基于多特征融合卷积神经网络的显著性检测*
2021-05-11赵应丁岳星宇杨文姬张吉昊杨红云
赵应丁,岳星宇,杨文姬,4,张吉昊,杨红云,4
(1.江西农业大学软件学院,江西 南昌 330045;2.江西农业大学计算机与信息工程学院,江西 南昌 330045;3.华中科技大学外国语学院,湖北 武汉 430074;4.江西省高等学校农业信息技术重点实验室,江西 南昌 330045)
1 引言
人类视觉注意力机制使得人眼能够快速地从视觉场景中获取到感兴趣的区域并传递给大脑,大脑重点处理感兴趣区域细节信息,这种方式大大加速了人类对视觉场景的理解。显著性检测即模仿人类视觉注意力机制,通过一系列的处理获得图像中容易引起人眼注意的区域或目标,其能够大大降低后续处理的复杂度,因此被广泛应用于计算机视觉领域,其中包括目标检测[1]、语义分割[2]、图像描述[3]、视频摘要[4]和无监督视频对象分割[5]等。
由于卷积神经网络CNN(Convolutional Neural Network)在计算机视觉领域中的突出表现,基于CNN的深度显著性检测方法成为显著性检测的主流方法。相比于传统的显著性检测方法,深度显著性检测方法不需要人为设计特征,能够自动学习有利于显著性检测的特征,使得到的显著性目标更加准确,而且深度显著性检测方法具有更强的鲁棒性。近几年,各种各样的深度显著性检测方法被提出。比如,Wang等人[6]通过集成局部估计和全局搜索来预测显著性图:首先使用深度神经网络学习局部块特征,为每个像素提供显著性值;然后将局部显著性图、全局对比度和几何信息合并在一起,输入到另一个神经网络中,预测每个区域的显著性值。Zhao等人[7]提出一种用于显著对象检测的多上下文深度学习框架,设计2个不同的CNN,以独立捕获每个分割段的全局和局部上下文信息,最后通过回归器确定每个分割段的显著性值。Lee等人[8]将CNN提取的高级语义特征和人工设计特征进行融合,通过全连接神经网络预测每一个查询区域的显著性。Hou等人[9]通过添加短连接对HED(Holisitcally-nested Edge Detector)网络进行更改,使其能够用于显著性检测,短连接的方式使得底层网络可在高层语义特征指导下,更好地定位显著性目标或区域,同时底层网络也能够优化高层网络的输出结果。Li等人[10]提出多分支CNN,网络最后分为2个分支,2个分支分别进行语义分割和显著性检测,通过这样的策略,网络中共享的部分就能够产生对对象感知更有效的特征,促进显著性检测。Wang等人[11]提出一种用于显著性检测的循环全卷积网络,并将显著性先验融合到全卷积网络中,利用显著性先验不断地修正之前的检测结果,从而获得更加准确的显著性图。文献[12]将3个VGG16网络并联,使得网络能够提取不同尺度的特征,然后通过融合3个VGG16网络预测的结果获得最终的显著性图,虽然能够得到更准确的结果,但是网络并联极大地增加了参数量。Luo等人[13]同样使用VGG16作为骨干网络,提出一种多尺度的网络模型,通过融合不同尺度下的检测结果得到最终的显著性图。文献[14]通过利用输入图像的对比度信息提出一个深度对比度网络,它结合了像素级完全卷积流和分段空间池化流,最后使用条件随机场进一步完善来自对比网络的预测结果。Liu等人[15]设计了一个2阶段的深度网络,通过该网络生成粗略的显著性图,然后使用递归的CNN逐步地完善显著性图的细节。
虽然深度显著性检测方法发展极快,很大程度上提升了显著性检测结果的准确性,但是它也存在如下问题:(1)受卷积核尺寸的限制,网络底层只能在较小感受野内提取特征;(2)CNN是通过不断堆叠卷积层的方式获取全局特征的,网络将局部信息从底层传递到高层,在高层综合局部信息获得全局信息,逐层传递的过程会造成大量信息遗失,此外,网络太深也会导致计算开销加大,难以优化。本文提出一种基于多特征融合卷积神经网络,该网络具备在多个尺度下学习局部特征和全局特征的能力,最后通过融合不同尺度的结果获得最终的显著性图。本文在多特征融合卷积神经网络中加入局部特征增强模块和全局上下文模块,较好地解决了上述2个问题。
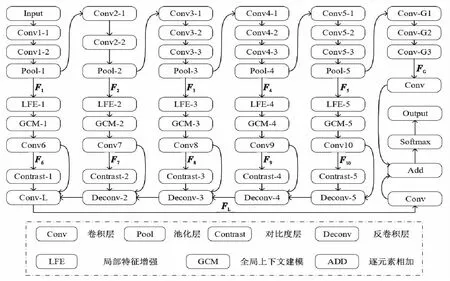
Figure 1 Structure diagram of multi-feature fusion convolutional neural network图1 多特征融合卷积神经网络结构图
2 网络结构的设计
纵观文献,好的显著性特征必须考虑图像的局部和全局上下文信息,并融合各种分辨率的细节特征。为达到上述目的,本文设计了一种基于多特征融合卷积神经网络的显著性检测方法。该方法的网络结构图如图1所示,网络使用VGG16作为骨干网络,并将其最后3层全连接层替换成全卷积层,用于提取全局特征。VGG16网络中包含5个池化层,每次池化操作后特征图大小都只有原来的一半,5次池化后将会获得5种分辨率的特征图。在网络的每个池化层后,都加入侧出部分用于提取特定分辨率的特征,这样,网络就具备学习多尺度特征的能力。网络的侧出部分:第1行由局部特征增强LFE(Local Feature Enhancement)模块组成,LFE大幅地增加了网络的特征提取范围;第2行由全局上下文建模GCM(Global Context Modeling)模块组成,GCM用来学习特征图的全局信息,然后将学习到的全局信息融合到特征图中,并输入到下一行的卷积层中;第3行的卷积层通过对包含了全局信息的特征图的学习,得到不同分辨率的多尺度局部特征图;第4行由对比度层组成,目的是捕获多尺度局部特征图中前景和背景的差异信息,学习对比度特征;最后一行用于融合多尺度局部特征图和对比度特征图;由于每一列局部特征图的分辨率不统一,所以增加了反卷积层,从分辨率小的特征图开始,逐层从后往前进行融合,最后通过一个卷积层来得到侧出部分输出的最终局部特征。将最终的局部特征和全局特征分别通过一个卷积层再相加,获得包含局部和全局的特征,最后通过Softmax输出预测的显著图。
2.1 多尺度特征图的产生
对于给定图像I,首先将图像尺寸调整为416*416,然后输入到如图1所示的网络中。网络采用VGG16作为骨干网络,网络的每一次池化操作都会使得特征图大小变为原来的一半,经过5次池化操作(Pool-1到Pool-5)即可得到5种分辨率的特征图,记为{F1,F2,F3,F4,F5}。
2.2 局部特征增强模块
在CNN中,卷积操作只在感受野内进行,对于特征图中的每个位置,都是以该位置为中心点,将该位置及其周围邻域位置进行加权求和得到新的特征图中该位置对应的滤波结果。对于显著性检测而言,更大的感受野可以更好地帮助网络定位感兴趣区域。在网络底层,相对于特征图尺寸,感受野尺寸太小,感受野范围内的特征变化不明显,导致局部对比不强烈,不利于显著性检测。因此,可以适当增加感受野范围,而感受野大小受到卷积核尺寸的限制,所以可以通过增加卷积核尺寸来增加感受野范围,使网络能够在更大视野范围内提取特征,从而达到增强局部特征的目的。但是,直接采用更大卷积核势必伴随着参数量的大幅增长,例如,对于一个13*13的卷积核而言,其参数数量是3*3卷积核的18.8倍,因此,直接使用13*13卷积核会造成负担不起的计算花销。
基于此,本文在前述提取的特征上加入局部特征增强模块,在只增加较少参数量的情况下大幅度增大了感受野的范围,从而达到了增强局部特征的目的,局部特征增强模块的结构如图2所示,其中,H*W表示特征图尺寸,C表示通道数。该模块可以提取到13*13范围内的特征,但相比13*13卷积核的参数量,该模块的参数量减少了83.4%,为3*3卷积核参数量的3倍。
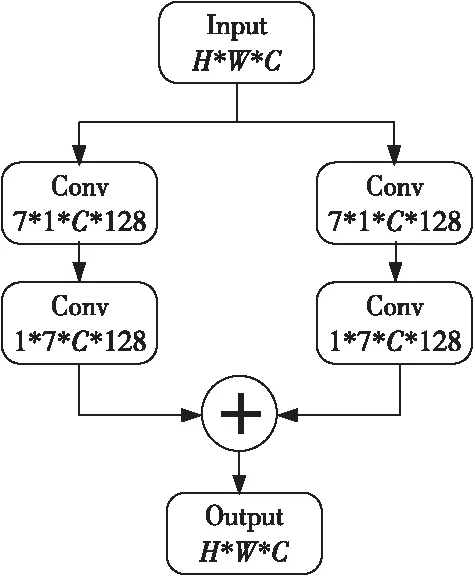
Figure 2 Local feature enhancement module图2 局部特征增强模块
2.3 全局上下文建模模块
全局上下文信息也是显著性检测的有效线索。在CNN中,首先,卷积层通过卷积核对特征图进行局部感知,然后通过不断堆叠卷积层方式,将底层感知的局部信息逐层向网络高层进行传递,在网络高层中综合这些局部信息来获得全局信息。这样的方式有很大局限性,堆叠卷积层会大量增加计算量,增大网络优化难度,而且信息从底层传递到高层的过程中也会造成信息的大量遗失。
本文通过在传统CNN网络中嵌入全局上下文建模模块[16]的方式克服上述问题,使得网络不需要通过叠加卷积模块就能够快速地获得对特征图的全局理解。该模块的具体结构如图3所示,其中X和Z分别表示输入和输出,Wk、Wv1、Wv2表示3次卷积操作,r控制通道数量。模块主要分为3个阶段:首先获取全局上下文信息,然后通过卷积操作进行特征转换,最后通过逐元素相加的形式进行特征融合。
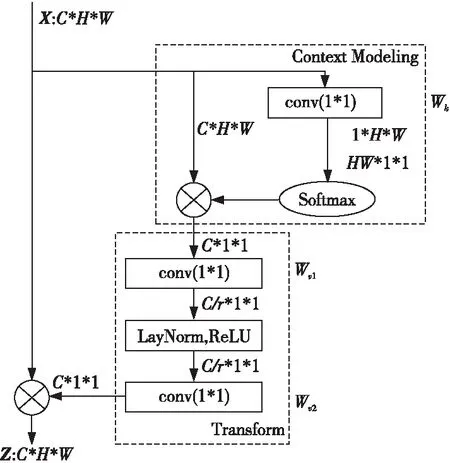
Figure 3 Global context modeling module图3 全局上下文建模模块
2.4 对比度特征的产生

(1)
其中,F′i表示Fi局部平均池化后的结果,平均池化的核尺寸为3*3。
2.5 多尺度局部特征图的形成
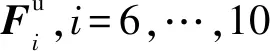
(2)
其中,concat表示特征图融合,Deconv表示反卷积操作。

(3)
2.6 全局特征图
检测图像中的显著性对象需要捕获图像的全局信息,因此,本文在Pool-5层后,使用3个卷积层Conv-G1、Conv-G2和Conv-G3替换VGG16网络中的3个全连接层,用来获得全局特征,将全局特征记为FG,这3个卷积层均包含128个特征通道,卷积核尺寸分别是7*7,5*5和3*3。
2.7 最终显著性图
组合前面得到的局部特征FL和全局特征FG来计算最终的显著性图S,本文使用局部特征和全局特征的线性组合来计算显著性图,最后,使用Softmax函数计算每个像素v是显著性对象的概率P,具体如下:
S(v)=P(G(v)=c)=
(4)
其中,G(v)表示人工标注图G中的像素v,c和c′分别代表类别和类别集合,wL和wG表示局部和全局权重参数,bL和bG表示局部和全局偏置参数。
3 损失函数
显著性检测可以认为是二分类任务,而在二分类任务中,通常使用的损失函数为交叉熵损失。交叉熵损失能够衡量真实概率分布和预测概率分布之间的差异性。二分类的交叉熵损失计算公式如式(5)所示:
(5)
其中,N表示样本个数;G和S分别表示人工标注的显著图和网络预测的显著图。
4 实验及分析
4.1 网络训练
为了缩短网络的训练时间,使用预训练的VGG16网络权重对网络的骨干部分进行初始化,网络的其余部分采用随机初始化。网络使用Adam优化器优化目标函数,初始学习率设置为10-6,β1=0.9,β2=0.999。
选用MSRA-B数据集作为网络的训练集,其中,BatchSize被设置为1,图像在输入网络之前尺寸会被重新调整为416*416,总共训练20轮,总耗时22 h。训练使用的计算机主要硬件配置如表1所示。

Table 1 Computer hardware configuration
4.2 对比其它方法
为了验证所提方法的有效性,分别在HKU-IS、DUT-OMRON、ECSSD和SOD数据集上对网络性能进行了验证。这4个数据集均提供像素级的人工标注图,各个数据集的简要说明如下:HKU-IS数据集包含4 447幅图像,大多数图像对比度低且具有多个边界重叠的显著性目标;DUT-OMRON数据集由5 168幅图像组成,大部分图像具有比较复杂的背景;ECSSD数据集共有1 000幅图像,图像内容多是包含结构复杂的自然场景;SOD数据集包含300幅图像,大多数图像中包含多个显著性目标,而且显著性目标和背景的颜色对比度较低。
在上述4个数据集上,将本文方法同其它11种显著性检测方法(MR[17]、HDCT[18]、TLLT[19]、RFCN[11]、NLDF[13]、DS[10]、DCL[14]、ELD[8]、SBF[20]、UCF[21]和RSD[22])分别在视觉和定量分析上进行了对比,其中前3种方法属于传统显著性检测方法,后8种方法是深度显著性检测方法,实验结果表明,本文方法优于参与比较的方法。
4.2.1 视觉对比
为了将本文方法检测的显著性图和由其它11种方法生成的显著性图进行视觉对比,在此,分别从HKU-IS、DUT-OMRON、ECSSD和SOD数据集中选择具有复杂背景或前景和背景对比度比较低的图像进行对比,具体结果如图4所示,其中GT表示人工标注的结果。

Figure 4 Saliency detection results of different methods图4 本文方法与11种方法的视觉对比图
通过观察图4可以发现,深度显著性检测方法的结果整体上是优于传统显著性检测方法的,后者错检和漏检的情况比较明显。观察深度显著性检测方法的结果(图4f~图4n)可以发现,它们都大致检测出了显著性目标的主要区域,观察图4c、图4d、图4g和图4h发现,大多数深度显著性检测方法虽然检测出了显著性目标的主体,但轮廓却不够完整,缺失较多边界细节,只有本文方法不仅准确检测出了显著性目标,同时保留了比较完整的目标轮廓(从图中可以看出,本文方法的检测结果不仅包含了老虎和山鸡的主体部分,其中比较细小的尾巴区域也被较完整地检测出来),因此本文方法的有效性得到了验证。
4.2.2 定量分析
为了从多个角度评价本文方法的有效性,本文还使用了PR曲线、F-measure、均值绝对误差MAE(Mean Absolute Error)和S-measure等4个指标评来价网络模型的性能。
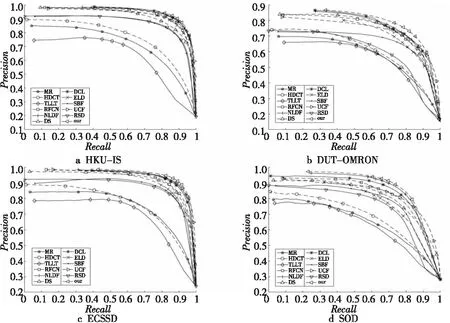
Figure 5 PR curves of different methods图5 各方法的PR曲线
(1)PR曲线。
PR曲线是显著性检测中最常用的评价指标。精确率Precision和召回率Recall是在二值显著性图和真值图上计算得到的,因此在计算Precision和Recall时,首先要将显著性图转换为二值显著性图。通常将显著性图转换为二值显著性图的方法是将阈值设置为0~255对检测的显著性图进行分割,每个阈值可得到一个二值显著性图,每个二值显著性图都对应一对Precision和Recall,所有的Precision和Recall对就形成了一条PR曲线,用来描述显著性检测模型的性能,PR曲线越靠近右上角(坐标(1,1)处),就表明模型的性能越好。Precision和Recall的计算公式如式(6)所示:
(6)
其中,TP表示人工标注为正类,同时被预测为正类的结果;FP表示人工标注为负类,但是被预测为正类的结果;FN表示人工标注为正类,但是被预测为负类的结果。在显著性检测中,正类表示显著性像素,负类表示背景像素。
各方法的PR曲线如图5所示,从图5中可以比较明显地看出,在4个数据集上,深度显著性目标检测方法都明显优于传统显著性目标检测方法;图5中的各深度显著性目标检测方法之间的PR曲线区分度较小,但不难发现,本文方法的PR曲线(所示的曲线)更加靠近外侧,说明在这些数据集上,本文方法的检测结果要更加准确。
(2)F-measure。
F-measure通过计算精确率和召回率的加权调和平均值全面考虑精确率和召回率,计算公式如式(7)所示:
(7)
本文同大多数方法一样,将β2设置为0.3,更加强调Precision。一些方法会使用自适应阈值(阈值为显著图平均值的2倍)分割显著性图,计算相应的平均F-measure值;另一些方法会直接使用最大F-measure值,本文使用最大F-measure。
本文方法和其它11种方法在4个数据集上的F-measure对比结果如图6所示,在4个数据集上,本文方法的F-measure分别是0.897,0.732,0.904和0.821。由于本文方法同时考虑了多尺度,局部增强特征和全局上下文特征等有益于显著性检测的因素,可以发现,本文方法在4个数据集上的F-measure均高于另外11种方法的,和排名第2的深度显著性检测方法对比,本文方法的F-measure也高出了1到2个百分点。
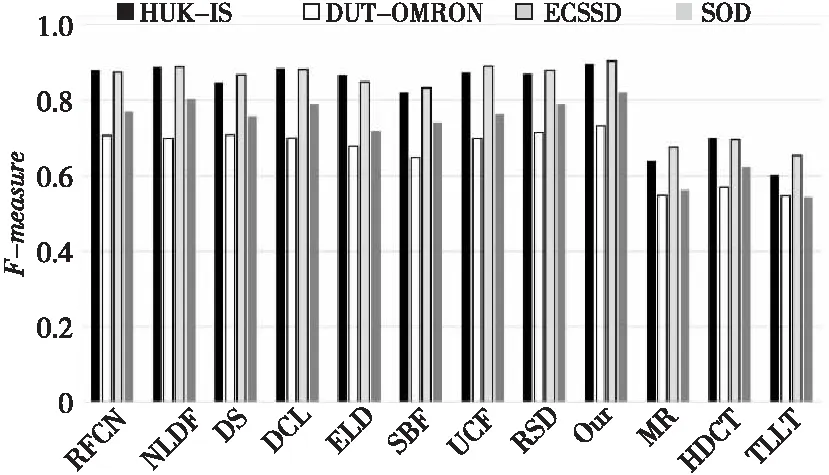
Figure 6 F-measure of different methods on different datasets图6 各方法在不同数据集上的F-measure
(3)MAE。
PR曲线和F-measure在显著性目标检测中使用的频率很高,但是它们也存在问题,即它们都没有考虑非显著性像素的情况。MAE通过在像素层次上计算归一化显著性图S和真值图G之间的绝对误差均值来解决该问题。MAE的计算公式如式(8)所示:
(8)
其中,W和H表示图像的宽和高,(i,j)表示图像中的像素点坐标。
各个方法的MAE评价结果如表2所示。MAE值越低说明方法的性能越好,表中加粗的数值对应的方法即为各个数据集上排名前3的方法。通过对比表2中的数据可以发现,在4个数据集上,本文方法的MAE值均低于其它11种方法的,说明本文方法的检测结果更接近真值,错检情况更少;对比结果表明,本文方法性能要优于其它11种方法的,本文的网络获得的多尺度局部增强特征和全局上下文特征十分有利于显著性检测。
(4)S-measure。
Precision、Recall、F-measure和MAE都是逐像素计算误差,而S-measure是从人类视觉系统对场景结构非常敏感的角度出发,使用结构性度量评估检测结果,使得评估结果和人的主观评价具有高度一致性。S-measure同时考虑了对象角度So和区域角度Sr的结构相似性,计算方法如式(9)所示:
S-measure=α×So+(1-α)×Sr
(9)
其中,α∈[0,1],本文中α设置为0.5。各方法的S-measure评价结果如表3所示。
同F-measure指标一样,S-measure的值越大就说明方法的性能越好,对比表3中的数据可以发现,在4个不同的数据集上,本文方法均得到了最高的S-measure值(以DUT-OMRON数据集上的结果为例,本文的S-measure值为0.798,比排名第2的DCL方法高了3.5%),说明本文方法检测结果的准确性更高,和人类视觉观察的结果更吻合。

Table 2 MAE of different methods

Table 3 S-measure of different methods
4.3 模块有效性验证
为了对局部特征增强和全局上下文建模模块的有效性进行验证,本文设计了4组实验,包括:(1)不使用局部特征增强模块,也不使用全局上下文建模模块;(2)使用局部特征增强模块,但不使用全局上下文建模模块;(3)使用全局上下文建模模块,不使用局部特征增强模块;(4)同时使用局部特征增强模块和全局上下文建模模块。
基于DUT-OMRON数据集图像数量大、背景结构复杂、图像中包含多个物体,更接近真实世界的情况,本文选择在DUT-OMRON数据集上进行有效性验证,4组实验得到的PR曲线如图7所示。图7的图例部分中,LFE表示局部特征增强模块;GCM表示全局上下文建模模块;“-”表示未使用此模块;“+”表示使用此模块。
将图7中4组实验的PR曲线进行对比可以得出以下结论:基于局部特征增强模块和全局上下文建模模块的模型是4种组合中性能最好的,因此基于局部特征增强模块和全局上下文建模模块的有效性得到了验证;其次,这2个模块都能有效地改进显著性检测的结果,但相比于全局上下文建模模块,局部特征增强模块能更明显地提升网络的性能。
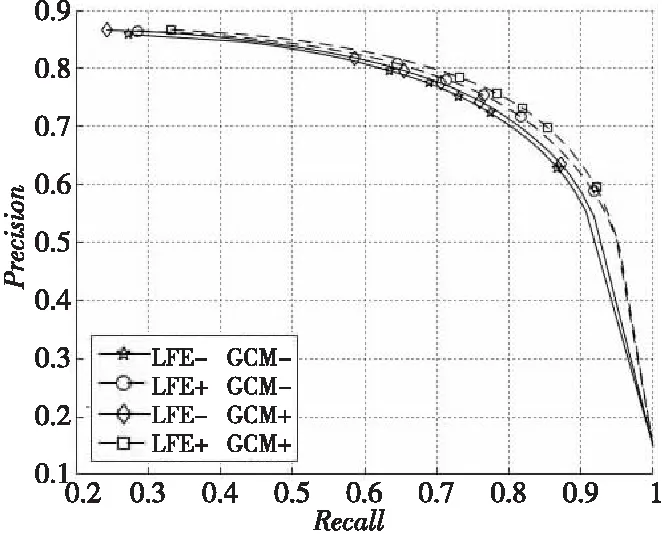
Figure 7 Validation results of two modules图7 模块有效性验证结果
5 结束语
本文提出了一种新的基于多特征融合卷积神经网络的显著性检测方法,该方法能够在不同尺度下学习局部特征和全局特征,在此基础上,通过局部特征增强模块和全局上下文模块对深度显著性检测网络性能进一步优化。本文通过对比实验,对2个模块的有效性进行了验证,结果表明2个模块均有效地改进了深度显著性网络的性能,能够使本文的深度显著性检测方法取得更好的结果。此外,本文使用了多项指标在4个公开数据集上对本文的网络性能进行了全面的评价,并和其它11种流行的显著性检测方法进行对比,视觉对比结果表明,本文方法不仅能够准确检测出显著性目标的主体,同时还能够保留比较完整的轮廓,在图像背景结构相对复杂或目标和背景对比度较低的情况下,本文方法依然能够较完整而准确地将显著性目标从背景中分隔开;在其它几项评价指标中,本文方法同样取得了更好的结果。
