Python多进程编程技术在第三次全国国土调查县级数据库质检中的应用
2021-05-10黄彦锋陈秀萍
黄彦锋,陈秀萍
(云南省测绘产品检测站,云南 昆明 650034)
0 引 言
第三次全国国土调查(以下简称“三调”)是为了全面查清当前全国土地利用状况,掌握真实准确的土地基础数据,健全土地调查、监测和统计制度,强化土地资源信息社会化服务,满足经济社会发展和国土资源管理工作需要。“三调”县级调查作业单位需要在短时间内完成外业调查、内业数据建库、文档编制等工作,成果需要经过县级、州市级、省级、国务院三调办等各级检查,其中县级调查数据库质量检查是一项十分重要的工作。“三调”数据库是“三调”成果的核心载体与展示平台,数据库质量检查合格是确保“三调”数据库建设顺利完成、数据准确汇总的前提,是保证“三调”数据库质量合格的重要措施。
由于“三调”县级调查工作量大,作业时间非常有限,留给各级检查的时间更少,这就需要各级检查能快速准确地将成果中存在的问题检查出来。县级数据库质检必然离不开质检软件,如果质检软件仅仅按照技术标准对县级数据库进行全面检查,不充分考虑运算速度的话,将会严重影响县级“三调”工作推进。由于“三调”在县级数据库检查方面设置的检查环节较多,快速对数据库进行质检就显得十分重要。
承担“三调”工作的各单位使用的计算机几乎都是多核CPU,更有甚者投入的图形工作站是多CPU架构。如何充分利用计算机CPU多核的优势,发挥单台计算机的计算潜能,是设计数据库质检软件必须考虑的问题。本文以“属性完全相同的图斑空间位置不能相邻”这一质检规则的Python多线程检查工具的实现为例,阐述并行处理在“三调”县级数据库质检中的重要意义。
1 Python多进程数据处理
“三调”工作使用的主流县级调查原始数据库格式为ArcGIS GDB格式(File GDB 和Personal GDB),可使用C#、Java、C++、Python等编程语言进行ArcGIS二次开发。之所以采用Python,原因如下:
1)ArcGIS的安装包中就已经集成了Python和Python的NumPy、SciPy计算库,安装ArcGIS时将自动安装Python,开发者无需进行复杂的安装和配置,可快速将精力放在业务问题的解决上,而不用在编程语言自身特性上花费较多时间。
2)ArcGIS提供Python编程接口非常方便用户使用,可大幅缩短开发周期。
3)Python语言数据处理的学习曲线相对其他语言较为平缓,开发者比较容易进入状态。
为什么不选择多线程,而选择多进程这种较为耗费计算机资源的方式进行数据处理呢?原因如下:
1)ArcGIS支持的Python 语言是CPython实现,对Python 虚拟机的访问由GIL(Global Interpreter Lock,即全局解释器锁)来控制,保证在任意时刻,只有一个线程在解释器中运行。
2)多线程Python处理ArcGIS数据时,在子线程读取Polygon对象时,不能正常完成Polygon对象的初始化,进而导致数据处理异常。说明ArcGIS对Python多线程处理支持不是太好。
3)Python的标准库multiprocessing提供的多进程并行数据处理方案能很好应用于ArcGIS数据处理,且技术复杂度不高。理论上,一台计算机的所有CPU共有多少内核,计算时就可以开多少个进程,可充分利用CPU的多核计算优势。
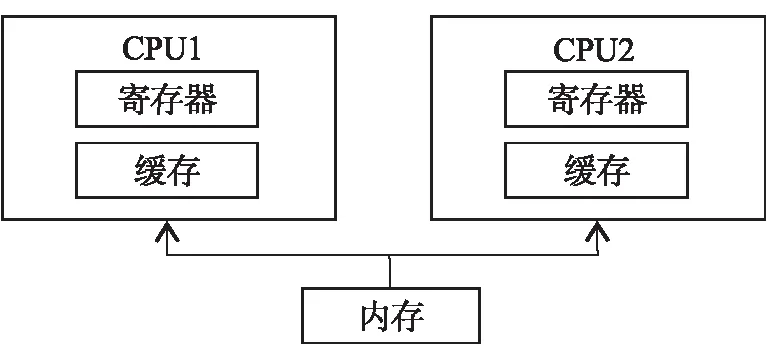
图1 多处理器系统Fig.1 Multiprocessor system
2 多进程并行处理
2.1 多处理器系统
在“三调”工作中使用的图形工作站一般包含2个相同的CPU,CPU之间可以相互交换数据,共享内存,I/O设备、控制器及外部设备等所有硬件系统由操作系统控制管理,在CPU和软件之间实现作业、任务、进程等的全面并行。多处理器系统见图1。
2.2 多进程处理流程
在进行数据库质量检查时,既要充分利用CPU资源,也要考虑计算机用户是否还需要利用本机同时进行其他业务工作。在执行进程检查软件前,用户可以根据计算机全部CPU内核数量、CPU主频和检查工作的计算量、等待质检结果的时间等情况进行综合考虑,指定质检软件在运行时使用的进程数。数据库质检并行数据处理流程如图2所示。
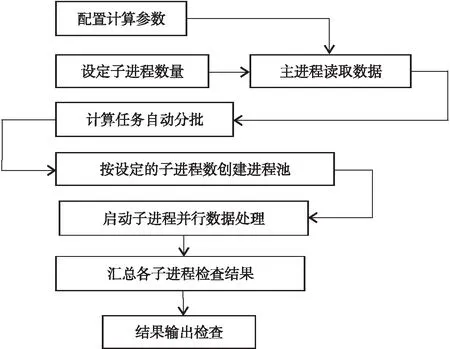
图2 数据处理流程Fig.2 Data processing flow
3 多进程示例代码
本文以地类图斑层的检查项“除面积字段、标识码、图斑编号外其它属性完全相同的图斑(道路、河流、沟渠除外)空间位置不能相邻”为例,阐述使用Python多进程编程技术进行自动检查的应用。
3.1 主程序文件头
若程序代码文件名为dltbpropertysame.py,则其主程序文件头Python代码如下:
主程序文件头Python代码
dltbpropertysame.py的文件头
#-*- coding: UTF-8-*-
import os, sys, re, sqlite3
from time import time, sleep
import xlrd, xlsxwriter
from multiprocessing import Pool, Manager
from threading import Thread
from Queue import Queue
from arcpy import env
from arcpyimport MakeFeatureLayer_management as makeFLayer
from arcpy import PolygonNeighbors_analysis as polyNeighbors
from arcpy import GetCount_management as getCount
from arcpy import Delete_management as deleteLayer
from arcpy.da import SearchCursor as searchCursor
from arcpy import CreateFileGDB_management as createFileGDB
from arcpy import AddFieldDelimiters as addFieldDelimiters
3.2 主程序的主方法
为便于读者理解数据处理流程,本文先对主方法进行讲解。限于篇幅,本文略去详细的实现代码,仅对方法参数和功能进行描述。
程序主方法Python代码
dltbpropertysame.py中的通用方法
def main(prjdir, dltb,cnum):
#主方法。检查地类图斑层属性相同的多个图斑空间不能相邻
# (除BSM、TBBH、面积类等字段外,其余所有字段)
#prjdir质检项目的目录。绝对路径
#dltb待检测的地类图斑数据层绝对路径
#cnum数据处理的子进程数。即,需要使用几个进程进行数据处理
#无返回值
tasks = createTask(dltb, prjdir) #创建任务列表
pool = Pool(processes=cnum)
mg = Manager()
oids = mg.list()#记录相邻图斑属性相同的记录
msgs = mg.Queue()#记录输出消息
pover = mg.Value(‘H’, 0) #数据处理进程是否全部结束
for cs in tasks: #启动所有子进程
cs.extend([oids, msgs])
pool.apply_async(chkDLTBlxx, args=cs)
print‘All tasks started.’
pool.close()
msgout = Thread(target=outMessage, args=(msgs, pover)) #创建消息输出子进程
msgout.start() #消息输出子进程负责统一输出所有子进程的信息,避免消息显示混乱。
pool.join()
pover.value = 1 #等于1表示所有数据处理子进程处理完毕。
msgout.join() #所有数据处理子进程处理完毕后,通知消息输出子进程结束输出。
outResult(dltb, outdir, oids) #汇总输出各自进程的检查结果
3.3 主程序核心方法
限于篇幅,本文仅对关键方法的输入参数和功能进行描述。
dltbpropertysame.py中的核心方法
def createTask(dltb, prjdir):
#根据地类图斑层不同地类和相邻图斑关键属性项创建任务列表
#dltb地类图斑数据层绝对路径
#prjdir质检项目路径
#返回任务列表
return tasks
def chkDLTBlxx(inws, infcn, prjdir, outdir,lyr, dlbm, wc, sc, oids, msgs):
#地类图斑层属性相同的多个图斑空间不能相邻
#inws地类图斑层所在的工作空间的绝对路径
#infcn地类图斑层基本名称,不含路径
#prjdir检查项目目录绝对路径
#outdir检查结果输出目录的绝对路径
#outws检查结果输出的ArcGIS工作空间
#lyr数据筛选层名称
#dlbm地类编码
#wc ArcGIS数据筛选条件,即ArcGIS数据库的SQL语句
#sc属性相同的判别条件
#oids相邻图斑属性相同的问题记录列表。用于记录问题图斑的ObjectID
#msgs统一输出消息的队列
#1.根据数据筛选条件筛选创建数据层
makeFLayer(infcn, lyr, wc)#创建数据层
flds =[oidname,′BSM′,′DLBM′,′QSXZ′,′QSDWDM′,′ZLDWDM′,
′GDLX′,′GDPDJB′,′TBXHDM′,′ZZSXDM′,′XZDWKD′]
#2.进行图斑相邻的空间分析
polyNeighbors(lyr, outtn, flds,
″NO_AREA_OVERLAP″, ″NO_BOTH_SIDES″,
″.0001 Meters″,″METERS″,″SQUARE_METERS″)‴。
#3.获取相邻图斑属性相同的图斑ObjectID
with searchCursor(outtn,′*′, sc) as cursor:
for row in cursor:
oids.append([row[1], row[2], lyr, dlbm])
ss=fmt.format(oidname, row[1],row[2])
msgs.put(ss.encode(′GBK′))
def outResult(dltb, outdir, oids):
#输出地类图斑层属性相同的多个图斑空间不能相邻的检查结果
#dltb待检测地类图斑层的绝对路径
#outdir检查结果输出目录绝对路径
#oids相邻图斑属性相同的问题记录列表
4 多进程数据处理计算效率测试
在双路CPU图形工作站上进行测试,CPU为Interl至强处理器 E5-2650 v4 @ 2.20GHz ,内存64GB,操作系统是Windows 7专业版64位。测试计算机的单CPU是12核24线程,故双CPU为24核48线程,计算主要是由CPU的内核数决定,而Python主进程和消息处理进程各需要1个CPU内核,所以为了合理测试,最大数据处理子进程数量为22。使用某县调查数据进行测试,该县总面积约 4 234 km2,地类图斑数有 166 823 个,自动检查效率见表1、图3。
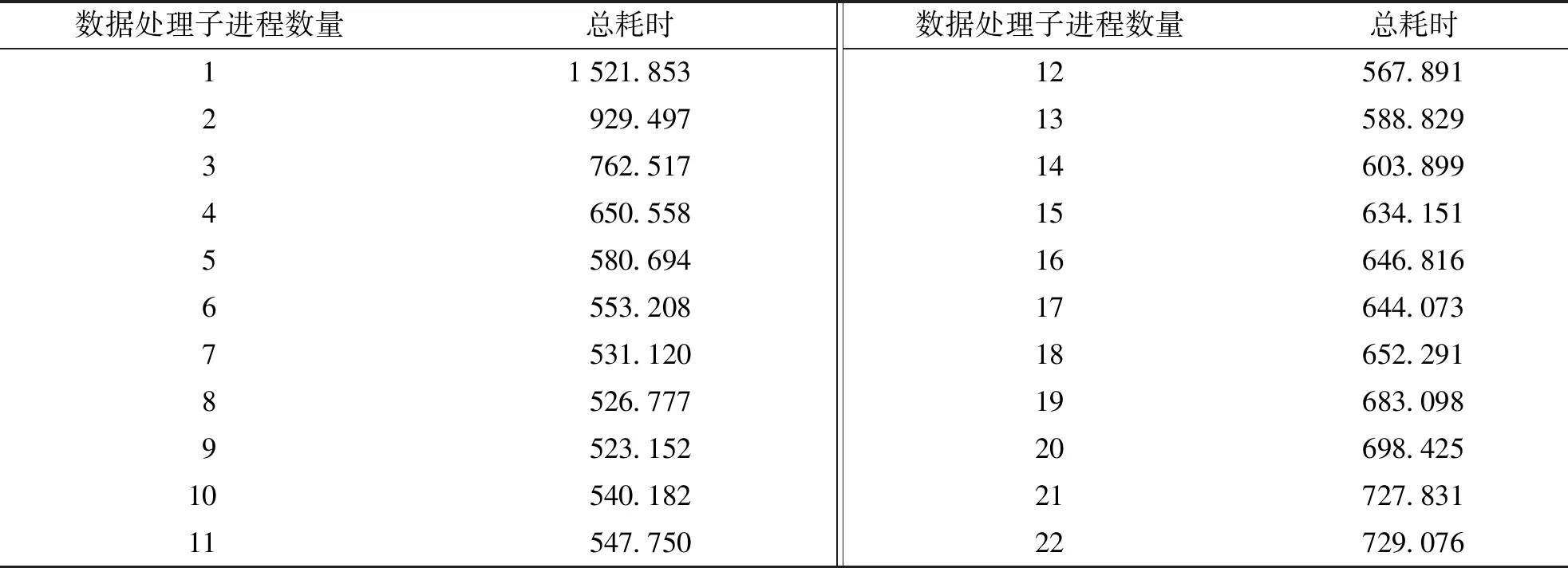
表1 多进程自动检查效率统计表
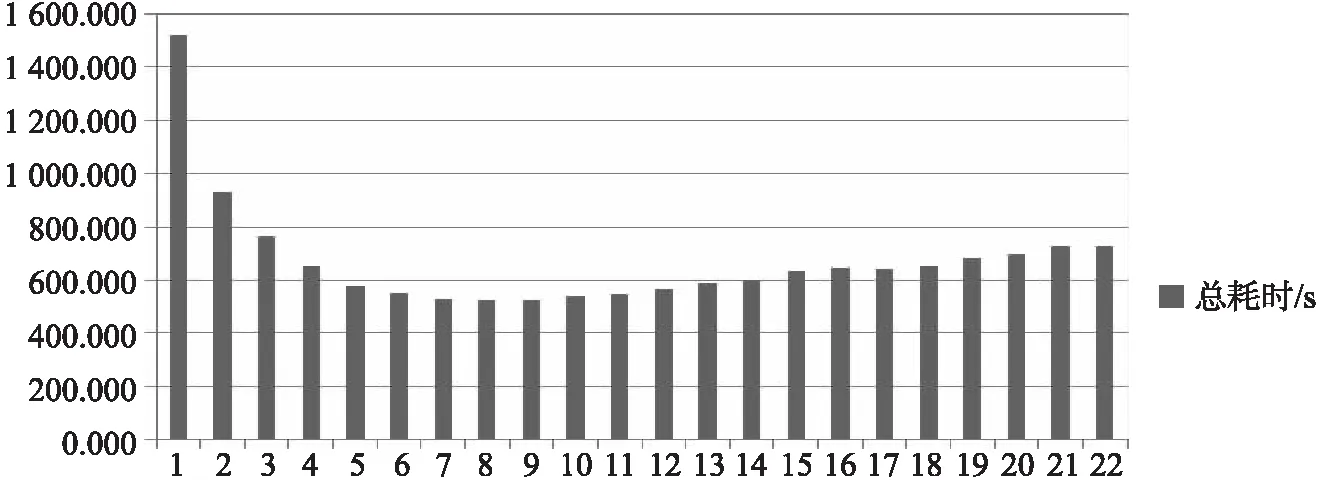
图3 多进程自动检查效率柱状图Fig.3 Multi-process automatic check efficiency bar chart
由表1、图3可知,单进程数据处理效率最低,使用9个进程进行数据处理时效率最高。那为什么使用22个进程进行数据处理时效率不是最高的呢?经初步分析,操作系统的各类服务、杀毒软件、数据库管理软件等都需要计算资源,而过多的子进程,增加了系统调度和对共同资源访问协同工作量,还增加了磁盘I/O的协同,故而数据处理子进程数量接近CPU总内核数一半时计算效率最高。
5 结 语
“三调”县级数据库质量检查属于地理信息数据库的质检,空间数据的空间分析计算密集度较高,很多时候分布式计算和服务器集群是一个较好的选择。然而实际工作中很多场合不具备分布式计算和服务器集群所需的硬件环境。设计地理信息数据库质检软件需要充分考虑和利用本机的计算能力。软件设计得合理,可发挥多核CPU并行计算的能力,相比单进程数据处理,可大幅度提高计算效率,特别是遇到类似“三调”工期要求非常高的工作,并行数据处理可节约大量时间,可将地理信息专业技术人员的精力集中在业务上,提高成果质量。
