融合文本分布式表示的重复缺陷报告检测*
2021-05-11贲可荣徐永士
曾 杰,贲可荣,张 献,徐永士
(海军工程大学电子工程学院,湖北 武汉 430033)
1 引言
大部分软件使用缺陷管理系统(如Bugzilla)来追踪和记录发生的缺陷。对于同一缺陷,使用软件的不同用户或者软件维护人员可能在不同时间提交多份缺陷报告,这样会增加修复成本。所以,对于每一份新提交的缺陷报告,先判断其是否是历史缺陷报告的重复,然后再行处理。在历史缺陷报告数庞大的情况下,人工查找是不现实的。而据有关统计[1]显示收集的关于Mozilla项目的768 335个缺陷报告中,重复报告的占比高达23%。由此可见,重复缺陷报告检测对于降低缺陷追踪管理系统的人力成本具有重要意义。
现有研究主要针对缺陷报告的非结构化属性和结构化属性2部分内容分别抽取特征,再利用机器学习算法构建分类模型。结构化属性只能从指定选项中选取,非结构化属性则由缺陷报告的提交者依据个人表述习惯利用自然语言进行描述,主要包括缺陷摘要和缺陷描述。部分缺陷报告在缺陷描述中会附上程序执行步骤和屏幕截图等其它信息。Lazar等人[2]提出的D_TS(Detection using Text Similarity)方法,抽取了25种特征,采用支持向量机SVM(Support Vector Machine)和随机森林等机器学习算法训练分类器,在重复缺陷报告检测方面取得了良好效果。为了进一步提升检测的准确性,在该方法的基础上,本文提出一种融合文本分布式表示的检测方法,利用大规模数据集挖掘缺陷报告在摘要和描述上的深层次语义信息,抽取缺陷报告的分布式表示,将该特征与其它特征进行融合后共同用于任务检测。文本分布式表示利用文档嵌入模型Doc2Vec[3]进行训练和抽取。在公开的大规模重复缺陷报告数据集[1]上进行评测,并将本文所提方法与D_TS[2]进行比较,证实了本文方法的有效性。为了保证实验可再现,全部代码和数据已开源(https://github.com/zyj183247166/BugReportDeduplicate)。
2 相关工作
重复缺陷报告检测的核心过程是比较2份缺陷报告不同字段内容的相似性,主要方法分为4种:
(1)信息检索方法。
早期的工作主要利用信息检索方法中的词袋模型进行分析。词袋模型首先计算单词权重,再将缺陷报告表示为这些权重的向量,最后通过比较向量距离来判定文本相似性。比如,DupFinder[4]使用词频计算单词权重;Hiew[5]则结合词频和逆向文档频率TF-IDF(Term Frequency-Inverse Document Frequency)计算单词权重。李宁等人[6]基于n-gram方法构建检测模型,将n元词组看作一个新的单词,再应用词袋模型。但是,语义相近的单词,如“StringIndexOutOfBoundsException”与“StringIndexOutOfBounds”,在字面上并不相同。这2个单词描述的均是数组越界错误,而词袋模型无法将它们有效关联。为此,Sureka等人[7]在字符粒度上利用n-gram方法构建信息检索模型。尽管如此,对于不具有共同前(后)缀的不同字面单词,如“error”和“bug”,词袋模型仍无法建立联系。
(2)机器学习与主题模型。
为了提高检测的准确性,Sun等人[8]利用SVM训练出一个判别式二分类器,但其抽取的特征仅仅来源于缺陷摘要和描述,过于局限。因此,Sun等人[9]后续又基于包括优先级、产品版本等多个域在内的信息利用改进的BM25F(Best Match 25 models with Fields)算法[10]来判别缺陷报告的相似性。改进的BM25F算法中,其参数并非先验设定,而是在训练数据上进行学习和优化得到。Lazar等人[2]则从包括缺陷编号和缺陷类型在内的9个信息域中提取出共计25种特征来训练机器学习分类模型。
单纯分析不同缺陷报告在字面上的相似性,不够充分。Nguyen等人[11]采取潜在狄利克雷分布LDA(Latent Dirichlet Allocation)模型对缺陷报告进行主题建模,比较不同缺陷报告的主题分布之间的相似性。Alipour等人[12]则构建多个主题词表。比如,将与可维护性主题有关的单词组合在一起形成列表。接着,基于BM25F算法判定缺陷报告与多个主题词表之间的相似程度,形成一个向量。对2份缺陷报告的这类向量计算余弦距离形成新的特征,称之为语境特征(Contextual Features),将其作为一种新的特征构建分类模型。Klein等人[13]则将不同缺陷报告的主题分布之间的海林格距离作为新的特征构建分类模型。范道远等人[14]融合缺陷报告中非结构化属性的文本信息与结构化属性的分类信息构建检测模型,在处理文本信息时使用了主题模型中的潜在语义索引LSI(Latent Semantic Indexing)算法。LSI算法利用奇异值分解SVD(Singular Value Decomposition)方法将高维矩阵映射到低维空间并抽取出主题信息,相较于LDA模型而言,其计算简单快速,但无法应用于词和文本非常多的大规模数据库。董美含[15]则提出一种基于动宾短语和主题模型的相似缺陷报告识别方法,通过抽取动宾短语过滤掉相对不重要的文本信息,同时使用LDA模型构建描述主题分布的特征向量。蒋欣志[16]则对比了向量空间模型与LDA主题模型,证实了主题模型应用于重复缺陷报告检测具有更高的准确率。
(3)利用附加信息辅助分析。
上述方法或者关注于缺陷报告自身,或者抽象出缺陷报告的主题,但是信息根源仍是缺陷报告各个域内的字面信息。Wang等人[17]则进一步关注于缺陷发生时所记录的程序执行信息,通过抽取程序执行过程所调用的方法名称,将程序执行信息具体化为方法名称的序列并转化为文本表示。然后,程序执行信息之间的相似性就可以利用文本相似性分析方法判定。由于部分程序执行过程调用的方法过多,会导致相似性分析过程的时间开销较大,Sabor等人[18]先将执行序列变为n-gram词组的列表,再转化为固定长度的稀疏特征向量,最后通过向量比较完成程序执行信息的相似性分析。 除了程序执行信息以外,提交缺陷报告时附加的屏幕截图等信息也被用于识别重复缺陷报告[19]。陈俊洁等人[20]则结合程序特征和文本特征查找编译器测试过程出现的重复缺陷报告,程序特征来源于测试程序,即能够导致编译器无法正常运行的被编译程序。总的来说,这些方法的应用场景是受限的。对于不存在附加信息的缺陷报告,需要对每个缺陷进行一次重现,在操作上复杂性很高,很难适用于大规模缺陷库。
(4)嵌入表示和深度学习模型。
前述方法常用的BM25F算法的前提假设是文档中出现的单词之间没有任何关联。显然,这种假设与事实不符。为了分析单词的上下文信息,Yang等人[21]将由词嵌入模型word2vec[22]学习到的词嵌入表示(Word Embedding)融入到信息检索模型中,用于识别重复缺陷报告。樊田田等人[23]先分别用word2vec模型和TF-IDF模型将缺陷报告表征为稠密向量,再进一步计算查询缺陷报告与历史缺陷报告的相似程度。Budhiraja等人[24]则详细对比了词嵌入模型、LDA模型和BM25F算法,再次证实了词嵌入模型用于识别相似缺陷报告的优越性。与word2vec不同,文献[25,26]基于文档嵌入模型Doc2Vec[3]识别相似缺陷报告,相较于word2vec模型取得了准确率的提升。本文方法同样使用文档嵌入模型Doc2Vec,但与文献[25,26]的方法不同。本文方法将2份缺陷报告的分布式表示之间的相似度作为一个新的特征,再将其与重复缺陷报告检测过程常用的传统特征进行融合,共同构建基于机器学习算法的二元分类模型。
后续研究中,Budhiraja等人[27,28]又针对基于词嵌入模型的检测方法提出2种优化方案。第1种是将单词的词嵌入表示结合单词的序列共同输入到全连接深度神经网络中,通过自动化学习缺陷报告的深度特征,训练出一个能够识别缺陷报告相似性的二分类器[27]。第2种则是先利用LDA模型进行初步筛选,缩小候选相似报告的范围,再由词嵌入模型分析候选相似报告的相似性[28]。喻维[29]则提出一种基于卷积神经网络的检测方法,先使用词嵌入来表示每个单词,再将向量拼接送入卷积神经网络进行训练。Deshmukh等人[30]针对缺陷报告的元属性、缺陷摘要和详细描述等3方面信息分别使用单层全连接、双向长短时记忆和卷积神经网络等3种网络结构进行建模和特征提取,并将3个特征向量拼接起来得到缺陷报告的最终向量表示。进一步,基于学习到的向量表示分别建立检索模型和分类模型:检索模型基于余弦距离度量2个报告的相似性,而分类模型则搭建Softmax层完成最终的二分类任务。
3 融合分布式表示的检测方法
本文研究Bugzilla缺陷报告库,包括Eclipse、Open Office和NetBeans等开源项目的缺陷报告。针对存在的重复缺陷报告问题,本文提出一种融合文本分布式表示的检测方法。整体流程包括4个步骤:数据预处理、文本分布式表示抽取、特征抽取和二元分类模型训练与使用。在抽取特征以后,为了避免单一机器学习算法对本文方法的结果造成偏差,并充分验证新特征用于重复缺陷报告检测过程的有效性,本文使用多种机器学习算法[31]构建二元分类模型,包括线性支持向量机(Linear SVM)、核函数支持向量机RBF SVM(Radial Basis Function SVM)、K近邻、决策树、随机森林和朴素贝叶斯。下面将详细介绍另外3个步骤。
3.1 数据预处理
该阶段主要针对缺陷报告的摘要和描述这2部分非结构化文本,采用常用的自然语言处理方法进行数据预处理,包括3步:
(1)分词:英文语句使用空格将单词进行分隔,据此将长文本拆分成单词和标点符号的列表,并且去除空格和换行等字符。
(2)去除标点符号和停止词:英文中有许多停止词和标点符号,诸如“to”“the”“.”和“!”等,它们包含很少的信息,而且频繁出现。为了避免这些无关信息对重复缺陷报告检测造成影响,本文利用正则表达式匹配方法去除 “?”和“!”等英文标点符号,并根据英文常用停止词表去除停止词。
(3)词干提取:词干是没有任何后缀的词,比如“commander”的词干是“command”,“raining”的词干是“rain”。有相同词干,但是不同表示的词,在语义上是相近的。本文利用Porter方法(https://tartarus.org/martin/PorterStemmer/)进行词干提取并将各个词进行简化。
经过数据预处理以后,下一步将从处理后的数据中抽取文本的分布式表示。
3.2 文本分布式表示抽取
基于词袋模型的重复缺陷报告检测方法将缺陷报告建模为稀疏离散向量,丢失了文本语序信息。为此,本文基于文档嵌入模型Doc2Vec[3]挖掘文本序列中蕴含的深层次语义信息,抽取缺陷报告的分布式表示。如图1所示,对于数据预处理后的缺陷报告库,将每份缺陷报告的摘要和描述拼接成一段文本,形成文本的集合并利用该集合训练Doc2Vec模型,最终将每份缺陷报告建模为稠密连续向量,而向量之间的相似度就可以用来表示缺陷报告在文本语义上的相似性。
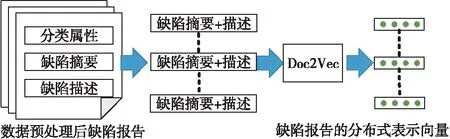
Figure 1 Extracting distributed representations of bug reports using the Doc2Vec model图1 Doc2Vec模型抽取缺陷报告的分布式表示
Doc2Vec基于word2vec[22]扩展而来。word2vec是一个浅层神经网络,包括输入层、隐藏层和输出层共3层结构,具体包括2种训练模型:连续词袋CBOW(Continuous Bag Of Words)模型和Skip-gram模型。前者基于上下文单词预测中心词,后者则基于中心词预测上下文单词。word2vec基于给定的输入单词,利用初始化参数的神经网络预测输出单词的概率,并与语料库中输入单词附近真实出现的单词进行比较,计算损失值。以降低损失值为目标优化神经网络参数,最终学习到的词嵌入表示能够反映训练语料库中单词出现的统计规律,而不同字面单词的语义相似性便可以用词嵌入表示之间的向量距离进行度量。
为了抽取段落或文档等长文本的分布式表示,Doc2Vec在word2vec的基础上,增加了一个与词嵌入向量长度相等的段落嵌入向量,即结合段落向量和词向量共同预测目标词的概率分布。Doc2Vec基于Skip-gram模型扩展得到分布式词袋DBOW(Distributed Bag Of Words)模型,基于CBOW模型扩展得到分布式记忆DM(Distributed Memory)模型。DM模型较DBOW模型而言,计算更快速并且更适合于大规模缺陷报告库,所以本文采用此模型。设定缺陷报告文本集合的词典为V,规模为n,滑动窗口为5,某个中心词w的上下文单词集合为C={c1,c2,c3,c4},则CBOW模型与DM模型的结构如图2所示。

Figure 2 Diagram of the CBOW and DM models图2 CBOW模型与DM模型示意图
DM模型初始化词嵌入矩阵W和段落嵌入矩阵D,然后根据上下文单词集合C中的单词编号从W中索引出对应的词嵌入向量,同时根据段落编号从D中索引出段落嵌入向量。将这些向量求和平均后,再与参数矩阵U进行计算,得到n个输出值构成的一维向量y。最后经过Softmax层计算,可以得出当前单词为w的概率:
(1)
其中,yw表示向量y中单词w对应位置的输出值。
对于大规模缺陷报告库,词典V的规模n会很大,会导致求和平均后向量与矩阵U之间无法进行矩阵乘法运算。为此,本文使用负例采样方法[32],按照高频率词汇有高概率被抽中的原则,从V中抽取部分词汇并且计算它们在y中对应位置的输出值,然后将输出值求和后作为式(1)的分母。这样做的好处是,向量与U的矩阵乘法运算,简化为了向量与U中部分列向量进行点乘运算。最后,设缺陷报告库形成的文本语料为T,在T上用滑动窗口不断取出新的w和C,则DM模型的优化目标就是最小化损失值:
loss=∑(w,C)∈T-lnp(w|C)
(2)
DM模型在训练过程中要学习到的参数为矩阵W、D和U。训练结束后,依据段落编号即可从D中抽取出该段落的分布式表示。这里的每个段落对应每一份缺陷报告经过数据预处理后的文本内容。
3.3 特征抽取
Lazer等人[2]将Sun等人[9]提出的缺陷报告分类属性比对特征和aric等人[33]提出的文本比对特征进行融合,再构建重复缺陷报告检测模型。本文则在Lazer等人工作的基础上,将2份缺陷报告分布式表示的相似度作为一个新的特征,同已有特征进行再一次融合。给定2份缺陷报告br1和br2,本文用于判定两者是否重复所使用的全部特征如表1所示。Lazer等人[2]使用了特征1~特征25,本文融合的新特征编号为26。

Table 1 Features used for duplicate bug report detection
表1中,WordNet[34]是一个大规模的英语词汇语义网,该网络将不同单词基于各种关系连接起来;词形还原是指把一个任何形式的单词还原为一般形式,同时保留完整语义,比如将“is”还原为“be”;abs是计算绝对值的数学函数;版本号version为“x.y.z”形式时,取数值x.y作为版本号的具体值;优先级为“PxNormal”形式时,取数值x作为优先级的具体值。由于不同特征的值不处于同一量纲,会影响分类模型的准确性,本文对抽取后的特征数据进行归一化,将所有特征值的范围缩小到[0,1]。
4 实验数据集与实验过程
本节介绍实验的数据集与实验过程。
4.1 评测数据集和指标
本文方法在大规模真实缺陷报告数据集[1]上进行评测。该数据集来源于Bugzilla缺陷库,包括Eclipse、Open Office、NetBeans和Mozilla共4个项目的缺陷报告。学者依据缺陷报告的重复(duplicates)属性中所记录的ID号来识别与其存在重复关系的其它缺陷报告,构建了重复缺陷报告数据集(http://alazar.people.ysu.edu/msr14data/)。但是,它只针对前3个项目构建了重复缺陷报告数据集,对Mozilla项目则只提供了原始缺陷报告。重复缺陷报告数据集是三元组的集合,每个三元组记录一对缺陷报告的ID号和它们之间的重复关系(重复或者不重复)。
经过实验发现,该数据集中存在一定程度的数据噪声。比如,Open Office项目中ID分别为13060和39496的2份重复缺陷报告所形成的三元组(13060,39496,1),在数据集中共计出现了6次。除此之外,还有许多三元组在交换2个ID的顺序之后所形成的新元组也在数据集中重复出现。显然,这些噪声势必影响最后的准确性评测过程。本文对这些噪声进行去除,最终用于评测的重复缺陷报告数据集概要见表2。

Table 2 Summary of duplicate bug report datasets for evaluation
在评测指标方面,本文用4个指标评价方法的效果:准确率(Accuracy)、召回率(Recall)、查准率(Precision)和调和平均数F1。调和平均数能够对召回率和查准率更接近的模型给予更高的分数,而两者相差很大的模型,往往在实际应用中没有足够的价值。在Recall、Precision和F1的计算上,本文更关注分类模型对重复类别的预测能力。4种指标的计算公式分别如式(3)~式(6)所示:
(3)
(4)
(5)
(6)
其中,TP表示重复缺陷报告对被检测为重复关系的个数,FP表示非重复缺陷报告对被错判为重复关系的个数,TN表示非重复缺陷报告对被检测为非重复关系的个数,FN表示重复缺陷报告对被错判为非重复关系的个数。
4.2 实验设置
实验的对照方法是2014年MSR(Mining Software Repositories)会议上由Lazer等人[2]提出的方法,该方法在规模为10 000左右的小型数据集上达到了99%的准确率。在实验数据集划分方面,本文采用的方法与Lazer等人[2]的方法保持一致,即针对Eclipse等3个项目随机抽取5 000个缺陷报告对作为训练集(重复与非重复标签数据的比例为1∶4),将其余数据作为测试集,并且面向3个项目分别进行模型的训练和测试。为了保证性能评测的稳定性,本文采取10次随机实验取平均值的方式,计算各项评测指标。在模型参数的设置方面,也同Lazer等人的方法保持一致:即利用网格搜索方法确定线性支持向量机与核函数支持向量机RBF SVM在训练集上的最佳参数;至于随机森林等其它机器学习模型,则直接使用scikit-learn工具箱的默认配置参数。这样做主要是为了避免主观因素对重复缺陷报告检测方法的评测过程带来偏差。
10次随机实验的某一次实验中,网格搜索方法确定的支持向量机模型在训练集上的最佳参数如表3所示。表3中,P是惩罚系数,即对误差的宽容度。P越大,表示越不能容忍误差,模型容易过拟合;P越小,表示越容易欠拟合。Gamma是核函数支持向量机的一个参数,决定了数据映射到新的特征空间分布后支持向量的个数。Gamma越大,支持向量越少;反之,支持向量越多。支持向量的个数影响模型的训练速度和准确率。网格搜索过程首先为P和Gamma设定范围和变化步长,再沿着步长不断变化参数值并在训练集上训练(采取五折交叉验证方式),最后会根据五折交叉验证平均准确率的高低来确定最优参数的取值。

Table 3 Best parameters for SVM models determined by the grid search
4.3 实验步骤
本文基于Python语言进行编程和实验,主要步骤包括:
(1)数据预处理。
利用NLTK(Natural Language ToolKit)(http://www.nltk.org)完成分词、去除标点符号和停止词,以及词干抽取等步骤。NLTK是Python解释器环境下专门用于自然语言处理的工具包。
(2)文本分布式表示抽取。
数据预处理后,将缺陷报告的文本和摘要拼接成段落,并在缺陷报告库的基础上形成段落的集合,再利用gensim(https://radimrehurek.com/gensim/)实现Doc2Vec模型,并抽取每份缺陷报告的分布式表示。
(3)特征抽取。
表1的特征中,特征1~19由工具包TakeLab(http://takelab.fer.hr/)的simple版本生成。TakeLab会自动生成共计21种特征。本文人工去除其中的2种特征,因为经过数据归一化后,所有数据的这2种特征的值均相同,即它们对重复缺陷报告检测无任何意义。这2种特征基于文本中的块索引符号(Stock Index Symbol)进行抽取。块索引符号是指在全部字母大写的单词前有一个英文点号“.”的特殊符号,如“.AAA”。
(4)二元分类模型的训练与使用。
通过libsvm工具包(https://www.csie.ntu.edu.tw/~cjlin/libsvm/)实现支持向量机模型,包括网格搜索方法确定最佳参数等。利用scikit-learn工具箱实现K近邻、决策树、随机森林和朴素贝叶斯等其它算法,模型参数为工具箱的默认设置。
5 实验结果分析
本节主要分析方法的检测性能,对不同特征用于重复缺陷报告分类的判别力进行评价,并分析一个对照方法无法检测而本文方法能够检测的重复缺陷报告实例。
5.1 检测性能分析
本文方法与对照方法在3个项目重复缺陷报告数据集上的实验结果如表4~表6所示,括号内的数字是本文方法结果。从表4~表6中可以看出,相较于对照方法,本文方法在Eclipse、Open Office和NetBeans项目上的F1值分别平均增长1.38%,2.61%和2.03%(对表中所有机器学习模型的F1值进行求和平均),即在全部数据集上平均增长约2%。在Accuracy等指标上,本文方法也均优于对照方法。以核函数SVM模型为例,相较于对照方法,本文方法在Eclipse、Open Office和NetBeans项目上的Accuracy值分别增长1.2%,2.59%和2.5%,即正确分类的测试样本个数分别增长2 907,2 436和4 514个(3个项目的测试集规模分别为242 302, 94 086和180 581)。这些结果充分表明了本文方法优于对照方法。

Table 4 Evaluation results on the Eclipse project (numbers in parentheses are the results of our method)

Table 5 Evaluation results on the Open Office project (numbers in parentheses are the results of our method)

Table 6 Evaluation results on the NetBeans project (numbers in parentheses are the results of our method)
5.2 特征的判别力分析
为了进一步评价本文融入的新特征应用于重复缺陷报告检测中的有效性,本节对不同的特征进行判别力分析,即判别力越高的特征具有越强的分类能力。本文选择3种常见的判别力分析指标,即斯皮尔曼(Spearman)相关性、费舍尔(Fisher)得分和信息增益。Spearman相关系数用来反映2个变量之间的相似度,即判断特征和类别是正相关、负相关还是没有相关程度。Fisher准则的主要思想是判别力较强的特征表现为类内方差尽可能小而类间方差尽可能大。某个特征的Fisher得分即为该特征在样本集上的类间方差和类内方差的比值。信息增益用于测度某个特征为分类模型贡献的信息量,信息增益越大说明该特征越重要。所有指标均为3个项目数据集上分别计算以后,再进行求和平均,不同特征的判别力如表7所示。从表7中可以看出,除了在Fisher得分上新特征仅次于特征20,本文融入的新特征在判别力上排名最优。特征20的计算结果见表7,即如果2份缺陷报告描述同一个产品,则特征值为1,否则为0。此外,从Spearman相关性中可以看到,基于版本与ID分别抽取的特征24和25,与分类属性呈现负相关,从统计意义上表明,2份缺陷报告的版本号相差越大,或者ID相差越多,重复的可能性越小。

Table 7 Features’ discriminative performance
5.3 重复缺陷报告实例分析
本文方法融入文本分布式表示来分析段落之间的语义相似性,这一点对于检测字面相似度较低的重复缺陷报告尤为重要。表8是Lazer等人方法无法检测而本文方法能够检测到的一个重复缺陷报告示例。从表8中可以看出,2份缺陷报告描述的是同一缺陷,即NetBeans 6.X版本的Local Variables窗口和Watches窗口无法显示。2份缺陷报告由不同人提交,在大部分属性上相同,而在产品和组件属性上均不相同,在摘要和描述上也存在较大的字面差异,尤其在使用换行符、标点符号和语言风格等方面相差较大。比如,2份缺陷报告分别用Netbeans和NB描述NetBeans。该实例表明文本分布式表示能够较好地适应这种字面变化,再一次说明了本文方法的有效性。

Table 8 An example of duplicate bug report detected表8 检测到的重复缺陷报告示例
6 结束语
本文提出了一种融合文本分布式表示的重复缺陷报告检测方法,通过抽取缺陷报告的分布式表示,将2份缺陷报告分布式表示的相似性作为一种新特征同传统特征进行融合之后再训练机器学习分类模型,能够更好地适应重复缺陷报告在摘要和描述等非结构化属性上的复杂字面变化。相较于未使用分布式表示的检测方法,具有一定程度的优势。本文方法在真实项目的大规模重复缺陷报告数据集上进行了评测,并与代表性方法D_TS进行了比较,评测结果显示了本文方法的有效性。
