基于图拉普拉斯变换和极限学习机的时间序列预测算法
2021-04-15邹小云
邹 小 云
(湖北职业技术学院公共课部 湖北 孝感 432000)
0 引 言
在许多领域内均存在多元的时间序列数据[1],如互联网中服务器的通信流量数据、虚拟现实技术的人体运动捕捉数据[2]和病人的脑电波实时监测数据等。多元时间序列一般伴随着高维数据的属性,导致多元时间序列的预测难度升高,且难以在合理的时间内取得理想的预测准确率[3]。
目前研究人员大多以时间为约束条件,以最大化预测准确率为研究目标,设计了不同的多元时间序列预测算法。文献[4]提出了基于无核相关向量机的多元时间序列预测算法,利用无核相关向量机不受核函数约束的特性,构建了高维特征空间。但无核相关向量机的非线性拟合能力不足,导致多元时间序列的预测准确率较低。文献[5]通过因子分析提取高维储备池状态矩阵的公因子,利用降维后的因子变量与期望输出之间的线性回归关系,求解神经网络的未知参数。文献[6]采用集群卷积神经网络对多元时间序列进行预测,提出了训练阶段新的数据结构,通过协方差矩阵对时间序列进行快速分类。该网络通过卷积运算和下采样自动对时间域特征和空间域特征进行选择,获得了较好的预测效果。但该网络模型需要实时更新卷积层参数、隐层单元数量和权重向量等超参数,训练时间过长。文献[7]通过递归神经网络预测多元时间序列的类别,该算法的准确率较高,但是对每个新到达时间序列需要很多轮数才能达到收敛。总体而言,基于神经网络的预测算法具有学习能力强的优势,但存在网络参数学习难度大的问题。当前的时间序列学习方法大多基于前馈神经网络实现,并通过梯度下降法和后向传播算法实现在线地学习和更新,但梯度下降法和后向传播需要很长的训练时间和复杂的参数调节。
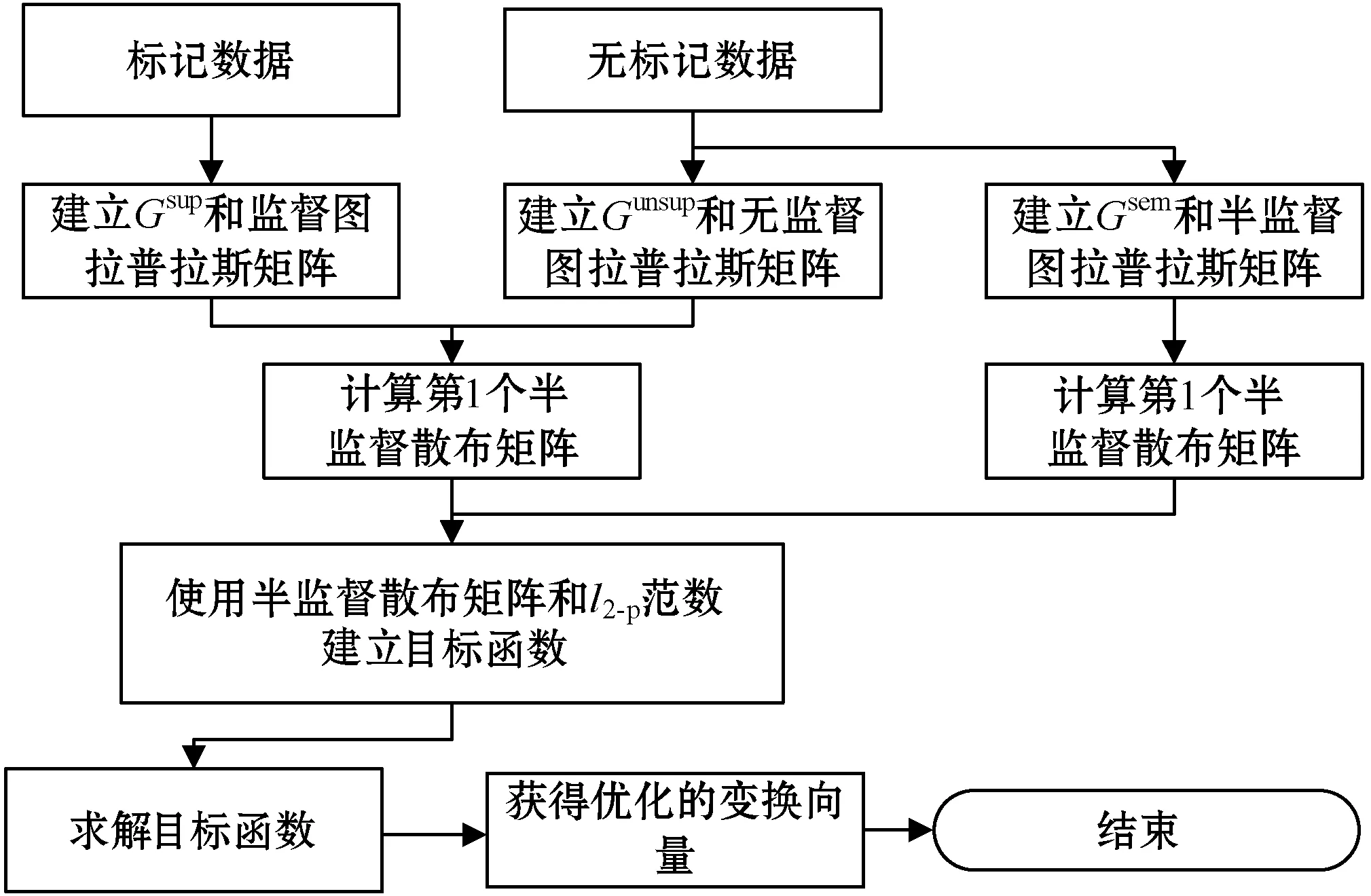
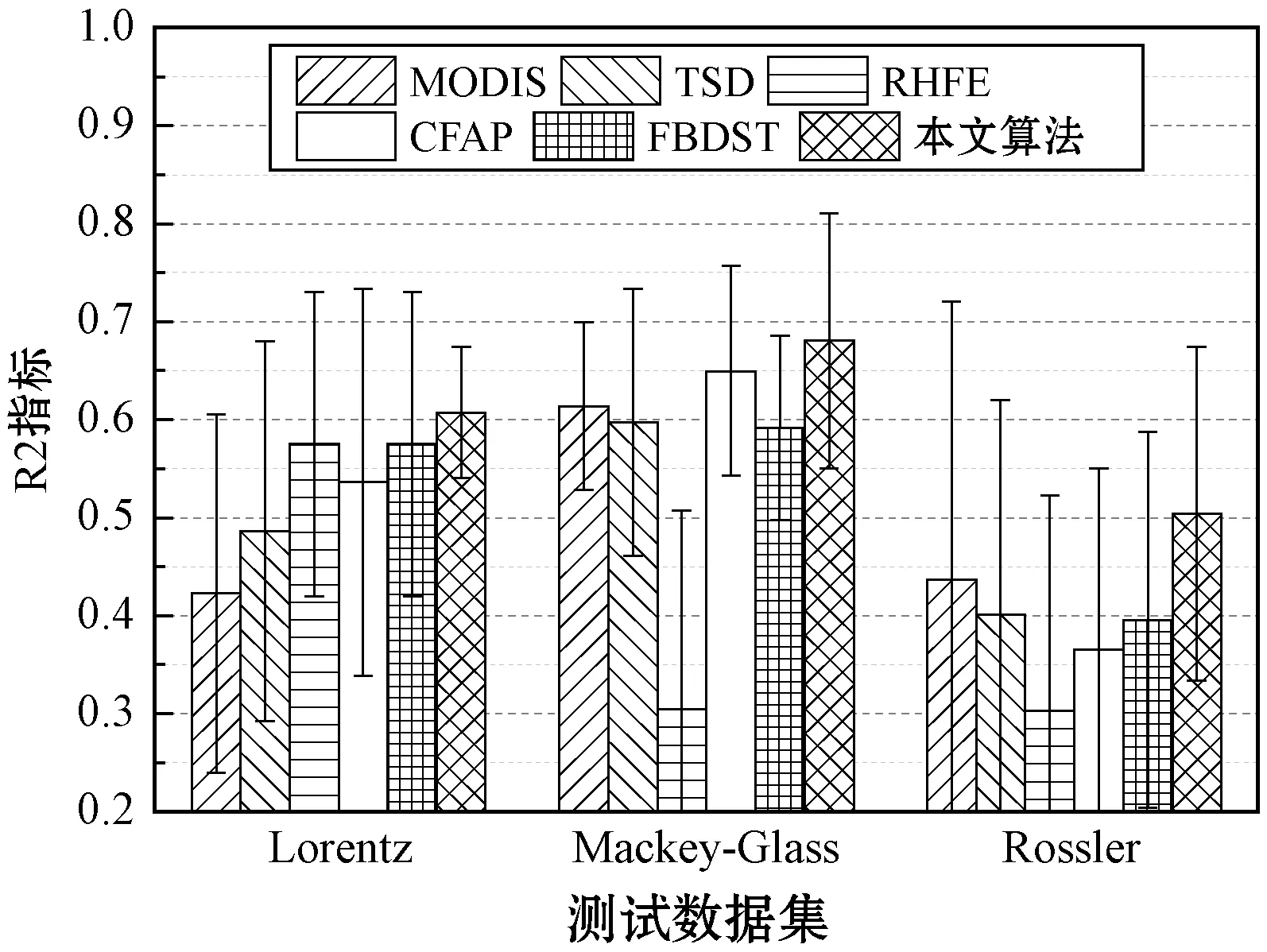
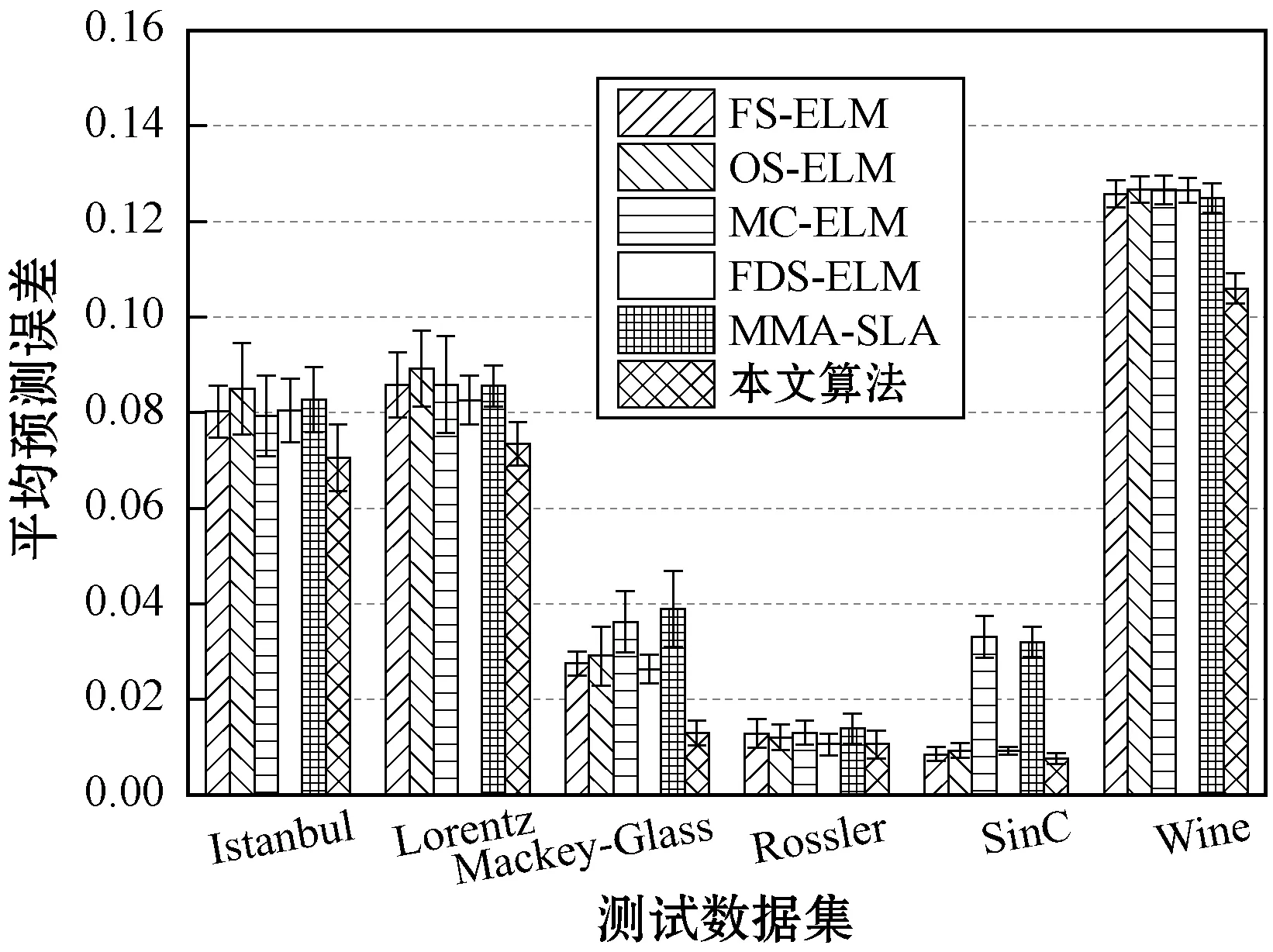
为了解决上述问题,本文提出了基于图拉普拉斯特征提取和极限学习机(Extreme Learning Machine,ELM)在线学习的多元时间序列预测算法。将标记观察样本和无标记观察样本分别构建图拉普拉斯的散布矩阵,再利用图拉普拉斯相关理论提取时间序列的特征子集。设计了新的时间序列在线极限学习机,该模型随机初始化隐层单元数量,在线学习程序通过最小二乘法递归地逼近问题最优解,从而更新网络的输出权重。在线学习过程中仅需要学习和更新隐层和输出层之间的权重即可完成训练。本文的贡献主要如下:(1) 提出基于图拉普拉斯的稀疏特征选择方法,利用凸l2-p范数(p=1)和非凸l2,p范数(0 本文基于图拉普拉斯建模特征学习问题[8],计算特征选择的稀疏变换向量,采用l2-p范数保证向量的稀疏性,使其符合特征选择的问题模型。图1是时间序列特征提取流程。设X=[x1,x2,…,xl,xl+1,…,xn]T∈Rd×n为训练数据矩阵,X=[x1,x2,…,xl]T∈Rd×l为X的标记训练数据,n为训练数据的数量,l为标记训练数据的数量。xi∈Rd(1≤i≤n)表示第i个训练样本,Y=[y1,y2,…,yl]T∈Rl表示训练数据的标记向量,yi∈R(1≤i≤l)为第i个标记样本的标记。定义W∈Rd为特征选择问题的变换向量。 图1 时间序列特征提取流程 将l2-p范数引入图拉普拉斯矩阵,以实现降维处理,目标函数定义为: (1) 第1个散布矩阵定义为图拉普拉斯的监督散布矩阵和无监督散布矩阵的结合,其计算式为: (2) (3) 式中:Lunsup∈Rn×n为训练数据的无监督图拉普拉斯矩阵。基于全部数据建立近邻图Gunsup,每个节点对应一个观察数据。如果xi属于xj的k-近邻,或者xj属于xi的k-近邻,则在两个样本间建立连接。图Gunsup中边权重的计算式为: (4) (5) 式中:Lsup∈Rl×l为标记数据的监督图拉普拉斯矩阵。 基于标记数据建立监督近邻图Gsup,每个标记数据为一个节点,根据观察样本的标记信息在相似的样本之间建立连接。图Gsup的权重矩阵Ssup定义为: (6) 第2个散布矩阵定义为: M2=XLSemiXT (7) 式中:Lsemi∈Rn×n为半监督图拉普拉斯矩阵,表示标记数据的标记信息和局部结构信息。为了计算半监督图拉普拉斯矩阵Lsemi,首先使用所有数据建立近邻图Gsemi,图Gsemi的权重矩阵Ssemi定义为: (8) 式中:dist为每对样本的距离矩阵,其定义为: (9) (10) 通过拉格朗日乘法求解式(10)的优化问题,式(10)转化为: (11) 式(11)对W求导,可得: (12) 式(12)说明W为R=M+(2/p)λD的特征向量,“∧”为特征值。目标问题是最小化式(1)的问题,即选择特征值最小的特征向量来最小化目标函数。 算法1是计算l2-p范数的迭代搜索求解算法,其中,第5行迭代地求解了l2,p范数的最小化问题。 算法1l2-p范数的迭代搜索求解算法 输入:训练数据X∈Rd×n,标记训练数据X∈Rd×l,标记训练数据的标记向量Y∈Rl,泛化参数λ。 输出:选择的特征。 //式(3) //式(5) 3. 计算半监督散布矩阵M1和M2; //式(2)和式(7) 4. 初始化:t=0,Wt∈Rd; //随机初始化Wt 5. while未达到收敛条件do 计算对角矩阵: Rt=M+(2/p)λDt; 更新Wt+1=r1; //r1为Rt的特征向量 t=t+1; end while 计算无监督图拉普拉斯矩阵的复杂度和半监督拉普拉斯矩阵的复杂度均为O(n2),Rt特征分解的复杂度为O(d3),特征排序的复杂度为O(dlogd)。因此特征选择的总体复杂度为O(n2)+O(d3)+O(dlogd)。 考虑一个单层前馈神经网络的ELM模型: (13) 式中:gi(·)对应第i个隐层单元的激活函数G(ai,bi,x);x∈Rd,βi∈Rm,d为输入层节点的数量,m为输出层节点的数量;L为隐层节点的数量;ai为输入层和隐层的连接权重;bi为输入层偏差向量;βi为隐层和输出层的连接权重。gi定义为: gi=G(ai,bi,x)=g(ai·x+bi) (14) 式中:ai∈Rd,bi∈R。采用径向基激活函数(Radical Basis Function,RBF),其计算式为: (15) 式中:ai∈Rd,bi∈R。假设共有N个实例(xi,ti)∈Rd×m,网络的输出oj定义为: (16) 式中:j=1,2,…,N。 (17) 式中:j=1,2,…,N。式(17)的广义形式为: Hβ=T (18) (19) (20) (21) 式(18)中:H为隐层输出的矩阵,H的第i列对应第i个单元的输出;x1,x2,…,xN为输入。h(x)=G(a1,b1,x),G(a2,b2,x),…,G(aL,bL,x)为隐层的特征映射函数。 本文将隐层单元的数量设为随机数,所以通过最小二乘解直接估计权重向量βi,训练ELM网络的目标等价于寻找线性系统Hβ=T的最小二乘解βms: (22) 一般情况的隐层单元数量远小于数据量,即L< βms=H†T (23) 式中:H†表示H的Moore-Penrose广义逆矩阵。 在线ELM通过式(23)计算矩阵βms,Moore-Penrose广义逆矩阵的计算式为: H†=(HTH)-1HT (24) 将式(24)代入式(23),矩阵βms变为: βms=(HTH)-1HTT (25) (26) (27) (28) 其中:Tk+1和Hk+1定义为: (29) (30) 在线ELM的学习程序总结为以下5个步骤: ① 初始化阶段。估计时间k的初始化矩阵βk,通过计算协方差直接估计Rk。 ④ 在网络中传播状态βk和误差协方差矩阵。 ⑤ 校准网络的状态βk和误差协方差矩阵。 实验环境为PC机,Windows 10操作系统,Intel Core i5处理器,主频为3.10 GHz,内存为8 GB。编程环境为MATLAB R2014b。 选择6个公开的多元时间序列数据集作为本文的benchmark数据集,如表1所示。将SinC之外的5个数据集属性值均归一化为[0,1]区间,SinC数据集的属性值归一化为[-1,1]区间。按照50%、25%和25%的比例将每个数据集分别划分为训练集、验证集和测试集。 表1 数据集的基本属性信息 网络的训练程序和测试程序均采用根均方误差(RMSE)作为评价指标,其计算式为: (31) 每组参数的实验重复若干次,使实验结果的置信度达到α=0.05。实验将本文算法的参数t设为0.1,μ设为1(两个散布矩阵重要性相同),参数p设为0.5。基线学习机隐层节点数量等于数据集的维度。 采用3个维度较高的时间序列数据集Lorentz、Mackey-Glass和Rossler数据集验证本文特征选择算法的降维效果,选择几个支持时间序列特征选择的算法作为对比方法。对比方法分别为:MODIS[9]、TSD[10]、RHFE[11]、CFAP[12]和FBDST[13]。其中:MODIS采用随机森林估计每个特征的重要性得分,再利用Jeffries-Matusita距离度量每个时间序列的类分离性;TSD通过时间序列的特征判别能力将选择判别能力强的特征子集;RHFE是一种基于直方图统计的时间序列特征选择算法;CFAP是一种支持海量数据的时间序列特征选择算法;FBDST是一种基于标记符号检测的时间序列特征选择算法。 采用4个分类指标评价特征选择的效果,包括:预测活动值R2、RMSE、平均绝对误差(Mean Absolute Error,MAE)和一致性相关系数(Concordance Correlation Coefficient,CCC)。 R2的计算式为: (32) MAE的计算式为: (33) 式中:n为测试集的样本数量。 CCC的计算式为: (34) R2和CCC的值越大说明时间序列预测算法的性能越好,MAE和RMSE的值越小说明性能越好。 图2所示为时间序列特征选择算法提取的特征数量。可以看出本文算法对于3个时间序列提取的特征数量均低于其他对比算法。因此,本文基于图拉普拉斯的特征选择算法具有较好的降维效果。图3所示为不同算法对3个时间序列的分类准确率结果。可以看出,本文算法的MAE和RMSE值均低于其他5个对比算法,而R2和CCC值均高于其他5个对比算法,说明本文算法的分类性能优于其他5个特征选择算法。综合特征选择的实验结果可得出结论:本文算法对时间序列实现了较好的降维效果,并且有助于后续的分类处理和预测处理。 图2 时间序列特征选择算法提取的特征数量 (a) R2指标 采用表1的6个时间序列数据集验证本文时间序列预测算法的预测效果,选择5个预测性能优秀的算法作为比较方法,分别为:FS-ELM[9]、OS-ELM[10]、MC-ELM[11]、FDS-ELM[12]和MMA-SLA[13]。FS-ELM将随机森林和极限学习机结合。OS-ELM通过选择判别能力强的特征,提高极限学习机的效率和泛化性能。MC-ELM引入直方图建模时间序列的走势,对噪声具有较强的鲁棒性。FDS-ELM也是一种将特征选择和极限学习机结合的算法,增强了极限学习机的效率和泛化性能。对比方法的模型采用对应文献内推荐的参数。 MMA-SLA对单层前馈神经网络进行了进一步的简化处理,其实验结果表明该网络对时间序列的预测效果优于许多经典的网络模型。 为了观察激活函数对极限学习机预测性能的影响,实验中极限学习机和MMA-SLA分别在RBF和Sigmod两种激活函数的网络模型下完成了预测实验。图4所示为时间序列预测实验的结果,本文算法对Istanbul、Lorentz、Mackey-Glass、Rossler和Wine共5种数据集的平均预测误差均明显低于其他5种算法,并且两种激活函数获得了相同的结论。本文算法对于SinC数据集的平均预测误差和FS-ELM、OS-ELM、FDS-ELM较为接近,SinC数据集的维度较低(仅为2),本文算法的特征选择程序未能发挥作用。 (a) RBF激活函数 为了提高多元时间序列预测算法的预测准确率,提出基于图拉普拉斯变换和极限学习机的时间序列预测算法。将标记观察样本和无标记观察样本分别构建图拉普拉斯的散布矩阵,再利用图拉普拉斯相关理论提取时间序列的特征子集。设计了新的时间序列在线极限学习机,在线学习程序通过最小二乘法递归地逼近问题最优解,从而更新网络的输出权重。 本文的特征选择程序和后续的极限学习机程序是两个分离的模块,未来将研究把特征提取的迭代程序和极限学习机的迭代程序融合,从而提高总体的学习速度并降低迭代的次数。1 多元时间序列的特征选择
1.1 基于图拉普拉斯的特征选择问题模型
1.2 时间序列的特征选择模型
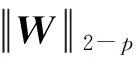

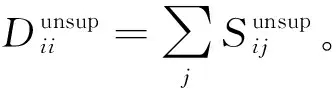
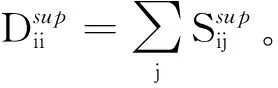
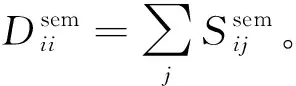
1.3 多元时间序列的特征选择
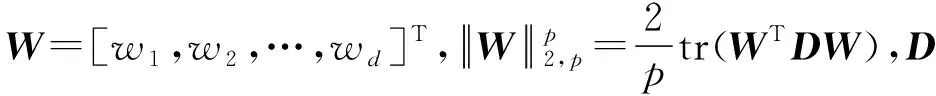
2 时间序列的极限学习机
2.1 极限学习机
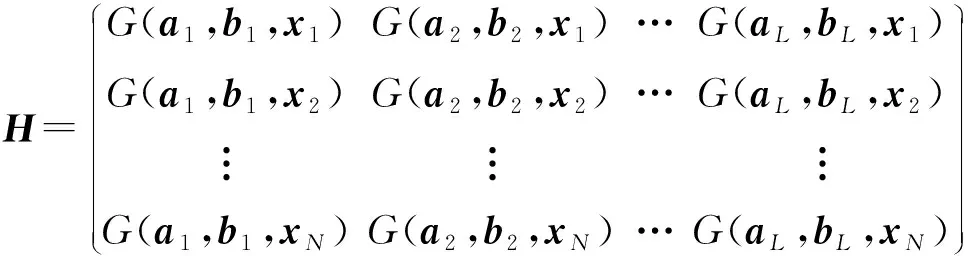
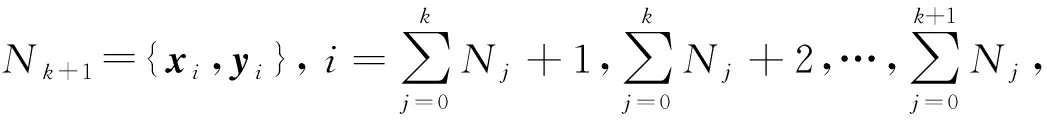
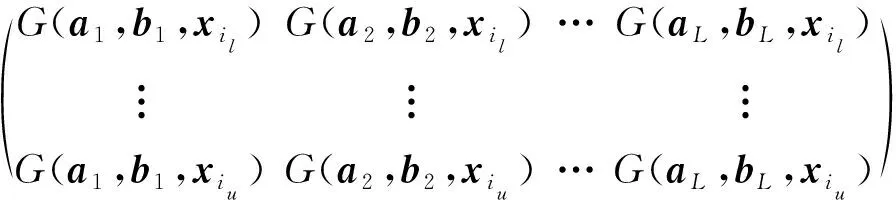
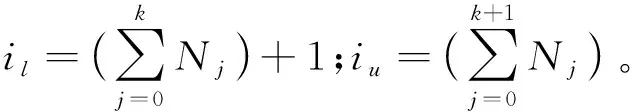
3 在线ELM的学习算法


4 实 验
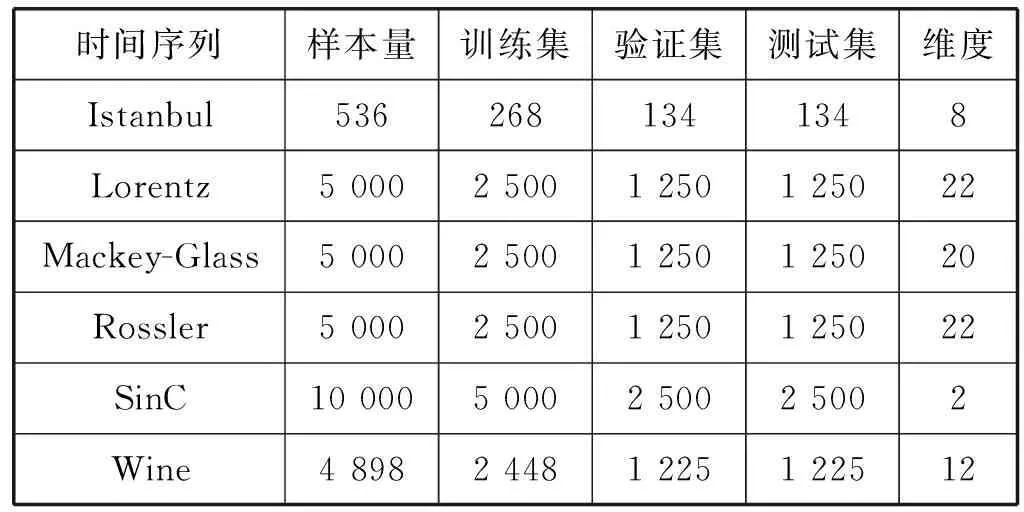
4.1 实验方法和参数设置
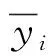
4.2 多元时间序列的特征选择实验
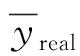

4.3 时间序列的预测性能实验
5 结 语
