基于深度强化学习的驾驶员跟车模型研究*
2021-05-12郭景华李文昌罗禹贡李克强
郭景华,李文昌,4,罗禹贡,陈 涛,李克强
(1. 厦门大学机电工程系,厦门 361005;2. 清华大学车辆与运载学院,北京 100084;3. 中国汽车工程研究院股份有限公司,重庆 401122;4. 同济大学汽车学院,上海 201804)
前言
智能驾驶系统通过现代传感、人工智能等先进技术辅助或代替驾驶员操控汽车,被认为是实现驾驶员、车辆和交通环境协同的有效手段[1]。为降低驾驶员的操作负担,提高驾驶员的操控能力和对智能驾驶系统的接受程度,须对驾驶员的驾驶习性进行深入研究。建立准确反映驾驶员跟车行为的驾驶员模型对于智能驾驶系统控制策略的开发具有重要的意义。
驾驶员跟车模型描述了单车道相邻车辆之间的相互作用,国内外学者建立了多种形式的跟车模型。Bando 等[2]提出了最优速度(optimal velocity,OV)模型,该模型假设车辆的最优速度与跟车距离相关,驾驶员通过加减速调整速度以实现最优车速。文献[3]中提出一种线性跟车模型,该模型在FVD(full velocity difference)模型[4]的基础上引入一个反映驾驶员特性的参数,以体现不同驾驶员的期望跟车距离。上述文献都是以运动学方程或经验公式的形式建立数学模型。驾驶员跟车时的决策是一个复杂的过程,以数学公式所拟合出的跟车模型不足以全面描述驾驶员的行为。
文献[5]中通过驾驶模拟器采集驾驶员跟车行驶数据,并使用人工神经网络学习驾驶员的速度规划行为。Papathanascpoulou 等[6]通过在意大利那不勒斯采集的驾驶试验数据,使用局部加权线性回归方法拟合驾驶员跟车模型,并将相同的数据用于校正Gipps模型进行验证。文献[7]中采集10 多个驾驶员的高速道路跟车试验数据,将相对速度、跟车距离、跟随车辆速度输入到自适应神经模糊推理系统进行训练,输出跟随车辆的加速度。Khodayari 等[8]设计了人工神经网络以建立驾驶员模型,其中输入为估计的反应时间、跟车相对速度与距离和主车速度,输出为主车加速度,并使用美国NGSIM数据集进行训练。文献[9]中利用递归深度神经网络建立微观驾驶员跟车模型,该模型与其他模型的区别在于采用更多的历史状态而不仅是瞬时状态作为输入。使用机器学习的方法建立的跟车模型能较好模仿驾驶员行为,且具有较大的灵活性。然而,现有的跟车模型大多是利用国外的驾驶行为试验数据集建立的,这些模型所体现的是国外道路和驾驶员的跟驰特性。不同国家在交通、车辆和驾驶风格与文化等方面存在一定的差异,这些差异极可能会造成驾驶行为的明显差异[10-11]。因此,基于国外道路数据建立的跟车模型不一定适用于描述我国驾驶员的跟车行为特性。为建立真实体现我国驾驶员行为特性的跟车模型,须采集大样本我国驾驶员真实道路驾驶数据,并利用数据驱动的方法对驾驶员行为进行学习,而当前这方面的研究较少。
因此,本文中提出一种基于深度强化学习的驾驶员跟车模型。通过我国自然驾驶数据分析了驾驶员跟车行为特性及其影响因素,基于深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法建立了驾驶员跟车模型,并通过试验验证所建立跟车模型对驾驶员跟车行为的复现能力。
1 跟车场景数据采集与提取
1.1 数据预处理
本文的数据来自我国大规模实车路试的自然驾驶工况数据[11],数据可划分为自车行驶数据、目标物信息和驾驶环境信息3类。自车数据主要包括速度、加速度、加速踏板行程和转向盘转角等;目标物信息主要包括目标速度、自车与目标的间距和目标类型等;而驾驶环境信息是指根据摄像头采集的视频数据通过人工标定的形式获取,如天气、道路类型、信号灯和标志牌等。
由于环境条件、设备条件等因素的影响,采集到的数据可能不完整和不准确,如数据缺失、数据噪声和数据异常等问题。因此,在对自然驾驶数据进行分析前须对原始数据进行加工处理。
本文针对自然驾驶数据的噪声进行了滤波处理,采用对称指数移动均值滤波器(symmetric exponential moving average filter,SEMAF)对速度和加速度信号进行降噪,其表达式为

式中:x(tk)为ti(i=1,2,...,n)时刻的原始数据;n为数据量;为处理后的数据;T为滤波宽度;dt为数据时间间隔。
1.2 跟车场景片段提取
跟车指的是主车(跟随车辆)的位置和速度实时受前方车辆影响的驾驶状态[10]。图1 所示为跟车场景示意图,跟车场景中主要包含相同车道上的一个前方目标车辆和一个主车。驾驶员在驾驶过程中,通过实时道路环境和周围车辆信息或交通约束条件和主观经验等对跟车条件进行判断,并在某段时间以前方车辆为目标车进行跟随行驶。

图1 跟车场景示意图
基于上述场景定义,从自然驾驶数据中截取符合条件的跟车场景片段数据,还须进一步根据数据特征进行经验性分析以确定场景辨识的阈值,从而建立场景自动截取算法[12]。从自然驾驶数据中人工筛选部分主车跟随目标车行驶的案例片段,通过人工观看视频和对车辆行驶动态参数分布范围进行分析,定义的场景截取准则如下。
(1)跟车时,主车与目标车的纵向距离不大于120 m。设立该准则的目的在于排除主车处于自由行驶的工况。
(2)整个片段过程中,主车与目标车的横向距离应小于5 m。本条准则用于避免车辆处于大弯道的工况。
(3)跟车片段持续时长应大于10 s。该准则保证主车处于稳定的跟车状态,同时保证整个场景片段具有足够的数据以供分析。
(4)跟车过程中,主车速度低于1 m/s 时则跟车结束,以保证车辆处于行驶状态。
根据自动截取算法进行初步筛选后,再通过人工观看视频的方式进行验证,以剔除无效案例。最终,总计得到1 147 个跟车场景片段,累计有效时长1.65×104s,每个数据片段平均时长为14.4 s。
2 驾驶员跟车行为特性分析
对跟车片段进行截取后可获得大量驾驶员跟车行驶轨迹数据,以这些数据为基础,选择驾驶员跟车加速度a、速度v、车间距d和相对速度vr等参数对驾驶员跟车行为特性进行分析。首先,通过驾驶员行为特征参数的频率分布特征总体了解驾驶员跟车行驶时的行为规律,其次通过相对系数对驾驶员行为特性的影响因素进行分析。
图2为驾驶员跟车行驶时主车加速度频率分布。由图可知,驾驶员跟车时的加速度整体大致符合正态分布,加速度值主要分布在[-1.5 m/s2,1.5 m/s2]区间内,表明驾驶员在跟车过程中习惯保持较为平稳的速度跟随目标车行驶。图3 示出主车速度的分布特征。由图可知,驾驶员跟车速度主要分布区间为[8 m/s,18 m/s],个别驾驶员跟车速度达到35 m/s,可能的原因为这些数据所对应的行驶道路为高速道路,且道路较为畅通。

图2 主车加速度频率分布

图3 主车速度频率分布
图4为驾驶员跟车距离的累计频率分布,其中25、50、75 3 个百分位对应的数值分别为24.19、44.22 和72.19 m,表明驾驶员在较高的速度行驶时期望保持较大的跟车距离,驾驶员跟车距离越小,越有利于提高交通道路利用率,但过小的距离容易给驾驶员造成心理负担,且容易造成交通事故。
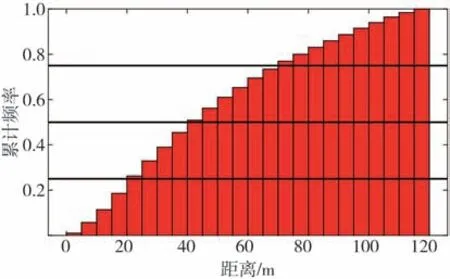
图4 跟车距离累计频率分布
图5 为驾驶员跟车时相对速度的频率分布,相对速度定义为目标车速度与主车速度的差值。从图中可以看出,驾驶员跟车时与目标车的相对速度呈明显的正态分布,驾驶员在大部分情况下期望以较小的速度差跟随目标车行驶,个别相对速度达到10 m/s。

图5 相对速度频率分布
车头时距(time headway,THW)是一个表征驾驶员跟车行为的重要参数,定义为前后两车头部通过道路某一断面的时间间隔[13]。THW(单位:s)可以表示为

式中:dx为主车与目标车之间的纵向距离;vx为主车的纵向速度。
THW 值越小,说明主车跟随目标行驶的形势越紧急,如跟车距离较小或主车速度较高等情况。图6示出THW 的频率分布。从图中可以看出THW 总体符合对数正态分布,主要分布区间为[1.5 s,3.5 s],说明驾驶员在大部分跟车行驶时较为从容,与目标车形成较为平稳的相对运动状态,从而在主观上达到安全舒适的感受,个别THW 值达到了15 s,可能原因是主车速度较小或跟车距离较大。图7 为驾驶员跟车THW 值累计频率分布。其中25、50、75 3 个百分位对应的THW 数值分别为2.11、3.17 和4.65 s。
进一步,为更好地利用自然驾驶数据建立驾驶员跟车模型,采用Spearman 相关系数量化分析驾驶员跟车距离d和相对速度vr以及THW 与主车速度v和加速度a的相关性,从而提示这些因素对驾驶员跟车行为的影响。Spearman相关系数是度量两个等级变量之间相关关系的非参数指标,其表达式为


图6 THW频率分布
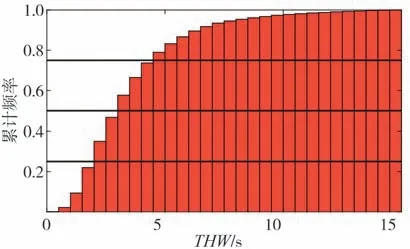
图7 THW值累计频率分布
式中:R为相关系数;di为两个变量的等级差;m为样本数。
由式(3)可知,相关系数取值范围为[-1,1],相关系数的正负表示两个变量呈正相关和负相关;相关系数值的大小反映两个变量的相关程度。
对各个跟车片段中的驾驶员跟车距离d、相对速度vr和THW 值与加速度和速度的Spearman 相关系数进行计算,并得到了显著性检验的p值。以0.2为间隔对相关系数分布区间进行划分,统计不同参数与加速度的相关系数在各区间的分布概率,结果如图8 所示。从图8 可知,车间距、THW 值与加速度的相关系数在各区间的分布概率较为均匀,而相对速度与加速度呈正相关的概率较大。为更好体现各变量与加速度的相关性程度,在表1 中列出了相关系数的分布。可以看出,各变量与加速度相关系数大于0.4 的概率均大于50%。此外,车间距与加速度相关的概率最高,THW 次之,其中车间距与加速度相关系数大于0.4 和0.7 的概率分别为63.12%和34.35%,而相对速度与加速度相关系数大于0.4和0.7 的分布概率最小,分别为53.18%和23.10%。结果说明驾驶员跟车时根据车间距对加速度进行调整的概率最大,而相对速度相对跟车距离和THW 而言,对驾驶员跟车加速度的影响较小。
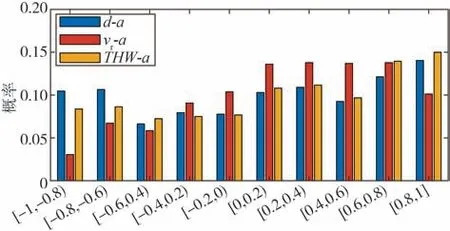
图8 各变量与加速度相关系数分布概率
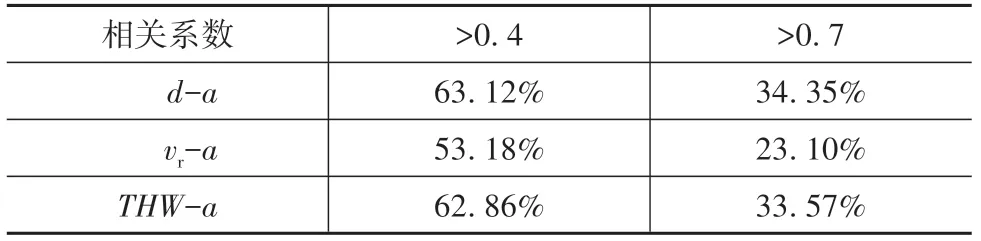
表1 各变量与加速度相关系数分布情况
图9 为各变量与加速度相关程度的显著性检验p值的概率分布情况,其中各变量对应的p值小于0.05 的分布概率均超过90%,说明90%以上的案例中各变量与加速度的相关性显著。综合以上统计结果的分析,可以判断跟车距离、相对速度、THW 值对驾驶员跟车加速度都有一定的影响。

图9 相关程度显著性检验p 值概率分布
图10所示为各变量与速度相关系数的分布概率情况。从图中可知,各变量与速度相关系数绝对值主要分布在[0.8,1]之间,说明大部分跟车片段中各变量与速度的相关性较强。跟车距离与速度呈正相关的概率最大,而相对速度与加速度主要呈负相关的趋势。表2 为各变量与速度相关系数的分布。其中相关系数大于0.4 和大于0.7 的概率分别分布在80%和60%左右,表明各变量大概率与速度具有相关性,且相关程度差异不大,表明驾驶员在跟车过程可能综合这些参数对速度进行调整。图11 为显著性检验p值的分布,同样地,各变量对应的p值小于0.05 的分布概率也都超过90%,表明各变量与速度相关具有较强的显著性。
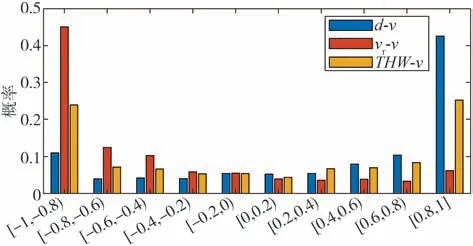
图10 各变量与速度相关系数分布概率
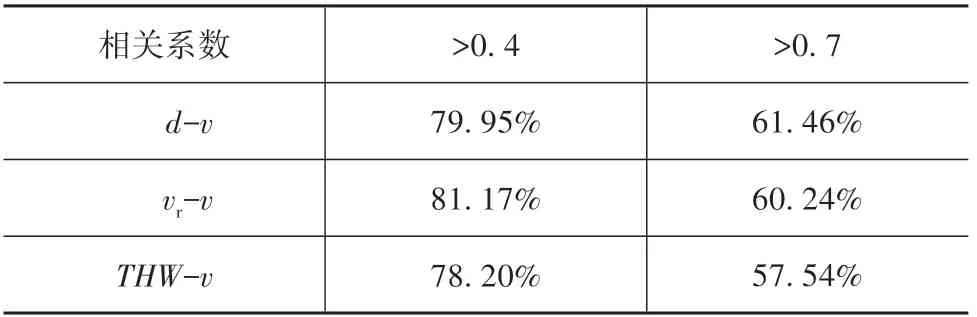
表2 各变量与速度相关系数分布情况
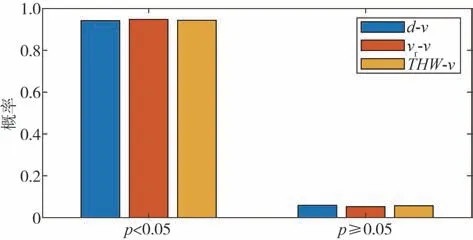
图11 相关程度显著性检验p值概率分布
3 基于深度强化学习的驾驶员跟车模型
3.1 跟车模型框架设计
当前的跟车模型大多缺乏个性化,精度不高[14]。为克服现有跟车模型的限制,提高跟车模型对驾驶员跟车行为的复现能力,且由于车辆加速度信息以连续状态存在,本文选择在连续动作空间中具有很好性能表现的深度确定性策略梯度算法DDPG 设计了驾驶员跟车模型框架。将驾驶员跟车轨迹数据集输入到模拟跟车环境中,让智能体从经验数据中学习驾驶员的决策行为,从而形成从跟车驾驶状态到加/减速行为关系的映射。
DDPG 使用的是基于确定性策略梯度(deter⁃ministic policy gradient,DPG)的Actor⁃Critic神经网络框架,包含一个基于策略的Actor网络和一个基于价值的Critic网络,每个网络又细分为在线网络和目标网络。此外,DDPG算法同样采用了经验回放池存储经验数据,在学习过程中采用某种策略从中均匀抽取小批量数据更新Actor网络和Critic网络的参数。
3.2 环境与奖励函数设计
由第2 节的分析可知,速度和加速度等驾驶员跟车行为参数受跟车距离、相对速度和THW 的影响,而THW 又与跟车距离和速度相关。所以,本文采用3 个关键参数来表征驾驶员在某个时刻t所采取动作的基准信息,即第n辆车(假设为受控车辆)的速度vn,车辆n与前方目标车辆n-1 的相对速度Δv,以及两车之间的间距s,而驾驶员模型的输出为车辆n的纵向加速度an(t)。
通过以下表达式描述环境状态的迭代关系,即
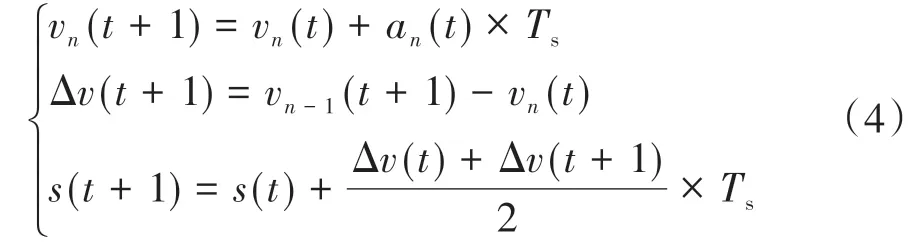
式中Ts为模拟时间间隔。
智能体从环境中获取当前时刻的状态信息,并根据策略从动作空间中选取动作,环境执行动作后进入下一个状态[15-16],同时智能体因动作获得相应的奖励(或惩罚),如此不断交互直至达到结束条件。智能体的目标是获取最大的累积奖励,其中评判智能体所采取动作好坏的度量标准通常用奖励函数表示。因此,奖励函数的设计影响智能体的决策方向,是强化学习算法的关键。
驾驶员在现实跟车中会根据驾驶环境,采取一定的动作调整车辆的纵向运动状态,使自车速度和车辆间距离在可接受的安全、舒适范围内。为更好地反映驾驶员的跟车行为特性,应尽可能减小模拟状态与真实状态之间的误差。本文采用速度作为性能指标,以最小化速度误差为目标训练跟车模型。为直观体现误差的大小,本文设计的奖励函数形式为

式中vobs和vsim分别为驾驶员驾驶车速和模拟车速。
3.3 网络结构与参数更新
设计的Actor 网络和Critic 网络的神经网络结构如图12所示。其中,Actor网络的输入为跟车状态信息,包括主车速度、相对速度和车间距,输出为主车的跟车加速度;Critic 网络的输入为跟车状态信息和Actor网络输出的加速度,输出为Q值函数。Actor网络和Critic 网络均包含4 层结构,包括输入层、两个隐层和输出层,其中隐层分别包含100 个和50 个神经元。

图12 Actor和Critic网络结构示意图
为得到较好的模型收敛速度,采用整流线性单元(rectified linear unit,ReLU)激活函数拟合隐层中的输入输出信号转换关系,ReLU 激活函数表达式为
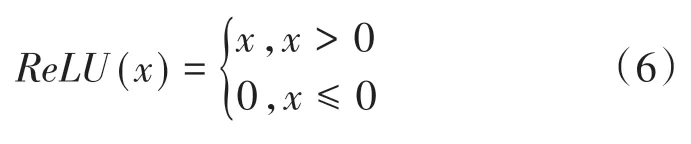
此外,为限制加速度输出范围,在Actor 网络输出层中采用tanh激活函数,使Actor网络输出的加速度保持在[-1,1]范围内。
Critic 网络从经验回放池取得经验样本后,通过最小化损失函数以更新策略网络参数,损失函数为
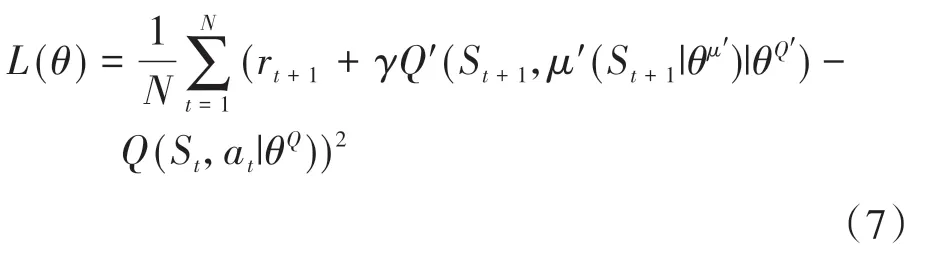
式中:θQ为Q值网络参数;θQ′为Critic 网络中目标网络的参数;θμ′为Actor网络中目标网络的参数。
Actor 网络中的目标网络用于更新价值网络参数,其策略梯度表达式为

式中θμ为策略网络参数。
每次训练完后,先使用梯度更新在线网络的参数,然后更新两个目标网络的参数,其表达式为
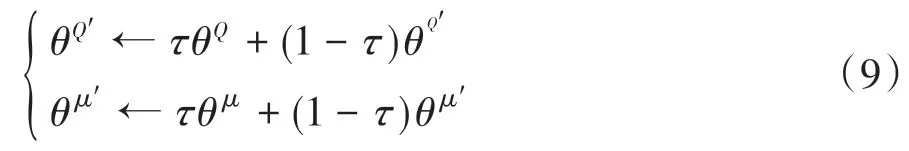
式中τ为软更新率。
4 验证与分析
从所有数据集中随机挑选70%的数据片段对驾驶员模型参数进行训练校正,剩余30%用于对模型验证。采用每个训练步数的总奖励、平均奖励和速度的均方根误差(root of mean square error,RMSE)作为训练效果的观测指标,RMSE定义为

式中vobs(i)和vsim(i)分别为采集的第i个真实车速和模拟车速。
每个步数所获得的总奖励值、奖励均值和RMSE 值如图13~图15 所示。由于奖励函数设计为误差平方的形式,因此奖励越小时,误差越小。由图13~图15可以看出,尽管训练步数设置为1 200步,在300步左右时模型便开始收敛。
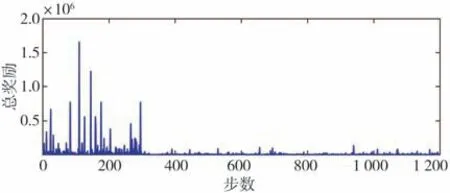
图13 训练过程总奖励变化

图14 训练过程平均奖励变化
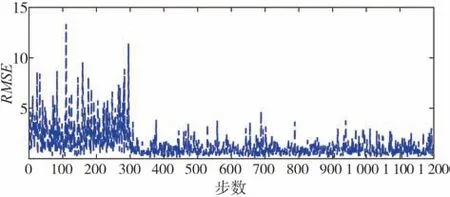
图15 训练过程均方差根误差曲线
为验证所提出的跟车模型反映驾驶员跟车行为特性的能力,随机选择测试集中的数据对300~350步中的模型参数进行验证。图16 展示一个跟车片段速度和车间距真实值与模型输出模拟值的对比。从图中可以看出,速度和车间距的仿真结果能较好地跟随真实值,从而说明所建立的DDPG 模型能较好地反映驾驶员跟车行为。

图16 速度和车间距的模拟与真实值对比结果
为验证所建立的跟车模型性能,采用现有研究中常用的FVD 模型[4]和IDM 模型[17]进行对比试验。采用遗传算法和自然驾驶数据集对FVD模型和IDM模型的参数进行标定,采用速度的均方根百分比误差(root of mean square percentage error,RMPSE)作为参数标定时的适应度函数,其表达式为

完成FVD 模型和IDM 模型参数的标定后,在稳态、加速、减速3种不同跟车工况下进行对比,分析所提出的模型与对比模型在反映驾驶员跟车行为方面的性能表现。图17~图19展示了不同工况下驾驶员跟车速度和车间距与3种跟车模型模拟结果的对比。
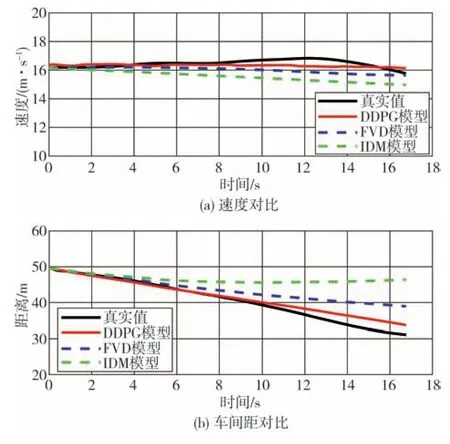
图17 稳态跟车工况
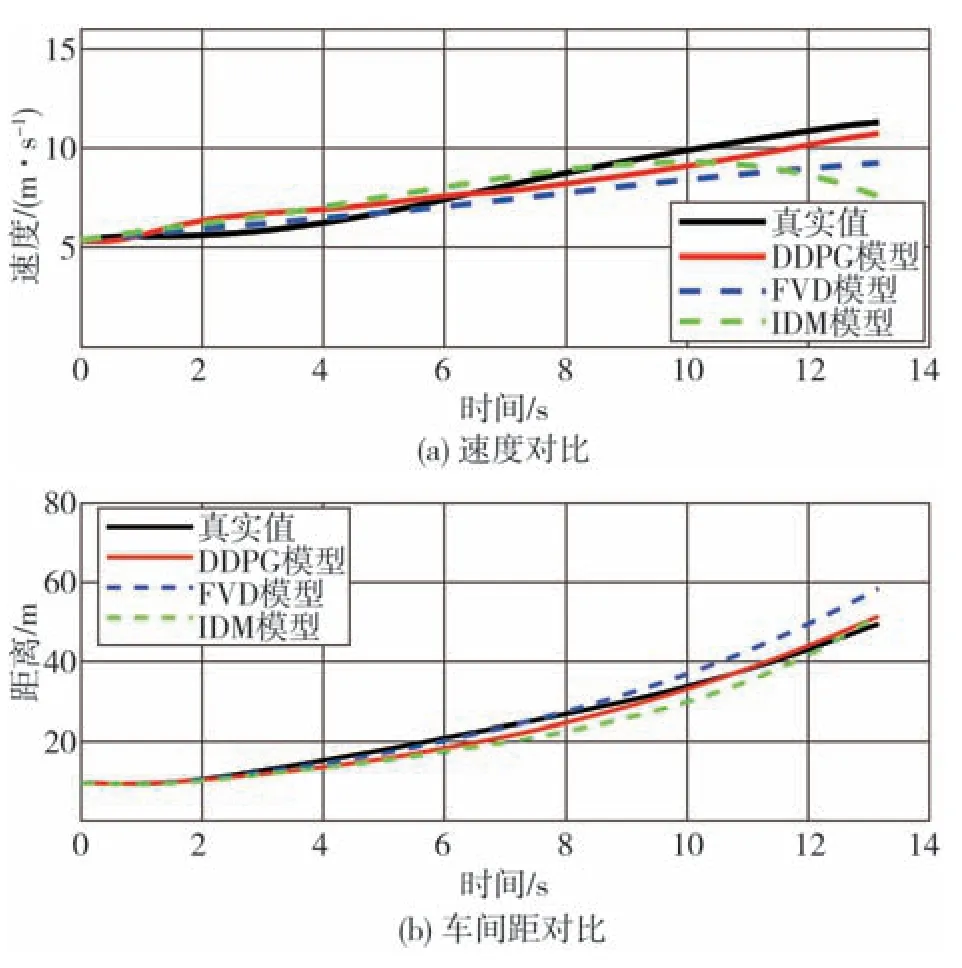
图18 加速跟车工况
图17为稳态跟车工况下的速度和车间距对比曲线。由图可见,DDPG 模型输出的速度和车间距比FVD 和IDM 模型的结果更接近驾驶员的行驶数据,表明DDPG 模型更能反映驾驶员的真实跟车行为。
图18 为加速跟车工况下的速度和车间距对比结果。由图可见,总体来说,加速跟车工况下,DDPG模型输出的结果比两种对比模型的结果能更好地体现驾驶员的跟车行为。
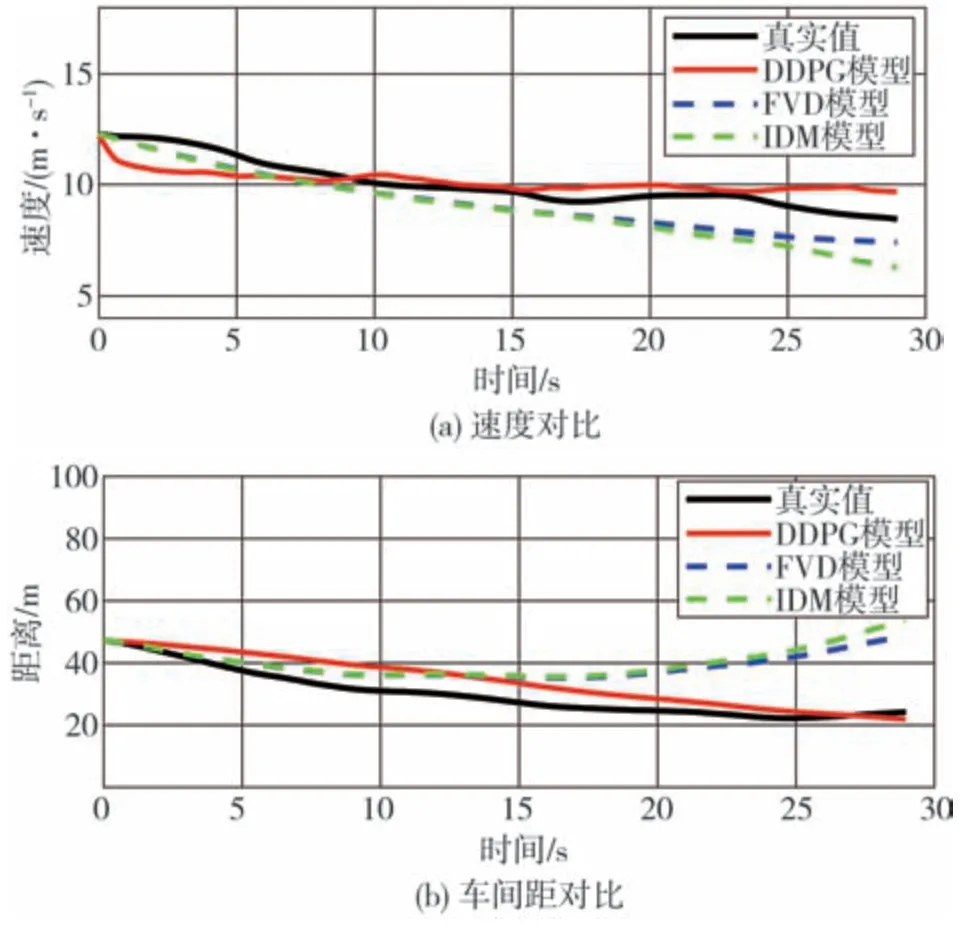
图19 减速跟车工况
减速跟车工况下的速度和车间距对比结果如图19 所示。由图可见,总体来说,在减速跟车工况下,DDPG模型能较好地跟随实际的速度和车间距。
5 结论
设计跟车场景截取准则,并从自然驾驶数据中筛选出符合条件的典型跟车场景。基于自然驾驶数据对驾驶员跟车行为进行分析,通过驾驶员跟车加速度、速度、车间距、相对速度和THW 等参数的频率分布特征对驾驶员跟车总体规律进行了分析和统计,并通过相关系数分析了车间距、相对速度、THW等因素对驾驶员跟车行为的作用机理,为建立驾驶员跟车模型提供了基础。最后,采用自然驾驶数据对跟车模型参数进行训练与调整,基于深度强化学习建立了驾驶员跟车模型,结果表明所提出的DDPG模型能够真实体现驾驶员的跟车行为。
