基于双重注意力机制的遥感图像场景分类特征表示方法
2021-04-06徐从安吕亚飞张筱晗崔晨浩顾祥岐
徐从安 吕亚飞 张筱晗 刘 瑜 崔晨浩 顾祥岐
①(海军航空大学信息融合研究所 烟台 264000)
②(清华大学电子工程系 北京 100084)
③(91977部队 北京 100089)
④(61646部队 北京 100089)
⑤(32144部队 渭南 714000)
1 引言
随着卫星与无人机等遥感观测技术的飞速发展,高分辨率遥感图像的数据总量和数据类型都不断增加,遥感信息处理正在进入“遥感大数据时代”[1]。高分辨率遥感图像相比于中低分辨率遥感图像包含着更丰富的纹理、细节和地物特征,在为遥感图像的自动解译工作提供了丰富信息的同时,也提出了更多的挑战和要求。
作为遥感图像解译工作中的重要组成部分,遥感图像场景分类(Remote Sensing Image Scene Classification, RSISC)是根据图像中包含的高层语义信息,将遥感图像映射到预定的类别标签中,实现对图像场景内容的自动判别。根据特征表示方法的不同,现有的研究方法主要可以分为基于手工特征的方法[2,3]和基于学习特征的方法[4,5]。尤其自AlexNet[6]的提出,以卷积神经网络(Convolutional Neural Networks, CNNs)为代表的基于学习特征的方法凭借较好的高层语义特征提取能力较大提高了算法的性能表现,逐渐取代了基于手工特征的相关方法。
基于CNNs的网络结构在计算机视觉领域不断提高着分类、识别等任务的性能表现,但在RSISC中,由于自然场景图像与遥感图像在成像内容和成像特点上的差异,用于自然场景图像的深度网络结构难以直接适用于RSISC问题。这主要是由遥感图像俯视成像带来的成像范围更广、尺度变化大和语义内容更复杂等问题导致的[7]。成像目标的繁杂性和语义内容的复杂性导致遥感图像场景分类面临着类内差异性大、类间相似性高的难点。为了解决该问题,已有较多研究方法提出,文献[8]提出了鉴别性卷积神经网络 (Discriminative-Convolutional Neural Networks, D-CNN)的网络结构,将度量学习和CNNs相结合,以拉近同类场景、推远异类场景图像特征表示间的距离,较好地提高了特征表示的鉴别性能力(discriminative ability),但该方法忽略了对遥感图像局部特征的关注;文献[9]提出了基于区域的深度特征提取网络,通过先检测后特征表示的方式,对图像中显著的局部区域进行特征提取,虽然关注了局部区域特征,但丢失了全局特征;文献[10]提出了多尺度CNN结构,利用两个不同尺度的网络结构分别提取图像的特征表示,以学习遥感图像中的尺度不变性特征;文献[11]通过先聚类再重排的方式挑选遥感图像中重要的局部区域进行特征表示,方法无法端到端训练,算法复杂度高;文献[12]利用注意力机制通过长短时记忆网络生成了高层特征图的重要性权重,对高层特征中每一个元素的重要性进行修正,虽然该方法可以端到端训练,但对每一个元素的修正没有实现对局部区域重要性的修正。文献[13]中针对遥感图像成像范围广、语义复杂的特点提出了适用于遥感图像特征表示的注意力模块,在高层特征的基础上,分别从通道维和空间维两个维度对图像的特征表示进行修正,以使得图像中显著区域和显著性特征更被关注,提高特征表示的鉴别性能力,该方法在遥感图像检索问题上得到了有效性验证。不同于文献[13]中注意力模块学习的无先验知识,文献[14]提出了一种局部和全局特征融合的特征表示方法,利用循环神经网络分别读取和捕获不同区域特征表示间的上下文关系,以生成不同区域的重要性权重,实现对局部重要区域的重点关注,整个方法可端到端地实现局部和全局特征的提取与融合训练,在多个公开数据集上达到了最佳实现(State-Of-The-Art, SOTA),但该方法只是在空间维对不同区域的重要性进行了修正,忽略了通道维重要性的作用。
基于以上讨论,针对遥感图像成像范围广、语义信息复杂的特点,而现有的特征表示方法又难以同时对遥感图像中的局部显著区域和显著性特征进行关注并有效地表达,本文提出了一种双重注意力机制的遥感图像场景分类特征表示方法,以CNNs提取的高层特征为先验信息,利用循环神经网络对上下文信息的提取能力,分别设计了一个通道维和空间维相结合的双重注意力模块,通过生成不同通道和不同区域的重要性权重,对原有高层特征表示中显著性特征和显著性区域两个维度的特征表示进行增强,减弱对非重要区域(背景区域)和非显著性特征的关注,提高特征表示的鉴别性能力。
2 本文方法
2.1 方法整体框架
卷积神经网络的强特征表示主要归因于其对高层语义特征的提取能力,如图1所示ResNet50所提取的高层特征(7×7×2048),其3维的特征结构可以分解为空间维(7×7)和特征维(2048)两个维度。一方面,空间维(7×7)与输入图像(一般为224×224)的空间位置存在着对应关系,即高层特征空间维中每一个像素(1×1)对应着输入图像中大小为32×32的图像块,因此,空间维(7×7)中每一个像素就可以看作输入图像中不同区域的特征代表;另一方面,卷积神经网络中不同的卷积层代表着不同的特征,每一层卷积层可能关注着不同类型的特征,因此,通道维的物理意义可以看作2048中不同类型的特征,对不同类别的遥感图像来说,决定其身份信息的特征也必定不相同。因此综上分析,为了进一步提高CNNs特征表示的鉴别性能力,需要从空间维和通道维两个维度进一步对高层特征进行修正,对重要区域和特征进行增加,非重要区域和特征进行减弱。
以CNNs提取的高层特征为基础,所提的双重注意力模块在通道维和空间维进一步对高层特征进行再权重化,方法的框架图如图1所示。以Res-Net50为例,以其最后一个大小为7×7×2048的卷积层为高层特征,依次连接通道维注意力模块和空间维注意力模块;通道维注意力模块以高层特征中各通道展开后得到的49维向量为输入,共2048个49维的通道向量依次输入到以门限循环单元(Gated Recurrent Units, GRU)[15]为基本单元的循环神经网络中,以提取各通道间的上下文关系,生成各通道的重要性权重,对高层特征的通道重要性进行加权修正;经通道注意力模块修正后的高层特征进一步输入到空间维注意力模块中,以高层特征中不同区域的特征表示为先验以此输入到以GRU为基本单元的循环神经网络中,输出得到不同区域的重要性权重,以此实现对显著性区域的增强、背景区域的抑制。最后,将经过通道注意力和空间注意力修正后的高层特征以全局平均池化的方式得到维度为2048维的特征向量,并与两个节点为2048的全连接层连接后,通过softmax函数预测输入图像的类别。
2.2 通道维注意力模块
经CNNs提取获得的特征图中,不同的通道代表着不同种类的特征,以ResNet50为例,高层特征图中包含2048个通道,可以看作2048种视觉特征。不同特征对遥感图像语义内容的表达起着不同的作用,通道维注意力模块的目的就是在CNNs提取的特征图基础上,根据不同通道的重要性程度,进一步生成各通道的重要性权重,实现对显著性特征的加强,对非显著特征的忽略。通道维注意力模块的具体网络结构如图2所示。
将得到的高层特征F(7×7×2048)按照空间维展开得到2048个维度为49的通道特征表示:F1={f1,f2,···,f2048},fi∈d49。文献[13]对通道注意力模块的生成是以随机初始化的方式,学习生成各通道的重要性,虽然起到了对不同通道重要性修正的目的,但对各通道间的相互关系和通道自身先验信息的利用不足。而循环神经网络作为处理序列信息的重要手段,能有效提取序列信息中的上下文关系,对进一步确定不同通道间的相互关系和重要性权重提供了解决方法。因此,为了准确生成不同通道间的重要性权重,本文以各通道的特征表示为先验信息,依次输入到以GRU为基本单元的循环神经网络中,GRU是一种包含参数更少,但在很多序列关系提取任务中都有较好性能表现的一种循环神经网络。通过对不同通道间的上下文关系的提取,生成

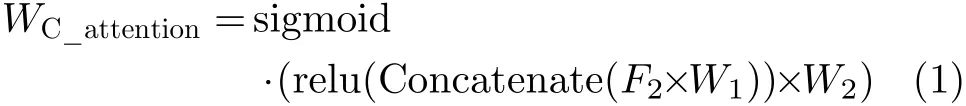
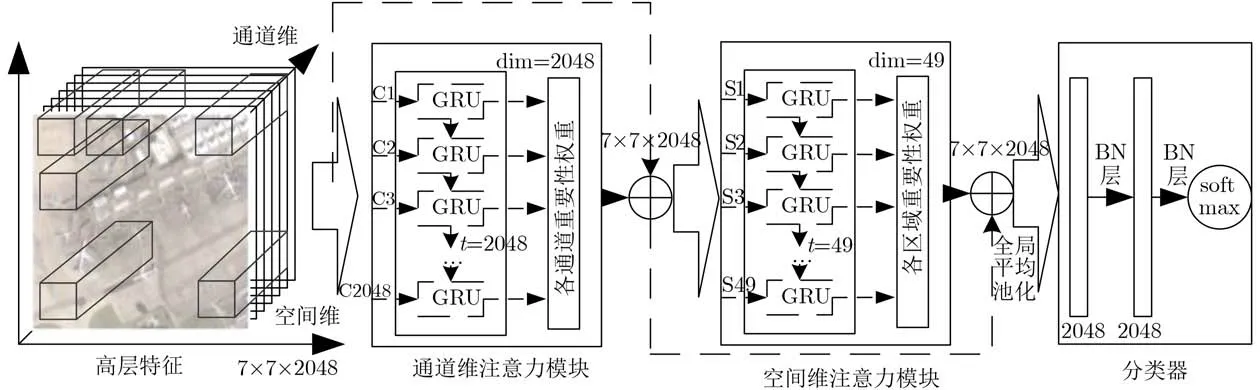
图1 本文算法框架图

2.3 空间维注意力模块
遥感图像广阔的成像范围导致遥感图像成像内容繁杂、目标众多,如何更好地关注显著性区域,忽略背景区域对于准确地实现遥感图像特征表示起着关键作用。空间注意力模块的目的就是在CNNs提取的高层特征基础上,进一步捕获不同区域特征的上下文联系,以生成各区域的重要性权重,实现对显著区域的重点关注,对背景区域的忽略。与通道维注意力模块的网络结构相似,空间维注意力模块的网络结构图如图3所示。
将经通道维注意力模块修正后的高层特征F3(7×7×2048)输入到空间维注意力模块中。由文献[14]可知,高层特征F3空间维中每个元素的特征表示(1×1×2048)可以看作原图像中局部区域的特征表示,因此,可以得到图像中49(7×7)个区域的高层特征表示F4={v1,v2,···,v49},vi∈d2048。与通道维注意力模块的结构类似,为了充分探索不同图像区域间的相互关系和重要性权重,利用循环神经网络作为不同区域序列信息的上下文关系提取器。将49个不同区域的特征表示依次输入到由GRU构成的循环神经网络中,并与共享全连接层和最后的分类全连接层相连,通过softmax函数输出不同区域的重要性权重 WS_attention;与通道维注意力模块相同,将空间维注意力模块的重要性权重与输入的高层特征按元素相乘,并与原输入的高层特征相加,得到最终的经通道维和空间维双重注意力模块修正后的高层特征F4。整个过程的计算如式(3)和式(4)所示
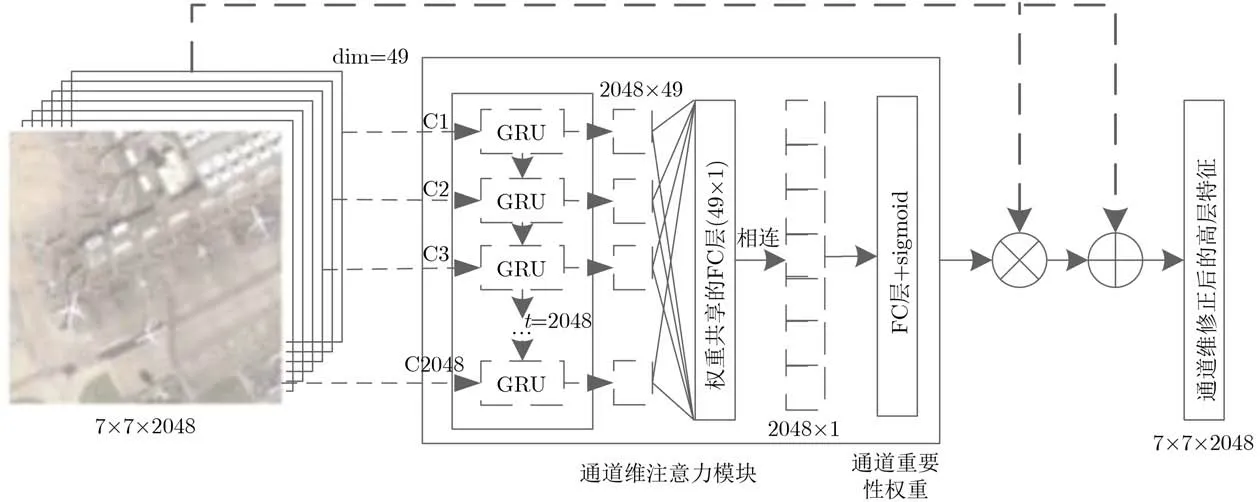
图2 通道维注意力模块网络结构图
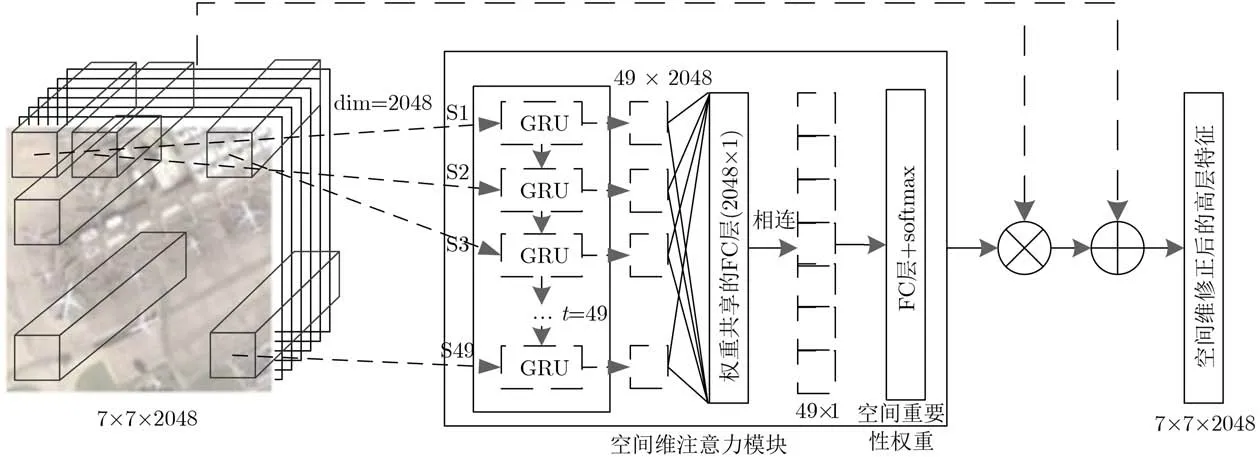
图3 空间维注意力模块网络结构图

3 实验验证与结果分析
3.1 数据集
为验证所提双重注意力模块的有效性,选取两个代表性数据集AID (Aerial Image Dataset)[16]和NWPU-RESISC45 dataset (NWPU45)[17]进行实验验证。数据集AID和NWPU45是遥感图像场景分类领域数据量最大、使用最广泛的两个数据集之一。AID中的数据来自谷歌地球,共包含10000张大小为600×600像素的航空场景图像,空间分辨率为1~8 m,数据集共被划分为30个类别,每个类别包含220~420张图像不等。数据集NWPU45也是收集自谷歌地球,覆盖率100多个国家的遥感图像,共包含31500张图像和45个场景类别,每类各包含700张大小为256像素×256像素的图像,分辨率为0.2~30 m。
为便于与相关方法进行比较,与相关文献[11–14,16,17]中的数据集设置保持一致,随机从两个数据集中挑选部分数据进行训练和测试,数据集AID分别挑选20%和50%进行训练,剩余的作为测试集;数据集NWPU45中随机挑选10%和20%的数据作为训练集,剩余的90%和80%作为测试集。
3.2 实验设置
在实验中,整个网络采用随机梯度下降(Stochastic Gradient Descent, SGD)优化器进行训练,数据批次大小(batch size)为64,数据集训练迭代30个循环(epochs),学习率设置为1e-6。
对于高层特征的获取,本实验主要采用VGG16和ResNet50作为基准网络,与所提的双重注意力模块相结合;在测试阶段,以整个网络结构倒数第2个全连接层作为遥感图像最终的特征表示;根据相关文献[11,14]中的验证,利用支持向量机作为测试阶段分类器的性能要优于训练阶段使用softmax的分类性能,因此,采用线性支持向量机作为测试阶段的分类器。
此外,算法的评价指标采用总体分类准确率(Overall Accuracy, OA)和混淆矩阵(Confusion Matrix, CM)两个综合性指标。OA的定义为测试集中分类正确的样本数占总测试集的百分比,计算方法见式(5)

其中,T为测试集中分类正确的样本数,N为测试集的样本总数。本实验中对每次测试结果重复10次,以10次的平均准确率和标准差作为最终的实验结果。
CM是分类任务中能更直观地表现算法性能表现的表达方式,其对角线元素表示各类别的分类准确率,其余元素 amn代表第m类被误分为第n类所占的比例,通过CM能更好地看出相近、混淆类别间的分类情况。
3.3 实验结果与分析
3.3.1 模型简化测试
为了验证双重注意力模块中各组成部分的作用,通过模型简化测试的方法对两种注意力模块的有效性进行实验验证,分别用C A(C h a n n e l Attention module)和SA(Spatial Attention module)代表通道注意力模块和空间注意力模块,将两类注意力模块分别与基准网络VGG16[18]和Res-Net50相连,在两个数据集上的实验结果对比如表1所示。
从实验结果中可以看到两个注意力模块的有效性,具体分析如下:首先,在两个基准网络VGG16和ResNet50上,两种注意力模块都能提升深度卷积网络所提取特征的表征能力,在两个数据集上的整体分类准确率都取得了较明显的提升,但空间注意力模块的性能提升要更优于通道注意力模块,本文认为这主要是由于受遥感图像在成像范围上广阔性的影响,通过空间注意力模块对局部显著区域进行重点的关注更能提高对遥感图像语义内容的理解;然后,通过表1可以发现两种注意力模块的结合能更进一步提高特征表示的鉴别性能力,使得基准网络的分类准确率大幅提升,尤其在数据量更大、更具挑战性的NWPU45数据集上,所提方法将原基准网络的准确率提升到了99%,证实了两种注意力模块针对的侧重点不同,可以相互补充、相互促进;最后,可以发现,两个基准网络的性能表现还存在着明显差距,ResNet50的特征表征能力明显超出VGG16,但所提的两个注意力模块都能较好适用于两个基准网络,证明了所提注意力模块的适用性是可以与任意卷积神经网络相结合。
3.3.2 与其他方法的对比及分析
为了进一步验证所提方法的有效性,在数据集AID和NWPU45上与近几年的相关基准方法进行比较,实验对比结果如表2和表3所示。
数据集AID下的对比结果如表2所示,本文所提方法在20%和50%两种训练比例下都实现了最佳性能表现,准确率超过了现有基准方法,分别达到了91%和95%左右的整体分类准确率。其中,2019年提出的方法ResNet_LGFFE将两种训练比例下原有最佳分类表现分别提高了2%和1.3%左右,在此基础上,本文方法又将整体准确率分别提高了0.5%和0.8%,达到了最佳实现(SOTA)。数据集NWPU45下的实验对比结果如表3所示,本文所提方法在两种训练比例下的准确率达到了98.55%和99.07%,接近于100%,较大提高了该数据集下的最佳实现。由此,在以上两个数据集下的表现可以看出所提方法的有效性。此外,将所提的双注意力模块与ResNet50相结合在数据集AID下所取得的最佳混淆矩阵展示如图4所示。
本文所提方法虽然能较明显地提升特征表示的鉴别性能力,在两个具有挑战性的数据集上取得了较好的总体分类准确率,但是对局部特征和局部区域的过分关注也反而导致对相似类别图像的混淆。如图4的混淆矩阵所示,所提方法对各个类别的分类准确率都比较高,尤其在50%的训练比例下,各个类别的准确率都接近1,但错误最明显的是将真值为类别22(度假村,resort)的图像大量误判为类别16(公园,park)。以图5中两个类别的代表性图像为例,可以发现两类图像在部分局部特征上存在较高的相似性,如游泳池、树木和建筑等。而所提方法是在原有特征表示的基础上对局部区域和局部特征的进一步关注,这就导致了所提方法在该数据集下训练学习后,对度假村和公园的局部相似特征过分关注,导致了对两个类别信息的混淆。
4 结束语
针对遥感图像场景分类存在的类内差异性大、类间相似性高导致的分类准确率不高的问题,本文提出了一种双重注意力模块的特征表示方法,在CNNs提取的高层特征基础上,分别从通道维和空间维各设计了一个注意力模块,利用循环神经网络的上下文信息提取能力,捕捉不同特征和不同区域间的重要性程度,以实现对重点区域和显著特征的重点关注,对背景区域和非显著特征进行忽略,以此提高特征表示的鉴别性能力。在两个公开数据集上,本文方法均超过了现有基准方法,验证了所提方法的有效性。但是,双注意力模块的引入不可避免地增加了一定的训练时间,对训练数据量有一定的要求,且通过实验结果可以发现对局部特征相似的部分类别容易出现混淆的现象,下一步重点从自监督学习的角度出发,减少模型对训练数据量的依赖。
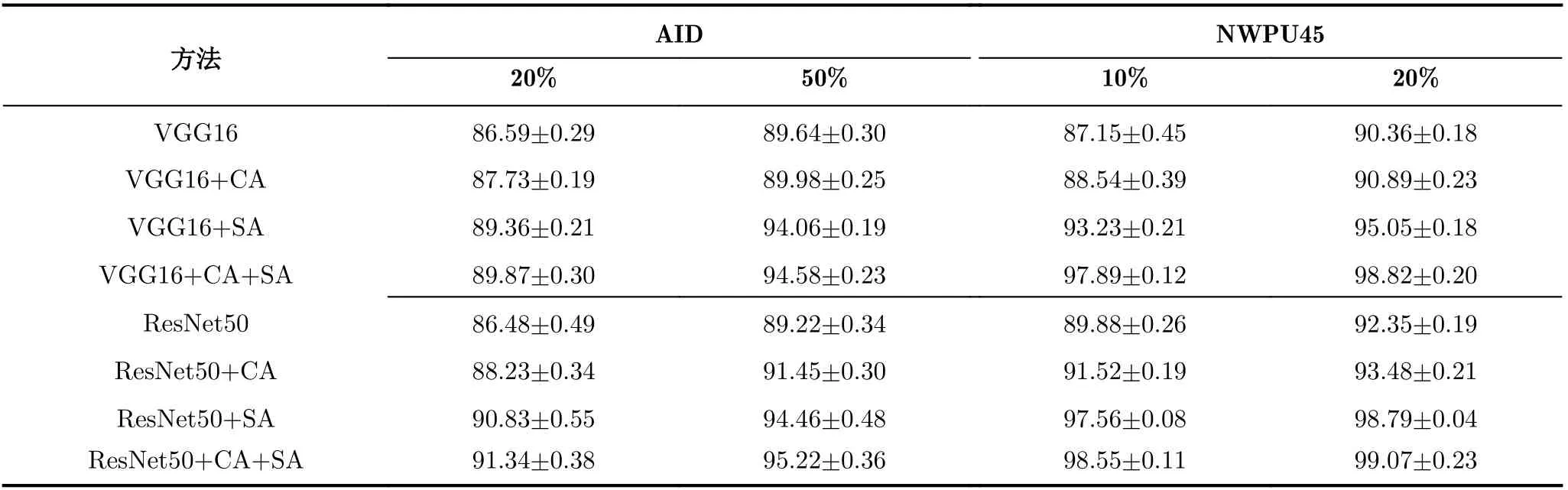
表1 数据集AID和NWPU45下的模型简化测试OA(%)结果对比表
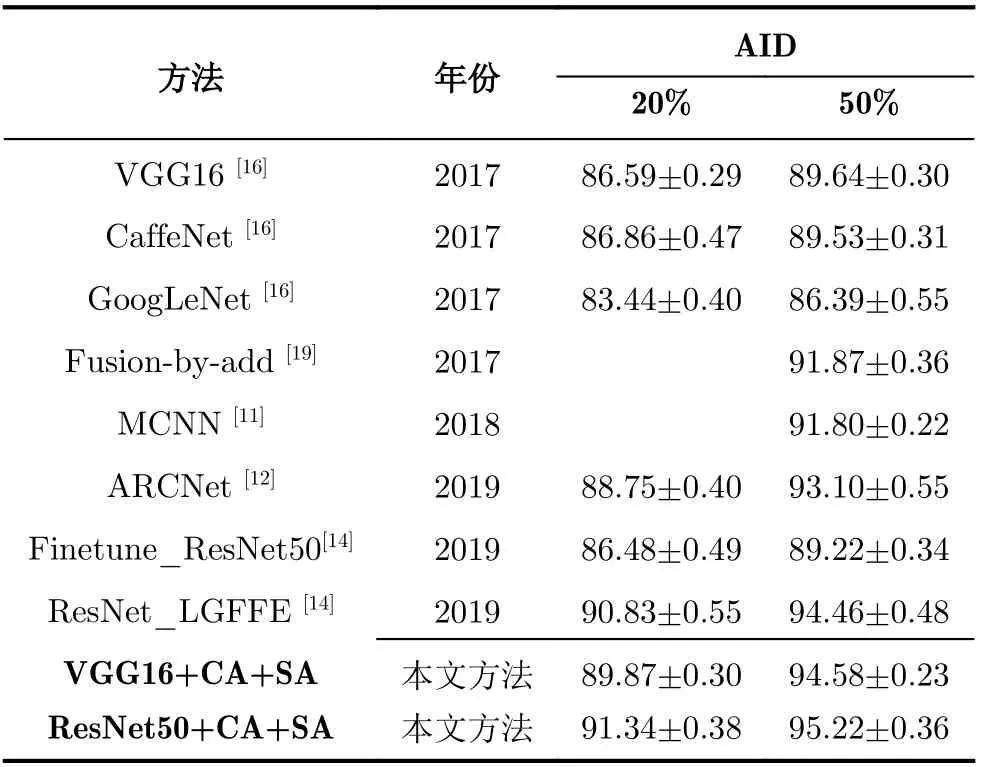
表2 数据集AID下所提方法与其他基准方法的OA(%)结果对比表
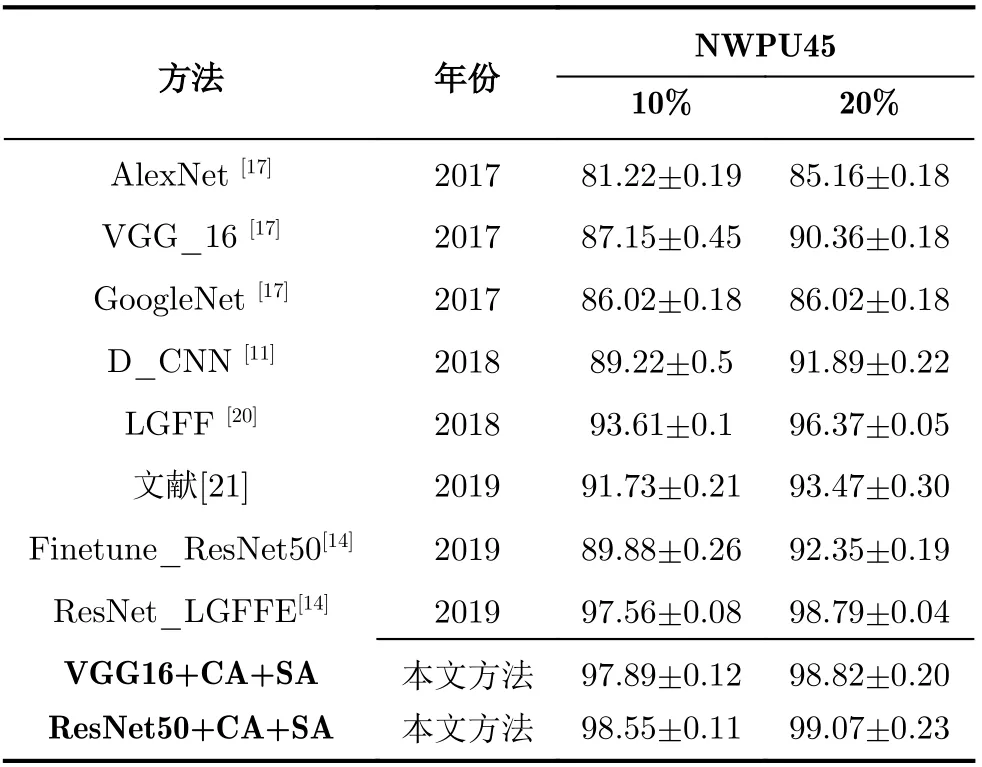
表3 数据集NWPU45下所提方法与其他基准方法的OA(%)结果对比表
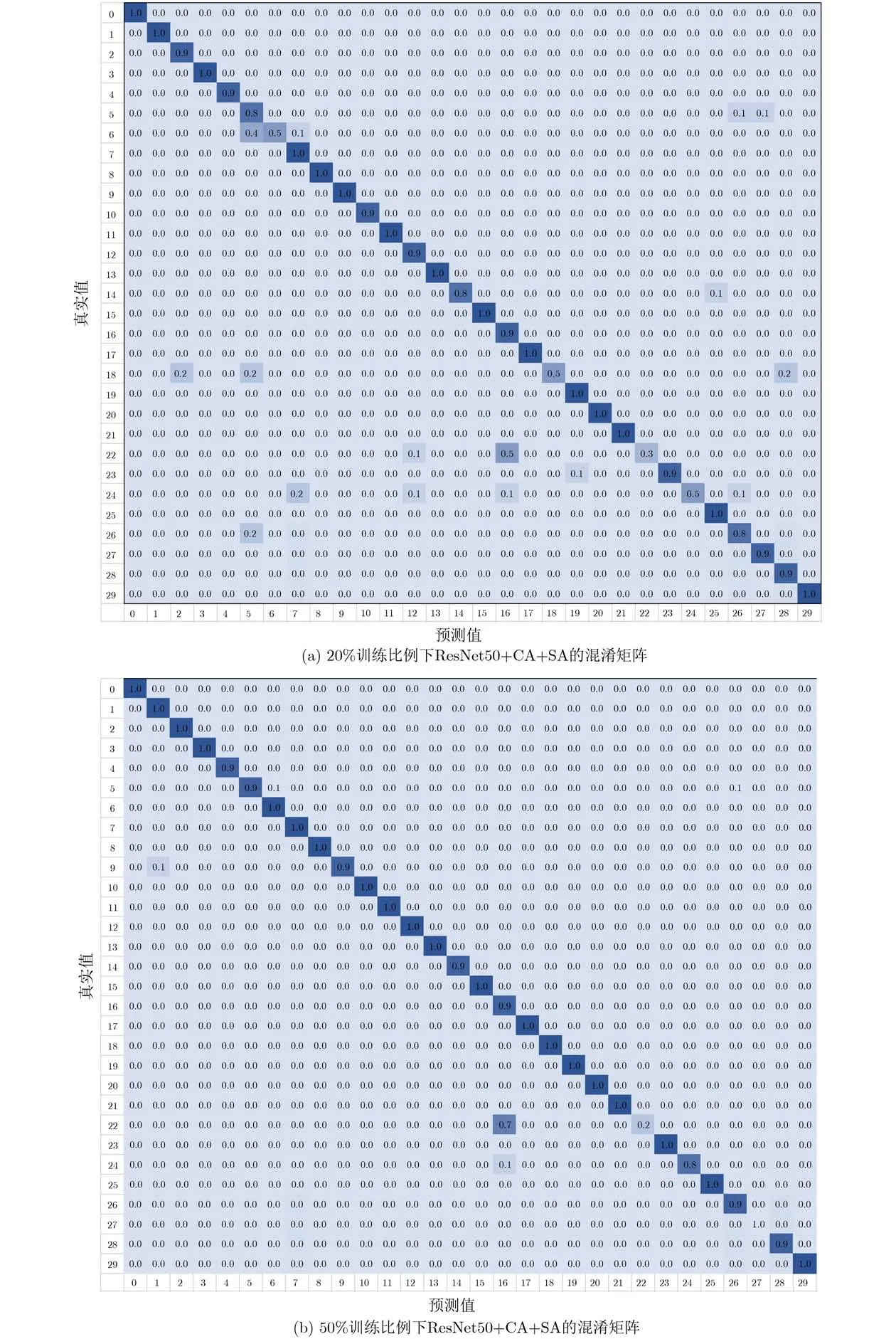
图4 数据集AID下所提方法的混淆矩阵图

图5 数据集AID在所提方法中的误判实例
