A Novel Automatic Classification System Based on Hybrid Unsupervised and Supervised Machine Learning for Electrospun Nanofibers
2021-04-14CosimoIeracitanoAnnunziataPaviglianitiStudentMemberIEEEMaurizioCampoloAmirHussainErosPaseroMemberIEEEandFrancescoCarloMorabitoSeniorMemberIEEE
Cosimo Ieracitano, Annunziata Paviglianiti, Student Member, IEEE, Maurizio Campolo, Amir Hussain, Eros Pasero,Member, IEEE, and Francesco Carlo Morabito, Senior Member, IEEE
Abstract—The manufacturing of nanomaterials by the electrospinning process requires accurate and meticulous inspection of related scanning electron microscope (SEM) images of the electrospun nanofiber, to ensure that no structural defects are produced. The presence of anomalies prevents practical application of the electrospun nanofibrous material in nanotechnology. Hence, the automatic monitoring and quality control of nanomaterials is a relevant challenge in the context of Industry 4.0. In this paper, a novel automatic classification system for homogenous (anomaly-free) and non-homogenous (with defects) nanofibers is proposed. The inspection procedure aims at avoiding direct processing of the redundant full SEM image.Specifically, the image to be analyzed is first partitioned into subimages (nanopatches) that are then used as input to a hybrid unsupervised and supervised machine learning system. In the first step, an autoencoder (AE) is trained with unsupervised learning to generate a code representing the input image with a vector of relevant features. Next, a multilayer perceptron (MLP), trained with supervised learning, uses the extracted features to classify non-homogenous nanofiber (NH-NF) and homogenous nanofiber(H-NF) patches. The resulting novel AE-MLP system is shown to outperform other standard machine learning models and other recent state-of-the-art techniques, reporting accuracy rate up to 92.5%. In addition, the proposed approach leads to model complexity reduction with respect to other deep learning strategies such as convolutional neural networks (CNN). The encouraging performance achieved in this benchmark study can stimulate the application of the proposed scheme in other challenging industrial manufacturing tasks.
I. INTRODUCTION
IN recent years, nanostructured materials have gained continuously growing interest both in scientific and industrial contexts, because of their research appeal and versatile applications. The mixing of nanotechnology and information and communication technology (ICT) represents the frontier of the fifth industrial revolution: indeed, the reduced size of products may facilitate the automation of tasks, previously limited by physical restrictions [1].Nanomaterials working at molecular level, allow generating wide structures endowed with different properties, useful to improve quality of life in different areas [2]. In biomedical engineering, the huge progress of nanomaterials research suggests that they could yield interesting alternative solutions to many healthcare problems. In tissue engineering application, nanofibers are used for the reproduction of tissue architecture at the nanoscale, thus giving an impulse to wearable applications. Nanofiber materials act as excellent structures for adhesion, proliferation and cells scaffolding differentiation for musculoskeletal, skin, vascular and tissue engineering and as potential vectors for the controlled delivery of proteins and DNA [3]. Among many nanofibers synthesis techniques, electrospinning appears to be the most promising technology able to meet these industrial objectives.Electrospun fibers can indeed be applied to study drug delivery, encapsulating the therapeutic agent in the fibers and maintaining the integrity and bioactivity of molecules due to slight processing parameters. Indeed, as the drug release depends on the degradation of the polymer fibers, it can be adequately controlled. In bioengineering, the nanofibers could allow to include substrate-based optical antenna systems for improved bio-sensing applications [4]. Because of their mechanical, thermodynamic, acoustic, optical, electrical and magneto-electric properties, they are also applied in chemical engineering for water quality improvement [5], [6].Nanofibers can yield good membranes in environmental engineering systems due to some specific properties like high porosity. In this context, electrospinning membranes are emerging as an effective technique with promising features for water treatment. Nanotechnology has exceptional potential for filtration applications due to its ability to create structurally controlled materials [7]. In renewable energy, nanofibers are used as polymer solid electrolytes for battery applications.These polymers are selected as yield properties like low density, easy fabrications and low chemical corrosion.Because of their high surface areas and porosities,nanomaterials are also widely used for energy storage devices.Nanofiber solid electrolytes can be used in developing lithium ion batteries, fuel cells, dye-sensitized solar cells and supercapacitors [8]. Recently, nanoelectronics has emerged as a novel approach to produce electronic component with peculiar electrical and electro-optical properties that stem from the metals and metal composites.
Nanofiber applications success requires to play special care to the quality of nanomaterial and thus to the generation process: the regular arrangement of the material grid and the absence of irregularities ensures the optimization of the nanomaterial properties. In particular, the electrospinning method is based on the electrostatic force of a polymeric solution, which causes the generated drop to fall towards a conductive collector, where the polymeric nanomaterial settles. Material quality, nanomaterial diameter size and the presence of anomalies (i.e., beads and flattened areas) depend on the selected electrospinning processing parameters: i.e.,voltage level, tip-to-collector distance, diameter of the needle,feed rate and type of collector [9].
Nanotechnology and nanomaterials promise to generate products characterized by unprecedented and enhanced properties, achievable by changing the microscopic structure of materials rather than through their processing on a macroscopic scale. In principle, the products can have industrial and commercial relevance, particularly within the framework of the Industry 4.0. Industry 4.0 approach looks at the industries as smart factories that aim to increase productivity and reduce production costs by integrating ICT.Industry 4.0 focuses specifically on automation, i.e., the techniques and methodologies that increase the production quality of the industrial systems by including humans and machines in a unique loop [10], [11]. In the production chain of nanomaterials, a crucial step to practically implement automation is the defect identification process, in order to reduce the number of laboratory experiments and the burden of the experimentation phase. The idea here proposed is to design, by suitable training, a model capable of emulating the recognition process carried out by the operators, subject to fatigue in the visual inspection. There are different types of anomalies that can affect the industrial process, in particuler:beads, i.e., agglomerates of material whose diameter is significantly larger than the rest of the fiber; films, i.e., thin layers of polymer that lies on nanofibers and holes, i.e., large dark areas not covered by nanofibers.
In this paper, a machine learning (ML) detection method that prescinds from the specific defect is proposed to automatically detect anomalies in nanomaterials. ML algorithms extract mathematical models from experimentally generated training data that are used to make predictions on novel instances of the emulated phenomenon. The data here used (i.e., nanoimages) have been generated through a scanning electron microscope (SEM), at the Materials for Environmental and Energy Sustainability Laboratory of the University Mediterranea of Reggio Calabria (Italy). The selected ML scheme is a deep neural network which scope is to discriminate between homogenous (H-NF) and nonhomogenous nanofibers (NH-NF) by inspecting sub-patches of the generated SEM images. NH-NF will be automatically discarded during the inspection. Fig. 1 shows examples of two different types of nanomaterials: anomaly-free (Fig. 1(a)) and with defects (Fig. 1(b)).

Fig. 1. Examples of SEM images of nanofibrous materials: (a) without defects and (b) with a defective bead.
The neural network topology used for solving the defect detection and classification problem is based on a cascade of an autoencoder (AE), trained with an unsupervised rule, and a standard multilayer perceptron (MLP) trained with backpropagation. This series of AE and MLP composes the proposed hybrid unsupervised and supervised ML system.The AE has the capability to learn an efficient and compact data representation through a code learned by exploiting the available data without needs of labels, thus extracting reliable features from unlabeled data. Here, SEM images are compressed by means of the developed AE and the corresponding decoding stage reconstructs an approximation of the original patch. Specifically, the unsupervised processor,represented by the AE, generates a latent representation of the input SEM image by compressing it into a code; then, the decoding stage approximately reconstruct the original image on the basis of the extracted features. The supervised processor, represented by the MLP, performs the probabilistic decision on the quality of the image (i.e., NH-NF or H-NF) by using the features previously extracted by the AE.
The original contribution of this paper is to address the problem of classification without using the redundant full image generated by the microscope but subdividing them in patches and then compressing each sub-part generating a code that allows distinguishing defective from non-defective patches with a reduced computational burden. This will facilitate the training of the classification system also improving the generalization to new experiments and, in principle, will allow to generate novel images.
The rest of this paper is structured as follows: in Section II,the state-of-the-art on ML approaches for nanomaterials classification is presented. In Sections III and IV, materials and methods used for the investigations are described. In Section III, in particular, the electrospinning process is considered and the generation of the database is detailed.Section IV introduces the ML methodology here proposed; in Section V the achieved results are shown. Finally, in Sections VI and VII, future work and conclusions are presented.
II. RELATED WORKS
The automatic detection of any possible structural anomaly plays a key role in industrial manufacturing of nanomaterials.Indeed, the automatic recognition of the materials quality entails an acceleration in the production chain for the use in the industrial sector. In this context, ML-based systems have been emerging for a more efficient anomaly detection.
Conventional algorithms identify the surface of a specific defect by extracting suitable features and more specifically analyzing texture, skeleton, edge and spectrum of the image.In [12], spatial correlation functions (conveniently defined between the bands of a sensor) are used to recognize the color structure. A linear model for surface spectral reflectance is used to show that changes in illumination and geometry correspond to a linear transformation of both correlation functions and their coordinates. In [13] a low computational method for classification of gray scale and rotation invariant texture based on local binary models and nonparametric discrimination, is presented. The technique is based on recognizing the local binary models, defined as uniform, that represent the main properties of the local image texture.
Other automatic defects detection algorithms are based on the selection of a suitable threshold. In this regards, the Otsu method is typically employed to perform thresholding by exploiting bimodal distributions [14]. As a consequence, the method fails when the image histogram is unimodal. At this purpose, to improve the Otsu method, the weighted object variance method (WOV) is proposed by [15], capable of detecting surface defects, by means of the defect occurrence cumulative probability weighted on the variance between classes. In [16] a new double-visual geometry group16 (DVGG16) is first developed to the automatic classification and localization of surface defects. Next, gradient-weighted class activation mapping (Grad-CAM) is applied to the original images. The achieved heat maps are processed through a threshold segmentation method in order to automatically detect anomalies in the input image.
Recently, advanced ML techniques (i.e., deep learning(DL) [17], [18]) are used to reduce production times and simultaneously increase the quality of nanomaterials. It is worth noting that DL has been successfully employed in several applications, such as cyber security [19], [20],neuroscience [21]-[23], sentiment analysis [24]-[26], remote sensing [27], [28], image decomposition [29], and fault detection systems [30]. With regards to the automatic nanomaterial anomalies detection in SEM images, some works have been proposed in the recent literature. Boracchi et al.[31] addresses the issue of automatic detection of anomalies in SEM images, allowing an intelligent system to control independently the validity of the data acquired by a sparsebased representation. Carrera et al. [32] proposed a detection algorithm based on a dictionary of normal patches,subsequently used to detect defects in a patch-wise mode.Napoletano et al. [33] presented a region-based method for detection and anomaly localization in SEM images. The degree of anomaly is assessed by means of a CNN,considering a dictionary generated from anomalies-free subimages belonging to the train set. The automatic detection of defects by using DL models has been addressed also by Ieracitano et al. [34], [35]. In particular, a CNN has been proposed to automatically classify SEM images of H-NF and NH-NF, interpreted as two different categories. As a difference with most of the previous papers, in this work both samples with and without anomalies are analyzed. This approach appears more significant as the images are typically generated with different sets of configuration parameters,which implies a variety of possible ranges of presentation for the nanofibers also in absence of anomalies. However, being it a fully data-driven approach, it is data hungry, requiring the collection of lot of examples through suitably designed laboratory experiments. In contrast, in this paper, we propose a novel automatic classification system based on hybrid unsupervised and supervised ML able to discriminate H-NF/NH-HF SEM sub-images (i.e., nanopatches), by avoiding the use of the redundant full SEM representation. It is worth noting that the use of sub-images allows to improve the detection of possible defects and reduces the computational complexity and cost of the network. Further, the originality of the proposed approach lies also in extracting the most relevant features via unsupervised learning, hence, without using the class information, that is not known in advance during realtime use. In addition, the cardinality of the available dataset is augmented by generating extra-latent vectors: this is carried out by corrupting available data with white Gaussian noise.This procedure enabled a rough emulation of new electrospinning experiments, eliminating the requirement for a costly laboratory test. Experimental results reported encouraging performance achieving accuracy rate up to 92.5%.
III. MATERIALS: EXPERIMENTAL SET-UP AND DATASET CONSTRUCTION
A. Electrospinning Process
Electrospinning is the most successful process for nanofibers fabrication as it is characterized by the ability to improve the product’s performance allowing specific modifications for each type of application [36]. The nanofiber fabrication method requires an instrumental apparatus (Fig. 2)comprised of a high-voltage supply, an extruder and a grounded metallic collector screen where the fibers are collected. A polymeric solution is initially contained into a dosing syringe, regulated by the volumetric pump, which allows controlling the flow-rate. A high-voltage is applied between the needle of the syringe (anode) and the collector(cathode), which are electrostatically charged to a different electric potential. By increasing the applied voltage, the surface charge of the polymeric solution increases while the radius of the polymeric solution drop decreases, until a critical voltage value. At this moment, the drop takes the form of a cone, referred to as Taylor cone [37]. Due to the electric field,a jet is generated from the cone to the collector; meanwhile,the solvent evaporates and is deposited on the collector in the form of nanofibers. Viscosity, electrical conductivity and surface tension of the polymer solution affect the diameter and the morphology of the generated fibers [38]. Specifically,increasing the viscosity also increases the diameter of the fibers, because the solution opposes more resistance to the elongation by the electric field, and consequently the jet stabilizes and makes a shorter path. The increase of the electrical conductivity of the solution causes a greater repulsion of charge jet, and a higher ironing of the fibers, which decrease in diameter. Hence, in order to produce the nanofibers, the applied electrical charge must exceed the surface tension of the solution.
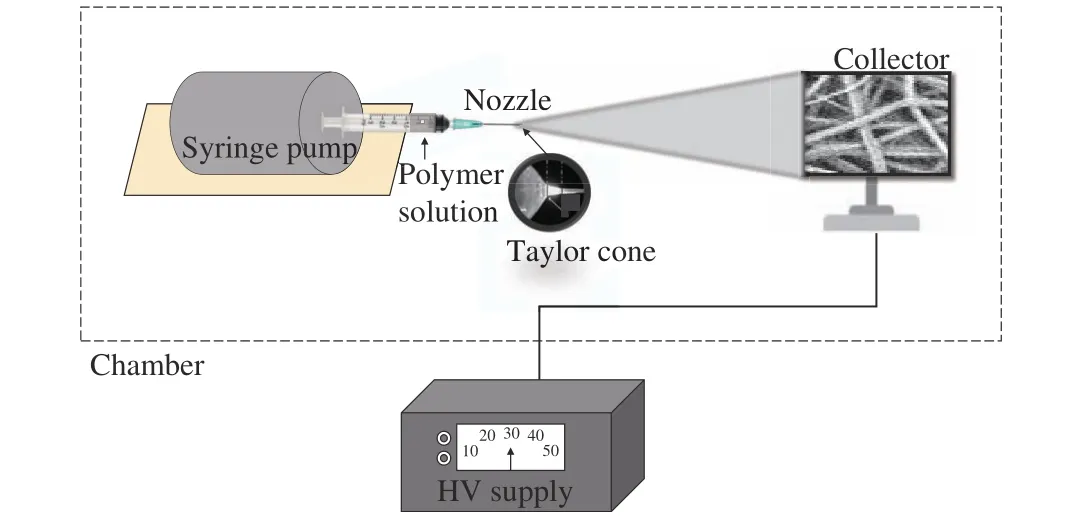
Fig. 2. A typical layout of the electrospinning apparatus.
B. Applications of Electrospun Nanofibers
The use of electrospun nanofibers materials is widely spread in different fields due to their significant characteristics: the high surface-to-mass (or volume) ratio and the porous structure with excellent pore-interconnectivity. These properties make electrospun nanofibers employable in advanced applications [39], [40]. One of the most important applications of nanomaterials concerns the biomedical sector. Most of the studies focused on their safety and their bio-compatibility with human tissues. Nanofibers are used for tissue engineering for reconstructing damaged tissues or organs. Notably, cells are generally seeded on biomaterial scaffolds and microenvironments in order to enhance tissue development;biomedical nanomaterials play a key role in this medical application because they may better support tissue regeneration [41]. Due to the high specific surface area and the high variability of the process variables, electrospun nanofibers are also used in drug delivery. Electrospun nanofibers prepared with an accurate analysis of polymers are used to deliver antibiotic and anticancer agents, DNA, RNA,proteins and growth factors. During drug delivery, the electrospun nanofibers enclose the medicinal agent to maintain the integrity and bioactivity of the drug molecules and reduce the side effects of the drugs through a localized inoculation [42]. Nanofibers provide advantages in filtration properties, removing solid particles from air or liquid substances, because of their high porosity and their grid of interconnected pores. Compared to traditional air filtration systems, nanofibers offer better efficiency in air filtration due to their smaller size. Indeed, electrospun membranes can filter all airborne particles with diameters between 1 and 5 μm. This
is remarkably in closed environments like in hospitals, where an accurate control of air filtration is required, so that bacteria and viruses cannot spread through the circulating air [43].Moreover, nanofibrous membranes with high permeability offer an excellent solution also in water filtration, as they allow a reduction of energy consumption with respect to conventional filtering materials [44]. Nanofibers have found novel applications also in renewable energy. Interesting researches have been carried out in the last two decades: they seems to be the most promising solution for photovoltaics development, whether in inorganic or organic solar cells. In particular, wide bandgap nanostructured materials are attracting an increased attention for energy transition. As an example, they can be prepared in different ways and shapes to improve the light absorption and carrier collection [45].
C. Experimental Setup and Dataset Construction
The main parameters used in electrospinning to control the morphology of nanofibers are: concentration ( p1), applied voltage ( p2), flow rate ( p3), and tip-to-collector distance(TCD, p4). In the laboratory experiments here carried out, a CH-01 Electrospinner 2.0 (Linari Engineering s.r.l.) was used with a 20 mL glass syringe, equipped with a stainless steel needle of 40 mm length and 0.8 mm thick. The solution was instead composed by polyvinylacetate (PVAc) as polymer and ethanol (EtOH) as solvent. In order to obtain a homogeneous polymer solution, it was placed in a test tube and then in a magnetic stirrer (a tool used to mix solvent and solute, by rotating a magnetic latch). To analyze the materials produced by electrospinning, the scanning electron microscope Phenom Pro-X (SEM) was used. It is an electro-optical instrument based on the emission of an electron beam on material surface. After the material production, the Fibermetric SEM images analyzer was used to evaluate the average diameter,the distribution of the nanofibers and the presence of anomalies (i.e., structural defects). Sixteen laboratory experiments were carried out at different working conditions,as reported in Table I. It is to be noted that the experiments were developed by varying the aforementioned parameters( p1, p2, p3, p4) in the well defined working range: p1[10; 25]%wt ; p2[10; 17.5] kV; p3[100; 300] μL/min ; p4[10; 15]cm . The e th nanofibrous material (with e = 1, 2 ,..., 16), underwent to the SEM analizer and 10 relevant and representative areas were selected by an expert operator. Hence, a total of 16 × 10 = 160 SEM images (sized 128 × 128) were collected[34]. Each SEM image was then partitioned into four patches(hereinafter referred to as nanopatches) of the same size 64 ×64 (as shown in Fig. 3). Each SEM patch was manually classified by the nanomaterials expert in two different classes:H-NF and NH-NF images. It is worth mentioning that homogeneous nanomaterial fabrication is typically observed with high values of voltages and concentrations; while nonhomogenous nanomaterial fabrication are affected by the presence of anomalies, such us beads or films, that can occur when the polymeric solution is made up with low values of concentrations or when the tip-to-collector distance is too high.
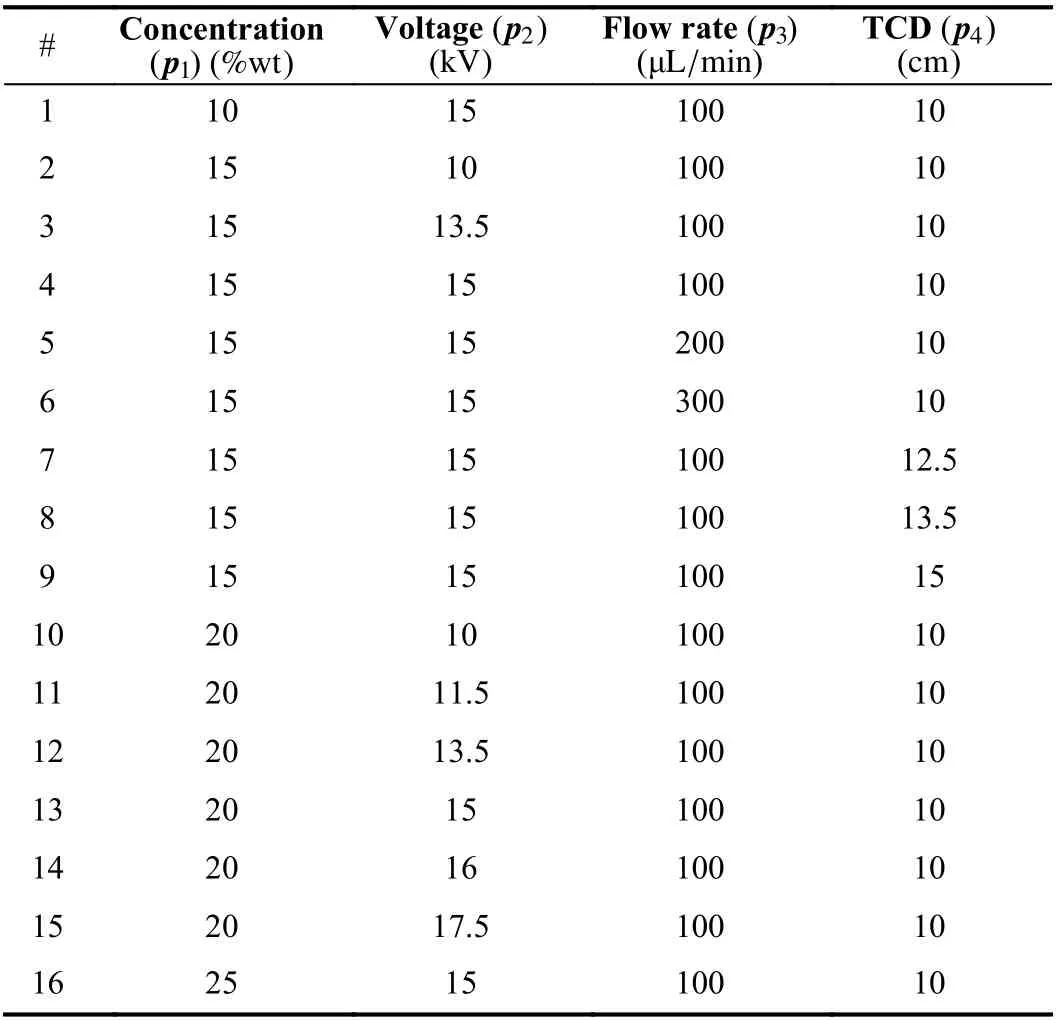
TABLE I SETUP OF THE EXPERIMENTAL ELECTROSPINNING PARAMETERS

Fig. 3. Example of a SEM image sized 128 × 128 partitioned into four SEM nanopatches sized 64 × 64. In the reported example, all the sub-images belong to the homogeneous nanofiber (H-NF) class.
IV. METHODS: HYBRID UNSUPERVISED-SUPERVISED MACHINE LEARNING SYSTEM
The proposed ML-based architecture is a series of the below detailed network topologies, i.e., an autoencoder and a multilayer perceptron.
A. Autoencoder
Autoencoders (AEs) are neural networks trained with unsupervised learning technique that are commonly used for the tasks of representation learning and dimensionality reduction [46], [47]. The most typical topology includes an encoding and a decoding stage. AEs commonly exploit backpropagation learning algorithm with a suitable cost function with the objective of making the output as similar as possible to the input while building an internal latent representation of reduced size. AEs thus project the input image into a lower-dimensional hidden layer (called latentspace representation) and then try to reconstruct the output from this reduced representation. After the compression phase, the number of neurons of the hidden layer should be smaller w.r.t. the input layer and the output layer. In the encoding stage, the network is forced to learn the hidden features behind the input data. In the decoding stage, the AE reconstructs the input layer data at the output layer with optimal accuracy [48]. In this way, the internal representation extracts the most significant aspects (i.e., features) of the image presented at the input by exploiting its redundancy. AE works in two steps: an encoding stage represented by the function y= f(x) and a decoding one that generates the reconstructed original vector/image z =g(y).
In short, AEs can be described by the function

where z is as close as possible to the original input x. The encoder contains the input layer and the hidden layer, where input data is mapped to obtain a deterministic latent-space representation y.

where σ is typically a sigmoid or other nonlinear functions; x the input image, W represents the encoder’s weight matrix and b is an offset vector. The decoder consists of the hidden layer and the output layer. In this case, the latent space representation is inversely mapped to obtain
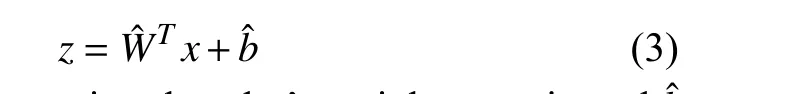
where Wˆ is the reconstruction decoder’s weights matrix andbˆ is the reconstruction offset vector. Finally, in order to reproduce the outputs more and more similar to the inputs, the error function J(x, z) is minimized.
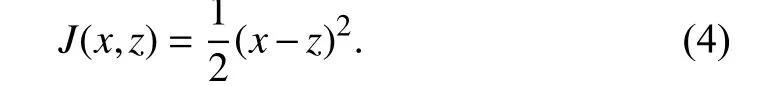
The ideal AE should be sensitive enough to the input to build an accurate reconstruction, while, at the same time,insensitive enough to it in order to avoid the model may simply overfit the training data. This tradeoff is achieved by taking advantage of the redundancies of the input [49].
B. Multilayer Percepetron
The second stage of the proposed network is a well-known multilayer perceptron (MLP). MLP is the commonest feedforward neural network that consists of an input layer, an output layer and of one or more hidden layers. If the MLP is used for classification, the successive layers are trained to build a complex decision boundary between the classes. It belongs to the supervised learning networks that exploit the class label information to minimize a loss function through standard gradient-based backpropagation technique. Each neuron in a MLP computes a weighted sum of all its inputs that is passed through a non-linear activation function to determine its output. In a classification problem, the output yields the probability that the input vector belongs to a specific class.
C. Implementation of the AE+MLP Network
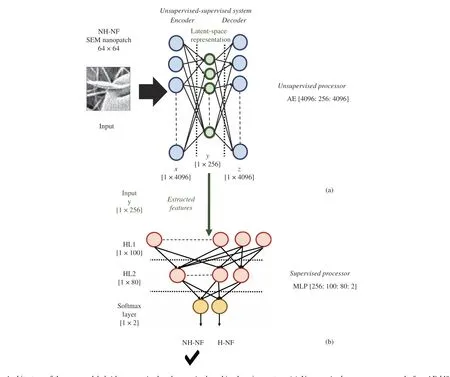
Fig. 4. Architecture of the proposed hybrid unsupervised and supervised machine learning system. (a) Unsupervised processor composed of an AE [4096:256: 4096]. The SEM nanopatch is reshaped into a single vector sized 1 × 4096 and used as input to the proposed AE that allows to extract the most relevant features (sized 1 × 256) from the input data. (b) Supervised processor composed of a MLP [256: 100: 80: 2]. The extracted features are the input to the proposed 2-hidden layers MLP for performing the 2-way classification task: NH-NF vs. H-NF. As an example, in the figure, a NH-NF SEM nanopatch inputs the hybrid unsupervised and supervised classification system.
Fig. 4 shows the architecture of the proposed hybrid unsupervised and supervised machine learning system for SEM images produced by electrospinning procedure.Specifically, the proposed system includes two main modules:the unsupervised processor (Fig. 4(a)), i.e., an AE that performs the features extraction operation, and the supervised processor (Fig. 4(b)), i.e., a MLP that performs the classification task: NH-NF vs. H-NF. The AE extracts a reduced representation of the input, i.e., a feature vector. Fig. 4(a)illustrates the architecture of the proposed AE-based unsupervised processor employed for features extraction. It includes an AE [4096: 256: 4096]. Notably, given the n th NHNF/H-NF SEM sub-image (i.e., nanopatch) sized 64 × 64, it is flattened into a vector 1 × 4096. Next, the AE compresses the input representation ( x, sized 1 × 4096) into a latent-space ( y,sized 1 × 256) subsequently used to decode the same input space (z ≈ x, sized 1 × 4096). In this work, the AE [4096:256: 4096] is trained in unsupervised learning mode for 103epochs on a workstation Intel (R) Core (TM) i7-8700K CPU@3.7 GHz with 64 GB RAM and 1 NVIDIA GeForce RTX 2080 Ti GPU installed (training time ≈ 120 s). The hyperbolic tangent is employed for the encoder and the linear function for the decoder module. Actually, the hidden layer size (1 × 256)of the AE was set after several experimental tests, by estimating the minimum reconstruction error. In particular, the minimum mean squared error was of 0.4416. Hence, overall, a features matrix of 640 × 256 (i.e., number of SEM patches by the number of features) was extracted (respectively, 320 belonging to NH-NF and 320 to H-NF). However, due to the limited size of such datasets with respect to the number of free parameters of the network, the accuracy in the training and test phases were quite different; hence, a simple data augmentation technique was used to enlarge the database size.Specifically, all the features data vectors were corrupted by a white Gaussian noise at a SNR = 10 dB, and the generated vectors were included in the dataset. A grand total of 1280 ×256 instances were taken into account (640 belonging to NHNF and 640 belonging to H-NF). Fig. 4(b) shows the proposed MLP. Specifically, the features vector (sized 1 × 256)previously extracted from the unsupervised processor is used as input to a MLP with 2 hidden layers of 100 and 80 hiddenunits, respectively. Note that the hyperbolic tangent is used as activation function for each hidden neuron. The network ends with a softmax output layer employed to perform the 2-way classification task: NH-NF vs. H-NF. The architecture, here referred to as MLP100,80, was trained over 103epochs on the aforementioned workstation (i.e., Intel (R) Core (TM) i7-8700K CPU @ 3.7 GHz with 64 GB RAM and 1 NVIDIA GeForce RTX 2080 Ti GPU installed). Training time was on average of about 40 minutes using the leave-one-out (LOO)technique over the whole dataset.

TABLE II CLASSIFICATION PERFORMANCE IN TERMS OF PRECISION, RECALL, F-SCORE, AND ACCURACY OF MLP WITH DIFFERENT HIDDEN LAYERS(HL) AND HIDDEN UNITS
V. EXPERIMENTAL RESULTS
A. Performance Metrics
The performance of the proposed hybrid unsupervised and supervised ML system were assessed using a set of standard metrics, i.e., Precision, Recall, F-score , and Accuracy,defined as follows:

where tp, fp, tn, fn are the acronyms of true positive, false positive, true negative, false negative, respectively. In this study, tp denotes SEM images with defects correctly identified as NH-NF; fp denotes SEM images of homogeneous nanofibers misclassified as NH-NF; tn is the number of SEM images of homogeneous nanofibers correctly identified as H-NF; fn is the number of SEM images of nanofibers with defects misclassified as H-NF. As described in Section IV, the augmented features dataset of 1280 instances (640 belonging to H-NF and 640 belonging to NH-NF) was used as input to our proposed MLP. It is worth mentioning that the LOO technique was applied to validate the efficiency and generalization ability of the developed model. Specifically,LOO consists in partitioning repeatedly the dataset into train set, composed of all instances excluded the ith, and test set composed of the ith left-out observation. Here, the LOO procedure was applied to the whole dataset. Hence, N = 1280 networks were trained on N-1 data-points and tested on the held-out case.
Note that the best MLP architecture was determined using a trial-and-error approach, namely, estimating the performance of different numbers of hidden neurons and hidden layers.Table II reports comparative classification performance in terms of Precision, Recall, F-score, and Accuracy. First, the 256-dimensional input representation was used as input to MLP classifiers with 1-hidden layer of different size.Specifically, 40, 60, 80, 100, 120, 140 hidden units were tested. Experimental results show that the 1-hidden layer MLP with 100 neurons (denoted as MLP100) achieved the highest F-score and Accuracy : 92.04% and 91.80%, respectively.Next, additional layers were used in order to find out possible better configurations. In particular, MLP classifiers with 2-hidden layers were tested, that is: MLP100,40, MLP100,60, and MLP100,80. As can be seen, among these architectures,MLP100,80reported the highest F-score and Accuracy: 92.68%and 92.50%, respectively. Finally, MLP classifiers with 3-hidden layers were tested: MLP100,80,20, MLP100,80,40, and MLP100,80,60. Here, the higest scores were achieved by MLP100,80,60with F-score of 90.88% and Accuracy of 90.63%. Hence, comparative results show that the 2-hidden layer MLP100,80achieved the best classification performance in terms of Precision (95%), Recall (90.48%), F-score(92.68%), and Accuracy (92.50%).
The proposed MLP100,80was also compared with other standard ML techniques. Notably, support vector machine with linear kernel (SVM, [50]) and linear discriminant analysis (LDA, [51]) were developed to perform the 2-way discrimination task (NH-NF vs. H-NF). For fair comparison,LOO procedure was applied to the whole dataset. Table III reports the performance of each classifier evaluated on the test sets: MLP100,80, SVM, and LDA. Specifically, SVM classifier achieved F-score of 65.87% and Accuracy of 66.72%;whereas, LDA classifier achieved F-score of 64.06% and Accuracy of 64.84%. As can be observed from Table III, our proposed MLP100,80outperformed all of the other models. In support of this outcome, the receiver operating characteristic(ROC) and the corresponding area under the curve (AUC)measure of the developed MLP, SVM, LDA based classifiers were evaluated. As can be seen in Fig. 5, MLP achieved the highest AUC score of 0.90.

CLASSIFICATION PERFORMATNACBE LINE TIIEI RMS OF PRECISION, RECALL,F-SCORE AND ACCUSRVAMCY A ONFD TLHDEA P CROLAPOSSSIEFDE RMS LP (i.e., M LP100,80),
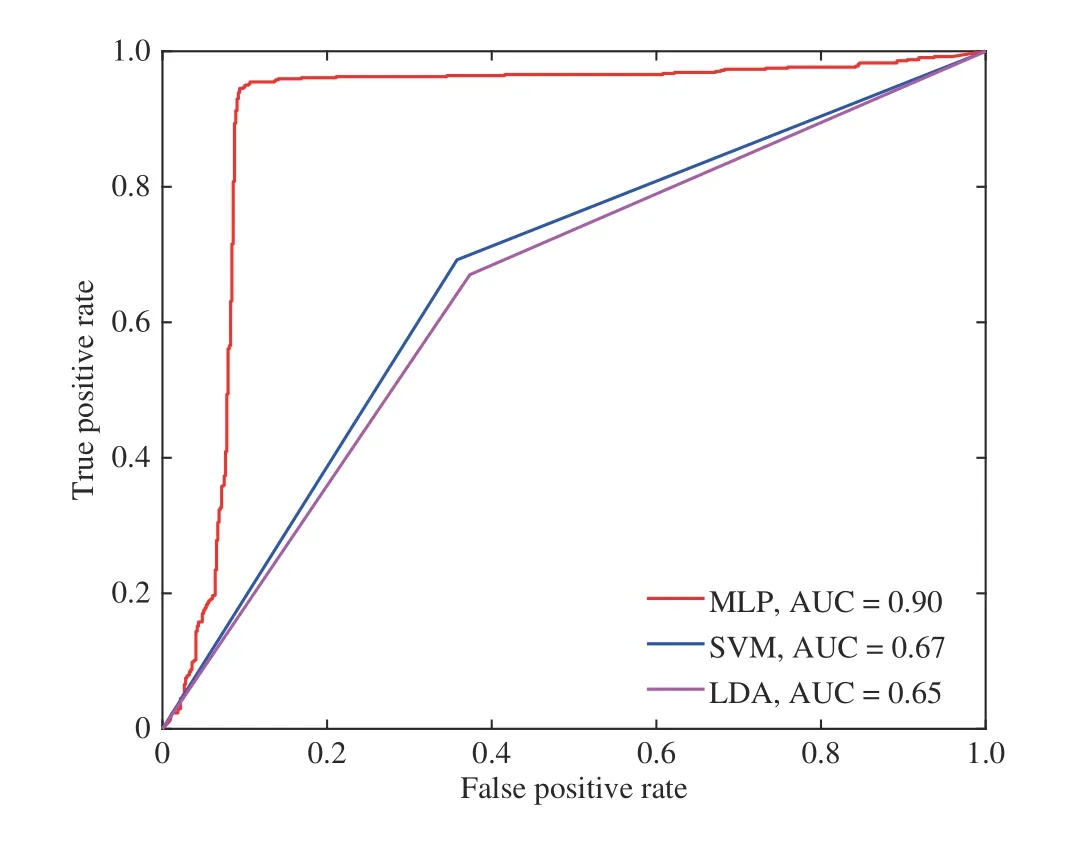
Fig. 5. ROC curves and corresponding AUC values of the proposed MLP,SVM and LDA classifiers for the NH-NF vs. H-NF classification. Note that the figure refers to the best MLP architecture (i.e., MLP100,80) as reported in Table III.
B. Permutation Analysis
In order to assess the dependency of the proposed classifier on the available dataset the standard permutation-based pvalue statistical test is carried out [52]. This test estimates the p-value under a certain null hypothesis that is: features and class labels are independent. Specifically, the labels are repeatedly permuted and for each iteration the statistical metric of interest (here, the accuracy Ai, with i = 1, 2,...,Nperm) is computed. Finally, p-value is empirically calculated as the total number of all Aiequal or greater than the performance estimated with the original dataset (i.e., accuracy Ao) , divided by the number of permutations ( Nperm). p-value smaller than a threshold (typically, α = 0.05) results in rejecting the null hypothesis and consequently concluding that the classifier is statistically significant. It is worth noting that,ideally, all of the possible labels permutations should be taken into account in order to evaluate the exact p-value. As this is computationally expensive, in this study, Nperm= 100 were performed [52]. Experimental results reported that p-value =0.00/100 = 0.00 < 0.05. Hence, the null hypothesis is rejected.In conclusion, the proposed classifier is statistically significant.
C. Comparison With Previous Works
The proposed classification system was also compared with previous works that addressed the classification of SEM images (NH-NF vs. H-NF) by using the same dataset of 160 SEM images employed in this study. In [34] raw H-NF/NHNF SEM images (sized 128 × 128) were fed directly into a DL classifier. Notably, a deep CNN was developed to perform the 2-way classification task (i.e., H-NF vs. NH-NF). The network achieved good performance (Accuracy of 80%). It consisted of 5 convolutional layers with 16, 32, 64, 96,128 filters (sized 3 × 3), respectively, 5 max pooling layer (each with filter size 2 × 2), 1 fully connected layer with 40 hidden neurons and 1 softmax output layer for the binary classification. In [35] the available H-NF/NH-NF SEM images (sized 128 × 128) were pre-processed by using an optimized Sobel filtering able to provide information on the contours of the SEM image taken into account. Although the complexity of the input image was reduced (i.e., binarized) the same deep CNN of [34] was employed reporting similar classification performance. In contrast, here, the proposed hybrid ML system allowed to achieve better classification performance (F-score of 92.68%, Accuracy of 92.5%) using a considerably simpler architecture. Indeed, the proposed system consisted of 1-hidden layer AE with 256 hidden neurons and 2-hidden layers MLP with 100 and 80 units,respectively. It is also to be noted that the use of sub-patches allowed the use of a coding through AE; at least in the final online working only the encoding stage was present, and the different layers could be easily reduced by using a larger database of examples. The use of ReLU activation functions in MLP can further reduce the cost. In order to improve the classification abilities of the MLP and to augment the experimental database, in this study, a white Gaussian noise at SNR = 10 dB was used to corrupt the features dataset extracted by the AE. Such noisy feature data were included in the original dataset, artificially increasing its cardinality. This operation allowed to roughly simulate new electrospinning experiments and achieve improved generalization. This computational approach can also be, in principle, used to emulate experiments at different configuration parameters thus reducing the whole cost of the experimental procedure.
VI. DISCUSSION

Fig. 6. (a) Representation of the 256-dimensional features vector extracted by a SEM H-NF image (sized 64 × 64) via the proposed AE. (b) Examples of 10 reconstructed H-NF images.
In this paper, an innovative hybrid unsupervised and supervised ML system is proposed aiming to automatically reject defective electrospun nanofibers by processing the related SEM images. The dataset here used for training the classification system is composed of 160 SEM images of PVAc nanofibrous materials [34]. However, in order to reduce the complexity of the classification task, the available full images, generated by the microscope, were divided into four sub-patches. The cardinality of the resulting dataset is now 640: 320 images belonging to NH-NF and 320 to H-NF classes, respectively. Each SEM image sized 64 × 64 was reshaped into a single vector (sized 1 × 4096) and used as input to the first module of our proposed hybrid ML system,i.e., the AE. The developed AE [4096: 256: 4096] was trained off-line using unsupervised learning and was employed to automatically extract the most relevant features from the input representation. As an example, the presence of beads in the original image reflects in segment of the feature vector with consecutive high values, whilst the presence of a regular texture gives rise to a quasi-periodic representation with low and high values. Next, the compressed 256-dimensional features vector was used as input to the second (supervised)module of the hybrid ML system, i.e., the MLP. The proposed 2-hidden layer MLP (i.e., MLP100,80) performed the binary discrimination task: NH-NF vs. H-NF.
The decomposition of the original SEM image in subpatches simplifies the processing and allows to zoom in small sections of the image that can include some defects. This is in contrast to the standard processing of the full image information. Furthermore, the originality of the proposed methodology lies in coding the information of the SEM subregions (i.e., their texture) into a compressed features’ vector achieved by the AE processor, by using only unlabeled data.Such unsupervised data compression allowed to facilitate the supervised training of the classification processor (i.e., MLP).It is worth noting that the average reconstruction error of the AE [4096: 256: 4096] was very small, namely, of only 0.4416; thus, the loss of information in the compression stage is rather acceptable as being finalized to reveal the presence of defects, not to regenerate the original image. As an example,Figs. 6(a) and 7(a) report the representation of the 256-dimensional features vector extracted by a H-NF and a NHNF images with the proposed AE. The figures also show the decoded images of 10 H-NF (Fig. 7(b)), and 10 NH-NF(Fig. 6(b)). As can be seen, the original NH-NF/H-NF image and the corresponding reconstructed NH-NF/H-NF image(produced by the AE) are visually similar. Note that the size of AE was empirically defined after several trial-and-error simulations. Furthermore, in order to find out the best MLP architecture, different numbers of hidden layers and hidden units were also tested (Table II). Experimental results show that our proposed hybrid unsupervised and supervised ML system, that is, the combination of AE and MLP architectures,reported the highest performance when compared with other ML-based classifiers (i.e., SVM, LDA). Specifically, the proposed MLP100,80achieved F-score and Accuracy rate up to 92.68% and 92.50%, respectively. Furthermore, a permutation test was carried out to assess the statistical significance of the estimated classification accuracy.

Fig. 7. (a) Representation of the 256-dimensional features vector extracted by a SEM NH-NF image (sized 64 × 64) via the proposed AE. (b) Examples of 10 reconstructed NH-NF images.
VII. CONCLUSION
In this paper, a novel automatic classification approach for SEM images of homogenous and non-homogenous patches of nanofibres has been proposed. To this end, a hybrid unsupervised and supervised ML based classification system is developed, specifically, the combination of an AE (trained with unsupervised learning) and a MLP (trained with supervised learning). Experimental simulations show that such a hybrid approach achieves the highest performance in terms of Precision, Recall, F-score, Accuracy, and AUC. Notably,the proposed AE-MLP system outperforms other standard ML techniques as well as other recent state-of-the-art methods,reporting an accuracy of up to 92.5%. However, the proposed hybrid ML system also has some limitations. First, from a technological perspective, limited electrospinning experiments have been carried out (i.e., 16) by using the same polymer(i.e., PVAc). Second, given the original full-size SEM image,ten representative electrospun regions have been manually selected, which make the procedure initially dependent on an expert technician. Third, a relatively naive technique of data augmentation was used; the cardinality of the original dataset of features (extracted by the unsupervised processor) is artificially increased by corrupting it with a white Gaussian noise of SNR = 10 dB. A higher level of noise determines a reduction of performance. Fourth, in this study, SEM images have been subdivided into four sub-patches and classified one by one into H-NF and NH-NF. Note that we decided to partition the original SEM image into only four sub-regions due to the difficulty of manually annotating the whole nanopatches dataset. We believe more sub-images with a smaller size would allow more efficient detection of possible anomalies in a SEM image and also improve the generalization performance of our proposed unsupervised and supervised system. In this regard, we will explore innovative ways to automate the annotation process, using human-in-theloop AI approaches. Furthermore, a re-assembly step will be carried out in the future. Specifically, if at least one quadrant is not homogeneous, the entire SEM image will be classified as non-homogeneous and then automatically discarded,through the use of fuzzy learning approaches (e.g., [53]). In addition, the proposed unsupervised AE based methodology can form the basis of a generative model (e.g., [54], [55]) that will allow augmenting the database by designing a reduced number of novel costly laboratory experiments. Other novel combinations of state-of-the-art deep and reinforcement [56],[57], ensemble-based [58]-[60], multi-task learning [61], [62],extreme learning machine [63], [64] approaches and new dendritic neuron models [65] will also be explored for a more extensive comparative evaluation.
ACKNOWLEDGMENT
The authors would like to thank the researchers at the Materials for Environmental and Energy Sustainability Laboratory at the University Mediterranea of Reggio Calabria(Italy) for use of the electrospinning system to generate the SEM image database adopted in this work.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Multi-Layered Gravitational Search Algorithm for Function Optimization and Real-World Problems
- Dynamic Hand Gesture Recognition Based on Short-Term Sampling Neural Networks
- Dust Distribution Study at the Blast Furnace Top Based on k-Sε-up Model
- A Sensorless State Estimation for A Safety-Oriented Cyber-Physical System in Urban Driving: Deep Learning Approach
- Theoretical and Experimental Investigation of Driver Noncooperative-Game Steering Control Behavior
- An Overview of Calibration Technology of Industrial Robots