基于CNN-BLSTM的食品舆情实体关系抽取模型研究
2021-04-02王庆棒汪颢懿张青川袁玉梅
王庆棒,汪颢懿,左 敏,*,张青川,温 馨,袁玉梅
(1.北京工商大学 农产品质量安全追溯技术及应用国家工程实验室,北京 100048;2.北京工商大学 计算机与信息工程学院,北京 100048)
食品舆情领域知识图谱以食品行业为基础,挖掘食品舆情信息的相互联系,在食品安全、食品舆情分析等方面都有着重要作用。食品舆情的实体关系抽取是构建食品舆情知识图谱的重要基础工作之一,旨在抽取句子中已标记实体对之间的语义关系。
食品舆情信息的挖掘依赖于数据的多维度特征[1],多层次的网络模型实现了基于大规模语料的自动挖掘特征信息,目前的研究主要分为基于特征向量的方法[2]、基于核函数的方法[3]和基于神经网络模型的深度学习方法。黄卫春等[4]为了解决特征空间维度过高的问题,提出了4种文本文类的特征选择算法;姚全珠等[5]采用了子树特征的实体关系抽取方法;Zeng等[6]采取建模的方式,在卷积神经网络(convolutional neural network,CNN)中引入了位置向量,但对位置信息的挖掘程度有些不足;Nguyen等[7]在CNN上使用不同尺度的卷积核对文本的语义关系进行了表征,但该模型仍然是基于浅层语义关系。本研究拟在注意力机制上,采用基于词语位置的语义角色标注(semantic role labeling,SRL)方法,使模型更好地对词汇特征和位置信息进行学习,并提高模型的精确度。
Santors等[8]在CNN中对目标函数做出了改进,虽然该方法提高了实体关系的识别力度,但是CNN却仍然不能很好地学习语句中上下文的语义信息;Zhang和Wang[9]利用双向循环神经网络来学习语句中的上下文语义,然而循环神经网络本身具有梯度消失和梯度爆炸等问题。双向长短时记忆(bidirectional long short-term memory,BLSTM)网络解决了梯度爆炸的问题,同时能学习句子中的上下文语义信息,因此本研究模型中引入了BLSTM网络。
翟社平等[10]采用BLSTM网络来提取句子特征,不过该模型对于词汇特征的挖掘还有些不足;Zhou等[11]改进了BLSTM网络,使其模型能够学习词汇中的某些信息,然而对词汇位置语义等重要信息没有进行很好的处理;吴佳昌等[12]提出了基于依存关系和双通道CNN的关系抽取方法,对词性的依存关系做出了进一步研究。本研究在BLSTM网络中引入了基于位置的语义角色标注方法,依据食品舆情领域的文本特点,引入了领域词机制,进一步挖掘词语层面上的语义信息,使模型更好地识别不同实体及其关系。
本研究拟针对食品舆情领域的实体关系抽取方法,在分析现有的实体关系抽取方法优劣的基础上,采用CNN-BLSTM双网络模型结构,区分不同的实体关系的同时,有效学习文本远程语义的信息和结构。
1 数据来源与处理
1.1 数据来源
模型训练所需数据集选用独立构建的食品舆情领域数据集(FO-Data)。通过搜集、整理2017~2019年食品伙伴网[13]、中国食品公众科普网[14]、食安通网[15]公布的文章数据,归纳为包装材料、保健食品、焙烤食品、茶叶、宠物食品、调味品、方便食品、蜂蜜、罐头、果蔬、进出口、酒业、粮油、认证体系、乳业、商超、食品储运、食品机械、食品检测、食用菌、糖果、添加剂配料、畜禽肉品、饮料、有机食品、渔业、水产转基因食品27个行业,包括除港澳台、西藏、新疆、内蒙古、宁夏和甘肃以外的全国26个省份。
实验平台使用基于PyTorch(https:∥pytorch.org/)的开源深度学习框架,构建深度学习模型。训练及使用的系统平台为美国微软公司的Windows和开源的LinuxCentOS7系统。
1.2 数据处理
采集的语料数据集按句划分,剔除无效句子,分别标注句子中的实体对及实体关系,并作为模型的训练输入样本,即每一条输入语料分为3个部分,第1部分为输入句子,第2部分为实体对,第3部分为实体关系。数据集整体划分为3个子数据集:训练集、测试集和验证集。子数据集的规模见表1。

表1 数据集规模的统计Tab.1 Statistics of data set size
1.3 评价指标的计算
本研究采用准确率P、召回率R和F1值作为实验结果优劣的评价指标,计算见式(1)~式(3)。
(1)
(2)
(3)
式(1)~式(3)中,TP为把正类预测为正类的数量;FP为把负类预测为正类的数量;FN为把正类预测为负类的数量。
2 基于CNN-BLSTM的食品舆情实体关系抽取模型建立
2.1 模型描述
在模型的开始,使用提前训练好的词嵌入模型,将食品舆情领域的语料进行文本向量化处理。之后将得出的词嵌入,分别作为CNN层和BLSTM层的输入,由CNN生成卷积核,BLSTM生成隐层向量。模型将会分成2个部分引入网络注意力机制:首先,将提前构建好的领域词词库与当前的每个词语进行逐一匹配,在经过基于位置感知的领域词语义注意力机制的计算后,得出影响向量,同时模型将影响向量与CNN卷积核输出的向量进行结合,影响CNN模型输出结果;其次,模型会对词语的语义角色进行标注,判断各个词语是否为核心主语或谓词,经过基于位置感知的语义角色注意力机制的计算,将影响向量传播到BLSTM的隐层向量中计算,从而影响BLSTM的输出结果。最后模型将会在2个网络输出向量的结合层累积影响向量,进一步得出实体及其关系抽取结果。网络模型整体过程如图1。

图1 CNN-BLSTM模型Fig.1 Model of CNN-BLSTM
模型的输出层包含3层输出向量。第1层输出的向量是关于实体关系的输出向量,第2层是关于实体标注中主体标签的输出向量,第3层则是关于实体标注中客体标签的输出向量。
在实体关系抽取中,本研究在网络的输出层采用了SoftMax函数,对于每种关系进行归一化处理,得到每种关系的概率值P,计算见式(4)。
P=softmax(CWT+bc) 。
(4)
式(4)中,W为权重向量,T为权重向量的转置,C为输出向量,bc为偏置向量。对于实体标注部分,输入句子的每一个词都会被指派一个实体标签,标签采用相同的编码模式:0-1标签(1是主体或者客体)。因此,实体标注问题可以转变为:对于给定的长度为m的句子S(s1,…st,…sm),假设标注输出结果为Y(s)(y1,…yt,…ym),在已知序列S下,找出使得Y=(y1,…yt,…ym)的概率为P(y1,…yt,…ym)的最大的序列[y1,…yt,…ym]。计算见式(5)。
(5)
式(5)中,S为输入的句子,y为预测的关系概率,W为权重向量,ψi(y′,y,s)=exp (WTy′,yzi+bi,y)是一个隐含函数,W为权重向量,T为权重向量的转置,yi为句子中第i个词向量,zi为句子中第i个词向量的权重向量,bi为第i个词向量的偏置向量。解码时最高条件概率计算见式(6),使用维特比算法可以进行有效的解码运算。
=arg maxy∈Y(s)P(y|s;W,b) 。
(6)
网络模型对于实体标注主体的处理过程如图2。实体标注中客体的标注过程与主体标注类似,其输出的位置是模型输出的第3层向量。经过最后的连接层可以得到客体的标注结果。

图2 实体标注主体的处理过程Fig.2 Process of entity labeling subject
本研究以2层向量的方式,来对关系实体的主客体做出区分,第1层表示主体的标记结果,第2层表示客体的标记结果。
2.2 基于位置感知的语义角色注意力机制建立
SRL是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元 (语义角色) ,如施事、受事、时间和地点等。本研究通过SRL划分语义角色,得到不同的句子成分,使位置注意力影响在不同的语义角色中进行传播。
SRL会将词语的语义角色、依存关系等标注出来,例如:对于“馒头的铝残留量不符合国家标准”这句话进行语义角色标注,其标注的结果为“馒头”“铝残留量”“不符合”“国家标准”,并且对它们的依存关系进行了标注,最终可以确定各词语的语义角色,从而确定核心主语和谓语的位置,标注过程如图3。

图3 语义角色标注的处理示例Fig.3 Example of semantic role labeling
在根据语义角色判断语句中的核心主语和谓词之后,需要让模型学习到更多的位置信息,从而提高准确率。假设语义角色在特定距离上的影响遵循隐层维度上的高斯分布,基于此假设定义影响的基础矩阵K,其每一列表示与特定距离对应的影响基础矢量。K的数学定义见式(7)。
K(i,u)~N[Kernel(u),σ] 。
(7)
式(7)中,K(i,u)代表第i维度中语义角色距离为u时相应的影响。并且N是符合Kernel(u)值的期望值和标准差σ的正态分布。Kernel(u)是高斯核函数,用它来模拟基于位置感知的影响传播,其数学定义见式(8)。
(8)
根据语义角色的位置关系,可以计算每个语义角色的影响矩阵,通过计算的积累,最后获得每个特定位置下语义角色的影响向量,见式(9)。
Srj=KCj。
(9)
式(9)中,Srj代表语义角色在位置j处的累计影响向量,Cj表示一个距离的计数向量,来测量属于各种核心语义角色的数量。将Cj展开,其标准的计算方法见式(10)。

(10)
式(10)中,w代表句子中的一个词,S为词语序列,即一个句子。pos(w)表示w在核心语义角色中出现的位置集合。符号[]为判断符,如果条件满足则为1,否则为0。
最后将得到的影响向量,与BLSTM的隐层向量结合。基于位置感知的语义角色注意力机制在BLSTM的执行和传播过程如图1右侧模型。
2.3 基于位置感知的领域词语义注意力机制建立
本研究的实体关系抽取领域为食品舆情领域,为了将食品舆情领域的语言特点融入网络中,引入了领域词机制。依据食品舆情领域的专业词汇,构建食品舆情领域词词库,依据词语是否匹配到领域词词库的原则,筛选词语,确定领域词汇。
对于词语的匹配计算见式(11)。
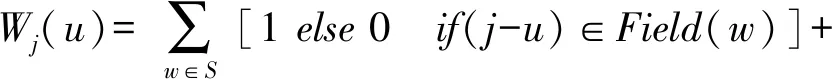
(11)
式(11)中,Field(w)表示w在语句中领域词匹配的位置集合。符号[]是判断功能,如果条件满足则为1,否则为0。
对于位置的影响力传播,与2.3中基本相同,结合式(4)、式(5)得出基于位置感知的领域词影响向量公式[式(12)]。
Fwj=KWj。
(12)
模型最后将得到的影响向量与CNN卷积层得出的最终向量结合。基于位置感知的领域词语义注意力机制在CNN的执行过程为图1左侧。
3 结果与分析
3.1 实验参数的设置
本研究在词嵌入层使用的是100维的Glove词向量;BLSTM和CNN的网络输出向量的维度为128维;位置影响传播的距离μ设置为8。另外,选取了交叉熵作为深度学习网络的目标函数,同时使用Adam算法作为网络的优化器,进行网络参数的更新。表2是对比模型中所需的参数设置。

表2 网络模型参数Tab.2 Parameters of network model
3.2 关系抽取实验结果
对比模型整体分为2类:一类是无注意力机制的常规CNN和BLSTM神经网络,一类是引用注意力机制的CNN和BLSTM单神经网络。不同模型分别在独立构建的FO-Data数据集上进行训练及预测实验,表3是关系抽取结果。
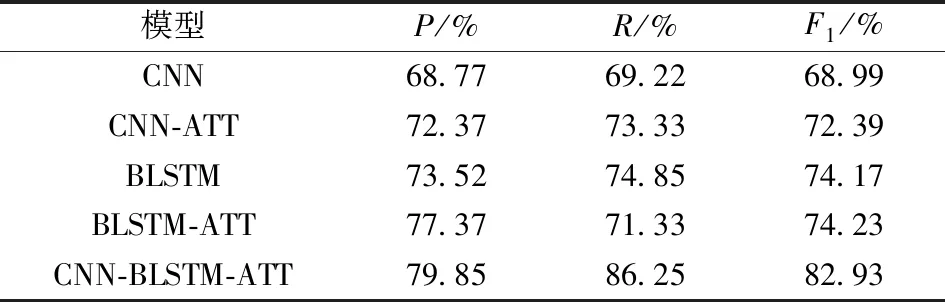
表3 不同模型的关系抽取结果Tab.3 Experimental results of relationship extraction of different models
表3的实验结果显示:在食品舆情语料中,常规的CNN模型的准确率表现良好,但是在召回率上表现不佳,因此本研究在CNN的基础上,对CNN模型引入了注意力机制,其召回率有了明显的提升。对于句子整体的语义而言,CNN模型对比BLSTM模型的学习机制依然有所欠缺,这在第3个对比模型中得到了进一步的验证。同时,本文发现BLSTM整体上要比CNN具有更好的性能表现。值得注意的是,双网络模型均有着较好的准确率和召回率,因为BLSTM不仅能在上下文中根据语义角色有效地处理位置权重的分配,而且在CNN领域词上,进一步优化了网络整体的注意力权值计算。对于实体关系抽取而言,CNN-BLSTM网络模型针对句子结构上有着较好的反馈,同时又不抛弃垂直领域词汇带来的更多有用的信息。
3.3 实体抽取实验结果
关系抽取需要在验证集和测试集上观测模型的表现优劣,表4展示了不同模型在FO-Data数据集上的实验指标数据。为了证明模型的有效性,加入了Zhou等[11]提出的基于注意力机制的BLSTM模型和殷纤慧等[16]提出的改进的CNN模型。实验结果表明:本研究提出的模型在各评价指数方面均有较大的提升。
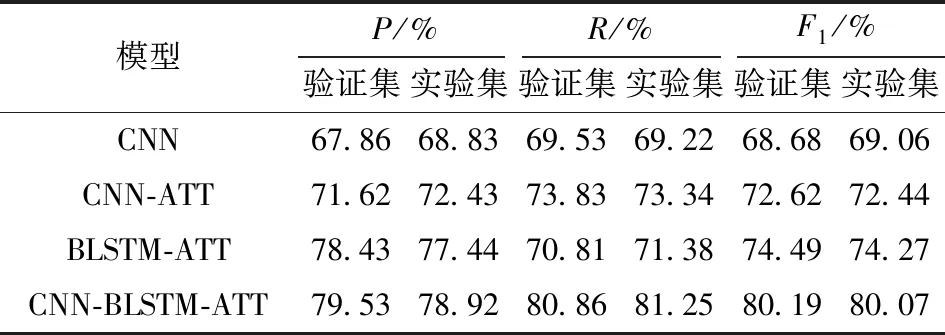
表4 不同模型的实体抽取结果Tab.4 Experimental results of entity extraction of different models
Zhou等[11]利用BLSTM模型进行实体关系抽取,但未对句子中词语的语义角色关系的信息加以利用,而本研究引入的基于位置的语义角色关系注意力机制,充分利用了实体和非实体词语的语义角色,从而能够进一步提升模型效果。
本研究提出的CNN-BLSTM模型和两大注意力机制,提高了CNN对于特殊领域词的识别能力和BLSTM快速捕捉上下文的实体联系的能力,使得模型能够在食品舆情领域中比单独的CNN和BLSTM模型有着更加优秀的准确率和召回率。
3.4 实验参数分析
3.4.1损失函数下降趋势分析
BLSTM是实体关系抽取领域常见的深度学习网络模型,因此,本研究对比了BLSTM网络模型和CNN-BLSTM模型的损失函数下降趋势,如图4。

图4 损失函数下降趋势分析Fig.4 Downtrend analysis of loss function
根据图4的实验结果可以发现,CNN-BLSTM模型在训练的前期与BLSTM模型表现相似,但随着模型训练次数的迭代,CNN-BLSTM模型的表现逐渐更优,而且学习能力和迭代速度仍然保持较高的表现。因为模型充分结合了食品领域的特殊词汇信息及其语义角色关系,使得模型能够快速提取出更多有价值的句子信息,所以模型整体的收敛速度更快,而且能够进一步提升针对具有复杂句意或者多重句子结构的语句的表现。
3.4.2词嵌入维度分析
由于CNN-BLSTM模型的前部分引入了词嵌入,所以词嵌入的向量维度会对实验结果产生一定的影响,为了展示这种影响关系,研究构建了不同词向量维度对模型F1值的影响,如图5。
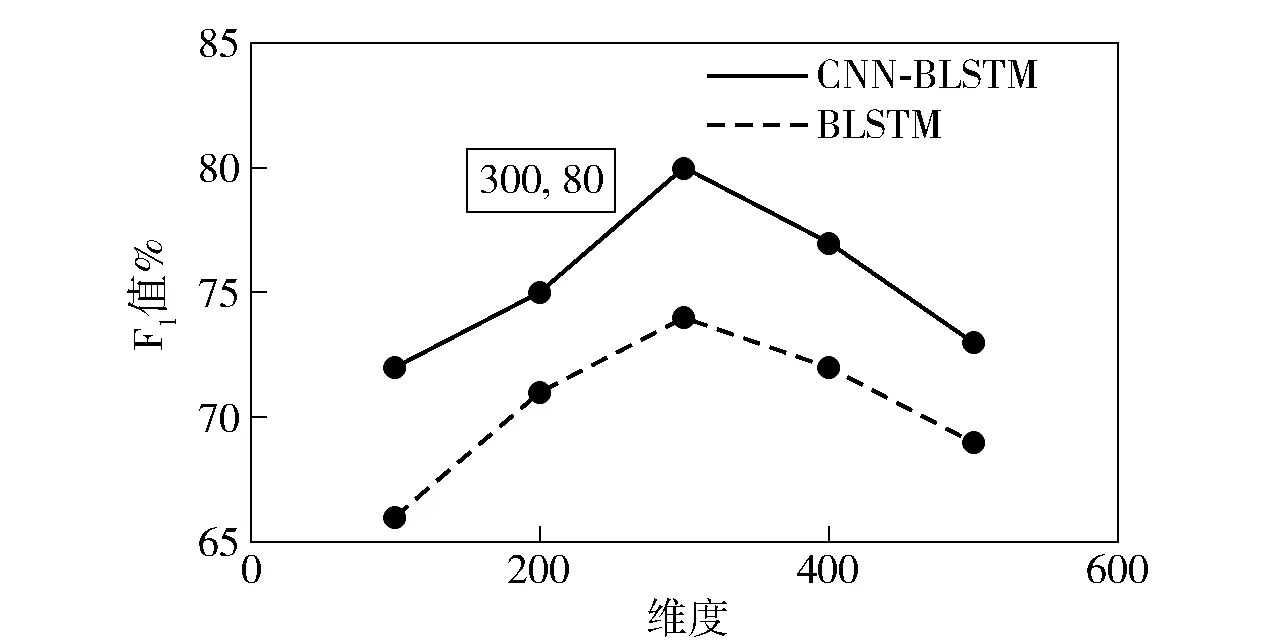
图5 不同词向量维度下的实验结果分析Fig.5 Experimental comparison of word vectors in different dimensions
实验结果表明,词向量在300维附近,模型的整体表现更优,因而本模型使用的词嵌入向量维度为300维。
4 结 论
本研究提出了一种基于CNN-BLSTM的食品舆情实体关系抽取模型。该模型在文本向量化的基础上,通过语义角色标注抽取舆情语句的主谓语语义,运用上下文语义角色的位置感知来更新词语权重,构建基于位置感知的语义角色注意力机制;依据食品舆情领域词词库,运用领域词的位置感知来更新词语权重,构建基于位置感知的领域词注意力机制,实现了食品舆情实体对多关系抽取。对比实验结果表明,该模型比以往常用的深度神经网络模型性能更优。
