Stacking集成模型模拟膜下滴灌玉米逐日蒸散量和作物系数
2021-05-12陈志君朱振闯孙仕军王秋瑶苏通宇付玉娟
陈志君,朱振闯,孙仕军,王秋瑶,苏通宇,付玉娟
·农业水土工程·
Stacking集成模型模拟膜下滴灌玉米逐日蒸散量和作物系数
陈志君,朱振闯,孙仕军,王秋瑶,苏通宇,付玉娟※
(沈阳农业大学水利学院,沈阳 110866)
为准确模拟膜下滴灌玉米逐日蒸散量和作物系数,该研究以4个经典机器学习模型:随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)、BP神经网络(BackPropagation Neural Network,BP)和Adaboost集成学习模型(Adaboost,ADA)为基础,基于Stacking算法建立了集成学习模型(Linear Stacking Model,LSM)对膜下滴灌玉米逐日蒸散量和作物系数进行模拟。并将LSM的模拟精度与RF、SVM、BP和ADA模型的模拟精度相比较,结果表明:1)RF、SVM、BP和ADA模型模拟膜下滴灌玉米的逐日蒸散量和作物系数时的相对均方根误差均大于0.2;2)相比RF、SVM、BP和ADA模型,LSM模型提高了玉米逐日蒸散量和作物系数模拟精度。LSM模拟的膜下滴灌玉米的作物系数相比于FAO推荐值更接近实测值;3)日序数、平均温度、株高、叶面积指数和短波辐射5个特征对玉米膜下滴灌玉米日蒸散量和作物系数影响最高,基于这5个特征建立的LSM模型模拟膜下滴灌玉米的蒸散量和作物系数的R分别为0.9和0.89,相对均方根误差分别为0.23和0.16。因此,建议在该研究区使用日序数、平均温度、株高、叶面积指数和短波辐射5个特征参数建立LSM模型模拟膜下滴灌玉米蒸散量和作物系数。该研究可为高效节水条件下作物蒸散量和作物系数的精准模拟和合理制定灌溉制度提供参考。
蒸散;模型;温度;机器学习;Stacking集成学习;膜下滴灌;作物系数
0 引 言
作物实际蒸散量(Crop Evapotranspiration, ETa)是指作物实际通过地表和叶面的蒸发和植株蒸腾作用损失的水量[1]。ETa的准确计算和模拟对于提高农业水利用效率和制定合理的灌溉制度具有重要意义[2]。FAO-56文件中提供了各类作物(玉米、水稻和小麦等)在不同生育阶段作物系数的推荐值[1]。但FAO-56推荐的作物系数多是关于时间的函数,并没有考虑土壤环境、作物生长情况和气象条件等对其的影响[3]。大量研究表明作物系数随着作物种类、地区和气象环境等变化而变化,因而使用FAO推荐的作物系数计算ETa存在较大的误差[4-5]。这种差异在非常规条件下(如地膜覆盖等)显得更加突出[3]。这是因为地膜覆盖一方面显著减少了土壤蒸发量降低了土壤蒸发系数,另一方面增加了作物的蒸腾量,进而增加了作物系数[6]。为此FAO也提出了修正方法,认为覆膜使作物系数降低了约10%~30%[1]。但即使修正后的推荐值与实际值之间仍存在较大误差[7-8]。Li等[9]研究表明,对于覆膜种植的春小麦而言,FAO-56文件提供的作物系数明显小于实际值;Shrestha等[10]研究表明,覆膜种植的西瓜和辣椒的实际作物系数与FAO-56推荐值之间的差异较大。为进一步提高ETa计算精度,很多学者在不同地区采用蒸渗仪试验,通过基于水文过程的物理模型探索特定条件下的作物系数值[11]。但传统试验成本较高,而且基于水文理论模型对复杂的自然环境进行简化,也会导致最终计算精度不理想[12]。随着机器学习算法的发展,一些学者开始使用机器学习代替传统的基于水文理论模型进行ETa计算和模拟,通过机器学习的强大非线性功能,描述复杂的自然环境对作物蒸散量的影响[3,5,13-14]。Shrestha等[3]在佛罗里达州使用支持向量机模型,利用灌水频率、降水频率、气象资料和播种后天数等指标模拟和计算了半个月尺度的作物系数和ETa,结果表明,支持向量机模型能够较为准确地计算作物系数和ETa。然而,该模型缺点是并未考虑作物生长和田间水热环境对耗水的影响。此外,有研究表明,集成多个单一经典机器学习模型能够有效提高模型的模拟精度,尤其是基于Stacking策略的集成学习模型[15]。袁培森等[16]使用Stacking策略融合了支持向量机和随机森林等基础模型对水稻表型组学实体进行分类,发现基于Stacking策略的集成学习模型相比于基础模型精度平均提高了6.78%。刘波等[17]研究也发现,基于Stacking策略的集成学习模型提高了基础模型对母线负荷的模拟精度。
目前,虽然基于Stacking算法的集成学习模型在机器视觉和自然语言处理等领域应用较广,但基于Stacking策略的集成学习模型对膜下滴灌玉米耗水和作物系数进行的探索尚不多见。同时,基于机器学习方法对作物蒸散量和作物系数的模拟研究中,所选择的研究尺度多为月尺度或半个月尺度[10],对于作物逐日蒸散量和作物系数的研究较为缺乏。事实上,对于作物蒸散量和作物系数的模拟尺度越小,对于提高农业水利用效率和制定合理的灌溉制度的意义越大[1]。
因此,本文建立基于Stacking策略的集成学习模型对膜下滴灌玉米逐日蒸散量和作物系数进行模拟;并综合评价基于Stacking策略的集成学习模型和经典机器学习模型对膜下滴灌玉米逐日蒸散量和作物系数的模拟精度和可行性;在此基础上探索不同输入特征对模拟膜下滴灌玉米逐日蒸散量和作物系数模拟精度的影响,并最终选定模型的最佳输入特征组合。
1 材料与方法
1.1 田间试验
田间试验于2016-2018年在辽宁省灌溉试验中心(120°30′44 ″E,42°08′59″N,海拔47 m)进行。试验在2个大型称重式蒸渗仪测坑内进行,测坑长和宽分别为2.5 和2 m,深度为3.5 m。测坑内土壤为壤土,耕层0~20 cm土壤含有机质、全氮、速效钾和速效磷分别为21.6 g/kg、108.0 mg/kg、142.5 mg/kg和23.1 mg/kg,土壤容重1.37 g/cm3, 田间持水量为21%。试验选用的玉米品种在2016和2017年为郑丹958, 2018年为良玉99。蒸渗仪测坑内布置3条垄种植玉米,种植密度为60 000株/hm2,黑色塑料地膜(膜宽120 cm,膜厚0.008 mm)仅覆盖在垄台之上,滴灌带置于地膜和土壤之间,膜下滴灌布置如图1所示。如图1所示,滴灌带布置在垄中间,在测坑中间每隔10 cm深度埋放1个水热传感器(美国),用于自动检测土壤水分和温度。试验期间膜下滴灌的灌水上限设置为田间持水量的90%,下限在玉米苗期设置为田间持水量的65%,在其他生长时期均设置为70%。实际灌水量如图2所示。为排除降雨对蒸渗仪测坑的影响,在试验区设置了遮雨棚。玉米于2016年5月9日播种,9月13日收获;2017年4月27日播种,9月15日收获;2018年4月29日播种,9月12日收获。播种时一次性施底肥,其中氮、磷、钾肥均为66 kg/hm2,其他田间管理同当地农户。
1.2 特征选取与数据预处理
1.2.1 气象数据特征
气象数据由试验站安装的气象站(FT-QC9)每隔30 min记录1次气温、湿度、风速和日照时数,其中日照时数用以计算实际太阳短波辐射(R,MJ/(m2·d)),同时根据日序数计算天顶辐射(R,MJ/(m2·d))。计算式如式(1)~式(2)[1]所示。
式中G为太阳常数0.082 MJ/(m2·min);d为日地间相对距离的倒数;ω为太阳时角,rad;为所在地区的纬度,rad;为太阳磁偏角,rad;为实际日照时数,h;为理论日照时数,h。2016-2018年气象变量的统计特征如表1所示。

表1 2016-2018年试验站气象变量统计
1.2.2 玉米生长指标
试验中使用卷尺定株测量玉米株高;使用直尺测量玉米植株上所有展开叶的叶宽和叶长,并通过式(3)计算叶面积指数,测量频率约10 d/次。
式中LAI为叶面积指数;为玉米种植密度,株/hm2;和分别为展开玉米植株叶片的长和宽,m;为土地面积,本文取值10 000 m2。
为进一步获得玉米株高和叶面积生长逐日数据,本文使用式(4)[18]拟合玉米株高数据;使用式(5)[19-20]拟合玉米叶面积指数数据。
式中为玉米逐日株高,cm;最大株高,cm;LAImax为最大叶面积指数;LAId为逐日叶面积指数;、t、、和为拟合参数;为播种后天数,d。
1.2.3 玉米田间水热情况
考虑到田间表层(0~20 cm)土壤的含水率和土壤温度对土壤蒸发有着显著影响[1],因此本研究将玉米田间表层的平均含水率和温度作为输入特征。表层土壤含水率和土壤温度采用探头自动监测,监测精度分别为0.01 cm3/cm3和0.01 ℃,每隔30 min记录1次数据。将每日由测坑内埋置的自动观测探头记录的48个0~20 cm土壤含水率和温度数据取平均值作为当日的平均含水率和温度值。
1.2.4 数据预处理
在膜下滴灌条件下玉米蒸散量的模拟研究中,模型的输入特征为平均气温、相对湿度、风速、天顶辐射、短波辐射、株高、叶面积指数、表层土壤含水率、表层土壤温度和日序数共10个特征参数。由于试验期间安装的蒸渗仪和土壤水热探头会有缺失值和异常值出现,本研究在建模之前对数据集中出现的缺失值和异常值进行了剔除,最终数据集中包含的有效样本点为543个。同时,为了降低不同特征的数量级对模型精度的影响,本研究使用式(6)[21]对所选10个特征参数进行标准化。
式中X为观测数据,min为最小值,max为最大值。
1.3 研究方法
1.3.1 作物系数计算
本文使用FAO-56推荐的式(7)计算作物系数[1]。
c=ETa/ET0(7)
式中ETa为作物实际蒸散量,mm;ET0为参考作物蒸散量,mm;c为实际作物系数。ET0采用Penman-Monteith公式计算得到[22]。本研究中根据蒸渗仪测坑相邻2 d的差值计算得到玉米实际蒸散量ETa。
1.3.2 机器学习模型
随机森林模型(Random Forest,RF):它是在以决策树为基本学习器,在Bagging集成学习算法的基础上,进一步采用自助采样法对特征进行随机选择[23-25]。支持向量机模型(Support Vector Machine,SVM):它可将给定的数据集正确分开,同时使得不同类别之间的间隔最大化[26-27]。神经网络模型(Back Propagation Neural Network,BP):本文采用含有3层隐含层的BP神经网络模型。前一层和后一层之间通过全连接层连接(图3a),激活函数使用Relu函数[20]。Adaboost集成学习模型(Adaboost,ADA):它的基本思路是首先建立一个基础学习器,然后根据基础学习器在给定数据集上的表现将数据集重新划分。将学习器表现不好的数据重新建立学习器,以此类推,直到学习器数量达到设定的数量为止,最终通过权重将所有学习器进行加权结合[28-29]。
基于Stacking算法的集成学习模型(Linear Stacking Model,LSM):为提高上述经典机器学习对膜下滴灌玉米逐日蒸散量和作物系数的模拟精度,本文使用Stacking集成学习算法[15],融合上述经典机器学习模型。LSM模型基本结构如图3b所示。如图3b所示,LSM模型的基本思路是:1)使用观测数据对上述4个经典机器学习模型进行参数率定和验证;2)使用率定好的经典机器学习模型对玉米逐日蒸散量和作物系数进行模拟;3)将上述4个经典机器学习模型的对玉米逐日蒸散量和作物系数的模拟输出结果作为LSM模型中线性层的输入,对线性层参数进行训练,最终训练好LSM模型并对玉米逐日蒸散量和作物系数进行模拟。
1.3.3 特征参数重要性评估
为评估平均气温、相对湿度、风速、天顶辐射、短波辐射、株高、叶面积指数、表层土壤含水率、表层土壤温度和日序数与膜下滴灌玉米日蒸散量之间的相关程度,确定这些特征对于上述机器学习模型模拟膜下滴灌玉米日蒸散量的重要性。本研究选用最大互信息系数(Maximal Information Coefficient,MIC)来衡量所选特征与膜下滴灌玉米日蒸散量之间的线性或非线性的强度。MIC是用来度量特征和响应变量之间的相关程度,与相关系数相比,MIC值可以有效体现特征和响应变量之间的非线性关系。MIC值越大,说明特征对响应变量的重要程度越高[20]。本研究使用Python 3.0软件中MINE函数包计算所选特征与膜下滴灌玉米日蒸散量之间的MIC值,并以MIC数值评估所选特征对模拟蒸散量时的重要程度。
1.4 模型建立与评估
本研究采用Python 3.0软件中Scikit-learn库进行模型的建立和训练。将上述543个样本点分成训练集和测试集2个部分,其中考虑到2017年2号测坑中数据缺失最少,共有94个样本(2017年6月1日—2017年9月15日)。因此选择2017年2号测坑中共数据作为测试集,其余449个样本为训练集。在此基础之上将训练集再随机平均分成3份,依次随机选择其中一份作为验证集,剩下两份作为训练集(3折交叉验证)。该研究采用决定系数(2)[14]、相对均方根误差(Normal Root Mean Square Error,NRMSE)[20]、均方误差(Mean Square Error,MSE)[14]和平均绝对误差(Mean Absolute Error,MAE)[23]这4个指标判断模型模拟精度好坏的评价指标。
2 结果与分析
2.1 玉米田基本情况与玉米株高叶面积指数拟合结果
2016-2018年0~20 cm土壤水热变化动态如图4所示。从图4中可以看出,2016年、2017年和2018年,在生育期内0~20 cm土层中的温度分别为16~28.9 、22.4~30.7 和17~30.7 ℃。3 a的含水率分别为16~16.3、11.6~20.5和12.5~23.7 cm3/cm3。2016-2018年膜下滴灌玉米日实际蒸散量与作物系数动态如图5所示。图5表明,3 a的膜下滴灌玉米蒸散量和作物系数均随着生育期的进行,呈现先增加后降低的趋势,在玉米生育中期达到最大值。3 a的膜下滴灌玉米生育期内蒸散量变化范围分别为0.3~9.1、0.3~7.3和0.1~7.8 mm;玉米实测逐日作物系数变化范围分别为0.12~2.8、0.19~1.6和0.02~2.01。
采用经典生长模型拟合株高和叶面积指数拟合效果如图6所示,玉米株高拟合的2为0.978~0.999而叶面积指数拟合2均不小于0.972,说明经典生长模型拟合精度非常高,可将拟合获得的玉米株高和叶面积指数作为机器学习模型模拟膜下滴灌玉米日蒸散量和作物系数的输入特征变量。
2.2 特征变量选择
本文所选的10个特征变量与膜下滴灌玉米蒸散量之间的MIC值按大小顺序排列如下(表2):日序数、平均温度、株高、叶面积指数、短波辐射、天顶辐射、相对湿度、表层土壤温度、表层土壤含水率、风速。其中,排名前五位的特征变量对应的MIC值分别为0.99、0.86、0.86、0.75和0.65,说明日序数、平均温度、株高、叶面积指数和短波辐射是对膜下滴灌玉米日蒸散量影响最大的5个特征变量。
为了提高模型模拟玉米蒸散量和作物系数的精度,同时降低获取相关特征的难度,本文选择MIC值排名靠前的3~10个特征作为输入特征,设置了8个模拟情景,用于模拟玉米蒸散量,如表3所示。
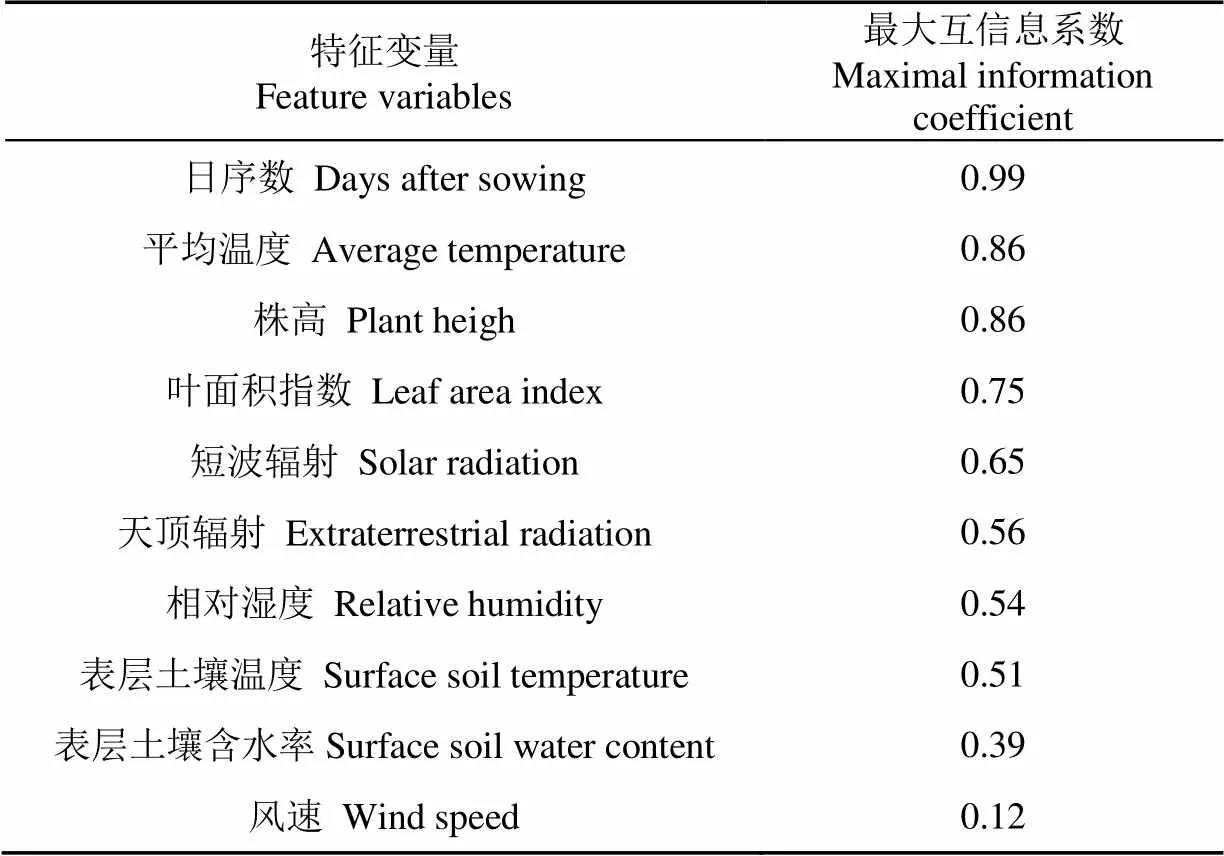
表2 特征变量与玉米实际蒸散量之间的最大互信息系数

表3 模拟玉米蒸散量和作物系数的情景
2.3 玉米蒸散量模拟结果
各模型采用验证集和测试集进行玉米蒸散量模拟的精度比较如表4所示,模拟玉米蒸散量时的主要参数率定结果如表5所示。
由表4可知,验证集上,在S1~S8情景中,LSM模型相比于ADA、RF和SVM模型,提高了模拟蒸散量的2约0.1~0.32,分别降低了NRMSE、MSE和MAE约0.11~0.31、0.45~1.79和0.19~0.79 mm。另外,在8个情景中,BP模型模拟蒸散量精度均是最低,其2明显低于其他4个机器学习模型,而且NRMSE、MSE和MAE高于另外4个模型。上述结果表明,在S1~S8情景中均是LSM模型模拟蒸散量精度最高,ADA、RF和SVM模型次之,BP模型最差。除此之外,从S3到S8情景,特征数据从5个增加到10个,但是LSM、ADA、RF和SVM模型模拟蒸散量的精度变化并不大,它们模拟蒸散量的2增加不到0.05、NRMSE降低不到0.05。其中LSM、ADA和RF模型模拟蒸散量的MSE和MAE减少均不到0.1 mm。
对于模拟ETa的测试集,在S1~S8情景中,与4个经典机器学习模型相比,LSM模型使2提高了0.05~0.5,使得NRMSE、MSE和MAE值分别降低了0.08~0.33、0.21~1.82和0.17~0.73 mm。可见,在S1~S8情景中,LSM模型对膜下滴灌玉米蒸散量模拟精度最高,其2为0.88~0.98,NRMSE为0.1~0.23。除此之外,与在验证集中类似,从S3到S8情景,各模型模拟蒸散量的2、NRMSE变化并不大,尤其是LSM、RF、SVM和ADA模型,2增加不到0.1,而NRMSE减低不到0.05,说明使用S3情景中的5个特征进行日蒸散量模拟便可获得较高精度。
综上,考虑到LSM模型模拟精度最高且S3~S8情景中LSM模型精度变化不大,因此该研究仅对LSM模型在S1、S2、S3和S8情景中对膜下滴灌玉米日蒸散量的模拟值和实际值进行了对比,结果如图7所示。在S1情景中,实测值和LSM模拟值之间的差异较大。在S1基础之上增加叶面积指数只之后,实测值和LSM模拟值之间差异较在S1情景中有明显降低趋势。进一步增加了短波辐射特征,LSM模型对膜下滴灌玉米日蒸散量拟合程度进一步提高。但是,相比于S3情景,S8情景中虽然增加了5个特征,但在S8情景中LSM对膜下滴灌玉米日蒸散量的模拟精度并没有明显改善。这说明在S3情景中LSM模型不仅取得了较高的模拟精度,还减少了特征的输入量。因此,本研究推荐使用日序数、平均温度、株高、叶面积指数和短波辐射5个特征对膜下滴灌玉米日蒸散量进行模拟。
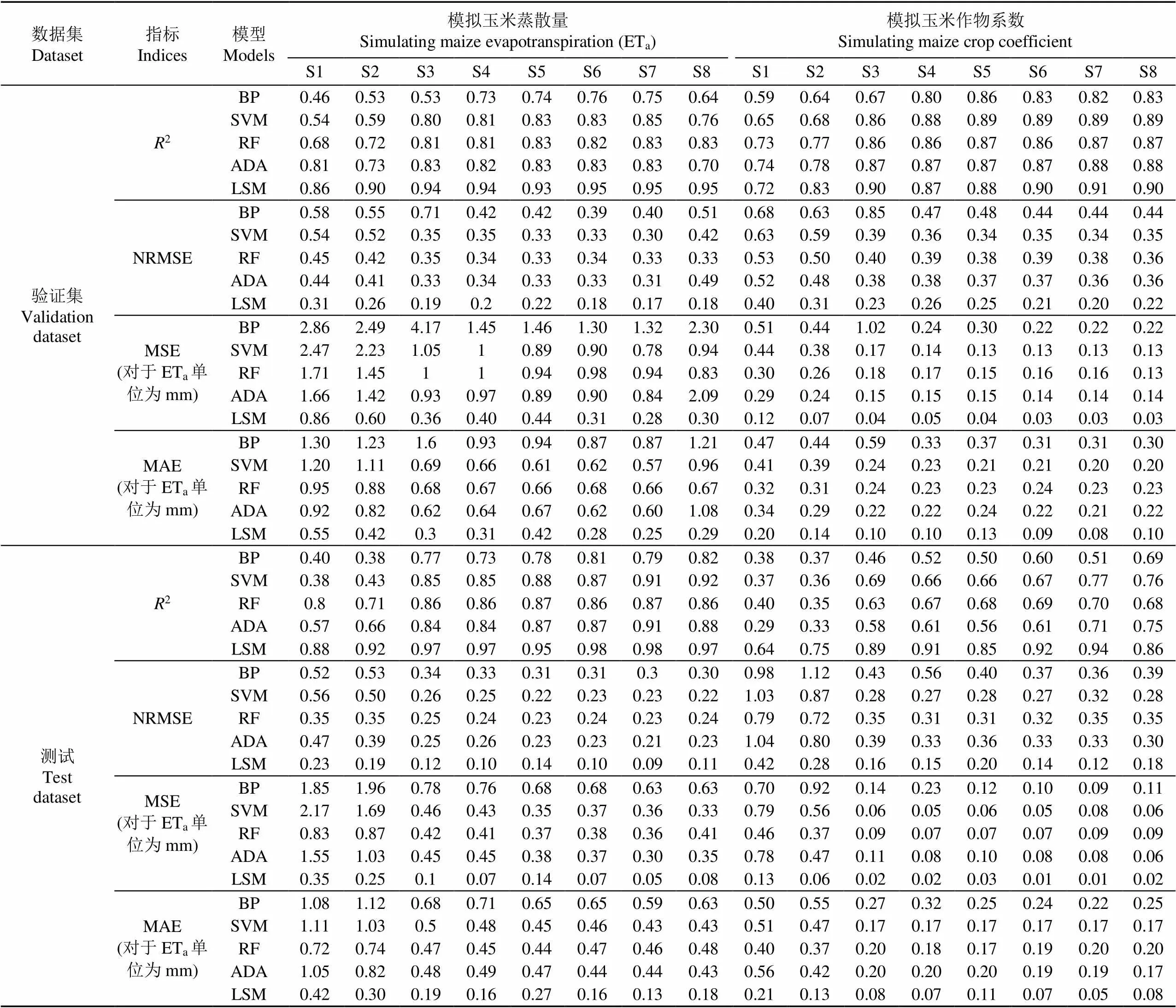
表4 各模型在不同情景中模拟玉米蒸散量和作物系数的精度
注:2、NRMSE、MSE和MAE分别为决定系数、相对均方根误差、均方误差和平均绝对误差。
Note:2, NRMSE, MSE and MAE are coefficient of determination, normal root mean square error, mean square error, mean absolute error, respectively.
表5 4个经典机器学习模型参数率定结果
2.4 玉米作物系数模拟结果
各模型在验证集和测试集上对玉米作物系数模拟精度如表4所示。从表4中可以看出,验证集上,在S1~S8情景中,LSM、ADA、RF和SVM模型模拟作物系数的2差别并不大,尤其是在S3到S8情景中,LSM、ADA、RF和SVM模型模拟作物系数的2均在0.86~0.91之间。但相比于ADA、RF和SVM模型,LSM模型使得NRMSE、MSE和MAE分别降低了0.09~0.28,0.09~0.32和0.08~0.25。另外,在文中5个机器学习模型中,BP模型模拟作物系数的精度最低,其2在0.59~0.83之间,NRMSE在0.44~0.68之间。值得提出的是,从S3到S8模型中,虽然特征数量增加了1倍,但LSM、ADA、RF和SVM模型模拟作物系数的2增加了不到0.03,RNMSE、MSE和MAE均降低了不到0.05。
在测试集上,从S1到S8情景中仍然是LSM模型模拟作物系数精度最高,其2为0.64~0.94,NRMSE为0.12~0.42。相比于ADA、RF和SVM模型,LSM模型使得2提高了0.1~0.42,使得NRMSE、MSE和MAE分别降低了0.08~0.62,0.03~0.66和0.06~0.35。另外,从S3到S8情景中,LSM模型随着特征数量的增加,模拟作物系数的2提高了不到0.05,NRMSE、MSE和MAE均降低不到0.05。综上,从各模型在验证和测试集上的精度对比表明,LSM模型模拟作物系数精度最高,ADA、RF和SVM次之,BP模型最差。同时,使用S3情景中的5个特征进行作物系数模拟便可以得到较高精度。
综上,在S1到S8情景中,LSM模型对膜下滴灌玉米作物系数模拟精度较高且在S3~S8情景中模型的精度变化不大。因此本文仅将LSM模型在S1、S2、S3和S8情景的模拟值与实测值以及FAO推荐覆膜条件下玉米作物系数进行对比,如图8所示。从玉米生长的不同生长时期来看,在快速生长期(2017年5月29日—2017年7月7日)膜下滴灌玉米日作物系数平均值为0.75。FAO-56推荐值低估了膜下滴灌玉米作物系数约17.3%,而LSM模型在上述4个情景中分别高估了6.7%、6.7%、4%和1.3%。在中期(2017年7月8日—2017年8月6日),实测作物系数为1.17,FAO-56推荐值低估了约8.3%,而LSM模型在4个情景中分别高估了6.3%、0、1.2%和−2.1%。在末期(2017年8月7日—2017年9月15日),相比于实测作物系数,FAO-56推荐值高估了约13.8%,LSM模型在4个情景中模拟值分别增加了13%、4.3%、−4.3%和0。综上,在玉米生育期内,使用LSM模型在4个情景中对膜下滴灌玉米日作物系数模拟精度均高于FAO-56推荐值。
3 讨 论
大量研究表明,作物蒸散量受到气候条件(日最高温度、日最低温度、日平均风速、日平均温度、短波辐射、天顶辐射和日平均相对湿度等)、作物生长情况(株高和叶面积等)以及土壤水热条件(土壤温度和土壤含水率等)的影响[1,3,20]。本文使用互信息法,计算了每个特征与膜下滴灌玉米日蒸散量之间的互信息指数。结果发现,互信息大于0.6的特征主要是日序数、平均温度、株高、叶面积指数、短波辐射。其中播种后天数与玉米日蒸散量之间互信息最大,为0.99。表明播种后天数是模拟膜下滴灌玉米日蒸散量的最重要特征,这与Shrestha等的研究结果一致[10]。这是因为玉米蒸散量与播种后天数之间具有显著的非线性关系。一般而言,膜下滴灌玉米日蒸散量和作物系数均随着日序数增加呈现先增加后降低的趋势(图5),这也是FAO-56推荐的作物系数是时间函数的原因。平均温度与膜下滴灌玉米日蒸散量之间互信息为0.86,仅次于日序数。这可能是因为日平均气温往往对应着较高的膜间蒸发和作物蒸腾量,进而增加了作物的蒸散量。同时日平均气温最高的时期也是玉米生长最旺盛的时期,使得日平均气温与玉米逐日蒸散量和作物系数有较强的相关性。叶面积指数和株高对玉米蒸散量模拟的重要性也较高,它们与膜下滴灌玉米日蒸散量互信息分别为0.75和0.86。叶面积和株高对膜下滴灌日蒸散量重要性较高,可能原因是:1)叶面积和株高是作物主要的生长指标,影响和田间蒸发和作物蒸腾量[1];2)叶面积指数和株高与播种后天之间存在显著的非线性关系,甚至他们之间的关系可以用的函数(如logistics函数)进行准确描述;3)叶面积指数和株高影响着空气动力阻力和水汽湍流方式,同时它们还会通过影响地面反射率影响大气与土壤的能量交换,进而影响作物耗水[1]。短波辐射也是影响膜下滴灌日蒸散量的一个重要特征,其与膜下滴灌玉米日蒸散量互信息为0.65。主要原因是太阳短波辐射是影响作物生长的主要因素[3]。需要提出的是,本研究中土壤温度和土壤含水率对膜下滴灌玉米的模拟重要性较低,而Allen等[1]认为土壤温度和含水率是影响作物蒸散量的关键因素。产生这种不一致结论的原因,主要是因为本试验是在覆膜条件下进行灌溉,2016-2018年土壤平均温度为25.1 ℃,表层土壤平均含水率为18.7%,约是田间持水量的89%,而且灌水下限设置在田间持水量的65%。表明本文中膜下滴灌生长在较为适宜的土壤水热条件下,因而土壤温度和含水率对膜下滴灌玉米蒸散量的对模拟玉米蒸散量的重要程度不大。这与Shrestha等[10]的研究结果一致,认为在在膜下滴灌条件下土壤含水率和温度一般适宜作物生长,因而表层土壤含水率和温度其对作物耗水的模拟的贡献率较低。
本文使用RF、SVM、BP和ADA模型在4种情景下对膜下滴灌玉米逐日蒸散量和作物系数进行模拟过程中发现,虽然这4种经典机器学习得到的2较大,但是它们的NRMSE值均大于0.2。说明使用这4种经典机器学习模拟膜下滴灌玉米的逐日蒸散量和作物系数时误差相对较大。然而,Shrestha等[10]研究发现,使用SVM模型可以相对准确地模拟花椒和西瓜的半个月平均ETa和作物系数值,其模拟精度高于BP模型。产生这类不一致结果的原因,一方面可能是因为机器学习模型在不同的数据集上的表现不同[20,30],另一方面可能是因为模拟的尺度不同。在Shrestha等[3]研究中采用的时间尺度为半个月尺度,而本文中采用的为日尺度。一般而言时间尺度越大,作物逐日蒸散量和作物系数在日尺度上的波动就会被弱化,使得模型的模拟精度越高,因而同样的模型在Shrestha等研究中精度会比本研究更高一些。这也说明,逐日蒸散量和作物系数更容易受到日尺度天气、生长和田间水热情况的影响。虽然4个经典机器学习模型对于日尺度膜下滴灌玉米蒸散量和作物系数模拟误差较大,但融合了这4个经典机器学习模型的LSM模型在S3到S8情景中,模拟膜下滴灌玉米蒸散量和作物系数的2和NRMSE均优于4个经典机器学习模型。该结果表明,相比于4个经典机器学习模型,基于Stacking算法框架下的LSM模型提高了模拟膜下滴灌玉米蒸散量和作物系数的精度。LSM模型能够显著提高模拟精度,这一定程度上说明使用Stacking算法集合了基础机器学习模型的优势[16-17]。Stacking集成学习算法核心思想是先训练1组模型,然后将这1组模型的输出作为输入再训练1个模型,最终得到模拟值。虽然该思想比较简单,但是大量研究表明基于Stacking算法建立的集成机器学习模型能够显著提高模型在回归和分类任务上的表现[31]。Sun等[32]使用Stacking集成学习模型对河冰破碎日期进行模拟,也发现基于Stacking集成学习模型能够提高基础模型的模拟精度。另外,值得提出的是,LSM模型模拟的膜下滴灌玉米生育期平均作物系数值比FAO推荐值更接近实测值。原因可能是:1)FAO推荐的作物系数是时间的函数,而且是根据生育期来确定推荐值。FAO推荐值一旦确定之后,就没有再考虑气候、品种、土壤等因素的影响。这也说明FAO推荐值在实际使用过程中必然会存在较大的误差,尤其是在覆膜等非标准农田中;2)本文在模拟玉米日作物系数时,综合考虑了气候、玉米生长和玉米田间水热情况等多种因素。
特征的选择对机器学习模型模拟精度有着较大的影响[33]。Khalid等[34]认为好的特征集合应该是包含尽量少的特征数量同时对模型的精度贡献最大。本研究通过互信息方法对所选的10个特征进行重要性排序,然后分别选择排序前3~10个特征和所有特征建立LSM模型模拟膜下滴灌玉米ETa和作物系数。结果发现,使用前5个特征建立的LSM模型对膜下滴灌玉米ETa和作物系数的模拟精度既高于使用前4个特征的和前3个特征的LSM模型又不低于甚至高于基于5个特征的LSM模型。基于前5个特征的LSM模型,相比于基于前3个特征和前4个特征的LSM模型提高了模拟精度,同时相比于基于所有特征的LSM模型显著降低了收集特征的难度和时间成本。这也说明在了膜下滴灌玉米逐日蒸散量和作物系数主要受日序数、平均温度、株高、叶面积指数和短波辐射的影响。
4 结 论
本文基于气象特征、玉米生长特征和土壤水热特征数据,建立4个经典机器学习模型:随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)、BP神经网络(Back Propagation Neural Network,BP)和Adaboost集成学习模型(Adaboost,ADA)和1个基于Stacking算法融合这4个机器学习模型的LSM(Linear Stacking Model)模型,对膜下滴灌春玉米逐日蒸散量和作物系数进行模拟估算。研究结果表明:
1)RF、SVM、BP和ADA模型模拟膜下滴灌玉米的逐日蒸散量和作物系数时精度较低,它们的相对均方根误差值均大于0.2;
2)相比于RF、SVM、BP和ADA模型,基于Stacking算法建立的LSM模型显著提高了膜下滴灌玉米蒸散量和作物系数模拟精度;同时,LSM模型模拟的作物系在玉米快速生长期、中期和末期均比FAO-56推荐值的更接近实测值;
3)使用日序数、平均温度、株高、叶面积指数和短波辐射5个特征建立的LSM模型在准确模拟膜下滴灌玉米的蒸散量和作物系数的同时,还能降低特征输入量。综上,本研究推荐使用日序数、平均温度、株高、叶面积指数和短波辐射5个特征建立LSM模型模拟膜下滴灌玉米蒸散量和作物系数。
[1]Allen R G, Pereira L S, Raes D, et al. Crop Evapotranspiration[M]. Rome, Italy: United Nations FAO, 1998.
[2]Dou X, Yang Y. Evapotranspiration estimation using four different machine learning approaches in different terrestrial ecosystems[J]. Computers and Electronics in Agriculture, 2018, 148: 95-106.
[3]Shrestha N K, Shukla S. Support vector machine based modeling of evapotranspiration using hydro-climatic variables in a sub-tropical environment[J]. Agricultural and Forest Meteorology, 2015, 200: 172-184.
[4]Allen R G, Smith M, Wright J L, et al. FAO-56 Dual crop coefficient method for estimating evaporation from soil and application extensions[J]. Journal of Irrigation and Drainage Engineering, 2005, 131(1): 2-13.
[5]Agam N, Evett S R, Tolk J A, et al. Evaporative loss from irrigated interrows in a highly advective semi-arid agricultural area[J]. Advances in Water Resources, 2012, 50(6): 20-30.
[6]Liu C M, Zhang X Y, Zhang Y Q. Determination of daily evaporation and evapotranspiration of winter wheat and maize by large-scale weighing lysimeter and micro-lysimeter[J]. Journal of Hydraulic Engineering, 1998, 111(2): 109-120.
[7]任新茂,孙东宝,王庆锁. 覆膜和种植密度对旱作春玉米产量和蒸散量的影响[J]. 农业机械学报,2017,48(1):206-211.
Ren Xinmao, Sun Dongbao, Wang Qingsuo. Effects of plastic film mulching and plant density on yield and evapotranspiration of rainfed spring maize[J]. Transactions of the Chinese Society for Agricultural Machinery, 2017, 48(1): 206-211. (in Chinese with English abstract)
[8]文冶强,杨健,尚松浩. 基于双作物系数法的干旱区覆膜农田耗水及水量平衡分析[J]. 农业工程学报,2017,33(1):138-147.
Wen Yeqiang, Yang Jian, Shang Songhao. Analysis on evapotranspiration and water balance of cropland with plastic mulch in arid region using dual crop coefficient approach[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(1): 138-147. (in Chinese with English abstract)
[9]Li S, Kang S, Li F, et al. Evapotranspiration and crop coefficient of spring maize with plastic mulch using eddy covariance in northwest China[J]. Agricultural Water Management, 2008, 95(11): 1214-1222.
[10]Shrestha N K, Shukla S. Basal crop coefficients for vine and erect crops with plastic mulch in a sub-tropical region[J]. Agricultural Water Management, 2014, 143: 29-37.
[11]Polhamus A, Fisher J B, Tu K P. What controls the error structure in evapotranspiration models?[J]. Agricultural and Forest Meteorology, 2013, 169: 12-24.
[12]Kim S, Shiri J, Kisi O, et al. Estimating daily pan evaporation using different data-driven methods and lag-time patterns[J]. Water Resources Management, 2013, 27: 2267-2286.
[13]冯禹,崔宁博,龚道枝,等. 利用温度资料和广义回归神经网络模拟参考作物蒸散量[J]. 农业工程学报,2016,32(10):81-89.
Feng Yu, Cui Ningbo, Gong Daozhi, et al. Modeling reference evapotranspiration by generalized regression neural network combined with temperature data[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2016, 32(10): 81-89. (in Chinese with English abstract)
[14]王升,付智勇,陈洪松,等. 基于随机森林算法的参考作物蒸发蒸腾量模拟计算[J]. 农业机械学报,2017,48(3):302-309.
Wang Sheng, Fu Zhiyong, Chen Hongsong, et al. Simulation of reference evapotranspiration based on random forest method[J]. Transactions of the Chinese Society for Agricultural Machinery, 2017, 48(3): 302-309. (in Chinese with English abstract)
[15]Czarnowski I, Piotr J. An approach to machine classification based on stacked generalization and instance selection[C]// 2016 IEEE International Conference on Systems, Man, and Cybernetics ( SMC). Budapest, Hungary: IEEE, 2016.
[16]袁培森,杨承林,宋玉红,等. 基于Stacking集成学习的水稻表型组学实体分类研究[J]. 农业机械学报,2019,50(11):144-152.
Yuan Peiseng, Yang Chenglin, Song Yuhong, et al. Classification of rice phenomics entities based on stacking ensemble learning[J]. Transactions of the Chinese Society for Agricultural Machinery, 2019, 50(11): 144-152. (in Chinese with English abstract)
[17]刘波,秦川,鞠平,等. 基于XGBoost与Stacking模型融合的短期母线负荷预测[J]. 电力自动化设备,2020,40(3):1-7.
Liu Bo, Qin Chuan, Ju Ping, et al.Short-term bus load forecasting based on XGBoost and Stacking model fusion[J]. Electric Power Automation Equipment, 2020, 40(3): 1-7. (in Chinese with English abstract)
[18]Darroch B A, Baker R J. Grain filling in three spring wheat genotypes: Statistical analysis[J]. Crop Science, 1990, 30(3): 525-529.
[19]王玲,谢德体,刘海隆,等. 玉米叶面积指数的普适增长模型[J]. 西南农业大学学报:自然科学版,2004,26(3):303-306.
Wang Ling, Xie Deti , Liu Hailong, et al. A universal growth model for maize leaf area index[J]. Southwest Agriculture University, 2004, 26: 303-306. (in Chinese with English abstract)
[20]Chen Z, Sun S, Wang Y, et al. Temporal convolution- network-based models for modeling maize evapotranspiration under mulched drip irrigation[J]. Computers and Electronics in Agriculture, 2020, 169: 105206.
[21]陈英义,程倩倩,方晓敏,等. 主成分分析和长短时记忆神经网络预测水产养殖水体溶解氧[J]. 农业工程学报,2018,34(17):183-191.
Chen Yingyi, Cheng Qianqian, Fang Xiaomin, et al. Principal component analysis and long short-term memory neural network for predicting dissolved oxygen in water for aquaculture[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(17): 183-191. (in Chinese with English abstract)
[22]Monteith J L. Evaporation and the Environment[M]. Swansea: Cambridge University Press, 1965: 205-234.
[23]周志华. 机器学习[M]. 北京:清华大学出版社,2016.
[24]Wang X, Liu T, Zheng X, et al. Short-term prediction of groundwater level using improved random forest regression with a combination of random features[J]. Applied Water Science, 2018, 8: 125.
[25]Wang Y, Song Q, Du Y, et al. A random forest model to predict heatstroke occurrence for heatwave in China[J]. Science of The Total Environment, 2019, 650: 3048-3053.
[26]Fan J, Yue W, Wu L, et al. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China[J]. Agricultural and Forest Meteorology, 2018, 263: 225-241.
[27]Mehdizadeh S, Behmanesh J, Khalili K. Using MARS, SVM, GEP and empirical equations for estimation of monthly mean reference evapotranspiration[J]. Computers and Electronics in Agriculture, 2017, 139: 103-114.
[28]Baig M M, Awais M M, El-Alfy E M. AdaBoost-based artificial neural network learning[J]. Neurocomputing, 2017, 248: 120-126.
[29]Asim K M, Idris A, Iqbal T, et al. Seismic indicators based earthquake predictor system using Genetic Programming and AdaBoost classification[J]. Soil Dynamics and Earthquake Engineering, 2018, 111: 1-7.
[30]Ferreira L B, da Cunha F F, de Oliveira R A, et al. Estimation of reference evapotranspiration in Brazil with limited meteorological data using ANN and SVM: A new approach[J]. Journal of Hydrology, 2019, 572: 556-570.
[31]Mawloud G, Farid M, Kacem G, et al. A comprehensive review of hybrid models for solar radiation forecasting[J]. Journal of Cleaner Production, 2020, 258: 120357.
[32]Sun W, Trevor B. A Stacking ensemble learning framework for annual river ice breakup dates[J]. Journal of Hydrology, 2018, 561: 636-650.
[33]Chandrashekar G, Sahin F. A survey on feature selection methods[J]. Computers and Electrical Engineering, 2014, 40(1): 16-28.
[34]Khalid S, Khalil T, Nasreen S. A survey of feature selection and feature extraction techniques in machine learning[C]// 2014 Science and Information Conference. London, UK: IEEE, 2014.
Estimation of daily evapotranspiration and crop coefficient of maize under mulched drip irrigation by Stacking ensemble learning model
Chen Zhijun, Zhu Zhenchuang, Sun Shijun, Wang Qiuyao, Su Tongyu, Fu Yujuan※
(,,110866,)
Accurate prediction of crop actual evapotranspiration (ETa) and crop coefficient has great significance for designing irrigation plans and improving the water resources use efficiency. To improve the accuracy for predicting actual evapotranspiration and crop coefficient of maize under mulched drip irrigation, in this study, a Stacking Ensemble Learning Model (LSM) was developed to estimate evapotranspiration and crop coefficient of maize under drip irrigation with plastic film mulch. The LSM model included four classical machine learning methods including Random Forest (RF), Support Vector Machine (SVM), Back Propagation Neural Network (BP), and Adaboost (ADA). The maximal information coefficient (MIC) method was applied to calculate the MIC value between ten proposed features, including days after sowing, average temperature, plant height, leaf area index, solar radiation, extraterrestrial radiation, relative humidity, surface soil temperature, surface soil water content and wind speed at 2 m, and maize evapotranspiration. The MIC values were used to evaluate the importance of ten features. The results showed that in the test dataset the LSM model improved the coefficient of determination (2) and decreased Normal Root Mean Square (NRMSE), Mean Absolute Error (MSE), and Mean Square Error (MSE), compared to SVM, RF, and ADA model. The BP model had the lowest2and the highest NRMSE. It revealed that the LSM model obtained the highest precision for modeling maize evapotranspiration, followed by SVM, ADA, and RF model, and BP model had the poorest performance for modeling maize evapotranspiration. Similarly, compared to four classical machine learning models, the LSM model increased2and decreased NRMSE, MSE, and MAE, indicating that LSM increased the precision for modelling maize crop coefficient under drip irrigation with film mulch. The MIC values of days after planting, average daily air temperature, leaf area index, plant height, and solar radiation were higher than those of the other features. It indicated that the five features above are important for maize evapotranspiration. Besides, compared to the LSM model with input of five top features, the LSM model with input of all the ten features didn’t show any obvious improvement in model simulation since the2was increased little and the NRMSE value was decreased by less than 0.05. The average crop coefficient values obtained by the LSM model with input of five top features were increased by 4%, 0, and −4.3% at developed stage, midseason stage, and late stage of maize, respectively, compared to the actual value. However, the crop coefficient values based on FAO-56 recommendation were 17.3%, 8.3%, and 13.8% lower or higher than actual crop coefficient in maize developed stage, mid stage, and late stage, respectively. This result indicated that the average crop coefficient values of LSM model with input of five top features were closer to actual crop coefficient value than that modified by FAO-56. Thus, the LSM model with input of days after planting, average daily air temperature, leaf area index, plant height, and solar radiation was recommended to estimate evapotranspiration and crop coefficient of maize under drip irrigation with plastic film mulch.
evapotranspiration; models; temperature; machine learning; Stacking ensemble learning; mulched drip irrigation; crop coefficient
陈志君,朱振闯,孙仕军,等. Stacking集成模型模拟膜下滴灌玉米逐日蒸散量和作物系数[J]. 农业工程学报,2021,37(5):95-104.doi:10.11975/j.issn.1002-6819.2021.05.011 http://www.tcsae.org
Chen Zhijun, Zhu Zhenchuang, Sun Shijun, et al. Estimation of daily evapotranspiration and crop coefficient of maize under mulched drip irrigation by Stacking ensemble learning model[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(5): 95-104. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2021.05.011 http://www.tcsae.org
2020-11-19
2021-02-13
国家重点研发计划重点专项(2018YFD0300301);辽宁省高校科研项目(LSNFW201913);辽宁省自然科学基金项目( 20180550617)
陈志君,博士生,研究方向为农业高效用水。Email:867389547@qq.com
付玉娟,博士,讲师,研究方向为作物高效用水和水资源综合利用。Email:fyj0249@sina.com
10.11975/j.issn.1002-6819.2021.05.011
S161
A
1002-6819(2021)-05-0095-10
