决策树模型预测Spark SQL作业执行时间的方法
2021-04-15吴恩慈
吴 恩 慈
(上海淇毓信息科技有限公司 上海 200120)
0 引 言
Spark SQL借助核心引擎将集群规模扩展到数千个节点,Catalyst提供了基于规则和代价的优化器,把数据仓库的计算能力推向新的高度。但在超大规模数据集上存在易用性和可扩展性的问题,SQL或Dataset程序在执行之前被解析成逻辑计划,然后生成可执行的物理计划,不同的执行计划对性能有很大的影响。若能够准确预测作业的执行时间,可以更加充分地运用作业运行时获取的数据,动态地选择一个最佳的物理执行计划。例如基于作业运行时Shuffle信息,根据机器学习模型预测结果自动为每个作业设置合适的Shuffle Partition值,调整可能发生数据倾斜的任务并行度,动态地调整执行计划,能够有效提升集群性能。
1 相关工作
文献[1]研究了预测Hadoop分布式存储系统中查询执行时间的方法,采用KCCA统计模型关联查询输出大小与执行时间,通过最近的类似查询的性能预测作业执行时间。文献[2]提出了一种混合模型估计不同类型算子的性能,在关系型数据库中有良好的表现。文献[3]使用样本数据模拟集群中不同节点的执行性能,存在Shuffle开销的IO密集型作业的预测精度较低。文献[4]提出了一种多元线性回归方法,根据Spark性能指标预测集群性能,模型指标R2小于平均值。文献[5]研究了更改Spark集群配置参数对性能的影响,在模型训练阶段捕获关键性能指标,允许用户询问配置参数对性能的影响。文献[6]通过分析MapReduce任务执行过程中收集的数据,提出两阶段回归方法预测任务的完成时间。文献[7]提出了一种Spark应用程序的预测框架,使用非负最小二乘法匹配给定数据的最佳模型和参数。
本文通过决策树回归模型预测作业执行时间的方法不同于上述文献,本文基于Spark分布式计算引擎,提取作业特征与选择指标时考虑了SQL作业存在的宽依赖、各阶段间Shuffle开销,以及集群的弹性配置。通过训练决策树及其组合算法生成的机器学习模型能够准确地预测作业的执行时间,主要完成了三方面的工作:(1) 研究了作业调度策略与计算引擎,基于核心引擎构建机器学习应用模块,使复杂的模型训练与测试过程都变得易于实现。(2) 提供了模型的运行原理与特征数据的收集方法,通过Pipeline机制构建机器学习模型工作流。(3) 通过交叉验证方法进行超参数调优,采用剪枝和组合算法优化过度拟合问题,确保在训练集上训练出泛化能力较强的模型。
2 调度策略与计算引擎
2.1 作业调度策略与流程
机器学习模型的训练需要在多次迭代后获得足够小的误差才会停止[8]。Spark任务调度策略简化了机器学习模型训练和测试的过程,DAG Scheduler实现了相关组件在内存中无缝集成与任务协调,根据依赖对Pipeline进行优化实现对作业并行计算。应用程序获取计算资源的策略包括两种,一种是把应用程序运行在尽可能多的Worker上,能够充分使用集群资源,有利于数据处理的本地性;另一种是应用程序运行在尽可能少的Worker上,适合CPU密集型而内存使用较少的场景。如果任务处于作业开始的调度阶段内,对应的RDD分区首选运行位置的数据本地性为Node Local;如果任务处于非作业开头的调度阶段,根据父调度阶段运行的位置得到首选位置,若Executor处于活动状态,数据本地性为Process Local。
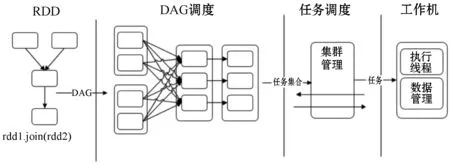
图1 作业调度流程
2.2 计算引擎与内存管理
Spark计算引擎在内存中完成多步骤的迭代计算,提升了机器学习应用的性能[9]。计算引擎主要包括执行内存与Shuffle两部分,Shuffle性能优劣直接决定了计算引擎的性能和吞吐量。执行内存包括在JVM堆上分配的执行内存池和在操作系统内存中分配的Tungsten。操作系统内存是整个架构的基础,无论执行内存如何分配,都离不开系统内存的支持。操作系统通过确定数据所在的页缓存,并使用页缓存的偏移量和数据的长度读取数据,避免了JVM加载额外类文件和对象,降低了GC扫描与回收的频率。内存管理器负责申请和释放执行内存,执行内存的消费者组件包括3种,任务中间过程输出数据在JVM堆上进行缓存和聚合等处理,操作系统内存中进行溢出和持久化处理的Shuffle操作,以及键值对存储到连续的内存块的批处理。
图2为内存申请与分配原理图。Tungsten是一种内存分配与释放的实现方式,直接操作系统内存实现类似于操作系统的页缓存的Memory Block数据结构,准确地申请和释放堆外内存、计算序列化数据占用的空间,降低了管理的难度和误差[10]。内存块中的数据位于JVM堆内存或者堆外内存,主要包括obj、offset和length三个属性。obj属性保存了对象在JVM堆中的地址,offset属性保存了页缓存的起始地址相对于对象在JVM堆中地址的偏移量,length属性保存了页缓存的大小。Tungsten处于堆内内存模式时,数据作为对象存储在JVM堆中,从堆内找到对象使用offset定位数据的具体位置。处于堆外内存模式时,通过offset属性从堆外内存中定位数据,从obj和offset定位的起始位置开始获取固定长度的连续内存块。若申请的内存块大于等于1 MB,且Memory Buffer Pools中存在指定大小的内存块时,从内存缓存池中获取,否则单独创建内存块用于分配。
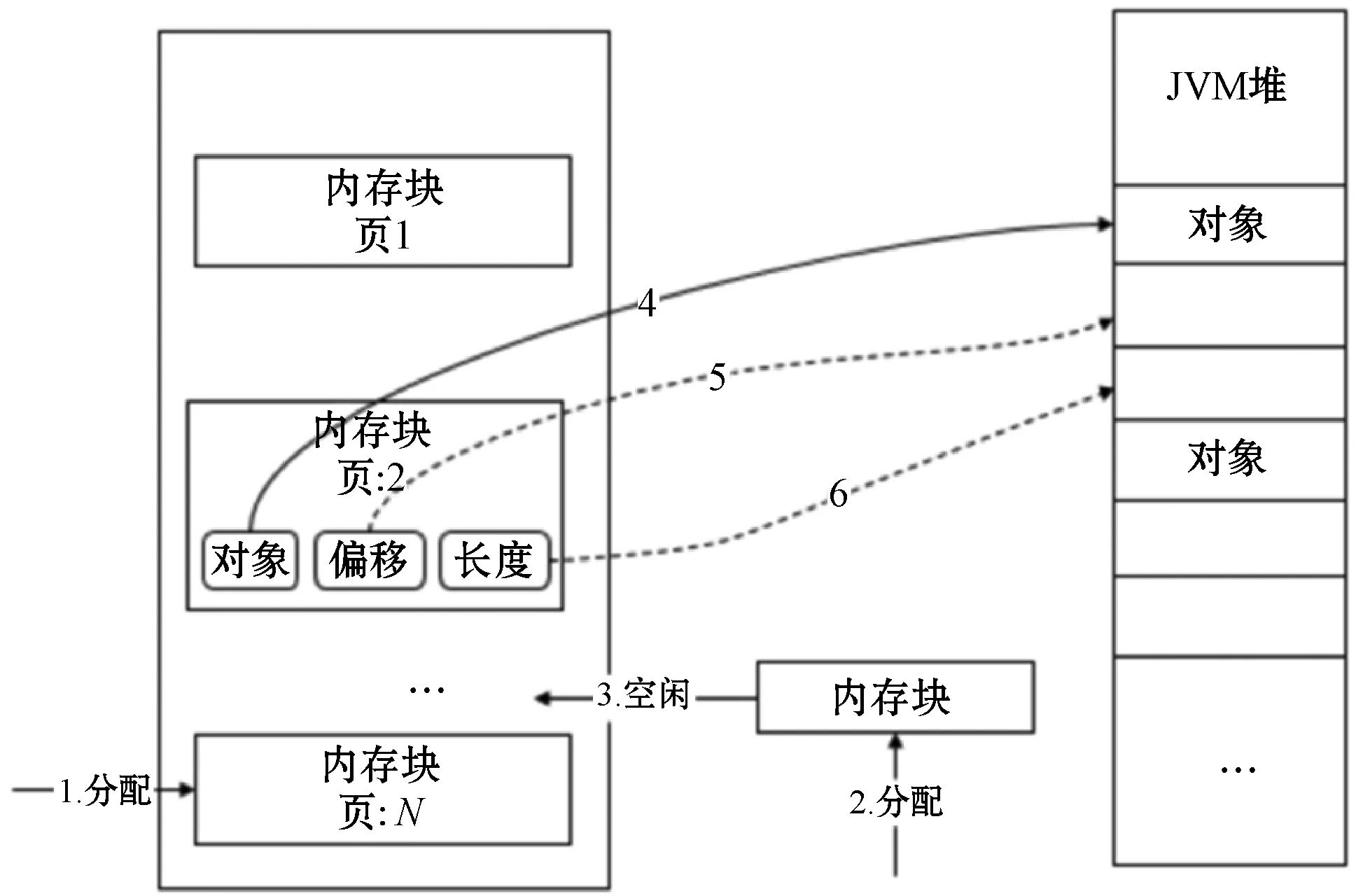
图2 内存申请与分配原理
3 预测模型构建
3.1 预测模型的运行原理
图3为作业执行时间预测原理图。预测模型的响应时间需要满足在线预测的实时性要求,能够并行化操作和处理更大规模的数据集与更加复杂的逻辑。功能包括收集作业运行时特征与指标、构建模型训练与测试过程、预测作业的执行时间。作业被编译生成DAG时,在调度程序中注入计数器计算每个阶段所需特征。运行SQL作业实现模型离线训练,训练阶段的目标是从作业中提取特征向量X,以及相应的性能度量指标向量Y。如果一个阶段有N个Task并行执行将为该阶段收集N组特征,特征收集器的输出是特征向量X。特征类别包括数据集规模、Shuffle和IO特征,以及集群配置等。模型的输入包括特征向量和度量指标,输出是特征和指标之间关系的回归模型,通过比较实际值和预测值评估模型预测的准确性。
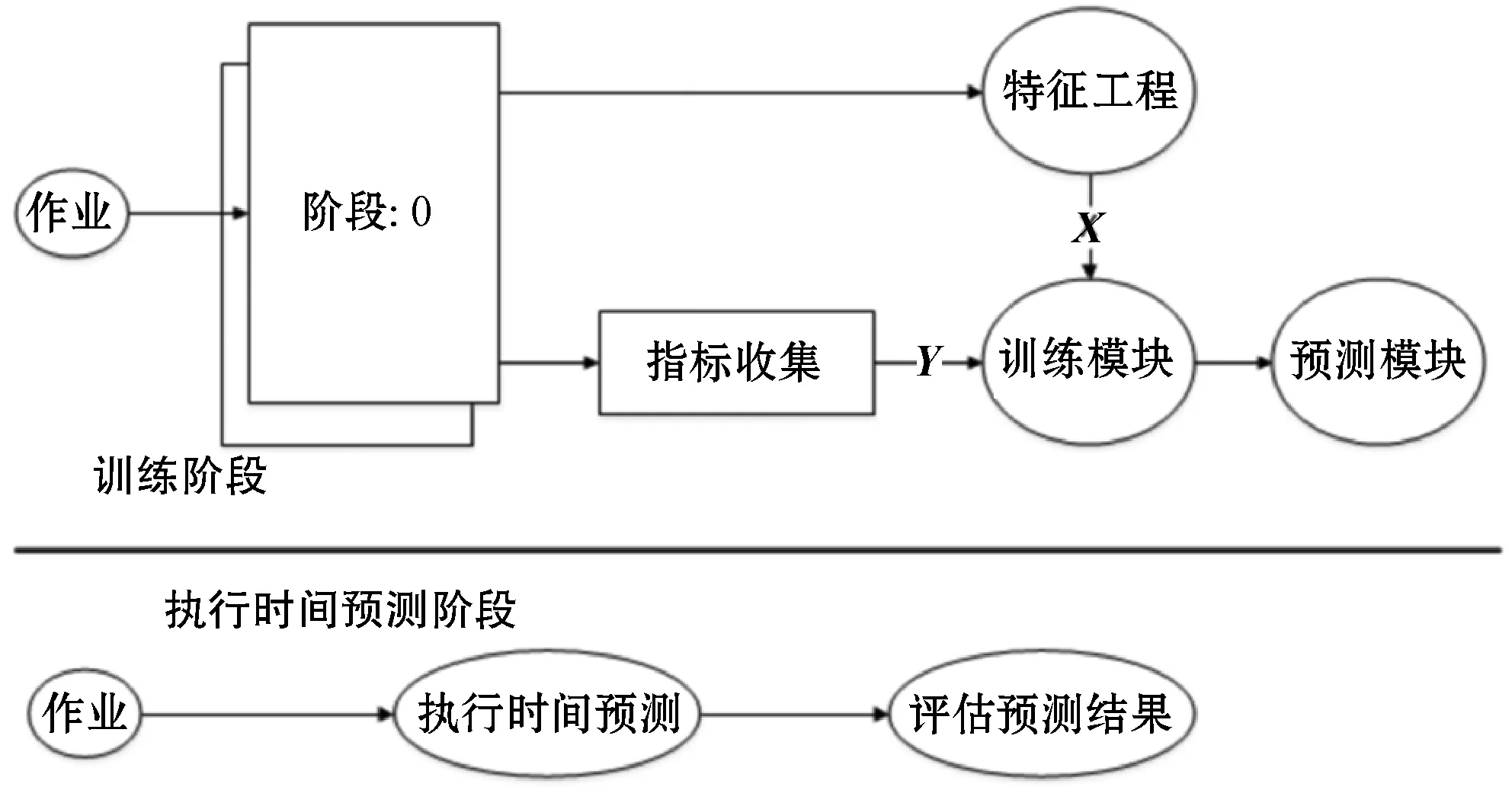
图3 作业执行时间预测原理
通过解析作业执行计划提取特征向量,机器学习模型预测执行计划中每个阶段执行时间,根据每个阶段的执行时间估计作业的执行时间。DAG中阶段是根据RDD依赖关系运行,某个阶段的执行时间是此阶段开始的最早任务的开始时间,与最后执行任务的完成时间之间的间隔,如式(1)所示。FTST表示在数据分区上某个阶段第一个任务的开始执行时间,LTET表示在某个阶段最后一个任务的结束时间。式(2)给出如何根据每个阶段的估计执行时间预测整个作业的执行时间,其中作业有N个阶段。
TStage(i)=FTSFi-LTETi
(1)
(2)
3.2 特征与指标的收集方法
表1为Task特征向量X来源与取值示例。机器学习任务中特征选择是重要的数据预理过程,剔除冗余和无关的特征,在高维数据分析中可以提升机器学习的性能。特征选择方法主要分为监督和无监督两种。卡方选择是统计学上常用的特征选择方法,通过特征和真实标签之间执行卡方检验确定关联度。编号1~3表征了网络流量特征,编号4~11表征了作业执行过程中的Shuffle和IO特征,编号12~15表征了数据规模特征。作业特征与指标数据的提取主要借助Listener Bus机制和Metrics System,采用异步线程将事件提交到对应的事件监听器。作业数据集获取方法包括三种:运行时作业调度页面、通过REST接口获取度量信息、借助外部监控工具。本文通过REST接口方式提取相关数据。
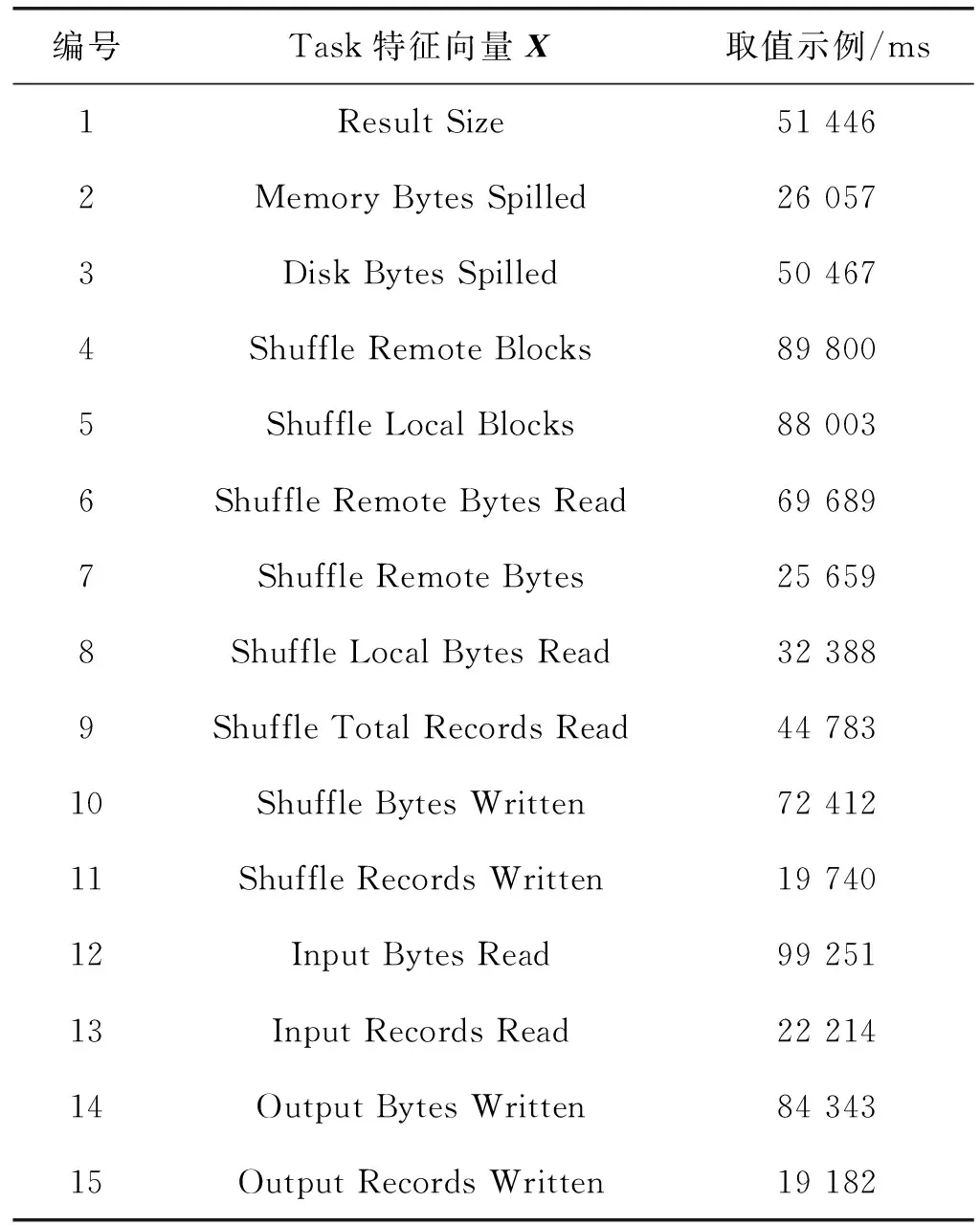
表1 特征向量来源与取值
表2为Task度量指标Y来源与取值示例。选取的度量指标能够体现不同规模的数据集、不同类型算子的Shuffle和IO操作,以及网络流量方面的时间开销。充分考虑了作业执行时间指标的动态性,每个作业执行计划的可用资源不同,作业并行运行时存在资源竞争,作业的GC时间和数据序列化与反序列化时间,以及网络传输存在一定的随机性与关联性,例如存在Shuffle过程算子的IO操作往往比较耗时。
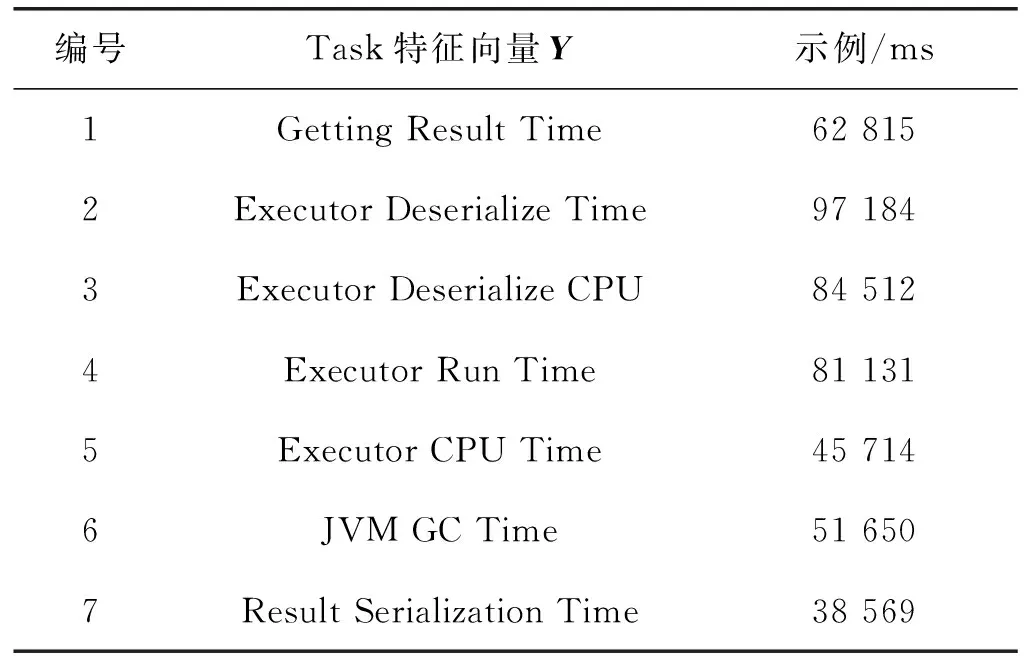
表2 度量指标来源与取值
3.3 预测模型的评估指标
决策树可以使用复杂的非线性模型拟合数据,通过改变不纯度的度量方法用于回归分析。类似线性回归模型使用对应的损失函数,决策树用于回归时使用不纯度度量方法[13]。方差是用于量度回归模型的节点处标签均匀性的量度。如式(3)所示,均方根误差RMSE是均方误差MSE的平方根,精确度会进一步放大,越接近零表示预测越准确,wTx(i)是预测值,y(i)是所有实际值。如式(4)所示,平均绝对误差MAE是预测值与实际值之差的绝对值的平均值,MAE避免正负误差相互抵消,更好地反映预测值误差的实际情况。如式(5)所示,拟合优度(R2)用来评估模型拟合数据的好坏程度,测量目标变量的变异度,表示可以根据自变量的变化来解释因变量的变体部分[14]。R2越接近1,表示自变量对因变量的解释程度越高。
(3)
(4)
(5)
4 过度拟合问题
4.1 过度拟合原因与对策分析
决策树易于解释和无须特征缩放,是分类和回归机器学习的有效方法[11]。决策树生成是一种贪婪算法,通过从一组可能的分割中选择最佳分割,贪婪地选择每个分区,以最大化树节点处的信息增益[12]。从根节点开始计算节点所有可能特征的信息增益,选择信息增益最大的特征,然后递归调用上述方法构造子节点直到所有特征的信息增益不再增加。当决策树中节点下的所有记录属于同一个类,或者所有记录属性具有相同值时,生长过程终止。递归算法生成的决策树通常具有过拟合问题,该问题可以从两个方面进行优化。通过剪枝主动去掉一些分支来降低过拟合的风险,该方法的关键是如何确定最优参数,通过调整参数提前在节点处停止递归构造能够有效避免过度拟合,可调整的参数包括Max Depth与Min Info Gain等。另一种方法是通过组合算法在一定程度上抵消过度拟合,Spark ML支持Random Forest和Gradient Boosted Trees两种决策树组合算法。
云南省统计局相关负责人分析认为, 投资是拉动经济增长的关键因素。今年以来云南省民间投资、制造业投资、服务业投资增长明显,促进了投资的高质量发展。下一步,应着力促进投资增长集中在高技术行业、高端装备制造业以及消费转型升级重要行业。同时,要进一步推进民间投资发展,降低准入门槛,优化营商环境。
4.2 交叉验证法优化模型参数
通过最小化决策树的损失函数实现剪枝,在一定程度上能够避免过度拟合,当节点深度等于Max Depth参数时决策树停止生长。Min Info Gain参数是拆分必须改善信息增益的最小值,没有分割候选项导致信息增益大于最小值时决策树停止生长。机器学习能够通过数据集找到特定问题的最佳超参数,可以在独立的Estimator中完成,或者在包含多种算法和特征选择的工作流中完成。通过重复进行模型训练和测试步骤,采用随机化抽样方法选定K个相似的互斥子集,每个子集尽可能地保持数据分布的一致性,分别训练和测试模型,通过取K个模型的均值避免过度拟合问题,该过程称为交叉验证,评估结果的稳定性和保真性在很大程度上依赖K的取值。
采用交叉验证方法评估模型参数时,计算由估计器拟合模型的不同数据对的平均评估指数,使用此参数重新拟合整个数据集的估算器,找到最佳配置参数,在整个训练集上训练具有较强泛化能力和相对较小误差的最佳模型。当交叉验证方法的训练成本较高时,可使用Train Validation Split方法进行超参数调整,创建单个训练和测试数据集对。使用训练比例参数将数据集拆分为两部分,常用75%生成一组训练和测试数据集对,使用最佳参数配置和完整数据集拟合估计器。交叉验证方法每个参数执行K次评估,Train Validation Split方法每个参数组合仅评估一次,训练数据集不够大时结果的可靠性较低。
4.3 组合算法优化过度拟合
随机森林采用Bagging思想,并行训练一组决策树集,模型训练过程是随机的,在每次迭代时对原始数据集进行二次采样,在每个树节点处分割不同的随机特征子集。先对节点随机选择包含K个属性的子集再选择最优属性,参数控制了随机性的引入程度。随机森林并不基于模型残差来构建集成模型,能够取得较低的方差,预测结果聚合了决策树集的预测。将每棵树的预测计为一类投票,获得投票最多的类别作为分类预测结果,平均值用作预测回归结果,能够捕获非线性特征提高判别精度,在一定程度上避免过拟合。
梯度提升树算法是迭代训练决策树,比随机森林需要更长的训练时间。每次迭代使用当前数据集来预测每个训练实例的标签,将预测结果与真实标签进行比较,然后重新标记数据集[15]。在下一次迭代训练中决策树将纠正先前的偏差,并可以进一步减少每次迭代训练数据的偏差,重新标记实例的机制由损失函数确定。表3为Spark ML梯度提升树支持的损失函数类型,N表示实例数,yi是实例的标签,xi是实例的特征,F(xi)是模型预测标签。梯度提升树根据观测值对预测结果进行调整,容易受到噪声点的影响,在训练时使用Run With Validation方法进行验证,当验证错误的改进不超过策略设置的容差时停止训练,能够有效地防止过度拟合。

表3 梯度提升树损失函数
5 实 验
5.1 SQL作业实验过程
实验环境的集群配置11个计算节点,每个节点配置16内核、32 GB内存、512 GB SSD、万兆网卡。每个节点上以独立模式运行Spark 2.0,数据存储在HDFS 2.6。决策树回归模型的超参数配置如表4所示,包括模型训练、度量方法和缓存策略等,超参数是通过交叉验证方法提取的最优参数。调整Max Depth与Min Info Gain训练参数提前在节点处停止递归构造避免过度拟合。
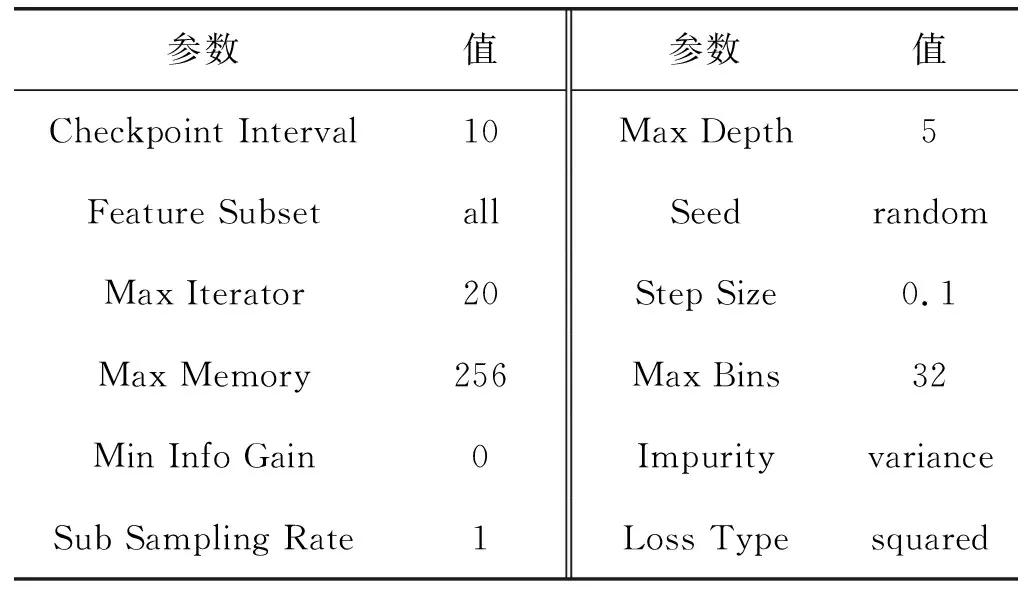
表4 决策树回归模型超参数
图4为使用Spark Bench模拟Spark SQL作业生成测试数据集规模信息,数据集包含约1 000万个实例,每个实例有50个属性。测试设定的应用场景与实际业务场景类似,SQL查询使用模拟生成的电子商务系统的订单数据,涵盖了CPU、内存、Shuffle和IO密集型工作负载。在此数据集上进行Spark SQL工作负载测试,包括Join与Group by算子的实验。

图4 Spark Bench模拟数据集
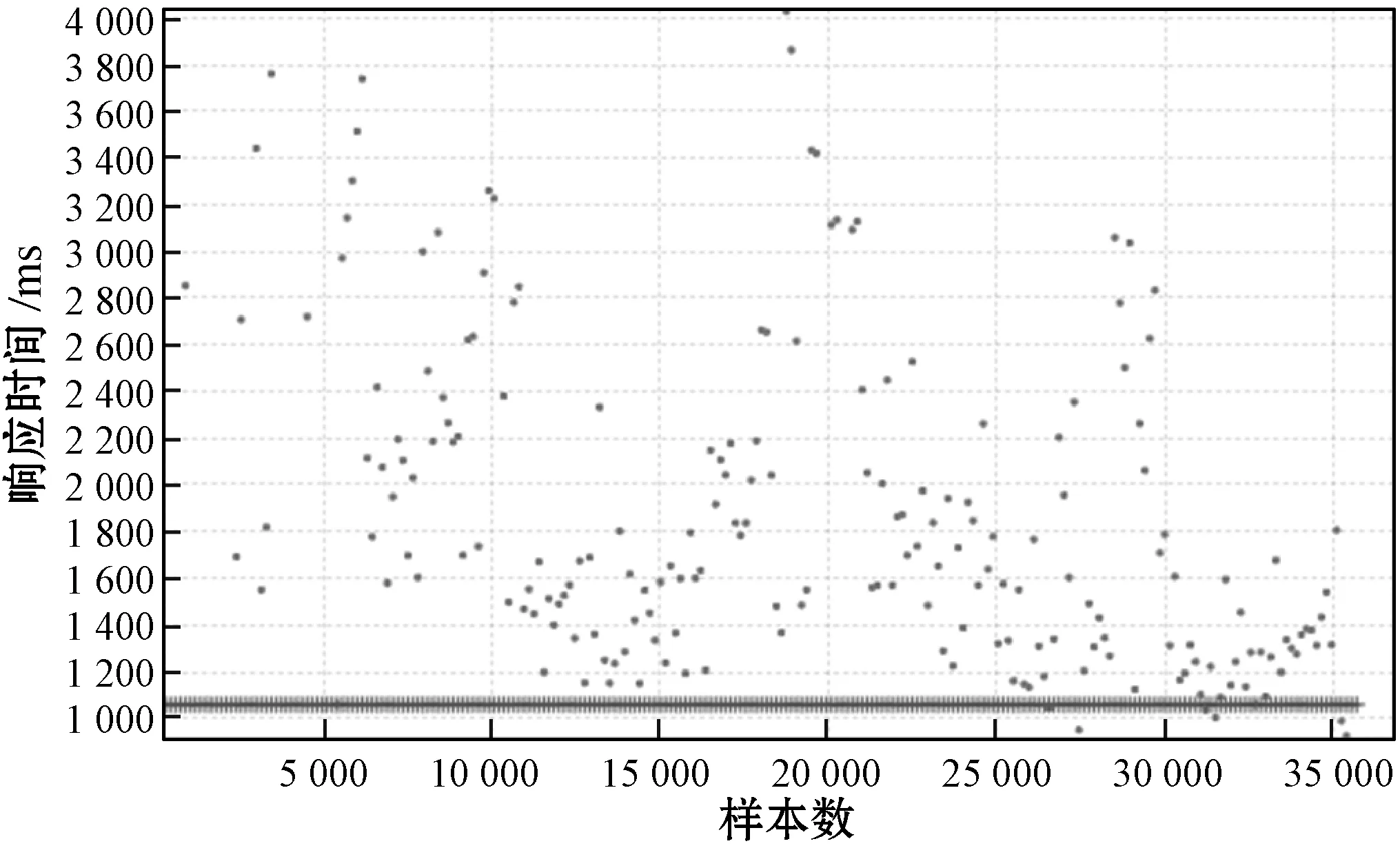
图5为Join算子作业数据集,数据集中用于模型训练的比率是0.7。Join算子作业共产生个236个Task,涉及到Shuffle Read(Write)数据量约1 800 MB。计算过程中Input(Output)数据规模约1 900 MB,作业累计持续时间5 min。

图5 Join算子作业数据集
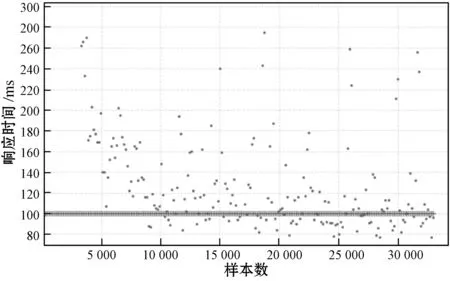
图6为Group by算子作业数据集,数据集中用于模型训练的比率是0.7。Group by算子作业共产生218个Task,涉及到Shuffle Read(Write)数据量约1 800 MB。计算过程中Input(Output)数据规模约1 600 MB,作业累计持续时间27 s。

图6 Group by算子作业数据集
5.2 预测模型准确率分析
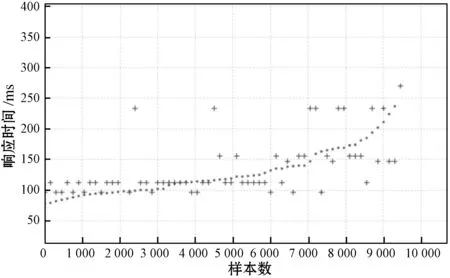
表5展示了决策树及其组合算法回归模型评估指标,其中Join算子的3种决策树回归模型的预测精度有明显的区别,梯度提升树回归模型的R2超过0.8,说明训练阶段选定的特征和模型有较好的匹配。随机森林的指标存在一定的偏差,但优于决策树。三种回归模型RMSE与MAE指标偏差也呈现相同的规律。Join算子模型预测值与实际值对比如图7所示,其中:点号(·)表示真实值。加号(+)表示预测值,可以观察到梯度提升树回归模型的拟合程度优于随机森林模型与决策树模型。
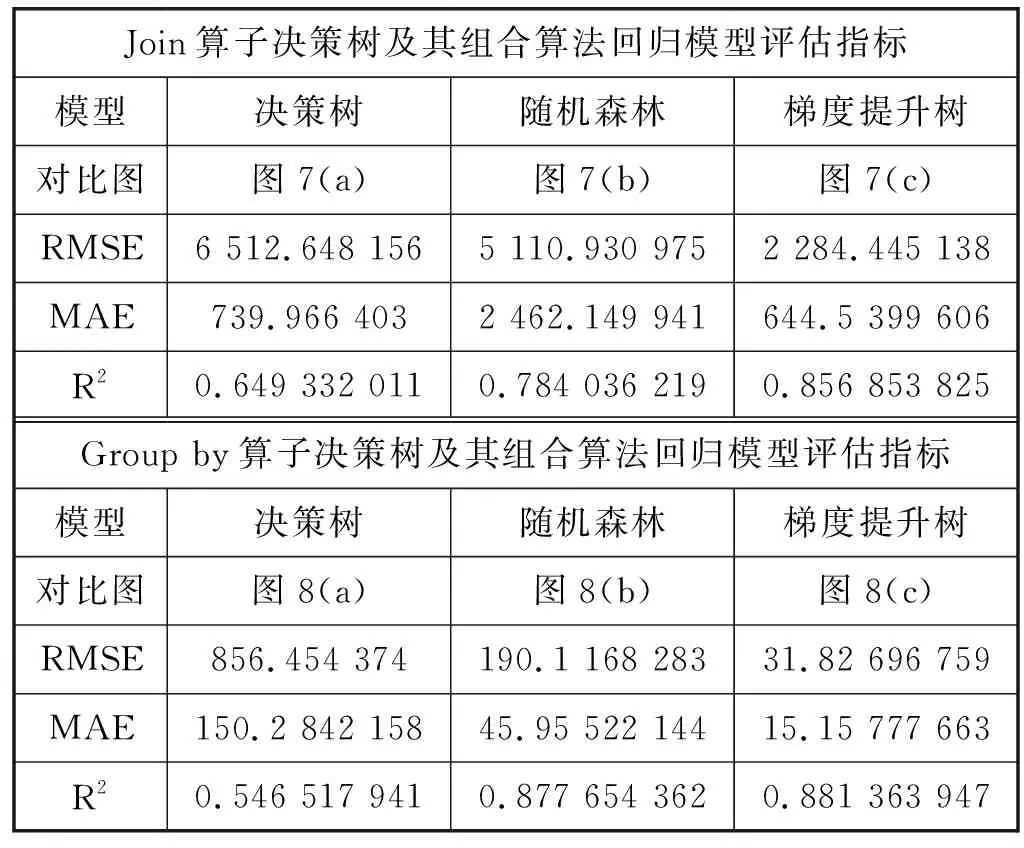
表5 决策树回归模型评估指标
由表5所示的Group by算子的三种决策树回归模型指标可见,随机森林和梯度提升树的R2都超过0.8,决策树的拟合程度较低,RMSE与MAE指标偏差也呈现出相同的规律。Group by算子模型预测值与实际值对比如图8所示,梯度提升树和随机森林的拟合程度相近,所选择的特征很好地表征运算符,决策树有较大的偏差。
(a) 决策树
三种其他回归模型评估指标如表6所示,线性回归使用弹性网正则化模型,广义线性回归模型采用高斯响应和身份链接功能训练模型。Join算子三种回归模型的R2都小于0.6,Group by算子三种回归模型的R2都小于0.3,其中广义线性回归模型的指标要优于其他两种,但都低于决策树回归模型的指标。Join算子线性回归模型预测值与实际值如图9所示;Group by算子线性回归模型预测值与实际值如图10所示。可以看出,所选的特征数据与模型的匹配度较差。

表6 线性回归模型评估指标
(a) 逻辑回归
(a) 逻辑回归
6 结 语
通过收集表征Spark SQL作业特征的数据集和时间指标,训练决策树及其组合方法的回归模型,评估实验表明梯度提升树回归模型在预测Spark SQL作业执行时间上有较好的表现,评估指标明显优于线性回归模型。通过Join算子与Group by算子的数据集测试,梯度提升树回归模型的R2都超过0.8,指标RMSE与MAE也达到预期效果,且满足在线预测的实时性要求,表明模型预测Spark SQL作业的执行时间的方法具有准确性和实用性。下一步将在此基础上,根据预测模型的输出结果,充分运用作业运行时数据,自适应地调整相关参数,选择最优的作业执行计划,提交给DAG Scheduler执行,提升集群性能。
