基于风电机组控制原理的风功率数据识别与清洗方法
2021-04-22胡在春
梅 勇, 李 霄, 胡在春, 姚 惠, 刘 达
(1. 国家电投集团能源科技工程有限公司, 上海 201100; 2. 国家电投集团广西电力有限公司, 南宁 530003; 3. 中国核科技信息与经济研究院, 北京 100048)
当前能源结构加速优化,风电作为新能源发电的一种重要形式,近年来发展迅速。随着技术的成熟和成本的进一步下降,我国风电装机规模逐年增大。据国家能源局权威数据显示,2019年我国新增并网风电装机2 574万kW,累计并网装机21 005万kW[1]。这也带来了风电运维管理方面的问题,尤其是“平价上网”时代的到来,使得风电场必须具备更高的运维管理效率才能获得良好的经济效益。随着大数据时代的到来,风电行业也在尝试通过大数据技术实现风电场的智能运维管理,提高发电效益。而在实施过程中,数据成为可利用的关键资源,风功率数据作为展现风电机组性能最直观的数据,倍受相关人员的关注。
风功率曲线可以通过数据采集与监控系统(SCADA)运行数据拟合得到,其反映了机组输出有功功率与风速之间的函数关系。随着风电在整个发电行业中比重的增加,风功率曲线的获取尤为重要[2],其在风场经济性分析活动中具有重要作用,不仅能验证风电机组运行状况是否在额定范围内,还可以横向对比各风电机组的运行数据,及时发现问题并加以排查,减少电量损失。而实际运行过程中,风功率数据在采集、测量、传输、转换等各个环节中都存在故障或干扰导致的数据异常或缺失,且国内普遍存在因风电接纳能力受限而“弃风”的现象,形成了人为因素造成的“限电”数据。以上两类数据都为非正常运行数据,不能用来进行风电机组性能和经济性分析,否则会影响结果的准确性与可靠性[3]。
对于风功率特性的研究,目前主要集中在两方面:一是风功率曲线的建模方法研究[2-7],二是对异常风功率数据的识别和清洗研究[8-13]。Gill等[6]提出采用Copula风功率曲线模型来清洗异常点,建立风功率曲线来对机组特性进行评估。Lydia等[7]对包括Copula方法和神经网络方法在内的多种风功率曲线建模方法进行对比和分析,发现这些方法都存在改进空间,无法从机理上将风功率曲线的影响因素关联到风功率输出。赵永宁等[8]提出了将四分位法和K-means聚类方法相结合的风功率数据清洗方法。娄建楼等[9]提出了最优组内方差清洗算法。沈小军等[10-11]提出了一种基于变点分组法和四分位法组合的异常数据识别清洗方法。上述方法有一定的适用性,但对位于风功率曲线右侧有大量异常点的情形无法达到较好的效果。杨茂等[12]结合标准风速-功率的传变特性,依据正态分布和标准差提出黏滞区间的概念,对异常数据进行识别和清洗后获得了较好的清洗效果。胡阳等[13]结合风机运行原理与风速、风轮转速和功率三维关联性关系,依照风速精细化分段剔除异常数据,也进一步改善了数据清洗效果。
目前,对于异常风功率点的判断主要有2种方法:一是根据数据点集中程度或位置分布来判断某一点是否为异常点[8-11];二是建立风功率曲线的数学模型来判断异常点[5-6,12]。前者算法较为简洁,适用性有限;而后者算法相对复杂,效果优于前者,但两者基本是纯数学处理方法,清洗效果都有待改进。笔者针对风功率散点清洗中存在的问题,从风电机组控制原理出发,提出了一种简单可行、适用性强的清洗算法,并对该算法的有效性进行了验证。
1 变速变桨距风电机组控制
1.1 控制原理简介
风力发电机是一种将风能转化为叶轮的机械能,再通过叶轮带动发电机,将机械能转化为电能的装置。风轮吸收功表达式为:
(1)
式中:Pa为风轮吸收功,W;ρ为空气密度,kg/m3;U为风轮面迎风风速,m/s;R为风轮半径,m;CP为风轮的风能利用系数。
如图1所示,若忽略机械效率损失的影响,则
Pa=T风轮Ω
(2)
T风轮Ω=Tgωg
(3)
式中:T风轮为风轮转矩,N·m;Ω为风轮旋转角速度,rad/s;Tg为发电机转矩,N·m;ωg为发电机旋转角速度,rad/s,ωg=GΩ,G为齿轮箱转速比,对于直驱风电机组,无齿轮箱则G=1。
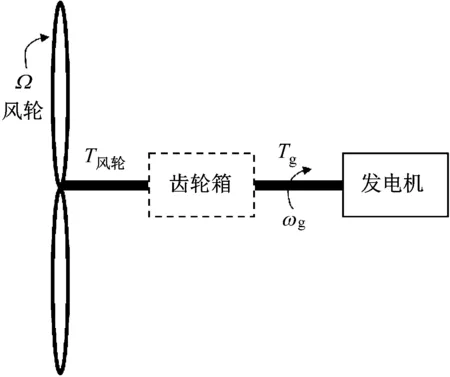
图1 风电机组发电原理简图
结合式(1)~式(3)可得:
(4)
在讨论风力机的能量转换与控制时,引入叶尖速比λ这一特性系数,其表示风轮在不同风速下的状态,用叶片的叶尖圆周速度与风速之比来衡量。
(5)
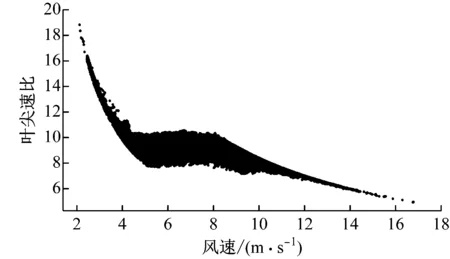
图2给出了风能利用系数与叶尖速比的关系。由图2可知,随着叶尖速比的增大,风能利用系数先增大后减小,即存在一个最佳叶尖速比λ(opt),可得到最大风能利用系数CP(max)。由于Ω=ωg/G,结合式(4)和式(5)可得:
(6)
令Kλ=ρπR5CP/(2λ3G3),并将其定义为发电机励磁转矩增益[13-14],则有
(7)

图2 风能利用系数与叶尖速比的关系图
1.2 控制参数分析
变速变桨距风电机组的控制目标为低风速运行变转速,追求最佳CP;高风速时桨距角变化,限制功率。如图3所示,实际运行中,由于机舱风速测量的不可靠,通常采用转速转矩控制的方式,控制过程可分为4个阶段[15]。
第一阶段,由于受风电机组最低转速的限制,风电机组在低于发电机最小转速时都采用恒转速-PI控制,此时由于风速小、转速大,风电机组在图2中高于最佳叶尖速比的区间内运行,随着风速增大,叶尖速比减小,逐渐接近最大风能利用系数。
第二阶段,在最小转速至额定转速之间,采用变转速控制,随着风速变化调节转速,保持叶尖速比维持在最佳值,因而能够维持在CP(max)点运行。
第三阶段,达到额定转速后,风电机组又采用恒转速-PI控制,通过增大转矩调节输出功率,随着风速增大,发电机转速不再变化,叶尖速比减小,风电机组在图2中低于最佳叶尖速比的区间内运行,CP也逐渐减小。
第四阶段,如图3右上角的虚线所示,达到额定转矩后,在更高的风速中,转矩需求量保持基本不变,由桨距控制来调节叶轮转速,使功率维持在额定功率,此时的叶尖速比进一步减小。

图3 变速变桨距风电机组转速转矩控制示意图
图4给出了理想运行状态下变速变桨距风电机组的风功率散点、转矩散点和叶尖速比散点图。从图4(b)可以看出,风电机组的转矩变化与图3所示的理想控制状态基本吻合。而图4(c)中叶尖速比散点的分布特征特点明显,基本可以分为3个区间,第一个区间与图3中的AB段对应,其值分布非常集中,随风速变化逐渐减小,近乎集中在一条曲线上;第二个区间与图3中的BC段对应,为CP(max)运行区间,叶尖速比基本维持在一个水平线两侧波动,分布也比较集中;第三个区间与图3中C点之后的运行区间对应,叶尖速比的特点与第一个区间类似,随风速变化基本集中在一条曲线上。根据风电机组控制原理,叶尖速比是整个控制过程中保证风电机组发电性能的重要指标,该值若偏离控制目标过大,必然对应着某种异常的发生,如测量参数异常导致的偏离或运行状态异常导致的偏离。基于叶尖速比的这些特性,笔者考虑对原始数据进行预处理后,对叶尖速比散点进行清洗,间接实现清洗功率散点的目的。

(a) 功率
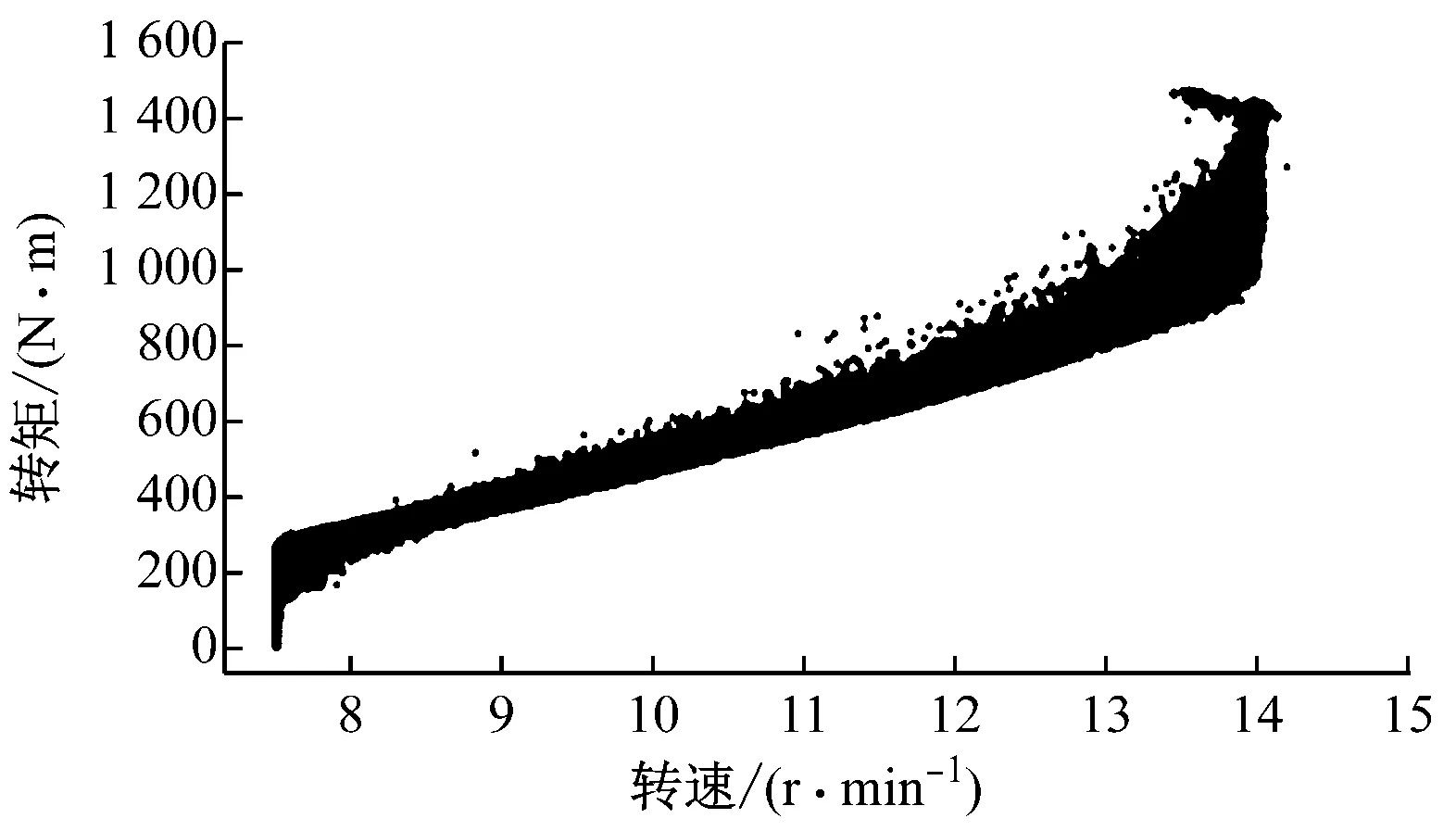
(b) 转矩
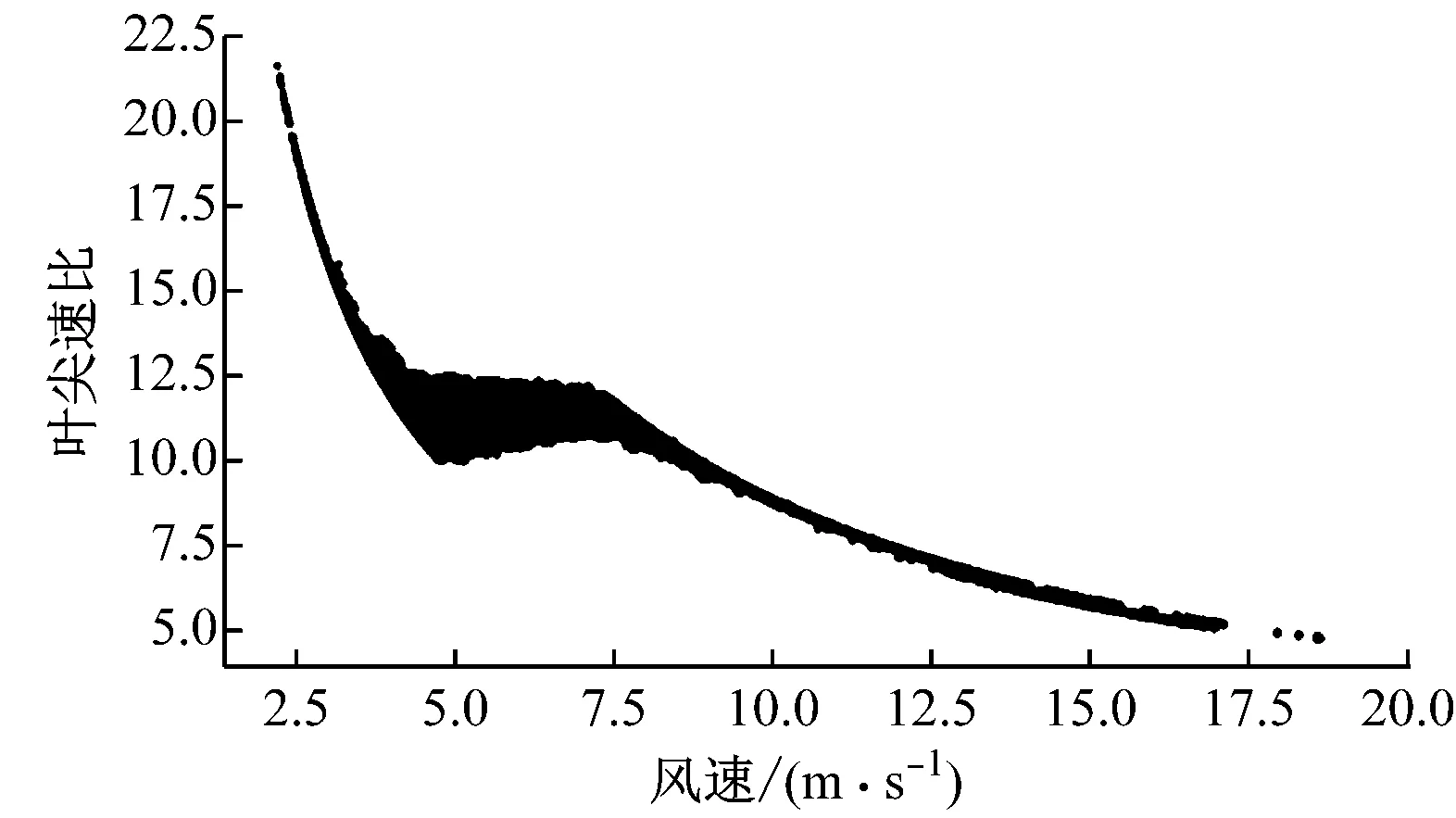
(c) 叶尖速比
2 数据清洗算法
2.1 运行参数特性分析
如图5所示,一般风电机组的原始风功率散点根据其运行状态可以划分为四大类:主体部分代表的正常运行点、限功率点、异常点(主要由传感器问题或机组故障造成)和停机点。而风功率散点清洗的目的就是要保留正常运行点,去掉其他三类点。停机点的筛选相对简单,直接删除功率小于接近0的某个数即可,一般将这一值定为5 kW。
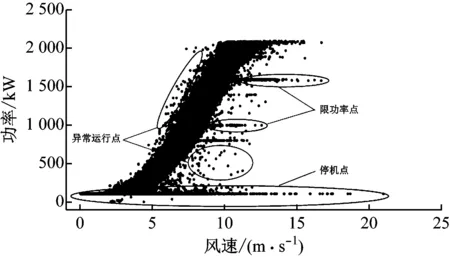
图5 风电机组运行点分类示意图
图6为对图5所示的风功率散点进行数据预处理后,直接采用四分位法清洗叶尖速比散点后得到的结果。从图6可以看出,通过对叶尖速比散点的清洗确实能清洗掉大部分异常数据。但是,由于部分限功率点的叶尖速比散点没有表现出明显的异常特性,无法仅通过清洗叶尖速比散点得到彻底清洗限功率点的目的,所以需要结合风机运行原理设计合理的识别算法,以达到比较理想的清洗效果。
2.2 算法的设计与实现
为了实现对风功率散点数据清洗的目的,设计了如图7所示的清洗算法。在实施数据清洗前,需要准备的数据包括SCADA运行数据(风速、功率、风轮转速和发电机转速)和风电机组参数(风轮直径、风电机组额定功率、发电机转速范围),计算间隔为10 min。
(a)

(b)

图7 风功率散点清洗算法示意图
清洗数据时,需要先将原始SCADA进行预处理,预处理步骤如下:(1) 删除停机数据;(2) 删除发电机转速小于设计最小发电机转速k(k<1)倍的所有工况数据,因为根据风电机组的转速转矩控制原理,在远低于设计最小发电机转速范围内运行不属于正常运行状态。考虑到实际运行在设计最小发电机转速的动态波动工况,可取k=0.9。
数据预处理完成后需要对限功率点数据进行识别。实际运行中,风速一般具有较大的波动性,其10 min均值很少在较长一段连续的时间内保持不变,所以在达到额定功率前未限功率的条件下,功率一般都会随风速波动。而限功率时,功率会在一段相对连续的时间内随风速的变化基本保持不变。根据限功率数据的这一特点,设计限功率数据识别算法:首先在最小功率和额定功率范围内,以一定的步长ΔP(根据经验可取5 kW)将功率点划分区间;然后在每个区间分析功率点的时间特性,若某个区间内某一天存在超过一定时间长度(一般取2 h)的功率点,则认为这一天的这些点为限功率点;这一步骤能找出绝大部分的限功率点,清洗这些散点后,已能满足后续进一步数据清洗的要求。
清洗完限功率点后,通过式(5)计算风电机组的叶尖速比,建立风速-叶尖速比散点关系,采用四分位法完成对叶尖速比的异常点的清洗。先将风速在最小值和最大值之间以0.5 m/s的区间进行划分,对每个区间内的叶尖速比进行排序λi={λi1,λi2,…,λin},将排好序的功率点平均划分为四部分,则可得到3个功率划分点即为3个四分位数,其从小到大依次为Q1、Q2、Q3,定义四分位距IQR为
IQR=Q3-Q1
(8)
根据IQR可以确定数据样本λi中异常值的内限[Fd,Fu],处于内限以外的数据都认为是异常值。
(9)
式中:kl和kh分别为区间下边界和上边界的系数,可将kl和kh都取1。
清洗完叶尖速比散点后,可能还会存在少数大风状态下未被清洗掉的异常点,需要再一次建立风速-功率散点关系,以0.5 m/s的风速区间划分功率散点,采用上述四分位法进行风速-功率散点清洗。通过以上步骤,即可获得正常运行的风功率散点。
3 数据清洗效果分析
3.1 测试散点的选择
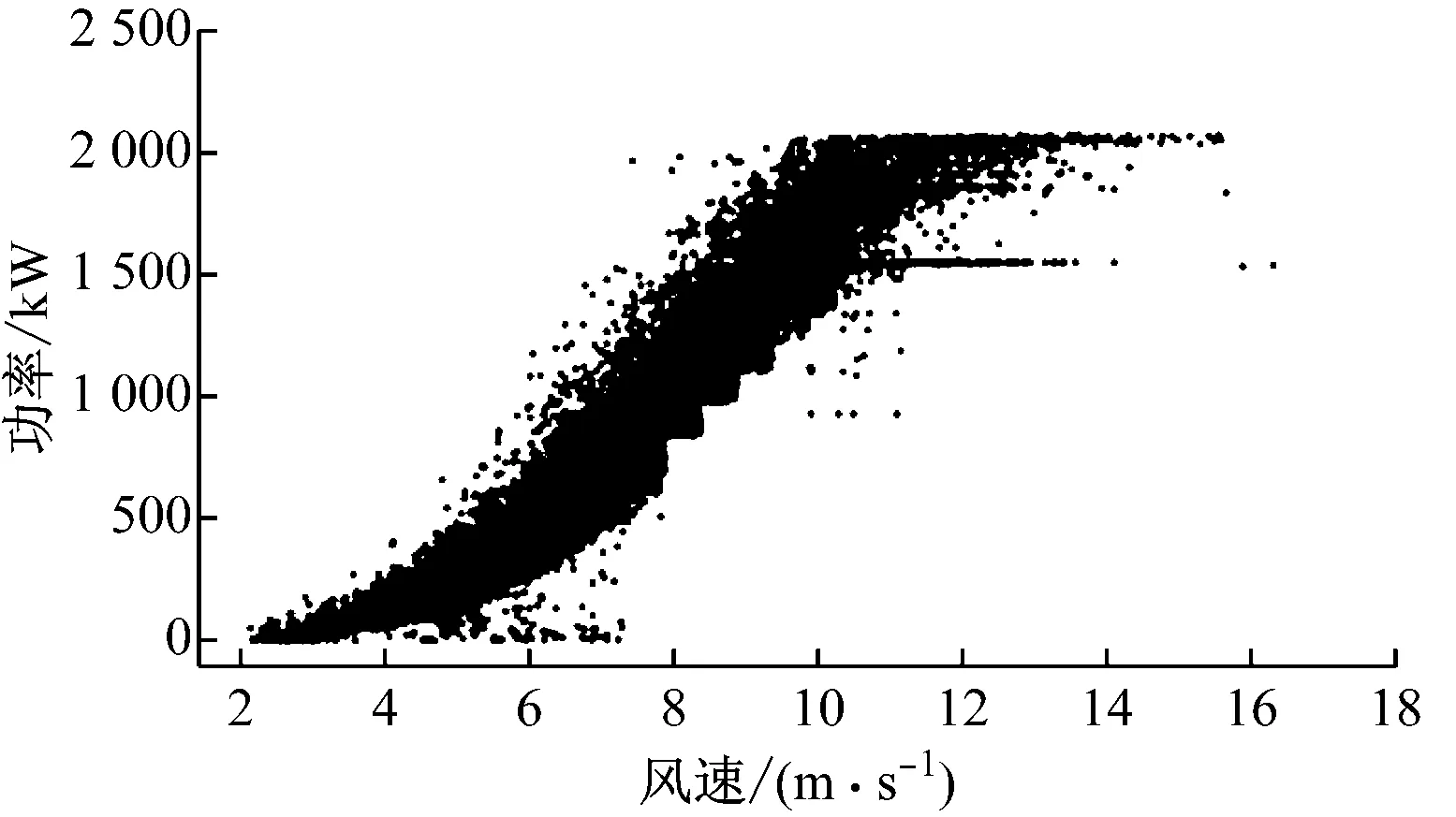
为了验证上述算法对于风功率散点清洗的有效性,选择变速变桨距风电机组的3种不同形态的功率散点进行测试,这3种形态的风功率散点基本能涵盖风场绝大部分风电机组运行情况。图8给出了3台不同风电机组一整年的风功率散点数据,取样间隔10 min。图8(a)中除了停机点外,只有少量的异常运行点;图8(b)中除了停机点外,有大量的限功率点和少量的异常运行点;图8(c)中存在大量的异常运行点,其中左右两侧表现出不同的功率散点形态,根据分析,左侧的功率散点形态是由于风速仪测风异常引起的,数据清洗过程中需要将其剔除。
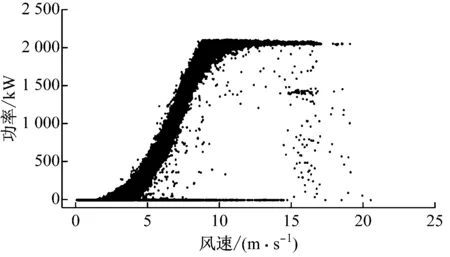
(a) 风电机组1
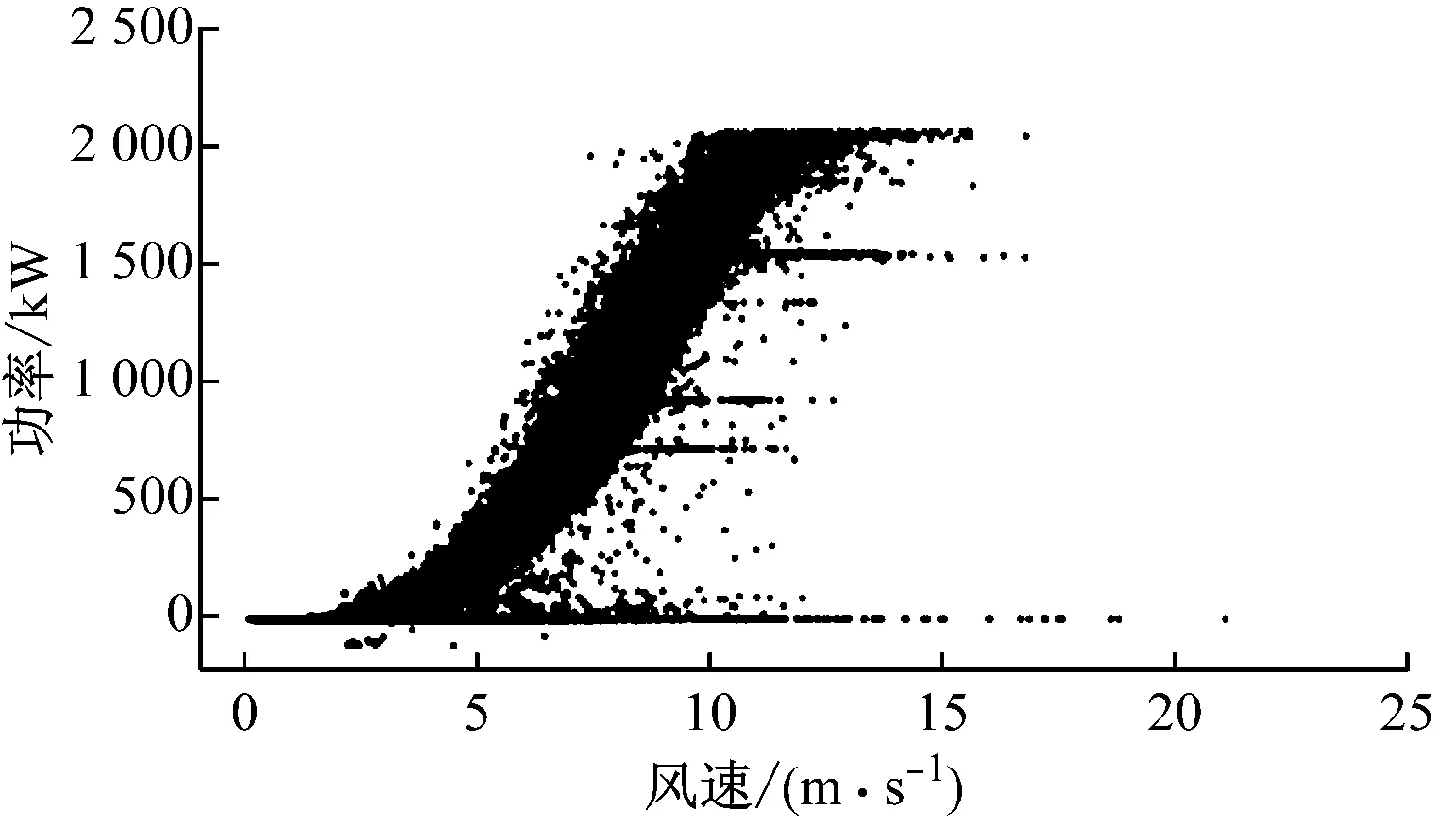
(b) 风电机组2

(c) 风电机组3
3.2 测试结果对比
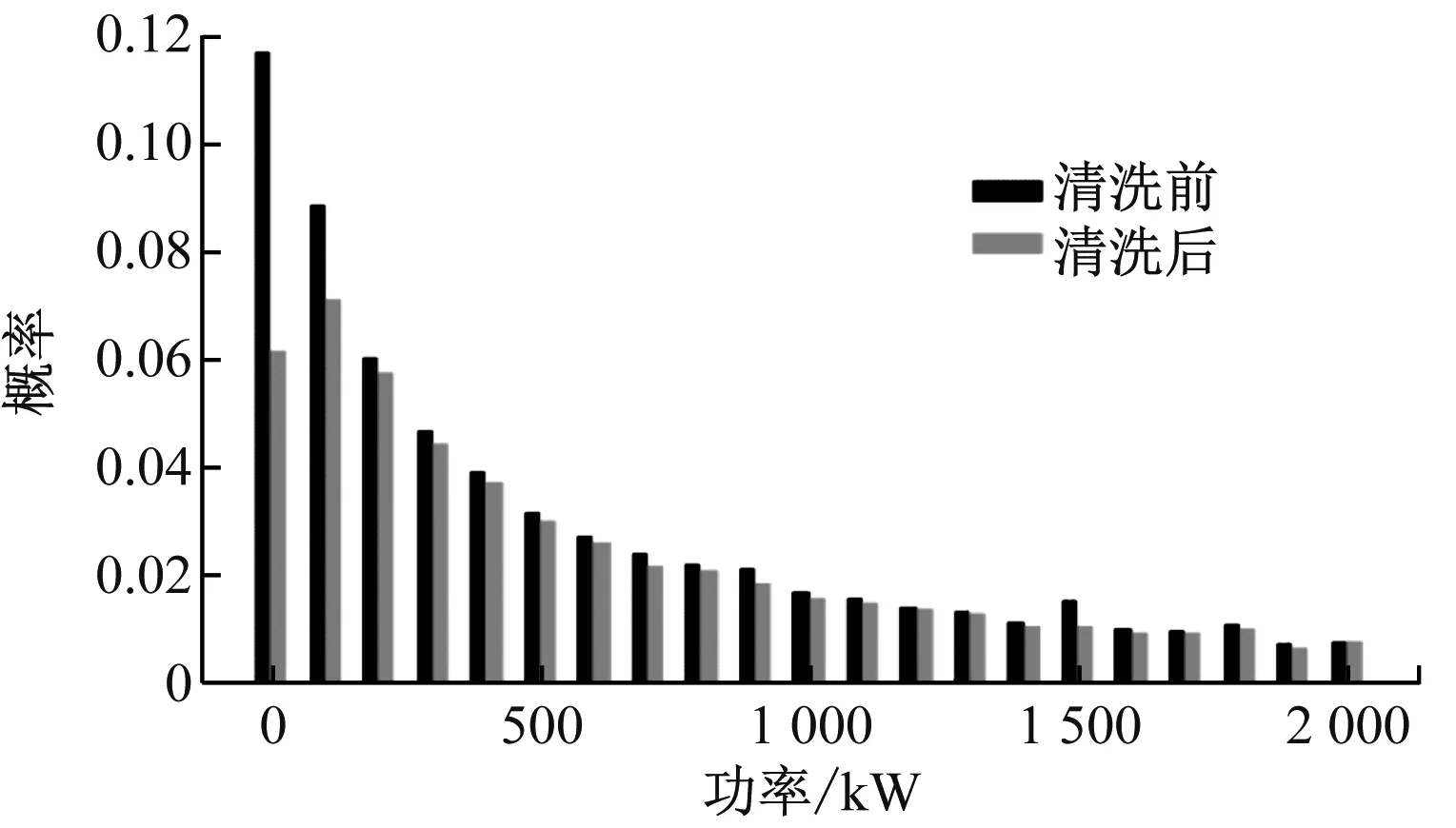
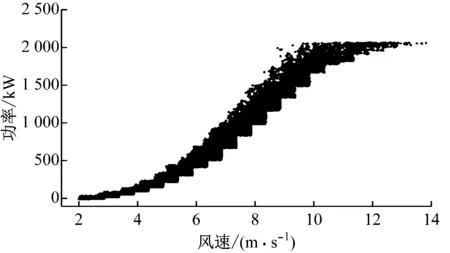
采用所提出的风功率数据清洗方法对上述3台风电机组的风功率点进行清洗,结果如图9所示。从图9可以看出,该方法对3台风电机组的功率散点都具有很好的清洗效果,尤其是对限功率点和风速异常点的清洗都具有很好的适用性。不考虑功率小于5 kW的停机点,对剩余的功率散点每100 kW整数点划分一个区间,得到每个区间的功率概率分布图(见图10),对比清洗功率散点前后的概率分布情况。可以看出,清洗前后功率数据的概率分布整体上差异不大,说明本文清洗方法具有良好的可靠性。
将本文清洗方法与文献[9]中的最优组内方差法(OIV)与文献[10]中的变点分组-四分位法清洗结果进行对比,选择图8(b)所示的功率散点进行测试。图11(a)中,采用最优组内方差法同样对左上方的异常数据清洗效果甚微,而右下方的部分限功率点未能被彻底清洗。图11(b)中,采用变点分组-四分位法能得到相对集中的风功率散点,但位于右下方的点被过多地清洗掉了。表1给出了3种算法的数据特征对比,其中有效数据比指清洗后数据占非停机数据的比例。可以看出,本文方法不仅能将功率散点清洗干净,而且清洗后剩余的有效数据比高,超过80%,表1中还给出了同样条件下各算法10次运行的平均耗时,可以看出本文方法运行耗时最短,比文献[9]的最优组内方差法耗时缩短40%。因此本文方法不仅鲁棒性好,能适用于多种形态分布的风功率散点情形,而且避免了过度清洗的问题,保留的散点分布可较好地体现机组控制特性。

(a) 风电机组1
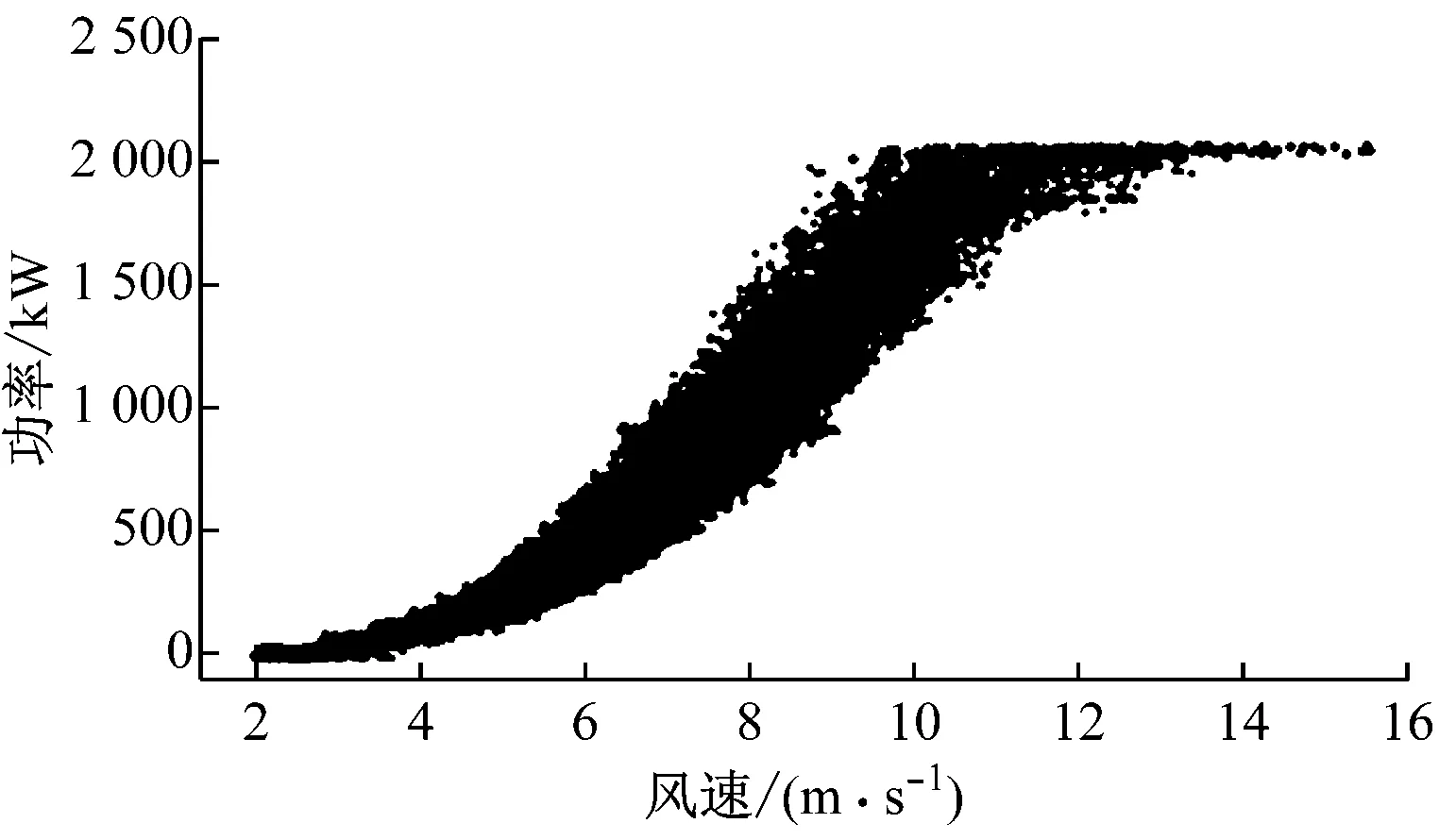
(b) 风电机组2

(c) 风电机组3

(a) 风电机组1
(b) 风电机组2

(c) 风电机组3
(a) 文献[9]算法
(b) 文献[10]算法

表1 不同算法对功率散点的清洗效果对比
4 结 论
(1) 在整个控制过程中,叶尖速比随风速变化呈现3种变化状态:低于最低发电机转速对应的风速下沿一条下降曲线的形态分布;在最低发电机转速和额定转速对应的风速区间沿一条水平线两侧分布,分布带较宽,均值基本不变;在发电机额定转速对应的风速以上区间,叶尖速比随风速变化与第一个风速区间类似。
(2) 基于风电机组的运行原理,结合叶尖速比的分布特点,提出了基于风速-叶尖速比散点四分位清洗的功率散点清洗方法,对各种不同形态特征的功率散点都具有较好的清洗效果。
(3) 将所提出的风功率散点清洗方法与文献中的算法进行对比,发现本文方法不仅能保留更多的有效数据,而且算法耗时较短,具有很好的实用性。
