基于画像技术的车货匹配与精准化推荐方法研究
2021-05-12李红莹张志清
李红莹 张志清


摘 要:在大数据信息技术的推动下,车货匹配平台迅速发展,市场竞争日趋激烈,同时市场对车货信息匹配精准度和效率有了更高要求。提高车货信息匹配的精准度不仅有助于车货匹配平台降低运营成本,提高业务效率,辅助业务决策,从而还可以实现更加有效地提高客户满意度。因此,文章通过对车货匹配现状进行分析,结合车货匹配平台的用户业务数据和行为数据,利用画像技术建立合理的画像标签体系,运用协同过滤推荐算法挖掘出具有不同业务类型的用户群体,以期为用户提供精准化个性服务。
关键词:画像技术;车货匹配;协同过滤
中图分类号:U294 文献标识码:A
Abstract: With the promotion of big data information technology, the vehicle and cargo matching platform develops rapidly, and the market competition becomes increasingly fierce. At the same time, the market has higher requirements for the accuracy and efficiency of vehicle and cargo information matching. Improving the accuracy of vehicle and cargo information matching not only helps the vehicle and cargo matching platform to reduce operating costs, improve business efficiency and assist business decisions, but also can achieve more effective improvement of customer satisfaction. Therefore, by analyzing the status quo of vehicle and cargo matching and combining the user business data and behavior data of the vehicle and cargo matching platform, this paper uses portrait technology to establish a reasonable portrait labeling system, and uses collaborative filtering recommendation algorithm to mine out user groups with different business types, in order to provide accurate personalized services for users.
Key words: user portrait; vehicle-cargo matching; collaborative filtering
0 引 言
随着物流行业的不断发展,人们对物流服务的要求也越来越高,车货的有效匹配不仅可以提高资源的有效利用率,降低空驶率,还能提高客户的满意度。关于车货匹配,目前的研究主要集中在以下几个方面:齐向春[1]借鉴国内外车货平台企业成功发展经验,设计铁路物流车货匹配平台的功能模块和逻辑架构。并结合铁路物流业务的发展需要,提出了近期建成面向鐵路货源的接取送达找车平台,中期建成面向社会货源的车货匹配交易平台,远期建成向物流金融、商贸延伸的车货匹配平台的建设思路。王爽等[2]通过对国内现有车货匹配平台进行分析比较,从车货匹配平台的组成部分、信任机制、监管机制和盈利模式等四方面提出几点创新性建议,将线下资源整合到平台中,对实现车货精准匹配、资源整合和提高行业效率有实际意义。张玲燕[3]首先对配载型物流信息服务平台发展现状进行了概述;其次分析了平台的车货供需匹配主体及匹配原则;再次分析了平台的车货供需匹配运作机理;最后分析了平台的车货供需匹配关键模块。王蓓蓓、崔杰[4]针对含有灰色、模糊等不确定信息的车货供需双边匹配决策问题,利用灰色绝对关联度分析法测度匹配主体的满意度,建立基于匹配距离和匹配距离偏差最小的多目标灰色双边匹配模型,有效地设计车货供需匹配方案,提高双方主体的满意度和匹配率。郭静妮[5]在描述车货供需匹配问题的基础上,建立了车源方与货源方相互的多指标语言评价体系,通对三角模糊数的应用以及模糊数清晰化的效用函数的引入,将语言评价集进行量化,提出了基于车源方与货源方相互满意度整体最高的模糊群决策方法。李慧[6]分析了配载型物流信息服务平台的车货供需匹配机理。结合车货配载供需匹配的实际情况,分析了平台供需匹配的主体、供需匹配的原则、供需匹配的流程、供需匹配的机理、供需匹配的模块及经营模式。为物流信息服务平台的供需匹配模块构建提供了可改进的思路。Gale和Shapley[7]在1962年提出的Gale-Shapley算法,是最先涉及双边匹配决策问题的研究。后续学者将最初的算法做了补充和扩展,把双边匹配决策应用到更多领域,如Roth[8-9]明确界定了“双边”和“双边匹配”的概念,并基于对医学实习生与医院匹配的现实问题研究,提出Hospital-Resident匹配理论。国外数据画像技术,Omar Hasan,Benjamin Habegger等人[10]也分析了在用户画像的隐私挑战的讨论大数据的技术,Ana Stanescu, Swapnil Nagar等人[11]也在用户画像建模方面进行了研究,通过关键字与评价进行建模。Paula Pe?觡a, Rafael del Hoyo,Jorge Vea-Murguía, et al[12]为推特上的用户集体知识本体用户画像进行了研究。
综上所述,本文将车货匹配与画像技术结合起来,提出用画像技术对车货双方进行画像,以便更好地了解双方需求,并运用相似度计算方法对车货双方进行精准匹配,尽可能快速的帮车找到货,帮货找到车,提高资源利用率,降低车辆空驶率。
1 基于画像技术的车货供需匹配模型的构建
1.1 车货匹配用户画像模型
根据获取的有关用户基本信息数据及动态行为数据信息,可以依次构建车货匹配用户画像模型,以实现个性化信息服务。在进行数据处理时,可以利用数据挖掘技术、知识发现技术、信息过滤算法、聚类算法、相似度算法等大数据技术,完成对用户数据信息科学、有效、具体的描述,同时随着用户动态行为数据的不断更新与变化,构建模型的过程也需要不断地优化与更新,才能准确、合理地构建用户画像模型,为数字车货供需精准匹配个性化信息服务提供数据基础与信息保障。构建车货匹配系统,主要包括车主和货主的基本信息,车货匹配平台根据车主的信息和兴趣度,再结合货主拥有的货物类型,结合双方标签用协同过滤的方法为车主和货主双方进行匹配。车货匹配画像模型如图1所示。
1.2 标签体系的设计与构建
车主和货主用户画像由车主维度和货主维度共同组成,其中,车主维度由定性用户画像的车辆属性特征、车主行为特征和车主兴趣特征构成。货主维度是由货物种类 、货物信息等构成。多维度标签体系的构建如表1所示:
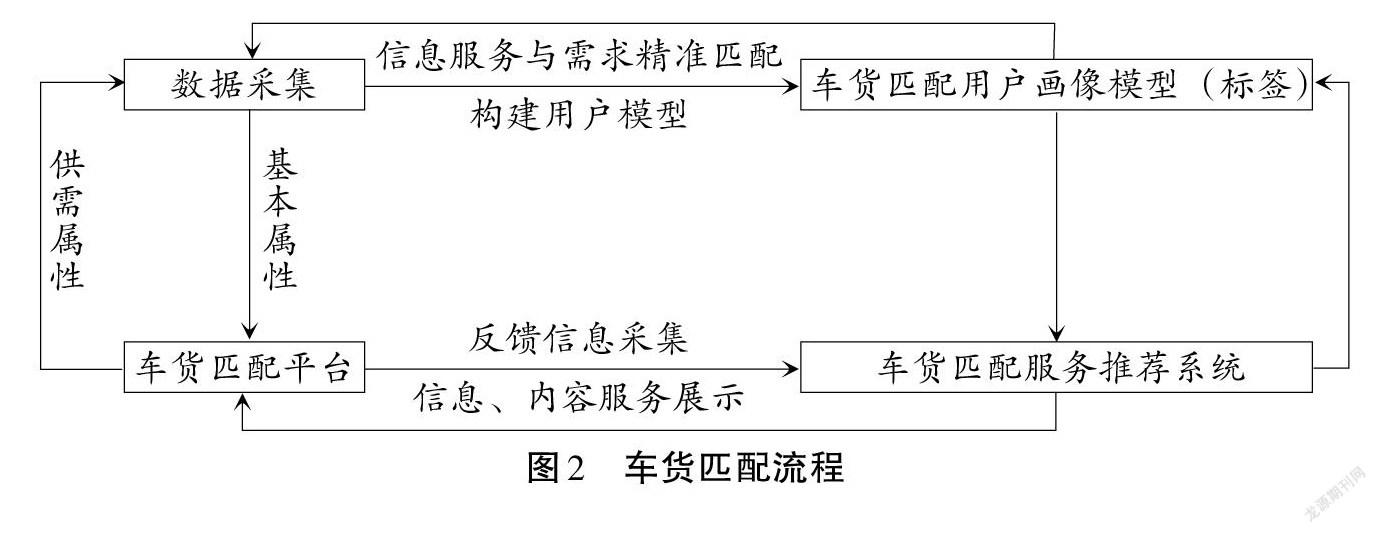
1.3 车货精准匹配流程
通过分析车主和货主的信息和需求,为双方建立各自的标签,用协同过滤方法计算出双方的标签相似度,根据标签信息的相似性通过匹配服务推荐系统,最终为车主找到合适的货物,为货物找到合适的车主,为其双方提供更加精准的个性化服务。车货匹配流程如图2所示。
1.4 数据采集
用户画像是用来描绘目标用户特征的,必须要遵循数据是用户真实有效的信息这一原则,确保信息是真实、客观、可靠的。然后为了保障能够获得有效的用户信息,实现对车货匹配用户的画像,实现车货匹配的优化,本文将数据采集所涉及的内容划分为以下几个维度,包括有用户基本信息、行为偏好、服务价值以及对匹配服务认可参与情况。为了实现对车货匹配用户的画像,本文围绕这些维度在中国物通网搜集了相关信息,主要了解车主的基本信息,比如车型、车长、载重、车主的专业性等。此外还包括车主行为、车主兴趣、车主的服务价值,货源的基本信息等。
2 基于用户画像的协同过滤推荐
本文所要分析的是基于用户的协同过滤推荐,通过该方法为车货供需精准匹配个性化推荐系统进行设计,并计算车货匹配平台中车主和货主的标签相似度,根据两者的相似度进行匹配,这样可以让车主迅速找到合适的货源,让货主也快速找到合适的车辆来运输货物。由于车主和货主信息之间的相似度不仅能通过车主和货主对所推荐项目的评分情况来计算,还能根据车主和货主对待推荐项目所打标签的情况进行分析。当车主和货主对项目的标签打的分数相似时,可以说明车主和货主有着相似的需求偏好,也就是两者有较高的相似度,比如用户u对一个项目的标签属性感兴趣,那么与用户u相似的邻居用户集合u中每一个用户都有可能和u的兴趣偏好具有一定的相似度。例如,用户u的主题兴趣领域分类中车辆和车主的信息偏多,那么用户的邻居用户也应该对车辆和车主相关的主题兴趣领域比较感兴趣。目前很多学者将用户信息和项目信息使用到核心算法的改进中,而且对用户和项目的建模不断完善,最后得到的推荐结果信息的精准度就越高,基于用户的协同过滤推荐算法的主要步骤如下所示:
2.1 构建用户评分矩阵
根据前面画像技术建立的标签,用集合T,T,…,T表示标签集,车主的集合用U,U,…,U表示,货主的集合用V,V,…,V表示,R表示车主i在标签j上的权重。权重评分值介于0~4,假设T=4则表示车主i具备标签属性j权重为 4,T=0代表车主i不具备标签属性j,用户对项目的评分矩阵是车主和货主双方对某一标签的综合评分。
从标签属性表中可以计算得出标签属性的偏好矩阵S,从用户项目评分表中直接得出该用户的评分数据矩阵R。其中,属性偏好矩阵S的维度为m×k,m表示车主的个数,整体的标签特征总和为k,Weight表示活跃车主i所评价的所有项目的第j个标签特征的总权重。R矩阵用来表示用户的评分数据,其维度为m×n,维度m代表注册用户个数,维度n代表待推荐项目个数。当r≠0时表示用户i在过去的一段时间内对项目j有过评分,评分值为r;当r=0时,则表示用户i对项目j的记录中没有过评分。评分矩阵如下:
S=, R=
其中:Weight=∑T,C为用户i评分的所有项目集合。
2.2 计算标签相似度
根据标签属性偏好矩阵S和公式(1)来计算系统中各个用户的标签属性偏好量:P=P,P,P,…,P;接着使用公式(2)来分别计算两个用户的标签偏好量的相似度Similarityu,v,u和v代表两个用户。
P= (1)
Weight代表用户u对项目第i个标签属性的总权重,Weight=∑T, C為目标用户所评分的所有项目和。同样使用Weight来代表用户所评论的所有相关项目包含的所有标签属性的总权重:
Weight=∑Weight
Similarityu,v= (2)
2.3 生成推薦结果
3 车货供需精准匹配实例分析
车主和货主画像:
在中国物通网随机获取一些相关信息,主要包括车主和货主的基本数据信息,通过对获得的相关数据信息进行数据清理后,并将部分数据进行数据清理后,下面选取10位车主和货主的信息作为本文的样本,如表4、表5所示,车货匹配结果如表6、表7、表8所示。
通过标签打分以及上述相似度公式计算发现货主3和粤B**345的相似度高于货主3和粤B**2K5以及货主3和粤S**819,所以把货主3推荐给粤B**345较为合适。
4 结论与展望
本文的主要研究内容是在车货匹配领域,针对用户平台画像,分析相关数据,并且从用户基本信息、行为偏好、服务价值以及对匹配服务认可参与情况等几个维度建立车货匹配标签模型,以及用户画像的生成标签属性和每个标签权重的计算获取,也对用户画像的意义进行了相应的分析,结果发现基于画像技术的车货供需精准匹配不仅优化了用户体验还实现了货物的精准匹配。由于推荐系统在快速的发展,其研究方向也呈现出不同的趋势。与此同时大量数据的堆积和冗余也使进行精准的用户数据画像研究成为可能。面对新技术的挑战,后续的研究工作还很长远,需要在实时性以及用户和项目的建模两个方面进行深入研究。
参考文献:
[1] 齐向春. 我国铁路物流车货匹配平台设计研究[J]. 铁道运输与经济,2018,40(6):29-34.
[2] 王爽,刘立强,葛林,等. 车货匹配平台创新模式探讨[J]. 黑龙江科学,2017,8(4):30-31,33.
[3] 张玲燕. 基于配载型物流信息服务平台的车货供需匹配技术研究[J]. 粘接,2020,43(9):189-192.
[4] 王蓓蓓,崔杰. 基于灰色绝对关联度的车货双边匹配决策研究[J]. 价值工程,2019,38(23):122-125.
[5] 郭静妮. 基于模糊群决策方法的车货供需匹配研究[J]. 交通运输工程与信息学报,2017,15(4):141-146.
[6] 李慧. 配载型物流信息服务平台的车货供需匹配研究[D]. 北京:北京交通大学(硕士学位论文),2015.
[7] Gale D, Shapley L. College admissions and the stability of marriage[J]. American Mathematical Monthly, 1962,69(1):9-15.
[8] Roth A E. Common and Conflicting Interests in Two-Sided Matching Markets[J]. European Economic Review, 1985,27(1):75
-96.
[9] Roth A E. On the Allocation of Residents to Rural Hospitals: A General Property of Two-Sided Matching Markets[J]. Econometrica, 1986,54(2):425-427.
[10] Hasan O, Habegger B, Brunie L, et al. A discussion of privacy challenges in user profiling with big data techniques: The EEXCESS use case[C] // 2013 IEEE International Congress on Big Data. IEEE, 2013:25-30.
[11] Stanescu A, Nagar S, Caragea D. A hybrid recommender system: User profiling from keywords and ratings[C] // 2013 IEEE
/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT). IEEE, 2013,1:73-80.
[12] Paula Pe a, Rafael del Hoyo, Jorge Vea-Murguía, et al. Collective Knowledge Ontology User Profiling for Twitter[C] // IEEE/WIC/ACM International Conferences on Web Intelligence (WI) and Intelligent Agent Technology (IAT), 2013.
