基于CART决策树的双尺度流域单元地貌分类研究
——以北回归线(云南段)地区为例
2021-04-15张艳可,王金亮*,苏怀,程峰
张 艳 可,王 金 亮*,苏 怀,程 峰
(1.云南师范大学地理学部,云南 昆明 650500;2.云南省高校资源与环境遥感重点实验室,云南 昆明 650500;3.云南省地理空间信息技术工程技术研究中心,云南 昆明 650500)
0 引言
地貌是地球表面各个圈层系统间相互作用的重要一环[1],对地貌进行分类研究不仅可以客观了解当地地形的实际情况,而且可为土地利用、水土保持研究等多个领域提供依据[2,3]。早期研究主要采用人工方法辅助野外实地勘察获取地貌信息[4]。随着GIS和RS技术的发展,国内外学者开始研究地貌类型的自动或半自动划分方法。目前地貌类型自动划分方法主要包括:1)基于地貌单元的划分方法。主要有基于栅格单元[5-8]和面向对象[9-12]两种统计方法,前者会破坏地理实体的完整性,后者虽可在一定程度上保证地表单元的完整性,但基于图像分割技术划分的图像单元的地理意义不明确[13]。小流域作为自然形成的地理单元,在地表形态和地貌演变方面具有明确的地理意义,能够很好地契合地貌和水文之间的关系[13]。但目前研究多应用单一流域尺度[13-16],当流域单元过小时,虽能保证不同地貌类型分界处界线清晰,但易造成相同地貌单元被过度分割,导致分类结果破碎;若流域单元过大,不同类型的地貌单元可能被归并为同一地貌类型,即出现漏分现象,在地势起伏较大的山地会更明显。2)基于地形因子的划分方法。有学者应用绝对高程[17]、相对高程[18]或二者的组合[4,19]进行地貌划分,基本可以筛选出某地区的地貌类型,但未考虑微观地形单元;也有学者考虑到更多因子对地貌划分的影响,如利用海拔、坡度、平面曲率、剖面曲率等多个地形因子划分地貌类型[20],或者从地形因子统计量、特征点线统计量等方面选取地形因子[13,14],使地貌类型包含的信息量更丰富,但参与分类的因子太多会造成信息冗余,影响分类结果。
综上,在地貌划分单元选取中,为避免划分结果破碎或漏分现象,本研究拟采用双尺度流域单元对地貌类型进行划分:即先利用小流域单元提取出划分效果明显的不同地貌单元分界处,再采用较大流域单元对破碎地貌类型进行二次整合划分,保证不同地貌类型的异质性和相同地貌类型的同质性。另外,以往地貌划分方法通常只能处理单一或少量因子[1,8,21],而CART决策树作为典型的二叉树算法,可以处理非数值型数据,具有很强的稳健性和对多源数据的深度挖掘能力[22],在基于遥感数据的分类研究中取得了较好的分类结果[23-25],但目前鲜见利用该方法进行地貌自动分类研究。本研究为适应多个地形因子参与分类,选用CART决策树算法进行地貌划分,选取北回归线(云南段)地区为研究区域,基于ASTER GDEM 提取的多个地形因子进行最佳地形因子组合筛选,得出研究区主要地貌类型并进行检验,以期为研究区旅游开发、植被生长、气象研究等提供数据支持。
1 研究区及数据
北回归线(23°26′21″N)又名夏至线,是北半球热带和亚热带的分界线。本研究以北回归线在云南省穿过的县市作为研究区(简称“北回归线(云南段)”)(图1),包括临沧、玉溪、普洱、红河和文山5个州(市)的富宁、西畴、麻栗坡、砚山、文山、蒙自、个旧、石屏、红河、建水、元江、墨江、宁洱、景谷、双江、沧源、耿马17个县(市),总面积达54 074.95 km2。研究区自西向东跨越滇西纵谷区(属横断山脉南延带)、滇中高原和滇东高原(云贵高原组成部分),西部山河相间、纵列分布,无量山脉、哀牢山脉、澜沧江水系、元江水系等分布在此;中部高原地区地势起伏平缓,属滇中大面积块断式上升区,分布有蒙自坝、平远坝等;东部高原位于云南高原边缘地带,绝对海拔低、喀斯特地貌明显。丰富的地貌特征为验证本文方法在不同地貌分类中的适应性提供了条件支持。
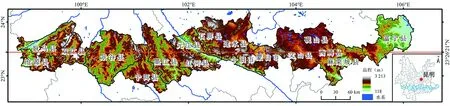
图1 北回归线(云南段)位置及高程分布
研究数据采用先进星载发射和反射辐射仪全球数字高程模型(ASTER GDEM)数据,由美国航天局(NASA)与日本经济产业省(METI)利用NASA新一代对地观测卫星TERRA的观测数据制作而成(http://www.gscloud.cn/),水平误差为30 m,垂直误差为20 m[26]。
2 研究方法
本文方法流程(图2)为:1)基于DEM数据进行地形因子提取,利用相应指标进行最佳地形因子组合计算;2)进行双尺度流域单元划分,以划分的小流域为单元对各因子进行分区统计;3)经流域单元统计后的各个最佳地形因子与以上因子的非监督分类结果(CART决策树分类的必需波段)合并,得到本文的待分类数据;4)将选取的训练样本数据(地貌类别)和多源地形因子数据(地貌属性)代入CART工具中进行自动运算,得到分类规则决策树;5)利用该决策树对待分类数据进行自动划分,可得研究区地貌类型分布图,并对分类结果进行检验。
2.1 最佳地形因子提取
综合考虑地貌的宏观和微观特征,并结合前人经验[7,19,27],选定高程(E)、地势起伏度(RF)、地表切割深度(SCD)、高程变异系数(EVC)4个宏观地形因子和坡度(S)、坡度变率(SOS)、地表曲率(SCV)3个微观地形因子以及可间接反映地势起伏度的光照模拟值(LSV)[19],各因子计算公式见式(1)-式(4)。以上地形因子均由DEM数据衍生得到,会存在信息冗余,在分类前需通过因子标准差和相关性计算进行筛选[28](标准差可反映地形因子对于均值的离散程度,值越大则灰度级分布越分散,包含的信息量越大;相关性能筛选出携带重复信息的地形因子,减少信息冗余,提高分类精度)。提取宏观地形因子地势起伏度时,需确定邻域统计单元的大小,本文采用均值变点法[29]计算得到其最佳分析窗口为14×14(1.76 km2)。
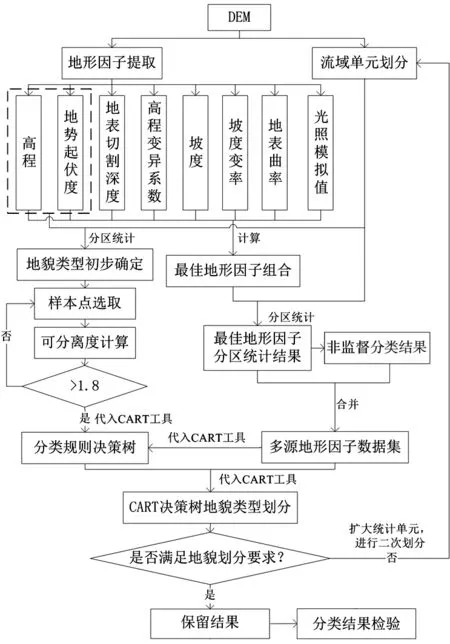
图2 技术流程
(1)
式中:Estd、Emean、Emax、Emin分别为统计窗口内的高程标准差、平均高程、最大高程和最小高程。
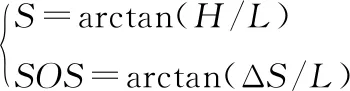
(2)
式中:H为垂直高差;L为水平距离;ΔS为坡度差。
SCV=CC×CP
(3)
式中:CC为平面曲率;CP为剖面曲率。
LSV=255×(cos(Z_r)×cos(S_r)+sin(Z_r)×sin(S_r)×cos(Azi_r-Asp_r))
(4)
式中:Z_r为太阳天顶角弧度,本文设定为45°;S_r为某点坡度的弧度;Azi_r为太阳光线方向角的弧度,本文设定为315°;Asp_r为某点坡向的弧度。
2.2 双尺度流域单元划分标准
最佳地形因子确定后,需利用流域单元对各因子进行分区统计。为避免地貌类型划分结果破碎或出现漏分现象,本文采用两种不同大小的流域单元(即双尺度流域单元)作为地貌划分基本单元,即先利用较小流域单元进行地貌类型初步划分,再利用较大流域单元对首次划分结果中的破碎地貌区域进行二次整合划分。因此,两次流域单元大小的确定是关键。结合前人经验[13-15],本文首次划分的较小流域单元采用定性方法确定,要求分割出的子流域能够基本涵盖山体的谷、脊线[15]。二次整合的较大流域单元采用定性和定量相结合方法确定,从定性角度讲,要求其对破碎地表单元有明显合并效果,且能兼顾地貌单元的完整性和内部同质性特征;从定量角度讲,选取高程和地势起伏度作为验证因子,利用Moran′sI(式(5))验证两地形因子在不同流域单元的地貌分类结果,确定出二次整合的最佳流域单元。验证标准为:两个地形因子的Moran′sI均位于[0,0.3]区间,表明同一地貌类型中各单元间差异性过高,位于(0.3,0.6]区间,各单元间相关性最佳,位于(0.6,1]区间,各单元间同质性过高。
(5)
式中:n表示研究空间的对象数目;wij为第i、j区域的空间权重数值,两者相邻为1,否则为0;xi和xj为对象i、j的属性值,x为该属性的平均值(即平均高程、平均地势起伏度)。
2.3 CART决策树构建
CART决策树[30]的核心思想是根据学习区域变量和目标变量,对原始数据集以二叉树的结构形式进行循环分析[24],通过计算Gini系数选取属性集中的某个属性作为二叉树的分类属性,并利用该属性将待分类样本集分为两个子集,重复执行此步骤,直到当前分类的样本集达到叶节点[25]。构建决策树需要合格的地貌类型训练样本和待分类数据集:本文待分类数据为多源地形因子数据,它包括经流域单元分区统计后的各个最佳地形因子及其非监督分类结果,利用GIS软件中的波段合成工具合并而得;下面进行地貌类型训练样本选取和可分离度计算,为便于地貌样本点选取,先对地貌类型进行初步确定。
2.3.1 地貌类型初步确定 目前关于中国地貌类型划分尚无统一标准,本研究主要参考沈玉昌等[31,32]的划分标准,并结合研究区的空间尺度和高原地形进行适当调整。综合考虑最终地貌划分结果的细致性、实用性及对划分方法验证的完备性,本文利用高程和地势起伏度将研究区划分为11种地貌类型(表1)。

表1 地貌类型划分标准
2.3.2 样本点选取 按照代表性、均匀性和一定数量原则对以上地貌类型进行训练样本选取,样本点选取标准为:各地貌类型样本的选取同等重要,面积越大,选取的样本点越多;在相似地貌类型(如中起伏中高山和大起伏中高山)样本点选取中,两者差异性明显区域增加样本点数量,相似性较高区域减少样本点数量。最终选取的样本点数量及面积如表2所示,其中小、中、大起伏低山3种地貌类型所占面积较小,可分离度太低,为不影响整体分类精度,将其合并为中起伏低山。
2.3.3 样本可分离度计算 选取J-M距离(式(6))[33]和转换离散度(式(7))确定不同地貌类型样本的可分离度,二者分别表示类别的可分离性和离散情况,取值范围均为[0,2]:当数值较小时,表明地物可分离性较差,需进行适当合并;数值越大,代表两类地物可分离性和离散性越强,当数值大于1.8时,可进行分类计算[33]。
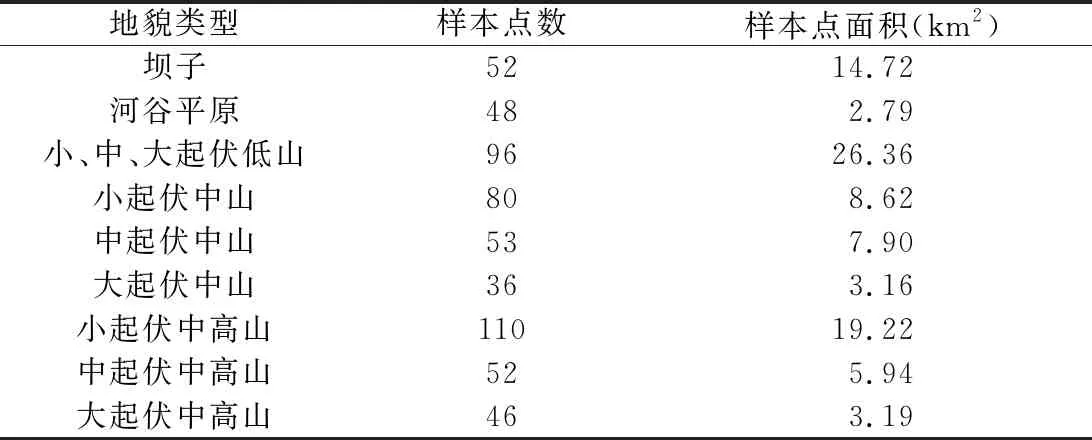
表2 各地貌类型样本点数量及面积
(6)
式中:B为c1、c2两种类别基于f特征的巴氏距离;m1、m2和σ1、σ2分别为c1、c2两种类别基于f特征的均值和方差[33]。
(7)
式中:i、j为要比较的两类;Ci为i类的协方差矩阵;μi为i类的均值向量;tr为求矩阵的迹。
2.4 分类结果检验
分类结果检验包括指标检验和人工判读检验两部分。指标检验中,除使用上述的Moran′sI外,还采用平均值和标准差评估结果的可靠性,前者用于检测地貌类型划分指标的准确性,后者可以检测不同地貌的异质性程度,海拔越高、地势起伏度越大,标准差越大。
3 结果与分析
3.1 最佳地形因子选取结果
通过地形因子相关性计算结果(表3)得出,相关性最大的地形因子是地表切割深度(SCD)和地势起伏度(RF),后者已被多数研究[6,8,18]选定为地貌划分的主要地形因子。由于不同因子的单位和值域不同,需先对其进行归一化处理,而后计算出高程(E)、高程变异系数(EVC)、地势起伏度(RF)、坡度(S)、坡度变率(SOS)、地表切割深度(SCD)、地表曲率(SCV)、光照模拟值(LSV)的归一化标准差分别为0.125、0.023、0.099、0.135、0.115、0.099、0.040、0.388,其中EVC和SCV的标准差明显低于其余地形因子,予以剔除。最终确定的最佳地形因子组合为:高程(E)、地势起伏度(RF)、坡度(S)、坡度变率(SOS)、光照模拟值(LSV)。
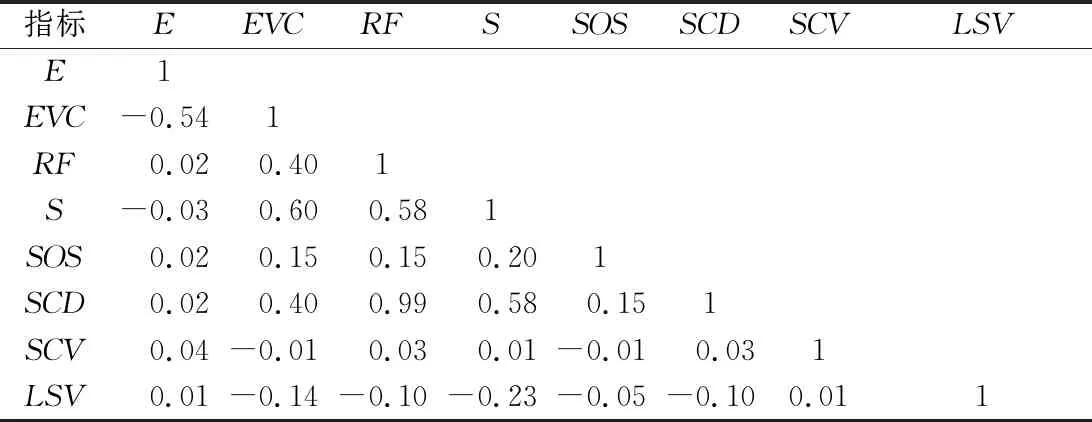
表3 地形因子相关性系数
3.2 双尺度流域单元地貌类型划分结果
3.2.1 双尺度流域单元划分 由不同流量阈值下地貌划分单元地形因子的Moran′sI(表4)可知,当流量阈值从500增至1 000时,除中起伏中山的高程和中起伏中高山的地势起伏度外,其余地形因子的Moran′sI呈增加趋势,表明相关性随着流域单元的扩大而增大;阈值从1 000增至2 000时,除坝子和河谷平原外,其余地形因子的Moran′sI仍呈增加或不变趋势,即相关性仍在提高;阈值从2 000增至3 000时,多数地形因子的Moran′sI出现下降(部分降至0.3以下),少部分呈上升趋势(大于0.6),可见流量阈值为2 000时的流域单元划分效果最好,此时Moran′sI多在(0.3,0.6]区间内。综上,结合定性和定量两种标准,本研究确定流量阈值为500时划分的流域单元为第一次地貌划分统计单元,此单元足够小且基本包含地貌单元的谷、脊线,流量阈值为2 000时划分的流域单元为第二次地貌统计单元,归并两次分类结果得出北回归线(云南段)地区的地貌类型划分单元(图3,彩图见附录4)。

表4 不同流量阈值下地貌划分单元地形因子的Moran′s I
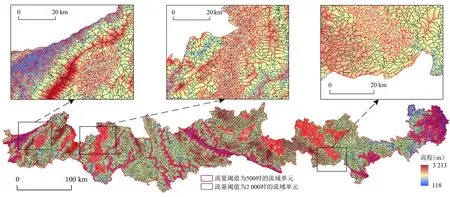
图3 流域单元划分结果
3.2.2 CART决策树构建及双尺度流域单元地貌类型划分
(1)由表5可知,各地貌类型样本的可分离度均大于等于1.8,故可用该样本构建CART决策树(图4)。首先,基于流量阈值为500的小流域单元分区统计高程、地势起伏度、坡度、坡度变率、光照模拟值及其非监督分类结果(图5,彩图见附录4),合并为多源地形因子数据;然后,运行决策树模型对多源地形因子数据进行划分(图6,彩图见附录4),可以看出,基于流量阈值500的流域单元分类结果基本可识别出研究区地貌类型特征,坝子、河谷平原、中起伏低山和部分小起伏中山的划分效果较好,地貌单元集中连片,破碎化程度低,地貌类型间界线明显,但剩余地貌类型明显存在破碎化程度高、山地被过度分割情况,在滇中、滇东高原交界地带和西部纵谷地区尤为明显。
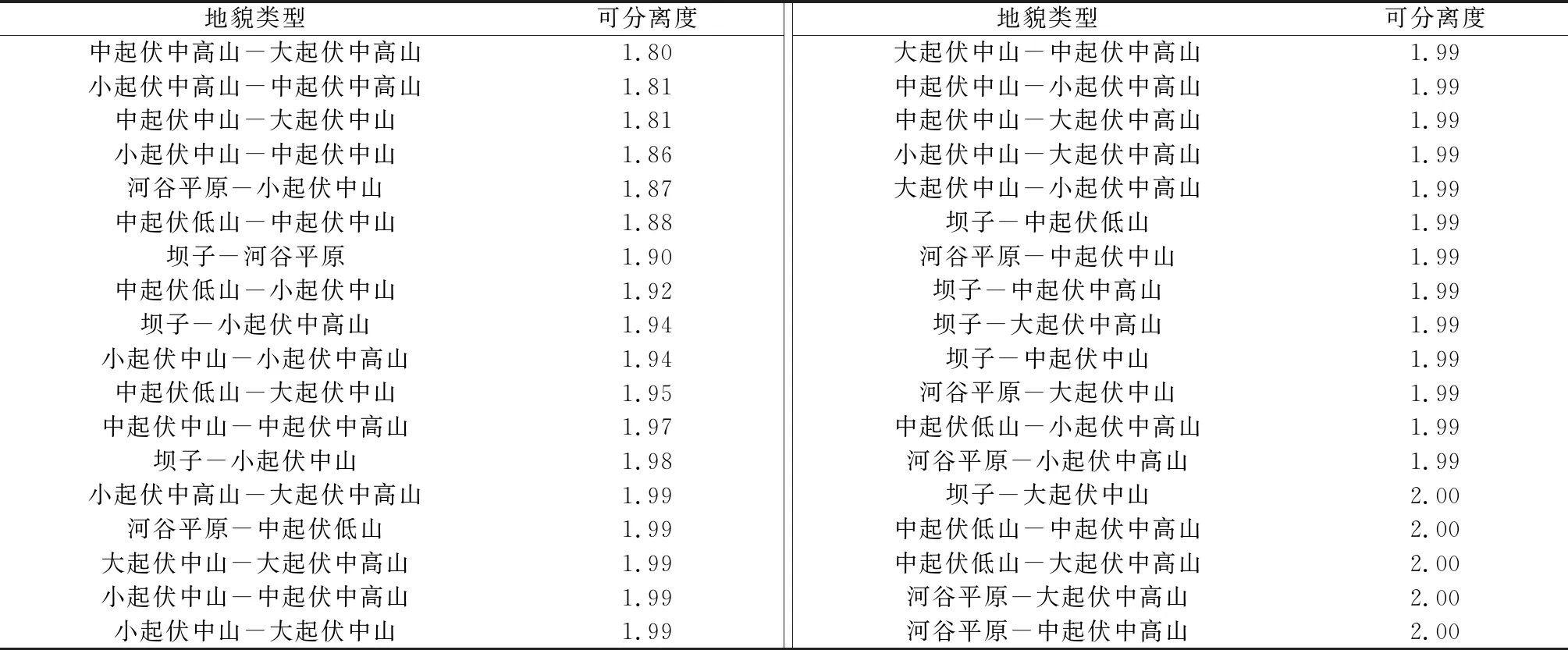
表5 不同地貌类型可分离度计算结果
(2)保留坝子、河谷平原、中起伏低山、部分小起伏中山等分类效果较聚集和地貌类型分界较明显区域,进而对过于破碎的地貌单元区扩大统计单元进行二次划分(图7,彩图见附录4)。可以看出,第二次划分结果中的破碎地貌类型区有明显合并效果,且符合客观实际,两次划分结果地貌类型分布位置基本一致。但受研究区本身地貌形态和算法分类误差影响,小起伏中山和中起伏中山、小起伏中高山和中起伏中高山、中起伏中高山和大起伏中高山等相似地貌单元交错分布,在西部纵谷地区尤为明显。这也符合实际的地貌特征,即相邻地貌类型之间存在交错分布。

图4 地貌分类规则决策树
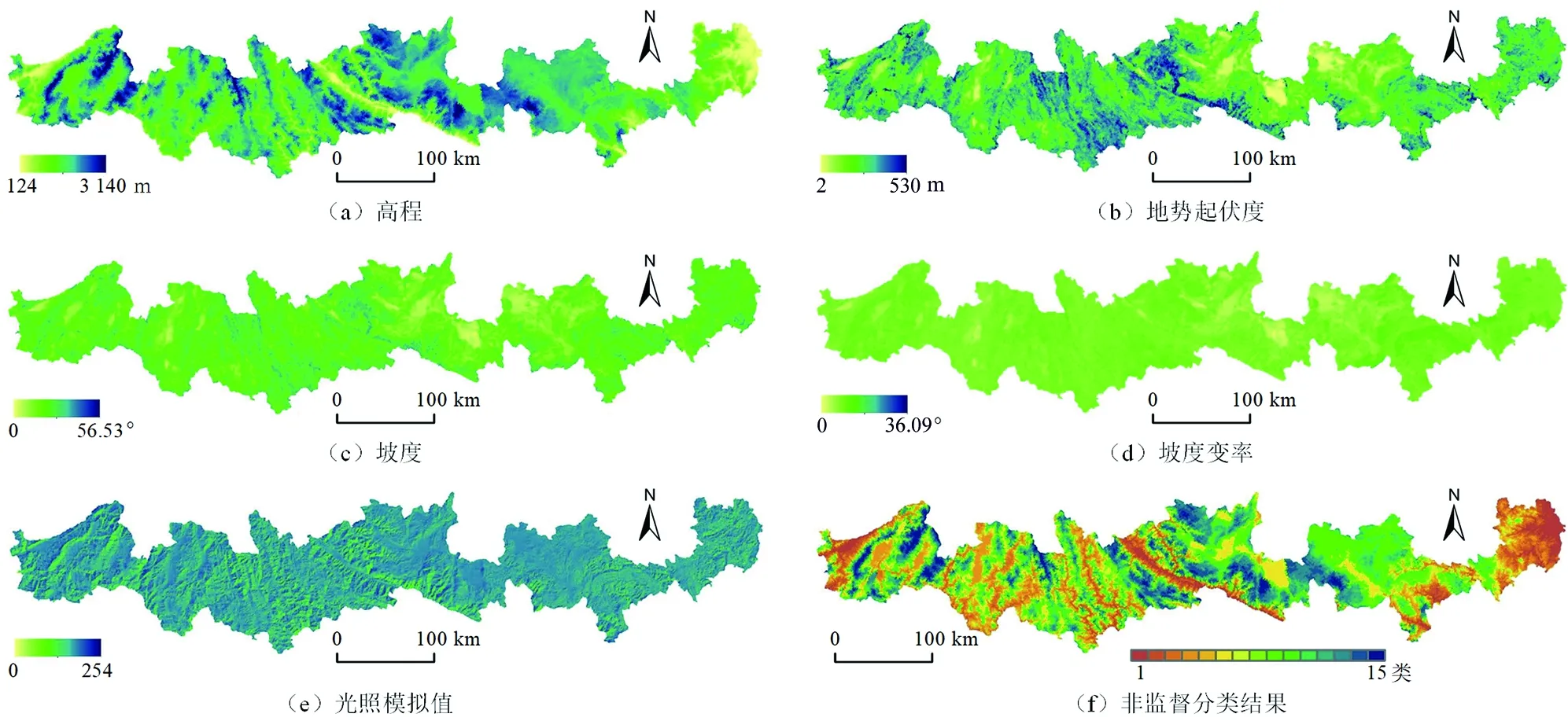
图5 地形因子统计结果
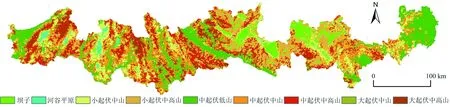
图6 地貌类型划分结果(流量阈值为500的流域单元)
(3)由北回归线(云南段)地区地貌类型划分结果(图7)可以看出,研究区地貌类型以山地为主,其中小起伏中高山占比最高,主要分布在滇中、东高原区,分属滇中大面积块断式上升、滇东穹隆式上升区[34],符合实际地貌特征;其次为中起伏低山,主要分布在东部的富宁县和西部低谷地(如元江谷地、南汀河谷地等)两侧,两地海拔低,地势有一定起伏,地貌类型主要为中、小起伏低山,与划分结果一致;中起伏中山占比居第三,主要分布在西部纵谷区和滇中、东高原过渡区(富宁县西部、麻栗坡县、西畴县),地势变化较大,且海拔相对较高,紧邻小起伏中山和中起伏低山,侧面说明CART决策树算法划分结果较科学,相似地貌类型在空间上具有相邻和过渡性质;剩余山地地貌类型有大起伏中山、中起伏中高山和大起伏中高山,主要分布在西部纵谷区,该地是横断山脉帚形地带的扩展部位,受新老构造运动影响,地势起伏最大[34],地貌多样且变化频繁。由此可见,本文山地地貌类型划分结果符合北回归线(云南段)地区实际地貌特征。平原地貌(坝子和河谷平原)中,坝子主要分布在石屏、建水、个旧、蒙自、文山、砚山等中东部高原地区,较为明显的蒙自坝、平远坝、建水坝均被识别;河谷平原主要分布在西部河谷地区,受水流作用影响,呈狭长形纵列分布在山地中间。

图7 北回归线(云南段)地区地貌类型分布
3.3 分类结果评估
3.3.1 指标检验 进一步计算不同地貌类型高程和地势起伏度的平均值、Moran′sI和标准差[9](表6)。可以看出,9种地貌类型的高程和地势起伏度均值都在规定的划分标准内,表明对分类指标的划分基本准确;9种地貌类型的Moran′sI均大于0,说明划分结果在相同地貌类型内具有空间同质性,但中起伏中山、小起伏中高山的Moran′sI值较大,表明这两类地貌单元可能存在一定过分割现象;随着地势起伏度和高程增大,对应地貌的标准差逐渐增大,说明不同高程和地势起伏度的地貌间具有异质性特征。
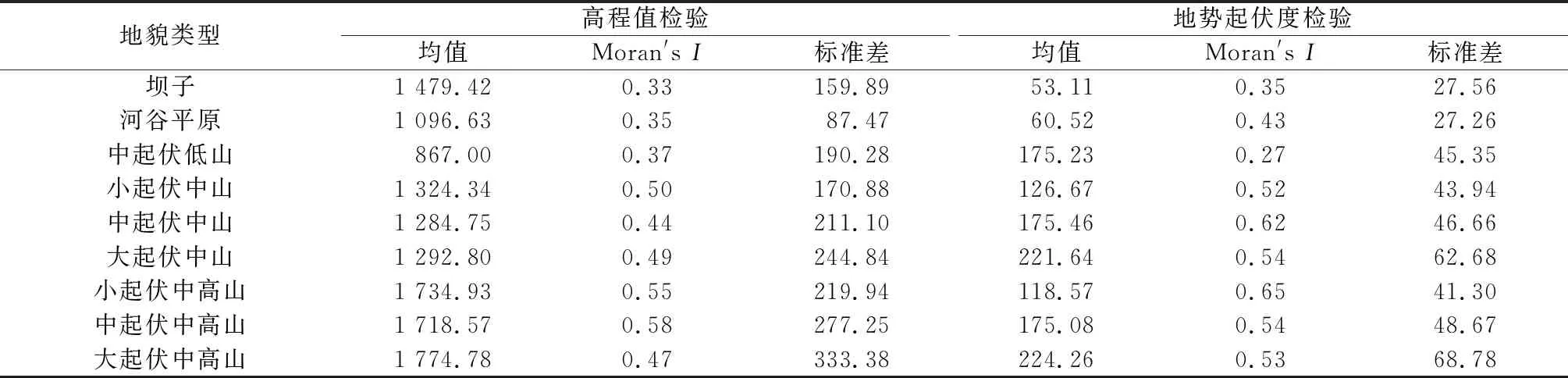
表6 地貌类型划分结果参数检验
3.3.2 人工判读检验 从划分的地貌单元中随机抽取140个小流域,将人工判读结果与CART决策树分类结果相比较(表7、表8),140个小流域有115个自动分类结果与人工判读结果一致,总体精度达到82.1%,Kappa系数为0.793。 25个错误分类点中7个分布在中、东高原地区,18个分布在西部纵谷地区,可见该方法对不同地貌类型的判别精度略有差别,对破碎程度小、地势起伏小、异质性强(河谷平原、中起伏低山、小起伏中山、小起伏中高山)的地貌划分效果较好,精度可达85%以上;对破碎程度高、异质性差(中起伏中山、大起伏中山、中起伏中高山、大起伏中高山)的地貌划分效果稍差,但精度基本也在70%以上。整体而言,本文方法是地貌类型划分的一种可行方法。
4 结论与讨论
基于ASTER GDEM 30 m空间分辨率数据,利用最佳地形因子组合、双尺度流域单元划分、CART决策树算法对北回归线(云南段)地区主要地貌类型进行划分,并对结果进行检验,主要结论如下:1)研究区地貌划分最佳地形因子组合为高程、地势起伏度、坡度、坡度变率、光照模拟值;研究区主要地貌为山地(占比93.39%),其中小起伏中高山占比最高,坝子和河谷平原仅占6.61%;研究区双尺度流域单元划分的最佳流量阈值分别为500、2 000。2)利用平均值、标准差、Moran′sI和人工判读结果对分类结果进行检验,结果显示:基于CART决策树的双尺度流域单元地貌类型划分方法具有较高的自动化程度和精确度,在北回归线(云南段)地区总体精度可达到82.1%,Kappa系数为0.793,能够准确识别出地貌类型空间分布特征,是地貌类型划分的一种可行方法。
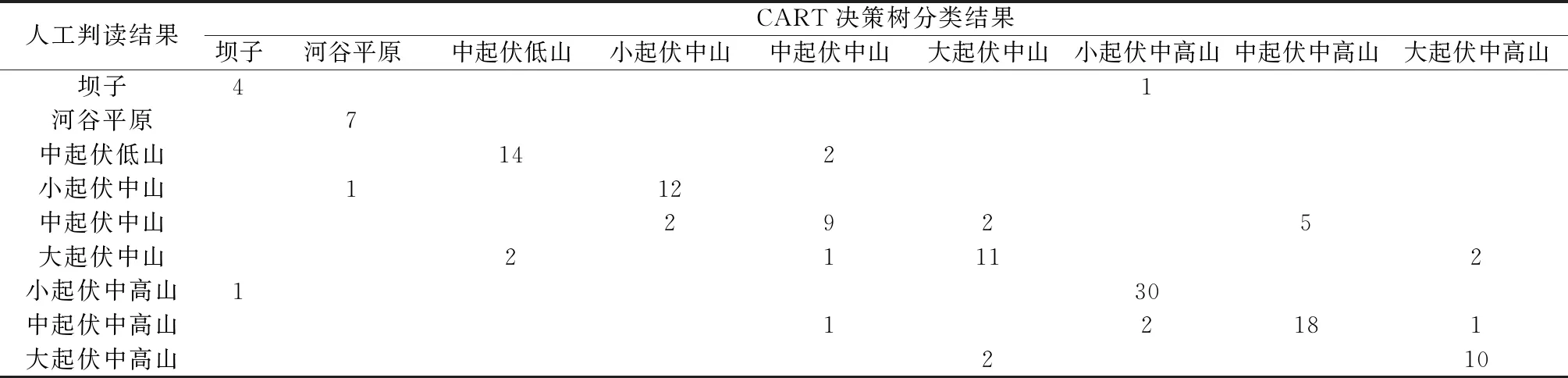
表7 CART决策树分类结果与人工判读结果的混淆矩阵
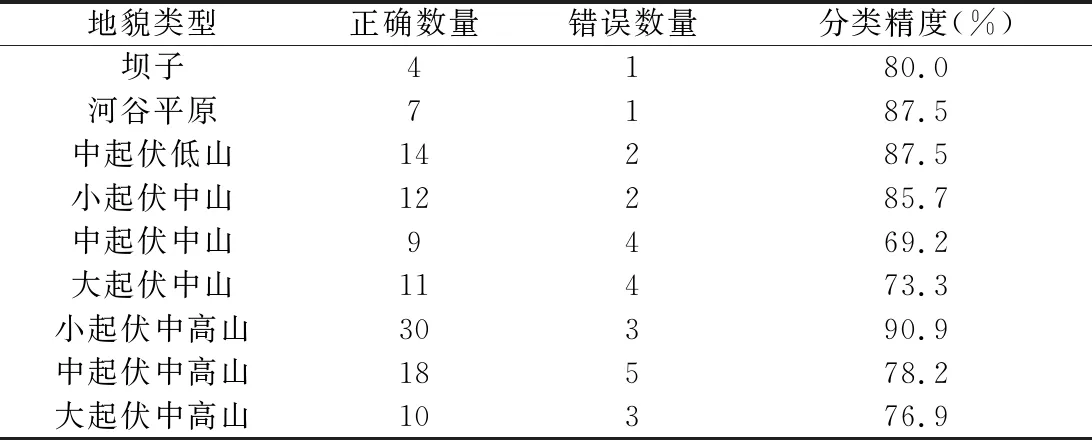
表8 不同地貌类型分类精度
本文双尺度流域单元综合考虑地貌划分的细分性和完整性,提高了两者在地貌划分中的兼容性;利用CART决策树算法对多个地形因子数据进行深度挖掘,综合考虑多个地形因子对地貌划分的影响,减少分类节点选择时主观因素的影响[35],在保证分类结果科学性的同时也具有操作简便性。但研究中仍存在不足之处:1)CART决策树的分类结果对训练样本依赖性较强,样本选取会直接影响分类结果的准确性,这也是监督分类中难以避免的问题。2)在地貌变化复杂区域存在对少量相似地貌类型的误判,除受地貌形态复杂影响外,也受流域单元划分大小的影响,“中山”、“中高山”单元划分可能存在过度分割。今后需深入研究如何为不同地貌类型寻找合适的地貌划分单元,以及如何应用更加完备的定量方法得到最佳地貌划分单元。另外,本研究为双尺度流域单元划分,在其他地区也可根据实际情况进行多尺度流域单元划分。
