基于改进快速区域卷积神经网络的视频SAR运动目标检测算法研究
2021-04-06李睿安王旭东张劲东朱岱寅
闫 贺 黄 佳 李睿安 王旭东 张劲东 朱岱寅
(南京航空航天大学电子信息工程学院 南京 210000)
1 引言
视频合成孔径雷达(Video Synthetic Aperture Radar, ViSAR)具备高帧率分辨率的成像能力[1],可在云层、沙尘、烟雾等恶劣作战环境下,实现对地面运动目标全天时全天候的持续观测,并获取目标的运动参数等重要信息[2]。因此,视频SAR一经提出就成为研究热点。美国桑迪亚实验室利用重叠模式下的回波信息,实现了Ku频段视频SAR的实时高分辨率成像[3]。美国国防部高级研究计划局也已经研制出了235 GHz的视频SAR成像系统。此外,美国喷气推进实验室、德国Fraunhofer研究所等研究机构,近年也研制出了不同频率、不同体制的太赫兹雷达成像系统[2]。目前,国内视频SAR系统的研制与国外仍具有较大差距。
由于视频SAR一般工作于太赫兹波段,运动目标极易产生多普勒频移,从而在目标真实位置处留下阴影[4]。国内外学者对视频SAR中出现的阴影现象,提出了很多处理方法。文献[5]利用Hough变换,检测在SAR图像中呈现条纹形状的运动目标阴影。文献[6]通过对序列图像进行背景补偿,利用混合高斯背景模型提取运动目标阴影。文献[7]将相干变换检测方法拓展到视频SAR中,通过实测数据验证了此方法在处理视频SAR数据上的优势。上述研究方法大多是建立在视频SAR帧间图像高度配准情况下的,如果未得到有效配准,则会带来较多的虚警。文献[8]借助美国桑迪亚实验室获取的对地视频SAR数据,采用了深度神经网络对运动目标阴影进行检测,并结合滑动密度聚类算法和双向长短期记忆网络减少漏警,取得了较好的效果。但是,对于快速运动目标,由于其合成孔径内阴影脉冲比例太小,成像后目标阴影并不明显。此外,当视频SAR工作于对海模式时,由于海面后向散射强度较弱,更加难以区分海面背景杂波和舰船阴影。
因此,本文重点对视频SAR下的运动目标“亮线”特征进行检测。借助课题组的MiniSAR系统获得的视频SAR图像,将改进的快速区域卷积神经网络(Faster Region-based Convolutional Neural Networks, Faster R-CNN)算法与K-means聚类相结合,利用残差网络提取原始SAR图像的高维特征,并引入特征金字塔网络,通过组合池化层前后不同尺度的特征图为后续的算法提供多尺度组合的图像特征,有效降低了视频SAR的虚警率,实现视频SAR模式下的运动目标检测。
2 视频SAR工作原理
根据轨迹的不同,视频SAR一般分为圆迹模式和直线模式。雷达平台在一定高度上,沿着一定轨迹持续飞行,通过调整波束指向,保证雷达波束始终覆盖目标区域,然后利用子孔径后向投影等算法进行处理,合理分割后实现视频成像[9]。视频SAR成像对雷达工作频率有很高的要求,而高频率视频SAR系统目前国内也较难实现,因此成像时,可根据实际情况使用帧间重叠复用技术。
由于太赫兹频段相关器件的硬件研制难度大、费用高,课题组研制的X波段MiniSAR系统,借助聚束SAR模式、帧间复用技术、PFA成像技术,实现了观察场景的视频SAR成像[10]。图1为MiniSAR成像系统的飞行图。由于该MiniSAR系统工作于X波段,相比于太赫兹波段相差较大,相应的多普勒敏感度也要远低于正常的太赫兹视频SAR系统,因此在本课题组实现的视频SAR成像中难以观察到有效的运动目标阴影,也无法利用阴影检测相关技术实现视频SAR运动目标检测。图2所示为观察场景的视频SAR成像结果(分别是第90帧、第640帧和第960帧)及合作运动目标的标注结果(黄色圆圈标注),可以看出不同帧数的运动目标有明显差异。表1为部分MiniSAR成像系统参数。
3 基于改进Faster R-CNN的视频SAR运动目标检测
深度学习目标检测算法[11]一般分为1阶段和2阶段两类算法,1阶段以YOLO系列算法为典型代表,2阶段以R-CNN系列算法为典型代表[12]。其中,2阶段算法对目标检测率更高,根据课题组研制的MiniSAR成像系统采集到的视频SAR中多小目标且难以检测的特点,本文选用Faster R-CNN算法。图3为设计的基于改进Faster R-CNN的视频SAR运动目标检测流程图。
3.1 数据集的构建
利用视频SAR构造数据集。首先对视频分帧,取出静态SAR图像并进行存储。本文使用的特征提取网络为卷积残差网络ResNet101[13]。由于ResNet101网络对输入图像的分辨率没有固定要求,因此得到的SAR图像可直接输入网络进行训练和测试。然后,为提高模型的泛化能力和鲁棒性,对视频SAR数据进行数据增强,并以一定比例划分训练集和测试集。

图1 自制MiniSAR系统飞行图

图2 观察场景的部分视频SAR成像结果及合作目标分布情况(黄色圆圈标注)

表1 部分MiniSAR系统参数
3.2 基于改进Faster R-CNN的视频SAR运动目标检测

图3 基于改进的Faster R-CNN的视频SAR运动目标检测流程图
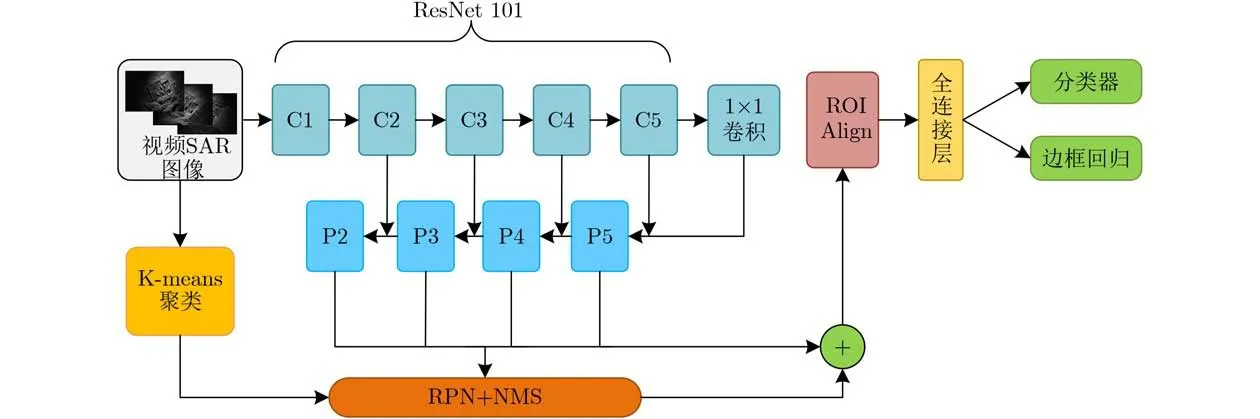
图4 改进的Faster R-CNN算法流程图
图4为本文改进的Faster R-CNN算法流程图。WILD TRACK公开数据集上已证明残差网络Res-Net101检测性能优于VGG16。因此,本文采用ResNet101残差网络提取视频SAR目标特征,以达到加深网络层数,高维特征较好提取的效果。
3.2.1 K-means聚类算法
K-means聚类算法作为一种无监督学习,在1967年由Macqueen提出,该算法是聚类分析中应用最广泛的算法[14]。使用该算法对视频SAR数据中大大小小的运动目标矩形框按相似度划分成n组,先随机选择n个数据点作为初始质心,然后通过计算两点距离和设置阈值不断更新质心来得出最终结果。
传统Faster R-CNN算法中的anchor box人为设置。然而针对不同的数据集,待检测目标有所不同,因此修改anchor box的大小和数量是很有必要的。Faster R-CNN算法的原始训练集是Pascal VOC数据集,与视频SAR中的运动目标大小分布不同,因此本文对视频SAR目标进行聚类,然后将结果作为anchor box的设置依据,以达到加快网络收敛和提高检测精度的效果。
3.2.2 区域生成网络
区域生成网络(Region Proposal Network,RPN)由一个全卷积网络实现。RPN用于判断视频SAR区域建议是否包含目标,若包含则输入后续网络。同时,RPN也将输出目标可能的候选区域。其中,定义目标的候选框和真实框的边框重叠度为交并比(Intersection Over Union, IOU)。通常定义IOU>0.7时,预测结果为正样本(目标),否则为负样本(背景)。非极大值抑制(Non-Maximum Suppression, NMS)算法[15]广泛应用在边缘检测和目标检测中,解决了分类时候选区域框的重叠现象,除去冗余框,提高了检测效率。
将FPN结构与ResNet101网络结合,可以对不同特征的视频SAR目标根据RPN产生的区域建议进行动态调整,并在不同深度的特征图上进行特征提取,从而达到更好的预测结果。图5为特征金字塔结构,图5中放大的区域使用1×1卷积核,将处理过的低层特征和高层特征进行累加,这样更加准确的视频SAR“亮线”位置信息和高维特征可以在一张特征图上显示,既减少了特征图数量又不改变特征图大小。
3.2.3 ROI Align
原Faster R-CNN中ROI Pooling层,将不同大小的视频SAR预选框裁剪成固定尺度的特征图,在整个网络框架中含有两次取整过程,那么降采样之后的结果框会与视频SAR原图产生偏差,对视频SAR较小运动目标的影响较为突出。而ROI Align将对每个候选区域保持浮点数边界,解决了上述偏差问题。然后,利用双线性插值法将区域固定到特征图大小为14×14。最后,所有结果输入分类层和回归层,分类层判断候选区域运动目标阴影的概率,回归层将给出运动目标的坐标。
4 基于实测数据的验证与分析
本文实验在Window10系统下进行,利用深度学习框架Tensorflow,硬件环境配置:GPU为GeForce GTX 1080Ti, CUDA 8.0,显存11 GB。
4.1 数据集的构建
深度学习需要大量的数据集进行网络训练,利用本课题组研制的MiniSAR系统实测得到的34 s视频SAR数据进行运动目标检测。通过对视频SAR进行分帧,共得到1021帧SAR图像,其中包含运动目标的有效SAR图像为806帧。一般情况下,训练集与测试集按7:3比例划分,由于视频SAR运动目标特征较少,因此按2:1划分训练集与测试集,将536帧原始图片用于训练,余下270帧作为测试集。
对536帧的原始图片进行数据增强处理以达到扩充数据集的目的,常用方法有平移、旋转、加噪等。通过对原始图片进行45°, 90°, 135°, 180°,225°和270°的随机旋转和加噪处理,使得训练集扩充为原训练集的4倍,部分数据强化如图6(a)—图6(f)所示。

图5 FPN结构
4.2 特征金字塔结构对Faster R-CNN算法的影响
特征金字塔结构将不同深度的特征图进行融合,提高了对视频SAR图片特征的利用。本文使用的数据集目标尺寸大小不一,其中较小目标不占少数,而Faster R-CNN在最后一层进行卷积池化时,许多小目标信息将大幅度减少甚至被遗漏。因此,引入FPN结构可以大大提高对小目标的检测率。针对测试集的270帧SAR图像的小目标进行统计,共含83个小目标。准确率为检测出的正确目标个数与真实总个数之比,漏检率为未被检测出的目标个数与真实总个数之比,误检率为错误检测出的目标个数与真实总个数之比。表2统计了特征金字塔结构对Faster R-CNN算法的影响。可以看出在83个小目标的检测中,结合了FPN结构的算法检测率提高了38.8%,同时误检率也有所下降。

图6 数据集的构建
4.3 网络结构参数对训练结果的影响
分辨不同网络结构参数对训练结果的影响,要采用控制变量的方法训练网络。为了抑制模型复杂度,避免过拟合,本文保持权重衰减率0.0001,动量0.9不变。通过改变训练次数、学习率和激活函数,研究这些参数对训练结果的影响。
首先,为减小局部最小值概率,采用warm-up分阶段学习率方法训练网络。即设初始学习率(Learning Rate, LR)为loss1,当训练次数达到N1和N2时,学习率下降为0.1×loss1和0.01×loss1。本文设置N1为20000步,N2为40000步。其次,传统Faster R-CNN算法使用默认激活函数ReLU。ReLU函数实现了单侧抑制的效果,当输入为正时,导数为1,允许基于梯度的学习;当输入为负时,导数为0,从而无法更新权重,导致神经元“坏死”。对于本文使用的视频SAR数据集中较小目标的检测,为了解决这个缺点,可以在ReLU函数的负半轴引入一个极小的泄露(leaky)值,使得负半轴的信息不至于全部丢失。具体参数对训练结果的影响如表3所示。
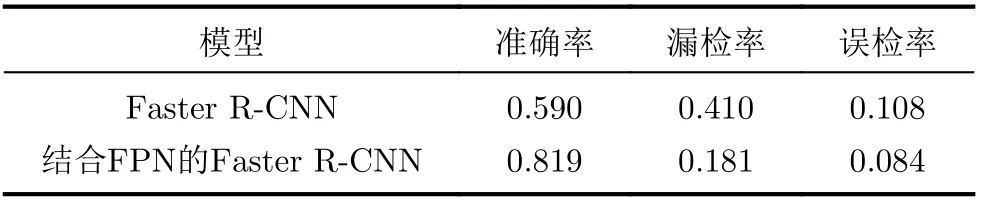
表2 有无FPN 结构的性能对比

表3 具体参数对训练结果的影响
可以看出网络结构参数对检测结果的影响各不相同。随着训练次数的增加,网络Loss值逐步下降至收敛。不难看出,训练次数设置在50000步最佳。激活函数选择使用Leaky-ReLU对检测结果的提升有一定的好处,但影响不是很大。学习率作为深度学习的主要参数,决定目标函数能否收敛到局部最小值以及何时收敛到最小值。一般范围内,学习率越小,收敛速度越慢。当学习率由0.010变为0.001时,运动目标检测的准确率提高了5.5%。
图7(a)—图7(f)分别是第54帧、第78帧、第120帧、第150帧、第191帧和第210帧的传统Faster R-CNN算法在单帧SAR图像上完成运动目标的初步检测结果。红色矩形框是正确检测出的运动目标,黄色椭圆框是漏检的运动目标,绿色椭圆框是误检的目标信息。其中,第54帧检测结果虽然检测出了运动目标,但是可以看出检测出的框大小与实际目标的大小有所出入;第150帧运动目标图像出现一定程度的间断,检测结果出现了结果不匹配情况;第191帧由于运动目标的信息较弱,发生了漏检和误检情况。由此可以看出传统Faster R-CNN算法的准确性低,漏检率和误检率高。
通过FPN充分利用目标信息,减少了运动目标的漏检情况。然后采用K-means聚类算法对算法进行预处理,得到一组合理的anchor box的设置,这样使得检测出来的框更加接近运动目标的真实框。通过以上方法的处理和网络参数的调整,大大降低了运动目标的漏检,实现了对虚警的抑制。图8(a)—图8(f)分别是第54帧、第78帧、第120帧、第150帧、第191帧和第210帧为改进后的Faster R-CNN算法的运动目标检测结果。
4.4 K-means聚类预处理
首先对运动目标的长宽进行K-means聚类,得到5个不同的长宽尺寸,分别为[124, 45], [518, 119],[830, 199], [226, 63]和[336, 120]。然后对运动目标的长宽比进行K-means聚类,得到5个聚类中心:2,4, 7, 11, 25。因此设置anchor box宽高比为{2, 4,7, 11, 25},面积为{4×4, 8×8, 16×16, 32×32,64×64}。在保持其余参数不变的情况下,anchor box的设置分为凭经验设置和利用K-means聚类结果设置两种。表4可以看出anchor box的设置通过K-means聚类,在算法准确率上得到了一定的提高。
为了更好地对比传统Faster R-CNN算法与改进后的Faster R-CNN算法的性能,表5为测试集270帧视频SAR图像共279个运动目标的统计结果。改进后的Faster R-CNN算法较传统Faster R-CNN准确率上提高了9.8%,误检率减小了3.6%。
5 结束语
本文提出了一种结合FPN的Faster R-CNN算法的视频SAR的动目标检测方法。对Faster R-CNN算法中的部分参数进行了定量分析,并利用K-means聚类方法对改进的Faster R-CNN算法进行优化,提高了该算法针对视频SAR运动目标的检测率,该方法同样适用于其他参数形式的视频SAR系统。将深度学习方法用于雷达领域,实现了针对视频SAR中多尺度目标的高精度端对端的目标检测,为视频SAR运动目标轨迹跟踪奠定基础。

图7 传统Faster R-CNN检测结果

图8 改进的Faster R-CNN检测结果

表4 anchor box设置对训练结果的影响

表5 不同模型下运动目标检测性能对比
