Dynamic Hand Gesture Recognition Based on Short-Term Sampling Neural Networks
2021-04-14WenjinZhangJiacunWangSeniorMemberIEEEandFangpingLan
Wenjin Zhang, Jiacun Wang, Senior Member, IEEE, and Fangping Lan
Abstract—Hand gestures are a natural way for human-robot interaction. Vision based dynamic hand gesture recognition has become a hot research topic due to its various applications. This paper presents a novel deep learning network for hand gesture recognition. The network integrates several well-proved modules together to learn both short-term and long-term features from video inputs and meanwhile avoid intensive computation. To learn short-term features, each video input is segmented into a fixed number of frame groups. A frame is randomly selected from each group and represented as an RGB image as well as an optical flow snapshot. These two entities are fused and fed into a convolutional neural network (ConvNet) for feature extraction.The ConvNets for all groups share parameters. To learn longterm features, outputs from all ConvNets are fed into a long short-term memory (LSTM) network, by which a final classification result is predicted. The new model has been tested with two popular hand gesture datasets, namely the Jester dataset and Nvidia dataset. Comparing with other models, our model produced very competitive results. The robustness of the new model has also been proved with an augmented dataset with enhanced diversity of hand gestures.
I. INTRODUCTION
A human gesture is a state or sequence of states of a special part of a human body, especially the face and hands. Among them, hand gestures are widely used to replace the spoken language for communication. For example,American sign language is a well-developed body language based on hand gestures [1], [2]. With the rapid advances in information technology and computer science, touchless human-computer interaction has been a hot research topic and so is hand gesture recognition [3]. Based on input devices,existing hand gesture recognition techniques can be classified into two categories: non-vision-based and vision-based [4],[5]. Non-vision-based approaches usually use wearable equipment with certain types of optical or mechanical sensors,such as accelerometers and gyroscopes, which translates hand motion into electrical signals. Although these sensors can provide high recognition accuracy, users have to wear them all the time. Moreover, they cannot produce any signal on static hand gestures. On the other hand, vision-based approaches use single or multiple cameras or precise body motion sensors such as Leap Motion controllers and Microsoft Kinect [6]-[9].Hand gestures can be recognized as long as they are visible to the cameras or sensors, regardless of whether they are dynamic or static. Vision-based approaches are thus more practical than non-vision based ones. Nowadays, most researchers focus on vision-based techniques.
Hand gesture recognition is a branch of action recognition that is hindered by two major obstacles. One is how to efficiently gain the spatial and temporal information from video inputs. In the past years, the most popular network architecture is the two-stream convolutional neural network,proposed by K. Simonyan and A. Zisserman in 2014. In this architecture, spatial features and temporal features are learned by two separate networks and are then fused using support vector machines (SVM) [10]. A lot of attempts in improving the spatial and temporal learning performance were evolved from this design [11]-[15]. However, the use of two separate learning networks means at least doubled training parameters and computational cost compared to using a single network.Moreover, fusing sampled frames with SVM does not catch long-range temporal information across consecutive sampled frames.
Wang et al. developed temporal segment networks (TSN) in[15], [16] for action recognition. In the TSN model, each input video sample is divided into a number of segments and a short snippet is randomly selected from each segment. The snippets are represented by modalities such as RGB frames, optical flow and RGB differences. Convolutional neural networks(ConvNets) that are used to learn these snippets all share parameters. The class scores of different snippets are fused by the segmental consensus function to yield segmental consensus, which is a video-level prediction. Predictions from all modalities are fused to produce the final prediction.Experiment showed that the model not only achieved very good action recognition accuracy but also maintained reasonable computation cost.
Motivated and inspired by the above observations and achievements, this study proposed a new network architecture for hand gesture recognition, called short-term sampling neural network (STSNN). The STSNN architecture, like TSNs,uses a single ConvNet component to capture both short-term spatial information and temporal information from color and optical flow, respectively. It then uses a long-short term memory network (LSTM) [17] to capture long-term temporal information. Similar to TSNs, the STSSN framework first divides the RGB video and its optical flow each into a fixed number of video frame groups. One representative sample is randomly selected from each group. The two samples from the RGB frame group and the corresponding optical flow group are fused into one sample. Then this architecture captures features from these representative samples through ConvNets.After that, features learned from each ConvNet are fed into an LSTM, where the long-range features are learned. In the end,the LSTM produces hand gesture classification from features learned through each LSTM component.
To deal with dataset limitation, we proposed a novel dataset enhancement approach, which is different from normal ones,such as horizontal flip and vertical flip that may affect hand gesture type. In our approach, we zoom out the original video with random distances to generate the “zoomed-out” dataset.It not only provides more training data samples but also helps verify the robustness of a trained model. In addition, random sampling in each group and stacking optical flow frames on RGB frames could also introduce the data diversity because different sampling representatives from different groups can form many different combinations of inputs.
Experiments have been performed on Jester dataset,“zoomed-out” Jester dataset and Nvidia dataset to evaluate the effectiveness of our STSSN model for hand gesture recognition. To reduce the training cost and ensure the ConvNet architecture capture the features from the input effectively, we introduce the pre-trained Inception V2 as our feature extraction module. STSNN with Inception V2 obtained the best performance in the experiment on Jester and Jester “zoomed-out” dataset with the testing accuracies of 95.73% and 95.69%, respectively. On the Nvidia dataset, it achieved a great performance with the classification accuracy of 85.13%, which outperforms the most popular models.
The main contribution of the paper is two-fold:
1) It designed a new deep learning neural network model that integrates several state-of-the-art techniques for action recognition to tackle the complexity and performance issues in dynamic hand gesture recognition. Short-term video sampling,feature fusion, ConvNets with transfer learning and LSTMs are the key components of the new model.
2) It developed a novel approach to “zoom-out” the existing dataset to increase the diversity of the dataset and thus ensure the robustness of a trained model.
The rest of the paper is organized as follows: Section II briefly reviews related work in gesture recognition, including ConvNets, LSTM networks, and action recognition techniques. Section III presents the proposed STSNN architecture.Section IV discusses the experiments and results. A summary of the paper and future work is presented in Section V.
II. RELATED WORK
A. Convolutional Neural Networks
Recent years have seen more and more applications of ConvNets in the domain of computer vision. ConvNets have achieved great success in object recognition, motion analysis,scene reconstruction, and image restoration. Lecun et al.proposed the standard convolutional neural networks called“LeNet-5” and applied this network in the recognition of handwritten digits, achieving an average accuracy of 99.3%on the MNIST Dataset in 1998 [18]. Simard et al., Schölkopf et al., and Ciregan et al. optimized Lecun’s approach and improved the accuracy to 99.6%, 99.61%, and 99.64%,respectively [19]-[21]. Bong et al. proposed a low-power neural network and developed a ConvNets-based face recognition system [22]. He et al. presented a residual learning framework to improve the ConvNets’ performance of image recognition and won the first price in the area of detecting images, locating images, detecting COCO and segmenting COCO in the ILSVRC&COCO 2015 Competitions 1 [23]. According to the literature review, it is obvious that ConvNets are the best choice for computer vision at present.
B. Long Short-Term Memory Networks
Long short-term memory neural networks, LSTMs, are a variation of recurrent neural networks, RNNs. RNNs are designed to process sequences of inputs where all the inputs are related to each other. The key component of RNN architecture is the loop that could persist the previous information with the internal state memory as shown in Fig. 1.x and o are input and output, respectively. h represents the hidden state of each time step and t is the index of time sequence. The state of the current step could be passed to the next step by using this loop. However, this design always encounters the exploding and vanishing gradient problem when training a traditional RNN. LSTMs are designed to solve this problem. A common architecture of an LSTM block is composed of three gates: input gate, output gate, and forget gate, plus a memory cell as shown in Fig. 2. Among them, the forget gate could control the value remaining in the cell [24].

Fig. 1. The architecture of recurrent neural network.

Fig. 2. The architecture of LSTM block.
LSTMs have achieved great performance in some areas of sequence data processing in the past years. For example,Microsoft used “ dialog session-based long-short-term memory” approach to reach 95.1% recognition accuracy on switchboard corpus with 165 000 words vocabulary [25].Google recognizes the speech by using LSTM on smartphone for Google Translate and smart assistant [26], [27]. Apple also used it for Sifi [28]. Amazon applied this approach to the product Alexa [29]. In 2019, a computer program AlphaStar based on a deep LSTM core, developed by DeepMind,excelled at the video game Starcraft II [30].
C. Action Recognition
Dynamic hand gesture recognition can be viewed as a branch of action recognition, whose task is to identify different actions by acquiring the context from a whole video of action rather than from each frame [31]. This means that action recognition needs to identify the different state of action from each 2D frame where the action may or may not be performed and then synthesize the obtained state to determine what the action is.
Although deep learning has achieved great success in the area of image classification in the past years, the progress of video classification research is slow. The major issues are with the standard yet defect benchmark and huge computational cost. UCF101 and Sports1M datasets have been recognized as the standard benchmark by researchers for a long time, but there are some problems with this benchmark.For UCF101, although the quantity of data could meet the requirement, the actual diversity of this dataset is not sufficient because of the high spatial correlation. Besides, both of them have the same theme, which is sports. It is difficult to prove that an approach that works well in this theme could be generalized into other tasks. Another problem is the huge computational cost. Video data can be considered as an image sequence, which means that video analysis is equal to process a large number of images. Therefore, video processing takes n times of the computational cost of a single image processing,where n is the number of video frames. According to Tran et al.,they spent three to four days to train a deep learning model on UCF101 and about two months to train on the Sports-1M dataset [32].
There are mainly two categories of deep learning networks for action recognition: single-stream networks and two-stream networks. The major difference between these two categories is the design choice around combining spatiotemporal information. In 2014, Karpathy et al. explored multiple ways to use a single-frame baseline architecture with pre-trained 2D ConvNets to fuse the temporal information from consecutive frames [33]. The architecture is illustrated in Fig. 3.
Considering the difficulty of deep neural networks in learning movement features, Simmoyan and Zisserman suggested using stacked optical flow to learn temporal features [10]. This architecture is shown in Fig. 4 and it has two separate neural networks. Among them, one is designed for spatial context from RGB frames and another one is used to learn motion context from optical flow. The author trained the two networks separately and fused them using a support vector machine.

Fig. 3. Single-frame baseline architecture for action recognition. Conv,norm, pooling, and fully stand for convolution, normalization, pooling, and fully connected layers, respectively.
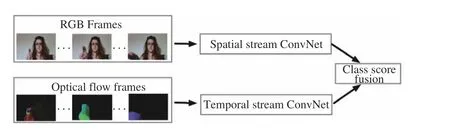
Fig. 4. Two stream architecture for action recognition.
D. Hand Gesture Recognition
A lot of vision-based approaches for recognizing hand gestures with normal cameras or depth cameras, such as Leap Motion and Kinect controllers, were reported. Among them with normal cameras, Tsai et al. proposed a syntheticallytrained neural network for 3D hand gestures [34]. An end-toend deep neural network, LPSNet, was proposed by Li et al.to recognize hand gestures [35]. Köpüklü et al. presented a new data level fusion method, motion fused frames (MFFs), to increase the accuracy of deep learning in [36]. In 2019,Köpüklü et al. attempted to use a lightweight CNN and a deep CNN to detect and classify hand gestures, respectively [37].There are also some other works based on depth cameras [38].Hu et al. trained deep learning neural networks with skeleton data collected from a Leap Motion controller and then used it to control a drone [8]. Marin et al. used an SVM with a Gaussian radial basis function kernel to recognize gestures with the combination of skeletal data and the depth feature from Kinect and Leap Motion controllers [9].
III. SHORT-TERM SAMPLING NEURAL NETWORKS
In this section, we give a detailed description of the shortterm sampling neural networks, STSNN. Firstly, we explain the rationale for this design. Then, we present the architecture of STSNN in detail. After that, we introduce the transfer learning technique into STSNN to increase model training efficiency.
A. Overview of STSNN
To perform hand gesture recognition effectively, we need to capture and utilize both spatial and temporal information in a video input. Both 3D ConvNets and two-stream ConvNet architectures try to fetch the information from a stack of RGB frames and optical flow [10], [39]. However, in our previous study for hand gesture recognition, we trained a 3D ConvNet[40] model with more than 146 million parameters. Such a complicated model is hard to deploy into an embedded system. Therefore, the goal of this design is to reduce the neural network computing cost and meanwhile ensure recognition accuracy and performance.

Fig. 5. The architecture of short-term sampling neural networks: It divides the input video frames and optical frames to m groups and the representative color and optical flow samples are randomly selected from each group. And then, the group sample is generated by combining the color and optical flow frame.ConvNets module is used to fetch the group features. The different group features collected by the FC module flow into the LSTM module for classification.
Because in an action video frames are densely recorded but the content changes slowly across the frames, sampling frames at a fixed rate has been proposed to reduce computing cost [41]. We adopted this approach in our previous study[40]. Although it is helpful to some extent, this approach ignores the diversity of video length: different hand gesture video samples have different durations. For example, the“swiping left” hand gesture lasts much longer than the “stop sign” gesture. In this case, if the two gesture video clips are sampled at the same rate, we will get more frames from the“swiping left” gesture than from the “stop sign” gesture, and then either padding or trimming will have to be used.
We use a group based short-term sampling approach, in which we divide consecutive video frames into a fixed number of groups and then take a sample from each group randomly.This way, we can get a fixed number of samples for each video sample, regardless of its duration. In addition, this group sampling approach can make sure that the features are learned fairly because all the samples are distributed uniformly along with the time. In order to ensure that the model can capture the spatial and short-term temporal information together, the representative sample of each group is the combination of RGB frame and optical flow frame, inspired by the earlyfusion idea, introduced by Zhang et al. [40]. After that, a ConvNet is used to capture the features from each representative sample. All ConvNets share the same parameters to reduce training parameters. Next, an LSTM module is used to learn the long-range temporal features from the feature sequence obtained from ConvNets. In the end, the SoftMax function is chosen to calculate the predicted probability of classes.
B. The STSNN Architecture
In this section, we give a detailed description of the STSNN architecture. This architecture consists of four modules: a module for group based short-term sampling, a ConvNet for feature extraction, an LSTM module for the long-range temporal features learning, and an output layer for hand gesture classification. The overall architecture is illustrated in Fig. 5.
Denote by N the total number of frames in a video input.We divide them into m groups, which are denoted by G1,G2, …, Gm. The number of frames in each group is

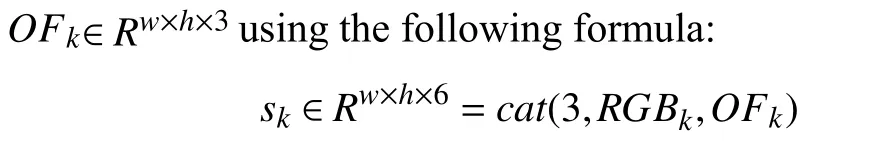
where cat(dim, A, B) concatenates B to the end of A along the dim-th dimension, k is the index of a group, w and h are the width and height of a frame, respectively.

Fig. 6. The process of fusing group sample.

where W is the parameters of ConvNet and they are shared by all groups’ filters. That saves computation costs significantly.With a standard 3D-CNN neural network that performs 3D convolutions on the frame sequence, if its filter size and the number of output feature maps are same as that are used in STSNN, the number of training parameters in the first layer of the 3D CNN will be FS × FS × FM times of that of STSNN[41], where FS is the filter size and FM denotes the number of feature maps. One fully connected layer, fFC, is used to transform the feature maps from ConvNet to a fixed dimension of vector and then we could get m feature vectors,Rm×d, where d is the dimension of a feature. The LSTM input is generated by stacking these m feature vectors together. The LSTM module is used to fuse the group features and learn the long-range temporal information. It is a recurrent process that the hidden state hkand output Okof the LSTM block is calculated based on previous hidden state hk-1and current LSTM block input Fk, that is

The consensus data are passed to fh, a hypothesis function unit, which calculates the final probability of each classification. In this study, we choose the SoftMax function as the hypothesis function. The benefit of using SoftMax longterm temporal features from the sequence of short-term group features. However, its corresponding consensus function fLSTMmust be differentiable or have sub-gradient, because it should support gradient descent optimization algorithm for backpropagation. The work of Feichtenhofer et al. showed that the gradient-based optimization approach could update the parameters from the loss of the whole video rather than just one group [13]. Assuming that the consensus function output is P,

C. Transfer Learning With Inception V2
Transfer learning plays a very important role in improving training performance and saving training costs. According to Pan et al., an image classification model designed for one domain may apply to another domain because their data may have the same feature and distribution [42]. A good practice of transfer learning is to extract features by using ConvNets.Thus, we choose the pre-trained model of Inception architecture with Batch Normalization, Inception V2.Inception V2 not only has a good balance between efficiency and accuracy, its batch normalization can also reduce the risk of over-fitting. These features lead to better testing performance through better generalization [43]. The dropout layer is another technique to reduce the overfitting problem.One extra dropout layer was added after the pooling layer in Inception and the dropout rate was set to 0.5 [44].
IV. MODEL TRAINING AND TESTING
This section introduces the details of model training and testing results. We first discuss the hand gesture datasets and how we enhanced the Jester dataset to improve the robustness of the trained model. Then, we go over the train details, such as optimization function, learning rate, and so on. In the end,we compare the performance of our model with other popular models.
A. Experiment System Overview
As Fig. 7 shows, the architecture of the system includes three components: the input module, the preprocessing module and the recognition module. The input module starts to capture the image sequence of a gesture at the rate of 12 frames per second when a user presses the “space” key. This capturing is stopped when the user presses the key again. The user should finish a hand gesture between the two consecutive keystrokes. It then uploads the image sequence into the preprocessing module asynchronously during, rather than after, the video input process. The responsibility of the preprocessing module is to calculate the optical flow and normalize the data. When the data flow into the recognition module, a prediction result will be produced. A web service is developed to share the recognition result with other applications to control engineering targets, such as robots and drones.
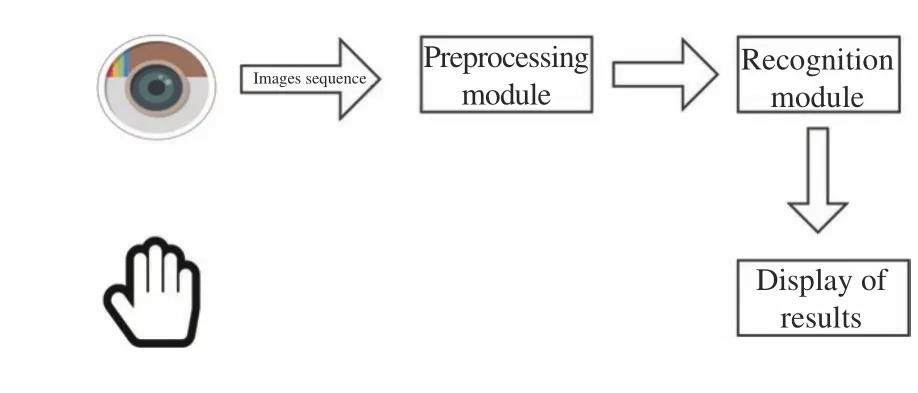
Fig. 7. Experiment system architecture.
B. Datasets
1) The Jester dataset
In this study, the 20BN-Jester dataset, which was collected and organized by Twenty BN, was chosen to train and test our model [45]. This dataset is a large collection of labeled video clips that show humans hand gestures collected by using the laptop camera or webcam. All the hand gestures were created by a lot of crowd workers rather than very few people.Besides, the gestures were performed in a very complex background such as a rotating fan, bright bulb, moving cat and so on. As Fig. 8 shows, there is a large variance of the appearance of people, and complex ambient occlusion and background scenes. Because of that, this dataset is a good choice to train machine learning models for hand gesture recognition. There are 148 092 videos in this dataset: 118 562 for training, 14 787 for validation and 14 743 for testing,which is provided as TGZ archive. Each video was converted into JPG images at the rate of 12 frames per second. So, the archive fold has 148 092 directories that contain these images.There are 27 types of hand gestures listed in Table I. Among them, 25 are gesture classes. The “No gesture” and “Doing other things” classes are special classes that could not be recognized as any hand gestures. “No gesture” means that a user sits or stands still without any movement and “Doing other things” is a collection of various activities exception 25 hands gesture included in the dataset. Thus, based on this dataset, a well-trained model should be able to handle these two exceptions.
2) The Zoomed-Out Jester Dataset
In order to test whether this design has the ability to handle situations that there is a bigger distance between video cameras and actors who perform hand gestures than usual.This distance of the samples in the Jester dataset is about 50 cm,meaning actors sat right in front of the cameras. That is the limitation of this dataset for a specific application. When we want to apply our approach to a real application, we cannot assume that users always do the hand gesture close to the webcam or camera. This motivates us to enhance this dataset by “ zooming out” video frames in the dataset to create“distant” video samples, in which the distance reaches to 100 cm.

Fig. 8. Some examples of hand gesture video clips from the Jester dataset.

TABLE I CLASS OVERVIEW IN JESTER DATASET
In order to zoom out the Jester dataset, we take into consideration the fact that adjacent pixels in a picture tend to have strong similarities, especially the background pixels, like white walls or sofa. Thus, our approach is to duplicate boundary pixels of a frame. Of course, such zooming-out processing should not affect the gesture in a video clip. In other words, the boundary pixels to be duplicated in a frame are not any pixels that will change in the following frames. As mentioned before, the optical flow algorithm could detect the movement between consecutive frames. Our experiment shows that 31.4% of moving pixels are located at the boundaries of video frames. One solution is to find a frame in which all boundary pixels are safe to duplicate and then use these pixels to extend the background of all frames in the video. To modify the dataset so that the distance between actors and cameras varies within a certain range, we set a maximum number of pixels to duplicated, Nmax, and then we randomly generate a number of duplicated pixels Nextendfor each video, Nextend[0,Nmax]. The whole process of zooming out video frames is shown in Fig. 9. The frame in Fig. 9(b) is generated by filling the surrounding area of the original frame in Fig. 9(a) with its boundary pixels. Then the “zoomed-out”frames are generated by resizing it to the same size.Comparing the original frames with “zoomed-out” frames,this approach effectively “increases” the distance between the actors and cameras in Fig. 10.

Fig. 10. The comparison between the original dataset and the “zoom out”Jester dataset (a) is the original frame and (b) is the “zoomed-out” frame.
3) The Nvidia Dataset
The Nvidia hand gesture dataset (Nvidia dataset) is collected by using the SoftKinetic DS325 sensor, including 25 hand gesture types. The samples of this dataset are front-video and depth videos and randomly split into training (70%,1050 videos) and test (30%, 482 videos) sets by subject. In this study, we focus on using the normal camera as the sensor to recognize the hand gesture. Thus, we only take the RGB frames from the videos for the experiment.
C. Training Details
This section introduces the experimental hardware and software environment and hyper-parameters about the learning phase.
1) Environment
The training and recognition system is implemented with Python 3.5, PyTorch 1.0 and Cuda 10.0. OpenCV 3 and pillow 5.3 libraries are chosen to preprocess video inputs because these libraries are friendly to Ubuntu Operation System, especially Cuda 10.0 and OpenCV 3.0.
Hardware for the experiment is as follows: Processor: Intel(R) Core (TM) i7-8700 3.20 GHz; System memory: 16GB(2400 MHz); GPU: NVIDIA Corporation GTX 1070 7 GB.
2) Training Configuration
We use the cross-entropy loss to measure the performance of our classification model and the mini-batch stochastic gradient descent algorithm, mini-batch SGD, to optimize the parameters of the network. The batch size is set to 16 and momentum 0.9. The dropout rate is set to 0.5. The network parameters are initialized with a pre-trained model, Inception V2, from ImageNet. The learning rate is set to 0.001 at the beginning of the experiment and decreases to its 0.1 when the loss fails to decrease compared with previous epoch training.The maximum optimization number of epochs is set to 50.
The number of groups in a video input may affect the model performance. Fewer groups could reduce the computation cost but also impact the accuracy of the model. On the other hand,more groups could increase the computation cost and meanwhile improve the accuracy of classification. Thus, we should find a balance between model accuracy and computation cost by choosing a suitable number of groups.For this purpose, we set the number of groups to 3, 5, 7, 9, 11,13, and 15 and then compare the classification accuracy with the different number of groups.
3) Data Augmentation
In order to deal with the problem of dataset bias, in addition to zoom out images, two online data augmentation approaches, rotation and crop, are applied to prevent model overfitting and improve the robustness of the trained model.They are applied to each training batch before it is fed to the STSNN model. The parameters of each augmentation approach are randomly selected from a fixed range. The range of rotation degree is from 0 to 45 and the range of crop rate is from 75% to 100%, but the two approaches do not apply to input data where the rotation degree is 0 and crop rate is 100%.
D. Results on the Jester Dataset
1) Change of Loss
During the training process, the network parameters are updated based on the gradient descend algorithm to minimize the cross-entropy loss. As Fig. 11 shows the loss of the model has been on a downward trend, which indicates that the training process is effective.
2) Accuracy
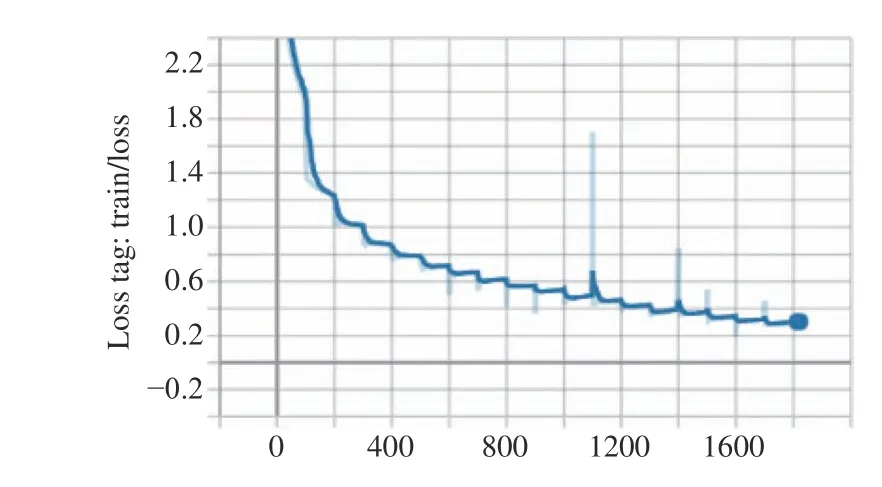
Fig. 11. The change of loss.
To find the optimal number of groups that every input video should be divided into, we did experiments with numbers 3, 5,7, 9, 11, 13, and 15 and checked the classification accuracy for each option. The experiment results are shown in Fig. 12. When the group number increased from 3 to 9, the accuracy of the model continued to increase. However, when the group number increased further, the accuracy pretty much remained unchanged. As we mentioned earlier, the more groups in a video,the higher the computational cost. Thus, our model achieves the best performance with an accuracy of 95.73% when every input video is divided into 9 groups. The best result on the “zoomedout” Jester dataset is 95.39% in Fig. 13. Comparing with the result of Jester dataset, our model achieves approximately the same accuracy when the group number is 9. However, the model trained by the “zoomed-out” Jester dataset should have better robustness and practicability.

Fig. 12. Result on the validation set of Jester dataset with different group numbers. x-axis: number of groups; y-axis: accuracy.

Fig. 13. Result on the validation set of the “zoomed-out” Jester dataset with different group numbers. x-axis: number of groups; y-axis: accuracy.
Fig. 14 shows the performance confusion matrix of the STSNN model on the Jester validation dataset. The row indices represent the actual labels and the column indices denote the predicted labels. According to this confusion matrix, this model tends to make mistakes in identifying“turning hand clockwise” and “turning hand counterclockwise”, “swiping right”, and “slide two fingers right”, but it still has great classification performance on the whole testing dataset.
3) Comparison With Other Approaches
The Jester website provides a learning board for researchers to test and rank their approaches. So far, about 90 research teams tested their models in this platform, including ours. The recognition accuracy of the top 60 models ranges from 91.22% to 97.26%. The accuracy of our model stands at 95.73%, 1.52% shy from the one ranked the first [46]. Table II shows part of the list. The website does not provide details of each approach and thus it is hard for us to have a full-scale comparison of these approaches. Comparing with the 3D CNN architecture that achieved a 94.85% accuracy, our approach only needs to train a ConvNet architecture that has been pre-trained through ImageNet dataset. Moreover, our approach a higher recognition accuracy than the 3D CNN.

TABLE II COMPARISON WITH OTHER APPROACHES ON JESTER DATASET
E. Results on the Nvidia Dataset
The Nvidia dataset is relatively small and can lead to the over-fitting problem. To mitigate the risk, we used the transfer learning and dropout layer technique as well. Before training the STSNN in Nvidia dataset, we reused the parameters of the pre-trained model on Jester dataset to initialize the network parameters and then froze all the training parameters of Inception V2 except the first two convolutional and batch normalization layers during the training phase. The number of groups is 9. The initial learning rate is set to 0.001 and decreased to 0.0005 at epoch 25 and 0.00025 at epoch 55,respectively. There were two dropout layers in the model: one is added after Inception V2 component with a drop rate of 0.5 and the other locates after the LSTM component with a drop rate of 0.8.
We also did a comparative experiment that trained the model from scratch. In Table III, we compare our models with state-of-the-art approaches in terms of recognition accuracy,which uses color and optical flow to recognize the hand gesture. Although the accuracy of our model trained from scratch is a little worse than R3DCNN and MFFs, when applied with transfer learning, it achieved great performance on this benchmark with an average accuracy of 85.13%.Nvidia also evaluated human classification accuracy by asking six subjects to label gesture videos in the test set after seeing the color video. Our result is close to human performance,88.4%.

Fig. 14. Confusion matrix of the STSNN model for hand gesture recognition on the Jester validation dataset.

TABLE III COMPARISON WITH OTHER METHODS ON NVIDIA DATASET
F. Feature Map Visualization
In addition to the model accuracy, we also want to know more about the network model itself. Several model visualization approaches have been used by researchers, such as activation maximization, network dissection based visualization network inversion, and deconvolutional neural networks, to interpret ConvNets. In this study, we adopt the deconvolutional neural networks based visualization approach, projecting feature maps into images directly by using DeconvNet architecture. Fig. 15 shows the feature map of our ConvNet model when it processes the “pulling two fig.”, “swiping right”, and “stop sign” hand gesture videos. It shows that the ConvNets can successfully track the hand movement.
V. CONCLUSIONS

Fig. 15. Visualization of ConvNets model for hand gesture recognition.
This study proposed a short-term sampling neural network for dynamic hand gesture recognition. Each hand gesture is captured as a video input. Each video input is divided into a fixed number of groups of frames. A sample frame is taken randomly from each group of color and optical flow frames.The samples are fed into ConvNets for feature extraction and the features are fused and passed to an LSTM for prediction of the class of a hand gesture input.
The developed system based on the new model was trained and evaluated on the Jester dataset. To test the robustness of the new approach, we zoomed out the Jester dataset by coping with the boundary of original images. We achieved an average accuracy of 95.73%, 95.69% on the Jester dataset and the“zoomed-out” Jester dataset, respectively. This model was also tested on Nvidia dataset and achieved a great performance with a classification accuracy of 85.13%. The results of these experiments show that the short-term sampling neural network model is effective for hand gesture recognition.
Future work of this study is as follows:
1) We will apply our approach to some other challenging video analysis tasks. In this way, we can test our approach in other application domains.
2) The optical flow approach plays a critical role in this study. However, the current optical flow algorithm is still costly. The deep learning methods could be used to calculate the optical flow features.
3) This study assumes that the input video has already been trimmed and each video contains only one of the hand gestures. This proposed model can be applied to untrimmed videos by sampling at a reasonable rate [49], [50].
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Multi-Layered Gravitational Search Algorithm for Function Optimization and Real-World Problems
- Dust Distribution Study at the Blast Furnace Top Based on k-Sε-up Model
- A Sensorless State Estimation for A Safety-Oriented Cyber-Physical System in Urban Driving: Deep Learning Approach
- Theoretical and Experimental Investigation of Driver Noncooperative-Game Steering Control Behavior
- An Overview of Calibration Technology of Industrial Robots
- An Eco-Route Planner for Heavy Duty Vehicles