基于混合信任模型的协同过滤推荐算法
2016-08-19彭玉


摘要:协同过滤技术在面临评分数据稀疏性问题时,推荐效果较差。为了提高推荐系统的推荐精度,可以将用户在社会网络中的交互信息加入到推荐系统中来,弥补评分数据不足的问题。在本文中,提出一种基于混合信任模型的协同过滤推荐算法,该算法将用户在社会网络中的历史评级信息和交互频率合并计算用户之间的直接信任度,并通过一定的信任传递规则将没有直接关联的用户间的间接信任度也计算出来,组成稠密的用户信任矩阵。最后基于用户信任矩阵和用户评分矩阵共同来计算用户之间的相似度并预测目标用户对未评分项目的评分,得到推荐集。实验结果表明本文提出算法可以提高数据密度,改善协同过滤推荐技术的稀疏性问题,有效提高推荐精度。
关键词:协同过滤;信任模型;基于信任的推荐算法;相似度;社会网路
中图分类号:TP31 文献标识码:A 文章编号:1009-3044(2016)20-0257-04
Abstract: In the face of rating data's sparsity problem, the recommendation effect of collaborative filtering technology is not so good. In order to improve the accuracy of recommendation system, we can add the interaction with the user information in social networks into the recommended system, in order to make up for the shortage of data rates. In this paper, we set up a hybrid trust model based on collaborative filtering algorithm, which combine the user rating information and interaction frequency in a social network, and calculate direct-trust-relationship between users. Following, the indirect-trust-relationship is also calculated by using some certain trust rules, and at last it forms a dense matrix of user trust. Finally, we calculate the similarity between users and predict the target ratings based on user-trust-matrix and user-scoring-matrix and get recommended set. Experimental results show that the proposed algorithm can increase data density, improve the sparsity problem of collaborative filtering technology and effectively improve the recommendation accuracy.
Key words:Collaborative filtering; Trust model; Trust-based recommender algorithm; Similarity;Social networks
1 引言
一个社交网站,比如脸谱网、微博,已经成为互联网用户不可或缺的一部分。信息技术和互联网技术的普及和迅猛的发展,加剧了信息过载问题,增加了用户获得有用信息的成本。推荐系统作为一种过滤技术,可以有效缓解信息过载问题,为用户提供优质的个性化服务[1]。在传统的个性化推荐算法中,协同过滤算法无疑是最成功的一种算法。协同过滤推荐算法是基于某些特定项目的用户之间的相似性偏好来预测推荐结果的。更一般而言,如果他们在某些项目上有类似的利益,他们最有可能对一些其他项目感兴趣。基于协同过滤的方法首先基于项目或基于用户的相似性度量计算发现邻居项目或邻居用户,然后通过相似性的邻居的历史偏好来预测目标用户的偏好。虽然协同过滤是有效的,但当评分数据稀疏,用户没有足够的历史评级数据来支撑相似性计算时,推荐效果表现不佳。此外,基于协同过滤的推荐系统忽略了用户之间的社会关系或信任关系,很多研究者也考虑利用社会网络关系信息来提高协同过滤推荐系统性能。
基于信任的推荐系统试图通过引入信任度量解决数据稀疏性问题,采用用户项目评分信息和用户社会信任网络信息来共同计算相似度[2]。如果两个用户有非常少的共同评分项目,只从他们的共同额定项目的评级信息计算的信任值可能会产生误导性的信任。虽然传统的基于信任的比照系统已经提出了基于评级的信任模型,或明确指定的信任指标,以获得用户的可信性,由于用户间共同评分数据的极度稀疏性,造成信任值度量的误差很大,对推荐系统精度的改良意义不大。所以本文提出一个新的混合信任度量模型,利用用户的历史评分数据和用户在社会网络中的互动交互频率来共同计算直接信任值,再通过一定的信任传递规则来计算没有直接联系和没有共同评分项目的用户之间的间接信任值,合并得到用户信任矩阵。最后基于信任矩阵和用户评分矩阵来共同预测评分,得到推荐结果。
2 传统协同过滤方法
2.1 传统相似性计算方法
协同过滤推荐的关键点是不同用户之间的相似性度量。广泛采用的方法是基于用户的共同历史评分数据项量来进行相似度的计算。在相似性计算方法中,虽然各有其优缺点,但最常用的相似性度量方法是余弦相似性、修正的余弦相似性和皮尔森相似性[3]。
2.2 基于信任的协同过滤算法
信任被定义为一个用户对另一个用户可靠性的主观信念。信任可以分为直接信任和间接信任,直接信任是用户间直接交互作用而建立的信任,而间接信任是一个用户通过信任传播的方式和别的没有直接联系的用户间的信任关系。假设信任度量的目的是量化用户之间的信任程度,如果信任关系没有明确表示,可以从评级数据或其他间接信息中推断出来。此外,许多研究人员将信任引入到基于用户的协同过滤的推荐中,并提出了许多信任模型。例如,从逻辑的角度研究用户之间的信任关系,Pitsilis提出了一种基于不确定概率理论的信任模型[6]。然而,由于不确定性是由用户的平均评分计算得到,而评分矩阵的稀疏性导致信任模型的准确性是有限的。Kwon等人研究了一种多维信任模型来测量用户间相似度,然后计算一个加权汇总选择邻居[7]。然而,尽管该模型在选择邻居的过程中有更多的多样性,但它仍然缺乏抵抗攻击的能力。为此,本文针对上述问题,在前人的研究基础上提出了一种改进的基于信任的协同过滤推荐算法,探讨了一种计算用户间信任度的新思路,然后将信任度和相似度按照一定原则组合,根据组合的相似度来搜索最佳邻居得到推荐。
3 基于混合信任模型的协同过滤推荐算法
本文提出的改进的基于信任的协同过滤算法将用户评分矩阵和用户之间的交互信息作为输入并计算用户间之间信任值,再基于一种信任传递规则来计算用户间接信任值。将直接信任值和间接信任值组合成为较稠密的信任矩阵。信任矩阵和评价矩阵被共同用来寻找目标用户的K近邻,并计算目标用户对未评分项目的预测评分,最后选择预测评分较高的项目作为推荐列表反馈给目标用户。
3.1 直接信任度量
信任权重是用户对另一个用户信赖程度的量化,信赖程度越高,其权重越大。但许多网站并没有提供用户表达的直接信任权重。因此,本文使用用户的评级项目和用户的互动来计算用户之间的直接信任值。用户之间交互频率越高,他们之间的相互作用就越强,用户的行为也更容易受到他们信任的朋友的影响,所以接下来我们定义了一个直接的信任度的度量方法。
(1)基于历史评分等级的直接信任度量
基于历史评分等级的直接信任度量主要是通过用户-项评分矩阵中用户对项目的评分数据来进行的,比如用一个用户对某一项目的评分去预测另一个用户的对该项目的评分,若预测评分与该用户实际对该项目的评分差异较小,我们认为这个用户推荐人是更可靠的,他们之间的直接信任值便相对较高。参考传统的信任计算模型,我们可使用雷斯尼克的预测公式来计算出依赖于用户得到目标用户的预测评分,计算方法定义如下:
3.2 间接信任度量
在现实生活中,人们不仅信任自己的朋友,还可以与朋友的朋友建立新的信任关系,这就是信任的传递规则。如果用户A信任用户B,用户B的信任用户C,虽然用户A,C之间没有直接信任关系,但通过用户B,用户A,C之间便可以找到一种可达的信任关系,也就是说信任是可以繁殖传播的。在本文中,我们将使用此功能扩展本地信任网络。类似地,我们可以在网络中获得这种间接信任关系。
在一段时间内,用户与用户之间没有任何交互联系,也没有一个共同的历史评分项目,也就是说,没有直接的信任关系。若用户和用户之间存在信任连通路径,如,其中都是该可达路径上的中间用户,则用户和用户之间可能存在间接信任关系。用户对用户的间接信任值定义如下:
在这里,表示用户和用户之间的可到达路径的长度。
根据上述方法,可以计算出所有用户之间的信任值,并可以形成一个关于所有用户之间的信任度矩阵,后面用到的信任相似度便是矩阵中用户所在行向量中各元素取值。
3.3 组合信任值的相似度计算
在上节中,通过计算用户之间的信任关系,反映了互动效应。因此,用户之间的信任度越高,它们之间的相互作用越大,就越相似。信任关系在一定程度上也反映了用户之间的相似性,因此本文提出的基于信任的协同过滤方法是用户信任矩阵中的信任值和用户评分相似性按照一定方式进行组合,组合后的权重作为新的相似度参与目标用户对未评分项目的预测评分。基于如上分析,我们提出了一种新的用户评分相似度和用户信任关系的评价方法,在最近邻对象的选择上,我们需要确定如何选择推荐对象的预测目标。通过定义两个相似度阈值,即用户的评分相似度阀值和用户信任度阀值。同时我们定义评分相似度大于相似度阀值的用户集合为评分相似邻居集记为,信任度大于用户信任度阀值的用户集合为信任邻居集记为,后续会合并评分相似度邻居集和信任邻居集来为目标用户作推荐。为评分相似度和信任度组合的权重因子,的最优取值问题会在后续实验中进行讨论。
最终的推荐相似度可以组合计算如下:
3.4 最终的预测评分值计算
在获得直接信任值和间接信任值后,本文提出方法通过目标用户的评分相似度邻居集合和信任邻居集合的并集记为来对目标用户未评分的所有项目进行预测评分。最后选择预测评分值较高的项目作为推荐结果反馈给目标用户。
4 实验结果
4.1 数据集
为了验证本文新提出的推荐算法比传统的协同过滤算法具有更好的性能,我们收集了MovieLens站点的相关数据集来完成相应实验。MovieLens数据集是最常用来测试推荐算法性能的标准数据集。此数据集包含100000个等级从1到5的评价数值,由943名用户对1682部电影的评价。在这个数据集中,用户被要求至少对20部电影进行评分,数据稀疏率是95%左右。在实验中数据集被分为训练和测试部分(80%用于训练测和20%用于测试集)。
4.2 结果分析
1)实验1:通过调节评分相似度和信任度组合的权重因子来对比推荐精度MAE的值
在本实验中我们将测试参数取不同值对推荐精度MAE值的影响。∈[0,1],的值从0开始,每次增加0.1,纵坐标为推荐精度MAE的值,观察纵坐标MAE值的变化,并将本文提出算法和“基于用户的CF” 以及“基于信任的CF”作对比,发现当参数取值为0.6时推荐效果最佳。
2)实验2:本文算法与其他协同过滤推荐算法的比较
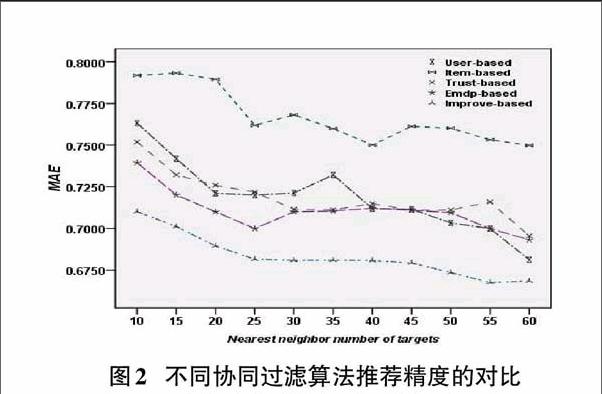
本实验的目的是将本文提出算法与传统的协同过滤算法以及近期业界比较领先的研究方法EMDP(Effective Missing Data Prediction)进行比较。我们使用相同的实验数据,比较了该算法与传统的协同过滤算法,如基于项目的CF”,“基于用户的CF”,“基于信任的CF”以及文献[5]中提出的EMDP算法在推荐精度方面的差异。在这个实验中,取值为0.6,和“最近邻数数目”取值范围为[10,60],每次增加5个邻居。实验结果如图2所示。实验结果表明,本文提出的方法可以得到较低的MAE值,因此推荐效果更好,随着产品最近邻居数目的增加,预测的质量也在不断提升。
5 结论
协同过滤是目前推荐系统所使用的主流技术,但用户项评分矩阵的稀疏性问题是协同过滤技术的主要限制之一。为了解决稀疏性问题,本文提出了一种改进的基于信任的协同过滤推荐算法。该算法使用用户的评级数据和交互信息作为推断,产生一个信任矩阵,代表用户之间的信任值,然后将信任值是用来纠正传统相似性计算并以此来寻找最近邻居用户得到未评分项目的预测评分。由于本文提出的改进算法能搜索到更优的邻居用户,所以使得推荐算法的推荐精度有较大提升。实验结果表明,该算法优于最近邻协同过滤的预测质量。与传统的基于项目的协同过滤算法、基于用户的协同过滤算法、基于上下文的协同过滤算法、基于信任的协同过滤算法以及目前业界比较先进的EMDP算法在推荐精度方面作了对比,推荐性能较好,能很好缓解数据稀疏性问题对推荐精度的影响。由于要计算用户之间的信任度,会增加推荐系统的时间开销,不过可以将信任度的计算离线进行,减少对系统响应时间的影响。未来的研究,以提高该算法的时间性能以及提高算法的抗恶意攻击能力等。
参考文献:
[1] 彭玉,程小平. 基于属性相似性的Item-based协同过滤算法[J].计算机工程与应用,2007,43(14),144-147.
[2] 李湛,吴江宁.基于用户行为特征分析的隐形信任协同过滤推荐方法[J].情报学报,2013,28(5),490-496.
[3] 邓爱林.电子商务推荐系统关键技术研究|D|.上海:复旦大学.2003
[4] Herlocker J. Konstan J A, Riedl J. An empirical analysis of design choices in neighborhood-based collaborative filtering algorithms[J]. Information Retrieval, 2002, 5(4): 287-310.
[5] Ma H, King 1, Lyu M R. Effective missing data prediction for collaborative filtering// Proceedings of the 30th Annual International ACM SIGIR Conference[C]. Amsterdam, The Netherlands, 2007: 39-46.
[6] Pitsilis, Georgios, and Lindsay Forsyth Marshall.A model of trust derivation from evidence for use in recommendation system[D].University of Newcastle upon Tyne, Computing Science, 2004.
[7] K. Kwon, J. Cho and Y. Park. Multidimensional credibility model for neighbor selection in collaborative recommendation[J]. Expert System with Applications, 2009,36(3):7114-7122.
