基于迁移学习和残差网络的农作物病害分类
2021-05-09王东方
王东方,汪 军
(安徽工程大学计算机与信息学院,芜湖 241000)
0 引 言
农作物病害影响农业产品质量和产量,自动识别作物病害是一个重要课题。随着农业生产种植结构不断复杂化,农业生产中所遇到的病害情况也越来越复杂,对农作物的生长造成了严重的影响,快速、准确地识别出农作物病害种类并进行及时防治,对于提高农作物的质量和产量至关重要。
传统机器学习技术检测农作物病害种类通常分为图像预处理、图像分割、特征提取和分类4个阶段[1-4]。在这一过程中,特征提取是一个难题,由于人为选择特征需要大量的试验和经验,而且存在一定的主观性。复杂的农作物病害种类又加深了特征提取的难度。深度学习是机器学习的一个分支,在计算机视觉领域应用潜力巨大。卷积神经网络能够从输入图像中自动提取相关特征,相较于人为选择的特征更加具有客观语义性,减少了人为主观性的影响。本文基于迁移学习并改进深度残差网络,创建自动检测和分类农作物病害种类的模型,以避免传统方法依赖人工特征设计的问题。
Jia等[5]发布的大型数据集ImageNet为图像识别研究提供了强有力的数据支撑。Krizhevsky等[6]提出的AlexNet卷积神经网络模型,在ImageNet比赛中获得了冠军,Top-5的错误率仅有15.3%,比第二名低10.8个百分点。AlexNet卷积神经网络的成功应用极大地促进了深度学习技术的发展,使得深度学习技术在多个领域得到广泛应用,例如人脸识别、语音识别、行人检测等[7-11],也促进了农业生产活动朝着智能化的方向发展[12-15]。龙满生等[16]针对油茶的5种不同病害,构建了基于卷积神经网络AlexNet与迁移学习的模型,在自建的数据集上,准确率达到了96.5%。赵立新等[17]以棉花叶部病虫害图像为研究对象,利用迁移学习算法和数据增强技术,通过改进AlexNet模型,在自建的数据集上取得了97.16%的平均准确率,实现棉花叶部病虫害图像准确分类,显示出了深度学习技术在农业领域巨大的应用潜力。Simonyan 等[18]提出VGG模型,使用小卷积核代替大卷积核,增加了通道数,模型结构简单、应用性强。Jia等[19]针对10种常见的番茄病虫害,构建了基于VGG-16和支持向量机(Support vector machine,SVM)的番茄病虫害检测模型,在包含7 040幅图像的数据集上进行训练和测试,平均分类准确率达到89%。许景辉等[20]实现了小数据样本复杂田间背景下的玉米病害图像识别,提出了一种基于迁移学习和VGG-16网络架构的病害识别模型,对玉米健康叶、大斑病叶、锈病叶图像的平均识别准确率为95.33%。Szegedy等[21]提出GoogLeNet 模型,使用不同尺寸的卷积核融合不同尺度的特征信息,提高网络的表达能力。Zhang等[22]使用改进型的GoogLeNet网络架构,对来自PlantVillage数据集和谷歌网站中包含9种类别的500张玉米图片进行模型训练和测试,识别准确率达到98.9%。黄双萍等[23]提出基于深度卷积神经网络GoogLeNet模型的水稻穗瘟病识别方法,在验证集上最高准确率为92%。He等[24]提出ResNet模型,在模型中运用残差模块有效缓解梯度弥散、梯度爆炸等问题。Picon等[25]针对小麦病害,构建了基于迁移学习和ResNet-50的卷积神经网络模型,在自建的包含8 178幅图像的数据集上进行了模型训练和测试,对3种小麦病害的平均准确率达到87%。Lecun 等[26]提出的LeNet模型是最早的卷积神经网络之一,确立了卷积神经网络的基本结构。马浚诚等[27]采用先分割再处理的思路,参考LeNet模型构建了一款基于卷积神经网络的病害识别系统,该系统对温室黄瓜的病害识别,准确率为95.7%。卷积神经网络模型的构造方法和思想在不断发展,Huang等[28]提出的DenseNet模型、Xie等[29]提出的ResNeXt模型和Hu等[30]提出的SENet模型都进一步拓展了卷积神经网络的设计思路,为图像识别研究提供了更多的参考。
以上研究中,单一农作物种类病害识别模型存在一定的局限性。真实农业生产环境下往往存在多种农作物,仅识别单一物种难以应对实际生产环境下复杂的种植结构。本文对深度残差网络SE-ResNeXt-101模型进行改进,并基于迁移学习提出一种农作物病害图像分类方法TL-SE-ResNeXt-101,用于不指定农作物种类的病害检测分类,并在重构的AI Challenger 2018农作物病害数据集上完成模型训练与试验。
1 农作物病害图像分类模型
1.1 迁移学习
迁移学习的实现方法分别为样本迁移、特征迁移、模型迁移和关系迁移,本文采用模型迁移的方法,利用在ImageNet数据集上预训练的SE-ResNeXt-101模型参数文件对TL-SE-ResNeXt-101模型网络的权值进行初始化,代替原先的随机初始化操作,并进行全局微调,其余训练过程照常进行。
1.2 残差模块
更深更宽的网络架构意味着模型可以提取到的特征信息更丰富,更具有语义信息。ResNet模型运用残差模块有效解决了网络加深之后出现的梯度弥散和梯度爆炸问题。残差模块从形式上定义为
式中x和y分别表示残差模块的输入和输出;F(x,{Wi})为网络要学习的残差映射。
残差模块引入了一个恒等映射,如图1所示,将原本网络要学习的函数H(X)=X转换成为H(X)=F(X)+X,该结构提高了模型的表达能力,避免了网络层数加深导致的退化问题,其中激活函数为线性整流单元(Rectified Linear Units,ReLU)。
考虑到深层次网络的计算成本,ResNet模型对残差模块的结构进行了优化。如图2所示,对原结构中2个3×3的卷积层进行替换,在图2b新结构的中间3×3卷积层之前,使用1×1的卷积层进行降维操作,在3×3卷积层之后使用另一个1×1的卷积层进行升维还原。相比较图2a的残差结构,图2b的结构既保持了精度又减少了计算量和参数量。
GoogLeNet模型中提出的“Inception模块”通过“分解-转换-融合(Split-Transform-Merge)”的策略进行网络设计可以融合不同尺度的信息,增强模型的表达能力,提升模型性能。ResNeXt模型借鉴了这种网络设计的思想对残差模块进行了改进。
ResNeXt网络对残差模块的改进过程如图3所示,可以看到图3b的残差结构将图3a中的卷积层分解成了32组,在转换计算之后将各组的结果融合。与“Inception模块”不同的是分组卷积层使用了相同结构,而不是被设计成不同结构,因为每个分组都设计不同卷积核及网络深度会导致参数迅速膨胀。相同结构设计简化了网络结构。图3c为残差结构中分组卷积的简洁表示形式,同时 ResNeXt网络引入了新的超参数“cardinality”表示残差结构中卷积层的分组数量。根据分组数量自动将卷积层均分成相同卷积核及输入输出通道维度的结构,在图3c中分组卷积使用的是32×4结构的模板,即分组数量为32组,3×3卷积层输入输 出维度为4维。
1.3 模型结构
在卷积神经网络架构中,通常在网络最后使用几层全连接层,再利用softmax函数进行分类。全连接层参数量过多会导致模型变得非常复杂,同时可能造成模型出现过拟合现象,全局平均池化层的使用可以极大地减少网络中的参数,并且一定程度上防止过拟合,但是会忽略一些细节信息。
本文基于迁移学习和SE-ResNeXt-101模型提出TL-SE-ResNeXt-101模型。模型结构如表1所示,整个网络由卷积层、池化层、残差模块和全连接层构成,其中残差模块采用的是32×4分组卷积结构。表 1展示的网络结构中,括号内是残差模块的构建参数和结构,括号外部参数表示残差模块重复堆叠的数量。4组不同结构的残差模块按照指定数量依次堆叠构成模型的基本网络架构,在原始网络架构中经过全局平均池化层和输出维度为1 000的全连接层,利用softmax函数进行分类任务。对于农作物病害这种细粒度分类需要更多的细节信息进行判断,所以本文对原始模型架构做出改进,使用2个3×3卷积核步长为2的卷积层代替原始模型架构中7×7的全局平均池化层,两者具有相同的感受野,但卷积层可以保留更多的细节信息。同时在第二个卷积层后使用批量归一化处理,以加速网络收敛、提高分类精度,为了适用农作物检测分类任务,将最后一个全连接层输出维度设置为33,利用softmax函数进行分类。
SE模块是SE-ResNeXt模型中使用的一种注意力机制。如图4所示,SE模块在原始的残差模块结构中加入一条路径用以计算每条通道的权重。在残差模块之后使用全局平均池化层获取每个通道的信息,2个全连接层分别使用ReLU和Sigmoid激活函数,其中在第一个全连接层中进行降维操作,降维比例在网络中被设置为16。在模型训练中,每个残差模块的输出通道经过这条路径学习到一组权重,对每条通道的输出进行加权计算,从而突出习得特征中的关键信息,抑制无用信息,增强模型的表达能力。

表1 TL-SE-ResNeXt-101网络架构Table 1 TL-SE-ResNeXt-101 network architecture
2 作物病害分类试验
2.1 试验环境
为了验证TL-SE-ResNeXt-101模型的有效性和适用性,本文进行了作物病害分类对比试验。试验在百度AI studio平台进行,模型的训练和测试均在PaddlePaddle深度学习框架下完成。平台的硬件环境:NVIDIA Tesla V100 GPU,16G显存;Intel Xeon Gold 6271C @2.60GHz CPU,32G内存。软件环境:Python 3.7;PaddlePaddle 1.6.2。
2.2 数据集
试验所使用的农作物病害数据集来自于AI Challenger 2018比赛,该数据集包含苹果、樱桃、玉米、葡萄、柑橘、桃树、辣椒、马铃薯、草莓和番茄10种植物,27种病害和健康类别,按照“物种-病害-程度”共分为61个类别。由于该数据集的测试集标签没有公开,本文对数据集进行重构,以更好地训练和优化模型;剔除含有多个叶片样本且存在同时含有健康和其他病害类别情况的玉米和柑桔2个健康类别,以符合本文对作物病害单标签分类的设定;同时,为了缓解样本不均衡问题对模型性能产生的影响,本文剔除了2个只包含一张图片样本的类别,并且将同一作物病害一般和严重程度的样本混合在一起,相较于区分病害程度,更加准确的区分出病害类别更为重要。数据集以“物种-病害”对的方式分为33个类别,共获得35 332张不同尺寸的作物病害叶片图像,所有图片均为RGB格式保存的JPG图片,按照8∶1∶1的比例划分为训练集、验证集和测试集。其中训练集28 253个样本,验证集3 532个样本,测试集3 547个样本。数据集中部分样本图像如图5所示。
2.3 数据预处理
试验数据预处理包括图片尺寸重定义、像素去均值化与归一化处理。
本文将数据集中不同尺寸的图片统一转换为224×224×3,模型输入维度的一致更便于比较各模型之间的性能。
对训练集中每张图片的每个通道的像素值都减去全部训练集图片的相同通道像素的均值,然后对每个通道像素进行归一化处理,从而减少计算量,同时也防止深度学习模型训练中出现的梯度爆炸,以加速模型收敛。
2.4 数据增强
数据增强技术可以增加样本的多样性,降低模型对某些属性的依赖,提升模型的性能和泛化能力。本文数据增强策略包括颜色增强、随机旋转、随机裁剪和水平随机翻转,样本数据增强示例如图6所示。其中颜色增强包括亮度调整、对比度调整、饱和度调整和色度调整,随机旋转是将图片在-15°与15°之间随机旋转,随机裁剪是将图片在0.1至1的比例之间任意裁剪一部分,再转换为224×224的图片尺寸,水平随机翻转是将图片随机翻转为镜像图片,本文数据增强策略均以50%的概率随机进行。
2.5 图像识别模型
2.5.1 VGG模型
VGG-16模型由13个卷积层和3个全连接层组成,网络中的激活函数为ReLU,部分卷积层后面连接最大池化层。在VGG-16模型卷积层中,通过小卷积核的堆叠代替大卷积核,在感受野大小相同的前提下,堆叠小卷积核的方式可以大大减少模型参数。为了符合本文试验数据集中33个分类标签,对该模型的softmax分类器进行修改。
2.5.2 GoogLeNet模型
GoogLeNet模型引入了Inception结构,该结构使用多个不同尺寸的卷积核和池化层,融合不同尺度的特征信息。模型运用1×1的卷积核对网络降维以及映射处理,在增加网络深度和宽度的同时减少模型参数。此外模型添加了2个辅助分类器帮助训练,对模型的softmax分类器进行修改。
2.5.3 ResNet模型
ResNet-50模型中引入了残差模块,有效地解决了因神经网络层数加深导致的梯度弥散、梯度爆炸和退化问题。本文试验修改了模型softmax分类器以适用于农作物病害图像的检测分类。
2.5.4 DenseNet模型
DenseNet模型是一种紧密连接的卷积神经网络结构。网络之间以前馈的方式直接相连,最大限度地保证各层网络之间的信息流动。从而缓解深层网络中的梯度消失问题,提升了模型表达能力。针对农作物病害分类任务,本文构建121层的模型DenseNet-121,修改模型的softmax分类器以符合本文分类任务。
2.6 超参数设计
超参数的设计对于模型训练及性能的影响至关重要,本试验超参数设计参考相关模型在类似数据集上的设计以及在本研究数据集上进行的系列试验,对超参数进行统一化处理。
学习率是深度学习中重要的超参数,合适的学习率可以使损失函数在较短的时间内收敛到局部最小值,学习率设置太小会导致网络收敛较慢,训练时间较长,设置太大可能会导致梯度在最小值附近震荡,甚至无法收敛。本文采用指数标尺选取0.000 1、0.001、0.01和0.1共4组学习率,经过各个模型的反复试验之后,最终将学习率设置为0.000 1。
每个批次(Batch)训练样本的数量大小(Batch Size)也会影响模型的性能及速度。为了寻求内存效率和内存容量之间的最佳平衡,本试验选取了16、32、64、128和256的Batch Size进行对比试验,最终将Batch Size确定为64。
对于损失函数和优化算法,本试验选择交叉熵损失函数在模型训练中对比随机梯度下降(Stochastic Gradient Descent,SGD)、动量梯度下降(Gradient Descent with Momentum,Momentum)和自适应矩估计(Adaptive Moment Estimation,Adam)优化算法。Adam优化算法适用于非凸优化问题,计算效率高、内存需求少。同时,本试验将一阶矩估计的指数衰减率设为0.9,二阶矩估计的指数衰减率设为0.999,L2正则化系数设为0.000 05。
3 结果与分析
3.1 图像识别模型性能对比试验
相同条件下,对4种图像识别模型与本文模型进行比较。为了评价各个模型的性能,结合农作物病害识别分类的特点和数据集的样本状况,本试验选择平均准确率(Average accuracy rate)和加权F1(Weighted-F1)作为模型性能的评价指标。各模型均迭代60次,每迭代5次保存一次训练模型,结合各模型在测试集上的表现,选择最优模型,结果如图7所示。
从图7中可以看出,本文提出的基于迁移学习的模型TL-SE-ResNeXt-101取得较低的损失值并且达到较高的准确率,在训练集和验证集上,损失值分别为0.017和0.083,平均准确率分别为99.24%和98.07%,分类效果优于其他模型。在模型的损失和准确率收敛方面,本文模型收敛速度最快,在第20次迭代左右趋于收敛,这说明相较于其他模型,TL-SE-ResNeXt-101能够在更短的时间内训练出最优模型。收敛速度最慢的是DenseNet-121模型,在第50次迭代左右趋于收敛,并且验证集的损失和准确率在训练的过程中存在一定的波动。其余模型在训练过程中相对稳定,在第40次迭代左右趋于收敛。纵观各个模型的损失和准确率收敛曲线,模型在验证集上的损失值略高于训练集,在验证集上的准确率略低于训练集。
表3 为不同作物病害识别模型在测试集上的平均准确率和加权F1值。由表3可知,各模型平均准确率均在93%以上,说明深度学习模型应用于农作物病害检测分类具有优秀的表现,并且各模型的加权F1值也达到93%以上,说明各模型在不同类别上的表现差异较小,相对均衡。本文模型基于迁移学习并将注意力机制运用到卷积神经网络中,将不同的特征赋以不同权重,突出重要信息,抑制无用信息,在测试集上取得了98%的平均准确率,加权F1值达到97.99%,优于未改进网络架构的TL-SE-ResNeXt-101模型,相较于VGG-16、GoogLeNet、ResNet-50和DenseNet-121模型分别提高了3.95%、4.12%、2.12%和4.26%。
3.2 基于迁移学习的模型性能对比
在迁移学习方式下,由于加载了预训练模型,模型前端各层网络均可获得较好的训练参数,在模型训练之初已经接近最优解。基于迁移学习的TL-SE-ResNeXt-101模型与未加迁移学习的SE-ResNeXt-101模型的损失与准确率曲线如图8所示,可以看出,迁移学习对加速网络收敛有明显的促进作用,TL-SE-ResNeXt-101模型在训练初始时刻就已经获得较低的损失值和较高的准确率,而且网络迅速收敛,在第40次迭代左右,模型的平均准确率便达到峰值,训练集上为99.24%,验证集上为98.07%。相比之下,SE-ResNeXt-101模型的损失和准确率曲线收敛较慢,在第50次迭代左右,模型的准确率才到达峰值,训练集上为97.82%,验证集上为97.25%。
2类模型在测试集上的平均准确率和加权F1指标如表4所示,可以看出,在迁移学习下,模型的性能有一定的提升,平均准确率和加权F1均提高了约3个百分点。说明基于迁移学习的农作物病害识别分类模型TL-SE-ResNeXt-101可以加速网络收敛,减少模型训练时间。由于采用迁移学习的方式,预训练模型在有目的的训练下,已经学习到相关上下文中有用的通用特征,当模型参数迁移到作物病害识别任务只能进行增量式学习,不容易对新数据进行过度拟合,因此具有良好的泛化能力,提高了模型准确率。

表4 迁移学习模型与普通模型性能对比Table 4 Performances comparison of transfer learning model and ordinary model
3.3 基于数据增强的迁移学习模型性能对比
表5 是本文模型在数据增强和没有数据增强方式下的性能表现,从表5中可以看出,在数据增强的方式下,模型性能有显著的提升,平均准确率和加权F1指标均提高了约5个百分点。说明数据增强对于模型性能的提升有明显的促进作用,而且通过对图像样本进行数据增强,可以减少网络模型对图片中某些属性的依赖,缓解训练阶段中可能会出现的过拟合状况,从而提高模型性能和泛化能力。

表5 基于数据增强迁移学习模型与普通迁移学习模型的性能对比Table 5 Performances comparison of data-enhanced transfer learning model and ordinary transfer learning model
3.4 真实环境下模型性能对比
使用PlantDoc数据集评价各模型对真实农业生产环境下农作物病害图像分类性能。PlantDoc数据集是对互联网上获取的图像进行人工标注的农作物病害图像数据集,涵盖13种植物,27种病害和健康类别。本文选取与AI Challenger 2018数据集重合的作物病害类别,只保留真实农业生产环境下的作物病害图像样本,共获得981张作物病害图像,包含16种作物病害类别(图9)。
将PlantDoc数据集按照8∶2比例划分为训练集和测试集,从不同角度评价各模型在测试集上的性能。
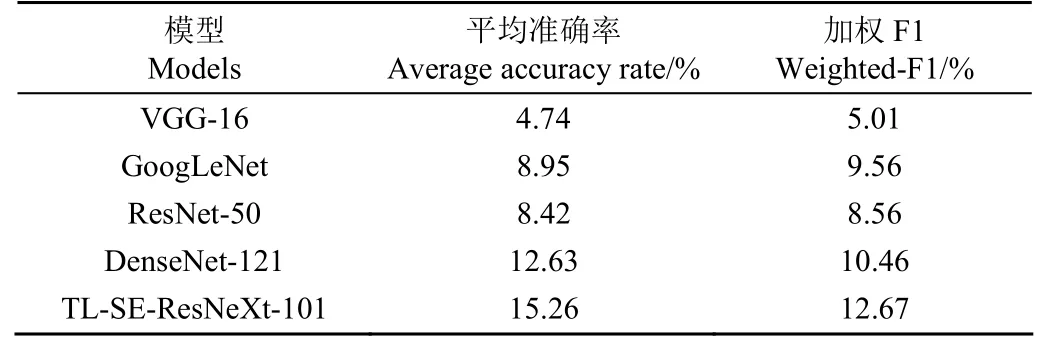
表6 不同模型在PlantDoc测试集的性能比较Table 6 Performances comparison of different models in PlantDoc test set
表6 是各模型在PlantDoc测试集上的性能表现,从表6中可以看出,各模型的性能表现较差,平均准确率和加权F1值分别在16%和13%以下。本文提出的TL-SE-ResNeXt-101模型表现最好,但平均准确率仅为15.26%。由于实验室环境与真实农业生产环境下拍摄的样本图像存在较大的差异,农业生产环境下的样本图像背景更加复杂,更容易受到光照等其他外界条件的影响,所以各模型在PlantDoc测试集上性能表现均较实验室环境差。为了缓解因环境不同图像样本之间差异造成的影响,本文将在AI Challenger 2018数据集上训练后的模型继续在PlantDoc训练集上训练。如表7所示,可以看出,各模型性能较未在PlantDoc训练集上训练的模型有很大的提高,VGG-16、GoogLeNet、ResNet-50、DenseNet-121和TL-SE-ResNeXt-101模型的平均准确率分别提高了28.42%、30.52%、23.16%、14.74%和32.11%。说明利用真实农业生产环境下作物病害图像样本进行模型训练有助于提高模型在实际应用环境下的性能。本文所提出的TL-SE-ResNeXt-101模型表现最好,平均准确率达到了47.37%,真实农业生产环境下对农作物病害图像分类效果优于其他模型。
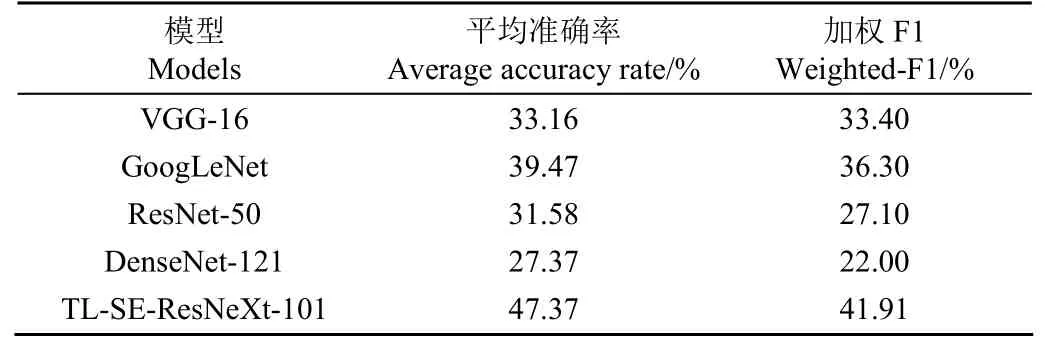
表7 在PlantDoc训练集训练的不同试验模型在测试集的性能比较Table 7 Comparison of the performances of different experimental models trained in the PlantDoc training set in the test set
4 结 论
本文对深度残差网络模型SE-ResNeXt-101进行改进,并基于迁移学习提出了一种农作物病害分类模型TL-SE-ResNeXt-101,用于不指定农作物病害种类的检测分类,从而避免传统方法依赖于耗时费力的人工特征设计,提高模型对不同作物种类不同病害的检测分类性能,增强模型在实际农业生产环境复杂种植结构下的应用能力。在重构的AI Challenger 2018农作物病害数据集上,本文方法对不同作物种类不同病害的检测分类平均准确率均达到98%,加权F1分数达到97.99%。结果表明,相同试验条件下,本文模型比VGG-16、GoogLeNet、ResNet-50和DenseNet-121模型分类效果更好,同时,对真实农业生产环境下的图像样本亦有较好的分类效果,在PlantDoc测试集上平均准确率达到47.37%。本文的对比试验说明迁移学习技术的运用可以加速模型网络收敛和提升模型性能,在较短的时间内训练出更优的模型。数据增强技术可以有效地降低模型对某些属性的依赖,缓解模型训练中可能会出现的过拟合问题,对农作物病害检测分类模型性能和泛化能力的提升有明显的促进作用。
目前公开的农作物数据集大多为背景简单,病害单一的作物叶片图像,而在真实环境下进行现场检测时,得到的往往是背景复杂且可能包含多种病害类型的作物图像。下一步研究计划收集更多真实环境的农作物叶片图像,进一步丰富农作物病害图像数据集,优化模型。同时,利用目标检测算法先识别叶片目标,限定区域,减少背景环境的影响,然后再对限定区域进行农作物病害的细粒度分类,提升模型性能和鲁棒性,建立端到端的农作物检测分类模型,提高其实用价值。
