基于舌象参数与多指标特征联合的2型糖尿病风险预测模型*
2021-04-25胡晓娟屠立平崔龙涛陈清光许家佗
李 军,胡晓娟,屠立平,崔龙涛,陈清光,陆 灏,许家佗△
(1. 上海中医药大学基础医学院,上海 201203; 2. 上海中医药大学上海中医健康服务协同创新中心,上海 201203; 3. 上海中医药大学附属曙光医院,上海 201203)
糖尿病属于中医学“消渴”范畴,其基本病机为阴虚为本、燥热为标,日久可生痰饮、瘀血等变证。望舌是中医辨证的重要环节,具体到糖尿病中病患舌色往往偏暗。燥热及痰湿偏盛时舌苔黄厚,阴虚为主时舌红苔少[1]。目前随着舌诊客观化技术研究的深入开展,舌的颜色、纹理等特征均得以量化,可以进一步提高中医临床诊断糖尿病的准确性,同时为糖尿病风险预测、疗效评价提供有力的技术支持。
糖尿病的发生与肥胖症和脂代谢异常高度相关,肥胖症患者体内脂肪分解增加,血中游离脂肪酸浓度增高,通过脂肪酸-葡萄糖循环诱发胰岛素抵抗,削弱胰岛素的降血糖作用[2]。基本生理指标包括身高、体质量、腰围、臀围、体质量指数、腰臀比、腰高比等,测量经济、方便、快捷,可以从多个角度反映肥胖人群的代谢情况,这些基本生理指标已被广泛应用于糖尿病风险预测。目前糖尿病患者逐年增加,预计到2030年全球糖尿病患病人群将达到3.5亿,因此早期识别糖尿病患者以及糖尿病患病风险增加的人群成为亟待解决的问题。
糖尿病风险预测模型可以早期敏锐感知人群患病风险,及时提供治疗及改变生活方式方面的建议,对于改善患者预后及控制医疗支出大有裨益。虽然人们设计了多种糖尿病风险预测模型,但是缺乏实用性、设计欠合理等限制了模型的推广应用[3]。随着医学与计算机科学交叉研究的深入,基于机器学习技术建立疾病风险预测模型逐渐成为研究重点。本研究探索基于舌象参数,使用机器学习算法建立糖尿病风险预测模型的可行性。所选用的4种机器学习领域的经典算法均在数据挖掘领域应用广泛,其中逻辑回归使用logistic sigmoid函数将输出转换为概率值,使其可以映射到两分类或者多分类中;人工神经网络具有生物特征,利用激活函数来简化和模仿人脑的神经细胞活动特点进行分类计算;支持向量机致力于寻找一个平面,从而实现对于高维数据的分类;朴素贝叶斯算法根据贝叶斯公式计算出分类对象的后验概率,取其中最大者作为该对象的类。本研究通过收集糖尿病前期人群和糖尿病患者的基本生理指标、糖脂代谢、舌象参数的统计学变化规律,在此基础上运用机器学习技术建立2型糖尿病风险预测模型,并评价舌象参数特征与基本生理指标联合预测2型糖尿病及糖尿病前期风险的能力,现介绍如下。
1 资料与方法
1.1 一般资料
收集2011年1月至2015年1月宝山社区卫生服务中心的体检人群共852人,其中符合要求的糖尿病受试者119例,男性45例,女性74例,平均年龄63(58、69)岁;糖尿病前期受试者491例,其中男性166例,女性325例,平均年龄62(58,68)岁;血糖正常对照组242例,其中男性88例,女性154例,平均年龄60(57,65)岁。3组性别构成比较差异无统计学意义(P>0.05),年龄差异有统计学意义(P<0.01)(表1)。本次研究已获得上海中医药大学附属曙光医院伦理委员会批准(伦理学批号2018-626-55-01),患者签署知情同意书。
1.2 诊断标准
1.2.1 糖尿病诊断标准 参考《实用内科学》及美国糖尿病协会糖尿病诊疗指南提到的最新诊断标准:空腹血糖≥7.0 mmol/L和(或)餐后2 h血糖≥11.1 mmol/L和(或)糖化血红蛋白≥6.5%[4]。
1.2.2 糖尿病前期诊断标准 空腹血糖<7.0 mmol/L且≥6.1 mmol/L和(或)餐后2 h血糖<11.1 mmol/L且≥7.8 mmol/L和(或)糖化血红蛋白<6.5%且≥5.7%。
1.3 纳入标准
符合以上诊断标准;年龄在18~95岁;签署知情同意书。
1.4 排除标准
消化系统等疾病或饮食等因素影响舌象者;1型糖尿病或特殊类型糖尿病及酮症酸中毒等急性并发症者;患有其他严重内科疾病如肿瘤、免疫系统、血液系统等疾病者;服用类固醇等影响糖代谢药物者;孕妇及哺乳期患者;资料缺失或输入有误者。
1.5 数据采集
采用上海中医药大学智能化诊断技术研究实验室开发的TDA-1型数字舌象仪采集舌象(图1),中医舌诊分析系统提取舌象特征(图2),包括舌质颜色参数L值(tongue body l value, TB-L)、舌质颜色参数a值(tongue body a value, TB-a)、舌质颜色参数b值(tongue body b value, TB-b);舌苔颜色参数L值(tongue coating l value, TC-L)、舌苔颜色参数a值(tongue coating a value, TC-a)、舌苔颜色参数b值(tongue coating b value, TC-b);基于像素值计算的舌苔面积/全舌面积(Per-all)、基于像素值计算的舌苔面积/基于像素位置计算的舌苔面积(Per-part)等。同时嘱受试者禁食10 h以上,抽取静脉血检查糖代谢相关指标葡萄糖(fasting blood glucose, GLU)、糖化血红蛋白(glycated hemoglobin, HbA1c)等,脂代谢相关指标总胆固醇(total cholesterol, CHO)、甘油三酯(triglyceride, TG)、高密度脂蛋白(high density lipoprotein, HDL)、低密度脂蛋白(low density lipoprotein, LDL)等,服用标准75 g葡萄糖水测量餐后2 h葡萄糖(2-hour postprandial blood glucose, 2hGLU),同时测量患者心率、血压、身高、体质量、腰围、臀围,并分别计算体质量指数、腰高比和腰臀比。
图1 TDA-1型数字舌象仪

图2 中医舌诊分析系统V2.0
1.6 统计学方法
1.7 构建风险预测模型
1.7.1 特征筛选 根据统计分析结果,筛选特征进入机器学习算法模型。正常对照组与糖尿病前期组分类模型,基本生理指标纳入年龄、体质量、体质量指数、腰高比、腰臀比、腰围等特征;舌象参数(T)纳入TB-L、TC-a、TC-b、Per-all、Per-part等特征;正常对照组与糖尿病组分类模型,基本生理指标(M)纳入年龄、体质量、体质量指数、腰高比、腰臀比、腰围、臀围等特征;舌象参数纳入TB-L、TB-b、TC-b、Per-all等特征;糖尿病前期组与糖尿病组分类模型,舌象参数比较差异无统计学意义,探索性将舌象指标全部纳入;基本生理指标纳入体质量、体质量指数、腰高比、腰臀比、腰围、臀围等特征。
1.7.2 数据预处理 对数据进行归一化处理,以提高模型分类精度,公式如下。
1.7.3 样本划分 将数据随机划分为训练集和测试集,其中划定70%的样本为训练集,划定30%的样本为测试集。
1.7.4 训练模型 本实验运用4种分类算法建立糖尿病风险预测模型,即逻辑回归(Logistics regression)、人工神经网络(artificial neural network,ANN)、支持向量机(support vector machine,SVM)、朴素贝叶斯(Naive Bayes)等。将数据集分为3个部分,分别为正常对照组与糖尿病前期组、正常对照组与糖尿病组、糖尿病前期组与糖尿病组,在每个部分基础上,每个算法分别纳入生理指标特征、舌象参数特征、生理指标与舌象参数联合特征建立3个模型,分别作二分类预测(图3)。

图3 构建2型糖尿病风险预测模型流程图
1.7.5 模型评价 运用受试者操作曲线下面积(area under the curve,AUC)评价模型的准确性,其中AUC的值为1时表现最好,为0.5时随机机会选择,分级如下:0.5~0.6表示精度极差,0.6~0.7表示精度较差,0.7~0.8表示精度一般,0.8~0.9表示精度良好,0.9~1.0表示精度极佳[5]。对于分类样本结构差异的情况引入F1分数、精度(Precision)、召回率(Recall)作为评价手段[6]。
2 结果
2.1 3组受试者基本生理指标比较
表1~4示,糖尿病前期与正常对照组比较,年龄、体质量、体质量指数有显著差异(P<0.05),腰高比、腰臀比、腰围差异有统计学意义(P<0.001);糖尿病组与正常对照组比较,年龄、体质量指数有显著差异(P<0.01),体质量、腰高比、腰臀比、腰围、臀围差异有统计学意义(P<0.001);糖尿病组与糖尿病前期组比较,体质量、腰臀比有显著差异(P<0.01),腰高比、腰围、臀围差异有统计学意义(P<0.001)。

表1 3组受试者性别年龄比较结果

表2 3组受试者身高体质量结果比较

表3 3组受试者腰围臀围结果比较

表4 3组受试者血压结果比较
2.2 3组受试者实验室检查指标比较
表5、6示,糖尿病前期与正常对照组比较,GLU、2hGLU、HbA1c、TG差异有统计学意义(P<0.001);糖尿病组与正常对照组比较,HDL差异有统计学意义(P<0.05),GLU、2hGLU、HbA1c、TG差异有统计学意义(P<0.001);糖尿病组与糖尿病前期组比较,TG有显著差异(P<0.01),GLU、2hGLU、HbA1c差异有统计学意义(P<0.001)。

表5 3组受试者血糖结果比较

表6 3组受试者血脂结果比较
2.3 3组受试者舌象参数比较
表7、8示,糖尿病前期与正常对照组比较,TB-L、Per-part有差异(P<0.05), TC-a、TC-b、Per-all有显著差异(P<0.01);糖尿病组与正常对照组比较,TB-L、TB-b、Per-all有差异(P<0.05), TC-b有显著差异(P<0.01)。

表7 3组受试者舌质参数结果比较

表8 3组受试者舌苔参数结果比较
2.4 糖尿病风险预测模型评价
由于正负样本结构差异,正常对照组与糖尿病前期组分类模型效果评价基于F1分数,Precision、 Recall、AUC作为参考(图4)。SVM生理指标和舌象参数联合特征分类模型分类效果最佳,F1为0.81,Precision为0.71,Recall为0.94(表9图5)。糖尿病前期组和糖尿病组分类模型效果一般,仅贝叶斯生理指标和舌象参数联合特征分类模型AUC达到0.7,但其F1分数过低,仅0.31(表9)。
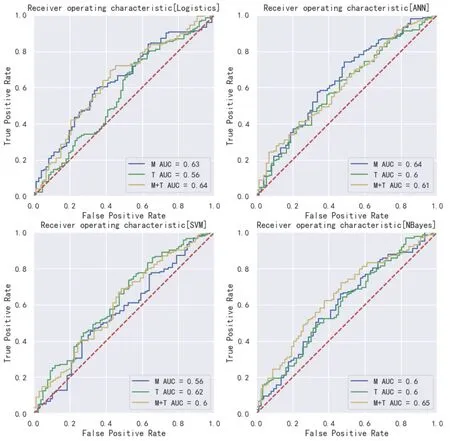
图4 正常对照组与糖尿病前期组分类模型ROC曲线

图5 正常对照组与糖尿病组分类模型ROC曲线
3 讨论
基本生理指标反映了人体的脂肪分布,与人的脂代谢水平和糖尿病发病密切相关。本研究发现,相比于正常对照组,糖尿病前期组的体质量指数、腰高比、腰臀比、腰围均有明显升高,体质量升高;糖尿病组的体质量、体质量指数、腰高比、腰臀比、腰围、臀围均有明显升高,糖尿病组与糖尿病前期组比较也是如此。体质量指数是评估全身脂肪分布的指标,腰围、臀围可以提供中心脂肪分布的信息,腰臀比、腰高比是近年来提出的代谢风险评估工具,反映了脂肪的相对分布。有研究证实,在南亚人群中,2型糖尿病与体质量指数、腰围有强相关性,与腰高比有一定的相关性[7]。
中医学认为,舌象可以反映人体的气血盛衰与运行情况,舌质舌苔的颜色变化、舌苔的厚薄又是肉眼最容易观察到的疾病体征。之前的研究发现,舌象参数与糖尿病的胰岛素抵抗指数有一定的相关性[8],因此选择舌色参数及舌苔厚薄参数参与建立糖尿病辅助诊断模型。舌象颜色特征的表述基于Lab色空间(CIELAB color space),由国际照明委员会在1976年定义而来。L表示亮度,范围在0~100之间;0代表黑色,100代表白色;a和b分别在-128~+127之间,其中+a代表红色,-a表示绿色,+b表示黄色,-b表示蓝色。Lab颜色空间的优势是非常接近人类的视觉系统,L分量与人眼对光线的感知相匹配,非常利于白平衡和色彩校正。相比于RGB等颜色空间,Lab颜色空间不依赖于设备,可以表现出人眼所能观察到的所有颜色,其色域广阔,被广泛运用于各个领域。本实验采用上海中医药大学智能化诊断技术研究实验室的舌象采集及分析设备,最大限度地保证数据采集环境和分析计算的一致性。实验发现,相比于正常对照组,糖尿病前期组与糖尿病组舌质颜色的L值更低,提示舌的颜色偏暗。糖尿病前期组舌苔面积/无舌苔面积降低,糖尿病前期组与糖尿病组的舌苔面积/全舌面积更高,提示糖尿病患者多因体内阴虚内热日久、煎灼津液产生痰湿,表现为胃阴亏虚、气血瘀滞。此外,相比于正常对照组,糖尿病组舌色b值降低,糖尿病前期组、糖尿病组苔色b值依次减低,提示糖尿病及糖尿病前期伴随血瘀证的发生。
实验室检查方面,与正常对照组比较糖尿病前期组和糖尿病组甘油三酯升高,与糖尿病前期组比较糖尿病组甘油三酯升高。与正常对照组比较,糖尿病组高密度脂蛋白降低。由上可知,糖尿病前期和糖尿病受试者存在着不同程度的脂代谢紊乱。严重的脂肪代谢失调与糖尿病的发生发展关系密切,高水平游离脂肪酸可以减少肌肉对于葡萄糖的摄入和氧化;破坏胰岛素作用下的肝糖原输出;通过脂毒性(lipotoxicity)机制降低胰岛素敏感性[9]。对比基本生理指标,糖尿病前期组和糖尿病组的脂代谢指标与正常组比较差异不甚明显,因此不太适合纳入预测模型,这也印证了生理指标在探测血糖异常方面的优越性。
机器学习技术起源于人工智能和统计学,对于数据分析有着先天优势,是目前数据分析的主要研究方向之一。本研究采用Logistics回归分析、人工神经网络、支持向量机和朴素贝叶斯4种算法结合舌象参数特征、基本生理特征进行分类计算。实践发现,只要特征选择得当可以取得较好的分类效果,可见先期数据的预处理以及传统统计学方法对于特征的筛选是后期分类算法获得成功的有力保证,这为后期其他病种风险预测模型的建立积累了经验。从结果看,舌象参数与基本生理指标联合特征神经网络2型糖尿病预测模型分类效果最好,神经网络基于前馈、反向传播、梯度下降、全局最小值等计算理论建立模型,其优势为反复迭代,根据前馈结果不断修正错误,从而不断逼近最佳效果,为糖尿病的辅助诊断提供一种可能性,尤其是那些血糖水平和糖化血红蛋白水平在边缘水平的患者,风险预测模型为他们提供及时的风险预警,督促存在患2型糖尿病风险的人改变饮食结构,增加运动量。通过机器学习算法建立的糖尿病分类模型对于逆转病程、减少患病概率是有价值的。单独基本生理指标建立的模型预测效果较差,结合舌象参数特征后分类效果提升较明显,可见舌象参数特征对于风险预测模型的建立具有突出作用。本研究为横断面观察性研究,观察的自变量与因变量之间处于相同的时间,不能确定2型糖尿病的发生与观察特征之间具有因果关联。同时样本量较小,对于模型的分类准确度有一定的影响。未来研究中需要增加样本量,修正机器学习参数,深入研究模型的最佳融合方法,并进一步探索深度学习的算法,以获得性能更加优良的预测模型。
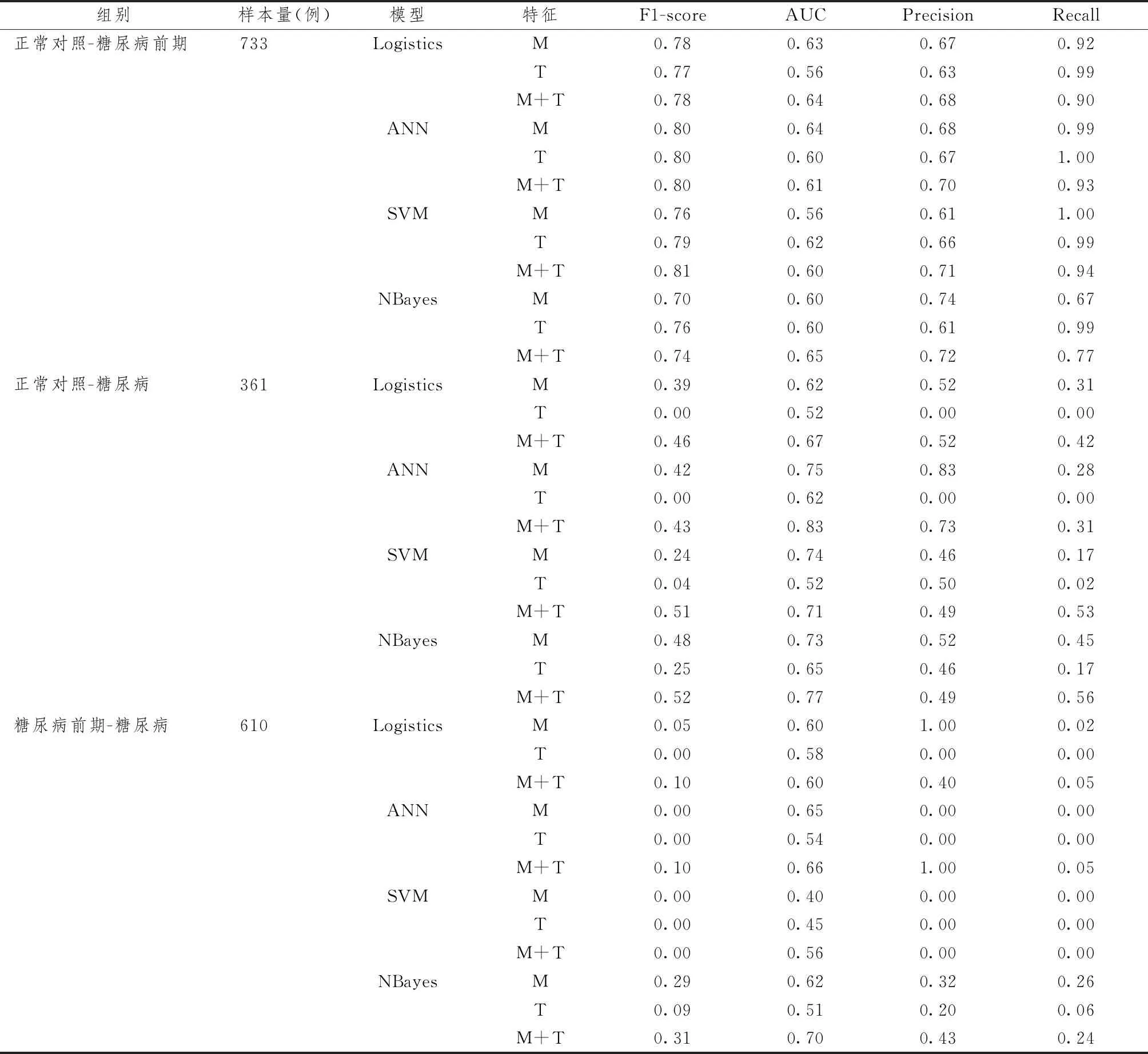
表9 3组模型评价结果比较
本研究发现,糖尿病患者和糖尿病前期人群呈高代谢状态,基本生理指标和糖脂相关的实验室检查均处于较高水平,舌质颜色偏暗,舌苔偏厚。基于支持向量机,根据生理指标和舌象参数联合特征建立的糖尿病前期分类模型性能较优良,可以应用于糖尿病前期检测。基于人工神经网络算法,以舌象参数与基本生理指标联合特征建立的糖尿病分类模型性能良好,符合临床对于2型糖尿病风险预测的实际需要。
