基于大数据关联规则的网络恶意行为识别检测
2021-05-07谢奇爱李正茂
谢奇爱,李正茂
(合肥学院 人工智能与大数据学院,合肥 230601)
0 引 言
网络恶意行为攻击是对于计算机网络安全而言最为主要的一种威胁行为。网络恶意行为一般以代码形式攻击计算机网络。[1]近年来,各种新类型的恶意代码通过客户端软件或者计算机端存在的漏洞攻击计算机,给用户的使用带来诸多麻烦。恶意代码传播行为隐秘性高,传播速度快,使用常见的杀毒软件很难有效抑制恶意代码的行为。[2,3]
各类杀毒软件相关公司积极研究遏制恶意代码的相关杀毒软件,但是部分软件研发公司受到利益驱动常常在免费软件中隐藏部分恶意行为,严重威胁到使用者的用户体验,极易泄露使用这的资料和隐私,给网络安全带来重大冲击。[4]恶意行为识别检测是以主机入侵作为基础的识别检测方法之一,一般是使用一种或者数种技术结合实现恶意行为的识别,一旦发现恶意行为立即实行保护机制。常使用的恶意行为识别检测方法主要基于异常检测或者特征码检测,将特征码作为检测基础的手段是判别已知特征码[5],具有较高检测效果但是对于大量涌现的特征代码却不适用;以异常作为基础的检测方法能够检测出位置软件中存在的恶意行为[6],一般为漏洞等攻击行为,但是对于其它行为检测效果较差。对于恶意行为相关识别检测已经成为众多研究者的重点。有学者提出基于事件流数据世系的恶意网络行为检测方法[7],通过事件流对用户和系统之间的网络相关行为实现刻画,构建使用数据驱动的事件流数据世系模型,检测出异常行为,但是该方法在实际应用时,存在漏识别的情况;还有学者提出基于上下文信息的Android恶意行为检测方法[8],提取敏感应用连接编程接口,判断恶意行为,该种方法精确率较高,具有实用性,但是计算过程存在复杂性,实际操作困难大。
除上述存在的问题外,再加之当今社会网络信息技术高度发达,物联网、互联网与云计算等计算机技术发展迅速,在各类网络中,海量数据大规模增长[9],为人类的日常生活带来更多机遇和生活便利,但是对网络的运行安全也带来极大的挑战性。在大数据背景之下,部分违法人员通过大数据持续发动恶意攻击行为。这种针对大数据的攻击行为不但能够在相同时间大量控制对象,而且攻击行为不容易被预防,攻击范围更广、隐蔽性更高、持续时间更长。[10]由此可见,大数据背景下网络安全问题已经日益尖锐,成为计算机研究领域中越来越需要受到重视的问题。
本文研究大数据关联规则作为基础的网络恶意行为识别检测,通过模糊关联规则提取数据特征,构建模型识别检测出网络恶意行为。
1 网络恶意行为识别检测
1.1 基于模糊关联规则的大数据挖掘
以模糊关联规则作为基础的大数据挖掘技术就是在关联规则中引入模糊集理论,构建模糊关联规则实现大数据挖掘,对海量大数据进行整理。[11]为了实现模糊关联规则的大数据挖掘,先查找存在最小模糊支持度的频繁项集,依据查找获得的频繁项集构建能够用在大数据挖掘的模糊关联规则,以此实现大数据挖掘。
选择大数据挖掘模糊关联规则,X⟹y为该规则的形式,X与y分别表示大数据属性值集合与大数据类标号。使用加权分类规则构建大数据分类器。
假设大数据分类规则中的后件只存在一个类,Aqi与CFqM分别表示大数据属性xi相对应的某个模糊项与大数据样本被模糊关联规则Rq预测为类CqM的置信度。
经分析各大数据分类规则权重构建分类器,使用式(1)表示各规则权重:
(1)
假设基因分类器S在对大数据样本Xp预测时标号为μAq(Xp),则有:
μAq(Xp)*wm=max{μAq(Xp)*wq|Rq∈S}
(2)
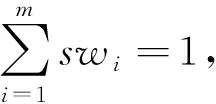
(3)
以模糊关联规则作为基础的大数据挖掘方法利用最小支持度法,数据挖掘时通过向大数据内少数类给予相对低的最小支持度实现,分类器精度不再严重受到数据不平衡的影响,使分类准确性得到提高,提升大数据挖掘效果。
假设freeDistr(ci)、minsupi与base_minsup分别代表类ci占大数据的比例、类ci的分类规则最小支持度与支持度基数,则有:
base_min supi=base_min sup*freeDistr(ci)
(4)
经过以上过程,构建大数据分类器,实现大数据分类,以此为基础聚类数据,综合考虑该分类是否适用于网络恶意行为大数据挖掘。为提升数据挖掘准确性,整理大数据,解决大数据存在的连续性,运用模糊离散化处理数据。[12]模糊关联规则中模糊离散化是关键内容,主要能够将方法扩散,保证方法在连续空间也可以使用,解决处理现实问题,同时为降低数据挖掘难度,实行连续属性的离散化,保证模糊关联规则大数据挖掘的难度得以降低,提升数据挖掘效率。
1.2 网络恶意行为识别模型
根据基于模糊关联规则的大数据挖掘方法得到具有关联规则的数据,分析网络用户的流量和网络用户信息熵,以此为基础通过网络恶意行为识别模型实现恶意行为识别检测。将数据挖掘获得的数据经计算得到信息熵以及网络流量特征,二者融合后建立网络恶意行为识别检测模型,识别出恶意程序或用户生成的流量。[13]
网络恶意流量运行方式主要是将主机资源消耗使得系统不能正常为用户作出相应服务,或者将大量宽带资源占用,导致网络出现大量拥堵等现象。恶意流量会导致短时间网络流量激增,且不会短时间消减,呈现出一种高峰稳定状态。识别这种高持续性高爆发性的恶意访问行为需要通过分析用户访问流量特征,加权用户信息熵特征和用户访问流量特征,建立网络恶意行为的识别模型。
1.2.1 网络用户流量特征
结合模糊管理规则的数据挖掘方法获得的数据,假设a与T分别表示用户IP地址和当前日期,T代表活动时间窗口,式(5)为用户IP地址流量特征值ft(a)的计算式:
ft(a)=max{dft(a,b),zft(a,b,T)}
(5)
b代表高爆发性流量异常参数。0或1作为ft(a)的取值,假如1作为ft(a)取值,可认定此用户IP地址a生成恶意流量;如果取值为0,则说明没有产生恶意流量。dft(a,b)代表在当前日期t下用户IP的流量函数,以此衡量在当前日期用户IP地址是否存在流量异常:
(6)
Zt(a)与Zavg(t)分别表示在当前日期t下用户IP地址a流量与当前日期t下所有用户的流量平均值;Zsd(t)代表流量标准差。在高频访问用户IP地址检测中,使用流量函数识别日爆性恶意流量,由于无法识别高流量持续性的非爆发流量,设zft(a,n,T)代表一段时间用户IP地址持续流量函数:
(7)
在式(7)中,n代表高持续性流量异常参数。用户IP地址流量特征值什么时间为异常值由b和n决定。
1.2.2 网络用户信息熵
结合模糊管理规则的数据挖掘方法获得的数据,将用户IP地址作为分析对象获得流量特征值,对单用户多恶意流量识别。对于数量少但是规模大的分散访问恶意行为,不能仅从用户IP角度识别,因此需要引入网络信息熵这一概念识别群体恶意攻击[14],衡量被访问地址的离散程度需通过单位时间中网络报文目的IP熵值计算,实现恶意流量识别检测。
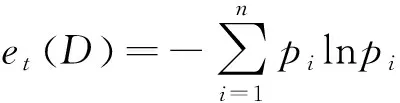
(8)
出现恶意流量后,网络日志内出现较集中的被访问目的地址,网络关系内正常网络流量熵与目的地址IP的信息熵会相对降低。根据公式(4),正常网络流量的熵大于恶意网络流量的熵,因此可以将信息熵作为判断IP恶意流量的标准。通过流量函数判断方法构建熵函数:
(9)
使用式(9)衡量网络流量熵是否存在异常。其中b′代表信息熵异常参数。
1.2.3 构建多特征融合的网络恶意行为识别模型
将用户信息熵特性与网络流量特征融合起来,识别高持续性、高爆发性的网络恶意行为。加权用户信息熵与流量特征,模型具体构建过程如下:
对用户IP地址的恶意值a实行计算,MAt(a)代表恶意值,通过恶意值判断用户IP地址是否是恶意流量。IP用户流量能够直接反映出用户访问的高持续性与高爆发性,但是不能识别大规模分散访问,而用户网络信息熵在这方面的识别能力较好,所以需要把这两个特征结合起来描述恶意访问行为[15]。假设二者在评估恶意流量时权重相同,以此建立网络恶意行为评价函数MAt(a):
(10)
为实现用户恶意值归一化,将0.5设置成各个特征的权重。将0-1作为恶意值MAt(a)范围,该范围可表示用户IP地址的恶意程度,取值范围如果超过0代表存在网络恶意行为,需重点追踪和监测。式(10)采用IP所在网络的熵特性与用户恶意访问相融合,避免了误报,提高了识别速度。
2 实验结果
将某软件设计公司作为研究对象,开展实验,验证本方法性能。该软件公司成立于2014年,主要研发终端包含小程序、APP以及计算机软件,主要开发的软件包含社交聊天、短视频直播、资讯类、跑腿类、社区服务类等。该公司聘请致力于研究云服务、软件开发应用、管理咨询、大数据应用等领域的专家,提高其研发水平,因此邀请该公司专家配合开展实验验证本文方法性能,模拟构建实验平台同时模拟网络恶意攻击,攻击类型包含6种,分别为恶意状态命令注入攻击(MSCI)、恶意参数命令注入攻击(MPCI)、简单恶意响应注入攻击(NMRI)、复杂恶意响应注入攻击(CMRI)、侦查攻击(Reconnaissance)、拒绝服务攻击(DOS)等。
为使实验具有对比性,同时在模拟软件中使用两种对比方法开展实验,对比各方法的实验性能情况。两种对比方法分别为基于事件流数据世系的恶意网络行为检测方法(简称事件流数据世系方法)和基于上下文信息的Android恶意行为检测方法(简称上下文信息方法),两个对比方法分别来自参考文献[7]和参考文献[8]。
验证三种方法在识别检测网络恶意行为之前先验证三种方法挖掘恶意行为特征时的时间消耗情况,反复开展1000次实验,统计历次实验数据挖掘时间消耗情况,结果见图1。
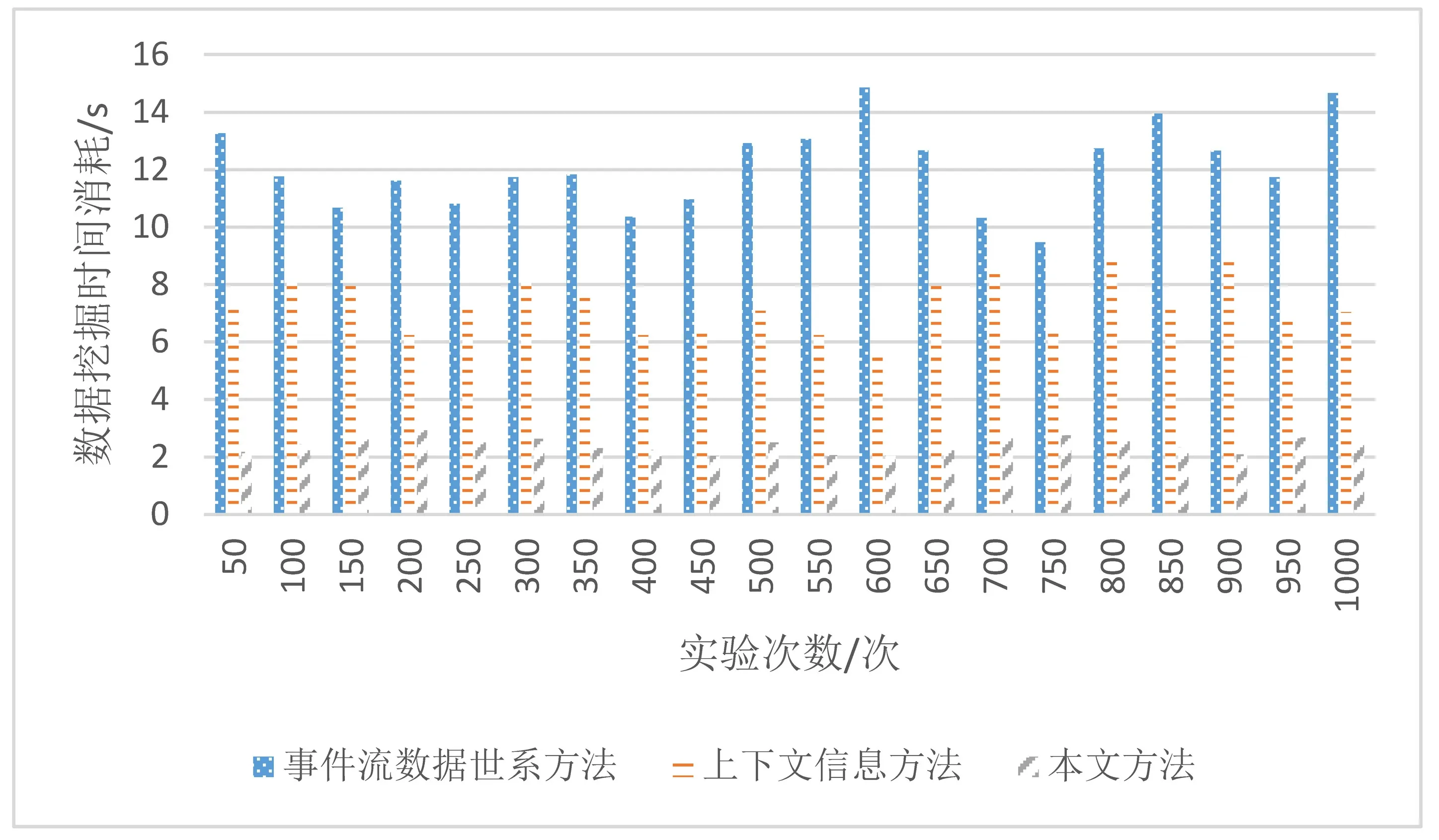
图1 数据挖掘时间消耗对比
从图1能够看出两种对比方法数据挖掘所需时间较高,且每次实验结果显示时间消耗波动较大,没有明显规律,而本文方法数据挖掘时不但所需时间较少且总体波动较小,具有较高的稳定性,说明本文方法数据挖掘效率较高。
三种方法数据挖掘时空间消耗情况,对比结果见图2。
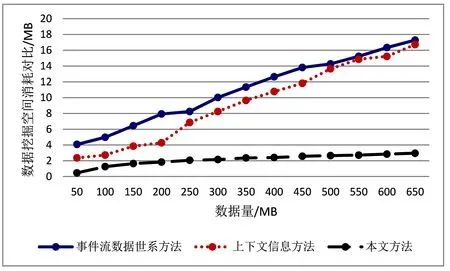
图2 数据挖掘空间消耗对比
分析图2可知,两种对比方法在空间消耗方面都呈现较大上升趋势,当数据量达到650MB时空间消耗量超过170MB,本文方法空间消耗较少,且上升缓慢,说明本文方法数据挖掘时占用空间较少,说明模糊关联规则具有较高优越性,所以数据挖掘占用空间较小。
对比三种方法在数据挖掘支持度方面情况,结果见图3。

图3 支持度对比结果
从图3可知,本文方法支持度最高,分析其原因主要是由于本文方法在数据挖掘之前充分分析数据属性,因此挖掘的数据具有良好的效果,支持度也较高。
对比三种方法在识别检测网络恶意行为时的准确性,对比结果见图4。

图4 识别准确率对比
从图4能够看出,基于时间流数据世系方法在识别检测MSCI和Reconnaissance时准确率较低,但识别检测其它网络恶意行为时准确率良好;本文方法识别准确率最高,准确率在93%以上,这是由于本文方法依据查找获得的频繁项集构建能够用在大数据挖掘的模糊关联规则,为解决大数据存在的连续性,运用模糊离散化处理数据,提高了识别网络恶意行为的准确率,说明在识别检测网络恶意行为时本文方法更具有优势。
对比三种方法在识别网络恶意行为时的识别概率,对比结果见图5。

图5 漏识别率对比结果
从图5能够看出,本文方法在识别检测各类网络恶意行为时,漏识别率较低在8%以下,这是由于本文方法结合模糊管理规则的数据挖掘方法获得的数据,将用户IP地址作为分析对象获得流量特征值,可以进一步识别单用户多恶意流量,降低漏识别率,进一步说明本文方法在识别检测网络恶意行为时具有较高准确率。
3 结 论
文章研究基于大数据关联规则的网络恶意行为识别检测方法,对网络中存在的海量数据实行挖掘,提升数据的利用价值,降低技术成本,为网络恶意行为识别检测打下坚实的基础。同时,文中方法以模糊关联规则大数据挖掘作为基础,获得经整理后的数据,从流量角度出发,识别网络中的恶意流量,恶意流量包含高持续性恶意流量与爆发性恶意流量识别两种。将IP所在网络信息熵特性与网络用户行为特性,有效降低误报性。经过模拟软件实验验证,文章提出的方法在数据发掘方面具有较低的空间消耗和时间消耗,支持度较高,在网络恶意行为识别检测中存在高于93%的准确率和低于8%的漏检测率,具有良好的网络恶意行为识别检测效果。
