基于相关性分析的指挥信息系统模拟数据集可用性评估算法
2021-04-08田相轩李军旗金丽亚刘正仁石志强
田相轩, 李军旗, 金丽亚, 刘正仁, 石志强
(1.陆军装甲兵学院 信息通信系, 北京 100072;2.陆军装甲兵学院 科研学术处, 北京 100072)
0 引言
信息技术的迅速发展,催生了大数据时代的到来,随着我军部队由信息化向智能化、单一兵种向合成化发展转变,基于大数据的模拟训练是实现战斗力生成的重要手段[1-3]。依托模拟训练系统开展指挥信息系统训练,需要数据增强系统生成数据支撑和驱动模拟训练,但是目前对于模拟数据集的可用性评估研究较少,无法鉴定模拟数据集在一致性、完整性、同一性上与真实数据集的差距。由于模拟数据质量不一,使得官兵在模拟训练过程中效率较低,能力提升速度较慢,降低了大规模投资的模拟训练系统的使用效能[4-6]。
在民用领域,大数据已经成为信息社会的重要财富,各种技术形式都由“人为建模”向“数据驱动”转变,然而随着数据规模的扩大,劣质数据也随之而来,极大地降低了大数据的可用性[7-8]。数据可用性评估问题亟需解决[9-10]。目前,对于可用性的研究多是基于一致性进行判断, Huang等基于统计原理提出了数据一致性错误的表示模型,描述了表示数据不一致性的方式,并且提出了一种数据一致性的增强算法[11];对于数据一致性的判定方法,Ma等提出了一种用于描述数据完整性的规则系统[12];对于数据同一性的判定法,Li等研究了基于识别结果的实体同一性的判定[13];Zhang等使用均方误差(MSE)作为衡量参数,提出了一种多模态数据集合的模型[14];聂凯等采用假设检验方法中的F检验方法检验静态数据,采用灰色关联分析方法分析动态数据[15];Traganitis等提出将随机抽样和一致性参数扩展到特征降维问题,对模型估计采用试错的方法,使用其余数据来验证估计的模型,从而产生高精度的聚类,并采用可视化分析的方式进行展示[16]。
上述研究成果都是基于数据集固有的某一属性出发描述数据的可用性,不能全面地反映数据内部的关联关系,表征数据的可用性。尤其针对指挥信息系统数据,敏感于数据之间的相关关系,不仅需要反映内在的线性关系,还应体现非线性与复杂的多维数据之间的嵌套关系。本文采用特征选择的思路提取出数据集各属性的特征信息,目的不在于筛选有用的特征,而在于构建数据集完整的可用性信息张量。
目前对于特征选择主要区分为依赖分类器与独立于分类器两类。包装法和表示法依赖分类器,其中:包装法使用预先确定的分类器来评估候选特征子集,具有更高的预测精度,但是一些启发式算法过度依赖超参数,计算量大,而且分类器过于具体,导致计算误差的风险也很高[17-18];表示法将特征选择集成到给定学习算法的训练过程中,计算成本较低,但需要严格的模型结构假设[19];滤过法不依赖分类器,依据特征与标签的相关性进行特征排序,基于信息论相关理论,理论基础扎实,且滤过法在特征降维方面优势明显[20-21]。
本文基于信息论的基本理论知识,采用滤过法,提出了基于相关性分析的指挥信息系统模拟数据集可用性评估算法(CA-UEA)。从特征的相关性定义出发,在描述各属性之间的相关、冗余性基础上,重点描述了属性之间的交互性,提出了交互信息和冗余信息计算的近似公式,设计了表征数据集可用性信息的张量形式,分别构建数据集的基本信息矩阵、冗余度张量、交互度张量。通过爱因斯坦求和约束构建数据集的相关关系张量,描述数据集各属性的特征相关关系与非线性关系。基于深度学习中损失函数的求解思想计算生成数据集与原始数据集可用性张量之间的误差距离,从而评估生成数据集的可用性,为数据生成算法提供鉴定依据,为全元素的指挥信息系统模拟训练提供可用的数据支撑。
1 基本原理
信息论中提出信息是用来消除随机不确定性的东西,并定义信息熵为离散随机事件发生的不确定性,是系统有序化程度的度量,有序的系统熵值较低,无序的系统熵值较高。下面描述信息熵、互信息、条件熵、联合熵、条件互信息的基本概念[20]。
1.1 信息熵
假设:存在随机变量X,在实数空间上的取值空间为{x1,x2,x3,…,xn},概率分布为P(X=xi)=pi(i=1,2,3,…,n),则随机变量X的信息熵定义为

(1)
1.2 条件熵
假设:随机变量X已知,随机变量Y发生的不确定性为Y在X已知条件下的条件熵,定义为

(2)
1.3 互信息
假设:存在两个随机变量X、Y,在已知某变量的前提下,另一个变量发生的不确定度减少的程度称为互信息,定义为

(3)
1.4 联合熵
假设:存在两个随机变量X、Y,X在实数上的取值空间为{x1,x2,x3,…,xn},概率分布为P(X=xi)=pi(i=1,2,3,…,n),Y在实数上的取值空间为{y1,y2,y3,…,yn},概率分布为P(Y=yi)=pi,则随机变量X、Y的联合熵定义为

(4)
1.5 条件互信息
假设:已知随机变量Z,随机变量X、Y的条件互信息,表示为在Z已知前提下,X、Y共享的信息量,即变量Y带来的关于变量X但不包含于Z的信息,定义为
I(X;Y|Z)=H(X|Z)-H(X|Y,Z).
(5)
2 CA-UEA算法
2.1 评价标准定义
在数据集特征选取过程中,通过度量一个属性或属性集在分类器中的筛选能力,来评估其潜在的可用性。本文采用各个属性的特征信息集合来反向描述数据集的可用性信息,提取数据集的内部抽象特征,构建数据集的可用性信息张量。在数据集内部的相关关系中,强相关性、不相关性是属性间的显性特征,易于计算,分别定义为
I(fi;fj)=1,fi,fj∈F;
(6)
I(fi;fj)=0,fi,fj∈F.
(7)
式中:fi、fj为数据集中的某属性值;F为已知的属性集合;i,j∈(0,m),m为总属性数量。强相关性、不相关性可以描述为弱相关性的特殊形态,在分析数据分布一致性时,应针对弱相关性出发,重点研究影响弱相关性的微观特征。
信息熵能够量化随机变量的不确定性和不同随机变量共享的信息量,旨在衡量一个特征或特征子集在分类器中使用时的潜在可用性,而在数据集属性描述中,重点关注的是各个属性的特殊信息,用来描述和全面地反映出数据集的整体特性。弱相关性包括属性之间的交互性、冗余性、互信息,对于特征选取,需要加权综合考虑属性的权重,从而构建数据集的特征。本文借鉴特征选取的思想,但区别于最大相关最小冗余算法[21]模糊估计各个属性特征信息的方式,目的不在于提取特征,而在于通过构建数据分布弱相关性张量,关注每个属性各方面的信息,从而提取出全部有用信息,完整描述数据集的分布。
下面结合信息论的基本技术,基于信息熵、条件熵、互信息、条件互信息等相关概念,给出属性描述特征的标准。
定义1互信息(基本信息),是指两两属性之间的互信息,即其中一个属性变化对另一个属性变化的影响程度。属性fi与另一属性ft之间基本信息定义为
Ib(fi;ft)=H(fi)-H(fi|ft),ft,fi∈F,
(8)
式中:i,t∈(0,m);H(fi)为属性fi的信息熵;H(fi|ft)为在属性ft已知条件下fi的条件熵,即属性ft已知情况下fi降低的不确定度。
H(ft,fi)=H(fi|ft)+H(ft),
(9)
H(fi|ft)=H(ft,fi)-H(ft),
(10)
Ib(fi;ft)=H(fi)+H(ft)-H(ft,fi).
(11)
为全面描述数据集任意两个属性之间的基本信息,本文没有采用统计方式获取均值或方差值来表示数据集的基本信息,而是采用矩阵方式进行描述,关注到任意两个属性之间的基本信息值,构建数据集的基本信息矩阵:
(12)
式中:nd为数据集的维度,大小为[nd,nd]。
定义2冗余度,是指任3个属性之间的重复度,即fi;ft互信息与fi;fj互信息的重复量:
Ir(fj;ft;fi)=I(fj,ft;fi)-I(fi;ft)-I(fi;fj),
Ir(fj;ft;fi)=H(fj,ft)-H(fj,ft|fi)-
(H(fi)-H(fi|ft))(H(fi)-H(fi|fj)).
(13)
构建数据集的冗余度矩阵,构建的冗余度张量形状为[nd,nd,nd],类似于多维数组,冗余度矩阵深度为3的矩阵:
(14)
定义3交互度,存在已知属性集合S,若属性fi∉S,与属性集合存在相关关系。随着另外一个属性ft∉S的加入,fi与S的相关性发生变化(变大或变小),即称fi与ft之间存在交互,交互度定义为
Ii(fi;ft)=Ir(fi;S)-Ir(fi;S|ft),
(15)
式中:Ir(fi;S)为fi与S的互信息,即相关关系;Ir(fi;S|ft)为ft加入后,fi与S的相关关系。S为除了fi、ft之外的属性值集合,采用矩阵方式进行计算,即S可以为属性集合剩余属性的任一属性影响,或几个属性的联合影响,因为联合属性影响是在单属性基础上的叠加,相对来说值较小。为降低计算复杂度,计算任一属性已知情况下fi、ft的交互度,可得Ii(fi;ft)的近似值:
Ii(fi;ft)≈I(fi;fj)-I(fi;fj|ft),
(16)
则fi、ft、fj三者的交互度为
Ii(fi;ft;fj)=
H(fi)+H(fj)-H(fj,fi)-(H(fi,ft)+
H(fj,ft)-H(ft)-H(fi,fj,ft)).
(17)

图1 算法流程Fig.1 Algorithm flowchart
针对fi、ft与fj为除了fi之外的任一属性值,构建的交互度张量大小为[nd,nd,nd],交互度矩阵:
(18)
2.2 算法步骤
算法流程如图1所示。
步骤1梳理数据格式,将原始数据集与生成数据集转换为相同格式,进行数据缺失值、异常值、噪音处理,即将重复、多余的数据筛选清除,将缺失的数据补充完整,将错误的数据纠正或者删除。
步骤2根据(1)式~(18)式,构建原始数据集与生成数据集的基本信息矩阵、冗余度张量、交互度张量。
步骤3基于爱因斯坦求和约束[22],即在张量的基底改变情况下,其中:某个向量的线性变换基于矩阵进行表示,以上标来标记;剩余向量的线性变换通过逆矩阵来描述,以下标来标记,保证伴随余向量的线性函数不变。将冗余度张量、交互度张量的维度转换为基本信息矩阵的维度,便于下一步信息整合,即将变量维度由[nd×nd,nd,nd]转换为[nd,nd]。
步骤4对基本信息矩阵、冗余度矩阵、交互度矩阵3个变量采用softmax函数进行归一化处理:
(19)
式中:softmax函数是将模型的预测结果转化到指数函数上,将转化后的结果除以所有转化后结果之和,可以理解为转化后结果占总数的百分比,可将结果转换到[0,1]之间,便于进行数据分析[23]。
步骤5基于爱因斯坦求和约束,将归一化处理的3个矩阵变量进行信息融合,即将变量维度由[3,nd,nd]转换为[nd,nd],得到原始数据集与生成数据集的可用性信息矩阵。
步骤6基于MSE[24],求取原始数据集与生成数据集可用性信息矩阵的欧几里得距离,表征生成数据集的可用性评估值。
CA-UEA算法的伪代码:
INPUT:生成与原始数据集特征集合
OUTPUT:生成与原始数据可用性估值
1. fori=1 tonddo
2. forj=1 tonddo
3. 计算基本信息矩阵Mb
4. fort=1 tonddo
5. 计算冗余度矩阵Mr
6. 计算交互度矩阵Mi
7. end for
8. end for
9. end for
获得更新后的Mn_b,Mn_r,Mn_i
10.Mn_b=softmax(Mb)
11.Mn_r=softmax(Einsum(Mr)<[k*k,k,k],[k,k]>)
12.Mn_i=softmax(Einsum(Mi)<[k*k,k,k],[k,k]>)
13. 分别计算原始与生成数据集的融合特征评价信息:
14. Ge_data=Einsum(Mn_b,Mn_r,Mn_i)
15. Or_data=Einsum(Mn_b,Mn_r,Mn_i)
16. CA-UEA=MSE(Gedata,Or_data)。
算法分别计算生成数据与原始数据的基本信息、冗余度信息、交互度信息等可用性特征信息,分别融合特征状态信息,基于MSE量化评估生成数据的可用性。
本文算法输入特征值数量为N,考虑多维度的特征信息之间的关联关系,分别考虑特征与特征之间的基本信息,特征与其余特征集合之间的交互信息和冗余信息,其算法的计算复杂度为O(N3)。当特征较多时,建议抽取部分显性特征信息进行计算,降低算法复杂度。
3 CA-UEA算法仿真实验
3.1 仿真准备
1)实验环境:利用实验室仿真环境,采用Python3,Anaconda环境下,配合PyCharm,使用TensorFlow框架,搭建基础实验环境。
2)原始数据:实验1与实验2使用的是MINIST手写数据集[25],数据维度为[6 000,28,28];实验3使用的是指挥信息系统模拟训练数据,来源于前期训练收集积累的历史数据,经过脱密处理后,为22维,共计200条数据,通过补0方式,将数据集拓展到28维,与MINIST手写数据集维度相同,为[200,28]。
3)在模拟训练过程中一手数据资源较少,需要数据增强技术对数据进行扩增,作者之前的研究中发现采用生成对抗网络能够较好地扩增数据,但是在量化评判生成数据与原始数据的真实度差异上还需要作进一步工作。
为验证本文提出的可用性检验标准与量化评定差异:实验1采用生成对抗网络(GAN)作为数据生成框架[26],扩增的数据为MINIST手写数据集;实验2采用的是辅助分类条件生成对抗网络(ACGAN)作为数据生成框架[27],扩增的数据为MINIST手写数据集;实验3选择GAN作为数据生成框架,扩增的数据为指挥信息系统模拟训练数据。
3.2 仿真实验
3.2.1 GAN扩增MINIST数据的仿真实验
按照文献[26]的方法,搭建GAN,以MINIST手写数据集的图片作为原始数据,生成模拟数据,经过10k轮后,得到图2所示的损失函数曲线。由图2可得,随着迭代次数的增加,判别模型的数据来源不仅是原始数据还包含生成模型产生的数据后,判别模型损失函数值出现上下浮动,随之生成模型的损失函数呈相反的方向变化,即判别模型与生成模型相互对抗,相互博弈,但从整个过程中系统损失函数总值=GAN生成模型损失函数值+GAN判别模型损失函数值可看到,出现小幅上下震荡,整个迭代过程,相对平稳,即系统沿着生成的图片被判别为真的优化方向前进。

图2 GAN损失函数曲线Fig.2 Loss function curves of GAN
实验迭代过程中,设计每间隔625次系统生成一次实验数据,共计生成16张实验图片,其中:第1张图片为原始图片(见图3);每张图片维度为[28,112],按照前后顺序排列为如图3所示。由图3可得,生成图片由开始的噪音数据图像,逐渐显现图片边缘数据,有一定向好的趋势。

图3 GAN生成的图片Fig.3 Pictures generated by GAN
针对实验过程中产生的过程图片,按照本文第2节的计算方法,对每张图片的真实度损失值进行求解,可得图4所示。由图4可知,GAN生成数据集真实度损失值随着生成器与判别器的对抗上下浮动,但是与原始数据集的差距变化不大,即GAN系统生成的数据集质量与原始数据集相比仍有一定差距,需要进一步训练,获取可用的数据集。

图4 GAN生成的数据集真实度损失曲线Fig.4 Dataset similarity loss line generated by GAN
3.2.2 ACGAN扩增MINIST数据的仿真实验
按照文献[27]的方法,构建ACGAN,该网络采用半监督的条件生成对抗网络,使判别器与分类器重建标签信息。使用标签信息进行训练,不仅能产生特定标签的数据,还能够提高生成数据的质量。实验MINIST手写数据集的图片作为原始数据,生成模拟数据,经过10k轮后,得到图4所示的损失函数曲线。由图4可得:ACGAN在开始阶段有小幅震荡,但是很快就达到了“纳什平衡”;当缩小y轴坐标范围,也可发现判别器与生成器的对抗过程(为与图2比较,选择了与图2相同的y轴坐标范围),可见ACGAN的优化速度明显优于GAN.

图5 ACGAN损失函数曲线Fig.5 Loss function curve of ACGAN
采用实验1相同的设计思路,共迭代10k轮,每间隔625轮获取一次实验数据集,共计16张图片,其中第1张为原始图片,如图6所示。由图6可得,随着迭代次数的增加,生成器不仅捕捉到数字的边缘信息,从第9张图片可清晰辨析数字的形状,直至最后完全确定数字,收敛速度较快,数据生成的质量较高。

图6 ACGAN生成的图片Fig.6 Pictures generated by ACGAN
针对实验过程中产生的过程图片,按照本文第2节的计算方法,对每张图片的真实度损失值进行了求解,可得图7所示。由图7可知,随着ACGAN优化水平的不断提高,生成数据集的真实度损失值逐渐降低,在下降过程中由于生成器与判别器的对抗,仍有上下浮动,但是从总体上看,数据集的可用性逐渐提高,印证了图6中生成的图片与原始图片的差异越来越小,并对差异降低的程度进行了量化,为工程化的数据生成提供了量化鉴定依据。

图7 ACGAN生成的数据集真实度损失曲线Fig.7 Dataset similarity loss line generated by ACGAN
为进一步分析数据真实度损失曲线的影响因素,针对数据集的基本信息、冗余信息、交互信息分别进行了画图,如图8、图9、图10所示。由图8、图9、图10可得,选取以上任意一个变量描述生成数据集的可用性都不完整,借鉴深度学习的思想,通过更高维度数据的拟合,实现数据的综合描述,使得第2节中的数据集可用性描述算法的有用信息更加全面,描述数据集可用性更加合理准确。

图8 ACGAN生成的数据集基本信息真实度损失曲线Fig.8 The generated dataset basic information similarity loss line generated by ACGAN
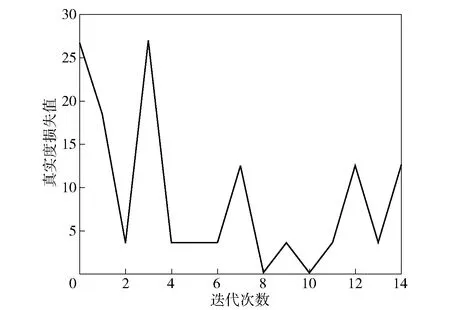
图9 ACGAN生成的数据冗余信息集真实度损失曲线Fig.9 Dataset redundant information similarity loss line generated by ACGAN

图10 ACGAN生成数据交互信息集真实度损失曲线Fig.10 Dataset interaction information similarity loss line generated by ACGAN
3.2.3 GAN扩增指挥信息系统数据的仿真实验
基于信息系统下的体系作战,强调得不再是某一兵种的强大,而是在体系下,系统的劣势和优势;各指标之间不再是相互独立,而是相互关联,呈现出多种关系,既有线性关系也有非线性关系。各指标之间关联关系的确定和发现,是评定生成数据集可用性的重要依据,借鉴实验1构建图片的思路,基于指挥信息系统指标特征的关键信息,分析各特征之间的相关关系,经过多次训练后发现关键信息,描述指挥信息系统生成数据的可用性,对生成数据的可用性进行量化表示。
按照文献[27]的方法,搭建GAN,以指挥信息系统模拟数据集作为原始数据,扩增数据,用GAN_C来表示。由于数据格式不同,将GAN中卷积层替换为全连接神经网络,判别器与生成器的层数分别为(22,128,512,128,10,1), (100, 256, 512, 256, 22),经过10k轮后,得到图11所示的损失函数曲线。由图11可得,GAN并没有到达“纳什均衡”,判别器与生成器的损失曲线没有达到平衡,还处于激烈的对抗中。

图11 GAN_C损失函数曲线Fig.11 Loss function curve of GAN_C
采用实验1相同的设计思路,共迭代10k轮,每间隔625轮获取一次实验数据集。数据集维度为[28,112],第1张图片为原始数据集,共计构建16张数据图片,如图12所示。从图12可得,随着迭代次数的增加,数据的密集度逐渐增加(图片显示中0为白色,数字值越接近255、颜色的饱和度越高),但是生成数据集的质量无法进行确定。

图12 GAN_C生成的图片Fig.12 Pictures generated by GAN_C
针对实验过程中产的模拟数据集,按照本文第2节的计算方法,对每个数据集的真实度损失值进行了求解,可得图13所示。由图13可得:随着迭代次数的增加,系统能够初步获取数据集的内部结构特征,能够在某些轮次的训练上获得与原始数据集接近的数据;但是生成的指挥数据的真实度损失值得变化幅度较大,GAN没有达到均衡,生成器与判别器对抗激烈,远离与接近原始数据集的概率几乎持平,需要持续提高优化水平,提高收敛速度;但也可由图13得到,生成模拟数据集与原始数据集真实度的差异程度,算法对目前生成的数据集可用性能够进行初步的鉴定分析,为模拟训练数据集的评估提供分析基础。

图13 GAN_C生成的数据集真实度损失曲线Fig.13 Dataset similarity loss line generated by GAN_C
4 结论
本文针对指挥信息系统模拟数据集质量不稳定,无法进行定量评估的问题,以数据集内部结构关系为基础,基于信息论的基础理论知识,提出了基于相关性分析的指挥信息系统模拟数据集可用性评估算法。得到主要结论如下:
1)在描述各属性之间的相关、冗余性基础上,重点描述了属性之间的交互性,提出了交互信息和冗余信息计算的近似公式。
2)分别构建数据集的基本信息矩阵、冗余度张量、交互度张量,基于爱因斯坦求和约束构建数据集的可用性张量,描述数据集各属性的相关关系与非线性关系;根据深度学习中损失函数的求解思想,计算生成数据集与原始数据集可用性张量之间的误差距离,从而评估生成数据集的可用性。
3)基于GAN、ACGAN的网络架构构建数据增强系统,以MINIST手写数据与指挥信息系统的模拟数据为原始数据分别进行数据扩增,通过本文提出的数据可用性评估算法进行定量计算,仿真结果表明算法能够很好地评价数据集的可用性情况,为数据生成算法提供鉴定依据,为全元素的指挥信息系统模拟训练提供可用的数据支撑。
参考文献(References)
[1] LI X, HUANG H Z, LI X Y,et al. Reliability evaluation for the C4ISR communication system via propagation model[C]∥Proceedings of 2019 Annual Reliability and Maintainability Symposium. Orlando, FL, US: IEEE, 2019.
[2] OUYANG S J, DAI Z J, YAN C X,et al. Operational effectiveness evaluation of maritime C4ISR system based on system dyna-mics[C]∥Proceedings of the 37th Chinese Control Conference. Wuhan, China: IEEE, 2018: 8583-8588.
[3] JIAO Z, YAO P. Capability construction of C4ISR based on AI planning[J]. IEEE Access, 2019, 7: 31997-32008.
[4] XIAO B, LUO P C, CHENG Z J, et al. Systematic combat effectiveness evaluation model based on xg-boost[C]∥Proceedings of International Conference on Reliability Maintainability and Safety. Shanghai, China: IEEE, 2018: 130-134.
[5] HILL R, TOLK A. Open challenges in building combat simulation systems to support test, analysis and training[C]∥Proceedings of 2018 Winter Simulation Conference. Gothenburg, Sweden: IEEE, 2018: 3730-3741.
[6] NIU H, SONG Y, WANG R, et al. Research on integrated simulation training system for warship communication[C]∥Proceedings of International Conference on Smart Grid and Electrical Automation. Changsha, China: IEEE, 2017: 533-537.
[7] KAYA A, OZTURK R, GUMUSSOY C. Usability measurement of mobile applications with system usability scale[C]∥Proceedings of Industrial Engineering in the Big Data Era. Nevsehir, Turkey: Springer, 2019:345-358.
[8] JEON B J, Kim H W. An exploratory study on the sharing and application of public open big data[J]. Information Policy, 2017, 24(3): 27-41.
[9] MIN M. Modeling and implementation of public open data in NoSQL database[J]. International Journal of Internet, Broadcasting and Communication, 2018, 10(3):51-58.
[10] MIN M. A data design for increasing the usability of subway public data[J]. International Journal of Internet, Broadcasting and Communication, 2019, 11(4):18-25.
[11] HUANG M, LI L L, XUAN P. Evaluating data consistency with matching dependencies from multiple sources[C]∥Proceedings of International Conference on Power Data Science. Taizhou, China: IEEE, 2019: 6-10.
[12] MA S, FAN W F, BRAVO L.Extending inclusion dependencies with conditions [J]. Theoretical Computer Science, 2014, 515(1): 64-95.
[13] LI L L, LI J Z, GAO H.Evaluating entity-description conflict on duplicated data [J]. Journal of Combinatorial Optimization, 2016, 31(2): 918-941.
[14] ZHANG Y, WANG H Z, GAO H. Efficient accuracy evaluation for multi-modal sensed data[J]. Journal of Combinatorial Optimization, 2016,32(4):1068-1088.
[15] 聂凯, 栾瑞鹏. 基于数据增强的仿真模型验证方法[J].指挥控制与仿真, 2019, 41(3): 92-96.
NIE K, LUAN R P. Validation method of simulation models based on data augmentation [J]. Command Control & Simulation, 2019, 41(3): 92-96.(in Chinese)
[16] TRAGANITIS P, SLAVAKIS K. Big data clustering via random sketching and validation[C]∥Proceedings of Asilomar Conference on Signals Systems and Computers. Pacific Grove, CA, US: IEEE, 2014: 1046-1050.
[17] PACKIANATHER M, KAPOOR B. A wrapper-based feature selection approach using bees algorithm for a wood defect classification system[C]∥Proceedings of System of Systems Engineering Conference. San Antonio, TX, US: IEEE, 2015: 498-503.
[18] LI J X, RAJAN D, YANG J. Local feature embedding for supervised image classification[C]∥Proceedings of IEEE International Conference on Image Processing. Quebec City, QC, Canada: IEEE, 2015: 1300-1304.
[19] LU M T, YIN J F. A feature metric algorithm combining the wasserstein distance and mutual information[C]∥Proceedings of IEEE International Conference on Progress in Informatics and Computing. Suzhou, China: IEEE, 2018: 154-157.
[20] HOSSAIN M A, PICKERING M. Unsupervised feature extraction based on a mutual information measure for hyperspectral image classification[C]∥Proceedings of International Geoscience and Remote Sensing Symposium. Vancouver, BC, Canada:IEEE, 2011:1720-1723.
[21] ZENG Z L, ZHANG H J, ZHANG R, et al. A novel feature selection method considering feature interaction[J]. Pattern Recognition, 2015,48(8): 2656-2666.
[22] RAO Q, YU B, HE K, et al. Regularization and iterative initia-lization of SoftMax for fast training of convolutional neural networks[C]∥Proceedings of International Joint Conference on Neural Networks. Budapest, Hungary: IEEE, 2019: 19028828.
[23] ÅHLANDER K. Supporting tensor symmetries in EinSum[J]. Computers & Mathematics with Applications, 2003, 45(4):789-803.
[24] BODMANN B G, SINGH P K. Burst erasures and the mean-square error for cyclic parseval frames[J]. IEEE Transactions on Information Theory, 2011, 57(7):4622-4635.
[25] ALI S S, GHANI M U. Handwritten digit recognition using DCT and HMMs[C]∥Proceedings of International Conference on Frontiers of Information Technology. Islamabad, Pakistan: IEEE, 2014: 303-306.
[26] GOODFELLOW I J, POUGET-ABADIE J,MIRZA M, et al. Generative adversarial nets[C]∥Proceedings of the 28th Annual Conference on Neural Information Processing Systems. Montreal, Canada: Neural Information Processing Systems Foundation, Inc., 2014: 2672-2680.
[27] MUDAVATHU K D B, CHANDRA SEKHARARAO M, RAMANA K V. Auxiliary conditional generative adversarial networks for image data set augmentation[C]∥Proceedings of International Conference on Inventive Computation Technologies. Coimbatore, India: IEEE, 2018: 263-269.
