基于稀疏彩色点云的自动驾驶汽车3D目标检测方法*
2021-05-12罗玉涛
罗玉涛,秦 瀚
(华南理工大学机械与汽车工程学院,广州 510641)
前言
由于激光雷达具有测量精度高、感知范围广等优点,目前的无人驾驶方案中普遍采用激光雷达作为车载传感器之一。针对激光雷达生成的点云数据的感知算法主要分为基于规则的算法[1]和基于神经网络的算法两大类。基于规则的算法主要通过地面分割、空间聚类和点云识别等规则对数据进行处理;基于神经网络的算法使用神经网络模型,通过点云数据直接感知周围环境信息,算法主要有:PointNet[2]、PIXOR++[3]、VoxelNet[4]、Second[5]和PointPillars[6]等,具有精度高、扩展性好等优点,是目前研究的主流方向。但由于激光雷达只能感知周围环境的位置信息,不能感知颜色等信息,从而限制点云处理算法感知精度的进一步提升。摄像机能致密地感知周围环境的颜色信息,但不能感知深度信息。将点云与图像进行融合是目前提高无人驾驶车辆的感知能力的主要方向之一。
在图像数据与点云数据融合中,目前存在数据级、特征级和目标级3 种融合方式,其中以特征级融合的算法最常用,如MV3D[7]、Cont⁃Fuse[8]、AVOD[9]等。该融合方式对图像利用卷积神经网络等提取特征后,再与点云或其特征进行融合。MV3D[7]以lidar点云的鸟瞰(BEV)、正视图(FV)和图像作为输入。Cont⁃Fuse[8]使用连续融合层将图像特征融合到点云BEV 特征图上。AVOD[9]对图像和lidar 点云BEV 地图进行特征提取,然后根据Top K 提议对特征进行裁剪和调整,最后融合特征。特征级融合方法须同时对图像数据和点云数据进行运算,计算量较大,且图像与点云没有空间完全对应关系。
目标级融合[10-11]将点云识别与图像识别输出的结果进行融合,它依然会受到图像数据缺少深度信息的局限,对遮挡严重和环境复杂的场景精度提升较小。
数据级融合根据点云与图像像素的投影关系,将两者进行一一匹配。目前对于数据级融合的研究较少,Ku 等[12-13]通过局部融合提升物体定位的准确性,且通过将点云与多视角的图像融合,增加对行人朝向检测的准确率。PointPainting 算法[14]先通过图像识别算法将图像分割后对点云染色,并对染色后的点云进行处理。
本文中提出一种稀疏彩色点云(sparse colorful point cloud,SCPC)结构,通过对图像与点云的特征进行直接融合。并通过改进的PointPillars[6]神经网络算法对稀疏彩色点云直接进行运算,提升了对较难识别的物体识别能力。
本文中提出将图像与点云直接融合,直接使用神经网络算法处理融合结果,实现对车辆周边物体的识别。与特征级融合方法[7-9]相比,本文中不再依赖卷积神经网络对图像单独进行特征提取,简化了神经网络架构。与目标级融合方法[10-11]相比,本文中无须将不同传感器感知到的物体进行匹配,降低了匹配难度。与其他数据级融合方法[12-14]相比,无须对图像进行预处理,简化了图像处理流程。
1 基本原理
1.1 总体框架
总体框架包含两个模块:稀疏彩色点云的生成模块和运算模块。其中稀疏彩色点云生成模块包含点云切割、投影和特征叠加;稀疏彩色点云运算模块包含特征提取、卷积和SSD 检测。具体见2.2 节与2.3节,整个流程如图1所示。
1.2 点云数据与图像数据的数据级融合
本文中提出了一种通过激光雷达与摄像头数据融合得到的稀疏彩色点云结构,它总共有7 个维度,分别为场景中点的空间位置(3 维)、反射率(1 维)与颜色信息(3 维)。其中,空间位置为该点在lidar 坐标系中的x、y和z坐标,反射率反映该点材料对激光的反射强度,颜色信息为摄像头读取的RGB 三通道信息。

图1 总体框架图
1.2.1 过滤点云
过滤不在相机视野内的点云,根据相机的投影矩阵[15](式(1))和图像尺寸,可以确定相机的视锥,并根据该激光雷达的探测范围,采用距离相机0.01 与100 m 作为截取视锥的平面,由此可以确定摄像机坐标系四棱台。

式中:C为相机内参矩阵[16],形式为上三角矩阵,见式(2),其中的参数为归一化焦距fx与fy、图像中心u0与v0和轴倾斜参数k;R为旋转矩阵;T为平移向量。C可以通过式(3)和式(4)得到,其中的M为投影矩阵的前3 列,QR分解是由Gram⁃Schmidt 正交化推理出来的一种方阵分解形式。
由式(5)可以得出四棱台8 个顶点的空间位置,如图2 所示,其中的u、v为图片4 个角像素坐标,Z为切割平面的距离。

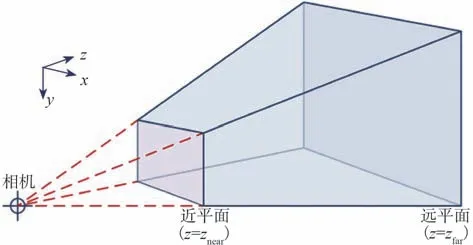
图2 摄像头坐标系四棱台示意图
1.2.2 坐标转换
将摄像机坐标系中的四棱台转化到激光雷达坐标系中,即对四棱台的8个角点进行坐标转换:


图3 分割前的点云

图4 分割后的点云
1.2.3 点云投影
根据点与图像的投影关系将分割后的点云投影至图像中[17]。根据式(8)将切割后的点云投影至图像坐标系中,其中Ps为点云的空间坐标位置,Pi为像素坐标系的位置,其中的投影矩阵Ttrans由式(9)得出。

1.2.4 特征叠加
将点云数据和其对应像素进行叠加。确定点云数据在像素坐标系中的位置后,将点云对应的颜色特征(RGB)作为稀疏彩色点云的后3 维信息,合为7 维稀疏彩色点云。
图5和图6为点云对应的图片信息与稀疏彩色点云数据示例。

图5 摄像机拍摄图片

图6 彩色稀疏点云示意图
1.3 基于稀疏彩色点云的神经网络方法
基于上文构建的7 维稀疏彩色点云结构,使用改进的PointPillars 算法,对周围环境的车辆、行人与骑单车人(简称骑车人)进行识别。Lang 等[6]提出的Pointpillars 算法是目前效果最好的针对点云数据的神经网络模型之一,具有速度快、效果好的特点。网络包括对于稀疏彩色点云的特征提取、“伪图像”(Pseudo image)的卷积神经网络处理和SSD[18]检测3 个模块,网络流程图如图7所示。

图7 稀疏彩色点云处理网络流程图
1.3.1 改进的特征提取网络
算法通过尺寸为0.16 m×0.16 m 的点云柱,按照俯视图对稀疏彩色点云进行划分,Pointpillars 算法偏向于对点云柱中的空间特征的提取,本文针对稀疏彩色点云数据,根据式(10)提取非空点云柱中的特征,维度为6维。
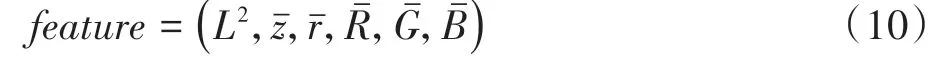
式中:为点云的平均纵向位置;为平均反射率;、、为平均三原色值。L2的公式为

式中和分别表示点云柱内所有点云的x、y数值的平均数。
设非空点云柱的数量为P,通过将非空点云柱提取6 维特征,可以获得大小为(6,P)的张量。点支柱中的最大点数设置为100,如果一个支柱包含100 个以上的点,则将对点云随机采样。最后将按照非空点云柱的位置,生成(6,H,W)的“伪图像”,其中H、W为伪图像的长宽,由式(12)确定。

式中:h和w分别为点云区域在y轴和x轴方向上的长度;vh和vw分别为点云柱对应方向的长度,在本文中都设置为0.16 m。
最终本文对“伪图像”进行批量归一化[19]、激活[20]和卷积运算,以生成大小为(D,H,W)的“伪图像”,其中D是“伪图像”的深度。
1.3.2 增加特征层数的卷积
在卷积神经网络的设计中,通过两个子模块完成,分别为上采样模块与下采样模块。下采样模块通过对伪图像的卷积,提取更高层的特征;上采样模块对特征进行反卷积,使特征还原为初始的尺寸,并将不同层的特征进行叠加。卷积神经网络对伪图像进行3 层卷积操作,第1 层卷积中始终保持卷积后的伪图像尺寸不变;在第2 层卷积中,通过两次卷积操作,使卷积后的特征尺寸缩小为之前的1/2,然后通过上采样模块,将尺寸为1/2 的特征反卷积为初始尺寸;第3 层采样与第2 层采样类似,通过下采样将特征尺寸缩小为之前的1/4,并通过反卷积得到初始尺寸,最后将3 层卷积的特征叠加,并输入到SSD网络[18]。
由于增加了颜色维度信息,使用128 个3×3×7 的卷积核进行卷积,将“伪图像”的特征提升至128 维,在对“伪图像”进行卷积操作时也相应提升了卷积层数,以适应点云的额外属性。
1.3.3 采用SSD算法进行检测
最后使用SSD 算法进行3D 检测,使用IoU[21]值对先验框和真实框进行匹配,而高度和高程为额外的回归目标。模型最终输出的预测框为物体的类型、三维大小与空间位置,以3D 框的形式输出,其结果如图8所示。

图8 彩色稀疏点云示意图
1.3.4 惩罚函数
本算法中的惩罚函数(loss function)使用了SECOND 算法[5]中的惩罚函数。真实框和预测框由参数(x,y,z,w,l,h,θ)定义,其中x、y、z分别为框的空间位置,w、l、h分别为3D 框的宽长高,θ为物体朝向。真实值和预测值之间的定位误差Lloc为

其中下标为gt 的值为真实框中的值,下标为a 的值为预测框的值,其中SmoothL1 函数如式(17)所示,da的计算如式(18)所示。

由于角度定位损失Δθ不能区分物体的朝向,在离散方向上使用softmax 分类损失Ldir,网络能够学习物体朝向。
文献[22]中的分类误差Lcls的计算公式为
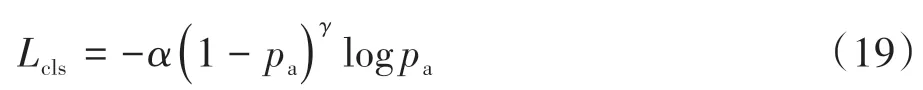
式中pa为预测框的分类概率;超参数α和γ分别设为0.25和2。
总体的损失函数为
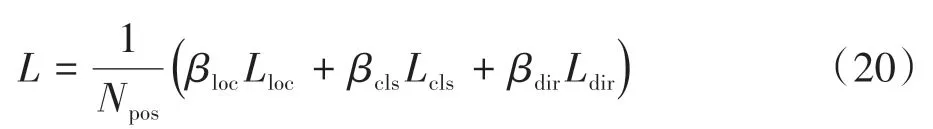
式中:Npos为正确框数目;超参数βloc、βcls、βdir分别取值为2、1、0.2。
2 方法验证与讨论
2.1 模型搭建与训练
为验证本文所提出的稀疏彩色点云和改进的PointPillars 算法的识别分割精度和实时性,采用KITTI 数据集进行验证。计算所使用的电脑配置为:INTEL 3.2 GHz i5⁃7500CPU,GIGABYTE GTX 1060 6G GPU。操作系统为Ubuntu 16.04,使用的语言为Python 3.6,深度学习框架为Pytorch。
2.1.1 训练参数设置
将KITTI 数据集按照文献[23]分为包含3 712 个样本的训练集和包含3 769个样本的验证集,由于训练样本占用的内存较大且GPU的内存有限,神经网络中的批数(batch size)为1,训练集总迭代次数为110 次,训练的步数(step)为408 320步,训练时长大约为30 h。
2.1.2 训练过程
训练过程中的分类和位置误差的变化分别如图9和图10所示。从图中可以看出,分类和位置误差都在400 000步左右收敛,但最终收敛的误差有差别,分类误差<10%,而位置误差>15%。训练结果表明神经网络模型从训练集中自主学习到周围环境的分类和定位。在训练完成后将神经网络对验证集进行验证。
2.2 评价指标
2.2.1 重叠度IoU
模型的效果是根据特定重叠度IoU[21](intersection over union)下的平均精度AP(average precision)来判断的。IoU 值用来评价预测值与真实值之间的重叠程度,IoU值越大,表明预测越接近真实值。2维IoU的计算示意图如图11所示,3维IoU同理。
2.2.2 平均精度值
AP 值是在机器学习领域运用广泛的评价指标之一,为多分类精度P的平均值,其计算公式为

式中:TP为真正例,即预测和真实值都为真的样本数目;FP为假正例,即预测值为真而真实值为假的样本数目。模型的评价指标一般为IoU 在特定值之上的记为真,但针对不同的物体通常设定不同的值,这是因为不同物体的检测难度不同,例如汽车IoU 值一般设为0.7、行人与骑车人的IoU 值设定为0.5。IoU 越大表明检测要求的误差越小,评价越严格。

图9 车辆、行人、骑车人的分类误差
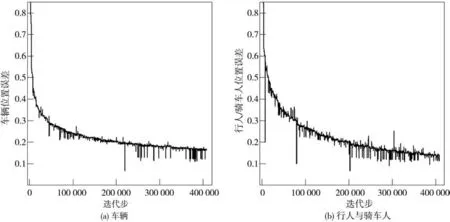
图10 车辆、行人与骑车人的位置误差

图11 KITTI数据集BEV视图与点云算法对比直方图
2.2.3 困难等级
KITTI数据集根据物体被检测的困难程度分为简单(easy)、中等(moderate)与困难(hard)3个等级[24]。其划分的依据为物体在像素坐标系的高度、遮挡程度和截断程度。例如,物体在图像中的高度大于40个像素,不存在遮挡且截断程度小于0.15,则划分为简单难度。
2.3 验证结果与对比
将得到的结果与其他的算法进行比较,比较的评价指标都相同,针对汽车的检测IoU 为0.7,针对行人与骑车人的IoU设为0.5。
2.3.1 与点云算法对比结果
将验证的结果与原算法PointPillars 进行对比,结果如图11 和图12 所示。本算法在BEV(俯视图)和3D 视图中都有提升,在行人与骑行人和较难检测到的车辆检测方面有较大的提升,在俯视图检测中的行人困难模式检测的AP提升最大,可以达到25.3%,在3D 检测中的困难等级车辆AP 提升了6.6%,中等等级行人检测与骑车人AP分别提升13.8%与6.6%,效果较为明显。

图12 KITTI数据集3D视图与点云算法对比直方图
将本算法与目前效果最好的点云处理算法进行比较。在车辆检测中的STD[25]算法的表现较优,在行人与骑车人检测中本方法表现较优,在BEV 视图中的困难等级行人与骑车人检测提升为28.9%和8.1%,在3D视图中两项提升为13.7%和7.3%。
2.3.2 与其他融合算法对比结果
将本算法与其他融合算法比较的结果如图13和图14 所示。在BEV 视图中,本算法在各方面的效果都较好,特别是在困难等级下,汽车、行人与骑车人的AP 值与其他融合算法中的最优结果相比分别提升9.4%、24.0%与14.4%。在3D 视图中的困难模式下,三者提升分别为9.7%、14.4%与18.8%。
2.3.3 运行速度分析
在估计运算速度时,由于不同的作者使用设备的计算能力不同,各算法的运算时间缺少可比性,于是根据不同显卡的运算能力,统一将各类算法的运行时间统一到同一算力的设备上进行比较。由于多数作者在评价设备时采用的是同等算力的NVIDIA GTX1080 Ti 与NVIDIA TITAN X,而各设备的换算会有部分区别,所以结果可能会有部分偏差。
将本文算法速度与其他算法进行了比较,结果如图15 所示。从图中可知,在相同的计算能力下,本文算法的运算速度仅次于PointPillars 算法,基本满足实时性要求。
2.4 验证结果分析
目前主流激光雷达传感器的采样频率为5-15 Hz,而本算法在NVIDIA 1080Ti GPU 级设备中的运算速度可以达到33.3 Hz,故本算法可以满足实时性的要求。
由于点云的稀疏性,激光雷达对较小和较远的物体采集的点云数量很少,算法不能从太少的点云中提取足够的特征进行识别,而增加了颜色特征后,行人或骑车人的颜色与周围环境差异很大,从而能够使算法提取足够多的特征对行人进行检测,大大提高了算法对较难检测物体的识别能力。

图13 KITTI数据集BEV视图与其他融合算法对比直方图

图14 KITTI数据集3D视图与其他融合算法对比直方图
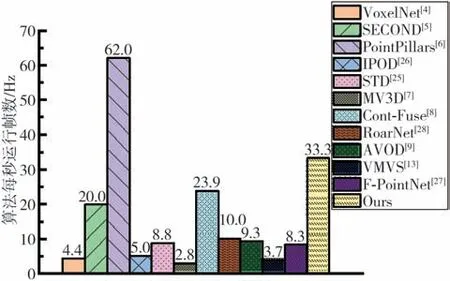
图15 各算法每秒运行帧数对比直方图
因为在光照不足或能见度不高的情况下无法显著提取到图像特征,以上两种环境对特征层融合方法的影响较大。而本文提出的方法本质上依然是对于点云数据进行计算,以上两种情形对于本文算法的影响较小。即使在摄像头完全失效的情况下,本文算法依然能够只根据点云的空间信息,实现对周围环境的感知。
3 结论
提出一种7 维稀疏彩色点云结构,通过空间位置与像素坐标的匹配将图像中颜色信息赋予激光雷达点云数据,并使用改进的PointPillars 算法对稀疏彩色点云进行计算。与其他融合算法或点云算法的对比结果表明,本文提出的融合方法具有较大优势,特别是在行人与骑车人的检测方面比目前主流算法有较大提升,为传感器融合算法的开发提供了一种新思路。
