基于多源数据融合的行人检测算法
2021-04-09段瑞雪马凯悦张仰森
段瑞雪,马凯悦,张仰森
(1.北京信息科技大学 计算机学院,北京 100101;2.国家经济安全预警工程北京实验室,北京 100044;3.北京信息科技大学 信息管理学院,北京 100192)
0 引言
行人检测(pedestrian detection)是计算机视觉领域内应用比较广泛和比较热门的算法,一般会与行人跟踪、行人重识别等技术进行结合,来对区域内的行人进行检测识别跟踪,广泛应用于安防、零售、无人驾驶等领域。由于行人的外观易受穿着、尺度、遮挡、姿态和视角等影响,目前行人检测仍然面临几大挑战:其一,杂物背景下低分辨率的行人难以检测,并且此种情况下会产生大量难例;其二,拥挤场景下难以精确定位每个行人。
近年来,深度学习技术快速发展,在行人检测方面也取得了较好的结果。Sermanet等[1]利用卷积神经网络模型进行行人检测,Chan等[2]利用自动学习的滤波来修改图像的卷积,提高了准确率。但是基于深度学习的方法其模型泛化能力较差,训练速度慢,而且容易出现过拟合等现象,并不适合于所有的行人检测环境。
本文采用传统HOG+SVM的算法,利用多源数据融合的方法,在样本处理、难例选择等方面对算法进行改进,设计了行人检测的各个模块,并进行了可视化,实现了在Caltech各个seq数据集和INRIA正负测试集之间的检测切换,改善了模型难以在Caltech上进行评测的问题。
1 国内外研究现状
目前有许多种行人检测的方法,其主流是基于统计的方法和深度学习的方法。基于统计的方法主要包括两个步骤:提取特征和分类。首先需要对原始图像进行处理,去除噪声并提取最符合人类属性的特征用于模型训练,然后在分类器中进行分类。常用的特征有HOG、LBP、CSS等。其中HOG是行人检测中应用最广泛的一种特征,主要描述图像局部纹理,能够较好地描述行人的边缘信息。Zhu等[3]针对HOG特征计算慢的缺点,提出了使用积分直方图加速计算的方法来提高检测的速度。Wang等[4]提出了将HOG和LBP特征结合的方式,并采用SVM分类器处理行人部分遮挡的问题。Costea等[5]通过从原始图片提取HOG、LBP和颜色特征进一步提高了检测的速度。基于统计的方法一般是通过学习正样本和负样本的变化、大量训练样本来构建行人检测分类器。
近年来,基于深度学习的目标检测方法不断涌现。RFBnet[6]提出了RFB卷积块的方法并集成到SSD[7]网络中以增加卷积网络的感受野。ExtremNet[8]提出了一种无锚框自底向上的方法来检测网络。M2Det[9]使用主干网的两层特征融合输入到多个级联的TUM模块中提取多尺度检测特征。
2 行人检测算法
HOG特征是在图像的局部区域上进行操作,因此其在图像几何和光学上具有一定的鲁棒性,这样保证了行人只需保持大体的站立姿势即可检测,当其有一些细微动作时不会影响检测效果。
模型采用的SVM+HOG方法是速度和效果平衡较好的一种检测方法,提取HOG特征以后,可利用分类器对样本进行训练分类。常用的分类器有SVM[10]、HIKSVM[11]和Adaboost[12]等,其中SVM是行人检测中最常用的分类器。
HOG+SVM进行行人检测的算法主要步骤如下:
1) 输入图像并对图像进行预处理;
2) 选择窗口。一般使用滑动窗口法;
3) 对每个窗口提取HOG特征;
4) 将提取到的特征送入已训练好的SVM分类器中进行分类,确定图像中是否包含行人。
HOG+SVM是一种经典的行人检测方法,OpenCV中可以直接调用,采用线性核的方式。
3 多源数据融合
Caltech数据集是目前规模较大的行人数据集,采用车载摄像头拍摄,约10 h,视频的分辨率为640×480,30帧/s。标注了约250 000帧(约137 min),350 000个矩形框,2 300个行人,另外还对矩形框之间的时间对应关系及其遮挡的情况进行了标注。
INRIA数据集是行人检测中最老的数据集,其训练集和测试集均为图片。负样本包含各种不同地理环境,正样本约2 400多张。实验使用的INRIA数据集的正样本已处理为96×160大小。
为实现行人检测和目标追踪,选择连续的视频集作为最终测试集。Caltech不仅数据量大,视频也最接近实际生活的街道场景,标注还包含完全被遮挡的人。因此选择Caltech数据集作为最终测试集。在HOG+SVM算法的基础上,为在Caltech数据集中取得能评测的行人检测效果并实现简单的目标追踪,本研究分别在训练集类型(Caltech/INRIA)、获取正负样本方法、训练参数P、难例迭代次数和测试参数w的不断调整上进行实验,以得到最优的数据融合方法。
4 实验
4.1 数据集介绍
Caltech、INRIA是行人检测领域最常用的两个数据集,符合本文方法的实验要求。
4.2 评测方法
本文采用2个评测指标,F1值和平均每张图片的检测时间RT,其中后者又称为满意指标。在满足满意指标的约束下,寻找最优的F1值。
4.3 实验过程
行人检测至少需要3步:处理数据集为正负样本;训练正负样本得到分类器;根据获得的分类器进行测试。为了得到最优的模型,本文采用改变正负样本的比例、设置是否获取难例,以及改变训练集等方法完成6组实验,不断提高行人检测的效果。
在模型训练输入阶段,采用两种方法:
方法1在计算图片特征值时,采用原图作为输入,直接将样本的特征值放入类别矩阵中,并将样本在样本数组中的位置放入样本标签矩阵中。
方法2在计算图像特征值时,采用灰度图作为输入,在描述子转化后的矩阵的行或列数为1时,将特征放入类别矩阵并对应样本标签。
4.3.1 实验1
模型训练输入采用方法1,使用不同训练集类型(Caltech训练集、INRIA训练集),Caltech数据集正负样本大小分别选取48×96、96×160,正负样本比为1∶1或2∶1,分别在Caltech、INRIA上测试,结论是无论改变训练集类型、正负样本大小、正负样本比、样本处理方法,都无法使得模型正常检测,虚警都非常多,而且只能指出人的大致位置。
通过实验1得到结论,以Caltech为训练集时,在INRIA 及Caltech上不能达到可以评测的效果。虽然一般情况下使用数据集本身的训练集训练效果更好,但在Caltech上使用HOG+SVM时并没有体现这点。相同的方法使用Caltech训练不如使用INRIA。
4.3.2 实验2、3、4
根据实验1的结论,设计表1所示的实验2、实验3、实验4,模型训练输入采用方法2,并采用INRIA为训练集,测试集为Caltech。

表1 实验2、3、4的设置
图1所示为实验2测试集的几个结果,从图中可以看出虚警的数量和实验1相比大幅减少,对人的识别虽然还有些遗漏,但是基本能够正确地框出人的位置。

图1 实验2在INRIA正样本测试集上不同图片的结果
表1中实验2和实验3使用相同的训练集和测试集,实验3中每个负样本的数量是实验2的5倍,从图2(a)(b)(c)实例可以看出通过增加负样本的数量,虚警数量得到了进一步的降低,行为位置的识别效果也有提高,但是从图2(d)(e)实例可以看出还是存在一些虚警现象。
表1中实验4和实验2、实验3使用相同的训练集和测试集,不同的是实验4中增加了难例。从图3实例可以看出,通过增加难例的样本,虚警数量得到了进一步的降低。

图2 实验3在INRIA测试集上不同图片的结果

图3 实验4在INRIA测试集上不同图片的结果
4.3.3 实验5
实验5的训练集和测试集都选用Caltech,不加入难例的情况下,大多数情况只在中间框一个框,并不能实现行人的检测。
4.3.4 实验6
实验6采用INRIA为训练集,样本大小为96×160,Caltech为测试集,正负样本比为2 416∶9120。为了增加负样本的数量,从每张负样本原图中抽取出10个负样本,采用加入难例的方式训练模型。结果如图4所示,虚警的数量大幅下降,可以实现行人位置的检测。

图4 实验6 的行人检测实例
4.4 实验结论
通过以上6组实验和行人检测效果图可以看出,以INRIA为训练集、Caltech为开发集、除开发集外的任意Caltech的seq为测试集的模型的检测速度和识别效果都比较好,可以得出以下结论:
1) 不同的正负样本类型及处理方法、训练方法以及检测算法是检测效果好坏的决定因素。
2) 增加负样本的数量可以提高识别的效果,减少虚警的情况。(实验3证明)
3) 加入难例可以有效减少虚警(从编号2~4的实验得出结论)。
4) 利用INRIA为训练集、Caltech为开发集和测试集可以取得更好的效果。
5 行人检测评测结果和错误分析
5.1 实验开发集的变更
通过以上的介绍和实验,采用多数据融合的方式,训练语料选取INRIA,Caltech为开发集,Caltech 为测试集。
5.2 评测待调参数
实验需要调的参数有:正负样本比、训练参数P(SVM类型为EPR时表示训练集中的特征向量和拟合出来的超平面的距离要小于P)、难例获取次数以及使用SVM中的参数w。
5.3 评测结果
初始正负样本比取2 416∶1 824;训练参数P分别选取0.1、0.2、0.3;难例获取次数取0或1,a=0表示不添加难例,a=1表示获取1次难例;测试参数w取0.1~0.5。
由图5可以看出当P= 0.2、加入1次难例、w=0.2时有最大F1值0.231,此时RT为893.428 ms。从图5可以看出,加入难例可以有效地提高系统的性能。
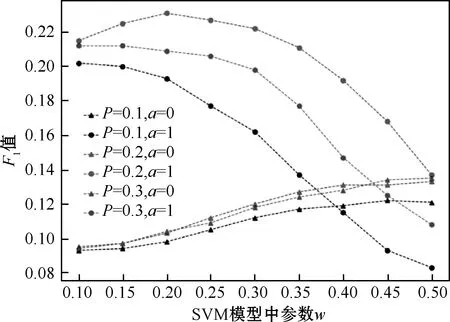
图5 最优化F1值
图6显示的是另一个指标RT。从图中可以看出,加入难例以后每张照片的检测时间RT要明显低于不加入难例的情况。
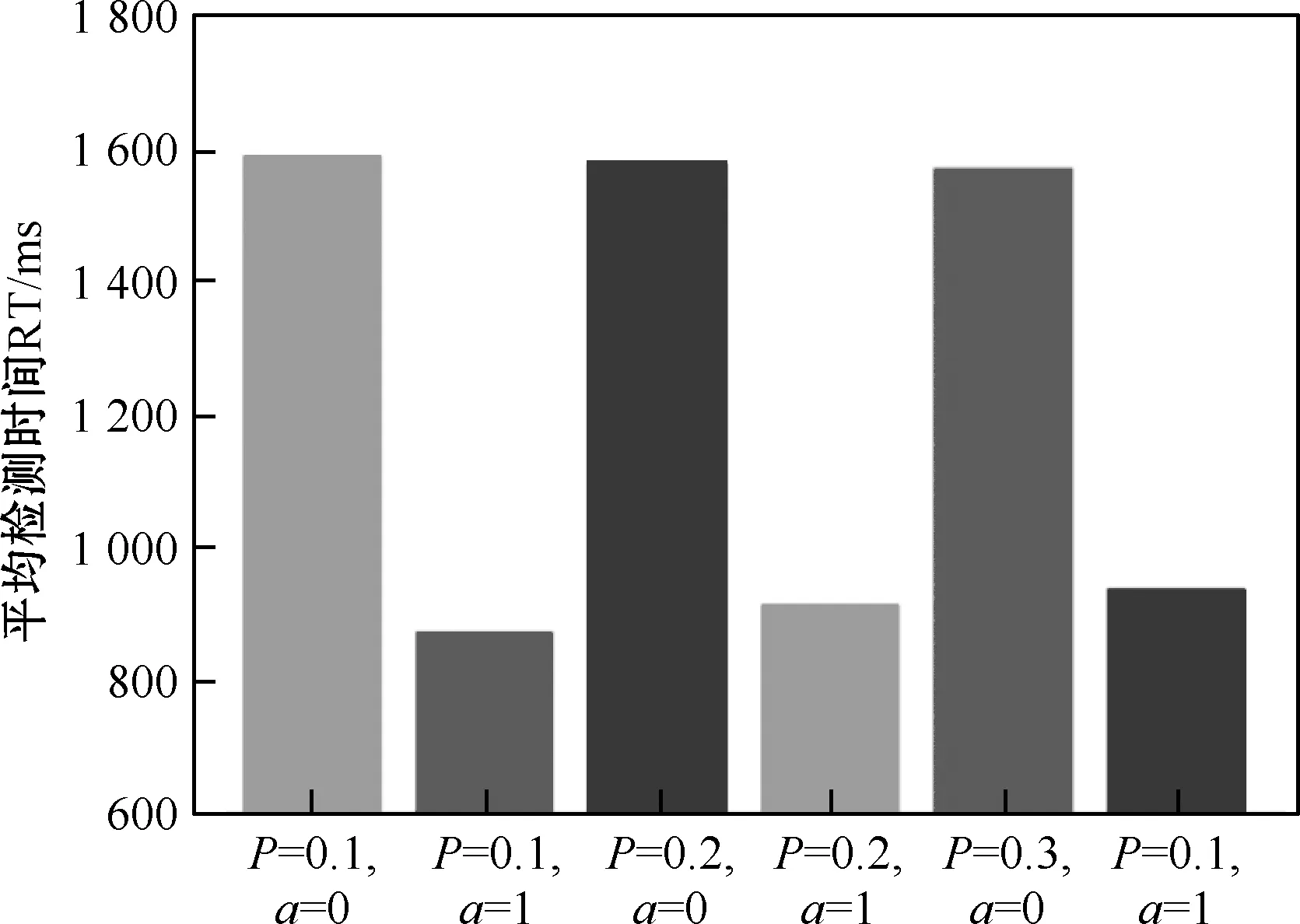
图6 每张图片的检测时间
通过观察评测的可视化结果发现Caltech漏检的有很多小尺度的行人。为验证这一猜想,分别去除边框尺度高度<55时的标注。图7显示的是分别去除边框尺度高度<10到高度<55的标注框时F1值的变化。从图中可以看出,去除小尺度标签可以有效地提高F1值,当F1值取最大时,w从0.2变为0.3。针对FN(false negative,漏检):对于约占一半的小尺度行人,需要利用小尺度特别的方法进行检测,后续工作会针对小尺度检测进行研究。

图7 小尺度猜想F1值
6 结束语
本文使用HOG+SVM算法,针对Caltech和INRIA数据集,为得到能在贴合实际生活场景的Caltech数据集上评测的模型,在训练集类型、正负样本获取方法、训练方法、加入难例次数、测试方法上采用了一系列的方法演进,得到模型的大致处理方法,以及一些普适性和特殊性的结论。通过评测找到满足RT的最大F1值,并在对模型进行错误分析后,提出了小尺度行人和虚警的处理方法。
