混合现实装配检测中深度学习的数据增强方法
2021-04-12郭锐锋董志勇王鸿亮张晓星
王 帅,郭锐锋,董志勇,王鸿亮,张晓星
(1.中国科学院大学 计算机与控制学院,北京 100049;2.中国科学院沈阳计算技术研究所,辽宁 沈阳 110168;3.陆军炮兵防空兵学院士官学校,辽宁 沈阳 110867)
0 引言
伴随着信息技术和先进制造的深度融合,智能制造日益成为制造业发展的主要趋势,装配是机械制造中的重要生产阶段,其任务繁多且过程复杂[1],正确装配是保证合格产品高精度组装的先决条件。目前人工装配仍具有不可替代的作用。传统的人工装配检测需要大量的劳动力且检测效果具有不确定性。温沛涵等[2]采用传统图像处理技术,并引入基于纹理分析和统计图像处理方法,进行装配视觉检测,但耗时较长。王小巧等[3]提出装配过程质量门监控方法,并基于状态空间模型进行装配误差分析,但装配质量控制参数有待进一步优化。模式学习、形状匹配、图像分割、特征分析、决策分类[4],以及基于单目、双目的目标识别[5-6]也是传统的工件检测识别方法。但这些方法大多是人为特征提取,主观性较强、设计较复杂,难以适应实体二维成像表观特征的多样性,普遍存在时间复杂度高,对多样性样本鲁棒性差的特点。近年来,深度学习对复杂背景下的目标识别表现突出[7],而且被广泛应用于智能制造领域。基于混合现实的装配检测可以实时进行装配和检测,能最大程度地避免周期延误、经费消耗、效率低下的情况。但是基于深度学习的混合现实装配检测方法存在两点问题:①光线干扰,装配者佩戴混合现实眼镜,无固定光源确保采集样本感光一致;②混合现实眼镜具有位姿不确定性,装配者与工件距离和角度都会对检测结果造成影响,对模型的泛化能力要求较高。
众所周知,深度学习是有标签的监督学习,样本需要大量人工标注,费时费力,成本昂贵。因此,采用数据增强技术转换人工标注,保留标签生成数据增强集[8]是目前最为有效的数据扩充方法。大量研究者应用数据增强技术扩充样本优化深度学习模型,提升识别精度。薛月菊等[9]采用自适应直方图均衡化方法减少光照因素的影响,通过调整图片亮度,可有效增加样本图像光照的多样性。但该方法对图片局部对比度提高过大,易导致图像失真较严重,而且局部对比度过高还会放大图像中的噪声。Yang等[10]采用多角度旋转结合卷积神经网络进行工件识别,未涉及复杂照明和背景下的多目标检测的研究。Stern等[11]先使用随机数据增强样本(如旋转90度和亮度变化),再经过多个卷积神经网络优化分类结果,该方法未规划数据增强方式,数据增强的方式为随机产生。Zhong等[12]随机为样本生成遮挡效果,增加低质量样本,进而提高模型的鲁棒性,但低质量样本占整个数据集的比重过大易影响模型的识别精度。Jia等[13]对基于深度卷积神经网络的图像分类任务的数据增强方法进行了综述,未讨论多种类的不平衡训练数据和负责网络模型。Cubuk等[14]考虑到样本的非对称性,采用搜索算法寻找最佳策略进行数据增强。袁功霖等[15]用Retinex算法进行增强处理,以增强夜间图片与日间图片的相似性,有效识别夜间航拍图片。由此得出,选择合适的策略对样本检测的正误率非常重要,但目前缺少对混合现实装配检测行之有效的深度学习的数据增强预处理方法的相关研究。为此,本文提出一种混合现实装配检测中深度学习的数据增强方法,在已有的基于卷积神经网络的智慧车间装配检测和跟踪方法的相关研究[16-17]基础上,采用人为最佳数据增强策略的数据预处理方法,从而有效进行数据集的扩充,提高模型的检测精度和泛化能力。
1 混合现实装配检测方法
混合现实技术在制造方面的研究是一个新兴领域,可有效增强装配制造过程,从而缩短时间、降低成本、提高质量[18]。基于混合现实技术的装配检测具有以下特点:①虚拟信息与真实场景无缝叠加,互相依赖且上下文敏感,可实时交互,无眩晕感,可有效增强装配者的装配体验;②无固定摄像头采样和固定屏幕显示,装配自由度更好,能确保准确装配的同时简化装配生产线布局。
混合现实装配检测的整个过程分为客户端和服务器端。客户端如图1所示,装配人员在装配过程中佩戴混合现实眼镜,可实时完成装配和检测。客户端采集实时数据上传到服务器端,服务器端存放装配零件的目标检测模型,模型将处理完成的混合现实提示信息及时传回传客户端。整个过程用时不到60 s,肉眼不能分辨,近乎实时检测。该模型由Faster R-CNN(towards real-time object detection with region proposal networks)卷积神经网络训练得到,Faster R-CNN卷积神经网络可以看作是区域建议网络和Fast R-CNN 网络的组合,区域建议网络生成候选框,Fast R-CNN 网络进行目标识别。前期自定义13 类待检测目标,首先采用预训练VGG16网络进行模型初始化,然后样本数据集经过预训练模型处理生成装配检测模型。混合现实技术直观地辅助指导装配人员,避免屏幕与装配实体存在对应有误的问题。然而,针对混合现实装配检测中装配者的检测位姿具有不确定性,极易发生误检漏检的问题,本文提出一种混合现实装配检测中深度学习的数据增强方法。该方法可有效解决深度学习中人工标注样本任务量大的问题,提升检测模型的泛化能力和装配检测模型的识别精度。同时,分该方法还能弥补工件多样性造成的二维表观特征难以充分表示的不足,解决比如小工件和相似形状或材质的工件二维成像后表观特征难以区分的问题。

2 数据增强的数据预处理方法
2.1 数据增强集
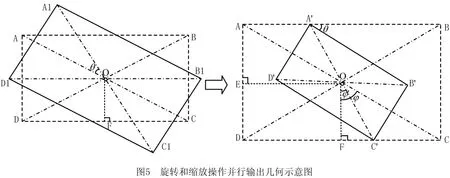
采用数据增强技术增加样本多样性是提升卷积神经网络检测精度和泛化能力最简单有效的方法。数据增强技术通过采用人为最佳数据增强策略和随机增加数据多样性的方法来实现。实验中的数据增强集的表达式为D=Dorigin∪DA-all∪DS-all∪Dlow,如图2所示为数据增强集部分样本,数据增强集相关内容如表1所示,其中Dorigin=DS-origin∪DA-origin,Dorigin为采集样本的原始数据集;DS-origin为对称样本原始数据集;DA-origin为非对称样本原始数据集;DS-all为对称样本数据增强集;DA-all为非对称样本数据增强集;Dlow是低质量图像样本集,Dlow=Dnoise∪DeraseDnoise;Dnoise是人为噪声干扰增强数据集;Derase为随机遮挡效果数据增强集。


表1 增强数据集
2.2 基于改进V-CLAHE方法的数据集样本图像增强
由于随机干扰的影响以及装配件车间存在粉尘大、阴天照明度低的客观因素制约,线阵工业摄像头采集的图像样本常伴有噪声混入。针对细节模糊、对比度低的图像样本,加强图像边缘、保持真实度是图像增强时关注的两大要素。本文在自适应直方图均衡化方法[19]的基础上对局部对比度进行限制,选用局部对比度限制自适应直方图均衡化方法[19],对装配件图像样本进行降噪和对比度增强,样本增强后效果如图3所示。

图3b所示的限制对比度的自适应直方图均衡化(Contrast Limited Adaptive Histogram Equalization,CLAHE)方法对有海绵的样本处理后效果不佳,失真较为严重,故本文对CLAHE 方法进行改进,提出V-CLAHE(value-CLAHE)方法提高图像颜色逼真度,V-CLAHE 方法是CLAHE 方法与HSV(Hue,Saturation,Value)颜色模型中V 通道结合的方法。V-CLAHE方法流程如图4所示,具体步骤如下:
步骤1输入真实图像样本。
步骤2真实图像样本由RGB 空间变换到HSV空间。

步骤3针对亮度V 通道采用静态小波变换,分解为入射分量和反射分量。
步骤4利用CLAHE方法对亮度通道的入射分量进行能量重分配。
获取输入值平均像素数值Paverage、对比度受限值L、每个灰度级获得剪裁部分的像素值和分配裁剪像素的步长S。剪切直方图并生成灰度映射。在每个灰度级上划分,计算平均像素数值:
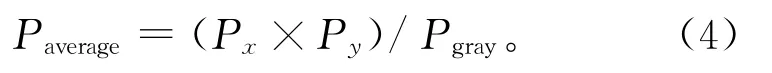
式中:Paverage为平均像素数值,Pgray为局部子区域灰度级像素值,Px为局部子区域x方向像素值,Py为局部子区域y方向像素值。计算对比度受限值:

式中:α表示裁剪系数,α∈[0,1]。截取每个局部子区域直方图中大于L的像素数,裁剪部分的总像素为∑Pclip,求出裁剪部分的总像素分配到每个灰度级的像素数为:
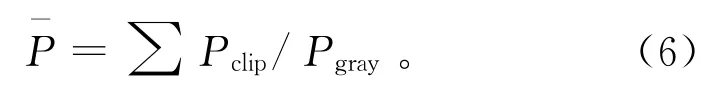
计算分配裁剪像素的步长:
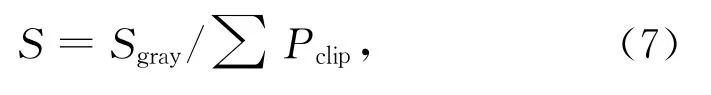
其中:S为分配像素步长,Sgray为灰度范围长度。
步骤5按步长循环搜索灰度级小于对比度受限值的位置并分配一个像素值。如像素未分配完,则重复步骤4,直到分配完所有剩余像素。
步骤6小波逆变换后,进行双线性插值运算完成灰度映射,将增强后的真实图像样本由HSV空间变换到RGB 空间,修正三基色RGB 的加权系数。
步骤7输出新生成的图像样本。

2.3 基于SGT方法和AGT方法数据集几何变换
自动数据增强方法[14]是创建一个搜索空间,使用搜索算法来寻找最佳策略,为每个样本随机选择两种操作变换的图像处理函数,依据样本特性,选取适合特定数据集的数据增强策略。本文提出对称几何变换方法(method of Symmetrical Geometric Transformation,SGT)和非对称几何变换方法(method of Asymmetric Geometric Transfprmation,AGT),对实验者熟知的数据增强方法进行改进,如采用平移、剪切、缩放、旋转、镜像、加噪声、调整色彩亮度和对比度[11]等操作,有效扩充训练样本。SGT方法针对对称样本效果明显,AGT 方法针对非对称样本效果明显,如表2所示样本示例中,装配件B和装配件D 是对称样本,装配件A、装配件C和装配件E是非对称样本。实验证明,非对称样本进行镜像数据增强为无效操作。
2.3.1 SGT方法
定理1SGT方法是指对称装配件人为决策最佳数据增强的几何变换最优组合方法,详见算法1。
算法1SGT方法。
输入人工选择不同放置姿态,不同背景的真实图像样本。
输出增加的数据集DS-all,以及对应的检测特征目标标签的集合PS-all。
步骤1设置增加图像的数量Qi,输入不同放置姿态,不同背景的真实图像样本。
步骤2读取实际图像样本Ti,并将输入图像作为模板图像,获取图像样本边缘矩形框的4个顶点A(Xtop,Yleft),B(Xtop,Yright),C(Xbottom,Yleft),D(Xbottom,Yright)。
步骤3获取手动标记的装配件上检测特征目标的标签,得到每个检测特征目标对应的4个顶点(xi-top,yi-left),(xi-top,yi-right),(xi-bottom,yi-left),(xi-bottom,yi-right)。
步骤4对图像样本边缘矩形框的4个顶点和样本中已标记的检测特征目标点进行关于Y轴的水平翻转变换Ti-h。设原图像高为h,宽为w,图像中A(Xtop,Yleft)经过水平翻转Ch点(x1,y1)矩阵表达式为
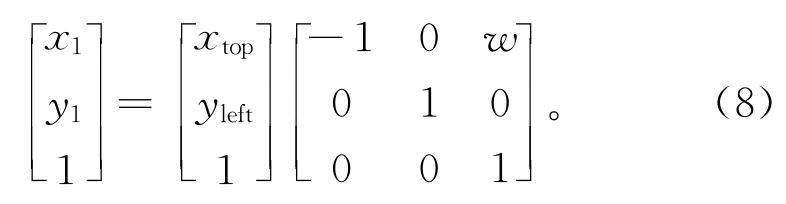
步骤5对图像样本边缘矩形框的4个顶点和样本中已标记的检测特征目标点进行关于X轴的垂直翻转变换Ti-V。设原图像高为h,宽为w,图像中A(Xtop,Yleft)经过水平翻转CV点(x2,y2)矩阵表达式为
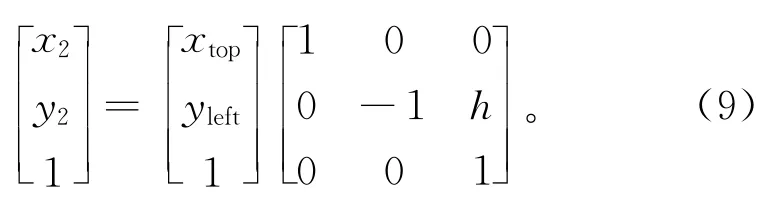
步骤6将水平翻转后得到的图像Ti-h和垂直翻转后得到的图像Ti-V得到数据集D1加入实际图像Ti所在的数据集DS-origin,得到增强数据集D2=DS-origin∪D1。
步骤7数据集L1旋转操作和缩放操作并行输出,分别旋转θ°,缩放比例因子为M,实验中θ=[30°,60°,90°,120°,150°]。图像样本上的点A(Xtop,Yleft)围绕中点O(x0,y0)旋转,得到A1(Xtop1,Yleft1)。
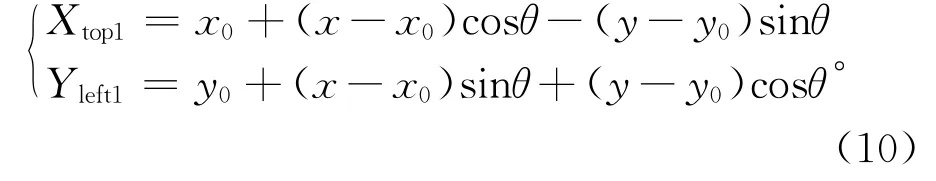
如图5所示,图像样本Ti的4个顶点为A,B,C,D,对角线交点为O,从O点向AD边作垂足交于E点,从O点向DE边作垂足交于F点,∠BA'B'=∠θ,∠FOC'=∠φ',∠FOC=∠φ。图像样本Ti的长为h,宽为w,即AB=h,AD=w,∠φ旋转角为θ,则φ'=φ-θ。缩放比例因子为

步骤8将旋转并按比例因子M缩放后的图像集合得到数据集D3,加入翻转增强的数据集D2得到新增强数据集D4=D2∪D3。
步骤9增强数据集D4进行裁剪操作。如图1所示,通过D'点作边AD的平行线交AB和CD边分别为点G和H,裁剪操作就是剪裁掉矩形AGHD。
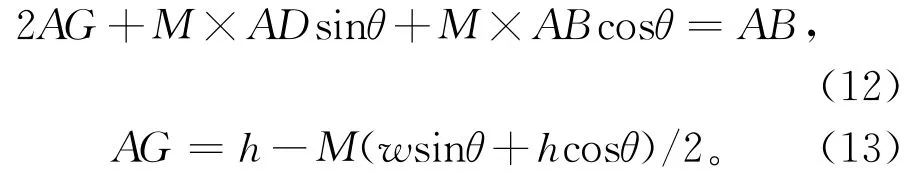
步骤10如果条件成立,执行步骤4~步骤9。
步骤11用式(8)~式(13)映射匹配检测特征目标标签,得到新标签PS-all。
步骤12增加的数据集DS-all=D4∪DS-origin,以及对应的检测特征目标标签的集合PS-all。
2.3.2 AGT方法
定理2AGT 方法是指非对称装配件在基础几何变换操作基础上,融合样本图像增强,人为筛选最佳数据增强策略的方法,详见算法2。
算法2AGT方法。
输入人工选择不同放置姿态,不同背景的真实图像样本。
输出增加的数据集DA-all,以及对应的检测特征目标标签的集合PA-all。
步骤1~步骤3与上文SGT方法相同。
步骤4将输入图像样本数据集DA-origin,以图片样本中心O为原点进行旋转操作,图片经过归一化处理,故旋转中心O与上文相同。
步骤5获得旋转操作后的图像样本集合DR。
步骤6对图像样本边缘矩形框的4个顶点和样本中已标记的检测特征目标点进行平移变换。图像中A(Xtop,Yleft)经过平移变换点At(xt,yt)的矩阵表达式为
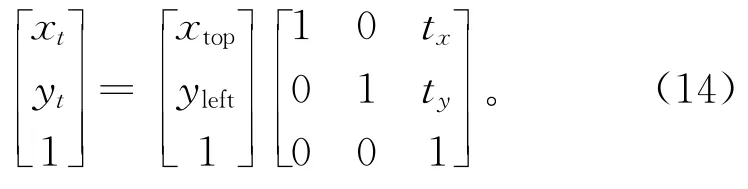
根据采集样本的自身特性,为最大程度地保留已标记的检测特征目标点,平移操作需在指定范围,即
步骤7获得平移操作后的图像样本集合DT。
步骤8用CLAHE方法进行图像样本增强,获得CLAHE 方法操作后的图像样本集合DV-CLAHE。
步骤9如果条件成立,执行步骤4~步骤8。
步骤10用式(14)映射匹配检测特征目标标签和图像增强样本标签Padd,得到新标签汇总集合PA-all。
步骤11增加的数据集DA-all=DA-origin∪DR∪DT∪DV-CLAHE,及对应检测特征目标标签的集合PA-all。
2.4 干扰增强数据集
由于模型精度过高,不易于真实样本检测,为保证样本图像的多样性,提升模型的泛化能力,在样本中加入噪声干扰和随机遮挡,降低图像质量。采用具有零均值特性的高斯噪声,降低样本学习时的高频特征,有效提升模型的泛化能力。但在降低高频特征信息的同时,低频特征也会受到影响,故添加适量的噪声干扰,再通过大量样本学习来忽略影响。实验证明,本方法能够有效防止模型的过拟合。噪声干扰增强数据集Dnoise如图2c和图2f所示。
实际应用中,当装配者佩戴混合现实眼镜进行实时装配时,很多客观因素决定了训练生成模型需要对遮挡具有鲁棒性,同时降低过度拟合的风险。随机擦除图像中的一个矩形区域[12],擦除细节信息,降低图像质量,相当于生成了不同遮挡程度的训练图像,可对常用的数据增强技术进行较好的补充,随机遮挡训练图像样本如图2a、图2b、图2d和图2e所示。实验时在装配件AB数据集中应用Derase增强数据集。
3 案例实验与验证
3.1 实验数据采集
被采集的装配件共5种,其中检测特征目标13类,用Hololens混合现实眼镜和工业摄像头采集实验数据,如表2所示。采集时灯光为室内日光灯或日光光线。汽车装配车间内一天的光线变化较明显,样本覆盖一天的光线变化。将数据增强的样本归一化处理,固定长宽比为0.5,分辨率为800×400 pixel。采集的实验数据人工标注检测特征目标,具体位置存储在XML文件中,用于生成增强数据集和训练模型。

表2 5种装配件检测特征目标
3.2 实验环境
本文实验操作系统是Ubuntu Linux 16.04,深度学习框架是Caffe。CPU 是Intel(R)Core(TM)i5-7500 CPU @3.40 GHz。显卡的处理器是Ge-Force GTX 1060,GPU RAM 是6 GB。CUDA 架构(compute unified device architecture)是NVIDIA提出的通用并行计算架构,用来解决GPU 复杂的计算问题,其版本号是8.0.44,CUDNN 库是NVIDIA专门为深度神经网络设计的基于GPU 的加速库,成功安装后训练速度是原来的4倍,其版本号是5.0.5。Python版本号是2.7.14。
3.3 实验结果
3.3.1 训练实验
实验中,用loss值判断模型学习训练的成功性,用准确率和召回率评判识别的准确性。采样原始数据集为823个样本,数据增强集为15 219个样本。学习率(base-lr)为0.000 5,阈值(Io U)为0.4,丢失率(dropout-ratio)设置为0.5。使用随机梯度下降(Stochastic Gradient Descent,SGD)优化方法,收敛效果更加快速稳定。每训练20次显示一次收敛结果,上一次梯度值的权重(momentum)设置为0.9,权重衰减参数(weight-decay)为0.000 5。卷积层核大小(kernel-size)设置为2,步长(stride)设为2,卷积层网络可视化如图6所示,图像特征平滑清晰,对比度较大,特征提取较好,训练时模型拟合较佳。

迭代次数设置为60 000时,此时完全收敛,模型的训练耗时相对较短,检测效果最佳。原始数据集中样本较单一,训练时网络收敛较快,在30 000次迭代时基本完成收敛,loss值稳定趋于0.009,此时得到训练模型M。因而数据增强集样本的多样性使模型的差异性增大,因而收敛速度相对较慢,在45 000次迭代时基本完成收敛,loss值稳定趋于0.004,此时得到训练模型N,loss损失函数值越小,模型拟合效果越好。本实验训练过程的loss特征曲线如图7所示。
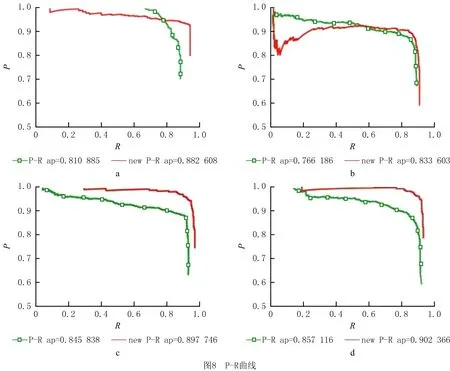
准确率和召回率曲线(Precision-Recall,PR)能有效地反映出训练模型的检测性能。准确率和召回率互相制约,以准确率为纵轴,召回率为横轴绘制出的曲线成为PR曲线,PR 曲线包围的面积越大,表示训练模型的检测性能越强。如表2所示,在样本数据集中选取顶角A、铝角、海绵A、T 孔四个检测特征目标,应用增强数据集前后对比效果的PR 曲线如图8所示,分别对应8a图、8b图、8c和图8d,其中P-R表示原始数据集产生的识别结果,new P-R表示增强数据集产生的识别结果。准确率(P)是在识别出来的图片中,正样本被正确识别为正样本所占的比率。召回率(R)是测试集中所有正样本样例中,被正确识别为正样本的比例,定义如下:


式中:TP为正样本被正确识别为正样本;TN为负样本被正确识别为负样本;FP为假的正样本,即负样本被错误识别为正样本;FN为假的负样本,即正样本被错误识别为负样本。
3.3.2 测试实验
以上的训练过程各个指标达到预期结果,模型的泛化能力和鲁棒性还需要进行测试集验证。使用改进的数据增强集训练模型N进行测试验证,用十折交叉验证,测试集样本为1 522个,随机选取20个测试样本进行测试,其中包含检测特征目标13类,每种装配件有20张采集图片,每张采集图片中,均含有多种检测特征目标,测试集装配检测结果如表3所示。

表3 测试集装配检测结果
由表中数据可得综合460个测试目标的正检测率为94.15%。其中装配件B上的检测目标铝片均出现了错检、漏检和重叠检测的情况。这是因为①标注者在标注时存在主观判断和选取设定误差;②采集训练样本时,由于标注目标在侧面存在遮挡情况,导致样本数少;③铝片在装配件的侧面,检测视角与训练样本有一定差距;④铝片金属材质存在一定程度的反光,测试样本受光照因素影响。由此可见光线、距离、角度因素与混合现实装配检测结果密切相关。
装配者佩戴增强现实头戴设备在完成装配的同时进行多角度的实时装配检测。混合现实设备具有无法固定光源和视觉检测位姿不确定性的特点。实验从光线、距离和角度3个要素定量分析增强数据集对提升模型鲁棒性和泛化能力的实验效果,受光线、距离和角度因素影响平均装配正检测率的实验数据分析如图9所示,其中平均装配正检测率受光线、距离和角度因素影响,平均装配正检测率分别提升10.98%、11.37%和11.79%。实验结果表明,该方法训练得到的新模型对汽车装配生产线零件的平均检测精度提升11.38%。
(1)光线因素影响平均装配正检测率
考虑日光强度随时间变化而改变,用24时计时方式,选取7时~19时这12小时时间段进行平均装配正检测率受光线因素影响的测试。增强数据集训练的模型在工作时间正检测率在92%~96%之间,检测精度较佳,可见数据增强集中的V-CLAHE方法起到了一定作用。如图9所示,在9时~15时日光光强较大正确检测率较高,19时日光几乎为0,仅依靠装配车间的室内照明灯,光线最弱,在混合现实眼镜上加点光源,随装配者视角发生变化,检测目标暗影也会变化,因此造成的重叠率较高,此时正检测率最低,应用增强数据集比原始数据集平均装配正检测率增加12.49%。
(2)距离因素影响平均装配正检测率
距离因素主要考虑混合现实眼镜到装配件中心距离。训练样本采集的距离范围为装配者臂长触及装配件距离。但有时需要进行装配后的质量校验,故测试时距离范围扩大,以利于实验的全面性。如图1所示装配者装配过程已知,AB=dcm 为距离,BC=xcm 为装配件中心到装配者中心的长度,实验设定每10 cm 为一个长度间隔,则x={10,20,30,40,50,60},装配者身高范围150 cm~190 cm,装配工作台高h'=800 cm,AC=hcm,则h={70,80,90,100,110}。综合各种身高范围和人为设定长度间隔的由式(16)计算可得距离d={79.75,88.69,97.85,107.16,116.58}。
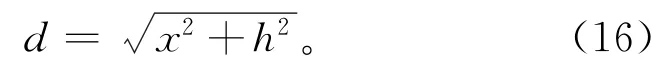
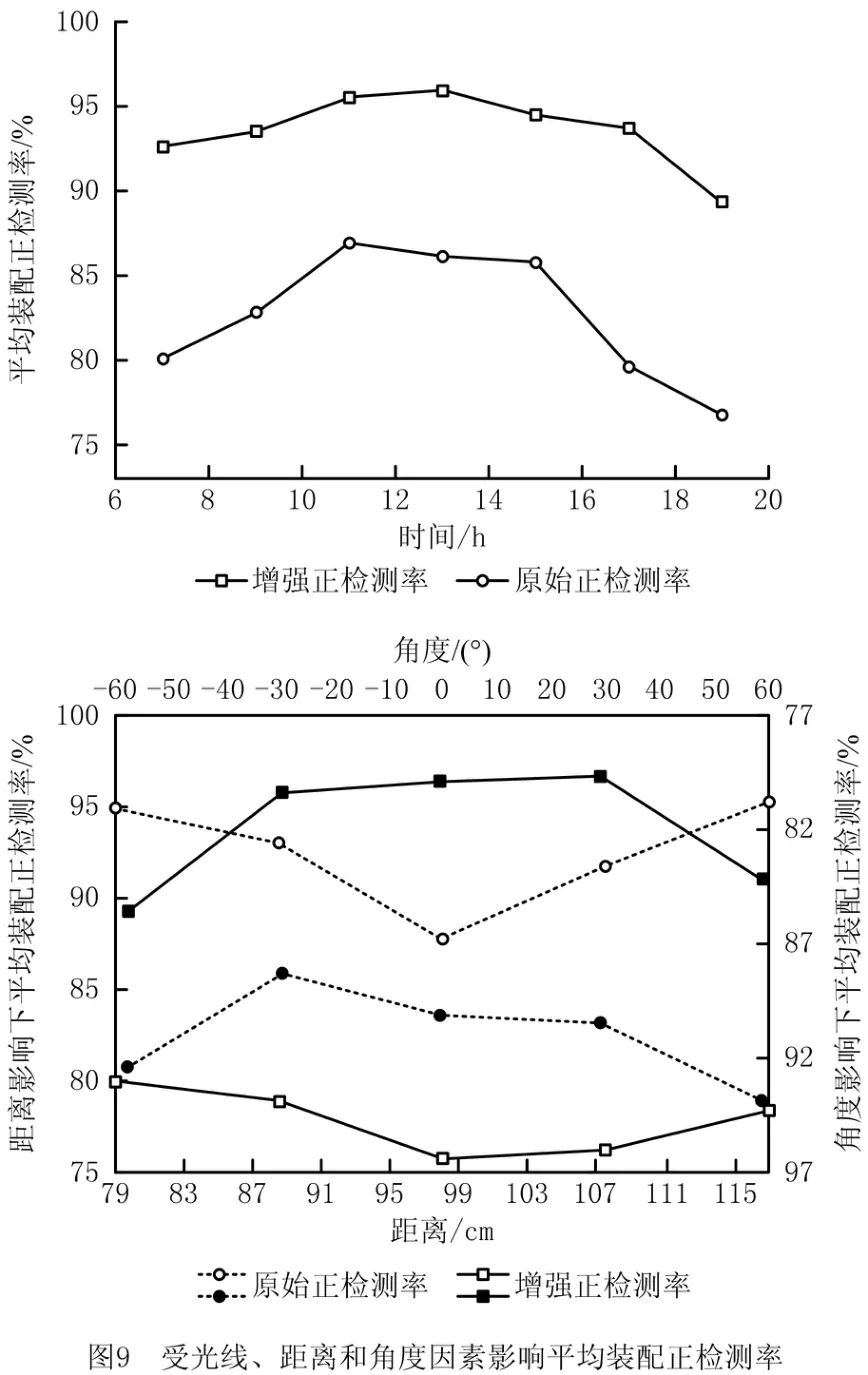
受距离影响下的平均装配正检测率,实际装配中身高为150 cm 与190 cm 的装配者极少,且距离为116.58 cm时,此时与装配件距离较远的原始正检测率最差仅为78.96%。但在增强正检测率中可明显看到12.09%的显著提升,其主要原因是增强数据集中用SGT方法进行数据扩充的数据起到关键作用,则增强的正检测率在远距离时优于最近距离1.78%。常规身高的装配者在装配范围可自由变换位置,正检测率基本没有变化为96%左右,与实验预期基本一致,满足混合现实装配中位置不断变化这一基础且核心的需求。
(3)角度因素影响平均装配正检测率
装配者中心和装配件中心点夹角为θ,θ={-60°,-30°,0°,30°,60°}。考虑装配工作台的宽度和传送带情况,装配者的活动范围在-60°~60°之间。如图9所示,原始数据集和增强数据集训练的模型在无角度的情况下训练效果均最好,差值为10.37%。增强数据集训练的模型对角度变化不敏感,具有较强的适应性,角度为负时,检测效果一般,这是由于部分检测目标被遮挡。
应用深度学习的数据增强方法,混合现实装配检测者不受光线、距离、角度三要素的约束,在装配的同时完成实时检测。能清楚区分该工件中待识别的细小检测单元,识别装配正确后返回精准位置信息,并在混合现实设备中标注绿色框,即装配成功;识别装配错误后也会返回精准位置信息,并在混合现实设备中标注红色框,即漏装或者误装。Hololens混合现实装配检测的第一视角效果展示如图10所示,实验选取具有代表性的装配件,装配件E具有检测目标小且颜色相似的特点,图10a为9时普通日光采集测试样本,此时检测目标是旋孔,安装位置角度有误,故标记为红色框,即发生错误安装,能及时装配者提醒;图10b为13时日光强烈采集测试样本,此时旋孔位置完全正确,故标记为绿色框,表示成功安装;图10c装配件A为非对称性浅色工件,检测出一个红色框,是缺少顶角A故识别为T孔,即发生漏装;图10d装配件B为对称深色装配件,其中顶角B、铝片、海绵B均成功装配,标记红色框为发生错误装配。由实验可得,增强数据集对提升模型鲁棒性和泛化能力有较强效果,能很好地应用于实际工业装配中。

3.3.3 对比实验
为证明数据增强的数据预处理方法的有效性,分别采用Fast RCNN[20]、Faster RCNN[21]、SSD300和SSD512[22]不同深度学习算法进行对比实验证明,该方法对不同模型都有提高,如表4所示。其中:对Fast RCNN方法性能平均提高7.2%,对Faster RCNN方法性能平均提高7.7%,对SSD300 方法和SSD512方法性能分别平均提高3.1%和3.5%。

表4 应用数据增强集前后在不同模型下特征目标检测精度对比 %
4 结束语
本文提出一种混合现实装配检测中深度学习的数据增强方法。通过图像增强、几何变换、少量噪声干扰和随机遮挡的方式以人为最佳策略生成增强数据集,有效增加了样本的多样性,解决了深度学习样本人工标注任务量大的问题。在图像增强模块,提出V-CLAHE图像增强方法,有效改善了经过图像增强后装配件的海绵铝角特征失真的情况。实验结果表明,该方法能有效扩充数据集,提高模型泛化能力。引入增强现实技术从多角度实时进行装配检测,增强数据集具有样本多样性和较佳的实验效果。该基于深度学习的混合现实装配检测方法与传统人工装配检测方法检测相比,检测精度更高、追溯性更强;与传统图像识别装配检测方法相比,检测时间更少。响应速度更快;与固定摄像头的装配检测方式相比,检测人员自由度更大、产线布局更精简。
目前实验主要对视频单帧和二维图像的进行检测,增强数据集为非任意视角的二维图像序列,后续研究拟增加任意视角样本,更全面地表达装配零件的完整视角信息,再引入数字孪生技术解决装配车间的生产要素的多元性问题,增加装配过程和结果的可预测性。
