一种基于中心和关系感知的跨域目标检测网络
2021-05-10吴泽远
吴泽远,朱 明
(中国科学技术大学 信息科学技术学院,合肥 230026)
1 引 言
目标检测是计算机视觉领域最基础的问题,对许多现实应用如自动驾驶[1],视频监控[2]十分重要,其目标是对图像中的物体进行定位并识别出类别.随着卷积神经网络的进展,基于卷积神经网络的方法[3-8]在目标检测标准数据集[9-11]上取得了明显进步.尽管效果显著,真实世界中目标检测仍然面临着数据的视角,外观,背景,光照等方面的巨大差异,即训练数据(源域)和测试数据(目标域)分布不同,导致训练好的模型泛化性较差,这一问题称为域偏移问题.为某个特定场景建立大型数据集是一个可行的办法,但是收集数据并标注是一个非常耗费人力和时间的事.
为了处理这个问题,一个具有吸引力的办法是无监督域适应[12],即将在源域上训练的模型用于目标域,却不需要对目标域进行数据标注.最近,基于对抗的域适应方法[13-21]取得了不错的结果,这一类方法基于生成对抗网[22],基本思想是训练一个判别器用来区分特征来自源域还是目标域,同时训练生成器用来欺骗判别器,使其难以区分.
然而,上述基于对抗网络的方法有几点缺陷:1)这些方法通常对数据域的整体进行对齐,而忽略了每个类的语义信息,结果导致即便整个域可以完美地对齐,来自不同域的同一类别物体在特征空间中也可能相隔很远;2)之前的检测方法通常没有考虑目标之间的关系,而上下文关系[23]对于目标的检测具有重要帮助.
为了处理上述问题,本文设计了基于类别中心和关系感知的跨域检测网络.在该网络中我们设计了3个机制,包括域级别对齐,关系感知和类别中心对齐.其中域级别对齐采用前面基于对抗方法的思路,对两个域从整体进行对齐.关系感知采用图卷积的方式,将检测网络提取出的目标作为节点,以目标之间的相似度作为边,构建图来更新特征.类别中心对齐中我们将每一类目标的均值作为类别中心,对两个域的同一类别中心进行对齐.
本文设计的网络同时考虑了域信息,类别信息,目标间的关系信息,在4个标准数据集上取得了相当甚至超过最佳方法的结果.
2 相关工作
2.1 目标检测
目标检测通常分为两类,包括两阶段方法和单阶段方法.两阶段方法主要有文献[3-5],这类方法通常采用区域候选网络[3](RPN)和区域池化模块[3](ROI Pooling)提取目标特征,然后送入后续的分类器和回归器进行分类和位置回归.与之相比,单阶段网络[6-8]更加简单和快速,他们直接回归输出目标的类别和位置,当然,相比于两阶段方法,单阶段在追求速度的同时也牺牲了精度.然而,这些方法通常用于常规检测,无法处理域偏移问题.本文选取Faster R-CNN[3]作为基础检测器,并且改善其泛化性能.
2.2 跨域目标检测
文献[13]在图像级别和目标级别分别设计判别器达到域适应的目的.文献[14]在图像级层面设置多层判别器,以增强对齐效果.在文献[17]中,Raj等人通过子空间对齐对检测器进行域适应.文献[18]通过CycleGAN[24]将源域图像转换为目标域图像,并在转换后的图像上训练检测器.文献[19]通过成对机制对目标域的样本进行增强,并且在图像级和目标级上分别对齐.文献[20]在特征提取网络的底层特征图和高层特征图分别对齐,并且对高层特征图采用Focal Loss[25],专注于难分样本.与上述方法相比,本文方法的不同之处在于将关系信息和类别信息考虑进来.
2.3 图卷积
图卷积神经网络的目的是对图结构数据应用卷积神经网络.通常可分为谱域方法和空域方法.谱域方法[26,27]从信号处理的角度利用图傅里叶变换在谱域执行卷积运算.空域图卷积方法[28,29]从空间位置的角度出发更新节点,他们通过对中心节点和邻居节点进行聚合完成节点更新,本文将目标作为节点,目标间的相似度作为边,属于空域方法.
3 网络设计

3.1 框架概述
本文设计的网络架构如图1所示.来自于源域和目标域的两张图像分别被送入网络G中提取特征.与之前的许多工作一样,我们在提取好的特征图上添加判别器以期达到域整体对齐的目的.为了方便起见,我们在图中画了两个RPN模块,实际上,它们是同一个模块.经过RPN和ROI Pooling模块,获得两组目标特征,PS,PT∈RNxD分别来自源域和目标域,其中,N是目标的数量,D是每个目标的维度,然后,我们把这两组目标分别送入关系感知模块,目的是更新每个目标特征,使其注意到上下文关系.最后,利用Faster R-CNN中最后的分类器对更新后的目标进行分类,对属于同一类的目标进行平均作为类别中心,并且送入类别中心对齐模块.网络总的损失包括类别中心对齐的损失和源域数据送入检测器的检测损失.

图1 网络结构图
3.2 关系感知模块
之前的检测网络通常对RPN输出的目标单独处理,进行分类和回归,而目标间的关系信息对于理解目标至关重要.本文通过关系感知模块对目标间的关系进行建模并更新目标.下面,本文将以一个数据域为例,另一个域实现同理.
具体而言,本文会使用目标候选区作为节点建立一个图,G=(V,E),其中V∈RNxD是顶点集合,由目标P组成,E∈RNxD是边的集合,本文定义边为节点类别输出的相似度,相似度采用点积计算,节点的类别输出即检测网络中最后分类器的输出.
此时,顶点集合V为二维矩阵,边集合E也为二维矩阵,本文首先对E的对角线置零,然后对每一行归一化,这样做的目的是对节点周围邻居加权求和.最后,利用矩阵乘法操作更新目标特征.
PS=ESVS
(1)
PT=ETVT
(2)
其中,PS代表源域中每个节点对邻居节点的加权求和结果,PT代表目标域中的结果.
3.3 类别中心对齐
更新目标特征后,需要计算当前批数据中每一类的类别中心,具体做法是根据分类器给出的类别进行分类,对每一类目标进行平均,平均结果作为该类的类别中心.
由于一批数据中不一定存在所有类别,即可能存在类别缺失,另一方面仅仅利用一批数据进行类别中心的计算很容易存在误差,故对于类别中心本文采用滑动平均的方式,对当前得到的类别中心与历史类别中心加权求和.
(3)
(4)
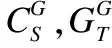
(5)
其中,k是类别数,φ是距离函数,这里采用L2损失.通过显式地约束不同域中同样类别中心的距离,本文可以使得属于同一类的目标在高维空间中更加聚集.
3.4 总目标函数
总的来说,为了实现跨域目标检测,我们同时把检测损失,域对齐损失,类别中心对齐损失考虑在内,总的损失函数定义见公式(6):
L=Ldet+γLdα+σLC
(6)
其中,Ldet代表检测损失,Ldα代表域对齐损失,LC代表类别中心对齐损失,γ与σ为平衡因子,检测损失定义见公式(7):
Ldet=E(x,y)~Ds[J(x,y)]
(7)
J包括RPN网络的损失,最终的分类损失和回归损失.Ldα代表域对齐损失,如公式(8)所示:
Ldα=Ex~Ds[log(1-D°G(x))]+Ex~Dr[D°G(x)]
(8)
其中,D代表域分类器,G代表生成器,在域分类器前插入了梯度反转层[30](GRL),可以简化训练,不需要分别训练生成器和判别器.
4 实验分析
在这一部分,首先阐述使用的数据集,评估场景,基线方法和实验细节,然后给出实验结果和相应分析.最后,给出消融实验结果.
4.1 数据集
为了验证所提出方法的有效性,我们利用下列数据集构建域适应场景并执行了实验:1)PASCAL VOC[10]这个数据集包含20类物体和相应的标注框.参考之前的方法,本文将PASCAL VOC 2007和2012训练集和验证集用于训练,总共15000张图片;2)WaterColor[15]WaterColor包含水彩图像,共2K张图像,6类物体,包含于PASCAL VOC的20类物体.1K张用于训练,1K张用于测试;3)Sim10K[31]这个数据集包含合成的驾驶场景图像,共10K张图像,全部收集于计算机游戏Grand Theft Auto.遵从文献[20]的做法,只在汽车这一目标上进行检测;4)CityScape& FoggyCityScape[32,33]CityScape中的图像由车载相机捕捉而来,FoggyCityScape是利用CityScape添加雾噪声合成得到.两个数据集都有2975张训练图像和500张测试图像.
4.2 评估场景
本文建立的域适应场景包括:1)场景1:PASCAL VOC到WaterColor;2)场景2:CityScape到FoggyCityScape;3)场景3:Sim10K到CityScape.这里,场景1用于捕捉真实数据到艺术风格数据的偏移,场景2用于捕捉正常天气到雾天的偏移,场景3用于捕捉合成图像到真实数据的偏移.
4.3 基线方法
本文的方法以两阶段检测器Faster R-CNN为基础,同时也与一些目前优秀的跨域检测方法包括DA Faster[13],MAF[14],DTPL[15],ST[16],DM[18],FAFR-CNN[19],Strong-Weak[20],SCDA[21]进行比较,这些方法的结果引用于文献[19-21].
4.4 实现细节
在实验中,设置图像的短边为600像素,batch size为1,初始学习率为0.001,每5个周期乘以0.1,共训练20个周期.优化器采用随机梯度下降(SGD),动量设置为0.9,权重衰减设为0.0001.采用一块GeForce Titan XP用于训练.对于所有实验,采用PASCAL VOC的评估标准,意味着采用阈值为0.5的MAP来评估所有方法.关于超参数,α=0.9,σ=0.2,γ=1.0.
4.5 结 果
这一部分展示在3个场景的实验结果并作出详细分析.
场景1.本文展示真实图像与艺术风格图像的跨域检测结果.具体地,采用PASCAL VOC作为源域.对于目标域,采用WaterColor.实验过程中,采用在ImageNet[9]上预训练好的ResNet101[34]作为基础特征网络.候选区目标的数目是128,维度是2304.根据表1,本文的方法超出所有方法至少4.0MAP,表明本文的方法在真实图像到艺术风格图像这种域偏移较大的场景上表现良好,本文认为关系信息和类别信息对于较大域偏移场景可以起到重要作用,可以看做对仅考虑图像级对齐或实例级对齐方法的有效补充.DA Faster相比于Faster R-CNN提升有限,而DTPL和DM等基于图像转换的方法效果突出,表明对于域风格差异较大的场景,图像转换可以起到良好作用.

表1 PASCAL VOC到WaterColor的域适应结果
场景2.在这个场景中,本文的目的是分析本文的方法在正常天气到雾天下的表现.用CityScape作为源域,FoggyCityScape作为目标域.参考Strong-Weak中的设置,本文采用VGG16[35]作为基础特征网络,候选区目标的数目设为256,维度设为4352.如表2所示,本文提出的方法超出所有方法.这一结果表明我们的方法在两个域不相似和相似时都能表现良好.在这一设置中,DA Faster和FAFR-CNN相比于Faster R-CNN分别带来7.3和11.0MAP.相比于MAF,Strong-Weak和DM,我们的增益分别是1.0MAP,0.7MAP和0.4MAP.这表明在域偏移较小时关系信息和类别信息只能带来有限的增益,因为两个域之间的唯一差异是天气,关注全局对齐就能有效缓解域偏移.

表2 CityScape 到FoggyCityScape的域适应结果
场景3.这里,评估本文的方法在合成图像到真实图像上的域适应效果.采用Sim10K作为源域.至于目标域,采用Cityscape.两个域都是驾驶场景,但是在光照,视角上有明显不同.相比于场景2,域偏移更大.结果展示见表3.在这一场景中,本文的方法相比于Strong-Weak DA有1.3MAP的提升,与FAFR-CNN效果相当.但是低于SCDA 1.6MAP,本文认为在这一场景中,仅有汽车这一类目标需要考虑,如果利用关系感知模块更新特征,极有可能收到假正例即背景的干扰,从而导致特征更差.但是相比于SCDA,我们的优势是不需要额外的参数,前者需要两个生成器和判别器,为训练带来负担.

表3 Sim10k到CityScape的域适应结果
4.6 消融试验
这一部分,本文执行一些消融试验以分析一些超参数和模型中不同模块的影响,所有实验采用PASCAL VOC到WaterColor这一场景.
1)σ的影响.结果展示在表4中,采用场景2进行实验.我们尝试了不同的参数设置,发现最好的结果是0.2.

表4 不同σ对PASCAL VOC到WaterColor的影响实验表
2)3个组件的影响.这里我们执行了几个实验以分析方法中不同组件的影响.结果展示见表5,可以观察到域对齐可以为Faster RCNN带来5.5MAP,关系感知模块和类别中心对齐分别带来2.9MAP和5.8MAP的增益,三者的结合可以带来最好的结果.

表5 不同组件对PASCAL VOC到WaterColor的影响实验表
5 结 论
在本文中,我们提出了一个新颖的方法,可以同时建模域信息,类别信息和关系信息在一个统一的框架中.为了鲁棒地匹配源域和目标域的分布,我们设计了3种有效机制,包括域对齐,关系感知和类别中心对齐.3种机制互相补充并学习到域不变的特征表达.在标准数据集上的实验验证了所提出方法的有效性.
