基于SVM 和Logistic 算法对比的中小企业财务困境预测研究
2021-04-19洪欣琪阮素梅
洪欣琪,阮素梅
(安徽财经大学 金融学院,安徽 蚌埠233000)
中小企业在一国的经济发展中占据重要的地位,发挥着关键性作用。2018 年习近平总书记在不同城市考察中小企业发展状况时提出“党中央高度重视中小企业发展”[1]。2019 年三季度,中小企业发展指数(SMEDI)为92.8,与上季度持平。2019 年我国中小企业营业收入已达到约78.1 万亿元,2019~2023 预计年均复合增长率约为3.75%,2023 年将达到90.5 万亿元。但中小企业在发展过程中仍存在种种阻碍,“第三年槛”现象[2]较为普遍,即中小企业经营到第三年时很可能会面临破产的风险,这种风险大多因为企业存在财务困境所致。
为了促进中小企业健康稳定发展,构建预警体系、建立财务困境预警模型预测中小企业财务危机对企业自身、银行等金融机构以及政府而言尤为重要。传统的财务困境预警方式包括财务分析法和企业资信评级法[3],但随着时间推移,传统财务困境预警方法的众多弊端显现,预测准确性无法满足中小企业经营发展的需要。众多研究结果显示:利用机器学习、深度学习的手段进行中小企业财务困境预测时能够极大提高预测的准确性和效率。
由于中小企业陷入财务困境是一个持续的过程,许多研究人员在财务困境的界定上有很多不同的观点。Carmichael[4]认为企业财务困境是指企业经营受阻,包括出现企业的流动资金短缺、股本不足、拖欠债务等现象。Beaver[5]认为企业财务困境是指企业因为银行透支、拖欠优先股股息、偿付债券违约金而进行破产清算。Deakin[6]认为财务困境是指为债权人的利益而破产、资不抵债或者最终清算公司。在国内,郭小敏等[7]在界定财务困境时提出:财务困境的存在不是一瞬间而是一个循序渐进的过程。这给予我们选择实验样本时的启示:当上市企业亏损满3 年,不能定期扭亏或财务状况恶劣时才会被ST 处理,本文认为将被ST 的企业作为存在财务困境的样本是合理的。李萌[8]在研究信用风险评估过程中发现企业流动性和偿债能力显著反映信用风险是否发生,由此可知企业财务指标能够反映企业运行状况,作为实验研究依据具有说服力。
数量和统计方法是最经典的企业财务困境预测方法,Altman[9]提出了利用多变量辨别分析建立最早的财务困境预测模型并且最先利用Z-score 模型估计企业破产的可能性。1980 年之后机器学习快速发展,决策树、神经网络、集成算法在各个领域得到广泛的应用,Odom[10]首次将人工神经网络应用到企业破产预测。刘厚钦等[11]利用机器学习算法中的迭代法和集成学习算法进行信用风险预测时效果较好,但发现实际数据往往存在很多限制,本文通过对原始数据进行缺失值填补、异常值筛查、欠采样处理不平衡数据让预测模型呈现更好的效果。方匡南[12]使用SGL—SVM 技术预测财务困境,预测效果佳,本文认为在众多机器学习算法中,支持向量机(SVM)存在极佳的分类与预测能力。Bradley[13]最初利用支持向量机进行特征选择,并提出应深入探索其泛化能力。许多研究在进行特征选择时使用方法较为单一,为了更好地把蕴含信息的特征筛选出来本文集成4 种特征选择方法建立特征选择模型并对原始特征进行打分最终选择出与中小企业财务困境关系最为密切的22 个特征。Chen[14]经过研究发现,提高支持向量机预测性能的关键在于核函数的选择。
综上所述,大量文献在对中小企业财务困境问题展开研究时采用支持向量机构建预测模型,但在进行数据预处理和特征选择时方法单一,而且就如何改进支持向量机核函数以及相关参数使得模型在提高准确率的基础上避免过拟合的问题亟待解决。本文在现有文献的基础上,利用欠采样处理非平衡数据,建立特征选择集成模型挑选拟合性较高的特征并经过反复实验精进选择使支持向量机模型预测效果评价最佳的核函数,并将支持向量机预测模型与逻辑回归预测模型进行对比,总结两种方法的优势和劣势。
1 理论基础与研究设计
1.1 基于支持向量机的中小企业财务困境预测模型
支持向量机有以下数学描述:
给 定 训 练 集 T ={( x1, y1) , ( x2, y2) , …, ( xn, yn)} ∈( Rm*γ)n,其 中, xi∈ RM, i = 1,2, … ,n为 样 本,yi∈ γ= {+ 1, -1 } , i = 1,2, … ,n为样本 xi对应的类标签。二分类问题即是在 Rm中寻找一个分类超平面g ( x) = w, x + b, w ∈ Rm,b ∈ R ,使得对任一样本x,若 g ( x) ≥ 0,则判断x 属于+1 类,若g ( x) ﹤ 0,则判断x 属于-1 类。
该模型考虑了与中小企业经营相关财务指标,对中小企业财务困境进行全面系统的评价及预测。
设训练实例集[ xi, yi]是由输入变量 xi= Rn和分类值 yi∈-1 ,1, i = 1, … ,I 构成,对于线性分类实例集,最优超平面离散二元决策类规则的支持向量是由如下公式确定:

其中,Y 为最终结果, yi为分类训练实例集 xi分类值,其代表中小企业财务指标属性向量;每个向量对应于一个输入变量 xi, i= 1, …,M,作为支持向量;c和 ai代表确定的超平面参数。对于非线性离散实例集,上式转化为高维形式如下所示:

其中,函数k 表示中小企业财务困境预测不同类型的非线性决策面在输入空间集的核函数。
在面对非线性数据时需要引入核函数来处理,核函数的作用是为了将数据的维度转化让分类更加正确精准。
核函数有以下数学描述:
称 k :Rm*Rm→ R是核函数,如果存在从 Rm到Hilbet 空间ŋ 的映射

使得 ∀x , z ∈ Rm,满足

其中,· 表示空间ŋ 中的内积。在二分类问题中,称作φ 为特征的映射,φ 的像空间ŋ 为特征空间。
核函数的种类有很多,参考大量文献可知有4 种常用核函数:
线性核函数

多项式核函数

径向基核函数

Sigmoid 核函数

在核函数中需要确定众多参数的值,包括:C:惩罚项,float 类型;gamma:核函数系数,float 类型;coef0:核函数中的独立项,float 类型。
1.2 基于逻辑回归的中小企业财务困境预测模型
在机器学习领域逻辑回归虽名为“回归”却是一种线性分类器,从线性回归演变而来,大范围的应用于分类问题中,是财务预警中的常用模型。模型的基本形式是:

P 值表示中小企业陷入财务困境的概率,本文设定当P>0.5 时表示中小企业第二年会发生财务困境;反之,第二年正常经营。
逻辑回归在工商业财务困境预测中受到青睐,主要得益于其拥有其他二分类器所不具备的优点:
(1)逻辑回归对于线性关系的拟合非常优秀。包括金融领域中信用卡欺诈、信用评分卡的制定、电商销售预测等数据都是特征与标签之间线性关系极强的数据。
(2)逻辑回归计算速度较快。逻辑回归在线性数据的拟合和计算的速度上非常快,经多次实验表明其计算速度要高于随机森林以及支持向量机,并且在大型数据上表现较好。
(3)逻辑回归的结果不限于0 和1,而是能够返回连续型的概率类数字。在实际操作中不仅能够返回客户是否违约的判断还能够计算出客户确切的“信用分数”。由此可知,逻辑回归在实际问题的处理上具有一定的优势。
1.3 模型的评价
为了辨别基于支持向量机的中小企业财务困境预测模型的分类效果以及与其他分类器相比是否更优,本文引入4 种评价指标,分别为准确率、召回率AUC 和ROC 曲线。首先,根据样本真实的类别和模型预测类别的组合形成4 类,分别为TP(真正例)、FP(假正例)、TN(真反例)、FN(假反例)。很明显,将这4 类所包含的样本相加就是完整的数据集,分类结果的混淆矩阵如表1 所示。
1.3.1 准确率
准确率(Accuarcy)正确分类的样本占总样本的比率即正确分类的概率,是判断分类模型分类效果最直观的评价指标,计算公式为

表1 分类结果混淆矩阵

准确率的判断受数据是否平衡的影响较大,当数据非平衡时,准确率会出现虚高的情况,需要预先处理非平衡数据以及与其他评价指标相结合。
1.3.2 召回率
召回率(recall)又称查全率,表示样本的所有正例中有多少被准确的分辨出来。召回率公式如下所示

1.3.3 AUC 值与ROC 曲线
ROC 曲线是受试者工作特征曲线的简称,以真阳率(TPR)为纵坐标,假阳率(FPR)为横坐标的感受性曲线。ROC 曲线之所以被广泛应用是因为不同于传统二分类的评价方式在ROC 曲线上可以反映更多模糊的中间状态,适应范围更广泛。

如果一个分类器的ROC 曲线将另一个分类器的ROC 曲线包裹住,则说明前者的分类效果更出色。但是,如果两个分类器的ROC 曲线相交则无法通过曲线图来分辨效果,因此,本文引入表示ROC 曲线下方面积的AUC 值,设ROC 曲线是由众多点连接而成,点的坐标分别为 {( x1, y1),( x2, y2), … ,( xn, yn)},则:

2 实验结果及分析
2.1 数据样本
本文将中小企业板块中被ST 公司作为存在财务困境的公司样本,非ST 公司作为正常样本。为了减少实验可能出现的异常情况,在数据收集时做了以下数据的筛选:
(1)将银行业证券业等价格波动比较大的金融公司剔除;
(2)将数据公开不完整的公司剔除;
(3)将不是因为财务困境而被ST 的公司剔除。
根据以上要求,共选择96 家中小企业,每家中小企业分别选取其前2 年(t-2),前3 年(t-3),前4 年(t-4)三年的财务数据来预测当年(t 年)财务状况。本文在中小企业板中选择2020 年83 家非ST 公司作为正常样本,13 家首次ST 处理的中小企业作为存在财务困境样本。为了避免模型过拟合或者失去实验意义,在样本数据的选择上类比实际比例。本文还选取了2020 年66 家企业作为测试集其中14 家ST 企业作为存在财务困境的样本,52 家非ST 企业作为正常样本。实验中的所有数据均来自于国泰安数据库。
2.2 数据预处理和特征选择
2.2.1 缺失值处理
本文共选取62 个中小企业财务指标,首先观察收集的数据是否存在缺失值随后利用python 对数据中缺失值进行探索,根据下表2 所示共62 个财务指标均存在缺失值,且缺失程度各异。
表2 缺失值探索
经过检验发现,本文数据不服从正态分布,所以无法采用简单的均值进行缺失值的填补。故本文选择K-最近邻(KNN)法填补数据缺失值。
2.2.2 异常值处理
当机器或数据整理人员出现纰漏时极易出现个别数据明显不符合整体数据特性的情况即出现异常值。本文首先通过描述性统计方法对数据中的异常值进行探索,结果如表3 所示。

表3 描述性统计结果(部分)
通过描述性统计结果可以看出,共有9 个财务指标存在异常本文将存在异常的财务指标进行删除处理(表4)。

表4 异常财务指标
2.2.3 非平衡数据处理
本文希望通过获得的中小企业财务指标的数据建立财务困境预测模型,但中小企业板块中“ST”处理的样本数量占样本总量的比例较低,属于不平衡数据,利用类别不平衡数据建立预测模型会出现分类器失真现象。为了提高分类器对中小企业财务指标数据的分类预测能力,本文采用规律性强、时间成本低的“欠采样”方法,以RUSBoost 集成分类为主,迭代训练集分类器,适当减少“非ST”中小企业样本但不影响研究价值的体现。
2.2.4 特征选择
本文选取与中小企业偿债能力、盈利能力、每股指标、发展能力、现金获取能力、成长能力相关的62个财务指标作为原始数据,在此基础上进行特征选择筛选出与目标变量关系更密切的特征。许多研究人员在进行特征选择时仅利用单一的特征选择方法,本文集成f_classif、随机森林、Lasso、XGBoost 四种特征选择方法构建特征选择评分模型,4 种特征选择方法分别按照财务指标的重要性进行顺序排序,其中f_classific特征选择筛选出24 个财务指标,随机森林特征选择筛选出15 个财务指标,Lasso 特征选择筛选出5 个财务指标,XGBoost 特征选择筛选出18 个财务指标,在评分模型中被1 种特征选择方式选中记1 分,得分在2分及2 分以上的财务指标将作为实验特征,最终从62 个财务指标中筛选出15 个实验特征,特征选择评分模型如图1 所示。
根据构建的特征选择评分模型结果,本文从62 个中小企业财务指标中选取15 个财务指标作为训练财务困境预测模型的实验特征,特征选择结果如表5 所示。

图1 特征选择评分模型

表5 特征选择数据集
2.3 结果分析
2.3.1 支持向量机财务困境预测模型的建立与调参
为了提高支持向量机模型的预测效果,需要选择使得模型准确率、召回率、AUC 值尽可能高的核函数。本文将96 家中小企业3 年的财务数据作为训练数据进行训练,找出最优核函数,具体结果如下表7。
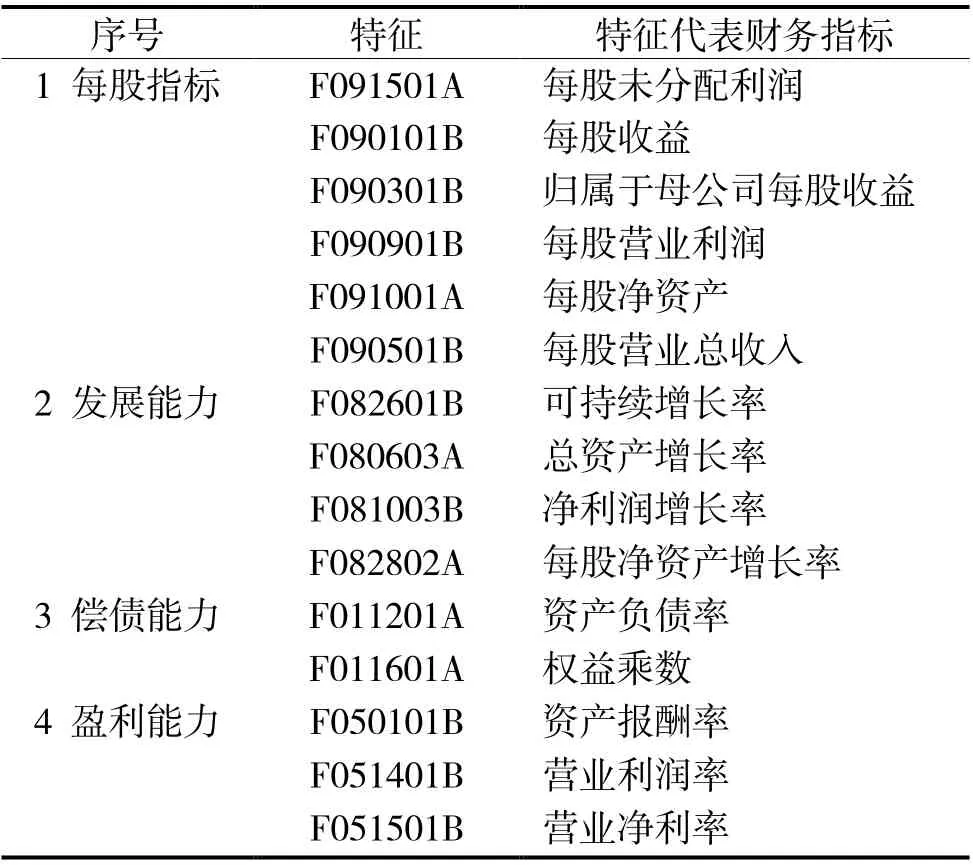
表6 所选特征释义

表7 核函数的选择
由表7 可知,径向基核函数准确率、召回率、AUC 值均达到最高,此时模型的预测效果最好。
C 值是核函数中最重要的参数,选择7 个C 值的备选数值,通过对分类器反复训练得到准确率最高的C 值,具体结果如表8,图2 所示。

表8 C 值的选择

图2 C 值选择效果图
由表8 可知,当C=1.06 和C=6.32 时准确度均能够达到0.88,根据图2 所示C=1.06 时模型最早实现最优状态,C 值作为惩罚系数,过大表示对误差的容忍度较小,但容易出现过拟合;过小时则容易出现模型欠拟合,所以在选择径向基核函数的基础上分别将2 个C 值代入模型观察二者的准确性、召回率以及AUC 值,结果如表9 所示。
由表9 可知,如果将C 值设置为6.23 则会出现过拟合现象,故在最终的分类模型中选择径向基核函数,C 值确定为1.06。模型整体在训练集的准确率达到0.98,召回率、AUC 值均达到1.00,分类效果出色。

表9 C 值的选择
2.3.2 模型结果对比
调参后,支持向量机预测模型和逻辑回归预测模型分类效果ROC 曲线图如图3, 4 所示。
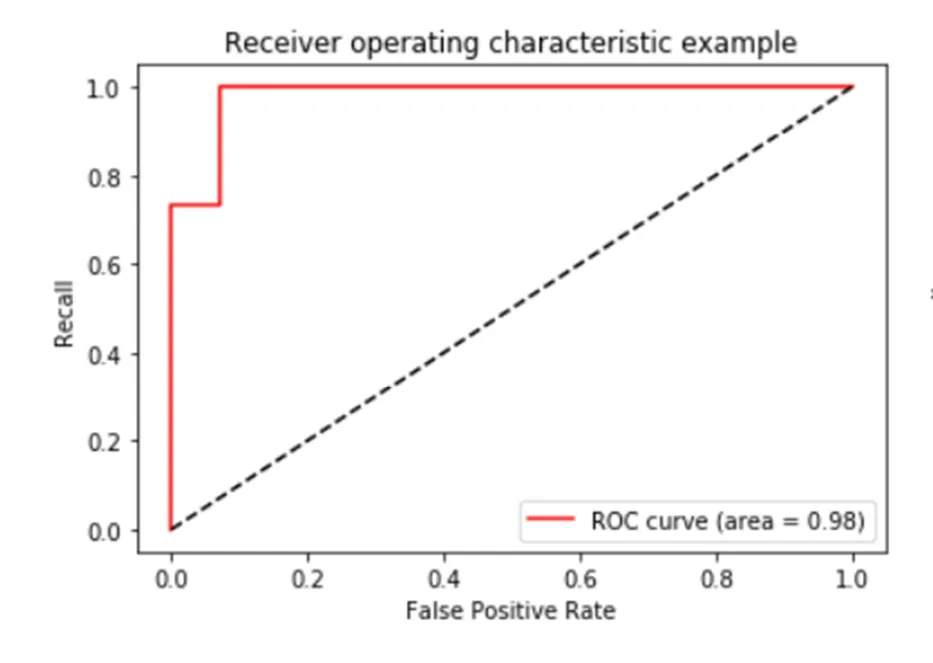
图3 支持向量机预测模型ROC 曲线

图4 逻辑回归预测模型ROC 曲线
由图3, 4 可知,支持向量机预测模型ROC 曲线凸起更靠近左上角,表示支持向量机预测模型的效果更好。
使用66 家中小企业3 年的财务指标体系数据作为测试集分别进行两种模型效果检验,结果如表10 所示。

表10 测试集结果
由表10 可知,支持向量机预测模型对于中小企业财务困境的预测准确率高于逻辑回归,故本文认为以追求预测准确率为目标时,支持向量机方法要优于逻辑回归。
3 研究结果与政策建议
本文选取中小企业财务数据并进行平衡数据与特征选择等数据预处理,利用支持向量机和逻辑回归方法分别建立财务困境预测模型。实验结果显示,在建立支持向量机财务困境预测模型过程中,通过选择径向基核函数,以及确定基于径向基核函数的最优参数C=1.06,能够大大提高支持向量机模型的预测准确率,并且通过调整核函数和其他参数更有利于将模型向其他领域推广;虽然逻辑回归预测模型能够处理大规模样本但其模型预测准确性远低于支持向量机模型,根据实验结果,本文认为使用支持向量机进行中小企业财务困境预测更加优越。支持向量机的优势在于其更加成熟和先进的算法大大提高了模型的准确性,满足我们进行中小企业财务困境预测的最终目标。支持向量机不仅可以通过调整核函数以及C 值改变模型适用于各种各样不同的财务数据,还可以根据AUC 值及召回率迎合不同的实验目的,如在一些实际状况中,某一次财务危机将带来致命的损失和打击,此时将不再一味追求预测准确率而是以牺牲准确率为前提将所有财务风险排除在外,在这种情况下便会选择召回率更高的模型。支持向量机的劣势在于不能很好地处理大规模数据集和多分类问题,同时运算速度慢于逻辑回归。
逻辑回归的优势在于不仅仅能返回其准确性概率,还能够得到具有定性分类作用的连续型数值,更易于解释和操作,且运算速度更快,并能够处理大规模数据。逻辑回归的劣势首先在于计算的复杂度低于支持向量机,所以准确性不够,判错率较高,在实际应用中会给银行等金融机构、政府及中小企业自身的带来额外损失;其次,逻辑回归无法通过调参来确定适合于不同数据的模型,根据不同的实践目标需要设定全新的模型,一定程度上增加了预测方的研发成本。
根据研究结论,从中小企业如何应对财务困境以及财务困境预测模型选择等方面提出建议:
(1)中小企业要积极预测自身是否存在财务困境并分析问题所在,降低可能破产的风险;其次,面对企业内部管理结构会计体系混乱的情况应该予以重视并进行调整,遵守会计准则,实现会计体系的明朗化和专业化;最后,将提高中小企业自身的能力作为重点,提高中小企业的授信评级。
(2)利用支持向量机建立财务困境预测模型满足提高预测准确性的需求,在企业内部、银行及其他金融机构、政府可以广泛应用;机器学习领域有众多方法适用于财务困境预测但各有优缺点,通过对不同模型进行结合,在保持原有模型优势的基础上将缺陷降到最低;后续研究可以拓展到多分类问题,进一步建立更完备的财务困境预测模型。
