一种基于迁移学习的小样本图像分类方法
2021-04-23胡胜利
胡胜利,吴 季
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
深度学习在人工智能(Artificial Intelligence,AI)中属于一个重要的分支,在图像识别等领域取得了不错的成绩。在深度学习还未得到真正应用之前,处理图像的方法一般有阈值处理、边缘、区域、图论等。对人脸图像进行识别时,一般采用的是Haar-like特征+级联分类器。这些传统方法在处理图像数据时,都需要进行十分复杂的预处理工作(即特征提取工作),不仅耗时长、精度低,而且破坏了许多图像原有的特性。因深度学习的兴起,卷积神经网络开始应用于图像处理中,解决了传统人工特征提取图像存在的种种问题。随着深度学习的发展,相关神经网络模型也不断推陈出新[1],如 He等[2]将Resnet101应用在深度卷积神经网络中,大大提高了图像分类的准确度。深度学习模型应用在图像处理中,可以得到极高的准确率。Doon等[3]使用12层卷积神经网络(CNN)对CIFAR-10数据集进行图像识别,在测试中得到了87%的准确率。但当深度模型应用于小样本的图像数据中时,训练学习效果不好,只有在训练样本量很大时,才可以很好地泛化到不同的样本[4]。而且,当使用深度学习模型进行高精度实验时,需要用到的计算机硬件价格极其昂贵,在计算量中计算代价极大。所以,一般在训练小样本的样本数据时,运用迁移学习对深度模型进行迁移训练,可以有效解决因样本量少带的来准确率低等问题。
针对小样本图像分类的问题,本文采用迁移学习的方法,将深度卷积神经网络模型应用于小样本的图像处理中,旨在为小样本图像分类提供一种新方法。
1 卷积神经网络与迁移学习
1.1 卷积神经网络
图像识别领域一般以卷积神经网络(CNN)为研究核心。该网络的主要执行内容是选定一部分区域,提取到特征后将其传递到高层进行信息综合,主要层次包括输入层、卷积层、激励层、池化层、全连接层、输出层。在提取特征的过程中,为了不让图像失真一般会填充零像素。这是因为相邻的零像素不会在下一层激活其相应的卷积单元[5]。CNN比BP神经网络多引入了感受野、权值共享和下采样这3种新思想[6]。
1.2 迁移学习
迁移学习是针对在图像识别时因数据集量少无法使深度模型的训练任务从头开始而开发出的一种新的机器学习方法[7]。迁移学习将已经训练好的模型放到新的分类任务中再次进行图像识别,把之前所学习到的原有特征当作新数据的特征再次进行识别。其工作流程是先实例化基本模型并将预训练的权重加载到其中,再冻结模型中基础层的所有层,然后在基础模型的一层或多层的输出之上创建一个新的全连接层或分类器层,最后在新的数据集上训练新的模型。Yang等[8]迁移了GoogleNet中Inception-V3的预训练模型,并且应用在拥有10类水果的数据集中,得到了高于94%的训练和测试精度。
迁移学习目前研究的主要对象是源域和目标域的场景。设源域为Ds,目标域为Dt,其中域D由特征空间χ和边缘分布概率ρx组成,每个输入的样本为X∈χ。迁移学习可以定义为:给定源域Ds、学习任务Ts、目标域Dt和学习任务Tt,以获取源域Ds和学习任务Ts中的知识来帮助提升目标域中的预测函数ft(·)的学习为目的,其中Ds≠Dt或Ts≠Tt。
2 深度学习模型与数据增强
2.1 MobileNet-V2
MobileNet-V2是一个轻量级的卷积神经网络,它与一般的卷积神经网络相比,加入了深度可分离卷积和倒置残差结构。其中,深度可分离卷积的作用是将输入的特征降低到原来的1/9~1/8,并通过1×1的卷积计算输入通道的线性组合来构建新的特征[9]。MobileNet-V2网络将原先的MobileNet-V1网络中的特征提取部分做了相应的改进,提出了倒置残差结构的方法。该方法使用1×1卷积进行特征升维用来学习更多特征,然后使用了3×3的深度可分离卷积与1×1的卷积进行降维,从而得到最优的特征。加入残差结构可防止网络加深之后发生梯度消失的现象。MobileNet-V2中还增加了线性瓶颈层,用于降低ReLu函数对特征造成的破环。
2.2 Inception-V3
Inception-V3网络可以在不增加计算成本的基础上扩张网络,在相同的计算能力下提取更多的细微特征,提高训练效果。其设计理论主要是基于Hebbian原理和多尺度处理的直觉来增加网络的深度和宽度[10]。
Inception基础模块如图1所示。1×1卷积用于处理输入图像的尺寸,降低计算成本。Inception-V3模块将5×5卷积替换成2个连续的3×3卷积,进一步降低了计算成本。它与VGG网络不同之处在于VGG网络只是卷积层不断堆叠,而Inception-V3中采用不同尺寸的卷积核,将感受野不断放大,最后实现拼接,达到不同尺度的特征融合。Inception-V3的最大特点是将层与层之间的卷积计算进行了扩展。
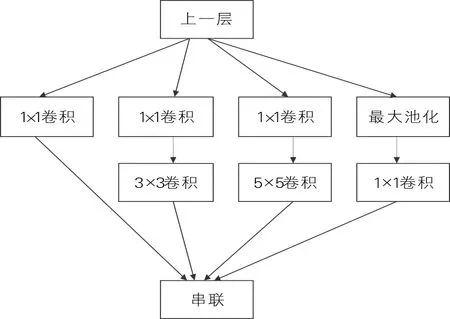
图1 Inception基础模块
2.3 Xception
Xception模型是Inception-V3的一种改进模型,主要引入了深度可分离卷积和残差块。与普通深度可分离卷积操作相反,Xception先进行1×1的卷积操作,再进行3×3的卷积。Xception模型可以将卷积神经网络的特征图中跨通道相关性和空间相关性的映射完全解耦[11]。
2.4 数据增强
数据增强可解决数据中样本量过少或者样本类别不均衡的问题。而数据增强的方法主要从单样本和多样本2个角度出发,单样本主要是样本的颜色变换和形状的几何变换,多样本主要是插值变换和混淆变换。一般在图像处理中较实用的方法是Mix-up,对图像和标签都进行了线性插值,不仅增强了原始图像数据集,还有效避免了模型过度拟合的风险[12]。
针对猫狗数据集,本文主要采用的是单样本的数据增强方法,对小样本图像数据进行水平翻转,按比例对图像的角度进行随机旋转、缩放、裁剪以及对图像的高度和宽度按比例进行调整。
3 迁移学习模型训练方法
在深度卷积神经网络中,当遇到小样本图像数据时,通常会因样本数据过少导致图像识别效果不够理想。若重新建立模型会消耗大量的人力,增加计算成本。迁移学习不仅可以学习到来自目标数据集之外的图像底层特征,还可以学习到训练目标数据集上的高级特征,对提升图像分类效果有极大帮助。为了证明迁移学习的效果,本文提出了一种基于迁移学习的小样本图像分类方法。该方法使用ImageNet数据集上训练而成的MobileNet-V2,Inception-V3和Xception的预训练模型。因为预训练的数据集和本次训练的猫狗图像数据都属于图像数据,所以关于图像的底层特征是可以被迁移的,符合迁移学习的条件。
基于迁移学习的小样本图像分类方法整体分为预训练和模型迁移2个部分,迁移学习流程如图2所示。图2中左半边图为预训练的流程,右半边图为将模型迁移训练的流程。

图2 迁移学习流程
预训练流程的执行过程与一般卷积神经网络的随机初始化训练过程类似,当模型达到收敛后即可输出预训练模型。
模型迁移训练不仅需要将训练好的模型参数进行迁移,还需要通过目标数据集来微调网络,使整个模型可以进一步地适应目标任务。猫狗图像分类任务的具体迁移训练方法步骤如下。
1)准备数据集。预训练模型中应用的是ImageNet数据集,将猫狗数据集作为目标数据集并将其作为预训练模型的输入。
2)选定模型。迁移训练选择MobileNet-V2,Inception-V3和Xception 3种模型,对比3种迁移模型的优劣性。
3)设计网络结构。首先根据迁移选择的网络特征将预训练模型中的特征进行提取,应用到目标数据集中,并将预测的类别更改为实验中所需要的类别;然后使用层数冻结、数据增强、Dropout等技术对迁移训练模型进行参数调整;最后对网络进行微调,解冻部分层次,提取到的分类特征更贴切于目标数据集,进一步提升分类效果。
4 实验设计与结果分析
4.1 实验环境及数据集
选用Tensorflow框架,处理器为intel(R) Core(TM)i7-7500u CPU,RAM 为8 GB,显卡为NVIDIA GeForce 940MX。实验涉及2个数据集,一个是以ImageNet为源域数据集,由140万张图像和1 000个类别组成的大型数据集;另一个是以猫狗数据集为目标域数据集,总共包含3 000张猫狗图片。
4.2 实验过程
将猫狗数据集划分为训练集、验证集和测试集。其中,验证集和训练集是同步完成的,这2个部分是在原有的旧样本中进行训练学习,而测试集是新的样本,不参与旧知识的训练。在猫狗图像分类实验中,训练集是将迁移过来的深度模型与猫狗数据集中的数据样本进行拟合;验证集是查看训练集训练后的模型,再次进行验证是否合理可行,并对该模型的泛化能力做初步地评估,有利于及时对训练的网络模型进行参数调整;测试集主要是用来测试微调后的网络是否能很好地泛化到未被训练的样本中,也就是微调后的网络可以应用于实际场景中,同时对于那些未知的样本网络也能进行处理,对得到后的训练模型进行深层次的评估。
4.2.1特征提取
特征提取是将在源域中预训练完成后的模型的训练权重进行冻结,并将它迁移到训练目标数据集中。这样只需修改网络最后的分类器,即可完成对小样本图像的训练。迁移学习进行特征提取的目的是将源域中提取出的特征应用到目标域小样本数据中,不仅简化了特征提取步骤,而且能够获得性能更好的训练模型。特征提取的详细步骤如下。
1)为了防止训练过程中修改预训练模型中的基础权重信息,将MobileNet-V2,Xception和Inception-V3在ImageNet数据集上预训练好的权重作为目标数据集的输入,并冻结3种模型的顶层,建立基本模型。
2)对小样本猫狗数据集进行数据增强,以此来反映目标数据集的更多细节,增加模型的泛化能力。
3)设置输入图片的尺寸为(100,100,3),采用预处理方法将图像像素从[0,255]调整至[-1,1],并建立特征提取器,将(100,100,3)图像转换成(4,4,1 280)的特征块。
4)将定义好的基本模型和特征提取器连接在一起构建模型,对获取到的特征向量进行全局平均池化。
5)为了进一步降低运算量,将Dropout设置为0.3,设置分类层,对猫狗图像进行分类,得出预测结果,构建图像分类模型。
在特征提取的实验中,设置学习率为0.000 1,优化器为Adam,损失函数为二进制交叉熵,周期数为10,且3种网络模型的参数设置相同。
4.2.2微调
在3种网络模型完成训练集和验证集的流程,且两者的数据处于收敛状态后,为了使目标数据得到训练以更好地适应目标域,需要对这3种模型进行微调,解冻全部或基本的模型。一般而言,对于图像分类任务来说,模型底层包含的是图像最基本的功能,几乎可以应用到任何类型的图像,因此模型底层不需要进行调整,依然处于冻结的状态。微调是调整模型的顶层部分,将模型的顶层部分与后添加的分类层在小样本的目标域数据集中继续进行训练,调整预训练的网络权重,以更好地适应小样本目标数据,最终提升3种模型的分类精度。微调的详细步骤如下。
1)MobileNet-V2模型总共有155层,设置前100层为底层部分并冻结,从第101层解除冻结,并与最后添加的全局平均池化层和分类层重新开始训练网络的权重,并设置优化器为RMSprop,学习率为0.000 01,周期数为10。
2)Inception-V3模型原特征提取层名为“mixed8”,为冻结状态,将“mixed7”之后的层次进行解冻, “mixed7”之前的层次依然处于冻结状态,微调后模型的参数设置和MobileNet-V2相同。
3)解冻Xception模型的基本预训练模型,仍处于冻结的部分是BatchNorMalization层,即批标准化层。这是因为BatchNorMalization层的更新会使模型所学习的知识遭到破坏,因此解冻了基本模型,并且学习率按原训练模型的十分之一对整个模型进行端到端的训练,所以,微调后的训练时间比Inception-V3和MobileNet-V2模型解冻部分层次的训练时间长,微调后模型的参数设置和MobileNet-V2相同。
4.3 实验结果
在3种模型上应用同一个目标数据集同时进行特征提取和微调,比较在微调操作前后的训练精度和损失变化。同时,将3种模型在新样本测试集中进行泛化,观察测试精度和损失的变化情况。3种模型微调前后的精度与损失见表1, 3种模型在测试集上的精度与损失见表2。其中,精度为正确识别图像和标签的概率;损失为预测标签和正确标签之间的差距。

表1 3种模型微调前后的精度与损失 %
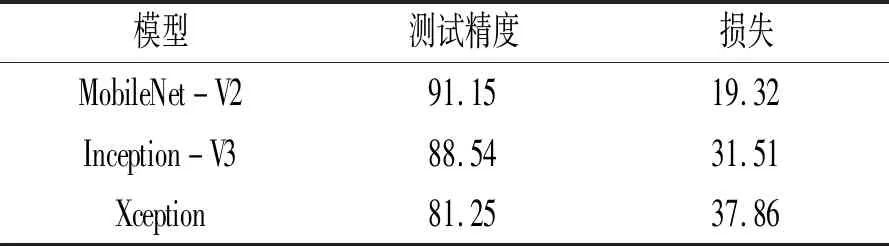
表2 3种模型在测试集上的精度与损失 %
表1中的数据反映的是在整个训练周期中在第10个周期和第20个周期,也就是微调前后的最后一个周期上的训练精度以及损失情况。由表1可以看出,3种模型进行微调后,精度和损失的变化都是极为可观的,均有一定的提升。由表2可以看出, MobileNet-V2的测试精度最高,损失最低,说明MobileNet-V2模型在适应新样本的过程中泛化性能最好。
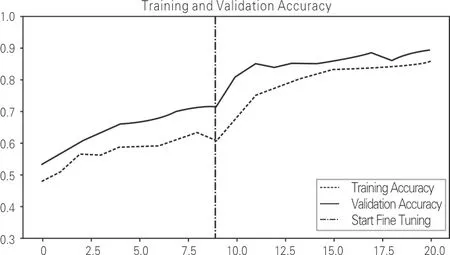
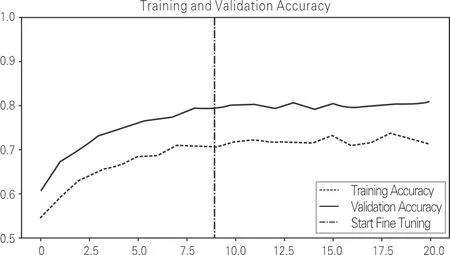
3种模型微调前后的精度与损失变化仿真图如图3~5所示。其中,每个小图的中间线为微调前后两者的分隔线。

(a) 精度变化曲线
(a) 精度变化曲线
(a) 精度变化曲线
从图3~5可以看出,微调前后Inception-V3模型的精度最高,且精度提升变化最为明显。Xception模型在精度提升方面已经趋近于饱和状态;Inception-V3模型在微调刚开始时精度上升明显,MobileNet-V2模型仍然有精度提升的可能。
通过实验可以看出,运用迁移学习的方法将迁移深度卷积神经网络应用于小样本的图像处理中可以构造出泛化性能很高的模型,大大减少了原深度模型训练时产生的过拟合问题。
5 结束语
将迁移学习的理念与深度模型的方法结合,应用于小样本数据处理中,不仅训练时间短,而且准确率也很高。模型经过微调后,泛化性能提高,更加适用于图像分类处理。可以适当增加输入数据集的大小以提升精度,但这样会使训练时间延长,或者通过优势组合,继续进化模型,进一步提高对特征提取感受野的范围大小等。
