基于可分离残差卷积与语义补偿的U⁃Net 坝面裂缝分割
2021-04-29冯春成李林静
庞 杰,张 华,3,冯春成,3,李林静
(1.特殊环境机器人技术四川省重点实验室,四川绵阳 621000;2.西南科技大学信息工程学院,四川绵阳 621000;3.清华四川能源互联网研究院,成都 610213)
0 概述
水利枢纽是修建于河道中多类水工建筑物的综合体,其具有防洪、供水、发电和航运等功能,在保障与促进社会经济发展中起到重要作用[1-2]。受工程建设水平和所在地的地质、水文以及气象等因素影响,水利枢纽中混凝土坝面易形成裂缝、脱落等缺陷[3]。通常采用缺陷检测技术分析坝面缺陷,在此基础上对水利枢纽进行维护,以确保其处于良好的工作状态。因此,坝面缺陷检测对溃坝防范和防震减灾具有重要意义[4]。
目前水利枢纽的坝面缺陷检测以人工巡检为主,存在耗时长、危险性大和成本高等问题。随着人工智能技术的不断发展,自动化水平较高的巡检设备及安全评估系统[5]成为未来水利枢纽维护系统发展的必然趋势。近年来,随着以卷积神经网络(Convolutional Neural Network,CNN)为代表的深度学习技术的迅速发展,基于计算机视觉的分类、检测和分割方法应用日益广泛[6]。针对建筑物表面缺陷检测,文献[7]提出一种基于深度卷积网络的道路裂缝分类方法,对分辨率为99 像素×99 像素的彩色图像进行准确分类。文献[8]使用基于Faster-RCNN 的缺陷检测方法,实现对混凝土裂缝、钢筋腐蚀面以及螺栓腐蚀面的分层检测与分类。文献[9]利用全卷积网络(Fully Convolutional Network,FCN)在彩色图像上分割出裂缝缺陷,获得精确的裂缝路径和形态信息。与传统分割算法相比,卷积神经网络能自动提取与任务相关的鲁棒特征,实现端到端的自动缺陷检测。
水利枢纽的混凝土坝面由于长期被水冲刷渗蚀,其图像数据存在严重的亮度不均衡、相似干扰噪声大、背景复杂以及裂缝前景与背景在像素数量上不均衡等问题,造成坝面裂缝分割较困难。由于U-Net[10]网络具有的对称式编解码结构可融合卷积网络低维和高维特征,保证输入和输出分辨率一致,具有较高分割精度,因此本文将U-Net 网络应用于水利枢纽的混凝土坝面裂缝图像分割,并根据坝面图像特点对其进行改进,提出一种基于可分离残差卷积和语义补偿的裂缝分割方法。在U-Net 网络的编码端构建大尺寸卷积核的可分离残差模块增大特征层感受野,在解码端设计语义补偿模块弥补不同层级特征的语义差异,使用焦点损失作为类间损失,增大裂缝前景的损失权重并提高对困难样本的注意力,同时增加中心损失缩小类内特征间距,以提高网络对像素的分类准确度。
1 坝面裂缝分割方法
本文提出的坝面裂缝分割方法在U-Net 网络基础上进行改进,改进后的U-Net网络结构如图1 所示。该网络由全卷积网络构建的编码和解码两部分组成。编码部分利用1 个传统的初始卷积模块和4 个可分离残差卷积模块逐级对前一层输出进行卷积处理,每个卷积模块由多个卷积(Conv)层组成,每个卷积层包含卷积核、批归一化(Batch Normalization,BN)层及ReLU 激活函数,通过最大值池化生成5 层不同尺度的语义特征。解码部分先利用语义补偿模块对每层特征进行补偿,再逐级与反卷积扩大尺寸后的输出特征进行拼接,并通过传统卷积模块得到后续输出,最终利用Sigmoid 函数得到与输入图像分辨率一致的像素级裂缝类别概率图。

图1 改进U-Net 网络结构Fig.1 Structure of improved U-Net network
1.1 可分离残差卷积模块
增加特征提取骨干网络层数、设置适当大小感受野的卷积核以及减少网络参数量与复杂度,在不降低网络效率的同时可更有效地提取特征[11]。本文基于空间可分离卷积[12]思想,在编码端设计一种感受野大小为7×7 的可分离残差卷积模块替换传统2 层3×3 卷积核的卷积模块,在扩大感受野的同时减少计算量,如图2 所示。利用残差结构[13]将卷积前底层边缘特征与卷积后高层语义特征相结合,可降低卷积层中零填充操作引入的边缘噪声干扰。

图2 传统卷积模块和可分离残差卷积模块结构Fig.2 Structures of traditional convolutional module and separable residual convolutional module
在图2 中,输出卷积核通道数为N,输入特征通道数为N/2,可分离残差卷积模块与传统卷积模块的感受野相同。每个卷积层参数量的计算公式为:

其中,kw和kh为卷积核尺寸。传统卷积模块和可分离残差卷积模块结构的参数量分别为3N+13.5N2、4N+8N2,U-Net 网络原有的2 层卷积模块参数量为2N+9N2。由此可见,可分离残差卷积模块参数量更少,其具有更多卷积和激活等非线性操作,能赋予编码端特征提取网络更好的非线性能力。
1.2 语义补偿模块
U-Net 网络在解码过程中可实现多尺度特征相互融合,并将深层语义特征与浅层细节特征相结合。然而不同尺度的特征在经过多次卷积池化操作后,会有一定语义与细节特征差异,且层级差异较大的特征层之间特征差异更大,若直接进行特征拼接则会限制最终的分割结果[14]。因此,本文设计一种语义补偿卷积模块分别对不同尺度特征进行补偿,如图3 所示。

图3 语义补偿卷积模块结构Fig.3 Structure of semantic compensation convolutional module
语义补偿卷积模块是由一定数量的3×3 卷积层及一个1×1 卷积层组成的残差结构,各层步长均为1。其中,3×3 卷积层为语义特征补偿单元,1×1 卷积层为边界特征保留单元,可分层级补偿语义特征并防止边界特征丢失。使用补偿单元与保留单元提取高层特征,并在解码过程中逐层增加补偿单元,将上述特征在拼接特征层经过语义补偿与保留边界特征后进行线性叠加,再与前序特征拼接融合。
1.3 混合损失函数
语义分割网络通常使用交叉熵等类间函数计算输出与标签之间每个像素的差异,并以所有像素差异的平均值作为训练模型的目标损失函数。
在水工建筑物坝面裂缝图像分割的二分类任务中,裂缝前景与背景图像的像素数量严重不均衡导致背景损失占比较大,模型在训练过程中会更注重背景识别,从而降低对裂缝的识别性能。此外,坝面裂缝图像背景中存在大量与裂缝相似的复杂干扰噪声,在模型训练过程中会产生较多困难样本,例如将裂缝识别为背景或将背景识别为裂缝等。针对该问题,本文使用焦点损失函数[15]和中心损失函数[16]分别作为类间损失函数和类内损失函数,使模型学习到更紧凑和中心化的输出概率特征值。将混合损失函数定义为:

其中,Lf(P,Y)为焦点损失函数,Lc(P,Y)为中心损失函数,P和Y分别为训练图像通过分割网络输出的概率特征图和真实标签,λ为中心损失的权重,在本文中λ设置为1。
1.3.1 焦点损失
在原有交叉熵损失的基础上增加两个调节参数α和β,将其作为坝面裂缝分割的焦点损失函数,相关定义如下:

其中,m为所有像素的个数,y为第i个像素的标签信息。
假设1 为裂缝、0 为背景,则标签为裂缝(y=1)而识别为背景(p<0.5)或者标签为背景(y=0)而识别为裂缝(p≥0.5)的像素为困难样本,标签和识别结果全为裂缝或者全为背景的像素为简单样本。(1-p)β及pβ分别为裂缝和背景两类像素的困难样本权重,本文增大困难像素样本权重并减小简单像素样本权重,设置β=2[15]。1-α与α分别为背景及裂缝的像素占比,通过赋予不同类型像素的损失权重来平衡两类像素数量,并根据计算得到的裂缝及背景像素数量比例,设置α=0.01。
1.3.2 中心损失
由于训练数据与测试数据的分布不一致,仅使用类间损失函数作为训练目标函数,尽管可实现测试集输出的特征类间可分,但同类样本输出的特征分布是离散的,仍存在误判的困难像素样本。因此,本文在以焦点损失为类间损失的基础上增加中心损失作为类内损失,从而得到更紧凑的输出特征,中心损失函数定义如下:
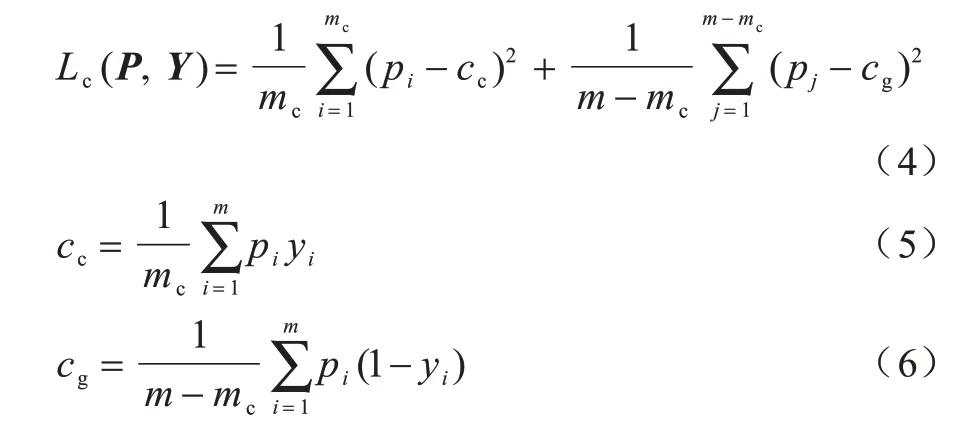
其中,mc是标签为裂缝的像素数量,m-mc是标签为背景的像素数量,cc是标签为裂缝的像素所得预测概率的均值中心,cg是标签为背景的像素所得预测概率的均值中心。每批次训练迭代均需重新计算上述两个均值中心。
2 实验与结果分析
为验证上述坝面裂缝分割方法的有效性,本文进行一系列消融实验分别评估可分离残差卷积模块、语义补偿卷积模块以及混合损失函数的性能,再与主流的图像分割方法进行对比分析。
2.1 实验数据集
由于目前无公开的水工建筑物坝面裂缝图像数据集,本文利用清华四川能源互联网研究院提供的中国西南部某大型水电站坝面图像数据自制水工建筑物坝面裂缝图像数据集。该数据集含有1 000 张图像,每张图像分辨率为608 像素×608 像素,所有裂缝像素区域均由人工标注完成。从该数据集中随机抽取200 张图像作为测试集,其余800 张图像作为训练集。
2.2 实验环境
本文实验采用Intel i7-7700K CPU@4.20 GHz 处理器,NVDIA GTX TITAN XP 25GB GPU,16 GB内存,Ubuntu 16.04 操作系统,Python 3.6 编程语言,Pytorch 1.3 和CUDA 10.0 深度学习框架。在训练过程中采用Adam 梯度下降法,优化器的学习率设置为0.000 1,批处理大小为4,取测试集平均损失值最小的模型作为最终模型。在训练和测试过程中,将概率值不小于0.5 的像素识别为裂缝前景,其他像素为背景。
2.3 训练图像的预处理
针对坝面图像的亮度不均衡、对比度差异明显以及背景干扰噪声复杂等特点,本文在模型训练过程中使用水平翻转、亮度及对比度随机调整、几何形变3 种方法随机组合对每批训练图像及标签进行预处理,每种方法独立进行,使用概率均为0.5。上述方法可在不增大数据集规模的同时增加训练集的多样性,从而提升分割模型的泛化能力。
2.3.1 亮度及对比度随机调整
使用灰度平均值u及均方差σ描述图像X的亮度及对比度,其表达式如下:

其中,xi为第i个像素的灰度值,m为像素数量。
为保证调整后图像与原图像具有较显著的差异性,生成变换系数η,其表达式如下:

为增强调整后图像的随机性,将255η与2η作为正态分布曲线的平均值与标准差,生成服从该分布的亮度值及对比度值2ησ。调整后的图像表示为:

其中,ε为一个极小值常数。服从正态分布的参数可使调整后图像的数据分布具有一定随机性,且与原图像差异较大。
2.3.2 几何形变
基于裂缝区域的不规则性,使用几何三角函数对所训练图像中每个像素的位置进行变换,可达到形变效果。几何形变方式定义为:
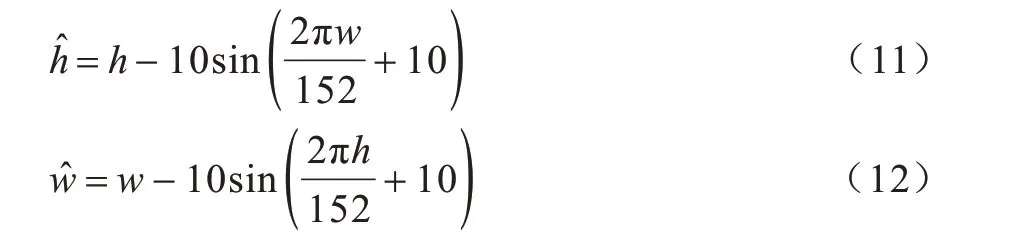
其中,h、、w和分别为形变前后的坐标位置。
3 种预处理方法的效果示例如图4 所示。图4(a)以网格图的形式描述了几何形变的预处理过程,图4(b)为原始数据图像经过水平翻转、随机亮度及对比度调整、几何形变3 种预处理前后的图像,图4(c)为原始数据图像对应的标签图像同样经过3 种预处理前后的图像。

图4 预处理前后的效果图Fig.4 Effect images before and after preprocessing
2.4 评价指标
本文实验分别采用准确率(PA)、召回率(Rc)、F1值和交并比(Intersection over Union,IoU)评价不同方法的裂缝分割性能[17],其中F1 值与IoU 为语义分割实验中综合度量指标。上述指标分别定义如下:

其中,TP 为正确预测为裂缝的像素个数,FP 为错误预测背景为裂缝的像素个数,FN 为错误预测裂缝为背景的像素个数。
2.5 训练过程分析
图5 为本文提出的坝面裂缝分割模型(以下称为本文模型)在训练过程中训练损失值与验证损失值的变化情况。可以看出,本文模型在训练过程中的损失值迅速衰减,并在迭代80 轮后趋于收敛。由此可知,该模型未出现过拟合现象,具有良好的泛化性能。

图5 本文模型在训练过程中的损失衰减曲线Fig.5 Loss attenuation curve of the proposed model in the training process
2.6 消融实验
在U-Net 网络基础上,逐个添加可分离残差卷积模块、语义补偿卷积模块、焦点损失函数及中心损失函数,将本文方法与上述方法的裂缝分割性能进行对比,结果如表1 所示。可以看出,本文方法针对坝面图像提出的一系列措施均能提高裂缝分割性能,本文方法的F1 值及IoU 较U-Net 网络分别提高1.32 个百分点和1.54 个百分点。

表1 不同方法的裂缝分割性能对比结果Table 1 Crack segmentation performance comparison results of different methods %
本文进一步对类内中心损失函数的有效性进行评估,图6 为表1 中实验4 和实验5 训练所得模型对相同测试图像输出概率值的分布密度曲线。可以看出,仅使用焦点损失函数的网络输出概率值分布较离散,且具有更多的像素输出概率值分布在0.5 左右,仍有较多的困难像素样本,而增加中心损失函数的网络输出概率值分布更集中,聚集于0.75 左右的极点两侧,处于0.5 左右的困难像素样本数量明显减少。由上述结果可知,中心损失函数不能有效增大类间的差异性,且降低了裂缝像素输出概率值的中心平均值。结合表1 的分析结果可知,焦点损失函数+中心损失函数较焦点损失函数的F1 值及IoU 分别增加0.44 个百分点和0.52 个百分点,表明中心损失函数能有效缩小类内像素输出概率特征值的差异,提升对困难像素样本的识别性能。

图6 不同模型的输出概率值分布密度曲线Fig.6 Output probability value distribution density curves of different models
由上述实验结果可知,改进前U-Net 的各项评价指标均低于改进的各个裂缝分割方法。其中,综合指标F1 值及IoU 随着改进措施的增加而提升,说明本文提出的各项改进措施能有效提升裂缝分割性能。
2.7 与其他网络的对比
将本文方法与改进前U-Net 方法以及SegNet[18]、FCN-8S[19]及DeepLab V3[20]3 种经典裂缝分割方法进行对比。其中,SegNet 利用末级单层特征层进行图像分割,FCN-8S 基于跳接结构将末端3 层特征融合后进行图像分割,DeepLab V3 使用空洞卷积及空间金字塔池化模块进行图像分割。上述方法的部分裂缝分割效果与评价指标结果分别如图7 和表2 所示。可以看出,SegNet 和FCN-8S 的裂缝分割效果较差,DeepLab V3及U-Net的裂缝分割效果稍好且U-Net优于DeepLab V3,本文方法的裂缝分割效果最佳。本文以U-Net 为基础网络,通过一系列改进措施有效提升了对包含细小裂缝区域的困难样本的识别性能,本文方法对坝面裂缝的分割效果较其他方法更优。

图7 不同方法的部分裂缝分割效果图Fig.7 Partial effect images of crack segmentation with different methods

表2 不同方法的裂缝分割指标结果Table 2 Crack segmentation index results of different methods %
3 结束语
针对坝面图像在复杂环境下存在的像素不均衡、干扰噪声大等问题,本文基于改进U-Net 提出一种坝面裂缝分割方法。在U-Net 网络编码端使用可分离残差卷积模块增大感受野,在解码端增加语义特征补偿模块改善特征融合效果,将焦点损失函数及中心损失函数作为目标函数提高对裂缝前景像素与困难样本像素的注意力,采用几何形变以及图像亮度和对比度随机变换的方法对训练的图像进行预处理。实验结果表明,本文方法较改进前U-Net的F1 值和交并比分别提高1.32 个百分点及1.54 个百分点,分割效果较SegNet、FCN-8S 等传统方法更优。后续将精简分割模型减少参数量,进一步提高该方法的检测实时性。
