一种基于分布式编码的同步梯度下降算法
2021-04-29李博文谢在鹏毛莺池徐媛媛朱晓瑞
李博文,谢在鹏,毛莺池,徐媛媛,朱晓瑞,张 基
(河海大学计算机与信息学院,南京 211100)
0 概述
近年来,深度学习技术已在语音识别[1-2]、计算机视觉[3-4]和自然语言处理[5]等领域得到广泛应用并取得了众多研究成果。在深度学习任务中常使用梯度下降(Gradient Descent,GD)算法作为深度神经网络(Deep Neural Network,DNN)模型训练的主要算法[6-7],然而由于数据量的爆炸式增长,现有单机系统已无法满足梯度下降算法对计算资源的庞大需求。分布式技术通过多机协同计算的方式,使用多个计算节点扩充计算性能,可提供梯度下降算法所需的大量计算资源,因此研究梯度下降算法在分布式集群上的并行化计算非常必要[8]。
目前,深度神经网络分布式训练中通常使用数据并行化方法,基于数据并行化的梯度下降算法包括同步随机梯度下降[9](Synchronized Stochastic Gradient Descent,SSGD)和异步随机梯度下降[10](Asynchronized Stochastic Gradient Descent,ASGD)两种算法。同步算法在每次迭代过程中通过同步各个节点的状态来保持状态一致,因此同步梯度下降能够保持和单机串行算法相同的收敛方向,从而导致其所需的通信量相对其他算法更多,容易受分布式集群中的通信瓶颈影响,同时计算节点之间需要相互等待传输梯度更新结果,从而造成了计算资源的浪费。异步算法则无需等待节点状态一致,每个节点在更新权值参数时不会检查其他节点的运行状态,独立地更新本地模型到全局模型上,并获取全局模型参数继续执行下一步计算,如果在该计算过程中又有其他节点更新了全局模型,那么该节点用于执行下一步计算的全局模型参数就不是最新的,该数据交互模式将导致梯度延迟问题[11-12],而梯度延迟问题又会导致每个节点用于执行下一步计算的全局模型不一致。在大规模分布式集群中,随着分布式集群中的节点数目增加,节点计算状态保持一致的概率越来越小,节点之间所需传输的信息量逐渐增多,因此无论同步或异步算法,都在大规模分布式集群中存在亟待解决的效率问题。本文提出基于分布式编码的同步随机梯度下降算法CSSGD,通过分布式编码策略[13-14]降低分布式集群上的通信负载。
1 相关工作
近年来,分布式并行梯度下降算法得到了广泛应用,研究人员针对分布式神经网络训练开展了大量研究工作,这些工作主要围绕分布式异构计算和通信负载两方面展开。分布式集群是典型的异构计算平台,在该异构计算环境下,每个执行进程的执行速度和任务完成时间均不确定,在同步梯度下降算法中由于系统需要同步每一批次中各个计算节点的状态,因此最慢节点的速度成为限制分布式集群整体任务运行速度的主要因素。文献[15-16]通过对每个节点的计算和更新过程进行限时,使每个节点都在已有样本上进行逐样本迭代计算,以保证每个节点都能在任意时间内给出一个可用但不完整的中间梯度运算结果,降低了节点异构对整体任务的影响。文献[17-18]针对大矩阵乘法的并行化问题,提出纠缠多项式码,使用纠缠多项式码对矩阵乘法运算进行拆解,并对原始矩阵计算任务添加一定量的冗余以加快运算速度。
此外,并行梯度下降算法还需在各个计算节点之间进行密集地数据交换,因此分布式集群的通信性能也是影响分布式神经网络训练性能的主要问题。文献[19]提出1-Bit 数值量化方案,使用Adagrad算法进行学习率迭代并结合误差累积回溯,在深度神经网络中得到一种低通信负载的分布式神经网络训练方案。文献[20]提出批次内并行化方法,使用较小的Block 划分和基于动量的参数迭代方案提高了分布式神经网络的训练速度。文献[21]提出改进的并行梯度下降算法,在改进算法中每个节点不再将本地计算结果推送给分布式集群中的所有节点,而是随机选取一部分节点进行更新以降低通信负载。文献[22]结合MDS 编码和分布式通信编码对分布式机器学习中的大矩阵乘法进行优化,有效解决了分布式系统慢节点和通信瓶颈问题,但其在编码过程中的冗余量较大。
上述文献分别从不同角度对分布式神经网络的训练过程进行分析与改进,然而在针对分布式通信瓶颈和分布式计算异构方面,使用量化或随机策略不可避免地会影响网络训练精确度,而利用MDS 码则会引入更多的通信冗余。本文设计一种用于同步梯度下降算法的分布式编码策略,能够降低分布式集群上的通信负载,并保证分布式神经网络的训练精确度。
2 本文同步随机梯度下降算法
梯度下降算法是用于求解目标函数最小值的常用优化算法,当网络模型参数为w、数据集为x和y、目标方程为F(w;x,y)时,计算公式如式(1)所示,迭代过程的计算公式如式(2)所示,其中,∇F(w;x,y)为目标函数的一阶导数,η为迭代步长,又称为学习率,t为迭代轮次。在分布式环境下,并行梯度下降算法在每个节点i上求其部分样本的梯度,计算公式如式(3)所示,最终汇总至全局模型参数w(t) 上的计算公式如式(4)所示。
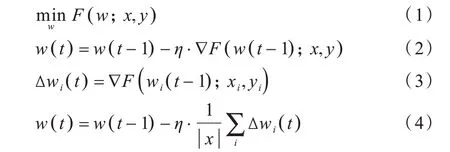
本文算法是同步梯度下降算法的一种改进形式,算法执行步骤为:1)将目标样本集合以预设批次大小进行划分,在添加冗余后将其平均分配到各个节点上;2)每个节点都在已有样本上执行反向传播算法,并对中间梯度结果进行编码,同时将中间梯度结果进行整合,实现数据分组交换;3)每个节点根据接收到的中间结果数据,解码出该节点所需的内容,继续执行训练过程。本文算法在任务分配时使用冗余分发策略,因此每个节点所需的中间结果数据可以从r个包含该数据的节点处获取,因此每个节点可以仅发送必要数据的1/r,由接收节点自行拼装完整结果,如图1 所示。同时,由于多个节点间存在冗余数据,因此一份数据可以被多个节点所共有,使用编码策略将需要发送的多个数据分片累加,将中间结果数据多播给多个节点,每个节点接收到累加结果后减去已知部分,即可得到所需部分的结果,如图2所示。本文结合上述两种策略并将其扩展至梯度矩阵信息交换过程中,提出能够有效降低梯度下降算法通信负载的方案。

图1 冗余分发策略Fig.1 Redundant distribution strategy
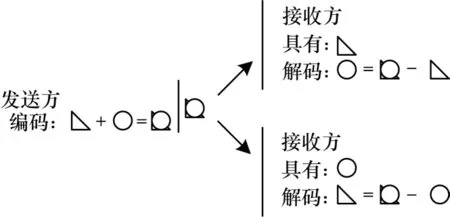
图2 编码策略Fig.2 Coding strategy
本文同步随机梯度下降算法的伪代码如算法1所示,具体过程为在给定的训练数据集F和迭代次数T的情况下获取当前最终模型参数wf。
算法1本文同步随机梯度下降算法

2.1 任务分配过程
本文设计一种任务分配算法,在有n个计算节点的集群上,将训练数据集F冗余r倍并平均分配到每个节点上,且每个节点上的样本组合不重复。上述分配过程可以描述为一个简单的排列组合过程,首先要实现r倍冗余的分配,且每个节点上的数据组合互不重复,需要将每个样本的r份拷贝发送到任意r个不重复的计算节点上。其次要实现每个节点上的样本数量一致,将要分配的样本集合划分为份,每一份样本子集都可以对应一个唯一的分发路径,依照组合结果进行分发,每个节点可以接收到(r⋅)个样本集合,完成任务的平均分配。任务分配算法的伪代码如算法2 所示,具体过程为在给定训练数据集F、分布式节点集合U和训练所用的批次大小b的情况下获取每个计算节点i的本地样本Di,其中,combinations(U,r) 返回U的r倍所有可能的组合结果,split_into_batch(F,b) 返回按照批次大小划分后的数据集,split(Fj,C.size)返回Fj平均分为C.size 后的结果集合。
算法2任务分配算法

为阐述算法2 的执行过程,首先定义分布式集群中所有节点的集合为U,如式(5)所示。取U的r倍组合结果记作C,如式(6)所示,在C中的元素个数为。

同样地,将训练样本按照输入的批次大小b划分为多个mini batch,并将每个mini batchFj平均分为份并记作P。将Pi和Ci一对一配对,依次将每个Pi发送至对应Ci表示的节点集合上。此时,每个节点上存在的待处理样本块个数为μ=r⋅/n,且每个样本被拷贝并发送至r个不同节点上。依照上述算法流程可将数据集F平均分配到N中的每个计算节点上,每个节点上的样本数据数目可根据节点的性能进行动态调整,且在一定限度内不会影响其他节点的负载。
2.2 编码过程
本文通过对中间结果矩阵进行编码,可压缩每个节点发送的数据量,同时实现数据多播以减少发送时间。由于在任务分配时使用冗余分发策略,因此每个节点所需的中间结果数据可以从r个包含该数据的节点处获取,因此每个节点可以仅发送必要数据的1/r,由接收节点自行拼装完整结果。同时,由于多个节点间存在冗余数据,因此一份数据可以被多个节点共有,使用编码策略将要发送的多个数据分片累加,将中间结果数据多播给多个节点,每个节点接收到累加结果后减去已知部分,即可得到所需部分的结果。上述编码过程可在不影响计算速度的情况下有效降低发送的数据量,一般情况下该过程可将数据量降低至朴素方法的1/n。
数据传输编码算法的伪代码如算法3 所示,具体过程为在给定所有中间结果矩阵的列表B、当前节点N和冗余度r的情况下获取中间结果集合C,其中,position_of(G,N)返回在编码过程中节点N获取梯度矩阵G的拆分子矩阵编号,block_id_of(G)返回用于计算G所使用的样本块编号,content_of(G,N)返回在编码过程中节点N应获取的对应G的拆分子矩阵,adversary_of(G)返回不具有G的所有节点,get_singularity(T)返回列表T中只出现一次的元素,pack(M,P,J,T)将内容M、P、J、T打包并等待发送。
算法3数据传输编码算法

按照算法3 的执行过程,定义编码的运算过程发生在节点Ni、神经网络层Ll、批次样本Fj和批次样本中的块Pq上,四元组(i,l,j,q)表示运算过程发生的环境,例如,在节点Ni和层Ll上批次为Fj且由全局编号为q的样本块计算所得的梯度记作G(i,l,j,q)。当某个对象的存在与某个下标对应的维度无关时,将其标记为数学中的任意符号∀,例如样本的存在与神经网络层数无关,因此在节点Ni上批次为Fj且全局编号为i的样本块记作F(i,∀l,j,q)。在样本块分发完毕后,每个节点在其接收到的样本块上执行前向传播和反向传播算法,计算以该样本块所得损失对网络参数w(i,l,j,q)的一阶梯度,一个块内所有样本的对应损失的梯度加和记作G(i,l,j,q)。
将节点Ni在任务分配阶段获得的μ个第j批次样本块在层Ll上计算得到的梯度矩阵记作G(i,l,j,∀),如式(7)所示。在B(i,l,j,∀q)中取r个元素进行组合,将包含个组合结果的结果集记作R(i,l,j,∀q),如式(8)所示。将R(i,l,j,∀q)中的组合结果记作,如式(9)所示。


图3 梯度矩阵按列拆分的示例Fig.3 Example for splitting a gradient matrix by column

将Ci中的节点下标编号aq进行升序排序,获取当前下标节点Nq在升序排列后的节点列表中的位置记作α,例如在节点组合{N1,N2,N3}中,节点N1对应的位置α=0,节点N3对应的位置α=2。获取位置信息αi并将其添加至组合结果拆分位置信息,同时将该块编号信息d添加至块编号信息。对应每个样本块都可获取一个该节点在该样本块分发列表中的位置αi,那么可以由上述数据求得,如式(12)所示。遍历编码所用的编码梯度矩阵G(i,l,j,∀q)求解Ai,如式(13)所示。叠加所有的Ai并获取其中仅出现一次的节点,将其添加至编码包的发送目标列表。

2.3 解码过程
根据编码时的累加结果和分片规则,解码时应按照编码时的运算过程反向求取节点所需的内容。首先通过减法减去节点已知的数据内容,求取未知的数据内容,然后按照分片规则,还原中间结果矩阵,以获取完整的中间结果。数据传输解码算法的伪代码如算法4 所示,主要功能为在给定所有中间结果矩阵列表B和接收到的编码数据包H的情况下输出矩阵切片(content)、切片编号(parts_id)和切片位置(parts_ position),其中,can_get(B,id) 判断节点是否包含样本块编号为id 所计算出的梯度矩阵,part_of(B,id,pos) 获取对应编号id 的样本块计算出的梯度矩阵的第pos 个拆分子矩阵。
算法4数据传输解码算法

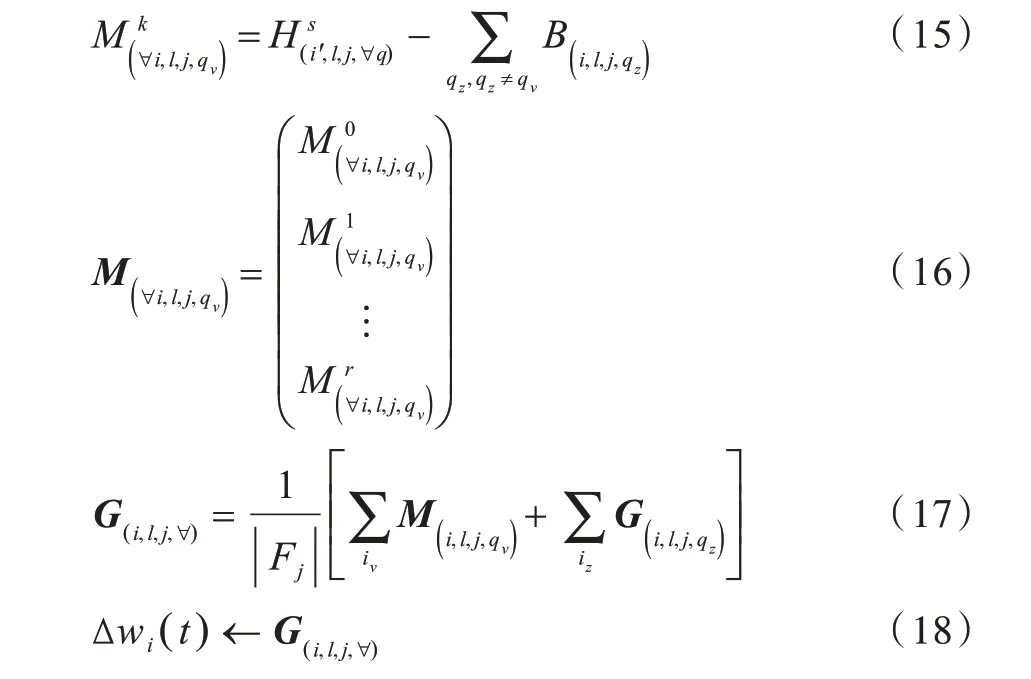
在编码包中已包含编码所用样本块编号和编码拆分矩阵的位置信息,依据发送规则可从编码包中提取节点Ni缺失的信息,将发送编码包给节点Ni的节点记作Ni,,将节点Ni,发送返回的信息记作。由于编码包中已包含样本块和拆分子矩阵位置信息,因此可利用节点Ni已有的信息解码未知信息,如式(15)所示。根据任务分配算法,将节点Ni缺失的样本块记作-μ,对应这些缺失样本所需的梯度中间结果记作G(i,l,j,qv),v=1,2,…,-μ。当节点Nq获取到所有缺失信息后,将其依照拆分规则进行合并,如式(16)所示。当节点Nq获取到所有样本块对应的缺失梯度时,使用式(16)和式(17)计算全局梯度,该全局梯度即进一步迭代所需的模型参数增量,如式(18)所示。
2.4 通信负载计算
若假设本文同步随机梯度下降算法的通信负载为Lcoding,传统不使用多播技术的梯度下降算法的通信负载为Lnormal,则两者存在式(19)所述的关系:

对上述关系进行证明,具体证明过程如下:使用编码策略进行任务分发和交换,节点数目为n,数据分配冗余度为r,每个划分占总批次大小为a1,a2,…,ap,其中p=,每个节点获取a1,a2,…,ap中的Dhave个样本块(如式(20)所示),并缺少其中的Dleft个样本块(如式(21)所示)。将节点i包含的所有样本块集合记作Di,如式(22)所示。

对于n个节点中任意r个节点组成的节点子集,其中一定存在1 个样本块被这r个节点所共有,因为样本块分发标签包含了所有节点编号可以形成的组合,所以任意r个节点必然属于种选择中的一个节点,如式(23)所示。同理,对于任意r+1 个节点组成的节点组至少存在个这样的样本块,如式(24)所示。在n个节点组成的集群中共有个节点组,每个节点组选取其中个样本块Dexchange进行数据交换,每个节点仅发送由样本块Dsend计算所得的数据,如式(25)、式(26)所示。

由于节点Ni完成所有分组交换后数据都不重复,因此其能够获得所有的Dleft中间信息,使用个节点组进行完全分组信息交换后,总的多播通信量如式(28)所示。对于具有同样冗余度的传统通信方式,每个节点所需通信量如式(29)所示,本文中的冗余度是指在同一样本块上进行计算的节点数量。对于不使用冗余策略的普通通信方式,每个节点缺少的数据是相互独立的,所需的通信量如式(30)所示。综上,式(19)所述的编码策略通信负载与传统方法通信负载之间的关系得以证明。

3 实验与结果分析
3.1 实验方法
本文通过神经网络对SSGD、ASGD和本文CSSGD算法进行分布式训练实验,对比在不同节点数目的情况下3 种算法到达指定训练精确度所需物理时钟时间和数据传输量,并利用集群模拟对上述指标进行实验验证,实验中共使用10 个计算节点,每个计算节点的配置信息如表1 所示。本文使用MNIST 和CIFAR-10数据集在卷积神经网络(Convolutional Neural Network,CNN)和DNN 上进行实验。表2 给出CNN 和DNN 在不限时单机执行环境下所得的测试精确度,以此测试精确度作为最优测试精确度,并在实验中对比3 种算法的测试精确度。
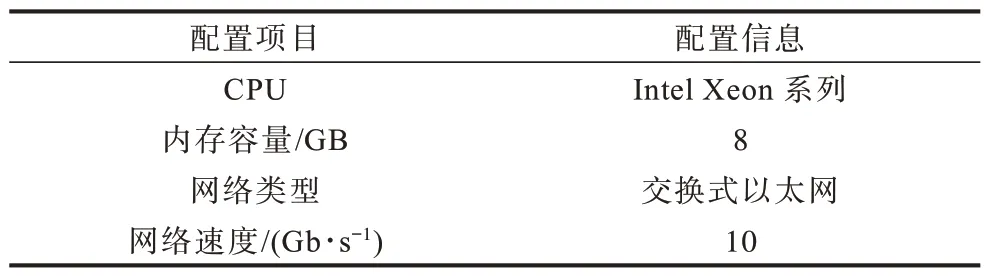
表1 计算节点配置信息Table 1 Configuration information of computing node

表2 实验数据集上的测试精确度Table 2 Test accuracy on the experimental dataset
为保证浮点数执行编码运算后的精确度,本文对计算产生的中间结果进行量化,使用32 位整型保存运算所需的浮点数据,设置中间结果区间为[-10,10],取0x7FFFFFFF 为10,取0x80000001 为-10,等区间划分取值,并使用该量化结果进行运算和编码。本文在实验中对不同节点的网络使用不同的样本划分,在2 个节点上只执行二分类,在3 个节点上只执行三分类任务,以此类推,保证每次测试时每个节点都能够执行相同数据量的任务,分析由通信瓶颈导致的性能损失问题,同时以串行算法测试所得结果作为目标精确度。
3.2 实验结果
本文首先对CSSGD 算法在DNN 与CNN 上的训练结果进行评估,然后使用SSGD、ASGD 和CSSGD 算法在MNIST 数据集上训练DNN、在CIFAR-10 数据集上训练CNN。在训练过程中,使用10 个训练节点(ASGD 算法额外使用一个参数服务器)并记录测试精确度的变化情况。由于CSSGD 算法的目的是减少训练执行时间,因此实验着重讨论3 种算法到达相同测试精确度的时间。
3.2.1 训练性能分析
DNN 和CNN 的训练结果如图4 和图5 所示,可以看出CSSGD、SSGD 和ASGD 算法在充足的训练时间下,均可达到最终的测试精确度。
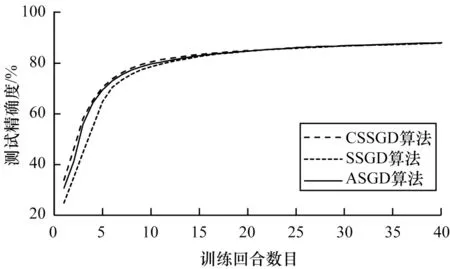
图4 利用CSSGD、SSGD 和ASGD 算法训练DNN 的测试精确度比较Fig.4 Comparison of test accuracy of training DNN with CSSGD,SSGD and ASGD algorithms

图5 利用CSSGD、SSGD 和ASGD 算法训练CNN 的测试精确度比较Fig.5 Comparison of test accuracy of training CNN with CSSGD,SSGD and ASGD algorithms
本节实验着重分析3 种算法训练所需的时间,在限定的测试精确度下比较算法执行所需的时间以评估算法执行效率。实验在CNN 和DNN 的原始训练结果中,在接近目标精确度附近选取一个相对3 种算法差异最大的基准测试精确度进行后续实验。如图6、图7 所示,对于使用MNIST 数据集的DNN,其选取的基准测试精确度为82%,对于使用CIFAR-10 数据集的CNN,其选取的基准测试精确度为70%。下文将针对这组基准测试精确度,比较3 种算法的执行效率。

图6 DNN 训练中的基准测试精确度Fig.6 Benchmark test accuracy of DNN training

图7 CNN 训练中的基准测试精确度Fig.7 Benchmark test accuracy of CNN training
后续实验从3 个方面详细分析了CSSGD 算法的执行效率:1)由于ASGD 算法无独占通信时间,因此在DNN 和CNN 训练过程中,对比使用CSSGD 与SSGD 算法在训练时间和通信总量上的差别;2)针对理论推导结果,通过实验验证不同冗余度设置下CSSGD 算法的每批次训练时间;3)使用相同的样本数据集和神经网络在上述集群环境下,对比ASGD、SSGD 和CSSGD 算法训练至基准测试精确度所需的训练时间。
3.2.2 DNN 实验结果分析
图8 展示了DNN 训练中SSGD 和CSSGD 算法在MNIST 数据集上达到82%测试精确度所需的时间,其中,SSGD Multicast 和SSGD Unicast 分别表示基于多播技术的SSGD 算法和基于单播技术的SSGD 算法,CSSGDr=2 和CSSGDr=3 分别表示冗余度为2 的CSSGD 算法和冗余度为3 的CSSGD 算法,可以看出CSSGD 算法能够有效降低SSGD 算法执行所需时间。图9 展示了DNN 训练中SSGD Multicast 和CSSGD 算法占用的网络数据通信总量,可以看出CSSGD 算法占用的网络数据通信总量相对SSGD 算法更少。
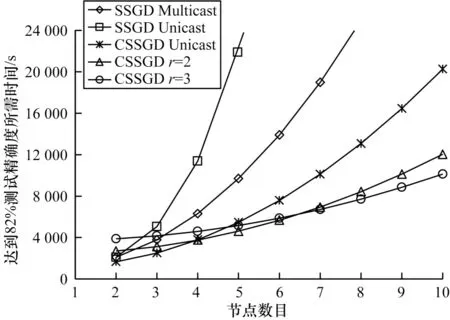
图8 在DNN 训练中SSGD 和CSSGD 算法达到基准测试精确度所需时间Fig.8 The time required for SSGD and CSSGD algorithms to reach benchmark test accuracy in DNN training

图9 在DNN 训练中SSGD 和CSSGD 算法达到基准测试精确度所需通信总量Fig.9 The total amount of communication required for SSGD and CSSGD algorithms to reach benchmark test accuracy in DNN training
3.2.3 CNN 实验结果分析
图10 展示了CNN 训练中SSGD 与CSSGD 算法在CIFAR-10 数据集上达到70%测试精确度所需的时间。在DNN 训练过程中产生的权值矩阵相对CNN 更大,容易由于网络速度限制造成计算瓶颈,如果对该类别网络使用CSSGD 算法,则可以有效缓解通信瓶颈问题。在CNN 中执行计算所需时间比DNN 更多,因此其对通信瓶颈的影响相对DNN 更小,在使用CSSGD 算法进行编码梯度下降时,其所能获得的测试精确度相对DNN 更低。图11 展示了CNN 训练中SSGD Multicast 和CSSGD 算法占用的网络数据通信总量,可以看出CSSGD 算法在CNN和DNN 训练中都能够有效降低中间结果的通信总量,但是CNN 计算中数据通信所占时间相较DNN更少,因此数据通信优化对总体执行性能的影响较小。

图10 在CNN 训练中SSGD 和CSSGD 算法达到基准测试精确度所需时间Fig.10 The time required for SSGD and CSSGD algorithms to reach benchmark test accuracy in CNN training
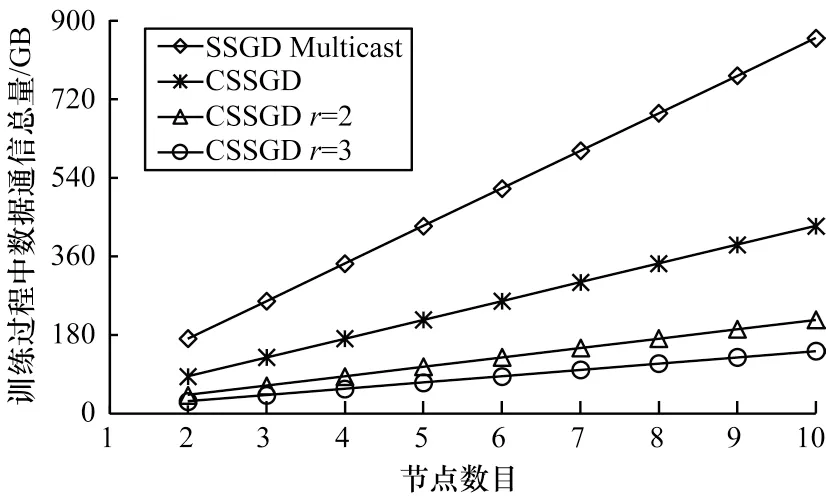
图11 在CNN 训练中SSGD 和CSSGD 算法达到基准测试精确度所需通信总量Fig.11 The total amount of communication required for SSGD and CSSGD algorithms to reach benchmark test accuracy in CNN training
3.2.4 冗余度分析
根据上文对编码过程的理论推导可以得出,当所需通信时间与数据通信总量呈线性相关时,CSSGD 算法单一批次训练所需时间TCSSGD可表示为每批次计算时间和每批次通信时间之和,假设SSGD 多播算法中一个批次计算所需时间为Tcalculate、中间结果传输所需时间为Tcommunicate,则TCSSGD可表示为TCSSGD=r·Tcalculate+1/r·Tcommunicate,可以看出,当Tcalculate和Tcommunicate为定值时存在一个确定的冗余度使得TCSSGD最小。本文在8 个计算节点的情况下对不同冗余度的CSSGD 算法单一批次迭代所需时间进行实验,结果如图12、图13 所示,可以看出在DNN 和CNN 训练中的最佳冗余度分别为3 和2。由实验结果可以得出和理论推导相同的结论,即在固定的计算时间和传输时间下,每个节点都存在确定的冗余度,当冗余度为r时整个分布式集群单一批次的训练时间最短。

图12 在DNN 训练中CSSGD 算法冗余度与单一批次训练时间的关系Fig.12 The relationship between the redundancy and the training time of single batch of CSSGD algorithm in DNN training
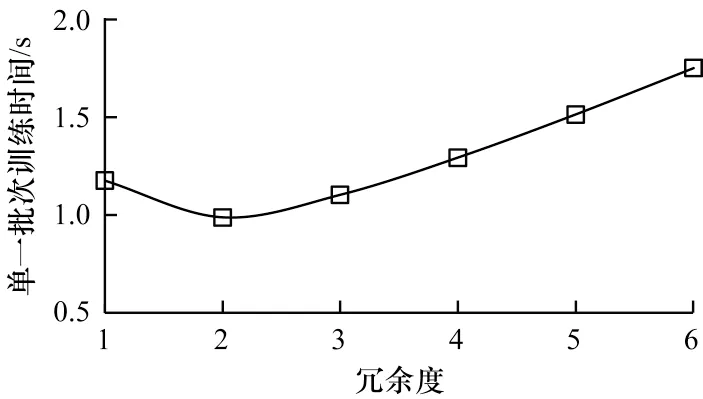
图13 在CNN 训练中CSSGD 算法冗余度与单一批次训练时间的关系Fig.13 The relationship between the redundancy and the training time of single batch of CSSGD algorithm in CNN training
3.2.5 训练时间分析
本节对比ASGD、SSGD Multicast和最优冗余度下的CSSGD(CSSGD Optimal)算法的实际训练时间,如图14 和图15 所示,由于ASGD 算法异步执行过程导致其执行状态难以确定,最终收敛所需次数也存在一定的随机性,因此对ASGD 算法进行10 次实验取训练时间的平均值。可以看出,在通信瓶颈问题较严重的DNN训练过程中,CSSGD 算法相对于SSGD 和ASGD 算法可取得明显的效率提升,在DNN 的分布式训练中,相对SSGD 和ASGD 平均能减少53.97%和26.89%的训练时间。在CNN 训练过程中由于计算执行过程占总执行时间的比例较高,因此通过添加冗余编码来降低通信负载的CSSGD 算法效率提升较少,但是ASGD 算法需要更多的计算开销来消除梯度延迟问题带来的干扰,因此CSSGD 算法相对SSGD 和ASGD 算法效率依然有一定的提升,在CNN 分布式训练中,相对SSGD 和ASGD 平均能减少39.11%和26.37%的训练时间。实验中给出10 个计算节点以内的训练时间结果,可以看出,ASGD 和CSSGD 算法在分布式系统上的性能不能随节点数目线性提升,随着节点数目的增多,ASGD 算法的理论同步更新概率会越来越小,迭代所需时间会继续增加,CSSGD 算法也会受到额外通信负载和多播带宽拥塞的影响,但是其在更多节点加入后可更新其最优冗余度参数配置,能够达到更好的训练效果。
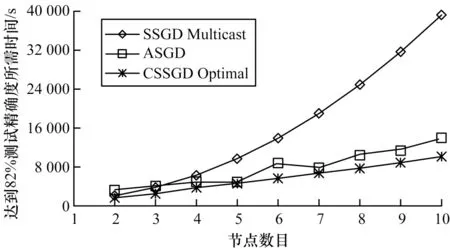
图14 在DNN 训练中SSGD、ASGD 和CSSGD 算法达到基准测试精确度所需时间Fig.14 The time required for SSGD,ASGD and CSSGD algorithms to reach benchmark test accuracy in DNN training
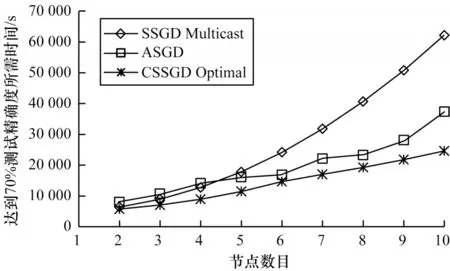
图15 在CNN 训练中SSGD、ASGD 和CSSGD 算法达到基准测试精确度所需时间Fig.15 The time required for SSGD,ASGD and CSSGD algorithms to reach benchmark test accuracy in CNN training
4 结束语
本文针对异步随机梯度下降算法的高通信负载问题,提出一种基于分布式编码计算的同步梯度下降算法,通过冗余分发策略降低通信负载并消除通信瓶颈对分布式集群的影响。实验结果表明,当配置合适的超参数时,与SSGD 和ASGD 算法相比,该算法在DNN分布式训练中能平均减少53.97%和26.89%的训练时间,在CNN 分布式训练中能平均减少39.11%和26.37%的训练时间,降低了分布式集群上的通信负载。下一步将研究并行梯度下降算法在分布式集群上的应用,并分析数值量化误差对最终损失函数收敛性能的影响。
