人工智能领域知识图谱构建与分析∗
2021-04-04赵毓诚陈建军
赵毓诚 陈建军
(1.沈阳航空航天大学计算机学院 沈阳 110136)
(2.沈阳北软信息职业技术学院 沈阳 110000)
1 引言
当下最火热的时事热点莫过于人工智能。无论最近名声大噪的谷歌Deepmind团队开发的Al⁃phaGo系统,还是1997年的“深蓝”击败国际象棋大师,2011年IBM开发的人工智能程序“沃森”在智力问答游戏中战胜人类冠军,这些大事件都表明了人工智能急速兴起与蓬勃发展。美国自2016年以来,先后发布了《为人工智能的未来做好准备》《国家人工智能研究与发展战略规划》《人工智能、自动化和经济》等多部白皮书,将人工智能置于维持其主导全球军事大国地位的科技战略核心。与此同时国内也推出相应的政策,2017年国务院印发了《新一代人工智能发展规划》,2018年发布了《人工智能标准化白皮书(2018版)》来应对人工智能时代的到来。无论是民用还是军用人工智能技术都已成为未来战略的制高点,因此了解人工智能技术发展动态,掌握当下应用水平为当务之急。与此同时互联网的数据层出不穷,如何从大数据中对当下最火热的人工智能信息进行分析与挖掘就显得尤为重要与紧迫。
在传统的知识表示与管理的框架下,获得与知识相关的周边内容困难繁杂,知识间的关联性并没有展现出来,知识之间形成知识孤岛缺少联系[1]。Google团队在2012年提出了知识图谱的概念[2],其目的是为了增强Google搜索的用户体验,提高搜索引擎的语义检索能力[2]。将知识图谱作为知识引擎用来解决知识间缺少关联的问题。
知识图谱是一种语义网络,一种语义知识库,语义网络的概念可以追溯到20世纪五六十年代用于知识表示,被人们称为万维网之父的Tim Bern⁃ers Lee于1998年提出的语义网(Semantic Web)[3]和在2006年提出的关联数据(Linked Data)[4]都和知识图谱有着千丝万缕的关系,随后知识图谱在此基础上发展而来。同时随着人工智能的技术发展和应用,知识图谱在搜索引擎上的大获成功,知识图谱一跃成为当下最火热的技术,已被广泛应用于智能搜索、智能问答、个性化推荐、内容分类等科研学术领域和工业界的产品中[5]。知识图谱通常可以分为通用知识图谱和领域知识图谱,其中领域知识图谱也被称为垂直知识图谱[6]。通用知识图谱是一种开放域的知识库构建,旨在构建出大量的实体与实体间的关系,包括全领域的信息,覆盖大量的知识点,对于知识的精度要求没有领域知识图谱高,而领域知识图谱则是在一个封闭的特定域中的将领域信息构建成领域知识图谱。业界上通用知识图谱近年来经过大力发展已经取得了不错的成果,具有代表性的有Google知识图谱,通过将Free⁃Base[7]和Wikidata[8]大量的丰富的开放域知识进行整合构建成知识库形成知识图谱,还有YAGO[9]、NELL[10]等知识库,采用互联网挖掘的方法从Web网页数据中自动抽取三元组知识,国内有百度的知心,搜狗搜立方,复旦大学的zhishi.me[11]等比较著名的通用知识图谱。在领域知识图谱方面比较具有代表性的有医疗领域的知识图谱、国内的“天眼查”知识图谱等。
目前学术界对于领域知识图谱构建主要集中在医学领域、商业领域和军事领域,比如金碧漪构建的健康领域知识图谱[12],于彤等面向中医药工作者提供知识服务构建的中医药知识图谱[13],丁君怡等为改善武器装备组织结构而构建的军事领域武器知识图谱[14],袁旭萍通过使用深度学习方法构建的商业领域知识图谱[15]等。在知识图谱应用分析上,张慧等[16]针对文献数据量大、格式复杂等问题,通过构建引文及前言的知识图谱分析出标准起草人之间的人物关系、标准与起草人之间的关系等关系和其趋势发展,袁丽等[17]根据文献分析了我国舞龙舞狮运动的发展趋势,利用可视化软件分析出该运动的基本发展脉络,发展影响因素等相关发展趋势。
本文对最近十余年的AAAI和IJCAI会议中的论文集(共10844篇)进行了整理分析和挖掘,构建了包含500000个反映研究主题、研究人员等实体及其关系的三元组的人工智能领域知识图谱,并在此基础上对人工智能领域的研究热点和发展趋势进行了分析和讨论。
2 人工智能图谱构建过程

图1 领域知识图谱构建框架
知识图谱构建过程,一般采用两种设计结构,一种为自底向上的构建方法[5],一种为自顶向下的,自顶向下的构建指的是预先定义好模式层,在此基础上将通过数据获得的知识实体对应的加入到知识库,进行一种槽填充模式。对于大型通用知识图谱来说,该构建方式需要利用一些现有的结构化知识库作为其基础知识库,形成图谱模式层,例如Freebase项目[7]就是采用这种方式,其中绝大部分数据来源于半结构化的维基百科信息。自底向上方法则与之相反,是从数据出发,在数据中提取出实体信息,这些信息经过筛选,选择正确的的信息添加到知识库中,再根据这些实体构建顶层的模式层[18]。目前,大多数知识图谱都采用自底向上的方式进行构建,包括Google公司构建的知识图谱[19]。
本文人工智能领域知识图谱的构建过程采用自底向上和自顶向下的混合设计结构,模式层采用自顶向下的构建模式,数据层采取自底向上构建模式,构建框架如图1所示。
为了研究人工智能领域的热点及发展趋势,本文知识图谱模式层设计涉及到的本体有领域专家、领域文献与领域热点,这些信息内容都在论文中有所体现,因此将作者信息,题目信息,摘要信息,关键词信息,会议来源信息,年份信息作为知识图谱数据层的知识获取的重要信息来源,通过以下四个步骤成功构建人工智能领域知识图谱。
1)模式层构建。本文采用自顶向下的构建方法,针对论文数据集所包含的信息内容,以及通过早期手工构建的知识图谱和现有知识图谱own⁃think图谱对比,发现领域专家、领域论文与领域热点这些节点对于整个人工智能领域体系具有关键性的作用,同时这些节点内容也相对开放,比较容易获得,通过数据间关联分析可以得到领域内大量的有价值的数据信息。因此模式层设计如图2模式层设计所示,模式层节点包含有领域文献、领域相关人员和领域研究热点。模式层节点属性设计,其中文献节点属性包含会议名称、会议年份、论文标题、论文摘要(url代替摘要展示)、论文作者、关键字。模式层节点关系设计:研究热点与人物之间研究内容关系,人物与论文之间作者关系,研究热点与文献间关键词关系,人物间合作关系,研究热点间共现关系。

图2 模式层设计
2)数据采集与整理。以模式层为基础,我们对模式层所需数据进行采集整理,选取人工智能两个顶级会议aaai与ijcai为数据来源,抓取aaai会议2000年~2018年间的论文信息以及ijcai会议发表年份为2007年~2018年间的论文信息。根据模式层设定,我们抓取信息内容为论文所在期刊、论文标题、摘要、作者、关键字、发表时间,两个会议总共抓取论文10844篇作为原始数据,其中关键字信息在许多篇章中为缺失信息,得到数据统计信息如表1所示。

表1 数据集统计信息
通过设计网络爬虫采集器将领域会议网站上的论文数据进行数据采集,根据爬取需求设计固定采集格式,将每篇会议论文的发表期刊、论文标题、摘要、作者、关键字、发表时间依次对应存储,转化存储为本地结构化信息。图3展现了采集会议论文数各个年份会议发表论文数,可以看到随着时间的推移,两个会议发表论文的数量都呈现上升趋势,18年的发文量较十年前都提升一倍,表明人工智能变得更加火热,成为越来越重要的技术与研究方向。

图3 会议发文数统计
3)领域信息抽取。关键字是一篇文章的主题内容,能简明直接地反映出该文章的阐述内容,从表1统计信息看出,爬取的数据中只有aaai会议部分论文(2010年和2012年~2017年间)含有关键字,并不是所有的论文都包含关键字,相比模式层其他数据为缺失内容,因此抽取关键字则成为了领域信息抽取步骤的重点内容。摘要是一篇文章的缩略信息,整个文章的内容梗概,涵盖全文重要内容的短文,所以采用论文的摘要信息作为关键字抽取的数据源。本文主要采取两种关键字抽取方法Tex⁃tRank[20]和Rake[21],分别使用两种算法对论文摘要进行关键字抽取,实验结果在下文实例分析中讨论。统计过程中发现关键字并非全在摘要中出现,有许多关键字出现在论文标题中,未在摘要出现,本文称之为未登录关键词,根据爬取的论文数据集,其中含有关键字的论文数量为3064篇,含有未登录关键字的论文数量为2796,含有未登录关键字的论文数量的比例达到91%,具体年份的含有未登录关键词的论文数如图4所示,因此将文章的标题与摘要进行联合抽取,以提升关键字抽取的准确率。

图4 关键词统计
本文选取2010年~2017年间aaai会议中含有关键词的论文作为数据集,对其中的摘要进行关键字抽取,采用TextRank和Rake两种算法进行对比实验,经统计含有关键字的论文共3064篇,以论文中的关键字作为标准答案集进行关键字抽取实验。在统计中发现其中2796篇论文包含的关键词未在摘要中出现,本文称之为未登录关键词。与此同时发现论文标题中含有大量关键字信息,论文标题也是论文的核心表现内容,因此对标题也进行关键词抽取,但因为标题字数较短,单独进行关键词抽取效果并不理想,会出现大量抽取关键词为空的现象,因此本文选择将标题和摘要进行联合,采用摘要+标题的形式作为输入,经过关键词抽取算法抽取关键词,表3为抽取关键词实验结果。
其中第一行数据为年份信息,最后一行为该年出现的关键词总数,中间为通过算法抽取正确的关键词数量,我们可以看到在是否使用标题和摘要进行关键词抽取上,两种算法都展示出相同的结果,联合抽取效果都要优于只使用摘要进行关键字抽取的结果,因此可以得出结论,将论文标题与摘要进行联合关键字抽取要优于仅使用摘要进行关键字抽取。

表3 关键词抽取结果表
4)根据模式层进行知识连接。将爬取得到的论文信息与抽取的信息根据模式层进行关系连接,关系设定为人物之间的合作关系,人物与研究热点之间的研究内容关系,研究热点间的共现关系还有论文基本信息如作者、摘要等与论文之间的属性关系,最后形成实体-关系-实体的三元组。图5为通过以上四个步骤构建出的领域知识图谱展示(展示部分节点),以Zhi-Hua Zhou为例,通过知识图谱搜索作者为Zhi-Hua Zhou年份为2015年以及会议为aaai的相关内容。

图5 知识图谱展示
3 图谱分析
依据本文构建的领域知识图谱对人工智能领域进行分析,对文献作者以及近年来研究热点进行分析,由每届会议的发文数可以看出人工智能领域受到的关注越来越多,更多科研工作者投入到领域的研究当中。
图6为发文作者统计,根据统计我们可以看出近年来发文作者的数量变化,整体呈现上升趋势,同时我们根据本文构建的知识图谱对其中近十年的作者发文数进行统计排序,得到发文数最多的作者top-N,同时关联作者的研究热点进行数据挖掘。表2中列举出了发文量前10名的作者,可以了解到近年来人工智能领域发文比较活跃的研究人员,其中每个人都发文50篇以上。从图谱的人物合作关系中我们可以对其中的作者进行关系发现,比如当前TOP10作者的合作关系网络,从关系网络中搜寻未合作但存在相对路径的连通节点,进而发现隐含的可合作关系,为领域人物发现提供可能,找出领域人物发展与合作状态。
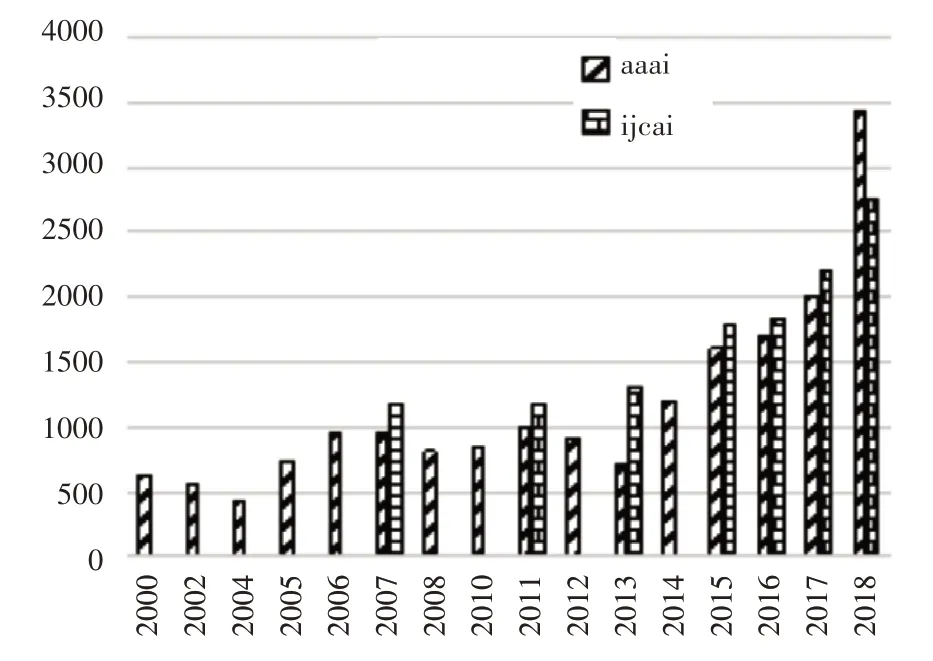
图6 发文作者数

表2 作者发文数统计表
根据图谱查找的领域关键人物,同时对领域关键人物研究内容进行分析,了解关键人物的研究内容变化,从而了解领域发展变化。以发文作者排名第四位的Zhi-Hua Zhou为例,图7为使用本文构建的知识图谱对作者Zhi-Hua Zhou进行研究内容查询(展示部分节点),从图谱的查询结果中可以看出Zhi-Hua Zhou的研究热点主要集中为Machine Learning,multi-instance multi-label learning,deep learning等一些相关算法模型,表明该领域活跃人物的研究内容总体情况,如果想要对该领域人物进行关注则需要对他的研究内容进行深入了解。从图谱查询情况来看也与实际相符和,侧面验证了本文构建的图谱的准确性。
掌握个人研究热点后对领域整体研究热点进行分析把握,图8为图谱领域研究热点查询统计(展示部分节点),对图谱中不同年份的关键字进行统计查询,其中数字节点为年份,其他为该年中关键字出现篇章数大于7篇的关键字,从图中可以看出位于中心位置的关键字为machine learning,rein⁃forcement learning,game theory,planning,crowd⁃sourcing,表明这些研究内容一直是人工智能领域的研究热点,近两年,我们可以看到像classifica⁃tion,deep learning,neural network作为当年的研究热点出现,据此掌握领域研究热点的大致变化,图谱中心位置的为连续性研究领域热点,周围节点为非连续性研究热点,分析内容符合实际,同时也证明本文构建的图谱的准确性与有效性。

图7 人物研究内容图谱
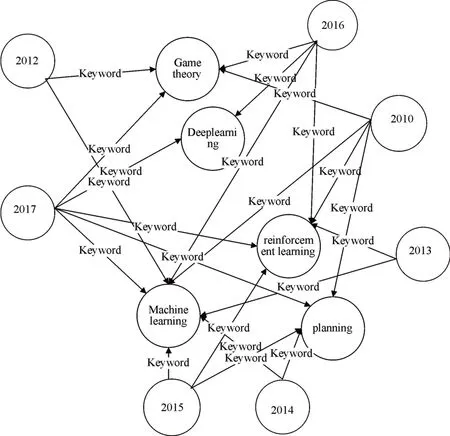
图8 领域研究热点图谱
4 结语
本文通过四个步骤面向人工智能领域顶级会议论文构建领域知识图谱,成功构建了人工智能领域的文献知识图谱,通过该图谱可以有效地了解近年来领域内的热点变化,领域相关人员的研究热点,掌握领域人物与研究热点信息以及论文发表状况并得到了以下结论。
1)成功构建了领域知识图谱,图谱节点包括文献题目、作者、领域研究热点、摘要、文献发表期刊和发表年份,节点关系包括文献与摘要、标题、作者、关键字的属性关系,人物之间的合作关系,关键词与人物的研究内容关系,关键词之间的共现关系,共构建实体三元组五十万条;
2)通过图谱掌握到领域热点人物top-N,并根据作者之间的合作关系图谱,为探寻潜在合作关系提供依据;
3)依据研究内容图谱网络,掌握人工智能领域研究热点发展趋势,发现有连续性和非连续性两类研究热点,连续性热点为领域持续研究方向内容,比如machine learning,game theory等,非连续热点则为某时刻新兴研究热点,或有重大突破的研究热点比如近年来的deep learning,neural network等,表明研究重心偏向目前的研究热点,据此帮助了解领域发展概况;
4)根据领域热点人物与研究内容图谱,可以发现热点人物与热点研究内容的交叉集合,找到人物与热点的连通路径,比如Zhi-Hua Zhou的研究热点主要集中为Machine Learning,multi-instance multi-label learning,deep learning等方面,为领域专项研究提供可靠的依据。
