基于改进GoogLeNet的锌渣识别算法
2021-04-21张振洲李克波但斌斌吴怀宇
张振洲,熊 凌,李克波,陈 刚,但斌斌,吴怀宇
(1.武汉科技大学冶金自动化与检测技术教育部工程研究中心,湖北 武汉,430081;2.武汉科技大学机器人与智能系统研究院,湖北 武汉,430081;3.武汉科技大学冶金装备及其控制教育部重点实验室,湖北 武汉,430081)
热镀锌钢板在汽车、家电、建筑、航空航天装备等行业具有广泛的应用。在冷轧热镀锌生产过程中,锌液与其他杂质元素及空气结合形成的锌渣漂浮在锌锅表面,影响镀锌板成品质量,因此需要定时清除[1]。锌渣可分为薄渣和厚渣两类,薄渣是刚生成的锌渣,可防止锌液被空气进一步氧化,而厚渣则是待捞锌渣,为了不影响热镀锌钢板的外观质量,必须及时捞出。已有的捞渣机器人[2-3]由于缺少相应的传感器,捞渣缺乏自主性,导致捞渣效率低下。采用机器视觉方式实现锌渣图像的自动分类,使捞渣机器人有选择性地捞起厚渣,这对于提高捞渣效率和实现冷轧生产线的智能化具有重要意义。
锌渣图像的特征提取是锌渣识别的关键,目前常采用基于纹理特征的图像分类方法,如局部二值特征[4]、灰度共生矩阵[5]、小波变换[6]等,虽然这些精心设计的人工特征在相应领域取得了不错的应用效果,但是其通用性不强。
近些年来,深度学习技术在图像识别领域发展十分迅猛,先后出现了AlexNet[7]、VGGNet[8]、GoogLeNet[9]等深度卷积神经网络。由于深度学习使用大量数据训练模型,所以在适应性方面表现更好,在工业图像识别中也得到了广泛应用。Han等[10]采用基于ROI选择的MobileNet进行电力设备识别,较大幅度提升了识别精度。Ricardo等[11]引入VGG16进行工业颗粒图像分类,比采用偏最小二乘判别分析、随机森林、简单CNN等方法的分类器有更高的准确性。王理顺等[12]提出一种基于改进卷积神经网络的织物缺陷在线检测算法,其平均测试时间比GoogLeNet方法减少了67%。樊丁等[13]改进了网络激活函数,并结合使用超像素分割算法进行焊缝探伤图像中的缺陷识别,达到了97.8%的准确率。
目前深度学习技术在冷轧生产线上的应用主要集中在带钢的缺陷检测[14-15],在热镀锌生产捞渣领域中的应用还未见报道。为了提升捞渣机器人的智能化水平,本文结合锌渣图像特点,提出一种基于改进GoogLeNet的锌渣识别算法。鉴于经典的卷积神经网络模型参数过多,并且容易发生过拟合,本文算法在GoogLeNet的基础上做出改进,降低网络参数的规模,以加快算法运行速度。最后,在采自实际生产现场的锌渣图像数据集上,将本文算法与一些现有的机器学习和深度学习分类方法进行对比分析,来验证其在锌渣识别领域中的优势。
1 基于改进GoogLeNet的锌渣识别模型
1.1 锌渣识别算法流程
在冷轧热镀锌生产线上,工业相机以俯视角度拍摄锌渣照片。为了全面识别出锌锅内的厚渣,并突出厚渣的局部特征,要将锌渣图片进行分块处理,分块数量参考捞渣勺与锌锅尺寸的比例关系,每块对应于捞渣勺大小。将每张原始图片分割为15×7共105张小图,标记好每张分割图片在原图中的相对位置,以便于厚渣的识别定位。
本文所提出的锌渣识别算法流程如图1所示,首先在人工标注的锌渣数据集上进行CNN模型的训练,然后将工业相机拍摄的锌渣图像进行分块及编号,将每张小块锌渣图像输入到训练好的模型进行检测,输出分类结果,依据编号对厚渣图片进行定位。由于其他步骤较简单,故本文主要工作是对锌渣识别网络进行优化。

图1 锌渣识别算法流程
1.2 GoogLeNet Inception模型
锌渣不具备固定形状及清晰的边缘,同时它是一种金属物质,具有光泽性,在不同光线下经常呈现不同的颜色。传统分类网络主要针对固定形状物体,不太适合于锌渣分类,本文采用GoogLeNet Inception模型的多尺度卷积结构,来增强网络对锌渣的识别效果。
GoogLeNet是一个22层的深层网络,采用独特的Inception结构来减少网络参数。一般的CNN只采用增大网络的方式来提升网络性能,在训练时有过拟合的风险并且增加了计算成本,而Inception结构很好地解决了这两个问题,它保留了网络结构的稀疏性以及密集矩阵的高计算性能,在增加网络的宽度和深度的同时减少了参数。图2为Inception结构,由4个主要成分组成:1×1卷积、3×3卷积、5×5卷积和3×3池化,其主要思路是通过多种不同大小的卷积核提取图像多尺度的信息,然后进行融合,从而具有更好的图像表征能力。在实际中,直接使用3×3和5×5卷积层会导致计算量过大,要在前面串联1×1的卷积层进行优化,同时可增加网络的非线性。

图2 Inception结构
1.3 全局平均池化
卷积神经网络中,每个卷积层的数据都是以三维形式存在的,可以把它看作是多个二维图片的叠加,其中每一张称为一个特征图。传统网络中全连接层将最后一个卷积运算得到的全体特征图拉伸成一个长向量,然后逐层降低向量维度,最后进行softmax分类,导致全连接层参数太多,特别是从特征图拉伸而来的第1个长向量与下一层的连接参数,这使得网络训练速度变慢。全局池化的解决方法是将最后一层卷积得到的每个特征图看作一个整体,对每个特征图求均值或最大值,每一个特征图都有一个输出,这样得到的特征向量的维数即是上一层特征图的数量。这不光增强了特征映射和类别之间的对应关系,且整个流程不需要优化参数,可以大大减少网络参数,并且可避免过拟合,全局池化原理如图3所示。
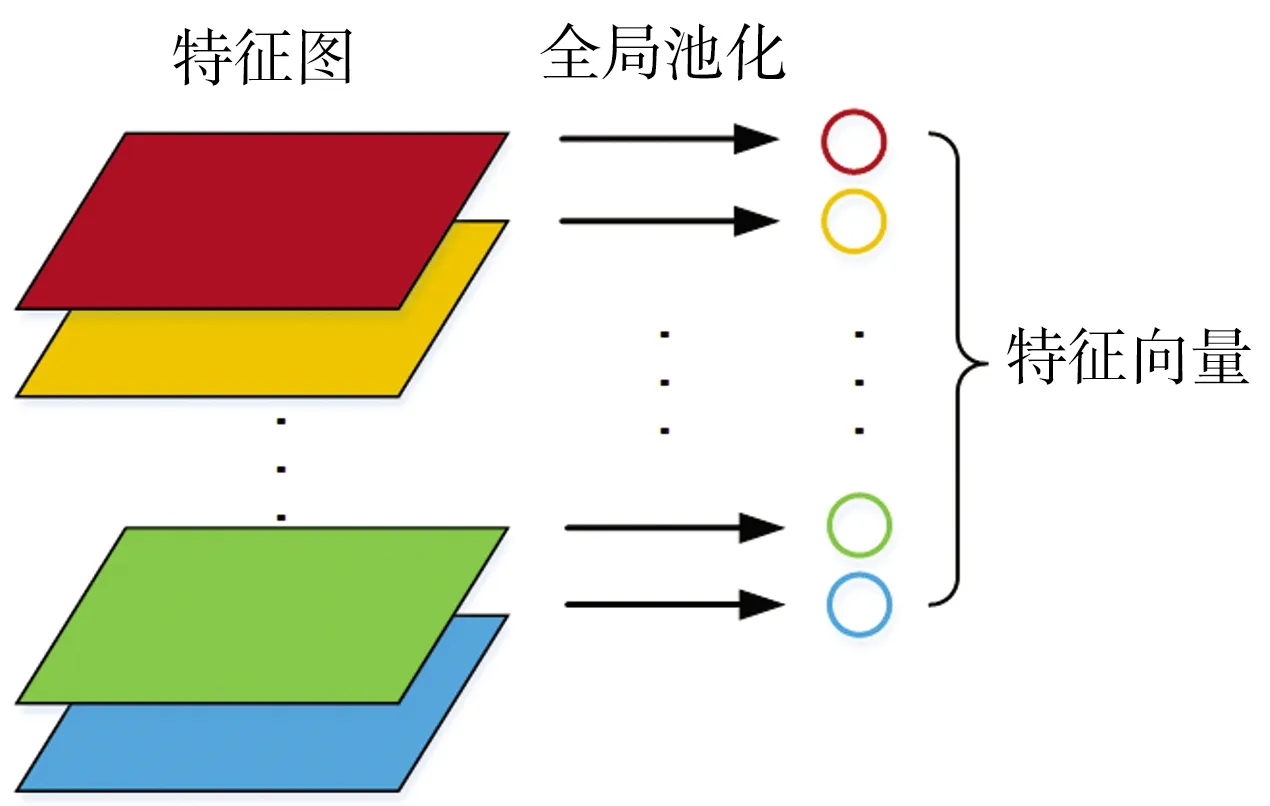
图3 全局池化方法
王泽霞等[16]采用全局最大池化方法来识别化纤丝饼的缺陷,其原因是丝饼缺陷相对较小,全局最大池化输出的是整个特征图的最大值,提取了最显著的特征,更适合于丝饼缺陷检测。然而,厚锌渣与薄锌渣两类图像的特征明显,使用全局平均池化可以弱化锌渣图像局部干扰,并且能考虑整张图片的信息,故本文算法采用全局平均池化来代替全连接层。

(1)
(2)
1.4 锌渣分类模型
本文在原始GoogLeNet的基础上,结合锌渣图片特点以及工业实时性需求,设计了一个适用于锌渣分类的网络结构。由于锌渣图像样本数较少,且原始GoogLeNet的层数较深,容易发生梯度消失和梯度爆炸的问题。Szegedy等[9]为了解决这个问题,在网络训练时加入两个辅助分类器并配以权重来获得最后的损失值并用于反向传播。为了满足工业实时性需求,本文进一步简化GoogLeNet结构,改进后的网络结构如图4所示。首先重复使用卷积和Inception结构来提取锌渣特征,在最后一个卷积层输出的特征图上采用全局池化进行特征映射及降维,这相较于传统的全连接层能够显著减少网络参数;然后加入dropout防止网络过拟合;最后由softmax输出样本的正负分类。除池化层外,网络在所有卷积层之后加入批归一化层(batch normalization,BN)用于加速网络收敛。改进后的网络共包含2个普通卷积层、3个Inception层、1个全局平均池化层和1个softmax层,网络各层参数如表1所示,其中“#3×3降维”和“#5×5 降维”表示Inception层中在3×3和5×5卷积之前使用的1×1卷积层中滤波器的数量,“池化降维”表示Inception层中池化层之后1×1卷积层中滤波器的数量。

图4 本文模型的网络结构
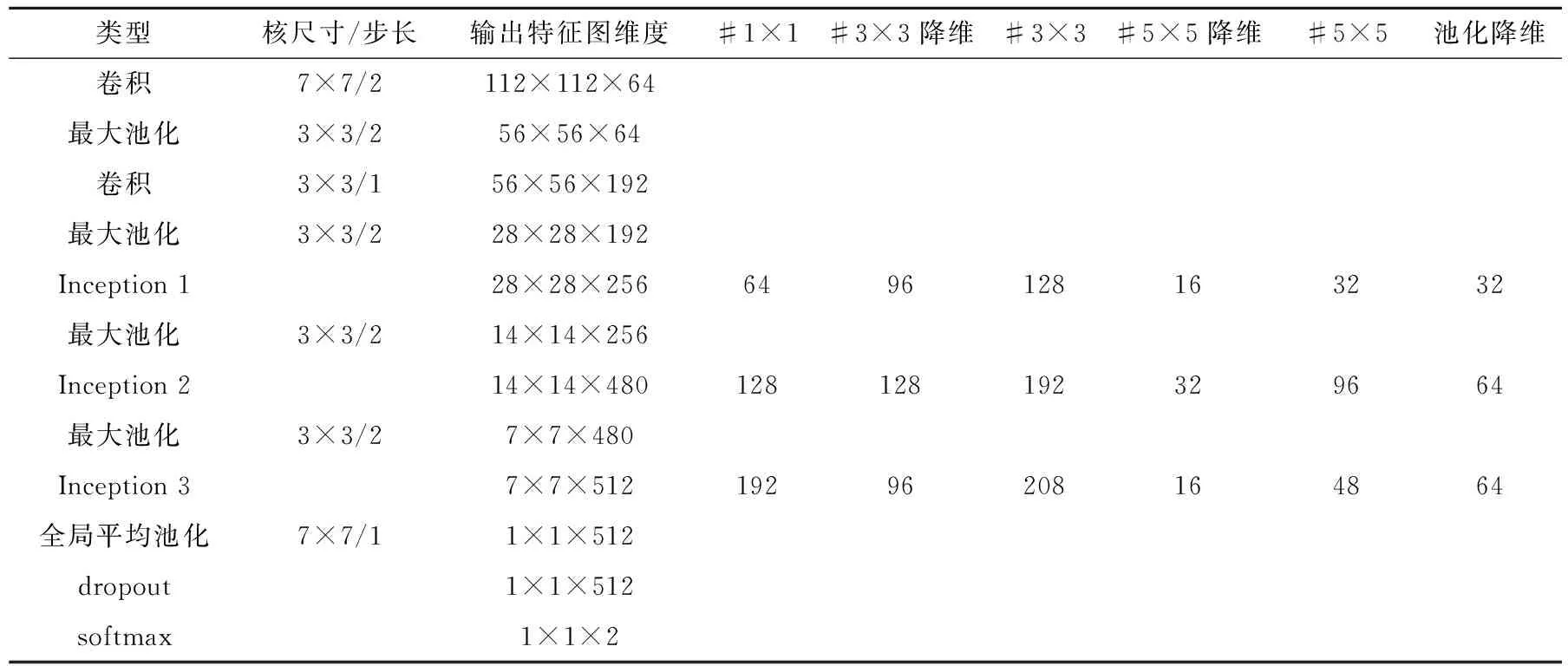
表1 改进GoogLeNet的各层参数
2 实验与结果分析
2.1 实验环境及参数设置
实验在win10专业版操作系统上完成,在Tensorflow与Keras深度学习开源框架中进行网络搭建和调试,选取Python作为编程语言。CPU为AMD Ryzen 5 3600,6核12线程,内存为16 GB,GPU为Nvidia RTX 2060s。
使用批量训练的方法将训练集分为多个批次,通过实验最终选择batchsize=32,此时网络收敛较快,且能达到最高精度。采用随机梯度下降优化算法,学习率设置为1×10-4,动量参数统一为0.9,迭代次数为100,同时在训练时加入学习率衰减策略,10次迭代后测试集准确率不上升则将学习率衰减一半,此方法使模型在训练后期更易获得最优解。
2.2 锌渣图像数据集概述
文中数据来自某钢铁公司热镀锌锅的现场照片。照片在不同时段和不同光照环境下获得,基本涵盖了各种锌渣分布情况。原始图片尺寸为1920像素×1080像素,首先剔除背景干扰,然后将每张原图分块为小图,并将小图的尺寸统一缩放为224像素×224像素。
厚渣和薄渣样本有较明显的外观差异:厚渣因长时间累积,表面有不规则褶皱,在室内环境下出现漫反射,故而锌渣亮度较高;薄渣生成时间较短,表面较光滑,纹理不明显且亮度较低。所有小图均由经验丰富的捞渣技术人员标注,分为厚渣和薄渣两类,据此构建锌渣图像数据库,用于CNN模型的训练。原始数据库共有图片2740张,为了提高模型的泛化能力,使用随机翻转、随机平移、随机旋转等方法来进行数据增强,扩充后的数据库包含厚渣和薄渣图片各3250张。使用Python脚本语言将厚渣和薄渣图片各按照4∶1的比例随机划分为训练集和测试集。图5为数据集中的部分锌渣样本。

(a)厚渣样本
2.3 结果与分析
采用识别准确率(accuracy)来评价模型的分类性能,它代表了正确预测样本占总预测样本的比值:
(3)
式中:TP(true positive)表示真正例;TN(true negative)表示真负例;FP(false positive)表示假正例;FN(false negative)表示假负例。
将本文模型和GoogLeNet模型分别在增强后的锌渣样本集上进行训练,训练过程中测试集的识别准确率及训练集损失值变化如图6和图7所示。从图中可知,由于加入了批归一化的原因,本文模型在训练前期损失值下降更快,在20次迭代后已接近其最小值,整个训练过程中本文模型的识别准确率曲线波动较小,网络收敛速度明显优于GoogLeNet模型,而且本文模型的最终准确率为99.1%,分类效果优于GoogLeNet模型(最终准确率为97.2%)。

图6 本文模型与GoogLeNet模型的识别准确率对比

图7 本文模型与GoogLeNet模型的训练集损失值对比
为了验证本文算法所采用的优化方法的有效性并获取最优超参数,分别针对BN层、全局池化方法及dropout取值进行了对比试验。
表2为有、无BN层时的模型识别准确率对比。结合图7和表2可知,在卷积层之后加入BN层,训练集的损失值下降速度较快,同时网络的识别准确率提高了2.7个百分点,说明批归一化能有效提高网络的分类性能。

表2 批归一化层对识别准确率的影响
对网络最后一层卷积得到的特征图分别进行全局最大池化、全局平均池化和全连接的操作,表3所示为不同连接方式下的模型识别准确率,其中全局平均池化方式下准确率最高,全连接方式下的准确率最低。因为全局池化操作增加了锌渣图片样本对旋转、平移等空间变化的鲁棒性,故较全连接方式具有更高的识别准确率;而全局平均池化弱化了锌渣图像局部干扰,考虑了整张图片的信息,又比全局最大池化更有利于锌渣分类。

表3 连接方式对识别准确率的影响
在神经网络的构建过程中,dropout值即节点隐藏率一般在0.3~0.7中选取,文献[9]选择dropout值为0.4。考虑到识别对象及样本数量级的不同,为了得到更好的正则化效果,本文分别对不同的dropout取值进行实验,结果如表4所示。由表4可知,在不使用dropout层时,利用较少的数据集进行模型训练容易发生过拟合,故识别准确率最低;dropout值取为0.5最适合于锌渣识别,这时模型具有最高的分类准确率。
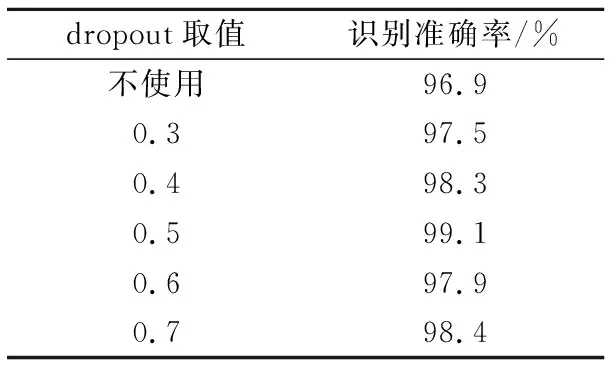
表4 dropout值对识别准确率的影响
为了评估本文算法在锌渣识别领域的优势,下面将其与一些现有的机器学习和深度学习分类模型进行对比,包括灰度共生矩阵(gray-level co-occurrence matrix, GLCM)特征[5]、局部二值模式(local binary pattern, LBP)特征[4]、AlexNet[7]、VGGNet[8]、GoogLeNet[9],对比项目包括识别准确率、参数内存以及测试耗时,结果如表5所示。

表5 各种算法的实验结果对比
表5中前面2种为机器学习算法,后面4种为深度学习算法。GLCM和LBP特征是两种经典的图像特征描述子,在图像分类和目标检测中具有广泛的应用。本文实验中首先分别采用GLCM和LBP方法提取锌渣特征,然后使用基于高斯核函数的SVM分类器进行锌渣图像的训练和分类。
由表5数据可见,本文算法在识别准确率上最优。同时,深度学习算法的分类准确率普遍高于机器学习算法,这是因为传统机器学习算法所提取的特征过于依赖人工设计,并且特征种类比较单一,而深度学习方法通过层层卷积,能够提取锌渣图像的局部纹理特征以及全局性的抽象特征,并且对图像的旋转和平移具有近似不变性,对不同场景具有更好的适应性。在AlexNet、VGGNet、GoogLeNet三种经典卷积神经网络中,GoogLeNet因为加入了Inception结构,故而具有最小的参数内存;本文算法进一步缩减网络结构,并使用全局池化代替全连接层,参数内存不到GoogLeNet的1/5,仅为1.1 MB。另外,网络模型训练结束后,在分块后的单张小图和原始图像上分别进行测试,结果取平均值。对比可知,本文算法具有最低的耗时,识别单张原始图像耗时仅为0.36 s,只有GoogLeNet模型的53%,本文算法更能满足工业实时性的要求。
3 结语
本文将卷积神经网络GoogLeNet应用于锌渣识别,通过对锌渣图像样本的分析,设计了一种适合锌渣识别的改进深度学习算法,然后在专门制作的锌渣图像数据集上进行训练,通过多次实验选取最适合的参数,得到最优网络模型。在测试集上与现有算法进行对比实验,结果表明本文算法的分类准确率较高,且相较于经典深度学习算法具有更低的空间复杂度和时间复杂度,能够有效地识别出锌渣,可为冷轧热镀锌生产线无人化作业提供帮助,具有较好的应用前景。未来工作将考虑进一步扩充锌渣图像样本数据集,并开展工业应用研究。
