意见代表:微博社会的内容阶层及其内聚性
2021-04-09□徐翔
□徐 翔
[同济大学 上海 201801]
引言
微博是一种重要和典型的社交网络与社交媒体应用。微博中的用户,随着粉丝量、影响力的增大而成为各种大咖、大V、各种流量明星、意见领袖,这些高影响力的用户之间,较之于低影响力的用户之间,在内容上是否变得相互越来越趋同?抑或相互之间变得内容越来越差异化?
基于微博用户数据提出用户随着影响力的提升,而呈现出“金字塔结构”:影响力越低的“底部”层级,层级中的用户之间的内容差异越大、彼此之间越是松散;影响力越高的“顶部”层级,层级中的用户之间的内容差异越小、彼此之间越是趋同和“浓稠”;从而从底部到顶部,表现出由松散、内容距离大,逐渐提升为内容距离越来越小、越来越紧密相似的“金字塔结构”。
采用新浪微博样本用户对此现象进行验证。按照粉丝规模的高低,把24 779个样本切分为从低到高的400个层级;为了统一比较口径,进行“等频”分层,每层级的用户人数相等。每个层级内用户内容的相互趋同程度,分别用两个指标来衡量。(1)指标a。层内用户的内容平均相似度:两两之间内容相似度的均值。(2)指标b。层内用户内容相似性网络的“平均群聚系数”(Average Clustering Coefficient)[1]。
对于这400个层级而言,指标a和指标b,都随着层级用户平均粉丝规模的提升而同步上升,具有显著而且高强度的线性相关性,如表1所示。
这种规律性的现象,对于上述“金字塔结构”表现得非常鲜明。用户根据粉丝规模划分为400个层级后,随着层级提升,越是高层级则内部越是相互趋同化,而非差异化、松散化。相关系数甚至达到0.758乃至0.8以上,这在社会现象研究中是高程度的正相关性。虽然对于微博意见领袖的研究已很多,但是多数集中于意见领袖的形成与识别[2~3]、微博意见领袖有哪些重要类型[4]、意见领袖具有怎样的行为特征[5~6]和影响作用[7~8],而意见领袖用户、高影响力用户的趋似现象和态势,特别是上述金字塔结构的演化态势,则得到的关注尚较少。
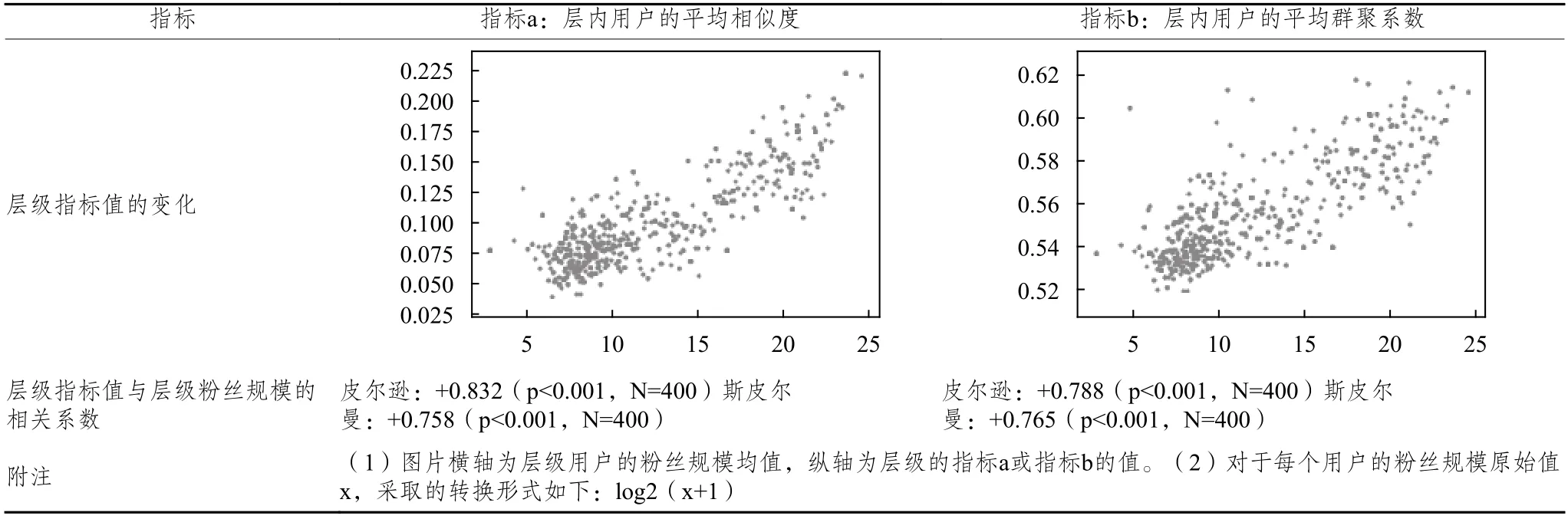
表1 用户层级的影响力与层级内用户趋同程度
本文把具有相似影响力程度且具有相似内容的用户层级,称为微博“内容阶层”。主要研究在“金字塔结构”下,三个相关方面的问题:(1)具有某种相同或相近影响力的用户群,也具有相似的内容,形成“相似用户在同影响力层级的聚集”,是否一种普遍性的现象与趋势?(2)本文后续的首要任务之一,是探讨用户为何会出现“内容阶层”的分化和封闭性,同影响力的用户之间的内容相似度高低及其内聚性如何发生?(3)“内容阶层”在何种作用机制与条件下,会表现出随着层级影响力从低到高而不断收窄、不断加强层级内用户相似度的“金字塔结构”?
对于这紧密相关、连贯问题的尝试回答,和微博用户、意见领袖的一种隐藏角色有关,我们称之为“意见代表”的用户角色。这种角色长期被重视程度不够,尤其在和“意见领袖”的主角光环之下相形见绌。但是它是用户的一种客观存在的角色,对于社交网络的用户层级凝聚和分化、形成内容阶层内聚性,具有不应忽视的作用。从意见代表到内容阶层的路径和效应,构成本文的中心任务。
一、微博“意见代表”与“内容阶层”
(一)微博“意见代表”的现象与内涵:用户内容–影响力对应性
意见领袖是网络传播与社交网络领域的热门研究主题。拉扎斯菲尔德等人提出,意见领袖是构成信息和影响的重要来源,并能左右多数人态度倾向的少数人[9]。结合已有研究[10~12]我们把微博意见领袖概括为微博具有高影响力的用户,并把影响力用于衡量用户作为意见领袖强弱的程度。
意见领袖会对于其他用户形成一定的同化作用。例如舆情场势理论认为,意见领袖通过社交网络场域节点中的“振动(闪烁)粒子”,同化受众。但是对于微博、社交网络的多数研究,强调的是核心用户、有影响力的用户,对于其粉丝和关注者、追随者带来的同质化效应;而不是处于相同或相近影响力的用户群本身,如何形成或加强相互的同质性。例如,有研究指出Twitter用户和其直接粉丝之间存在着信息内容和主题上的同质现象[13]。博客中的普通用户关注对象常常集中在特定的核心博客上,容易陷入特定主题的交流社区[14]。这些对于意见领袖的同化现象与作用的研究是本研究的基础和借鉴。然而,高影响力的意见领袖用户比低影响力用户,粗看起来,并没有理由需要和同影响力程度的其他用户更为趋似。直接从“意见领袖”角色和特征仍然难以直接解释的是:同影响力的用户群体或层级内为何会具有相似的内容,从而表现出该“影响力层级”内的特定强度的用户趋同性?对于不同的影响力层级,其层内用户趋同程度的高低变化受到什么样的影响因素的作用,尤其是,为何会随着层级影响力的变化而发生正向对应的变化?
用户的同质化聚集以及区隔受到多种因素影响。Marshall认为网络信息技术加深了学科专业、社会阶层、个人偏好、社会文化的壁垒,加强网络“巴尔干化”中的个体信息相似程度[15]。Itai Himelboim等人通过社会网络分析Twitter上发表意见的用户,发现集群内观点、立场的同质化明显[16]。张志安等人的研究显示,微博中公知型意见领袖群落分散,营销类、娱乐类用户成为微博意见领袖群体的主流[17]。这些显示社交网络用户基于某些壁垒发生“巴尔干化”的局部聚合,产生用户类型的狭窄化分布的可能。而同质用户如何在影响力这个因素下发生内聚与区隔,也成为亟待继续研究的问题。这种壁垒不仅仅是用户的社会身份、个体属性等线下因素壁垒,也可能是在线的影响力和话语内容特征本身带来的壁垒,以及由此而生成的不同层级间的区隔。
针对这种在相近影响力条件下,内容相似用户的聚合及其变化机制,本研究强调的是,在用户的“意见领袖”角色之外,一种容易被忽视的用户角色和功能,我们称之为“意见代表”。微博网络中,意见代表的内涵定义如下(C0):其他任意用户y,若与用户x在内容上越相似,则y的影响力和x越接近,反之亦然;这亦等价于,若其他用户和x在内容相似度、影响力接近度这两方面正相关程度越高,则用户x的“意见代表”程度越强。这里显现的是一种“内容–影响力”上的对应性,用户作为一种影响力的“代表”,指涉着这个影响力层级所属人群的内容特征。意见代表不是像意见领袖那样涉及影响力的扩散,而是涉及某种影响力人群的代表。
为便于后文的进行,把用户作为意见代表的程度简称为“代表力”,以区别于用户作为意见领袖的程度或“影响力”。对于代表力的衡量方法,直接从意见代表的定义(C0)就可以得到,如下(C1):设微博中的某个用户为x,其他用户依次标为序列U=[U1,U2,U3,…,Un];U中每个用户和用户x的内容余弦距离(也即1−内容余弦相似度),依次标为序列S=[S1,S2,S3,…,Sn];U中每个用户与x的影响力接近度(也即两者影响力之差的绝对值),依次标为序列H=[H1,H2,H3,…,Hn];其中序列U和序列S、序列H中的每个元素顺序是严格一一对应的;通过H与S的皮尔逊相关系数Px的值,即可以反映用户x作为意见代表程度或者“代表力”的高低。如果x的“意见代表程度”(或“代表力”)足够高,则序列S和序列H应该是显著正相关的,从而使得,S中的元素值越大则意味着H中对应顺序的元素值也越大。其中,若Px相关系数不显著,则表明两者不存在直接相关性,把Px记为0;总体上,代表力Px值在[−1,+1]区间内。Px越大,表明:其他任意用户若与用户x相似度越高,则影响力越接近,两者的正相关程度很高,从而等价于用户x作为意见代表的程度也越高。
意见领袖的角色只能够确证的是,自己是具有影响力的,但是不能够确证的是,和自己内容相似的其他人是不是也具有影响力?以及和自己在内容上越相似的其他人,是不是就越拥有和自己相近似的影响力?然而从深层次可以期望的是,影响力不只是指涉自己拥有影响力,也可以指涉自己拥有的影响力程度有可能通过内容相似性而传递到其他用户的影响力程度。而这种影响力的传递,会进而带来相关联的社会后果,这也是我们对“意见代表”的作用与机制进行审视的进一步意义。
“意见代表”与“意见领袖”相比,差异如下:“意见领袖”强调的是,用户自身内容所可能具有的影响力,是对于自身影响力的描述;而“意见代表”强调的是,与自己内容相似的其他用户所可能具有的影响力,以及对于和自身同影响力层级的其他用户在内容上的“代表”,也是对于和自身内容相似的其他用户在影响力上的“代表”与“标杆”。
上述及后文将要涉及几个简称,内涵如下。1. 影响力层级(后文简记为Z1)。在本研究中,用户所处的影响力层级,指的是对于某用户x而言,与该用户x具有相同或最相近影响力的k个用户所组成的用户群(也包含x自身)。后文的实证分析中,选择k=50,使得层级既不会规模太小而影响稳定性,又不至于规模太大而包含过多的影响力差距太大的用户。2. 内容阶层(后文简记为Z2)。指具有相同或相近影响力的k个用户构成的影响力层级中,这些用户群,同时也具有很强的用户内容趋同性,形成“特定影响力–特定内容”的对应关系,形成微博中具有本群体的内容特质的、处于特定的话语地位的用户“阶层”。3. 影响力层级或内容阶层内部的用户趋同性(后文简记为Z3)。指的是,某个用户群或用户层级,在内容上趋于彼此相似、各个用户内容“长得像同一个人”的趋势和程度。4. 影响力层级或内容阶层的内聚性(后文简记为Z4)。Z4和前文Z3具有共同的指向;为了简化行文,后文用内聚性,指称层级内部用户在内容上的趋同态势,内聚性的高低则指代这种趋同的程度。
对于微博“意见代表”的现象,要做的基础性的准备工作和预调研如下:其一,通过测量,考察意见代表在现实中是否存在,在何种程度上存在,而不只是一种理论抽象;其二,既然意见代表和用户的影响力存在着密切的内在联系,所以要考察意见代表和意见领袖这两种角色之间的关系,它们是相互独立的吗,抑或具有重合性?
而这两个基础性的准备工作都服务于后续的核心问题:微博用户作为“意见代表”的角色(C0)与程度(C1),是否以及如何作用于该用户所处的影响力层级(Z1)内的用户趋同性?对此,将继续围绕意见代表,从直接和间接两个方面,展开这个核心问题的分析:其一,直接层面,用户作为意见代表的角色和程度,如何影响到用户所处的影响力层级的用户趋同性(Z3、Z4)?其二,间接层面,用户作为意见代表和意见领袖的角色之间的关系,如何影响到用户所处的影响力层级的用户趋同性(Z3、Z4)?而这直接层面与间接层面的效应,构成本文路径分析的“意见代表–内容阶层”效应和作用机制的核心。
(二)微博“意见代表”与内容阶层:同影响力用户的内容趋同
本小节针对的核心问题,是从“意见代表”的角度和直接层面,来探讨微博用户中为何会形成“相近影响力的用户具有相似内容”的对应性,从而加强用户所处的影响力层级内部的趋同性?尤其是,用户作为“意见代表”的角色和程度,是否以及如何作用于用户所处的“影响力层级”内部趋同性的程度(Z3、Z4)?
从意见代表的内涵定义(C0)可以知道,一个用户的“意见代表”程度越高,则和他内容越相似的用户影响力就越接近,也就意味着和一个“意见代表”内容最为相似的k个用户的影响力和该“意见代表”越接近乃至于趋同。其结果就是,当一个用户的意见代表程度足够高的情况下,就会形成相似内容的用户,其具有和他相似的影响力。换一个角度来看,具有相同或相近影响力的用户,表现出更高的内容相似度,而非彼此之间的内容差异、杂乱和随机化。也即,和该“意见代表”的影响力相同或相近的其他用户,和“意见代表”的内容相似度,会随着“意见代表”程度提升而升高。由于各个用户都和“意见代表”的相似度提高,导致这些用户相互的差异也在减少,共同点变得越来越多,从而层级内各个用户越像同一个人,彼此相似度越高。最终结果是,越强的“意见代表”所处的影响力层级内的用户,内容相似度越高。
如果用户x的“意见代表”程度越高,则意味着该用户x作为该影响力层级的“内容代表”的程度越强,其他与该用户x同影响力的用户就和x的内容相似度越高,两者的正相关程度、可预测性越强。
总体而言,用户的“意见代表”程度,虽然只是用户个体的角色特征,但是却会带来对于微博整体中的层级分化。对于微博的全局用户系统而言,会形成一个个“内容相似且影响力接近”的内容阶层(Z2),而不是用户之间内容相似但影响力差距杂乱化、随机化,或影响力相似的一群用户但相互之间内容差异杂乱化、随机化。更为重要的是,用户的意见代表程度,直接关系到这种“内容阶层”内部的紧密性,或者说,关系到该用户所处的影响力阶层内部的趋同性高低。使得微博全局系统中,用户不仅出现基于影响力的“内容分层”,而且这种层级的趋同、内聚程度受到该用户的意见代表程度的正向作用力。
由上分析,可得假设H1:任意用户x的意见代表程度,对于该用户所处的影响力层级内的用户趋同程度,具有正向作用。
用户作为意见代表的代表力程度,回应了用户“内容阶层”(Z2)是否可能的问题,也直接作用于用户所处的同影响力层级内的趋同程度(Z3、Z4)。而用户所处的影响力层级内的趋同程度的高低,正是本研究从“意见代表”要面向的核心对象之一,它关系到微博社会中的层级分化以及层级分化的松散或稠密演变。
(三)微博“意见代表”与内容阶层的金字塔结构
本小节针对的核心问题,是从意见代表的间接层面,尤其是意见代表和用户影响力之间的关系,来探讨微博中“相近影响力的用户具有相似内容”的对应性,是否以及如何与“意见代表”有正向关联?尤其是,“意见代表”用户是否以及如何通过其和“意见领袖”角色的关系,间接作用于“意见代表”所处的影响力层级内部趋同性的程度?
这里,我们首先需要探讨意见代表和意见领袖的角色关系。高程度的意见代表是谁?是高影响力的意见领袖吗?抑或是低影响力的“普罗大众”更容易作为代表?这两者都和用户的影响力密切相关,关系到用户的影响力程度或者对于自身影响力的传递程度。对于这个问题,容易有两种误识:一种是不认为意见代表的分布有什么规律,认为他们在各种小咖、中咖、大咖里面的分布是“差不多”的、均匀或随机的;另一种误识,认为他们主要是处于影响力最底层的“普罗大众”或“下里巴人”等最为草根和“群氓”的用户,因为这些低影响力的用户看似无个性的芸芸众生,他们中的每个人似乎都可以很好地“代表”其自身所处的影响力层级的其他用户,反映这些同为低影响力用户的共同“无个性”、无辨识度的特征。
关于这两种角色的关系,我们面临三种不同的可能性:可能1,用户作为意见代表的程度和作为意见领袖的程度是正相关的;可能2,用户作为意见代表的程度和作为意见领袖的程度是负相关的;可能3,用户作为意见代表的程度和作为意见领袖的程度是不相关的。
如果验证成立的是可能1,则会意味着:用户的影响力越高,则其“意见代表”程度越高,而与其同影响力层级的k个用户的趋同程度就越强,从而表现为在意见代表和意见领袖的共同角色作用下,用户的影响力越高则其影响力层级内的用户越是彼此“长得像同一个人”。在此基础上,会形成影响力底部层级内部用户松散、彼此内容距离稀疏、缺乏相似性,影响力顶部层级相互似同、内容距离窄密,表现为底松顶紧、逐渐递减的“金字塔”结构。如果验证成立的是可能2,则基于相似的原理,微博用户全局会形成底部稠密、顶部松散、逐渐变化的“倒金字塔”结构。如果验证成立的是可能3,则由底到顶缺乏明显规律性的变化趋势,可能表现为既非金字塔也非倒金字塔的平衡结构。基于微博最终表现出来的是“金字塔结构”,所以我们可以推测的是,成立的是可能1。否则后两种的可能2、可能3,都只会导致倒金字塔结构或平衡结构,而不是金字塔结构。这样,我们提出前后关联的两个假设:
H2:任意用户x的意见代表程度,对于该用户的意见领袖程度具有正向作用。
H3:任意用户x的意见领袖程度,对于该用户所处的影响力层级内的用户趋同程度具有正向作用。
H2和H3的假设如果成立,意味着:同影响力层级的内收,不仅受到用户的代表力的作用,也受到“意见代表”和“意见领袖”的共同作用,其中“意见代表”通过“意见领袖”而对于用户的影响力层级趋同性产生间接效果,而“意见领袖”则起着连接“意见代表”与用户影响力层级趋同性的中介效应。内容阶层的分化与影响力层级的内聚是金字塔结构的前提;而“金字塔结构”则进一步表明这种影响力层级的内聚趋同,受到用户的“意见代表”的间接作用,从而表现出与用户影响力的关联越来越强。
(四)整合后的“意见代表–内容阶层”模型(RLC)与路径分析
对于前文的三个子假设H1、H2、H3进行整合,形成下述的“一主线、两路径”的问题结构和逻辑关系。“一主线”是:用户的“意见代表”角色(C0、C1),是否以及如何加强用户所处的“影响力层级”内部趋同性,使得用户产生“特定影响力–特定内容特征”的对应现象?或者说,意见代表如何形成与加强内容阶层内部的趋同性和内聚性?围绕这个主线,从直接路径和间接路径两方面展开。直接路径是:用户的意见代表程度,直接作用于该用户所处的影响力层级、加强其层级内的趋同性(假设H1)。间接路径是:意见代表同时也是意见领袖(假设H2),从而通过其意见领袖的程度,作用于该用户所处的影响力层级,加强其层级内的趋同性,并且在此过程中表现出影响力层级的“金字塔结构”现象(假设H3)。
最终形成直接路径和间接路径整合后的作用关系模型(图1所示),命名为“意见代表–内容阶层”效应模型。其中的三个要素:起始的自变量要素指涉为意见代表,中介性的变量指涉为意见领袖,终端的因变量指涉为内容阶层,结合三者的英文单词首字母,将该模型简称为“RLC”模型。采取Amos软件进行路径分析,考察RLC模型中各子路径的效应和总体模型的拟合状况。
二、研究方法和操作过程
围绕上文的“一主线、两路径”及其H1、H2、H3组成的路径分析模型,针对用户的意见代表角色和程度如何影响、加强微博社会“内容阶层”的分化与凝聚,选取新浪微博的用户样本,进行实证检验与分析。
(一)样本选取与数据预处理
根据新浪微博数据中心的资料,新浪微博月活跃用户4.62亿,月阅读量过百亿领域达32个[18]。新浪微博是我国具有高度的人气和舆论覆盖度的社会化媒介平台。本研究采取广覆盖、成本相对较低的多阶段抽样。首先从新浪微博首页47个内容版块(社会、国际、科技、科普、数码、财经、股市、明星、综艺、电视剧、电影、音乐、汽车、体育、运动健身、健康、瘦身、养生、军事、历史、艺术、时尚、美妆、动漫、宗教、萌宠、法律、视频、上海、美女模特、美图、情感、搞笑、辟谣、正能量、政务、游戏、旅游、育儿、校园、美食、房产、家居、星座、读书、三农、设计)中,获取其发布者和评论者共3 501 153个用户的数据库,从中最终抓取到具有有效个人资料的、发帖数不少于500条的88 739个有效用户;对这些有效用户,再采取整群抽样,以每页作为一个群,抓取每人的前5页关注者资料(新浪微博对于数据抓取的实际限制,只开放最多为5页×每页20个=100位关注者)。由于不同的用户其所关注的人可能有重复,经过选取发帖数不少于500条、去重以及具有相匹配的个人资料等清洗环节,从这些被关注者中选取到有效用户130 082个。
对用户统一横向的比较口径。其一是帖子发布的时间段统一在2018年1月1日~2018年12月31日。其二是帖子数量,每个用户统一随机选取在上述时间段内所发的500条帖子。以达到通过帖子样本,“察其言、观其人”,并进行用户相似度计算。
经过上述取样和有效数据的清洗整理,最后得到的样本用户为24 779个,这些用于计算的用户有广泛性与代表性。粉丝量、发博量、关注数等各主要指标都包含从数十到数万乃至数千万的大范围,各种重度/轻度、活跃/不活跃用户都有良好覆盖,如图2所示。

图2 样本用户的特征分布柱状图
(二)微博用户作为意见领袖程度的指标
“圈粉”能力和效果,是社交网络中的意见领袖、大咖的重要区分指标,也是对于诸多微博用户而言,最具有现实难度和实际经济价值、社会价值的事。对于社交网络意见领袖、大V的诸多研究突出“粉丝数”指标的重要性[19]。用粗糙集理论发现,“粉丝数对能否成为意见领袖至关重要”[20]。有研究甚至把粉丝规模作为区分微博大V、中V的唯一依据[21]。本研究把粉丝规模作为微博用户影响力的指标,用该指标反映用户的意见领袖程度。实际抓取得到的粉丝数,将其原始数值x经由对数函数转换为log2(x+1),作为研究中的粉丝规模指标值。
(三)用户内容的特征提取与向量化表示:VSM+LSA
把单个用户的各条帖子,无顺序拼接为一个长文本,先通过向量空间模型(VSM)得到每个用户的词频矩阵。词频矩阵的获取,采取常用的模块scikit-learn中的CountVectorizer()函数,其中最低词频数min_df设为50,max_df设为0.2,只采用一元词,由此得到词频矩阵X0。将X0转为经L1规范化的TFIDF矩阵X,转换函数为sklearn.TfidfTransformer(norm='l1')。
对于矩阵X,采取潜在语义分析(LSA)进行降维和内容特征提取[22]。LSA利用奇异值分解(SVD)技术,可把数十万以上的高维、稀疏的词频矩阵,降到只有数千、数百的低维表示。其中,对于矩阵X,进行奇异值分解可得:X=TΣDT。LSA保留前k个最大的奇异值,即通过TkΣkDkT来近似地表示原用户–词项矩阵X。
本研究中,每个用户的VSM词频矩阵原有113 694维,一律通过潜在语义分析降维到700维。降维工具选择广泛应用的开源模块scikit-learn中的TruncatedSVD()函数。
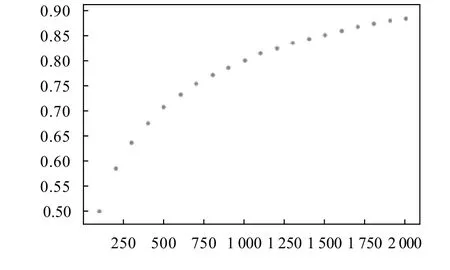
图3 潜在语义分析对用户内容降维的解释方差比
选择700维的维度时,处于图3中“肘拐点”的位置,再增加维度对于保留原信息的程度增长平缓;同时,TruncatedSVD()计算得到的解释方差比(explained_variance_ratio_)值已达0.76,用尽可能精简的维度,提取和高效保留了原有的11余万维矩阵的大部分信息,从而表示用户特征并用于用户之间的内容相似度的计算。
(四)用户的内容相似度计算:两个用户之间或两组用户之间
把每个用户转化为一个若干维的向量后,两个用户之间的内容相似度,由计算他们各自向量的余弦相似度得到,值域在[−1,+1],值越大表明这两个用户之间内容越相似,当该值等于1时表明这两个用户的相似度等于1,也即彼此相同。与之对应的两个用户之间的内容距离,则用1减去上述余弦相似度。
任意两个用户Um和Un之间的内容余弦相似度,计算方式表示为:

在上述式(1)的基础上进行扩展,从“1对1”的用户相似度,扩展到“n对n”的两组用户(每组中用户数量n≥1)之间的相似度。任意一组用户G1(包含n1个用户)和另一组用户G2(包含n2个用户)的内容相似度,表示为:

式(2)在式(1)的基础上,采用衡量两组对象间的平均距离所常用的“类平均法”(或称“簇平均法”,average group linkage)扩展得到。其中G1或G2都可以有且仅有一个用户。如果H(G1,G2)的值越大,表明G1、G2这两组用户之间两两的趋近、类同乃至重复程度越高;若两组用户的异质化内容越大,则平均相似度就会越低,也即H(G1,G2)的值越小。
式2中,当n1=n2=1时,则等同于式(1)。这种情况下:式(1)中计算的个体与个体之间的两两相似度R(Ux1,Ux2),成为式(2)中n1和n2分别是1时的特例。
当n1=1而n2>1时,式(2)为计算一个用户和一组用户之间的平均相似度。
式(2)中,当计算层内用户的平均相似度(也即前文的指标a),此时过滤掉个体和他自身的相似度(因为该值等于1)后,计算剩余元素的平均值,所以采取式(2)的微调形式
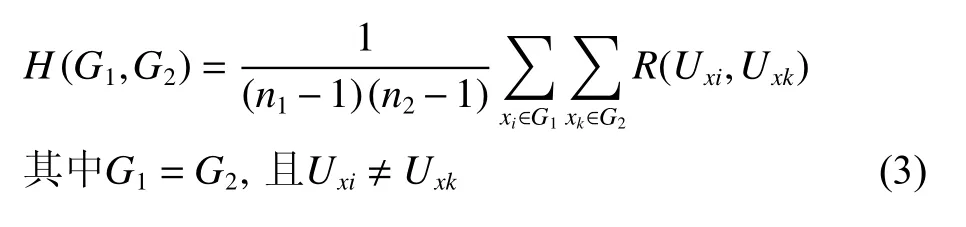
三、对于主要变量和子假设的预调研
根据对于意见代表的内涵界定(见C0)及其程度的衡量方法(见C1),以及用户向量化、用户内容相似度等的计算方法,最终对获取的24 779个微博样本用户,计算得到每个用户的意见代表程度(代表力),分布柱状图见图4。

图4 微博“意见代表”分布柱状图
用户作为“意见代表”,并不是特殊现象而是普遍现象。全体的意见代表程度均值为0.037,中位数为0.041。57.7%的用户具有正的意见代表程度;32%的用户的代表力为负;只有10.3%的少数用户的意见代表程度为0,不具备意见代表的角色和属性。
接下来,这些“意见代表”的分布至关重要。用户作为“意见代表”的代表力,和作为“意见领袖”的影响力,两者的程度是否有重合性?因此,针对H2进行验证。对于24 779个样本用户,分别取得“意见代表”程度的序列和影响力程度的序列:皮尔逊相关系数+0.618(p<0.001,n=24 779),斯皮尔曼相关系数+0.494(p<0.001,n=24 779)。从而意味着,对微博用户而言,其影响力程度越高,则其意见代表程度越高。这两种角色的正向兼容而非相互独立或对立很重要,从而由意见代表和意见领袖的共同作用机制,带来了用户影响力层级不断增强内容趋同的“金字塔结构”和变化规律性。
总体上,H1、H2、H3的检验过程和结果见表2,全部得到了检验。

表2 子假设的检验结果
其中,对H3的检验结果,显现了用户的影响力与其影响力层级内用户趋同程度的高度正相关,上表已经显示了其高达0.8以上的相关系数,这在社会科学研究中是比较少见的正相关程度。其具体的可视化图见图5。这种较为强烈的正相关,得以形成用户随着影响力层级的提升而内聚性不断增强的金字塔结构。
四、整合模型的路径分析
对于“意见代表–内容阶层”模型,通过AMOS软件进行整体化的路径分析。为了简化,用户的影响力层级内趋同程度,只采用指标b表示(因为指标a和指标b具有高度的重合性,两者的皮尔逊相关系数高达0.997(p<0.001),所以只选择其中一种)。分析中涉及的三个指标,即用户的意见代表程度、影响力、影响力层级内的用户趋同程度(也即所采取的指标b),全部由BLOM公式转为正态得分值,转换后符合正态分布的要求;模型的参数估计方法选择常用的最大似然估计。
路径分析的拟合效果,部分重要指标及其判断标准见表3。
各路径的标准化回归系数及其显著性检验如表4所示。
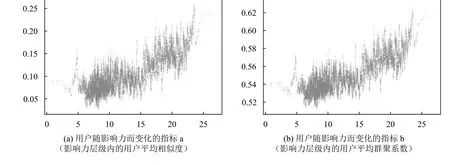
图5 不同影响力层级的用户趋同程度
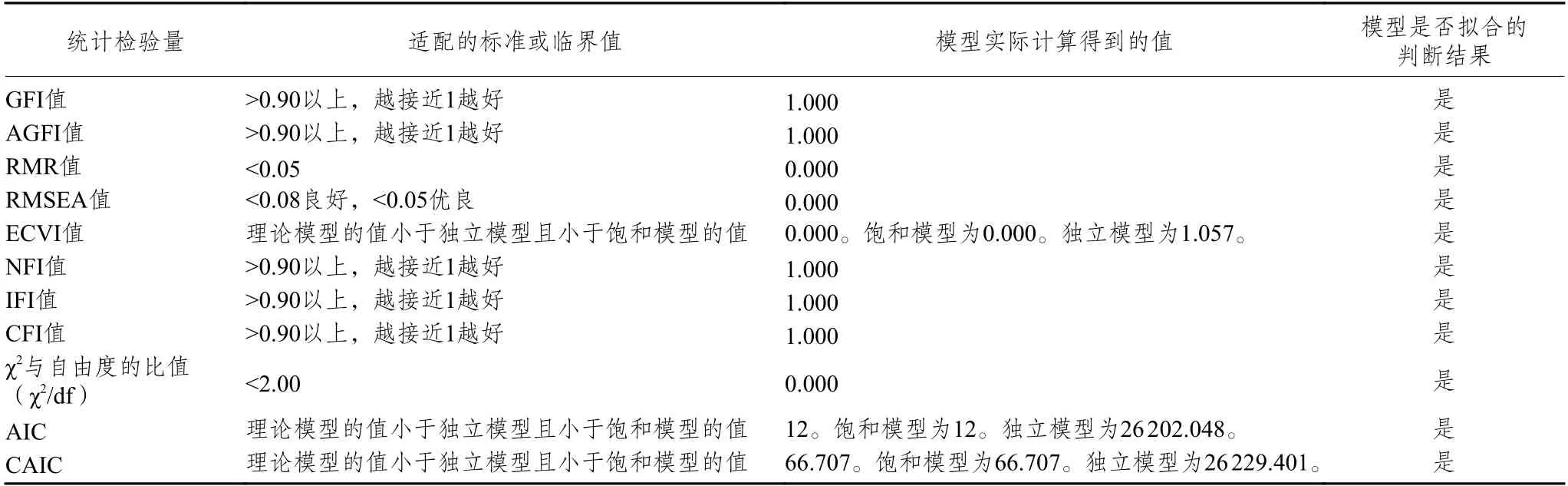
表3 路径分析的拟合判断

表4 标准化回归系数
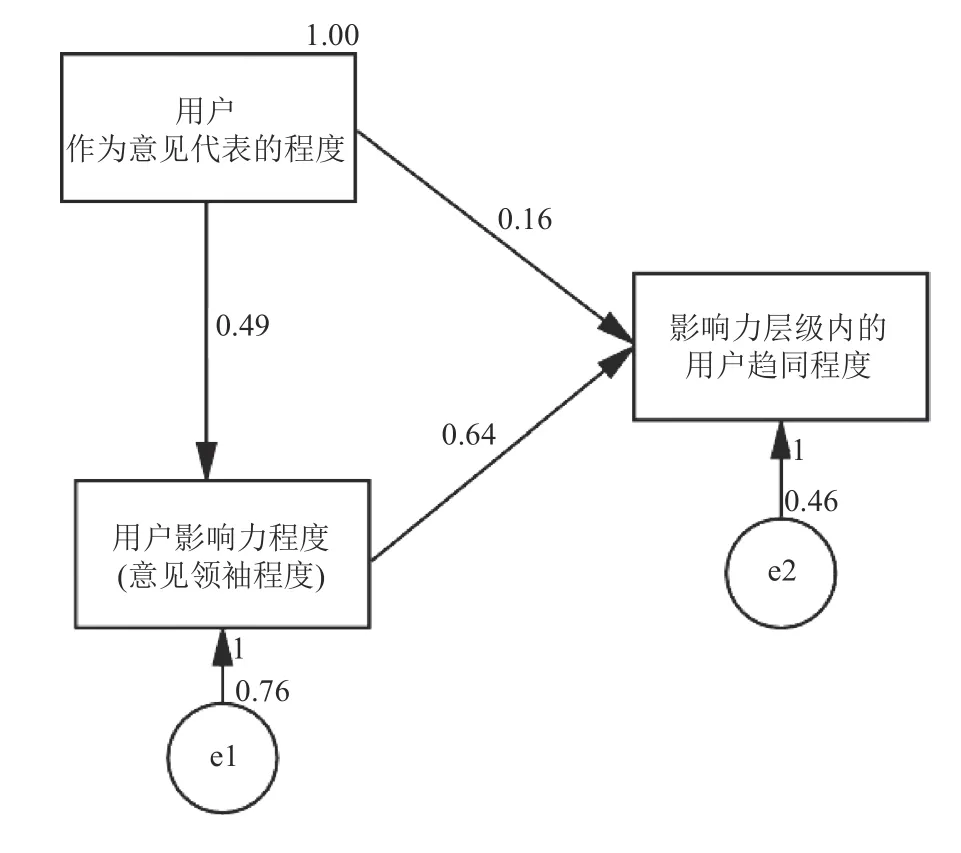
图6 路径分析的标准化回归系数结果
图6所示的模型中,记“用户作为意见代表的程度”为变量Vx,记“用户的影响力程度(意见领袖程度)”为变量Vm,记因变量“影响力层级内的用户趋同程度”为Vy。从Vx到因变量(Vy),各路径均显著。经由Vm的中间作用,这个间接作用路径,通过Amos的Bootstrap进行中介效应的检验,Bootstrap次数设定为1 000次;Vm的中介效应的显著性为0.004,标准化的中介效应是0.317。相比较直接效应(也即Vx作用于Vy)的0.16,中介效应相对值足够大,这也说明意见代表–意见领袖的共同作用,于用户内容阶层形塑的重要性。其中蕴含着,意见代表和意见领袖这两种用户角色的兼容性与内在的联系。同时,也是由于这个中介效应的重要性,使得意见领袖程度作用于因变量(Vy)所显现的“金字塔结构”,构成本模型中的重要组成与内蕴现象。
总体而言,路径分析的结果中,明确了Vx到Vy的直接效应,同时也明确了从Vx经由Vm而对因变量Vy产生的间接效应;H1、H2、H3涉及到的作用与效应具有整体性,整体模型的评估指标优良。
五、结语:从流动走向封闭
本文的主要工作在于以下方面:(1)强调在作为研究热点的意见领袖角色之外,容易被忽视的“意见代表”角色、效应及其重要性;(2)“意见代表”的社会作用不是影响力的扩散,而是影响力的分层,生成“同影响力–同内容”的内容阶层现象,并正相关于这种同影响力层级内的趋同程度,带来微博社会的话语分层和封闭性;(3)对于用户意见代表程度如何作用于影响力层级内聚性的“意见代表–内容阶层”的效应,进行模型的路径分析,支持了意见代表带来的影响力层级内聚性及其增长的金字塔结构,呈现了意见代表对于微博话语层级分化及其结构的社会作用。
微博中“意见代表”的用户角色与功能,使得系统从开放走向封闭、从流动走向凝聚带来了更多可能。微博中不同影响力和话语地位的用户分化为具有特定的、趋同化内容的影响力阶层,消解用户层级内部的异质性、多样性并使之趋于窄化。系统在层级的内聚中,“内容坐标–影响力坐标”的组合并非杂乱和随机,而是具有其对应性的封闭圈层。同影响力层级的用户,由于这种封闭性而形成具有相似内容特征、特定的影响力坐标的内容层级。
在作为主流研究对象的“意见领袖”占据各种研究热点的背景下,“意见代表”的角色、功能由于看起来和实践隔得较远,因而未被足够重视,缺乏相关的明确的“理论自觉”与实证分析支撑。但是,“意见代表”本身所反映的在线社会的“用户间性”,对于“意见领袖”等其他角色发生属性传递而产生的层级内聚,对于微博用户的话语分层与加强社会壁垒的“巴尔干化”,这些是在“意见领袖”等的理论框架下难以涵括的,也是“意见代表”在个体角色之外承载着的更为丰富的系统意义与社会效应。
