基于特征组分层与半监督学习的鼠标轨迹识别
2021-04-29康璐璐范兴容王茜竹杨晓雅
康璐璐,范兴容,王茜竹,杨晓雅,明 蕊
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆工商大学计算机科学与信息工程学院,重庆 400067;3.重庆邮电大学电子信息与网络工程研究院,重庆 400065)
0 概述
随着互联网行为式验证码技术的快速发展,以拖动滑块为代表的鼠标轨迹识别因其传输数据小、暴力破解难度大等特点,已经广泛运用于多种人机验证产品中。然而,攻击者仍可通过黑产工具产生的类人轨迹批量操作来躲避检测,并在对抗过程中不断升级其伪造数据以持续躲过同样升级的检测技术。因此,研究一种新型的鼠标轨迹识别技术来增强人机攻防识别性能,在保障网站抵御黑客攻击、用户恶意大规模访问与机器批量在线投票等方面具有重要的现实意义。
鼠标轨迹是用户在使用鼠标拖动滑块的过程中,经过采样获得水平方向、垂直方向和时间3 个维度的轨迹点集。鼠标轨迹时间序列数据相较传统时间序列具有以下6 个特点:多变量,即鼠标轨迹包括水平方向x轴、垂直方向y轴和时间t轴3 个维度;不规则采样,即由于网络延时等原因使得每个采样点之间的时长不同;长度不等,即由于鼠标轨迹采样间隔不确定,导致每一条轨迹的长度不等;变量之间存在关联性,即x、y、t3 个维度在时间和空间上存在关联性;数据不平衡,即人类轨迹样本数远多于机器轨迹样本数;标记样本少,即考虑到标记数据获取困难、标记代价高等问题,导致训练样本数量少。因此,鼠标轨迹识别可以看作一种特殊的时间序列二分类问题,同时也是一个典型的人机识别问题。
传统时间序列分类方法[1-3]不能直接用于鼠标轨迹的识别,如鼠标轨迹时间序列的长度不等,将会导致其不能直接作为传统时间序列分类方法的输入。虽然动态时间规整(Dynamic Time Warping,DTW)方法[4]能够处理长度不同的时间序列分类,但是由于鼠标轨迹序列的采样时间不等,因此不能进行准确的序列相似性判断。为此,本文对鼠标轨迹数据进行充分挖掘,从不同视角提取基础特征组和辅助特征组,提出一种基于特征组分层和半监督学习的鼠标轨迹识别方法。利用半监督随机森林算法对标记样本进行扩充,采用随机抽样改善数据不平衡问题,并通过将半监督随机森林算法与特征组分层策略相结合来提升鼠标轨迹的识别性能。
1 相关工作
目前,针对不规则采样与长度不等的时间序列分类问题主要有两类解决方法。
第一类是基于模型的方法,如文献[5]通过高斯过程(Gaussian Process,GP)后验重新表示每个时间序列,然后在GP 后验空间上定义核函数,并应用基于核函数的方法进行时间序列分类。文献[6]对肾小球滤过率时间序列进行自动分类,先采用高斯回归过程填补特殊时间序列的缺失值,并转换为长度相等的时间序列,再使用KNN/SVM 算法对其分类。文献[7]从单个时间序列中推导出时间连续的动力系统模型,并用推导出的模型表示时间序列,使用分类器对模型上的后验分布进行分类。上述研究在实验中均取得满意的效果,但这些方法都是基于二维时间序列,且没有提出针对数据不平衡以及标记样本量较少的处理方法,因此不适用于本文鼠标轨迹数据具有的多变量、变量之间存在关联性、数据不平衡与标记样本量少等实际情况。
第二类是基于特征的方法,该方法用一组特征来表征时间序列信息,从而解决时间序列不规则问题。如文献[8]提出一种基于特征的时间序列分类方法,该方法从时间序列中提取数千个可解释的特征,并使用贪婪前向特征选择方法选择出信息量最大的特征。文献[9]将时间序列预测与不同的特征选择相结合,实现一个更为简单的建模过程。针对鼠标轨迹识别的实际问题,目前国内外的研究都较少,且多数采用基于特征的分类方法。如文献[10]对提取的鼠标行为特征进行分析,证明了利用行为特征进行身份认证的可行性。文献[11-13]基于有监督学习构建出鼠标轨迹识别方法,利用轨迹信息分别构建特征工程,并采用梯度提升模型与朴素贝叶斯模型等模型进行人机识别,且取得较好的识别结果。但这些方法存在特征挖掘不充分且没有考虑类别不平衡等问题,使得模型的泛化性能较弱。文献[14]提出一种融合并行投票决策树和半监督学习的鼠标轨迹识别方法,该方法提取出105 个鼠标轨迹特征,采用基于半监督的策略与并行决策投票树的思想进行识别。然而,该方法仍然不能解决数据不平衡问题,且特征工程过于冗余,造成识别效果有限。
针对上述方法存在的特征挖掘不充分且鼠标轨迹数据存在标记样本少、数据不平衡等问题,本文提出一种基于特征组分层和半监督学习的鼠标轨迹识别方法。该方法通过构建有层次的鼠标轨迹特征组,描述用户滑动鼠标轨迹的移动规律,增加鼠标轨迹识别置信度。借鉴半监督学习的思想,利用多个随机森林模型对未标记样本进行伪标记,抽取标签预测一致且高置信度的部分样本加入到训练集合中,再基于基础特征组和辅助特征组,在扩充的训练样本集上重新训练随机森林算法,实现鼠标轨迹的人机识别。
2 背景工作
2.1 数据样本
本文的实验数据来源于某人机验证产品经过脱敏后的鼠标轨迹数据[15],其主要字段为唯一编号id、鼠标轨迹水平坐标x、鼠标轨迹垂直坐标y、鼠标轨迹采样时间t、轨迹目标点水平坐标xa和轨迹目标点垂直坐标ya。鼠标轨迹的数据字段说明如表1所示。

表1 鼠标轨迹数据字段说明Table 1 Field description of mouse trajectory data
2.2 特征提取
本文分别从描述人类轨迹特性和强化人机轨迹差异性的角度来提取基础特征组和辅助特征组。
2.2.1 基于人类轨迹特性的基础特征组
基础特征组是从基于人类鼠标轨迹特性的角度而构建的,这是因为人类轨迹特征具有较好的稳定性,且主要体现在以下3 个方面:
1)拟合过程:人们拖动滑块接近目标位置时存在拟合现象,会缓慢将滑块放到目标位置(拖拽速度逐渐变小),而机器轨迹速度则不会有明显的变化趋势。不同鼠标轨迹的水平移动速度如图1 所示。
2)无规律性:人类轨迹的移动偏移量是不停变化的,而机器轨迹受黑客程序控制,其偏移量一般有规律可寻,具体如图2 所示。
3)回退现象:人们在拖动滑块接近目标位置时,由于惯性会出现拖离目标点又重新拖动回来的现象,而机器轨迹到达目标点后则会立即停止,不存在回退现象,具体如图3 所示。

图1 人类轨迹与机器轨迹的水平移动速度Fig.1 Horizontal moving speed of human trajectory and machine trajectory

图2 人类轨迹与机器轨迹的水平移动偏移量Fig.2 Horizontal movement offset of human trajectory and machine trajectory
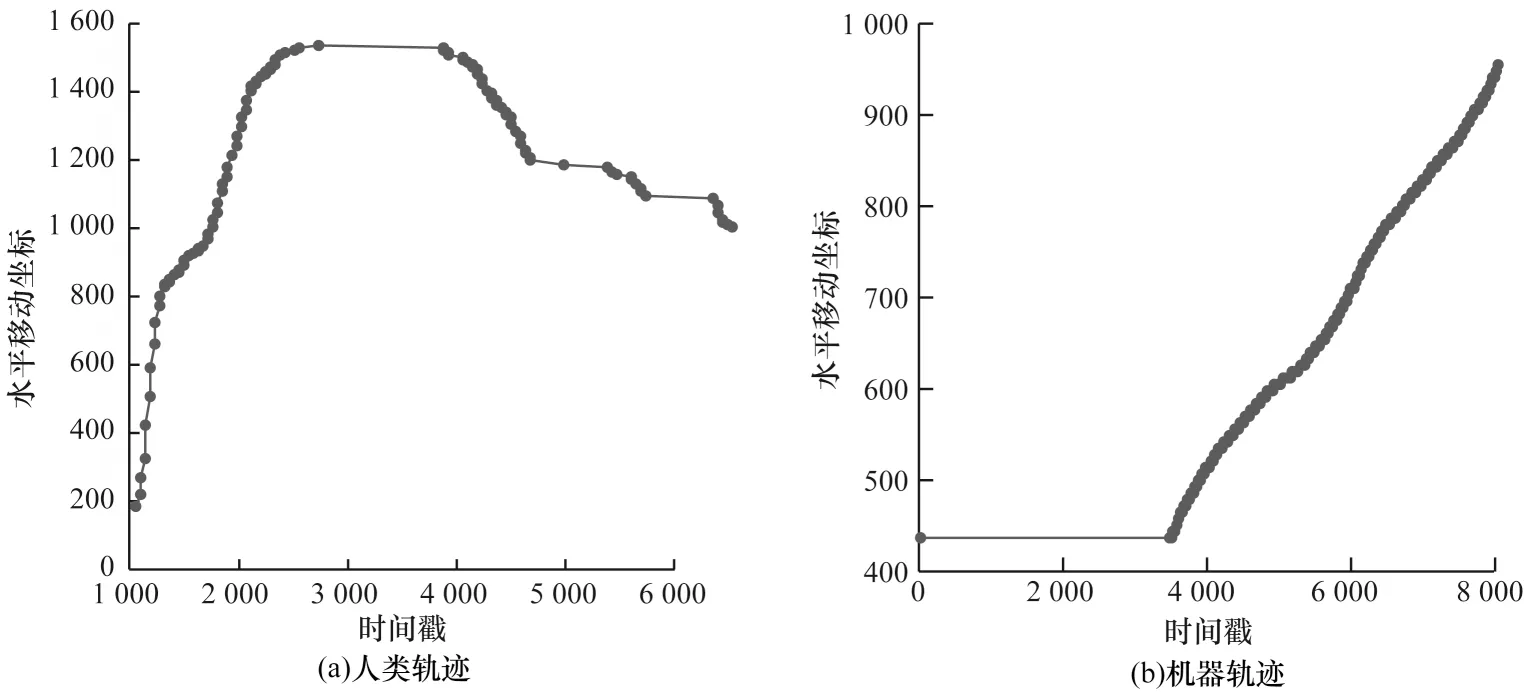
图3 人类轨迹与机器轨迹的回退现象Fig.3 Regression phenomenon of human trajectory and machine trajectory
基于上述规律,本文主要提取以下基础特征:
1)水平坐标最大值与目标值之差xovs和水平坐标最大值与最小值之差xdiffer。假设X=[x1,x2,…,xn]为轨迹水平坐标(n为鼠标轨迹采样点数),则有:

其中,xa为轨迹目标点的水平坐标,max(x)函数和min(x)函数用来返回数组的最大值与最小值。
2)水平坐标偏移量最小值dxmin和水平坐标偏移量标准差dxstd。假设dX=[dx1,dx2,…,dxn-1]为轨迹水平坐标的偏移量,则有:

3)回退轨迹(拖离目标点后重新拖动回来产生的轨迹,无回退轨迹则取轨迹后10 个点)水平坐标偏移量最小值和回退轨迹水平坐标偏移量中程数。假设为回退轨迹水平坐标(m为回退轨迹采样点数),为其偏移量,则有:
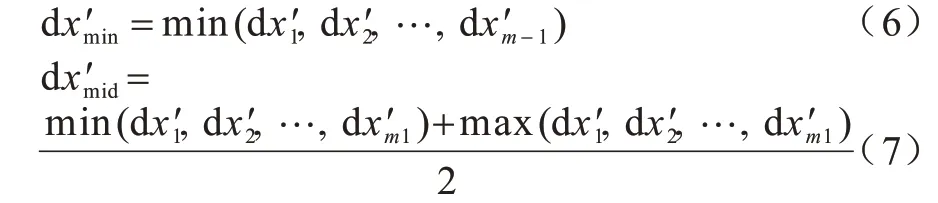
4)回退轨迹速度最大值和回退轨迹速度末尾值。假设为回退轨迹移动速度,则有:
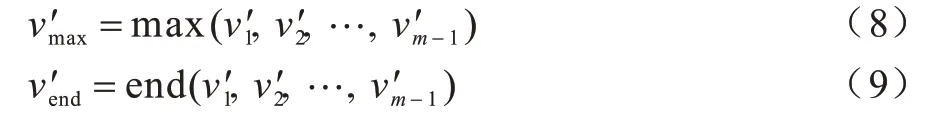
其中,end(v)函数用来返回数组末尾值。

2.2.2 强化人机轨迹差异性的辅助特征组
辅助特征组是从基于强化人机轨迹差异的角度而构建的,主要提取不明显的人机差异性,但在数据规模较大时依然不能忽略的特征(如y维度和t维度的特征)用于辅助判断,增加轨迹识别置信度。
1)垂直坐标最小值ymin和垂直坐标改变次数ychg。假设Y=[y1,y2,…,yn]为轨迹垂直坐标,则有:
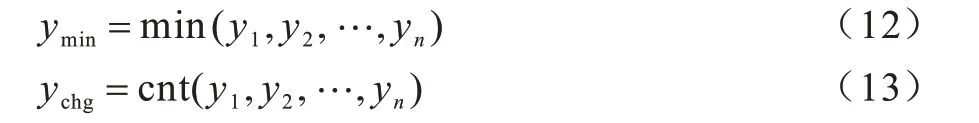
其中,cnt(y)函数用来返回数组中数据不重复的个数。
2)垂直坐标偏移量初始值dyinit。假设dY=[dy1,dy2,…,dyn-1]为垂直坐标的偏移量,则有:

其中,init(dy)函数用来返回数组初始值。
3)采样时间初始值tinit,采样时间中位数tmed和鼠标第一次移动到目标点所需时间taim。假设T=[t1,t2,…,tn]为轨迹采样时间,则有:

其中,ta为鼠标第一次移动到目标点的时间,median(t)函数用来返回数组中位数。
4)采样时间偏移量初始值dtinit。假设dT=[dt1,dt2,…,dtn-1]为时间的偏移量,则有:
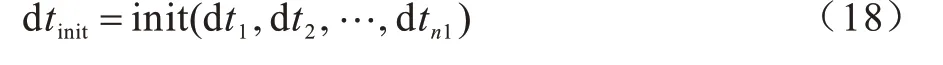
3 本文识别方法
本文提出一种基于特征组分层和半监督学习的鼠标轨迹识别方法。假设v=v1×v2为鼠标轨迹特征空间,其中v1和v2分别表示人类轨迹特性和人机轨迹差异性2 个视角。本文所提方法的实现框图如图4 所示。

图4 本文所提方法的实现框图Fig.4 Implementation block diagram of the proposed method
3.1 单视角随机森林分类器的训练过程
随机森林算法[16]具有训练速度快、模型泛化能力强以及可平衡误差等优势,因此本文采用随机森林作为基础分类算法。从v1视角提取特征构成标记样本集L,将标记样本以自助(bootstrap)采样的方式抽取N份,单独训练N个单视角随机森林分类器{R1,R2,…,RN},并使用这N个分类器对未标记样本U进行预测,其中任意一个分类器Ri对未标记样本的预测置信度和伪标签计算过程如下所示:
假设Ri中的单棵决策树fid(xu)=f(xu,θid),θid表示第d棵决策树构建过程中的随机因素(如特征的随机选择),单视角随机森林分类器Ri={fi1,fi2,…,fiD},D为决策树个数,则分类器Ri将样本xu预测为k类的概率为:

其中,pi,d(k|xu)为第d棵决策树中叶节点的类别预测概率。
样本xu的预测置信度定义为:

其中,C∈{0,1}表示样本类别集合。
样本xu的伪标签为:

3.2 单视角随机森林分类器的迭代过程
在单视角随机森林分类器的迭代过程中引入了半监督学习的思想[17-19],并将部分未标记样本加入标记样本中,利用新的样本重新进行分类器的训练。
假设{R1(xu),R2(xu),…,RN(xu)}为未标记样本xu在N个分类器上的表示形式,则样本在N个分类器上的伪标签和预测为该标签的置信度分别为:

由于对样本的伪标记正确与否对后续多视角随机森林分类器的识别性能起至关重要的作用,因此本文从伪标签和置信度2 个方面对未标记样本进行选择,即标记条件为:
1)样本在N个分类器中的伪标签一致,则pl1(xu)=pl2(xu)=…=plN(xu)。
2)样本在N个分类器中预测置信度大于阈值参数θ的个数至少有ε个,即countif(Conn(xu)≥θ(n=1,2,…,N))≥ε,其中countif 为计数函数,若满足括号内条件则再加1。
由于数据样本类别的不平衡性(人类轨迹远多于机器轨迹),如果将所有满足标记条件的未标记样本全部添加,可能会导致模型在第ω+1 轮更新后劣于第ω轮的模型。为了达到类别平衡的目的,按照标记样本类别之间的样本比率对未标记样本进行随机抽样,通过逐步缩小多数类别使得数据趋于平衡,具体抽样过程如下:
假设第ω轮迭代时标记样本集中人类样本和机器样本的比率为β,满足标记条件的未标记样本中人类样本B1和机器样本B2的数量分别为b1和b2,则有:

其中,′ 和分别表示人类样本和机器样本的抽样个数,和表示最终要扩充进标记样本的人类样本集和机器样本集,subsample(b,B)函数表示在B集中随机抽取b个样本。
将上述未标记样本及其伪标签加入到标记样本中,并从未标记样本中剔除。当进行分类器的迭代训练时直至满足迭代终止条件时停止。通过分类器的多次训练,逐步实现了标记样本的扩充,并改善了数据不平衡与标记样本量不足的问题。
3.3 多视角随机森林分类器的鼠标轨迹识别
经过多次迭代训练后,鼠标轨迹的标记样本集得到扩充,数据类别不平衡问题也得到改善,此时从v1×v2视角提取特征构成多视角随机森林分类器训练样本L′={(xi,yi,ci)}(i=1,2,…,|L′|),其中xi和yi分别表示从视角v1和视角v2中提取的基础特征组和辅助特征组,ci为类别标签,|L′|为标记样本和添加进的未标记样本的数量总和。可以看到此时样本的数量相比之前得到扩充,因此在特征中加入v2视角,并利用此样本集训练多视角随机森林分类器,最终实现鼠标轨迹的人机识别,且识别算法如算法1 所示。
算法1基于特征组分层和半监督学习的鼠标轨迹识别方法

3.4 使用R 对测试样本集T 进行预测
算法1 中的PseSample 为未标记样本中满足标记条件的样本抽样函数,MeasureError 函数的作用是估计R1&R2&…&RN组合的分类错误率。本文使用初始标记样本来计算分类错误率,假设该样本集中假设满足标记条件的样本有z个,其中有z′个的分类是正确的,则分类错误率e=(z-z′)/z。如果第ω+1 次迭代训练后模型的分类错误率小于第ω次,则继续迭代,从而保证模型向性能提升的方向更新。
4 实验设置和评价准则
4.1 实验设置
1)数据设置。本文数据来源于某人机验证产品经过脱敏后的鼠标轨迹数据,经过数据筛选后,共有103 000 条,其中人类轨迹82 600 条,机器轨迹20 400 条,数据比约为4∶1,可以看出数据类别存在不平衡现象。将其中3 000 条数据样本用于模型训练,其中标记样本比例选用20%,未标记样本的比例选用80%,100 000 条用于模型测试。
2)特征选择。实验共选取17 个特征,包含描述人类轨迹特性的基础特征组10 个,用f1~f10表示,强化人机轨迹差异的辅助特征组有7 个,用f11~f17表示。
3)仿真平台。本文采用MATLAB2017a 软件,在Windows7 64 位操作系统Intel i5 处理器的惠普电脑上进行实验测试。
4.2 评价准则
本文采用精确率P、召回率R与调和均值Fα作为模型的评价指标,计算方法如下所示:

其中,TP 为被正确识别为机器轨迹的样本数,FP 为被错误识别为机器轨迹的样本数,FN 为被错误识别为人类轨迹的样本数。
为保障网站抵御黑客攻击等网络安全问题,通常要求尽可能地识别出机器轨迹(即偏重召回率),以避免漏识别机器轨迹导致不可挽回的损失,但又不能使得用户验证体验太差(保证较高的精确率)。因此,在衡量人机轨迹识别性能时引入了调和均值Fα,其计算方法为:
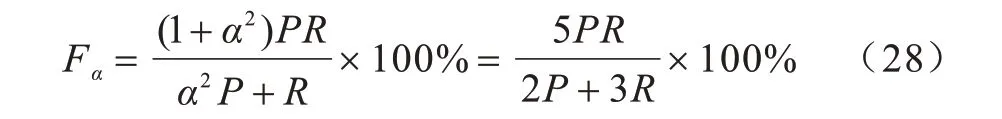
其中,α<1 表示合适的偏重召回率。
5 结果分析与讨论
5.1 不同特征的重要性分析
为评估不同特征对识别效果的影响,本文采用随机森林自带的评估特征重要性方法计算本文所提取特征f1~f17的重要性得分,结果如图5 所示。
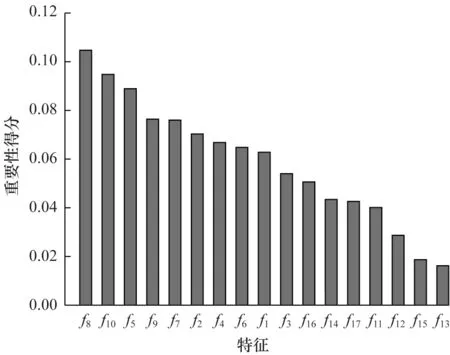
图5 本文提取特征的重要性得分Fig.5 Importance score of features extracted in this paper
从图5 可以看出,基础特征组f1~f10相较于辅助特征组f11~f17,其总体重要性得分更高,这是因为基础特征组是基于人类鼠标轨迹特性的角度去构建的,能够更好地区分人机轨迹,而辅助特征组主要用于辅助判断,增加轨迹识别置信度。
5.2 参数N 和θ 对识别性能的影响
文献[20]给出了随机森林分类算法中决策树各节点选取的特征个数mtry满足时,算法的性能最佳。其中,d为数据集的特征个数。在本文方法中,单视角随机森林分类器的参数mtry1=3、决策树个数ntree1=50,多视角随机森林分类器的参数mtry2=4、决策树个数ntree2=100。由于参数N和θ是影响本文算法性能的重要参数,因此通过对这2 个参数设置不同的取值进行实验来找到参数的最优值。
图6 给出了参数N和θ在不同取值下鼠标轨迹的识别结果。从图6 可以看出,当N=3,θ=0.8 时,本文方法在召回率、精确率和调和均值上都具有较好的性能。如果参数过大,则未标记样本得不到充分利用,并且无法解决数据不平衡、标记样本不足的问题。如果参数过小,则会导致训练样本中引入过多的噪声数据,极大影响最终的识别效果。

图6 参数N 和θ 对识别性能的影响Fig.6 Effect of parameters N and θ on recognition performance
5.3 方法性能分析
5.3.1 特征组分层有效性分析
为了验证本文提出的特征组分层对鼠标轨迹识别性能的影响,实验分别比较了引入特征组分层和不引入特征组分层这两种方式下的识别性能,结果如表2 所示。可以看出,引入特征组分层时模型的精确率、召回率和调和均值较不引入时分别提高了6.4、11.27 和8.5 个百分点,这说明在半监督学习的基础上引入特征组分层在鼠标轨迹识别中能够有效提高模型的识别性能。

表2 特征组分层有效性分析结果Table 2 Analysis results of hierarchical effectiveness of feature group %
5.3.2 方法运行时间分析
表3 给出了参数N在不同取值下本文方法的训练耗时和测试耗时结果。可以看出,随着分类器个数N的增加,测试耗时相差不大,但训练耗时逐渐增加。因此,本文方法需要选取合适的N值,在保证分类性能的同时降低运行时间。

表3 分类器个数对本文方法运行时间的影响Table 3 Effect of the number of classifiers on the running time of the proposed methods
5.3.3 方法对比分析
实验将本文所提方法与基于朴素贝叶斯的鼠标轨迹识别方法[11]和基于梯度提升决策树的鼠标轨迹识别方法[12]在同一数据集上进行性能对比,结果如表4 所示。其中,文献[11]提取8 个特征,并使用加权朴素贝叶斯模型实现人机识别,文献[12]提取6 个轨迹特征,使用梯度提升决策树模型对鼠标轨迹进行识别。由于这2 种方法都采用监督学习,不涉及未标记样本的使用,因此在训练模型时只采用训练集中的标记样本。

表4 3 种鼠标轨迹识别方法的性能对比Table 4 Performance comparison of three mouse trajectory recognition methods %
从表4 可以看出:本文方法的精确率、召回率和调和均值较文献[11]分别提高8.32、12.37和10.06个百分点,较文献[12]分别提高6.1、16.59 和10.8 个百分点。造成上述结果主要有以下2 个原因:1)文献[11-12]没有对轨迹特征进行充分挖掘,使得轨迹特征不能完整地刻画人机轨迹;2)本文方法采用半监督学习策略,充分利用了大量未标记样本提升模型性能,且通过随机抽样改善数据不平衡现象,而文献[11-12]采用有监督方法,未考虑鼠标轨迹数据不平衡和标记样本量少的实际情况,造成最终识别性能较低。
6 结束语
本文提出一种基于特征组分层和半监督学习的鼠标轨迹识别方法,该方法从特征和数据2 个层面对鼠标轨迹识别方法进行改进。在特征层面,根据不同视角特征在不同阶段所起的作用构建出有层次的特征组并分层添加至模型中,避免在训练样本数量过少的情况下盲目添加特征而造成模型过拟合问题。在数据层面,利用半监督学习方法扩充训练样本,解决数据类别不平衡、标记样本量不足的问题,并通过将两者融合实现提升鼠标轨迹识别效果的目的。实验结果表明,本文方法能够有效提升鼠标轨迹识别任务的性能。针对未来黑客攻击呈现方式多元化的问题,下一步将采用深度学习动态提取特征,以应对黑客攻击方式的转变。
