基于优化的随机森林心脏病预测算法
2021-04-10赵金超张俊虎
赵金超,李 仪,王 冬,张俊虎
(青岛科技大学 信息科学技术学院,山东 青岛266061)
目前医学领域正面临由传统医学模式向精准医学模式转变的契机,给人工智能技术充分参与医疗实践活动创造了有利的环境[1-2]。国内外研究人员,依靠不同的算法,通过对心脏病进行分类从而实现帮助医生进行辅助诊断,正在进行大量的研究工作。COMAK等[3]在2007年通过支持向量机建立了对心脏病识别的系统。PARTHIBAN等[4]在2011年应用朴素贝叶斯算法在心脏病治疗上。史琦等[5-7]连续3 a分别使用数据挖掘、决策树、模式识别对心脏病进行了分类预测研究,史瑜等[8]在2015年用K近邻算法对心脏病进行分类,得到了75%的准确率。医生在诊断患者时,主要根据病人的一系列的医学检查结果,自己学习的医疗知识和以往的经验,对病人是否患有该疾病进行判断。然而在医生做出判断时,会由于人为不可抗原因,可能会产生错误判断。而目前流行的通过医疗与机器学习算法相结合的方法,能够帮助医生有效减少误诊率,提高诊疗准确率和效率,对医疗事业的发展有着推动作用。在机器学习算法中,随机森林就是一种易理解,易应用的集成学习的方法,本研究基于随机森林算法建立一种KNN-RF模型,对心脏病进行辅助诊断,通过对算法进行优化和与其他机器学习算法对比,获得较高准确率。
1 算法原理
随机森林的基本组成单元是决策树,对用与分类与回归问题的研究,它是许多各自独立同分布的决策树结合而成的,组成随机森林的每一棵决策树都会对输入数据进行分类处理,处理完成后,对每棵树的决策结果进行投票处理,票数高的即为输出结果。与决策树相比,随机森林有更良好的分类效果和更加优秀的泛化能力,实质上就是对决策树的一种改进算法。
1.1 决策树
决策树是一种基础结构形似一棵树的监督学习算法,其每个节点代表一个字段,最早由HUNT等提出,反映输入的属性与输出值的一一对应关系。决策树由三部分构成:决策点、状态节点、结果节点。对每一个新输入的数据,根据模型进行自上而下的节点分配,每一个内部节点只有一个父节点和两个或多个子节点,根据所规定的规则划分数据集,直到最下层,最终将叶子结点的分类作为该输入数据的类别。决策树中,每个节点表示一个对象,决策点是最终选择的方案,若为多级决策问题,则可以存在多个决策点。决策树的模型构建分类两部分:特征选择和生成树。
决策树的分类好坏取决于其属性的选择,在不断划分的或域中,使节点“纯度”越来越高。决策树使用无需先验知识,可以同时处理连续与离散数据,更容易学习和理解,复杂度低效率高。但是会容易出现过拟合现象,存在局限性[9]。
1.2 随机森林
为了解决单棵决策树存在的不足并提高模型精度,文中采取随机森林(random forest)算法。该算法主要用于分类与回归,在20世纪90年代由BREIMAN[10]提出,在生物处理,人脸识别等方面应用广泛。随机森林利用集成学习思维为基础,构造多个决策树合成,其中的每一棵决策树之间是独立的。当输入新样本时,随机森林中的每一棵树都会判断该样本的分类结果,最后综合判断结果进行投票判决,票数多的一类即为预测的最终结果,公式如下:。该算法能够有效解决决策树准确性较低或过拟合的问题,有效的提升了算法模型的泛化能力,实现简单。大致流程见图1。
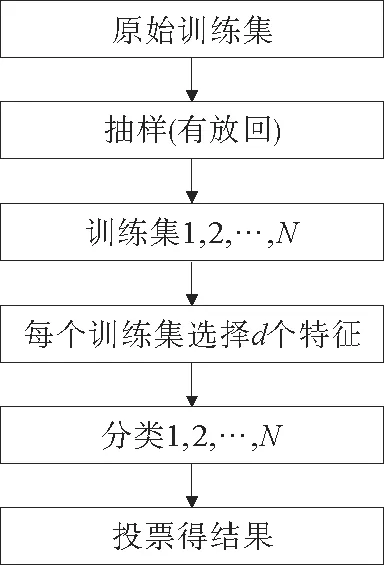
图1 随机森林算法流程Fig.1 Flow of random forest algorithm
步骤:
1)假设原始训练集有N个样本,随机有放回的抽样组成训练集。
2)设d<D,从样本的D个特征中,随机抽取d个特征。
3)用抽取的特征进行构造随机森林模型。
4)输入数据,每棵树得到各自的结果,将结果进行投票,选择票数多的为最终结果。
随机森林中的每一棵树都是按照由顶而下的原则,从根节点开始划分而成。在该树中,根节点包含所有的数据,直到分裂至满足停止条件才会停止分类。该算法将单个分类器进行加权组合,构建性能较好的分类器,任意两棵树关联性越小,该模型错误率越低。
随机森林在实验中性能较好,有较强的抗噪声性能,但在处理非平衡的数据上,存在缺陷,由于本研究数据标签分布均衡,故本数据集适用于随机森林算法。
1.3 网格搜索算法
网格搜索(grid search CV),又被称为穷举搜索,是在机器学习中非常常用的一种调参方法。其包括两部分:网格搜索,交叉验证。一般就是根据实验需要指定一项需要调整的参数,在指定的范围内,通过遍历选定参数,选择能够让模型得到最优结果的那个参数作为最终结果。
为了提高模型的精确度,本研究对随机森林中的两个参数:树的数量即n_estimators、树的高度即max_depth和最大叶子节点数即max_leaf_nodes作为需要搜索的超参数,选择最佳的参数。该方法可避免产生严重的误差,得到较优的解。但是该方法的缺点是会消耗比较多的时间。
2 数据预处理
从数据库收集的数据,存在良莠不齐的特点,可能会存在缺失值和异常值,因此需要先对数据进行处理,得到符合实验规定的数据,再进行模型建立。
2.1 数据说明
本研究选取UCI上的心脏病数据集,该数据集有13个属性,303条数据,其中第14位为分类项,target代表是否患病。此外,本研究还使用了来自克利夫兰医学中心的270条数据,同样有13个属性,是开源数据集。属性名称分别见表1。

表1 数据集属性Table 1 Data set properties
2.2 处理过程
机器学习常用的数据库,超过40%都含有缺失数据[11]。在原始数据集中,可能会存在大量“脏数据”,这些“脏数据”的使用,会导致模型的分类效果变差,准确率变低,有价值信息被忽略等情况,因此,在进行相关的研究之前,需要对数据进行预处理。本研究数据处理包括:缺失值处理,one-hot编码,归一化数据。
2.2.1 缺失值处理
缺失值处理常用的办法有2种:删除法和插补法。删除法,主要用于删除有缺失的数据,适用于数据量大的情况。由于本研究数据集较小,使用的是第2种方法,插补法。对于填补方法,通常,数值型用中位数进行数据填充,离散型用众数进行填充,但是这样做会增加噪声,会使数据的使用结果产生一定的偏差,只适用于缺失数据特别少时可用。由于K近邻算法具有简单、直观的优点,在将其与中位数填充、均值填充、众数填充、不进行处理等4项操作进行对比后,选择效果最好的K近邻填补法对数据进行填充完善。
首先将数据初始化,构建成数据矩阵;其次,对矩阵中的数据进行欧式距离计算,其公式如下:D=,并从中选择欧氏距离最小的K个数据;最后,计算所选数据的权值,并对数据进行填充。该算法具体流程图2所示。
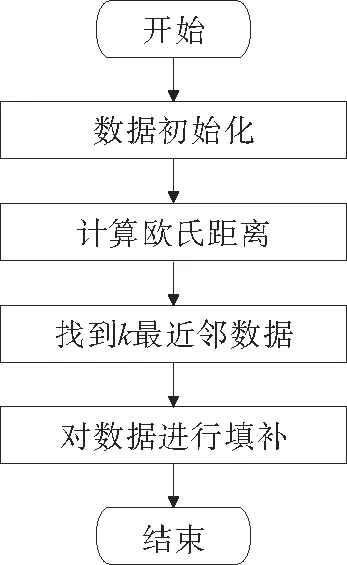
图2 数据填补流程Fig.2 Data filling process
以上所述的方法,只能处理离散值属性,如果遇上连续型属性,就要把连续型属性离散化,再按照上述步骤进行数据处理既可。
2.2.2 one-hot编码
one-hot编码为机器学习技术常用数据预处理方法。其主要思想是把一个词语转化成为一些数字化特征,也可以看作将其映射到一个新的空间并用多维的实数向量进行表示,而这个向量就称之为词向量[12]。
one-hot编码就是把词向量的非连续性数值进行转换,是分类变量的二进制表示形式。使用该编码,将离散特征的取值映射到欧式空间,离散特征的某个取值就对应欧式空间的某个点。
在处理后,该值只有一个维度为1其余维度为0。由于本研究数据集中CP、Slope、Thal 3个特征属性是离散特征,采用one-hot方法对3个特征属性进行数字标号处理,离散数据特征进行one-hot编码后,每一维度的特征都可以被看作是连续的特征。可以对其进行归一化处理。CP、Slope、Thal 3个变量进行one-hot编码后,数据集由原来14个特征变为22个特征。
2.2.3 数据归一化
数据归一化是将数据按照一定比例,将其缩小到特定阈值内,而对于不同数据,存在不同的量纲,计算起来较为复杂,需要对数据采取归一化处理。本研究采用Min-Max方法,将数据变成0~1之间的数,其计算公式如式(1)所示。由于心脏病数据集中各属性的取值不都在0~1之间,需要对其进行归一化处理,来提高分类算法准确度。归一化后部分数据见表2。

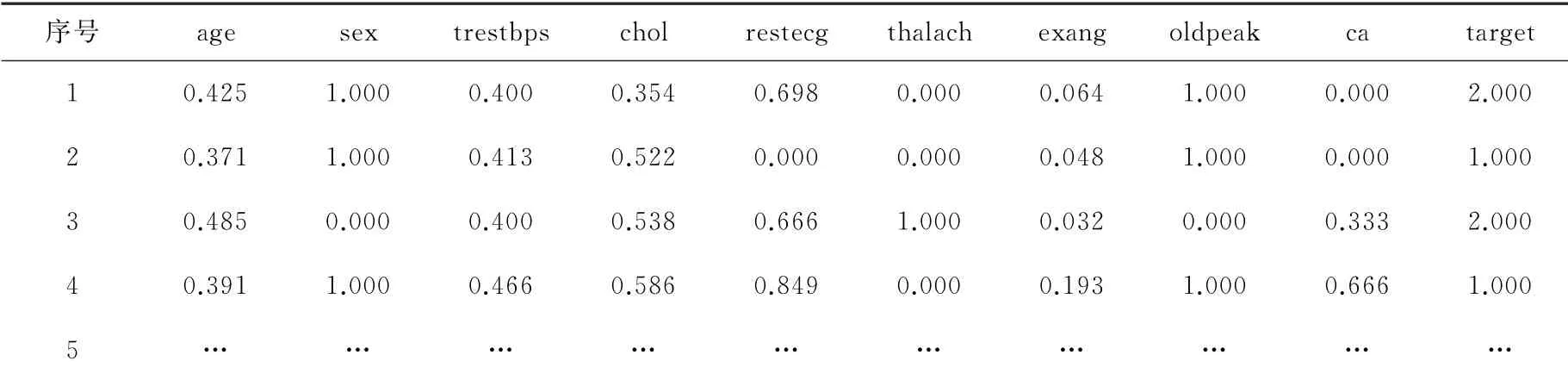
表2 归一化后部分数据显示Table 2 Normalized partial data display
2.2.4 连续值离散化
经典决策树算法比较适用于离散型属性数据,对于连续数值型属性问题,它生成的决策树较为庞大,一般选择取值区间二分离散化对其进行处理。其具体步骤如下:1)给定一个训练集D和连续属性a,初始化区间,通过离散化连续型属性,基于划分点t将样本进行划分为和为取值小于等于t的样本,为取值大于t的样本);2)对属性a,把区间的中点作为划分点,就可以对其进行处理;3)分别计算信息增益并比较大小,Gain(D,a)=(D,a,t),信息增益比较最大的,即为最佳分裂点,由该点将概率属性值划分。
3 算法优化与设计
3.1 特征分析
数据集特征之间可以进行分析,利用特征之间的关系可以更好地理解数据集数据之间的关系。在统计学领域,特征之间的关系称为相关[13]。可以用热力图观察各个特征之间的相关性,每一个颜色块代表横坐标和纵坐标特征的相关程度,右侧为划分的相关系数。颜色越深说明两个特征之间的关联性越小,相关系数越小。相关系数为0时表明两个特征之间是独立的。反之,说明特征之间是冗余的。通过图3可得,该数据集特征之间相关程度较弱,数据没有冗余。
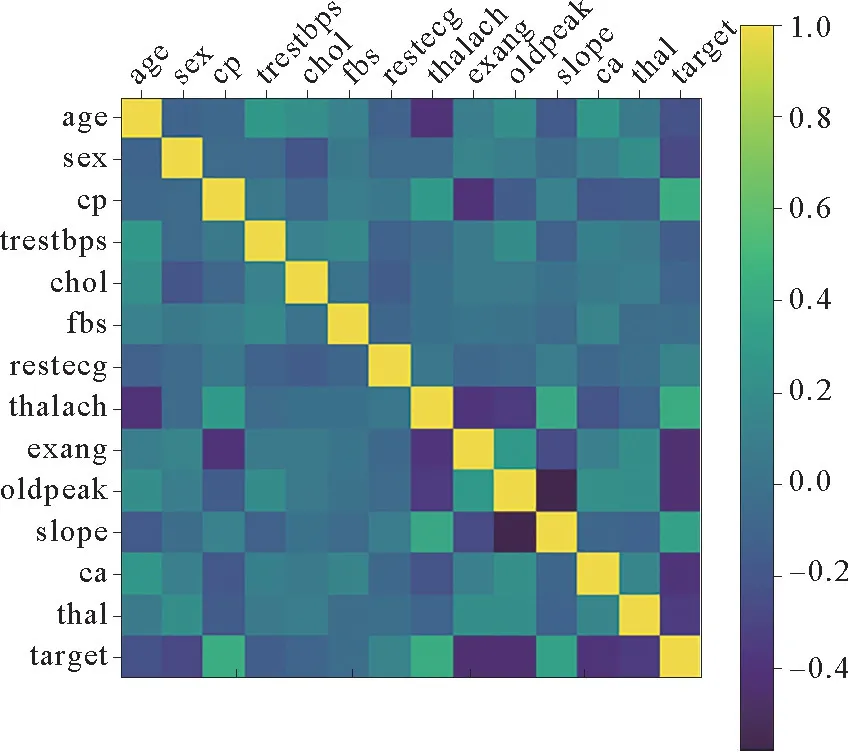
图3 特征相关性分析Fig.3 Feature correlation analysis
3.2 算法设计
为了提高算法的准确度,利用网格搜索算法对随机森林(RF)算法进行参数调优。设定随机森林分类树的数量为n_estimators,范围设置为[10,100,200,500,1 000],分类树的高度为max_depth,范围设置为[3,4,5,6,7,8],最大叶子节点数为max_leaf_nodes,范围设置为[11,12,13,14,15,16]。利用Python中Scikit-Learn.GridSearchCV网格搜索算法按步长依次调整参数,在指定的参数范围内找到精度最高的参数,采用10倍交叉验证方法对其进行评估。10倍交叉验证对训练数据集进行训练,将数据集平均分为10份,随机选择其中的9份作为训练集,剩下的1份作为测试集,一共进行10次训练和测试,使用选择好的评分方式如准确率来求平均值,然后找出最大的一个评分对应的参数组合,得到分类准确率最高的最优参数。通过网格搜索算法多次寻优后,确定最佳参数组合为[n_estimators:100,max_depth:5,max_leaf_nodes:16],算法准确率最高。
本研究模型流程主要包括数据预处理、特征分析以及利用随机森林(RF)对数据集进行分类预测。模型流程如图4所示。

图4 基于优化的随机森林预测算法模型流程Fig.4 Model flow of prediction gorithm based on optimized random forest
4 实验结果与分析
4.1 实验过程
本研究的实验数据来自UCI公开心脏病数据集以及克利夫兰医学中心,由于两个数据集的特征数量和内容相同,在经过数据预处理后,两者对数据的表现形式完全一致,因此,为了实验能够表现出更好的泛化能力,将两个数据集的数据进行混合,并按照7∶3的比例分类训练集和测试集,进行建模。
此外,建模所用的数据共573条,为了让模型拥有足够多的数据量以便使预测效果更好,本研究采用交叉验证方法扩充数据集。交叉验证也就是重复使用数据进行切分组合,将其组合成为不同的训练集和测试集。在此基础上可以得到多组不一样的训练集和测试集。此外,在机器学习中,讨论的数据量大小一般是指样本量除以特征量的值,适中的数据量较适合使用树结构模型,若数据量过大,也容易造成过拟合现象。因此,综合数据量与特征数,本研究使用随机森林进行建模所需的数据量基本足够。
本研究基于Python语言,在Anaconda环境中构建随机森林算法进行实验。本实验对数据集进行缺失值处理、one-hot处理以及数据归一化等一系列数据预处理操作,得到更加干净、可用性高的数据。为了分析各特征之间的相关度和对疾病产生的影响,选择使用热力图展示来各个特征的相关度,经过分析比较,该数据无冗余特征。
实验采用优化的随机森林算法对模型进行训练,通过bootstrap重采样技术,抽取训练样本,对选取特征进行节点分裂,生成随机森林。使用网格搜索算法对随机森林配置最优参数,得到预测模型。建模流程如图5所示。

图5 随机森林模型流程Fig.5 Random forest model process
为了进一步验证网格优化后随机森林的有效性,将该模型测试结果与Logistic回归、GBDT、决策树(DT)进行比较。
4.2 评价标准
在医学诊断中,评价分类器的优劣通常采用准确率、召回率(灵敏度)和特异度等指标。准确率(accuracy)表示对于给定的测试数据集,正确分类的样本个数与总数之比[14];召回率(recall)表示预测为正例的样本与实际为正例的样本的比例。特异度(spcificity)表示预测也为负例的样本与实际为负例的样本的比例。以关注的类通常为正类,其他类为负类[15]。混淆矩阵表示分类器在测试数据集上预测是否正确,如表3所示。

表3 混淆矩阵Table 3 Confusion matrix
其中,P为正类样本的数目,N为负类样本的数目。4个评价指标的公式:
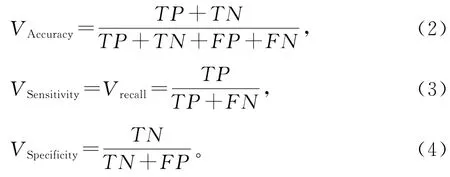
ROC曲线是由灵敏度(真阳性)为纵坐标,特异性(假阳性)为横坐标绘制的曲线,能够反映不同分类算法的性能。ROC曲线越靠近左上角,表明准确度越高。ROC曲线下的面积称为AUC,也是衡量算法优劣的性能指标,AUC值越大,算法效果越好[15]。
4.3 结果分析
利用随机森林算法,对21个特征与是否患心脏病进行相关性分析,得到输入特征的重要性,如图6所示。图6横坐标为21个特征属性,其中,0:age,1:sex,2:trestbps,3:chol,4:fbs,5:restecg,6:thalach,7:exang,8:oldpeak,9:ca,10:cp_0,11:cp_1,12:cp_2,13:cp_3,14:slope_0,15:slope_1,16:slope_2,17:thal_0,18:thal_1,19:thal_2,20:thal_3。实验结果表明,thal_2对是否患心脏病影响最大,特征重要性最高。
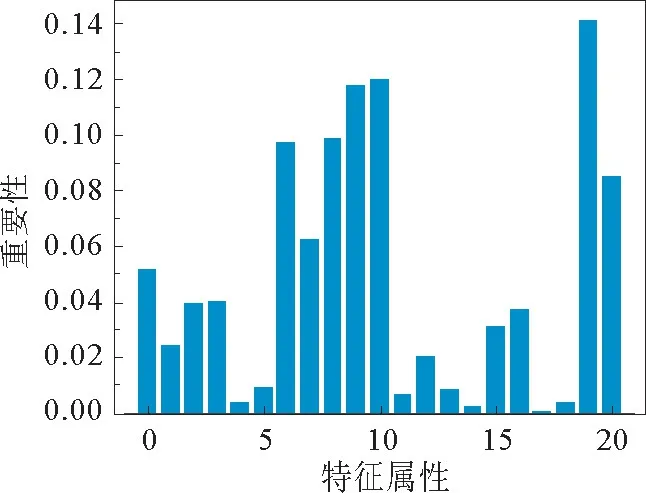
图6 随机森林输入特征重要性Fig.6 Random forest input feature importance
其中,特征6~9、10、19、20重要性排在前7位,这7个特征分别代表最高心率、运动是否诱发心绞痛、运动引起ST抑制、主要血管数、胸痛类型、地中海贫血,根据医学常识这7个特征可作为主要判断参数,患者在就医时通过体检,获得特征数值可作为医生诊断重要参考。这几个重要特征不仅能够预测是否患有心脏病,同时也给医生诊断和患者就医带来参考意见。
分别将其与Logistic回归、GBDT、决策树(DT)进行比较,验证优化后随机森林(RF)算法是否具有更好的效果,通过对其几种算法的准确率、召回率、AUC值进行对比,发现本研究提出的方法结果优于其他算法,实验结果如表4所示。
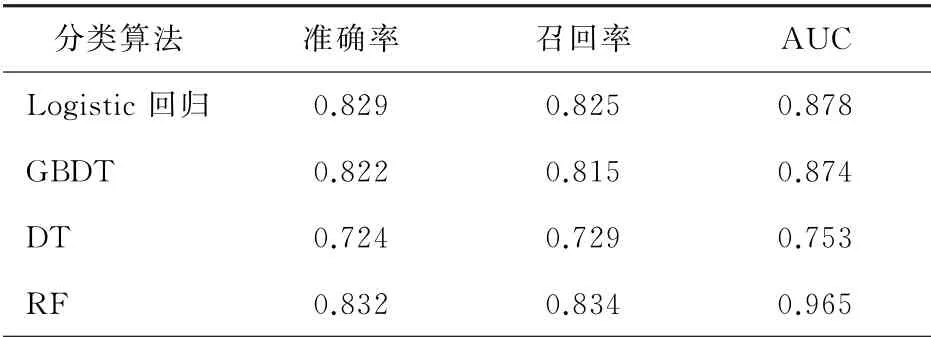
表4 不同算法结果比较Table 4 Comparison of results of different algorithms
从表4可以看出,随机森林算法准确率为0.832,较Logistic回归提高了0.3%、较GBDT提高了1%、较决策树(DT)提高了10.8%;随机森林算法召回率为0.834,较Logistic回归提高了0.9%、较GBDT提高了1.9%、较决策树(DT)提高了10.5%。为了更清晰的对比各个算法的性能,更好的展示AUC值,对各种分类算法进行ROC曲线比较[16](图7)。从图7可以看出,RF算法的ROC曲线下的面积是最大的,即AUC值最大,值为0.965。

图7 不同分类算法的ROC曲线Fig.7 ROC curves of different classification algorithms
经过实验发现,通过对随机森林算法进行网格搜索优化,算法的准确性得到了提升,泛化能力能到增强,不同的调参数值得到的结果不同。表明随机森林算法在心脏病预测方面的有效性和可行性。可以根据算法预测结果对医生进行辅助诊断,给患者带来就医参考。对智慧医疗中疾病预测的进步有现实意义。
5 结 语
本研究在UCI开源心脏病数据集和克利夫兰医学中心数据集上进行实验,针对精度较低的缺点,提出了基于网格搜索的优化随机森林算法的建模方法,用来预测心脏病。通过对数据集进行预处理,对特征进行分析,对超参数进行调整,用随机森林算法对数据分类预测,获得了较好的效果。为了验证该算法的优越性,将其与Logistic回归、GBDT、决策树(DT)等算法进行比较,在准确率、召回率、AUC值方面验证该算法优于其他机器学习算法。由于该数据集的数据量较小,无法证明该算法适用于大数据集,下一步对大数据集进行分类预测的情况下,需要进行特征选择对算法进行优化。
