基于BiLSTM-CRF的中文电子病历命名实体识别研究 *
2021-05-12戴文华任作炜
叶 蕾,戴文华,钱 涛,任作炜
(1.武汉纺织大学 数学与计算机学院,湖北 武汉 430074;2.湖北科技学院 计算机科学与技术学院, 湖北 咸宁 437100)
电子病历(Electronic Medical Record, EMR)是以文本格式存储的患者在医疗机构诊断、治疗过程的全部记录。它包含大量结构化和非结构化数据,其中包括患者的健康状况和诸如症状、药物、疾病、进度记录和出院摘要等信息。电子病历便于医疗机构和医疗专家跟踪诊疗信息,并监测患者的定期体检,它还可以为生活在偏远地区的患者提供医疗保健建议。此外,当患者转院治疗时,医院可通过电子病历轻松获取患者的病史和当前健康状况[1]。因此,从电子病历中提取所需信息是医学领域重要任务之一。
近年来,将自然语言处理技术用于临床决策支持成为研究热点[2,3]。电子病历命名实体识别的主要研究内容是识别病历中包含的各种医学领域实体[4,5],并建立它们之间的关系[6]。
在医学领域,英文电子病历命名实体识别最开始通常采用词典与规则相结合的方法。自2006 年起,一直到2012年,美国国家集成生物与临床信息学研究中心依次组织了许多任务,推动了命名实体识别的发展,这些任务包括去隐私信息[7],吸烟状态识别[8],肥胖及综合症状态识别[9],药品属性信息识别[10],概念识别及关系抽取[11],共指消解[12],特殊实体识别[12]等任务。
与英文电子病历命名实体识别相比,中文电子病历命名实体识别相关研究[13]还没有完整的体系。主要原因是中文电子病历命名实体识别缺乏公认的标准和规范,中文电子病历语料库仍然处于空白状态。
叶枫等人基于CRF算法,对中文电子病历中的疾病、临床症状、手术操作3类命名实体进行智能识别,并构建了覆盖25个疾病大类的250份病历[14]。Jagannatha通过训练双向循环神经网络模型,对电子病历进行命名实体识别,并证实了该方法的实验结果确实显著优于CRF模型[15]。
随着医学领域信息处理智能化技术不断前进,对于电子病历命名实体识别的要求也越来越高[16~18]。为了提高电子病历命名实体识别的效率和精度,本文提出一种基于BiLSTM-CRF的中文电子病历命名实体识别方法。一方面,根据现有中文电子病历中的语义特点,并结合多种有监督学习方法,实现基于神经网络的BiLSTM模型。另一方面,引入条件随机场(CRF)模型,对模型性能进行优化,保证命名实体识别的识别效果,为计算机智能诊断和决策打下良好的基础。
一、基于BiLSTM-CRF的中文电子病历命名实体识别
BiLSTM-CRF模型是一种典型的深度学习模型,由嵌入层、BiLSTM层、CRF层和输出层组成。命名实体识别时,首先通过嵌入层将电子病历转换为特征向量,然后送入BiLSTM层,随后通过CRF层约束结果标签,最后在输出层输出分类结果。BiLSTM-CRF模型的基本架构如图1所示。

图1 BiLSTM-CRF模型架构图
1.词向量表示
词向量是指使用特征向量表示每个分词单位,词向量的每个维度代表一个特征。目前流行的词向量表示方法主要有两种:(1)独热编码表示(One-Hot Representation)(2)分布式表示(Distributed Representation)。
由于单词在NLP中是离散的,所以最简单的方法是用相同句子长度的向量表示每个单词,例如Jack wants to eat an apple。这句话的one-hot表达方式如图2所示。
每个词都是一维向量,整个句子是一个矩阵。 但是,如果仔细观察每个向量,则会发现一些问题: 每个向量的内积彼此正交,即内积为0,即单词之间没有关系。

图2 one-hot表示图
为了解决“one-hot”问题,有人提出了一种更有效的词向量表达方法,即使用分布式表示的词嵌入(Word Embedding)。 简而言之,词嵌入实际上是将高维稀疏向量简化为密集的低维向量,这是高维到低维的映射过程。2013年,Google开发出开源工具包word2vec。word2vec就是一个高效的实现词嵌入的算法工具。
word2vec得出的词向量其实就是一个神经元隐层的权重矩阵,在经过CBOW或者Skip-Gram模型训练之后,具有相似含义的词的权重更紧密,因此,向量的间距可用于度量词的相似性。
本文在嵌入层将利用词嵌入的方式把电子病历转换为特征向量。
2.电子病历命名实体标注
采用“BIO”标注规范对数据进行标注。其中,命名实体首字符用“B”表示,结尾命名实体用“I”表示,非命名实体用“O”表示。例如:他/O最/O近/O头/B-SIGNS痛/I-SIGNS,/O流/O鼻/O涕/O,/O估/O计/O是/O发/B-SIGNS烧/I-SIGNS了/O。以上述例子为例,“头”是SIGNS(症状和体征)类别的命名实体首字符,“痛”是SIGNS(症状和体征)类别的命名实体结尾,其它的“最”“近”等被O描述的都是非实体组成部分。
电子病历命名实体主要包括五大类,分别为检查和检验,症状和体征,疾病和诊断,治疗以及身体部位,分别使用“CHECK”“SIGNS”“DISEASE”“TREATMENT”“BODY”来表示各个命名实体标签。下面是以“因玻璃割伤面部,左前臂及左膝后疼痛,出血”为例,采用BIO标注规范标注该句的结果如表1所示。

表1 电子病历命名实体标注实例
3.BiLSTM层
BiLSTM-CRF模型的第二层为BiLSTM层,其结构如图3所示。
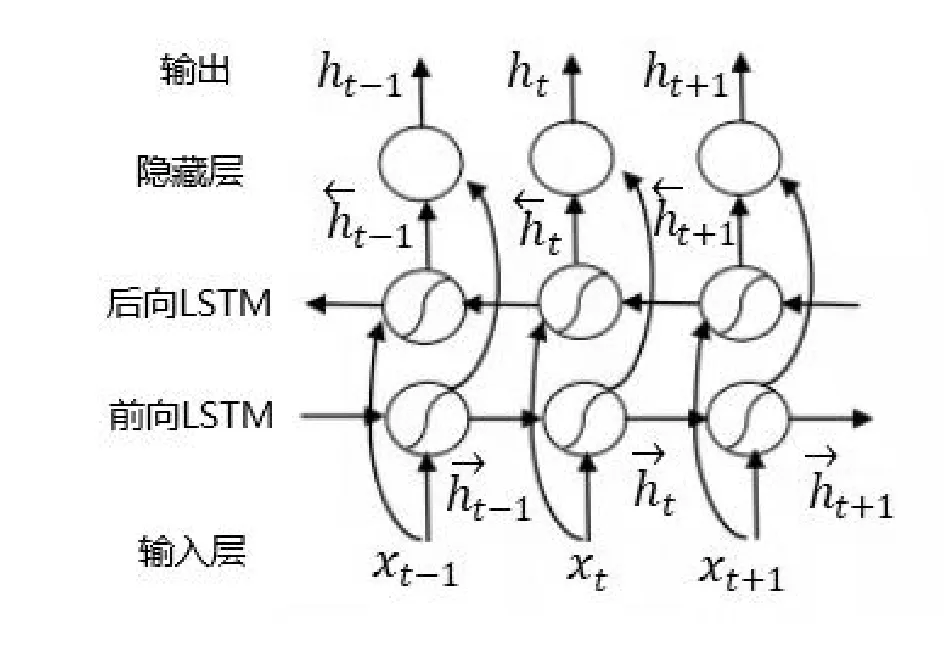
图3 BiLSTM层结构图
BiLSTM层的具体步骤如下:
(1)BiLSTM的输入层接收嵌入层生成的特征向量,分别将特征向量的正序和逆序作为前向LSTM和后向LSTM的输入;
(2)前向LSTM和后向LSTM分别计算得到前向和后向隐状态向量;
(3)隐藏层将前向和后向隐状态向量拼接,形成完整的隐状态向量,并将隐状态向量映射到K维空间(K为标注集合的总标签数,对于电子病历命名实体标注集来说,总标签数为11);
(4)隐藏层的输出作为CRF的输入。
图1中BiLSTM层的输出是每个标签的分数。例如,对于w1, BiLSTM节点的输出为1.7 (B-CHECK)、0.04 (I-CHECK)、0.1 (B-SIGNS)、0.05 (I-SIGNS)、0.03 (B-DISEASE)、…,这些分数将作为CRF层的输入。
4.CRF层
条件随机场(Conditional Random Field, CRF)由Lafferry2001年首次提出,是类似于HMM的序列建模框架。该模型的目标是学习映射函数xs→ys,使得正确的输出标签最大化。但是,每个输出ys并不是独立的。CRF模型能够通过计算给定观察到的特征向量x=x0,x1,…,xt的随机变量条件概率来预测输出向量y=y0,y1,…,yt。
假设CRF的输入和输出是线性链,并且P(Y|X)服从马尔可夫性质。需要找到参数来建立模型,所以通过给定输入的单词序列X=X1,X2,…,Xn和标签序列Y=Y1,Y2,…,Yn。P(Y|X)对应的方程式为:


tk(Yi-1,Yi,X,i)表示在给定序列X的情况下,序列Y在位置i-1处的值转换为i的概率。sl(Yi,X,i)表示在给定序列X的情况下,序列Y的相应值在位置i处的概率。λk和μl是两个函数的权重。
tk(Yi-1,Yi,X,i)和sl(Yi,X,i)是特征函数,如果设sl(Yi,X,i)=sl(Yi-1,Yi,X,i),则可以通过下面的公式来设置它们:
因此,对于给定的句子(词)X,可以给标签序列Y打分:
然后可计算得分概率:
使用对数似然算法作为估计函数来估计CRF的权值:
使用改进的迭代缩放算法通过以下公式求出向量增量δ:
然后使用δ更新当前参数λ=λ+δ。如果并非所有λ都收敛,重复该步骤。
对于给定的特征向量、权重向量和观测序列,可使用维特比算法(Viterbi Algorithm)来预测单词的分类,步骤如下:
(1)通过以下公式进行初始化
δ1(j)=wF1(y0=start,y1=j,x),j=1,2,…,m
(2)找出每个标签l在位置i的最大概率
(3)记录路径
停在i=n,在这个位置,最大概率是:
最佳路径的终点:
从最佳路径返回:
二、数据集构建
为了验证模型的具体表现,使用如下的实验数据集和实验参数。
1.实验数据集
本文模型训练测试以及验证所涉及到的数据集由以下两部分组成:
(1)来自CCKS 2018大会上TASK2发布的公开数据集。
如图4所示,数据集的相关信息,共1 200份数据。

图4 电子病历相关信息
如图5所示,电子病历本地详细存储记录。

图5 电子病历本地详细存储记录
(2)中国wiki百科数据集。用于预训练词向量。
将数据集数据分别按照7∶2∶1的比例,分为训练集、测试集、验证集。词向量训练使用Google开发的工具word2vec进行训练。使用data1已标注好的数据进行训练和测试以及评估。
2.模型的实验参数设置
相关参数如图6所示

图6 模型最佳参数
三、实验结果
1.实验一:模型对比实验
以下为 HMM模型,CRF模型,以及BiLSTM-CRF模型的识别结果。实验结果如表2所示。

表2 模型对比实验
从表2中可以发现BiLSTM-CRF模型效果明显优于HMM模型和CRF模型。
2.实验二:模型对不同类型命名实体的识别比较
CRF与BiLSTM-CRF模型对不同类型命名实体的识别比较,结果如表3所示。
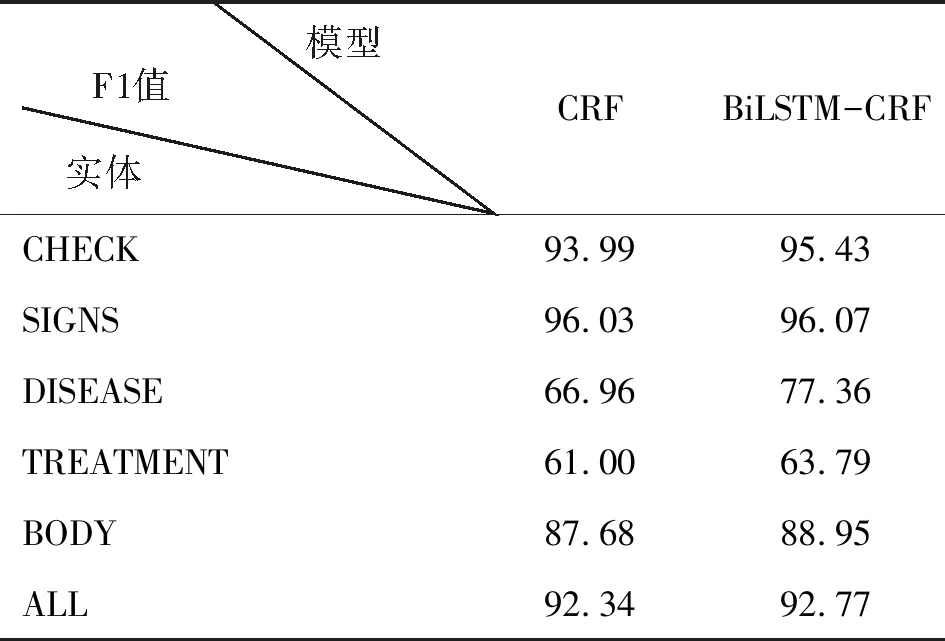
表3 模型对不同类型命名实体的识别比较
从表3中可发现,对不同类型的命名实体,BiLSTM-CRF模型均优于CRF模型。
3.实验三:实例分析
测试文本1:口腔溃疡需要多吃维生素
CRF模型识别结果如表4所示:

表4 CRF模型识别结果
BiLSTM-CRF模型识别结果如表5所示:

表5 BiLSTM-CRF模型识别结果
CRF模型在命名实体识别时,由于没有判断出口腔溃疡这个疾病症状,导致无法保存信息传递给下一个网络,以至于无法识别出维生素这个治疗实体。而BiLSTM-CRF模型,可以长久的保存实体信息,也就能准确的识别出口肠溃疡和维生素这两个实体。
测试文本2:他感觉喉咙痒,然后去医院检查,发现是支气管肺炎,需要吃牛黄蛇胆川贝片。
CRF模型长文本识别结果如表6所示:

表6 CRF模型长文本识别结果
BiLSTM-CRF模型长文本识别结果如表7所示:

表7 BiLSTM-CRF模型长文本识别结果
实验表明,当待识别文本较长,且表达复杂的情况下,BiLSTM-CRF模型比CRF模型具有更多优势,为准确识别电子病历命名实体提供了很有效的帮助。
四、结语
中文电子病历命名实体识别是医疗信息化的一项基础工作,能为计算机智能诊疗和决策提供有力支撑。临床实践中,由于电子病历量大、面广,如果仅靠人力进行电子病历命名实体的标注和识别,效率低下且易于出错。通过计算机来进行电子病历命名实体识别将是一件极具实际意义的事情。
本文以BiLSTM-CRF模型应用于中文电子病历的命名实体识别,实验表明模型的准确率、召回率和F1值均达到了较好的效果。对于中文电子病历中的五类命名实体,BiLSTM-CRF模型也有较好的表现,但具体涉及DISEASE、TREATMENT两类实体,F1值相对较低,这是由于训练集相对较小,模型训练不充分,导致效果不佳。
后期研究工作中,将收集整理更大规模的中文电子病历语料,进一步改善模型各项参数,以保证训练出更好的模型,为中文电子病历的命名实体识别提供帮助。
