些研究对于中文场景中的分词环节均未进行深入的探索和研究。本文提高中文分词在BIM应用中的自适应性,可以有效提高上述应用和方法在中文场景下的可用性。
因此,本文从BIM模型入手,首先以工业基础类(industry foundation class,IFC)文件为数据来源提取BIM模型信息。然后,以公共语料库为基础语料,分别将建筑领域术语特征和BIM模型特征信息标注后加入训练语料,利用条件随机场(conditional random fields,CRF)方法训练分词模型。最后,构建建筑领域测试集和BIM模型测试集,利用测试集验证本文方法的有效性。根据调查,在建筑领域的BIM智能信息场景和基于BIM的决策辅助应用中,本文研究是非常有必要且可行的[10]。
1 提取BIM模型特征
BIM是工程设施实体及其特性的完整数字化表达,旨在实现建筑全生命周期的信息集成和共享。作为贯穿建筑生命周期的信息交互方式,BIM被视为解决建筑行业“信息孤岛”和“信息流失”等问题的有效手段[11]。 IFC是一个开放和标准化的数据库,旨在实现AEC行业中构建信息建模软件应用程序之间的互操作性,从而能够在建筑物的整个生命周期实现高效率的信息流转[12]。在各种建筑数据模型交换格式中,IFC标准是当今世界各国政府和机构采用最广泛的公共开放数据模型[13]。IFC提供了可行的扩展机制和明确的语义信息结构,为获取BIM中的信息奠定了坚实的基础。本文对IFC中的信息进行分析,提取所需要的模型特征其仅指中文分词所需要的模型术语信息。
IFC只允许直接使用ISO8859-1编码表十进制32-126表示的字符[14]。任何其他的字符如中文汉字字符,在作为部分字符串值进行数据交换之前均需要经过编码。编码规则和解码规则在ISO10303-21工业自动化系统集成-产品数据表示和交换第21部分中介绍。例如在实际文件中的内容编码“X2987690E8504F79FBX0”字符串对应的解码内容为中文字符“顶部偏移”。其中,字符“S”为基本字母表中的字符,可代表扩展字母表中的相应位置的字符;字符“X”出现在一个字符串中表明下2个十六进制字符应该解释为一个8位字符;字符“X2”表示之后4个十六进制字符的倍数序列应该看作双字节的编码表示字符;字符“X4”表示之后的8个十六进制字符的倍数序列可用全编码空间的四字节表示。任何情况下,“X0”用来表示字符串编码的结束和一个在基本字母表中直接编码的返回标志。
1.1 模型特征信息
IFC标准定义了众多的建筑构件实体及大量的模型构件语义信息,包括建筑内的项目信息,构件之间的关联关系和属性信息,如项目周期、成本等模型基本信息。图1为北京建筑大学图书馆项目,以IFC结构为例,BIM中包含了很多个性化的模型信息,其中,不仅有对象名称信息和属性信息等模型术语信息,还有空间信息、项目信息、构件关系信息等。例如“图书馆建筑外墙”在这里是指模型中的一个墙构件对象的名称,诸如“底部偏移”、“顶部偏移”等均是模型内的属性名称,这部分模型特征术语是增强BIM模型自然语言理解的有效信息。在BIM信息处理过程中,主要是由于模型术语特征的缺失导致了分词性能的不佳。因此,本文需要在IFC文件中将BIM模型的特征术语进行收集并形成模型术语词典,将其分为对象名称、属性名称和其他价值。图1中,对象名称包括属性Name的值,而属性名称是定义所有IFC对象属性的名称列表。由于一些属性或属性值在BIM模型中可能是独有的,这些属性值属于第3类。对于IFCSpace对象,在Name属性被赋予编号之后,其名称会存储在LongName属性中。
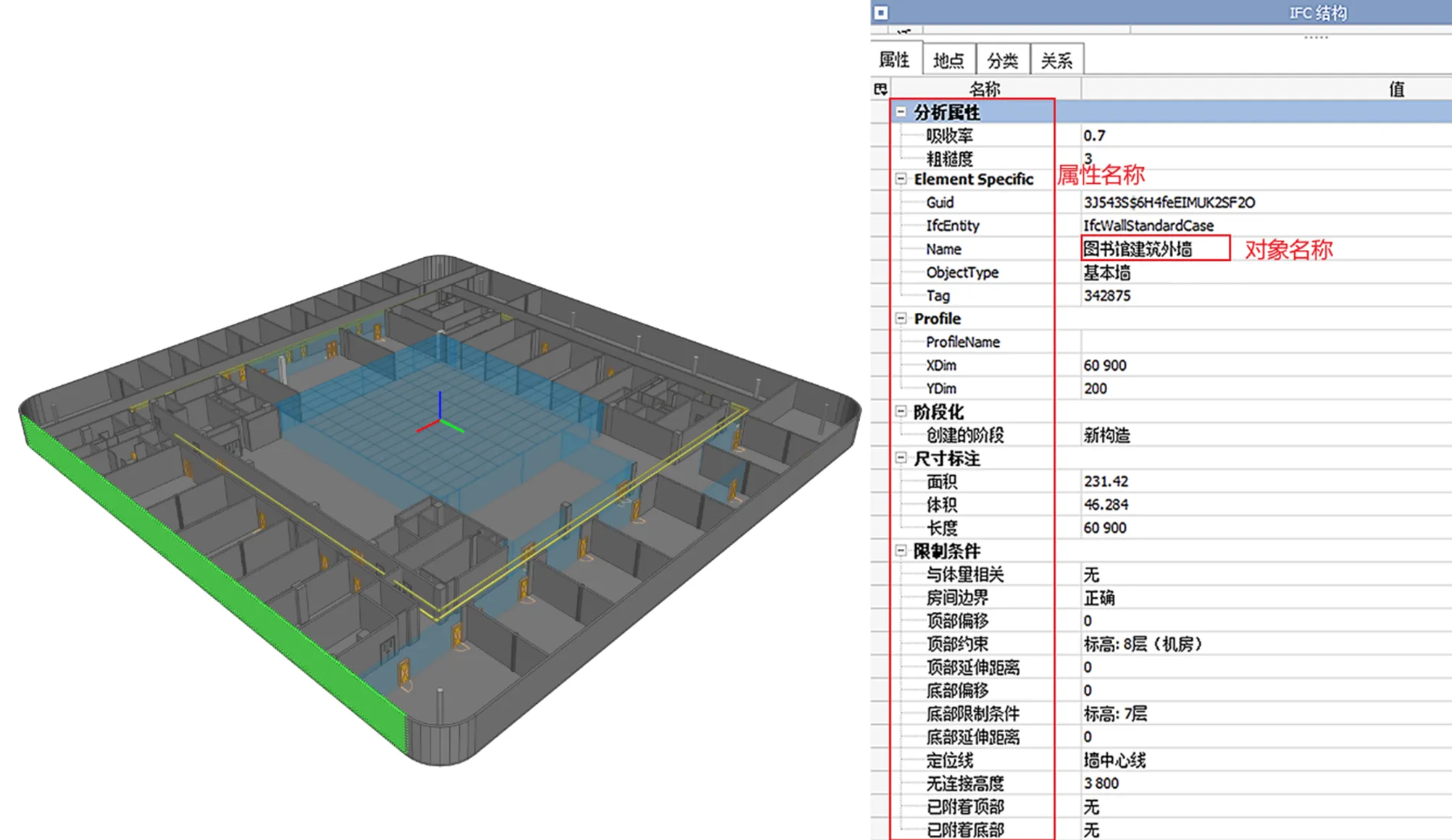
图1 BIM中的构件名称信息和属性名称信息
IFC标准经过数十年的发展,截止目前,IFC中拥有超过653个实体和300多个补充数据类型以及可扩展的属性集。图2描述了IFC标准语义要素以及要素之间的关联关系,IFC标准定义了大量的建筑构件类,包括IfcWall、IfcDoor、IfcBeam、IfcSlab、IfcColumn、IfcStair等,这些构件类均继承于IfcBuildingElement,其是建筑构件类的父级;IfcOpeningElement为建筑物的开口要素类,其作用是明确构件要素之间的包含关系,例如IfcWindow与IfcWall就需要IfcOpeningElement来充当中间要素;IfcSpitialStructureElement代表的是IFC的空间结构要素,其继承类包括IfcProject、IfcSite、IfcBuilding、IfcBuildingStorey、IfcSpace,这些类分别代表了空间结构的不同级别,不同层的空间要素需要IfcRelAggregates连接类进行连接,IfcElement与IfcSpatialStructureElement的连接也同样需要通过IfcRelAggregates来实现。在buildingSMART发布的IFC 4.0说明文档[15]中,表1给出了几条定义,为本文所需要的BIM模型特征信息。
1.2 提取模型特征信息
通过1.1节对BIM模型特征的定义,本文对IFC文件进行分析,IFC文件结构如图3所示。在IFC标准中,IfcRoot是所有实体类定义的最抽象的根类。IfcRoot的第3个参数即为Name属性的值,换言之,第3个参数即为IFC实例的对象名称。图3展示了编号为#21134的IFCSpace实例。其中,第1个参数“3TW89BcuP5$PFoInu5k$Jg”是该实例的GUID,第2个参数“#33”定义了#21134的所有权信息,第3个参数“202”即#21134的名称。显然,提取给定IFC实例的Name属性是可行的。
LongName属性仅在具有专业名称的类中定义。例如在IfcSpatialStructureElement中,其表示空间名称的全称,如图3所示,IfcSpace实例#21134作为IfcSpatialStructureElement的子类,第8个参数为“X28D705ECAX0”,解码后为“走廊”即为LongName的值。
IFC属性主要由IfcProperty,IfcExtended Properties和IfcPropertyEnumeration等实例来描述。属性名是IfcProperty,IfcExtendedProperties和IfcPropertyEnumeration中的第一个属性。因此,可以直接从IfcProperty,IfcExtendedProperties和IfcPropertyEnumeration实例中的第一个属性的值获得属性名。以IfcPropertySingleValue #21261为实例。IfcPropertySingleValue类是IfcProperty的子类。第一个属性的值是“X2987690E8504F79FBX0”,解码后是“顶部偏移”,其是IfcSpace实例#21134的属性名之一。
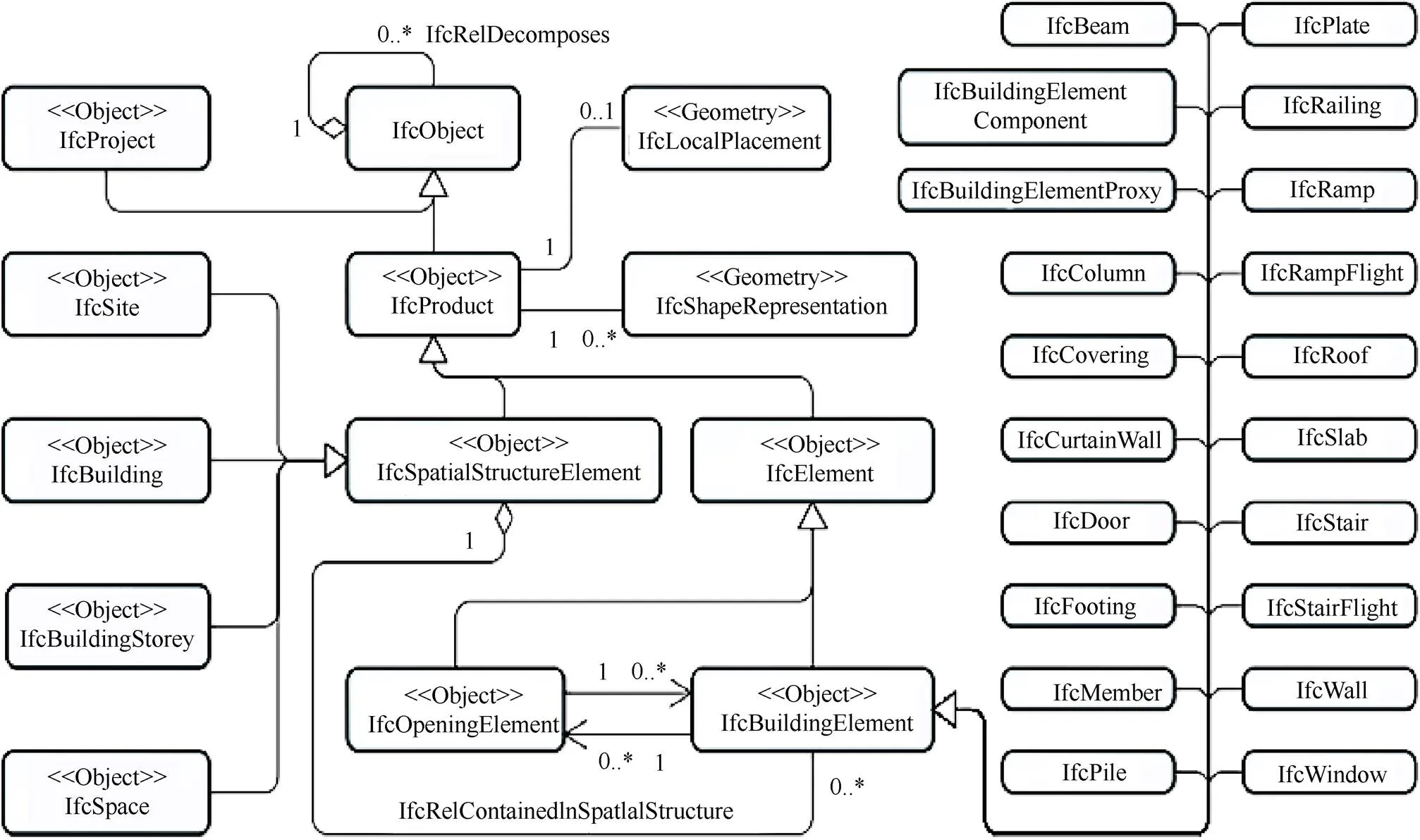
图2 IFC标准语义要素

表1 IFC 4.0中定义的模型信息

图3 IFC文件中的模型特征
表2列出了BIM模型专有词汇表需要收集的IFC实例属性值,其中包括IFC类型,该类型需要提取的属性名称,以及待提取参数的位置和参数的信息。算法1总结了BIM模型特征提取的整个过程。假设一个IFC文件有||个IFC实例,IFC标准定义了个类,可以计算出算法1的时间复杂度为(× ||)。
算法1. BIM模型特征提取
输入:IFC file
输出:BIM特征词典D
1. function BIMDicExtract():
2. BIM dictionary D = {}
3. for each instancein:
4.class of
5. ifis a class or subclass of IfcRoot:
6.= value of 3rdparameter
7. D = D∪ {}
8. end if
9. ifis a class or subclass of IfcSpatialElement:
10.= value of 8thparameter
11. D = D∪ {}
12. end if
13. ifis a class or subclass of IfcProperty
or IfcExtendedProperties
or IfcPropertyEnumeration:
14.= value of 1stparameter
15. D = D ∪ {}
16. end if
17. end for
18. Remove empty values from D.
19. returnD
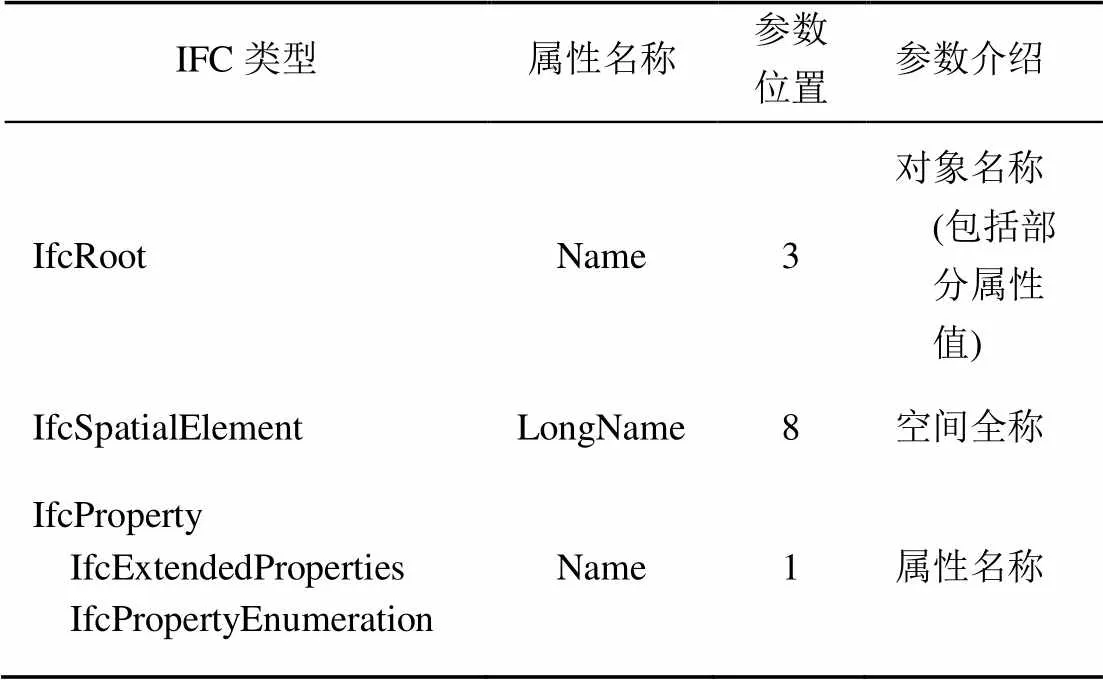
表2 BIM模型特征提取参数
2 训练BIM自适应分词模型
中文分词是将中文文本(汉字序列)分割成单词的任务,作为NLP领域中文信息处理的基础性工作,在搜索引擎、文本分类、自动摘要等任务上均发挥重要作用。自从XUE[16]将中文分词任务抽象成序列标注问题以来,CRF成为了统计机器学习方法中的主流[17]。当前,以卷积神经网络(convolutionalneuralnetwork,CNN)、循环神经网络(recurrentneuralnetwork,RNN)、长短时记忆网络(short - and long-term memory networks, LSTM)等深度学习模型在NLP任务上的性能不断提升,受限于训练资源和代码迁移等客观条件,本文采用了CRF结合特征词典的方法训练自适应分词模型。
2.1 训练基础分词模型
CRF在建模时考虑了数据的内容信息和数据标签之间的变化信息,其相关模型在基于统计机器学习的NLP任务中取得了较好的结果[18]。在基于字标注的序列标注问题中,句子中的每个字符可根据其在词中的位置进行分类,在当前使用最广泛的4-tag标记法中,共分为,,,4类。其中,代表该字符是在一个词的开始;表示在一个词的中间位置;表示在一个词的结束位置;表示该字符可以独立地构成一个词。如图4所示即一个中文分词序列标注示例。

图4 中文分词序列标注示例

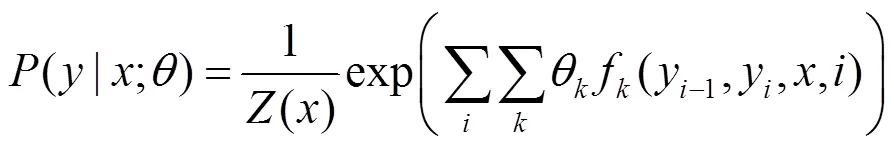
其中,为标注语料的取值;为字状态的取值;为特征函数;为对应的权值;()为标准化因子,是所有可能的状态序列之和,即
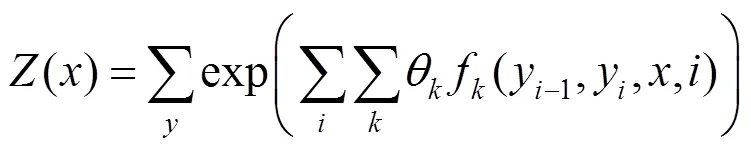
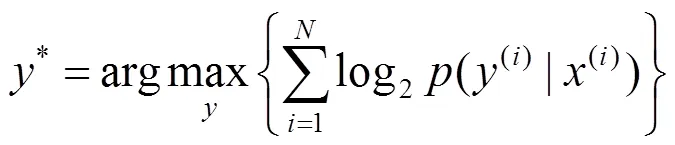
在本文中CRF中文分词模型所使用的基本特征见表3。其中下标代表着距离当前字符的相对位置,例如1表示当前字符的下一个字符。(0,1)表示0和1是否为2个完全一样的字符,(C)表示字符C的类型。
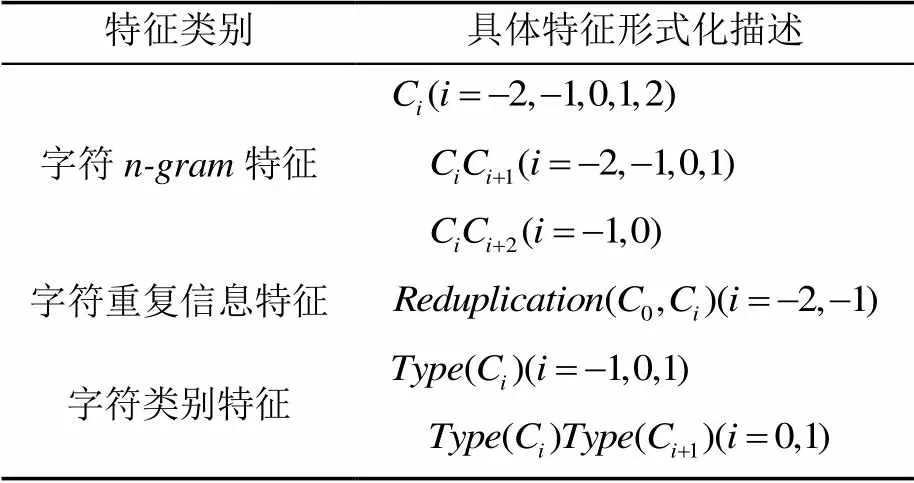
表3 CRF中所使用的基本特征
2.2 分词自适应性的实现
一直以来,统计中文分词都面临着专业领域适应性的问题,这是因为在训练语料中缺乏专业领域特征所导致的[19]。在BIM模型中,许多空间和构件的属性信息是项目中所独有的,同时由于这些特征过于分散,难以形成大规模的标注语料,因此,本文将BIM模型特征提取成模型特征词典,采用将术语相关特征标注后加入训练语料重新训练分词模型,通过将术语特征融入统计中文分词模型的方法,提升分词模型的适应性。在本文实验中发现,融入术语特征后,模型对于词的分割位置表现较好,然而对于较长的术语则表现不佳,因此,本文在分词流程中增加了利用最大匹配方法来进行合并分词结果的环节,其自适应分词优化流程如图5所示。
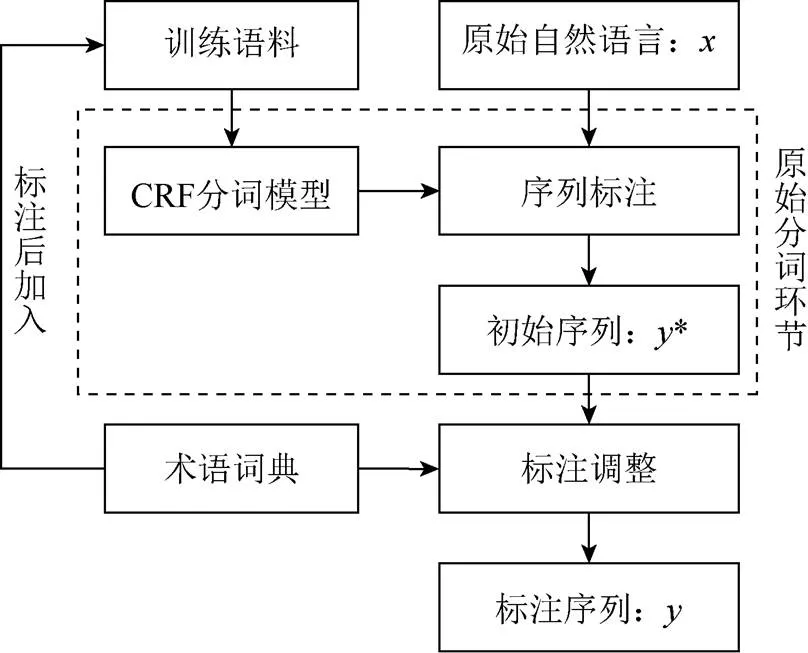
图5 BIM分词优化流程
在中文分词中,首先需提取原始自然语言的序列特征,由CRF分词模型进行序列标注,得到初始序列*。然而,由于缺少BIM模型特征,原始语料训练的分词模型得到的序列*在模型术语上面的正确性还不足以满足BIM应用的需要。因此,需要利用BIM模型征调整序列标注,通过将词典特征标注后加入训练语料训练模型可以将术语特征有效地应用到标注调整中,对于将一个术语标注成2个词语的情况,最大匹配法可以将其合并为正确的术语。本文最大匹配方法只会从词的分割处进行合并,不会将CRF标注为一个词的结果重新切分为2部分。图6展示了从原始CRF模型生成的序列*,在通过将术语特征词典标注后加入训练语料中得到的CRF分词模型预测生成标注序列的过程。如图6中“五层西南强电间的双击双控开关”,由于缺少BIM模型特征,基础分词模型将其切分成了“五层”、“西南”、“强电间”、 “的”、“双击”、“双控”、“开关”等词,在使用添加有模型术语特征的自适应分词模型之后,“西南”和“强电间”融合成为“西南强电间”,“双击”、“双控”、“开关”融合成为“双击双控开关”,其中“西南强电间”是BIM模型中的空间名称,“双击双控开关”是BIM模型中的构件名称,两者均是从BIM模型中提取的模型术语。
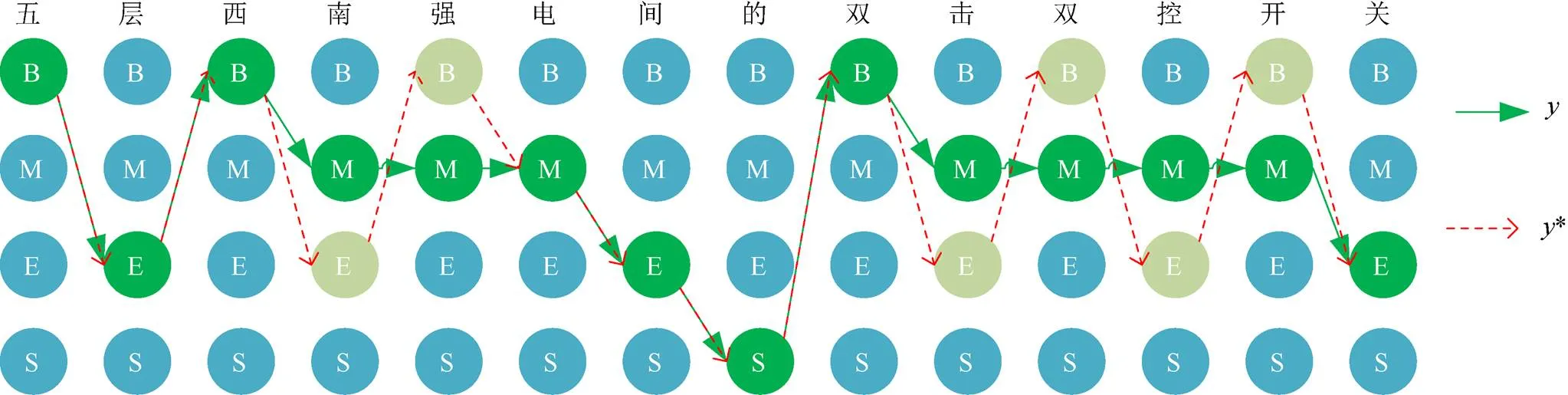
图6 从原始序列y*到标注序列y
3 实 验
为了验证本文所提方法的有效性,采用SIGHAN CWS BAKEOFF 2005中提供的PKU标注语料作为训练语料训练基础分词模型,建筑领域术语特征使用了搜狗(https://pinyin.sogou.com/dict/)整理的建筑工程领域术语词典,然后从中华建筑工程管理网(http://www.ctnoc.com/)抓取的建筑领域文章人工标注后建立的建筑领域测试集和北京建筑大学图书馆的BIM模型(图7,1.22 GB)及其设备安装点位表数据构成的测试集进行了不同的对照实验。本文实验部分采用CRF++工具包(https://taku910.github.io/crfpp/)进行训练和标注,其中实验结果部分采用SIGHAN 2005中所给出的评价程序进行评价。
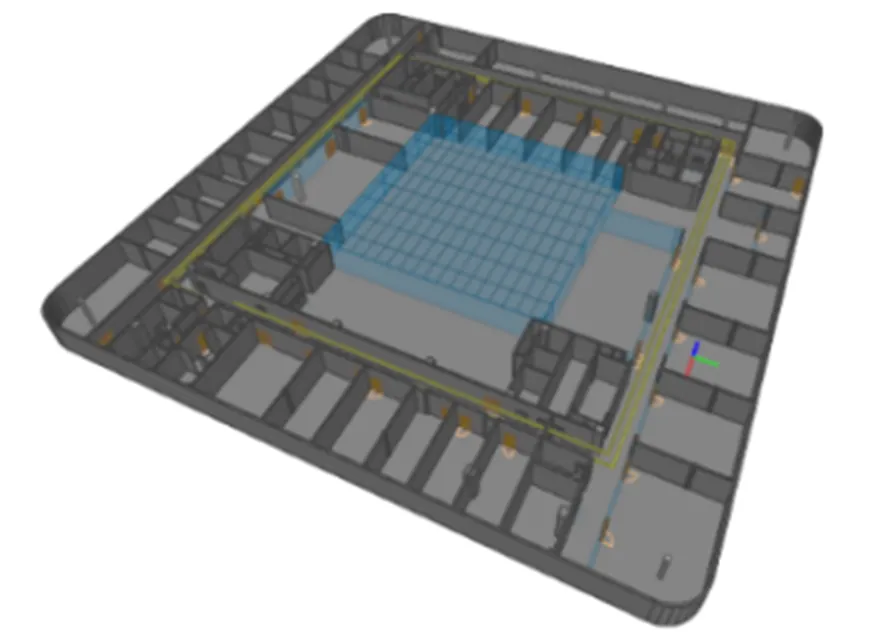
图7 北京建筑大学图书馆BIM模型
3.1 实验设置
3.1.1 评价指标
分词性能的测试标准主要分为准确率、召回率和F-measure值,分别用,,表示。其中,准确率表示分词模型分词的准确程度;召回率也称为查全率,表示分词模型切分正确的词占正确结果的比率;F-measure值综合反映分词模型的整体指标,即


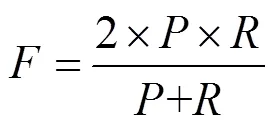
3.1.2 数据测试集
(1) 建筑领域测试集。在建筑信息领域的中文分词研究中,没有公开的测评语料库。因此,本文抓取了中国建筑施工技术管理网上的1 300篇文章用作构建建筑领域测评语料。这些文章中包含了大量建筑工程领域的术语和概念,从中选取了3 200句语料组成建筑领域语料测试集。
(2) BIM模型测试集。建筑设备安装点位表即工程项目中建筑设备的具体安装信息,包括设备名称、编号和安装位置,能有效地提供对应BIM模型中的空间和设备信息,可用作测试中文分词在BIM模型上的测试数据集。本文采用的北京建筑大学图书馆设备点位表共包含1 193项设备安装信息(设备类型和所在位置),表4为建筑消防设备点位表。
3.1.3 实验设计
CRF-Original为原始语料训练出来的基础分词模型;CRF-Domain为加入建筑领域术语词典后的分词模型;CRF-BIM为加入BIM模型特征词典后的分词模型;CRF-Extern为融合BIM模型特征词典和领域术语词典之后的分词模型。
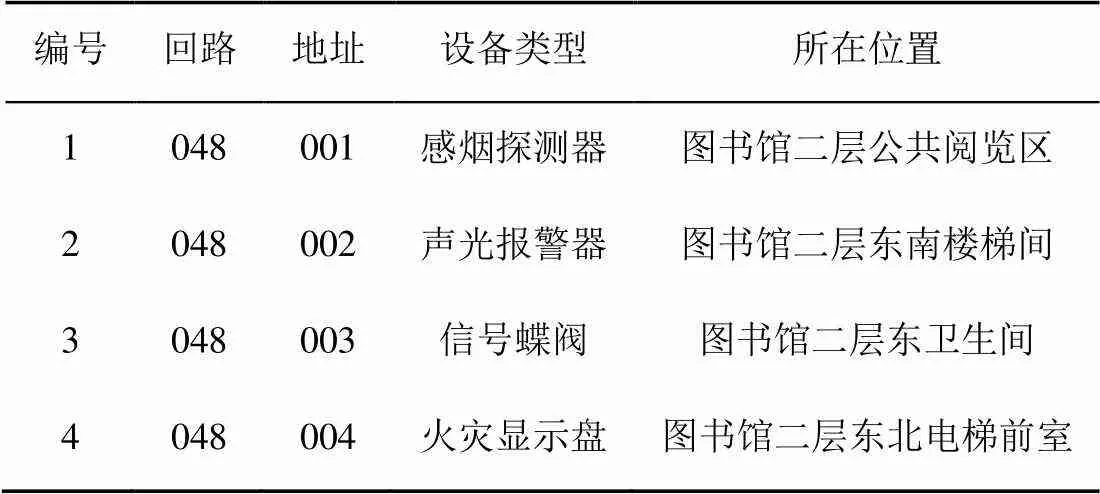
表4 建筑消防设备安装点位表示例
实验1.在建筑领域测试集上,分别验证CRF-Original,CRF-Domain,CRF-BIM和CRF-Extern的分词性能,验证领域术语特征和BIM模型特征对于分词模型在建筑领域文本上性能提升的有效性。
实验2.在BIM模型测试集上,分别验证CRF-Original,CRF-Domain,CRF-BIM和CRF-Extern的分词性能,验证模型特征对于BIM模型分词性能提升的有效性。
3.2 实验结果及分析
表5给出了在建筑领域测试集上的测试结果,可以看出,与CRF-Original相比,CRF-Extern的准确率提高了2.66%,召回率降低了0.72%,F-measure值提升了1.26%。其中,在只添加BIM模型特征时,准确率提升了0.12%,召回率提升了0.07%,F-measure提升了0.10%,证明了添加BIM模型特征对于提升建筑领域的分词性能是有效的。
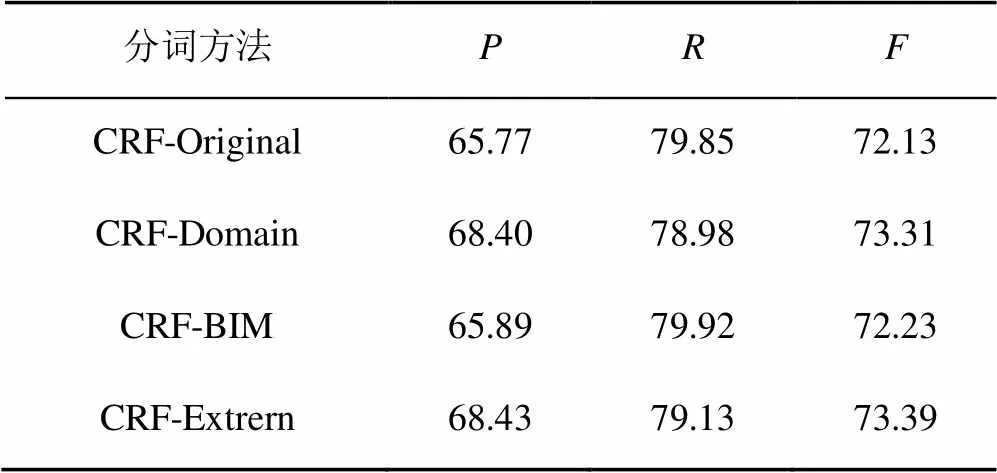
表5 建筑领域测试集测试结果(%)
表6为在BIM模型测试集上的测试结果,对比CRF-Original和CRF-Domain的测试结果可以看出,F-measure在提升后仅为55.43%,该实验结果说明仅仅添加建筑领域特征对于BIM模型分词性能提升极有限。对比CRF-Original,CRF-Domain和CRF-Extern可以看出,加入BIM模型特征后,分词性能有了很大的提升。与仅加入建筑领域术语特征相比,准确率从46.97%提升到87.74%,召回率从67.60%提升到94.77%,F-measure从55.43%提升到91.12%,提升了35.69%,表示本文方法能够有效解决BIM应用中模型术语识别不佳的问题。其中,存在的一些切分错误主要是由于设备点位表中的术语信息和BIM模型文件中的术语信息不同导致的。
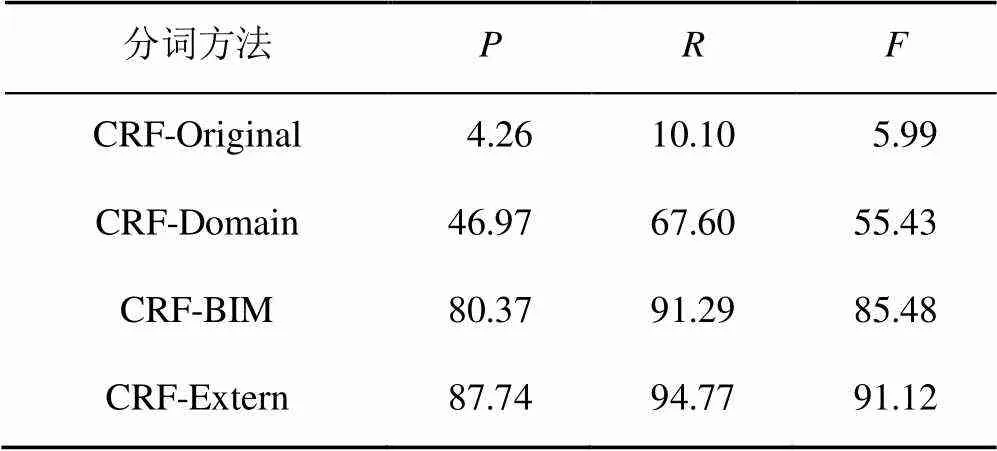
表6 BIM模型测试集测试结果(%)
从以上实验可以看出,①向统计分词模型中添加词典特征可以有效提升中文分词在建筑领域的分词性能;②在建筑信息领域的BIM应用中,仅仅添加领域术语特征不足以有效提升中文分词在BIM模型自适应性上的需要;③通过将模型术语特征和领域术语特征一起融入中文分词模型中,可以有效提高中文分词在建筑领域BIM应用中的自适应性。
4 总结和展望
本文通过分析存储BIM信息的IFC文件数据,从中提取BIM模型相关的术语特征词典,然后通过将BIM模型特征词典配合领域术语特征添加进入中文分词模型的方式来提升中文分词在建筑领域的自适应性。由于BIM是当前建筑领域信息技术应用的主要方案,当面对不同的BIM模型时,只需要提取其模型特征词典加入到中文分词模型中即可。实验表明,本文方法有效提高了中文分词在建筑领域BIM应用中的自适应性。
本文方法虽有效提高了中文分词在BIM应用中的自适应性,然而术语信息仍有歧义问题有待解决,下一步将考虑引入国际字典框架(international dictionary framework,IFD)来解决这一问题。
[1] ZHANG J, EL-GOHARY N M. Automated extraction of information from building information models into a semantic logic-based representation[C]//2015 International Workshop on Computing in Civil Engineering. Reston: American Society of Civil Engineers, 2015: 173-180.
[2] KANG T W, CHOI H S. BIM-based data mining method considering data integration and function extension[J]. KSCE Journal of Civil Engineering, 2018, 22(5): 1523-1534.
[3] SANTOS R, COSTA A A, GRILO A. Bibliometric analysis and review of Building Information Modelling literature published between 2005 and 2015[J]. Automation in Construction, 2017, 80: 118-136.
[4] PEZESHKI Z, IVARI S A S. Applications of BIM: a brief review and future outline[J]. Archives of Computational Methods in Engineering, 2018, 25(2): 273-312.
[5] ZHOU X P, ZHAO J C, WANG J, et al. Towards product-level parallel computing of large-scale building information modeling data using graph theory[J]. Building and Environment, 2020, 169: 106558.
[6] LIN J R, HU Z Z, ZHANG J P, et al. A natural-language- based approach to intelligent data retrieval and representation for cloud BIM[J]. Computer-Aided Civil and Infrastructure Engineering, 2016, 31(1): 18-33.
[7] WU S F, SHEN Q Y, DENG Y C, et al. Natural-language-based intelligent retrieval engine for BIM object database[J]. Computers in Industry, 2019, 108: 73-88.
[8] LIU H, LIU Y S, PAUWELS P, et al. Enhanced explicit semantic analysis for product model retrieval in construction industry[J]. IEEE Transactions on Industrial Informatics, 2017, 13(6): 3361-3369.
[9] XIE Q S, ZHOU X P, WANG J, et al. Matching real-world facilities to building information modeling data using natural language processing[J]. IEEE Access, 2019, 7: 119465-119475.
[10] 王煜, 邓晖, 李晓瑶, 等. 自然语言处理技术在建筑工程中的应用研究综述[J]. 图学学报, 2020, 41(4): 501-511. WANG Y, DENG H, LI X Y, et al. A review of natural language processing application in construction engineering[J]. Journal of Graphics, 2020, 41(4): 501-511 (in Chinese).
[11] SUCCAR B. Building information modelling framework: a research and delivery foundation for industry stakeholders[J]. Automation in Construction, 2009, 18(3): 357-375.
[12] LAAKSO M, KIVINIEMI A O. The IFC standard: a review of history, development, and standardization, information technology[J]. Electronic Journal of Information Technology in Construction, 2012, 17(9): 134-161.
[13] AZZRAN S A, IBRAHIM K F, TAH J H M, et al. Assessment of open BIM standards for facilities management[M]// Innovative Production and Construction. WORLD SCIENTIFIC, 2019: 247-259.
[14] NEPAL M P, STAUB-FRENCH S, POTTINGER R, et al. Ontology-based feature modeling for construction information extraction from a building information model[J]. Journal of Computing in Civil Engineering, 2013, 27(5): 555-569.
[15] BuildingSMART. IFC4说明文档,BIM时代的数据标 准[EB/OL]. (2013-05-31) [2020-08-05]. http://www.vfkjsd.cn/ ifc/ifc4/index.htm.
[16] XUE N W. Chinese word segmentation as character tagging[J]. Computational Linguistics & Chinese Language Processing, 2003, 8(1): 29-47.
[17] 黄昌宁, 赵海. 中文分词十年回顾[J]. 中文信息学报, 2007, 21(3): 8-19. HUANG C N, ZHAO H. Chinese word segmentation: a decade review[J]. Journal of Chinese Information Processing, 2007, 21(3): 8-19 (in Chinese).
[18] 邓丽萍, 罗智勇. 基于半监督CRF的跨领域中文分词[J]. 中文信息学报, 2017, 31(4): 9-19. DENG L P, LUO Z Y. Domain adaptation of Chinese word segmentation on semi-supervised conditional random fields[J]. Journal of Chinese Information Processing, 2017, 31(4): 9-19 (in Chinese).
[19] 张梅山, 邓知龙, 车万翔, 等. 统计与词典相结合的领域自适应中文分词[J]. 中文信息学报, 2012, 26(2): 8-12. ZHANG M S, DENG Z L, CHE W X, et al. Combining statistical model and dictionary for domain adaption of Chinese word segmentation[J]. Journal of Chinese Information Processing, 2012, 26(2): 8-12 (in Chinese).
A model adaptive method for Chinese word segmentation using IFC-based building information model
ZHANG Xin1, ZHOU Xiao-ping1,2, WANG Jia1,2
(1. School of Electrical and Information Engineering, Beijing University of Civil Engineering and Architecture, Beijing 100044, China;2. Beijing Key Laboratory of Intelligent Processing for Building Big Data, Beijing 102616, China)
The building information model (BIM) has become an effective solution to information technology applications in the construction industry. With the continuous increase of BIM data, natural language processing (NLP) has been introduced into BIM applications in many studies to effectively utilize BIM data. In the Chinese language environment, due to the absence of terminology features in the building field, Chinese word segmentation cannot be efficiently adapted in BIM application. By analyzing the currently popular industry foundation class (IFC) files in BIM data format, this study extracted BIM model features from IFC files and added them together with architectural terminology characteristics into the statistical word segmentation model, thus improving the adaptability of Chinese word segmentation in the building field. The experimental results show that compared with the original conditional random fields (CRF)based word segmentation model, on the domain test set, the F-measure increased by 1.26%, and F-measure still increased by 0.10% with BIM model features added alone, indicating that appending BIM model features to the segmentation model can effectively improve the performance of Chinese word segmentation in the building field. Meanwhile, on the model test set, compared with the case of architectural terminology characteristics being appended alone, after BIM model features were appended, the precision rate increased from 46.97% to 87.74%, the recall rate from 67.60% to 94.77%, and the F-measure from 55.43% to 91.12% (by 35.69%), thereby effectively boosting the BIM model adaptability of Chinese word segmentation in the building field.
building information model; industry foundation classes; Chinese word segmentation; model adaptation; building information extraction
TP 391
10.11996/JG.j.2095-302X.2021020316
A
2095-302X(2021)02-0316-09
2020-09-24;
24 September,2020;
2020-10-30
30 October,2020
国家自然科学基金项目(71601013);北京市自然科学基金项目(4202017);北京市青年拔尖人才培育项目(CIT&TCD201904050);北京建筑大学青年英才项目;北京建筑大学市属高校基本科研业务费专项资金(X20039)
National Natural Science Foundation of China (71601013); Beijing Municipal Natural Science Foundation (4202017); Beijing Youth Talent Training Project (CIT&TCD201904050); Young Elite of Beijing University of Civil Engineering and Architecture; The Fundamental Research Funds for Beijing University of Civil Engineering and Architecture (X20039)
张 鑫(1996-),男,陕西渭南人,硕士研究生。主要研究方向为建筑信息模型、自然语言处理。E-mail:happyirick@gmail.com
ZHANG Xin (1996-), male, master student. His main research interests cover BIM, NLP. E-mail:happyirick@gmail.com
周小平(1985-),男,福建宁德人,副教授,博士,硕士生导师。主要研究方向为大数据挖掘、人工智能和建筑信息模型。E-mail:lukefchou@gmail.com
ZHOU Xiao-ping (1985–), male, associate professor, Ph.D. His main research interests cover big data mining, artificial intelligence and BIM. E-mail:lukefchou@gmail.com
