考虑工位约束及能耗的双边拆卸线平衡问题建模与优化
2021-04-12谢梦柯张则强
谢梦柯,张则强,蒋 晋
(西南交通大学机械工程学院,四川 成都 610031)
0 引言
中国制造2025[1]是我国实施制造强国战略的第一个十年行动纲领,纲领中五大工程第四点——绿色制造工程明确指出国家应大力开展资源回收利用、再制造和低能耗等技术产业化示范。而我国制造业及其产品的能耗约占全国总能耗的2/3,可见高能耗必将成为制约我国制造业发展的重要因素[2]。因此,将能耗作为主要优化目标,对企业节能减排和降低成本具有重要意义。此外,现代化企业还应坚持可持续发展道路,加大对废旧产品进行回收利用的力度。然而,废旧产品数量庞大且大多需进行拆卸作业才能获得可回收零部件,为提高回收效率,回收过程常采用生产线方式进行。拆卸生产线常考虑工作站数、均衡指标、拆卸需求指标及拆卸危害指标等多方因素。自Gungor等[3]首次提出拆卸线平衡问题(Disassembly Line Balancing Problem,DLBP)以来,DLBP很快又被证明为NP-hard问题[4]。传统拆卸线多以单边和U 型为主[5],面对受特定作业方向约束的部件,传统拆卸方式会因频繁转换拆卸方向导致拆卸效率严重降低。而采用双边拆卸方式能有效减少拆卸方向的转换[6],降低生产成本,提高生产效率。
与单边拆卸线不同,双边拆卸线的工作站沿传送装置两侧布置,每两个平行工作站形成一个组合工作站(亦可用组合工作站包含两个平行工位进行描述),组合工作站左右两侧皆可分配拆卸任务[7]。当前双边拆卸研究采用传统单边或U 型拆卸线中的优先关系约束,未考虑实际拆卸过程中拆卸方向的变换会对任务分配造成影响。如文献[8]中,单一使用0,1变量表示任务间优先关系,当出现具有优先关系约束的任务分配至同一组合工作站不同侧、不同组合工作站不同侧和不同组合工作站同一侧3种情况时,上述优先关系约束则不能满足任务间的分配关系。因此,对于具有优先关系约束的任务,本文采用建立时间轴的方式,以考虑工位的优先关系约束代替传统优先关系约束。对于分配至同一工作站内的不同任务,现有双边研究中未明确指出其相对位置关系,如文献[9]中,任务间站内排序仅根据编码产生的拆卸序列依次排布而未给出具体的线性表达。针对这一问题,本文明确给出站内任务间相对位置约束表达式,即当前分配任务所在工作站内,先于该任务分配至此工作站的其他任务应满足其排序在当前分配任务之前。上述两种问题建模过程将在第1.4节数学模型中进行详细阐述。现有DLBP研究很少考虑实际拆卸过程中的能源消耗[10],且现有双边DLBP中还未对能耗进行深入研究。因此,本文针对该研究方向的不足,对拆卸过程主要能耗来源进行分析,并将能耗来源简化为拆卸任务所需能耗、组合工作站开启待机能耗及回收可利用产品所需能耗3方面。将能耗作为优化目标之一,以此节约拆卸能耗[11],降低拆卸成本,有效提高拆卸效率。
已有用于拆卸线平衡问题的常见算法有:线性规划[12]、H-K 算法[13]、变领域搜索[14]、强化学习[15]等。但上述算法均通过权重的方式将多目标问题转化为单目标问题进行求解,其本质依旧为求解单目标问题,因而存在难以均衡及协同优化多个子目标、目标间的量纲不同、互相干涉及权重的取值受主观因素影响等问题。而Pareto思想[16]筛选非劣解集时,不需量化各目标间的权重关系;在比较拆卸方案优劣的同时,会权衡拆卸方案中各个子目标的优劣,当各个子目标皆优化至较优情形时,才说明该拆卸方案较优。因而,研究学者将Pareto思想融入智能算法中提出了以下算法:混合遗传算法[17]、改进人工鱼群算法[18]、禁忌搜索算法[19]、遗传模拟退火[20]算法等。这类智能算法能够权衡各个子目标,求解出多个拆卸方案供决策者选择。为保证计算效率,结合NSGA-II拥挤距离机制[21]对Pareto非劣解集进行二次筛选,选择拥挤距离较大的较优解存入外部档案中,以提高求解质量。
差分进化(Differential Evolution,DE)算法是一种随机的启发式搜索算法[22],具有较强的鲁棒性和全局寻优能力,从数学角度看,它是一种随机搜索算法,从工程角度看则是一种自适应的迭代寻优过程。除具有较好的收敛性外,DE 算法还易于理解与执行,它只包含几个控制参数,且在整个迭代过程中数值保持不变。因此,将DE算法引入拆卸线平衡问题研究中,并结合Pareto思想及拥挤距离机制提出一种改进差分进化(Improved Differential Evolution,IDE)算法。
本文首先考虑工位优先关系约束及站内任务间位置约束,建立以最小化工作站数、工作站空闲指标、危害指标及能耗指标的多目标DLBP 数学模型;然后将IDE算法与经典案例和双边拆卸案列进行对比,验证其可行性与有效性;最后通过打印机拆卸实例计算分析,进一步将DLBP与实际相结合。
1 考虑能耗的DLBP数学模型
1.1 问题描述与假设
双边拆卸线沿传送装置左右两侧分别布置工作站,平行的两个工作站形成一个组合工作站。解码过程中,对于不同拆卸任务,只能分配至左侧工作站记拆卸方向为L,只能分配至右侧记拆卸方向为R,任意分配拆卸方向记为E。如图1所示,为8任务拆卸优先关系图,圈内数字表示拆卸任务编号,上方对应该任务的拆卸方向。以任务2为例,其紧前任务为1,紧后任务为6和8,拆卸方向为右侧。相比于传统单边或U 型拆卸线,双边布局在位置上有所改变,解码过程需要遵循两侧平行工位约束。分配拆卸任务时,应避免拆卸任务皆分配至组合工作站同一侧,而是将拆卸任务均匀分配至组合工作站的两侧,以此确保整个拆卸生产过程达到负载均衡能耗最低的效果。
综合考虑双边拆卸线特点,作做出如下假设:
(1)拆卸产品不断供应。
(2)拆卸产品均进行完全拆卸。
(3)不考虑待拆卸产品存在缺失或破损的情况。
(4)组合工作站左右两侧拆卸作业互不影响。
(5)工作站之间拆卸作业互不影响。
(6)所有拆卸任务皆有拆卸方向,对应于L,R,E。
(7)组合工作站成对开启。
(8)拆卸过程不受两侧工作站的位置干涉影响。
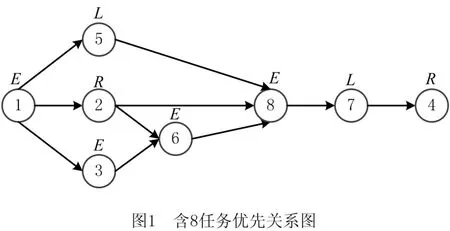
1.2 符号说明
i,j,s表示拆卸任务编号。
I表示拆卸任务集合,
M表示组合工作站数集合。
Wm表示第m对组合工作站开启,则Wm=1,否则Wm=0。
m,z表示组合工作站编号。
k表示组合工作站的边,k=1为左边,k=2为右边。
ximk表示任务i分配至第m个组合工作站的k边。
yismk表示若任务i,s皆分配至第m个组合工作站的k边,当任务i先于任务s分配至该工作站内时记yismk=1,否则yismk=0;当任务s先于任务i分配至该工作站内时记ysimk=1,否则ysimk=0。
BTimk表示分配在第m个组合工作站k边的任务i的起始作业时刻。
FTjmk表示分配在第m个组合工作站k边的任务j的截止作业时刻。
ti表示拆卸任务i所需时间;
CT表示节拍时间。
PL表示拆卸任务只能分配在左侧工作站的拆卸任务集。
PR表示拆卸任务只能分配在右侧工作站的拆卸任务集。
PE表示拆卸任务能分配在任意一侧工作站的拆卸任务集。
di表示对拆卸任务i的需求指标,若有需求,则di=1,否则di=0。
hi表示拆卸任务i的危害指标,若有危害,则hi=1,否则hi=0。
nL表示左侧拆卸任务集合。
nR表示右侧拆卸任务集合。
li表示拆卸任务i分配至左侧拆卸序列第l个。
ri表示拆卸任务i分配至右侧拆卸序列第r个。
ei表示拆卸任务i所需能耗,为已知量。
em表示第m个组合工作站开启时待机能耗,为已知量。
ed表示对需求零件进行回收所需能耗,为已知量。
Aij表示任务优先关系,若任务j是i的紧前拆卸任务,则Aij=1,否则Aij=0。
k(i)为任务位置属性,若为左侧作业则k(i)=1;若为右侧作业,则k(i)=2;否则为3。
1.3 能耗分析
选择任务i进行拆卸时,假设所需能源包含一切用于拆卸该任务的能耗。例如,对拆卸工具启动、照明、传输装置启动、人因等因素皆进行归一化处理,而不再单独考虑。设定单位时间拆卸任务i所需能耗值ei,因此拆卸任务i所需能耗如下:
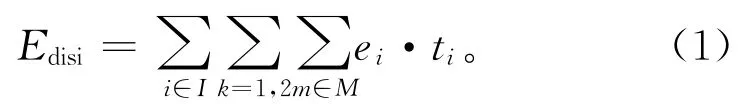
当前工作站未分配任务时,工作站处于待机状态。设定单位时间工作站待机能耗em,则工作站待机能耗如下:
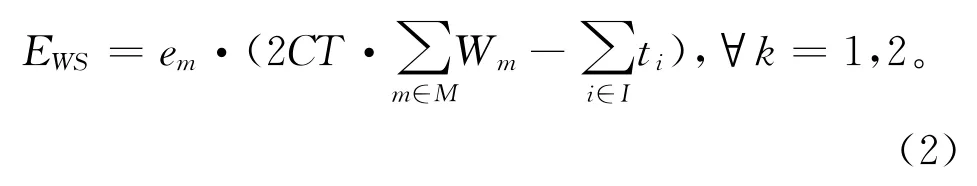
拆卸过程中对需求零件要进行二次处理才能回收利用,例如,零件的分类、搬运、清洗等皆需能量供给。将该回收过程统一考虑在拆卸过程中完成,所述能耗用ed进行简化处理。回收需求零件的能耗如下:
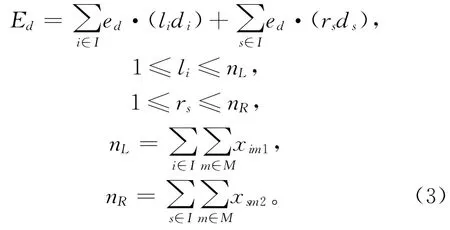
1.4 数学模型
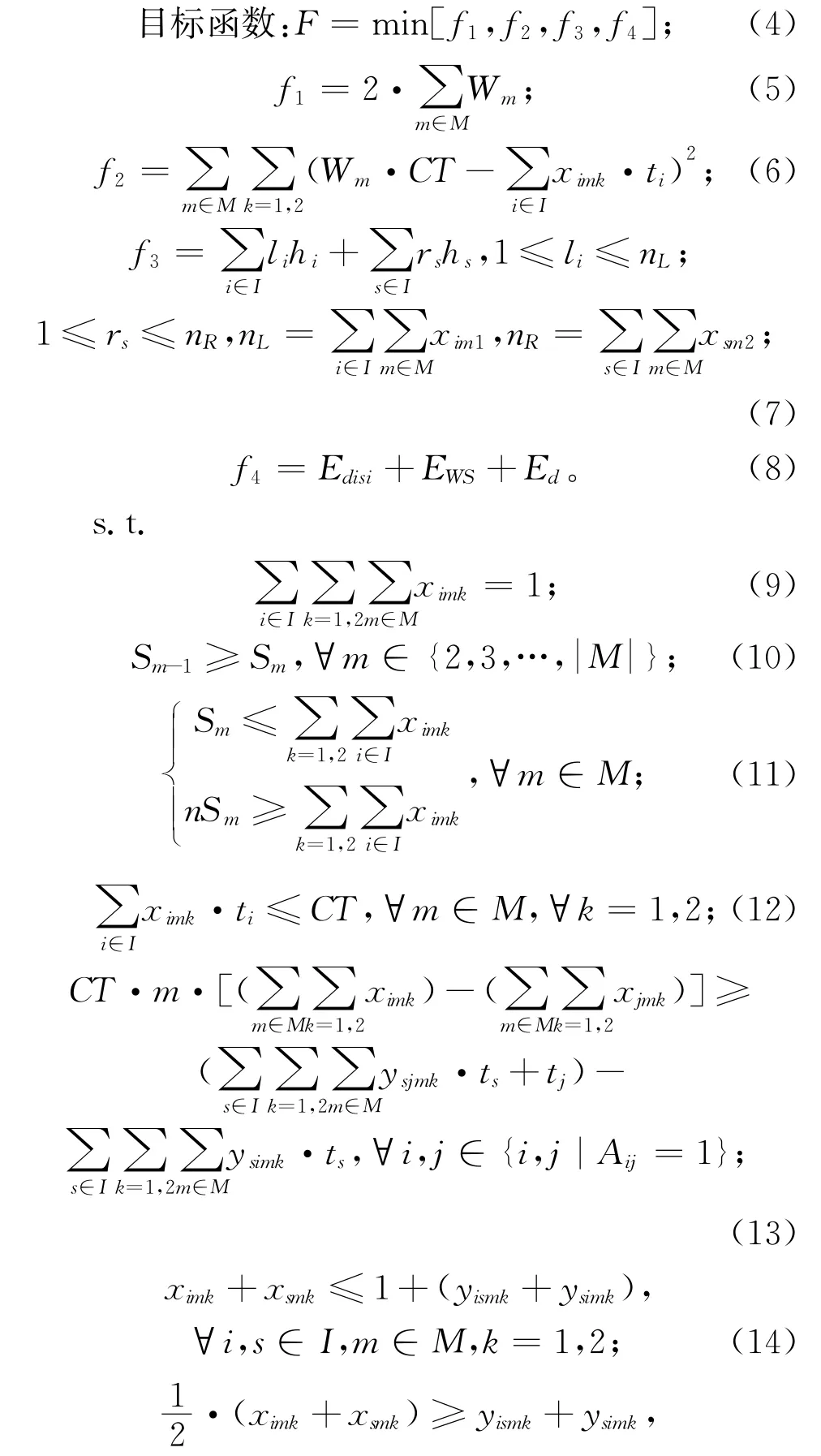
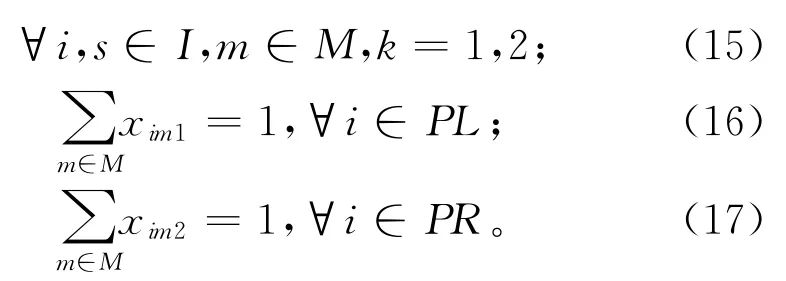
对于目标函数:式(4)为最小化目标F,包含4个子目标;式(5)为开启工作站数f1,以减少拆卸线作业长度,从而有效减少能耗,提高空间利用率以及拆卸效率;式(6)为空闲指标f2,减少工作站空闲待机时间,均匀分配拆卸任务使工作站负载均衡,减少拆卸资源浪费;式(7)为危害指标f3,待拆卸产品中会有对人以及环境造成污染的有害物质,因此需将危害零件集中尽早拆卸,以此降低拆卸危害;式(8)为能耗指标f4,拆卸作业所需的成本主要源于能耗,因此减少拆卸能耗能有效提升经济效益。
对于约束条件:式(9)为拆卸任务分配约束,鉴于所提拆卸类型属于完全拆卸,需将任一拆卸任务分配在指定工作站中进行拆卸作业;式(10)为开启工位约束,保证工位依次成对开启;式(11)为拆卸任务与开启工位约束,拆卸任务被分配至某工位时,该工位处于开启状态;式(12)为节拍约束,对于任一工作站内所有拆卸任务作业时间之和不大于节拍时间。
式(13)为优先关系约束,假设任务j是i的紧前任务,即Aij=1,且任务s先于i分配至第m个组合工作站k侧。建立如图2所示拆卸作业时间轴。确定任务i起始作业时刻BTimk,如式(18)所示。
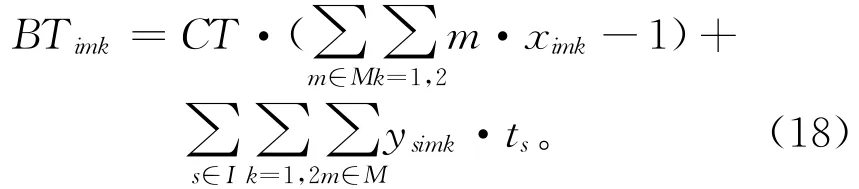
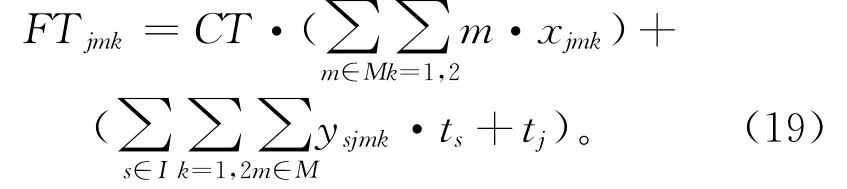
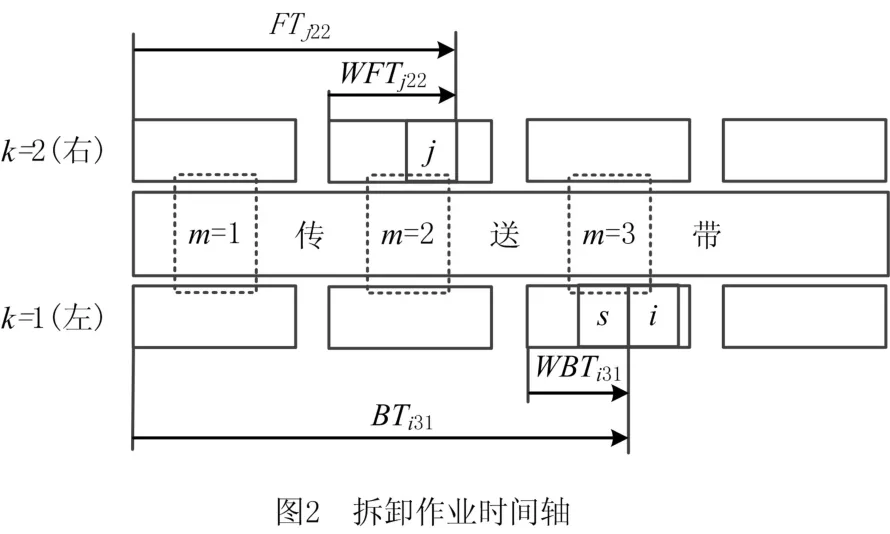
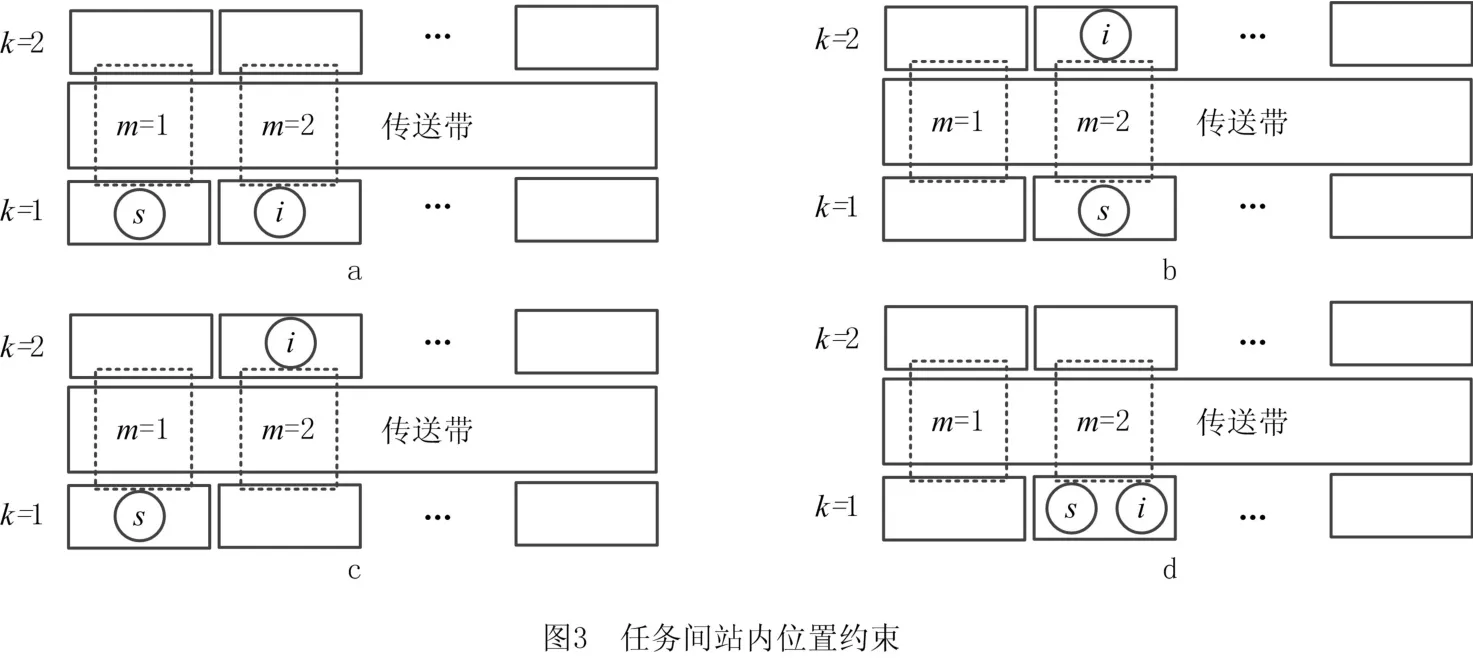
式(14)与式(15)为站内拆卸任务相对关系约束。假设任务s先于i分配至第m个组合工作站k侧。该约束限定任务i与任务s仅能分配至同一组合工作站的同侧。通过以下4种情况验证该约束的有效性。①当任务i与任务s分配至不同组合工作站同侧时,如图3a所示,例如:任务s分配至第一个组合工作站左侧,任务i分配至第二个组合工作站左侧,即xi21=0,xs11=1,yis21=0,ysi11=1,可见不满足上述约束;②当任务i与任务s分配至相同组合工作站不同侧时,如图3b所示,例如:任务s分配至第二个组合工作站左侧,任务i分配至第二个组合工作站右侧,即xi22=0,xs21=1,yis22=0,ysi21=1,可见不满足上述约束;③当任务i与任务s分配至不同组合工作站且不同侧时,如图3c所示,例如:任务s分配至第一个组合工作站左侧,任务i分配至第二个组合工作站右侧,即xi22=0,xs11=1,yis22=0,ysi11=1,可见不满足上述约束;④当任务i与任务s分配至同一组合工作站同侧时,如图3d所示,例如:任务s分配至第二个组合工作站左侧,任务i分配至第二个组合工作站左侧,即xi21=1,xs21=1,yis21=0,ysi21=1,满足上述约束。对比上述4种情形,仅第4种情形满足所提约束,因而验证了该约束能有效限定分配至同一工作站内任务间的位置关系。相比现有拆卸线平衡问题研究中以编码序列依次分配拆卸任务,所建约束更能明确地线性表达站内任务间相对位置关系。
式(16)与式(17)为拆卸任务分配约束,即只能在左侧进行拆卸作业的任务仅分配至左侧工作站;只能在右侧进行拆卸作业的任务仅分配至右侧工作站。
2 改进差分进化算法
2.1 改进差分进化算法
DE算法是一种基于自身种群差异的随机演化算法,常在连续空间进行优化计算,具有快速收敛的能力。要将DE 算法用于求解混合整数规划问题(Mixed Integer Programming,MIP),需对算法进行离散化改进处理。鉴于DE算法参数少,全局搜索能力强,结合差分随机策略DE/rand(如式(20)所示),差分进化策略DE/best(如式(21)所示),提出一种IDE算法。
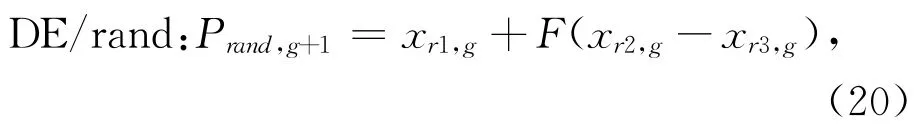
式中:F在[0,2]之间取值,为变异算子;g为进化代数;xr1,g、xr2,g和xr3,g对应于第g代种群中3个互不相同且不同于个体Pb,g的个体;(xr2,g-xr3,g)为偏差向量。
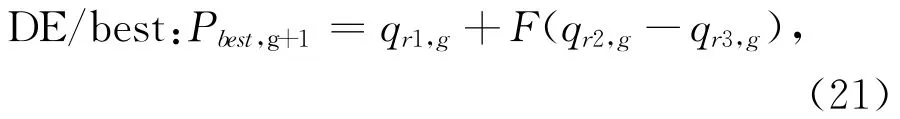
式中:F为变异算子,在[0,2]之间取值;g为进化代数;qr1,g、qr2,g和qr3,g对应于第g代种群中3个互不相同且不同于个体Pb,g的个体;(qr2,g-qr3,g)为偏差向量。
2.1.1 差分随机策略
为避免IDE算法因计算过程快速陷入早熟状态而无法做到全局搜索等问题,将差分随机策略加入算法寻优过程,以确保解的多样性,从而保证算法的分布性能。差分随机策略具体步骤如下:
步骤1采用式(20)获得第b个个体Pb,g发生第g+1次进化的变异向量Prand,g+1,其中,b∈{1,2,...,N-Nevol}。
步骤2选用偏差向量中元素与xr1,g进行变异操作得到新个体Prand,g+1(可能有多个)。
步骤3Prand,g+1与Pb,g分别进行交叉操作获得第g+1代的新个体Pb,g+1。
步骤4对第g 次进化得到的所有新个体Pb,g+1和Pb,g进行Pareto比较,将其中一个Pareto较优解替换Pb,g,即完成Pb,g的更新。
2.1.2 差分进化策略
为使所提算法具备快速寻优性能,将差分进化策略加入IDE算法中,保证算法能够快速收敛,以此提高算法运算效率。差分进化策略步骤如下:
步骤1采用式(21)获得第b个个体Pb,g发生第g+1次进化的变异向量Pbest,g+1,其中b∈{N+1-Nevol,N+2-Nevol,…,N}。
步骤2选用偏差向量中元素与qr1,g进行变异操作得到新个体Pbest,g+1(可能有多个)。
步骤3按式(22)获取第g+1代的新个体Pbest,g+1。
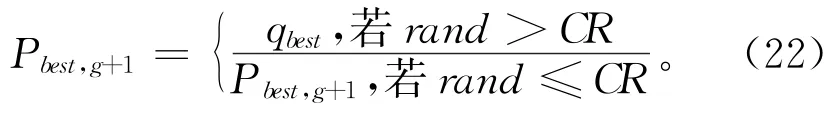
式中:rand表示在[0,1]之间产生一个随机数;CR为交叉算子,取值范围[0,1]。当rand>CR时,随机选择外部档案中个体qbest与Pb,g进行交叉操作获得第g+1代的新个体Pb,g+1;当rand≤CR时,将Pbest,g+1与Pb,g进行交叉操作获得第g+1代的新个体Pb,g+1。
步骤4对第g次进化所得的所有新个体Pb,g+1和Pb,g进行模拟退火处理,即进行Pareto比较,将其中一个Pareto较优解替换Pb,g,即完成Pb,g的更新。
2.1.3 变异交叉
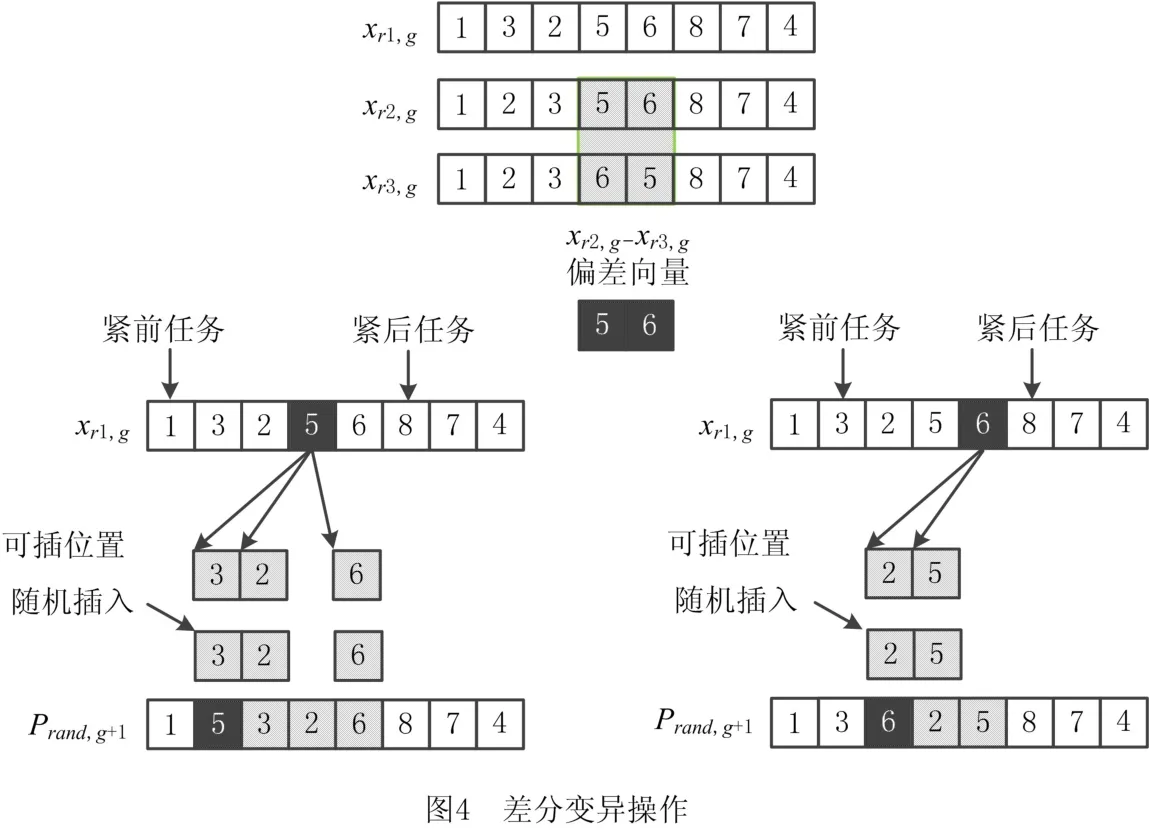
差分随机策略及差分进化策略所用变异及交叉操作,分别如图4和图5所示。以差分随机策略中拆卸任务数量为8个的待变异个体Pb,g=[1,2,5,3,6,8,7,4]为例:
(1)对于变异 获取第g代种群中3个互不相同且不同于个体Pb,g的个体:xr1,g=[1,3,2,5,6,8,7,4],xr2,g=[1,2,3,5,6,8,7,4],xr3,g=[1,2,3,6,5,8,7,4];得到偏差向量(xr2,g-xr3,g)=(5,6),对于偏差向量中的拆卸任务5,其在xr1,g中的紧前任务为拆卸任务1,紧后任务为拆卸任务8,因此在拆卸任务1和拆卸任务8之间随机插入到拆卸任务1之后,得到第一个变异向量Prand,g+1=[1,5,3,2,6,8,7,4]。同理,对于偏差向量中的拆卸任务6,可以得到第二个变异向量Prand,g+1=[1,3,6,2,5,8,7,4]。可见,变异向量的个数与偏差向量中拆卸任务的个数相同。
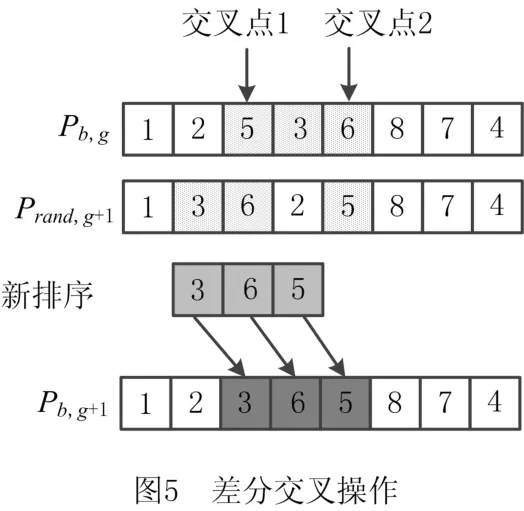
(2)对于交叉 假设Pb,g的随机交叉点在第三位置和第五位置,两个交叉点之间的拆卸任务为拆卸任务5、拆卸任务3和拆卸任务6,然后根据这3个拆卸任务在第一个变异向量中的排序来调整拆卸任务5、拆卸任务3和拆卸任务6在Pb,g中的排序,即可得到新个体Pb,g+1=[1,2,3,6,5,8,7,4]。
2.2 双边拆卸编码解码
2.2.1 编码
DLBP属于多目标离散问题,在编码过程中需要考虑优先关系约束,形成一个可行的拆卸序列。因此,借鉴一种染色体编码方式,染色体序号为拆卸任务编号,如图4和图5所示。在编码过程中引入由0和1组成的优先关系矩阵。任意选择无紧前任务的拆卸任务(对应优先关系矩阵中列元素全为0)进行分配。当前任务分配后,将该任务所在列的全部元素变为1,以此表示该任务已分配至工作站;将该任务所在行的全部元素变为0,以此表示解除该任务对其他未拆卸任务的紧前约束。
2.2.2 解码
双边拆卸不同于单边拆卸,需考虑拆卸任务的工位约束。拆卸序列上方用L,R,E分别代表该任务只能分配在组合工作站左侧工位,组合工作站右侧工位及不受工位约束。对于不受拆卸方向约束的任务,采用一种类启发式规则。建立左右两侧工作站拆卸任务的时间轴,在满足优先关系约束的前提下,将可任意分配拆卸方向的任务分配至左右两侧总截止时间较小的一侧。FTL表示组合工作站左侧第一个拆卸任务开始到当前最后一个拆卸任务结束的时刻;FTR为组合工作站右侧第一个拆卸任务开始到当前最后一个拆卸任务结束的时刻。对于任务i,BTimk为站内起始作业时刻;BTimk为总起始作业时刻;WFTimk为站内截止作业时刻;FTimk为总截止作业时刻。上述时刻在数学建模过程中已详细阐述,解码过程不再赘述。
具体解码步骤如下:
步骤1令i=1。
步骤2判断任务i的拆卸方位。若k(i)=1,∀i∈PL,将任务分配至组合工作站左侧;若k(i)=2,∀i∈PR,将任务分配至组合工作站右侧;若k(i)=3,∀i∈PE时,则判断FTL与FTR大小,根据下式重新赋值分配方向,即
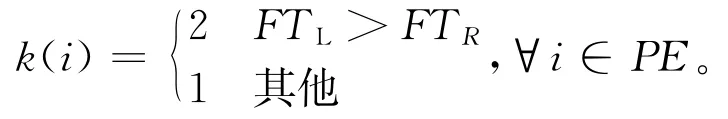
步骤3若当前任务i与紧前任务q在同一个组合工作站,则转步骤4,否则转至步骤5。
步骤4确定当前任务i分配时的站内起始作业时刻WBTimk,总起始作业时刻BTimk,站内截止作业时刻WFTimk与总截止作业时刻FTimk,转步骤6。
步骤5令该任务站内起始时刻WBTimk=0,BTimk为下一个工作站开始时刻,即BTimk=(m+1)CT,确定站内截止时刻WFTimk与总截止时刻FTimk,转步骤6。
步骤6确定当前工作站站内剩余时间RT=CT-WBTmk,若当前任务ti>RT,则开启新的工作站m=m+1,RT=CT;否则,更新站内RT,RT=CT-WFTimk。
步骤7继续下一任务分配(i=i+1),转步骤2,直至任务分配结束。
2.3 算法更新机制
2.3.1 种群更新
算法的全局搜索能力和收敛速度均受种群更新策略影响。为使更新后的种群在收敛性和分布性方面皆优于初始种群,本文运用模拟退火思想对种群中每一个体进行逐步更新,即所用IDE算法每迭代一次后可形成新一代种群(规模与初始种群一致),该新种群内的个体性能皆优于初始种群中对应位置的个体。此外,本文设置独立于初始种群之外的外部档案集来保存较好的非劣解,且运用精英策略将外部档案中的非劣解随机插入下一代初始种群中,以提高下一代初始种群的质量,从而加速算法寻优过程。
2.3.2 外部档案更新机制
本文所提IDE算法求解大规模算例时所产生偏差向量的维度较大,因而变异交叉后得到的较优个体也较多,若将这类非劣解放入外部档案中,将使其规模急剧增大,算法运算效率大幅度降低。因此,结合Pareto思想对新得到的非劣解进行一次筛选,再与外部档案结合进行第二次筛选,从而提升算法运算性能,提高其求解效率。Pareto思想具体解释为:假设两个拆卸序列A,B对应的适应度函数值分别为AFj,BFj,有j个子目标j∈{1,2,3,…,n}。若AFj,BFj满足式(23),则称A支配B,B为支配解,A为非支配解,即较优解,所有非支配解形成的解集为Pareto解集。但Pareto解个数无法预测且数量较多,为保证算法运算效率,需对外部档案规模进行限定。
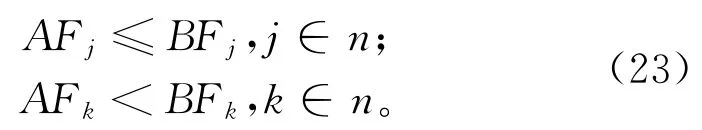
现有对外部档案进行更新的较好方法包括:聚类法、自适应网格法、ε分配法和偏好排序法。但上述方法存在计算效率低、后退和收缩等问题。而文献[23]经试验得出运用NSGA-II拥挤距离机制所得结果更好,因拥挤距离机制不需要将新的方案与外部档案中方案进行比较,仅根据各个方案的子目标进行计算筛选。NSGA-II拥挤距离机制解释为:假设处于边缘的第j个子目标的拥挤距离=∞,其中E为外部种群规模。非边缘的第i个非劣解的第j个子目标的拥挤距离如式(24)。
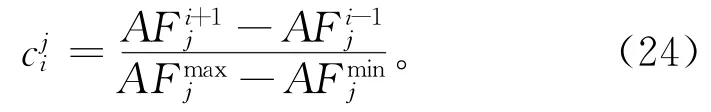
式中,第i个非劣解的拥挤距离计算式为Ci=分别表示第j个子目标的最大值和最小值。对子目标AFj,j∈{1,2,3,…,n}按照升序方式排列,选取拥挤距离较大的解放入外部档案。
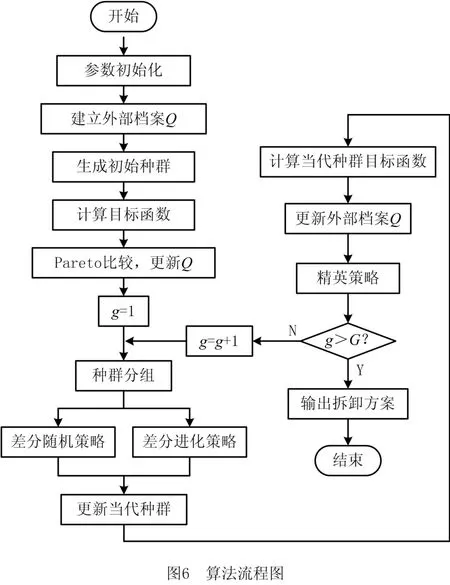
2.4 算法总流程图
本文所提IDE算法将差分随机策略和差分进化策略融入DE算法,保证算法的全局搜索能力和快速收敛性能。结合Pareto思想和NSGA-II拥挤距离机制对当代种群及外部档案进行更新,保留解的多样性与优越性。采用精英策略将较好解拆入下一代初始种群,以此提高下一代初始种群质量。综上所述,给出算法流程(如图6)。算法主要步骤如下:
步骤1算法参数初始化。种群数量N,最大循环次数G,分组率Pam,外部档案规模Q。
步骤2生成初始种群,通过Pareto比较初始种群的目标函数值并将Pareto较优解输出至外部档案中。
步骤3初始化迭代次数g=1。
步骤4将种群分为数量为N1的第一种群和数量为N2的第二种群。
步骤5对第一种群进行差分随机策略的更新。
步骤6对第二种群进行差分进化策略的更新。
步骤7运用Pareto思想对更新后的当代种群进行筛选。
步骤8结合Pareto思想和NSGA-II拥挤距离机制对外部档案进行更新。
步骤9将外部档案中的解随机插入到下一代初始种群中。
步骤10若g>G,则输出外部档案中的Pareto较优解为拆卸任务分配方案;否则,令g=g+1并转步骤3。
3 算例验证及实例应用
3.1 算例验证
为验证所提IDE算法的可行性与高效性,引用单边拆卸线经典案例以及最新发表文献中双边实例的求解结果与之对比。为保证算法的公正性,对比所用结果皆引用于已发表文献。
对于一个算法,其核心体现在结构优越性上,且考虑拆卸线平衡问题的特殊性,即双边拆卸与单边拆卸的区别仅在于解码方式不同,而算法结构并未发生改变。因此,将所提算法在结构不变的前提下与经典单边拆卸案例进行对比,以此验证本文所提算法的高效性。此外,引用双边拆卸实例与所提算法进行对比验证,不仅充实了对比的可信度,还弥补了现有双边拆卸研究中仅与传统单边案例进行对比验证的不足。
测试实验所采用的计算机配置为Pentium(R)Dual-Core CPU E6700@3.20 GHz 4 G,在Win7系统下MATLAB R2014b运行。
3.1.1 小规模算例验证
应用文献[24]中给出的10拆卸任务小规模案例。已有文献所用的算法包括:蚁群优化(Ant Colony Optimization,ACO)算法[25]、人工蜂群(Artificial Bee Colony,ABC)算法[24]、启发式算法(Heuristic)[26]、禁忌搜索(Tabu Search,TS)[19]。求解目标包括:工作站指标(F1),需求指标(F2),空闲指标(F3),危害指标(F4)。上述算法对应求解结果如表1所示。
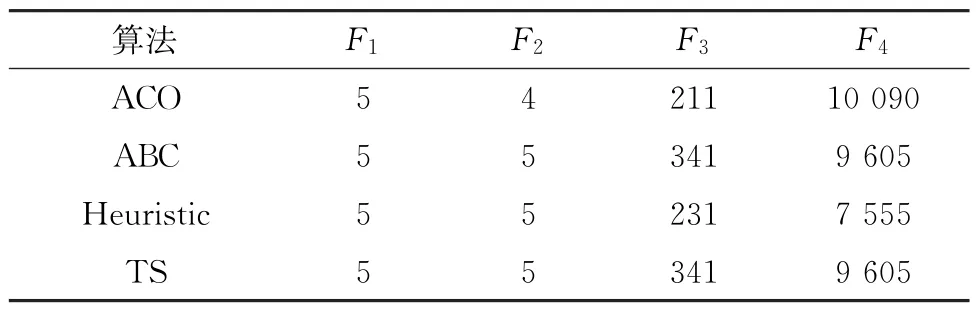
表1 已有算法对P10问题的求解结果
对于P10问题,建立四水平三因素正交实验表,通过正交计算,设置参数如下:种群规模N=100,最大循环次数G=80,分组率Pam=0.5。算法独立运行10次,取其中一次求解结果如表2所示。通过对比可见,ACO、ABC、Heuristic、TS算法独立运行一次仅能获得一组拆卸方案。而所提IDE算法能求解到P10问题的7个高质量解,且每一个求解方案均不劣于上述求解结果。此外,纵向对比各个子目标最小值,可见表2中F2与F4最小值皆优于表1求得的最小值。因此,验证了IDE算法运用于小规模算例的可行性与高效性。
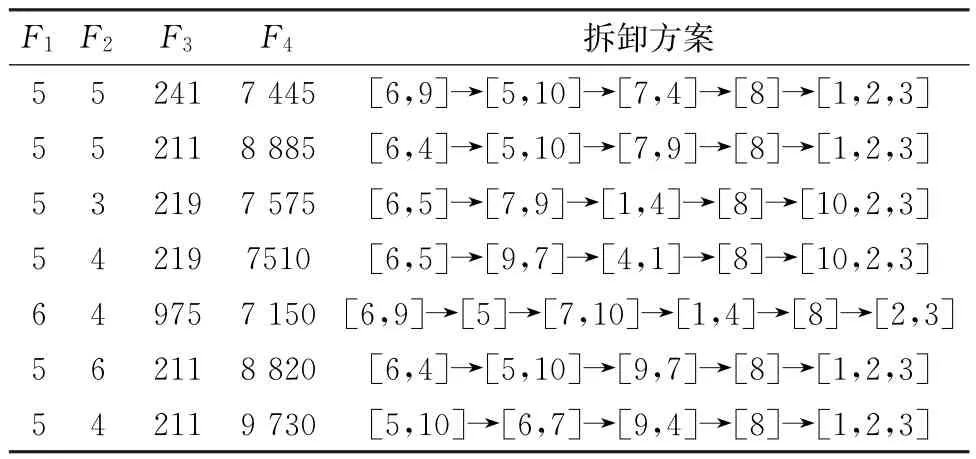
表2 IDE算法对P10问题求解结果
3.1.2 中规模算例验证
应用文献[15]给出的25拆卸任务中规模拆卸案例。已有文献所用算法包括:变领域搜索(Variable Neighborhood Search,VNS)[14]、强化学习(Reinforcement Learning,RL)[15]、粒子群优化(Particle Swarm Optimization,PSO)算法[27]、遗传算法(Genetic Algorithm,GA)[28]、模拟退火算法(Simulated Annealing,SA)[29]、遗传模拟退火(Genetic Algorithm Simulated Annealing,GASA)算法[20]等。上述算法对应求解结果如表3所示。
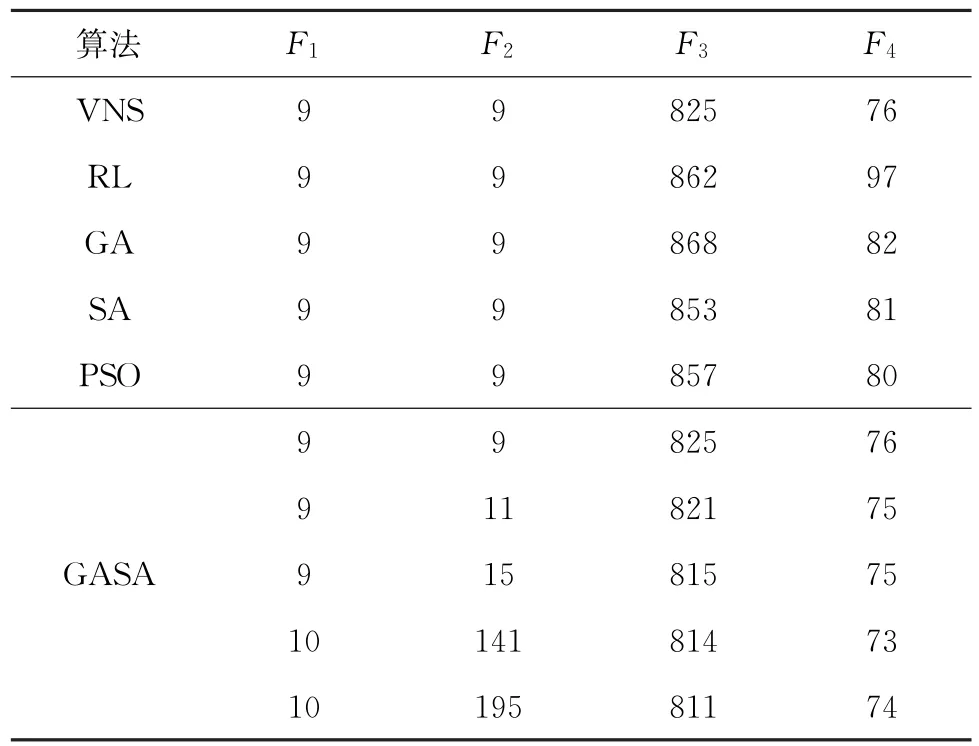
表3 已有算法对P25问题求解结果
与小规模案例一致,对于P25问题,通过正交计算,设定参数如下:种群规模N=200,最大循环次数G=100,分组率Pam=0.4,外部最优种群Q=10。算法独立运行10次,取其中一次求解结果如表4。可见,所提IDE算法所求方案中,空闲指标F3的最小值为802,危害指标F4最小值为70,皆优于上述算法相应目标的最小值,且所得到的解数量更多,效果较优,从而证明了所提算法运用在中规模案例时的可行性与高效性。

表4 IDE对P25问题求解结果
3.1.3 大规模算例验证
应用文献[30]中的52拆卸任务大规模案例。与中小规模案例不同,该案例将闲置率FIdel、负载均衡指标FSmooth以及拆卸成本FCost作为目标函数求解。已有文献求解该算例采用的算法包括:多目标细菌觅食优化(Multi-Objective Bacteria Foraging Optimization,MBFO)算法[31]、人工鱼群算法(Artificial Fish Swarm Algorithm,AFSA)[32]、ACO算法[16]、GASA 算法[33]、蚁群遗传优化算法(Ant Colony and Genetic Algorithm,ACGA)[34]。对于P52问题,通过正交计算,设定参数如下:种群规模N=200,最大循环次数G=200,分组率Pam=0.4,外部最优种群Q=10。为保证算法公正性,使算法独立运行10次,选择其中较好一次求解结果,如表5所示。将求解结果与上述五种算法所求结果进行对比,鉴于各个算法对闲置率的求解结果皆为0.057 9,因此建立二维直角坐标系,对比负载均衡指标及拆卸成本等两个目标函数,如图7所示。

表5 IDE对P52问题求解结果
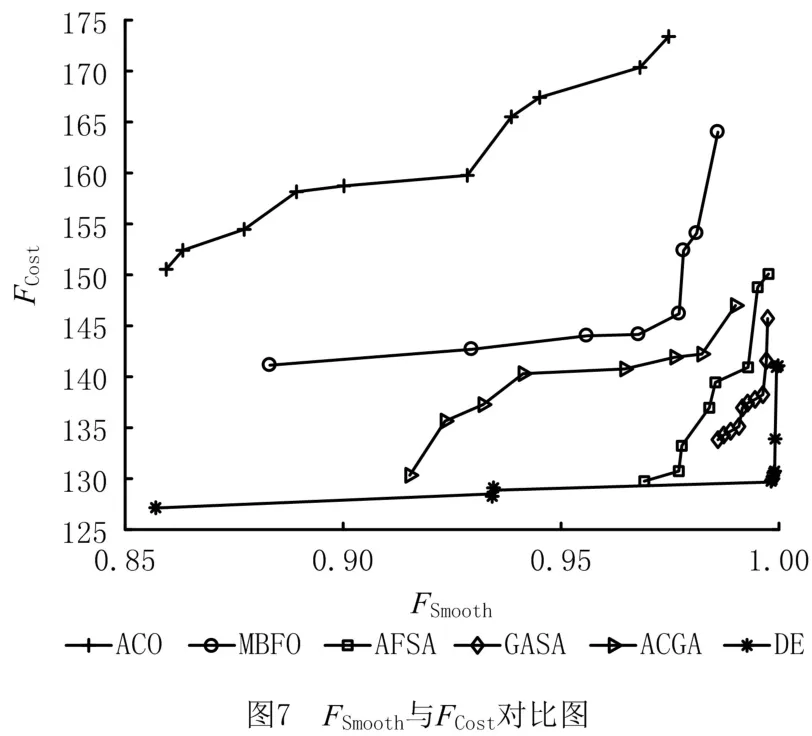
由表3~表5可见,所提算法求解方案中,负载均衡指标FSmooth最大值为0.999 8,拆卸成本FCost最小值为127,所求目标函数值皆优于以往算法求解的极值。除了上述目标函数值的优越性,结合图7可见,所提IDE算法求解结果能有效包裹上述5种算法的结果,且平滑率更高,成本指标更低,验证了该算法运用在大规模案例求解时的可行性与有效性。
3.1.4 双边实例验证
应用最新发表的文献[35]中电冰箱拆卸实例,该案例优化目标分别为:工作站指标(F1)、需求指标(F2)、空闲指标(F3)、危害指标(F4)。求解结果如表6所示,可见该文献中所用蝙蝠算法(Bat Algorithm,BA)求得工作站数目为6~9,空闲指标在5 907~51 679之间。本文所提IDE算法对该案例求解时,设定参数如下:种群规模N=200,最大循环次数G=200,分组率Pam=0.3,设置外部档案为Q=8。算法独立运行10次,取其中较好一次如表6所示,求得工作站数目在5~9之间,空闲指标最小值为765。当工作站数量为5 时,可见所提IDE算法求得的工作站数与空闲指标大幅度优于BA算法。当两种求解结果中工作站数目皆为9时,对比F2、F3和F4可见,IDE算法求得的最后两组解的目标函数值完全占优于BA算法的倒数第二组解的目标函数值。综上可见,本文所用IDE算法在求解性能上优于BA算法。
3.2 实例应用
为使研究更具实用性,引用文献[18]中某打印机完全拆卸实例。该实例中具体信息为本课题组实地调研所得,即该打印机由55个拆卸单元组成,每项拆卸任务作业时间(单位:s)取决于多次测试拆卸该任务实际作业时间的平均值。需求数量(单位:个)根据市场考察统计得出。任务的拆卸方向取决于实际工厂中分配的拆卸方向(1表示左侧拆卸、2表示右侧拆卸,3表示左右均可进行拆卸)。最终统计拆卸任务相关信息如表7,任务间优先关系如图8所示。
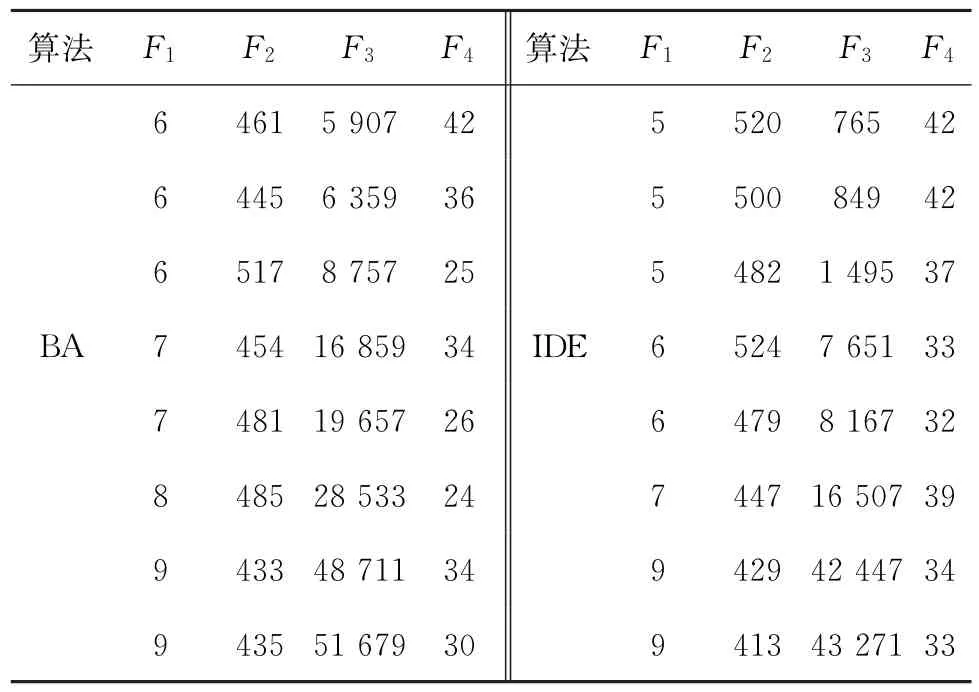
表6 BA和IDE求解结果
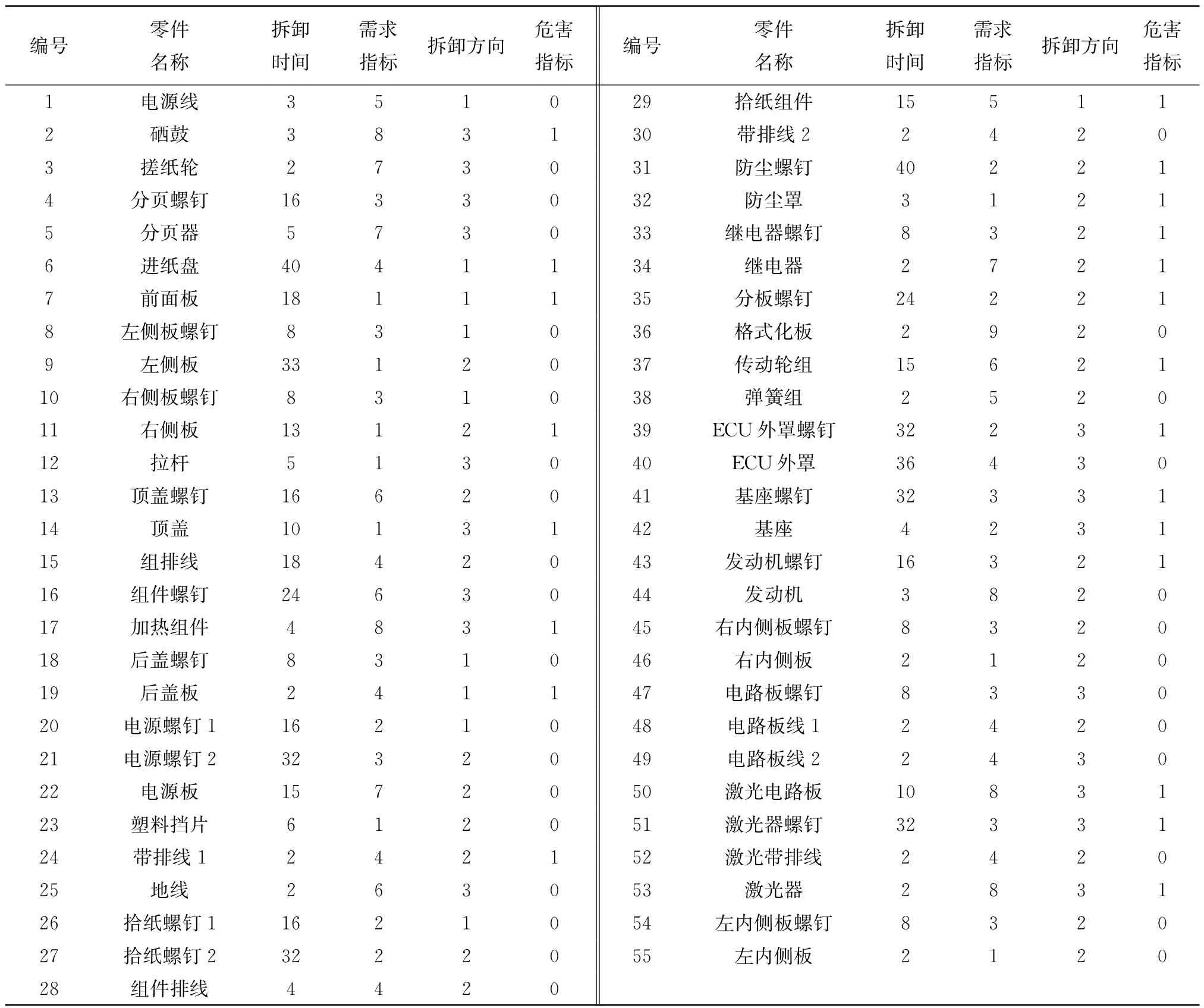
表7 打印机拆卸信息表
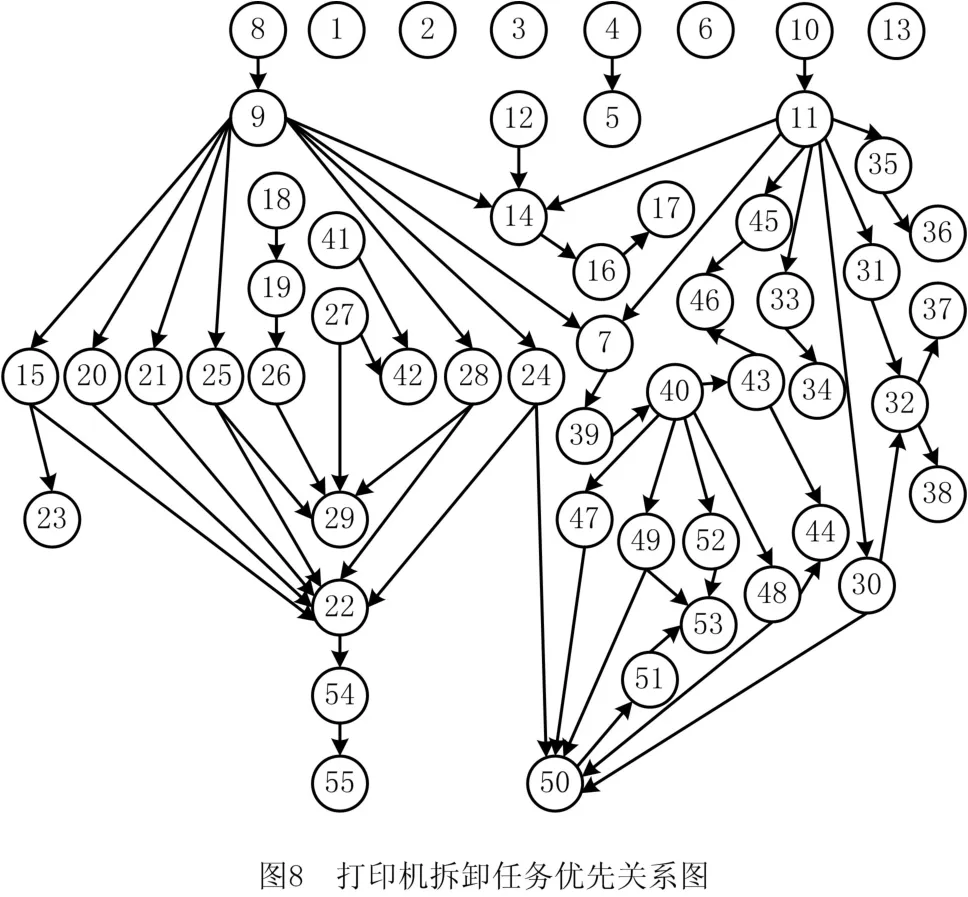
根据该算例特性,通过正交计算,设定算法参数如下:种群规模N=250,最大循环次数G=200,分组率Pam=0.4,外部最优种群Q=14。为保证求解结果的稳定性,使算法运行10次,取较稳定一次结果如表8所示。
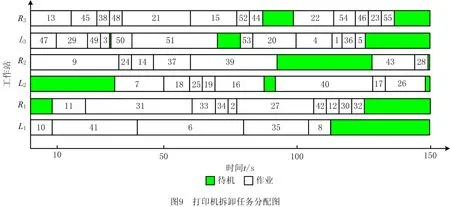
由表8可见,所提IDE算法求得的14组方案中,最小工作站数均为6,最小化空闲指标为8 441,最小化危害指标为185,最小化能耗指标为795。若是着重考虑能耗指标,可选择能耗较少的拆卸方案1,其工位分布如图9所示。若综合考虑负载均衡指标,危害指标与能耗,可选择方案3,4,8。
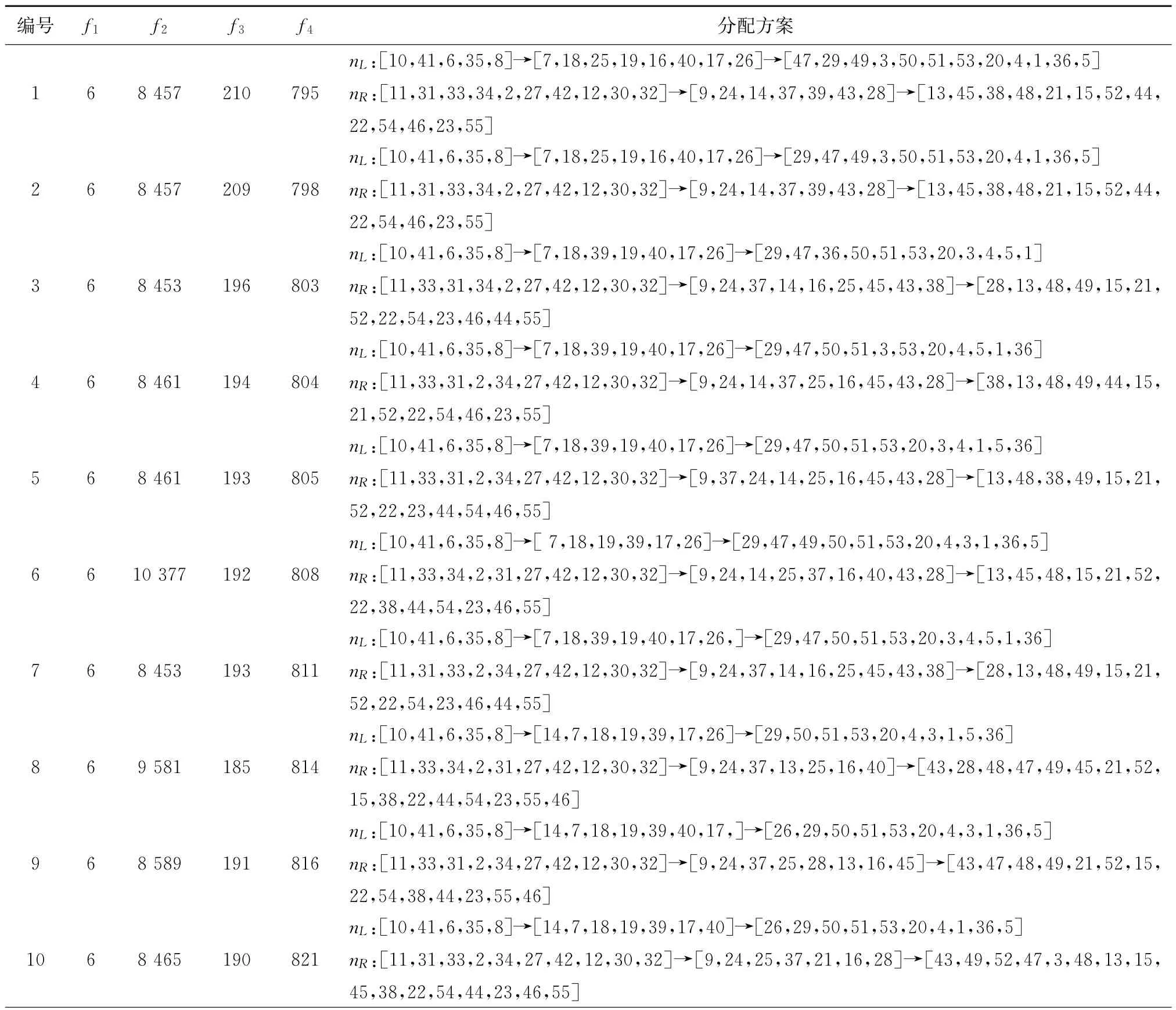
表8 IDE对打印机拆卸求解结果

续表8
4 结束语
本文针对现有双边拆卸线还未深入研究能耗问题的不足,建立了考虑能耗及工位约束的双边拆卸线数学模型,提出一种改进的IDE算法求解以最小化工作站数、负载均衡指标、危害指标和能耗指标为优化目标的多目标拆卸线平衡问题。
本文首次采用时间轴的方式线性化表达任务间的优先关系约束及站内位置约束,弥补了以往拆卸线模型不能精确求解的不足。对所建模型进行详细阐述,分析了拆卸生产过程中主要能耗来源。针对所提能耗问题,在双边拆卸解码过程中加入对应启发式分配规则,以保证求解结果的稳定性与高效性。
将差分随机策略及差分进化策略融入差分进化算法,以此保证算法的全局搜索能力和快速收敛性能。结合Pareto思想及拥挤距离机制,保留解的多样性与优越性。运用所提算法分别求解P10、P25和P52 3个经典案例,并与相关智能算法进行对比,验证所提算法的有效性。为使算法对比更为全面,对比了电冰箱双边拆卸实例,以此确保算法的可行性。最后通过打印机拆卸实例计算,求解出14种高质量方案,决策者可根据自身需求进行选择。
本文对空间干涉问题做了相关假设,所用实例为种类单一的简单产品。因此,考虑双边位置干涉因素,对比多种类及复杂拆卸案例的混流双边拆卸线平衡问题值得进一步探索。
